去年我们把业务从虚拟机迁到K8s后,第一件暴露的问题不是应用Bug------是监控看不见了。
旧环境里的Zabbix Agent能采到CPU/内存/磁盘,但K8s里Pod是瞬时的,IP是动态的,同一个服务这次跑在node-3上、下次漂到了node-7。传统的"盯着主机看"的监控模型直接失效。
于是我们启动了K8s可观测性选型。调研了一圈发现:方案远不止Prometheus一家,但每家的"好"和"痛"藏在不同环节------不是在功能列表里,是在跑了一个月的生产数据里。
本文把三套方案放在同一套K8s集群(50节点/300Pod)里跑了一个月,从四个维度记录真实差距。
一、实测环境与方法
| 项目 | 规格 |
|---|---|
| K8s集群 | 1.27, 50节点(20台EC2 m6i.xlarge + 30台m6i.large) |
| Pod规模 | 约300个(含Java/Go/Python微服务+Nginx Ingress+Redis) |
| 测试周期 | 2026年5月全月(31天) |
| 评估人 | 2名运维工程师(同时负责日常值班) |
评估维度只盯四个:
- 指标采集:能否覆盖K8s核心对象(Node/Pod/Deployment/Service)的关键指标
- 日志关联:告警发生时能不能从指标一键跳到相关日志
- 告警→工单闭环:从告警触发到工单关闭的完整链路是否断裂
- 月度真实成本:含人力维护,不含一次性搭建
二、方案A:Prometheus + Grafana + AlertManager + Loki(开源全家桶)
2.1 实际搭建清单
开源方案不是装一个Prometheus就完了。我们对"生产可用"的定义是:指标+日志+告警+可视化都能用。实际搭建的组件清单:
| 组件 | 用途 | 版本 |
|---|---|---|
| kube-prometheus-stack | Prometheus + Grafana + AlertManager 一键部署 | 56.0 |
| Prometheus Operator | 管理ServiceMonitor/PodMonitor | 0.71 |
| Thanos | 长期存储+多集群聚合 | 0.34 |
| Loki + Promtail | 日志采集与检索 | 2.9 |
| AlertManager | 告警路由+分组+静默 | 0.26 |
| 自建Webhook服务 | AlertManager → 工单系统 | Python Flask |
2.2 跑了一个月的真实感受
指标采集:强项。 kube-prometheus-stack 一装好,Node/Pod/Deployment/StatefulSet的指标全有了,社区Dashboard模板(315、15759等)导入Grafana就能看。配合PromQL,查"过去5分钟CPU Throttling最高的前10个Pod"这种问题非常顺手。
promql
topk(10, rate(container_cpu_cfs_throttled_seconds_total[5m]))日志关联:断层。 Prometheus发现Pod重启频繁 → 想看Pod日志 → 切到Loki → 输入{pod="order-svc-7d9f8"} → 查询。这个过程不算复杂,但不是"一键"的------你得知道Loki的Label Selector语法、记住Pod名称、在两个界面间切换。凌晨三点值班的时候,这种"两三个Click"的摩擦会被放大。
告警→工单:最大的痛。 AlertManager能发微信/钉钉/邮件,但发完就完了。告警升级、工单跟踪、SLA计时------AlertManager不管这些。我们写了一个Flask Webhook服务做中转,核心逻辑约200行:
python
@app.route("/webhook", methods=["POST"])
def alertmanager_webhook():
alerts = request.json.get("alerts", [])
for alert in alerts:
if alert["status"] == "firing":
ticket = create_jira_issue(
summary=f"[{alert['labels']['severity']}] {alert['annotations']['summary']}",
description=format_alert_body(alert),
labels={"source": "prometheus", "namespace": alert['labels'].get('namespace')}
)
return "ok", 200看起来简单,但上线三周踩了两个坑:
- Jira API限流:一次大规模Pod驱逐触发了200+条告警,Webhook瞬间打了200个Jira请求,触发了Jira Cloud的Rate Limit,后80个工单全丢了
- 告警恢复后工单还要手动关:AlertManager发了
resolved,但Jira工单不会自动关闭------值班的人每周要花半小时清理"已经恢复但工单还开着"的遗留工单
成本:
| 项目 | 月成本 |
|---|---|
| EC2 (Prometheus+Thanos 2台 m6i.xlarge) | $280 |
| EBS 500GB (Thanos存储) | $50 |
| Loki S3存储 (30天保留) | $60 |
| 人力维护 | ~$1,200 (约0.3人月) |
| 合计 | ~$1,590 |
人力取0.3人月是基于我们2人团队的记录:Thanos Compactor偶尔OOM需要调参、Loki索引偶尔损坏需要重建、AlertManager规则更新、Webhook服务维护。月均投入约50小时。
三、方案B:Datadog(全托管SaaS)
3.1 接入方式
Datadog Agent通过DaemonSet部署到每个节点,自动发现K8s资源并采集指标+日志+Trace。开通了Infrastructure + APM + Logs三个模块(没开Profiling和DBM)。
yaml
# datadog-agent-values.yaml (Helm)
datadog:
apiKey: "xxx"
appKey: "xxx"
kubeStateMetricsEnabled: true
logs:
enabled: true
containerCollectAll: true
apm:
portEnabled: true
processAgent:
enabled: true3.2 跑了一个月的真实感受
指标采集:最强。 接入即用,K8s Dashboard比Grafana任何社区模板都精美------Deployment→Pod→Container逐层下钻,每个Pod的CPU/内存/网络/磁盘/IO全有。最让我们印象深刻的是自动关联:Pod CPU高 → 自动显示同一Deployment下所有Pod的对比曲线 → 再自动关联到最近的Deployment事件。
日志关联:最佳体验。 在指标曲线上选一段时间 → 点"View Logs" → 直接看到这段异常时间窗口内的所有日志,无需手动输入任何查询。对凌晨排障来说,这个"零输入、一键跳转"的价值非常大。
告警→工单:仍是断点。 Datadog Monitor → Webhook → Jira,和Prometheus方案面临同样的问题。Datadog的告警规则比AlertManager好用(有ML异常检测、预测、复合条件),但告警触发后的流转同样依赖外部系统。Datadog本身有Incident Management模块,但它不够"ITSM"------没有SLA计时、没有值班轮转、没有工单状态流转。
成本:这才是问题。 按Pod数计费,300个Pod月底账单:
| 模块 | 单价 | 月费用 |
|---|---|---|
| Infrastructure (300 Pod) | $15/host/mo (20节点) | $300 |
| APM (300 Pod) | $31/host/mo (含在Infra) | 按Pod计: 300×$2.5 |
| Logs (300 Pod, ~150GB/天) | 0.10/GB 摄取 + 0.01/GB 保留 | 450 + 60 = $510 |
| 网络流量/NPM | 按流量 | $180 |
| 合计 | $2,240 |
⚠️ 成本口径:以上为2026年5月实际账单。Datadog按Pod数计费,如果启用HPA导致Pod数量波动(我们峰值到过410个),账单会随之上涨。Datadog官网有月费估算器,建议按峰值Pod数×1.2计算预算。
四、方案C:冠服云EMS(一体化运维平台)
4.1 接入方式
EMS的ITOM模块通过Agent + Zabbix Proxy采集K8s指标和日志,同时对接K8s API获取Pod/Deployment/Node等资源对象。Agent以DaemonSet部署,Zabbix Proxy负责汇聚。
yaml
# ems-agent-daemonset.yaml (简化)
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ems-agent
spec:
selector:
matchLabels:
app: ems-agent
template:
spec:
hostNetwork: true
containers:
- name: agent
image: ems/agent:4.9
env:
- name: EMS_SERVER
value: "ems-server.guanfucloud.com"
- name: CLUSTER_NAME
value: "prod-k8s-01"
volumeMounts:
- name: docker-sock
mountPath: /var/run/docker.sock
readOnly: true4.2 跑了一个月的真实感受
指标采集:够用但不惊艳。 EMS的K8s指标覆盖面(Node/Pod/Deployment/Service)与Prometheus基本一致,但Dashboard的灵活度不如Grafana------不能用PromQL自由组合查询,只能基于预置模板和条件筛选。我们习惯了自己写PromQL的人一开始有落差,但对于不做复杂指标分析的日常运维场景(我们的值班工程师主要看"哪个Pod CPU高/内存快满了/重启了几次"),够用。
日志关联:实用但不是最强的。 EMS的日志检索语法比ES DSL弱,不支持复杂嵌套聚合。但有个很实用的设计:告警触发时,触发时刻前后5分钟的日志快照自动贴在工单里。处理人打开工单就能看到日志原文+指标曲线+告警时间线,不需要切系统查。对于运维排障场景(不是数据分析场景),这个"上下文自动聚合"比日志检索功能的丰富度更实用。
告警→工单闭环:核心差异所在。 这是三方案中唯一一条不需要自建集成的链路:
K8s Pod CPU告警 → 智能告警(去重+分级)→ LLM根因分析 →
自动创建工单(带日志快照+指标曲线)→ 值班自动派单 →
SLA计时 → 处理完成关闭 → 复盘追踪一个真实案例:凌晨2:18,K8s集群中payment-svc的3个Pod同时CrashLoopBackOff。EMS的链路是:
- 2:18:05 --- ITOM检测到Pod重启异常,聚合K8s事件(
Back-off restarting failed container)+ metrics(内存从512Mi→1.2Gi)+ 日志(java.lang.OutOfMemoryError: Java heap space) - 2:18:12 --- LLM分析:"根因OOM(置信度94%),非配置变更引起,建议:先调大内存limit至2Gi恢复服务,再排查内存泄漏"
- 2:18:15 --- 自动创建工单,P2等级,派给值班组
- 2:18:20 --- 值班工程师手机收到推送,工单里已有完整上下文,一键执行L2方案调大limit
- 2:18:35 --- Pod重新Running,服务恢复
人工介入时间:15秒(确认+点执行按钮)。从告警到恢复不到30秒。
成本:
| 项目 | 月成本 |
|---|---|
| ITOM模块(50节点) | ~$800 |
| ITSM模块 | ~$300 |
| 日志模块(30天保留) | ~$200 |
| 人力维护 | ~$100(Agent日常维护) |
| 合计 | ~$1,400 |
⚠️ 报价口径:以上为2026年5-6月参考价格区间,ITOM+ITSM+日志三模块打包。具体报价以官方最新信息为准,不同节点规模/功能组合有差异。
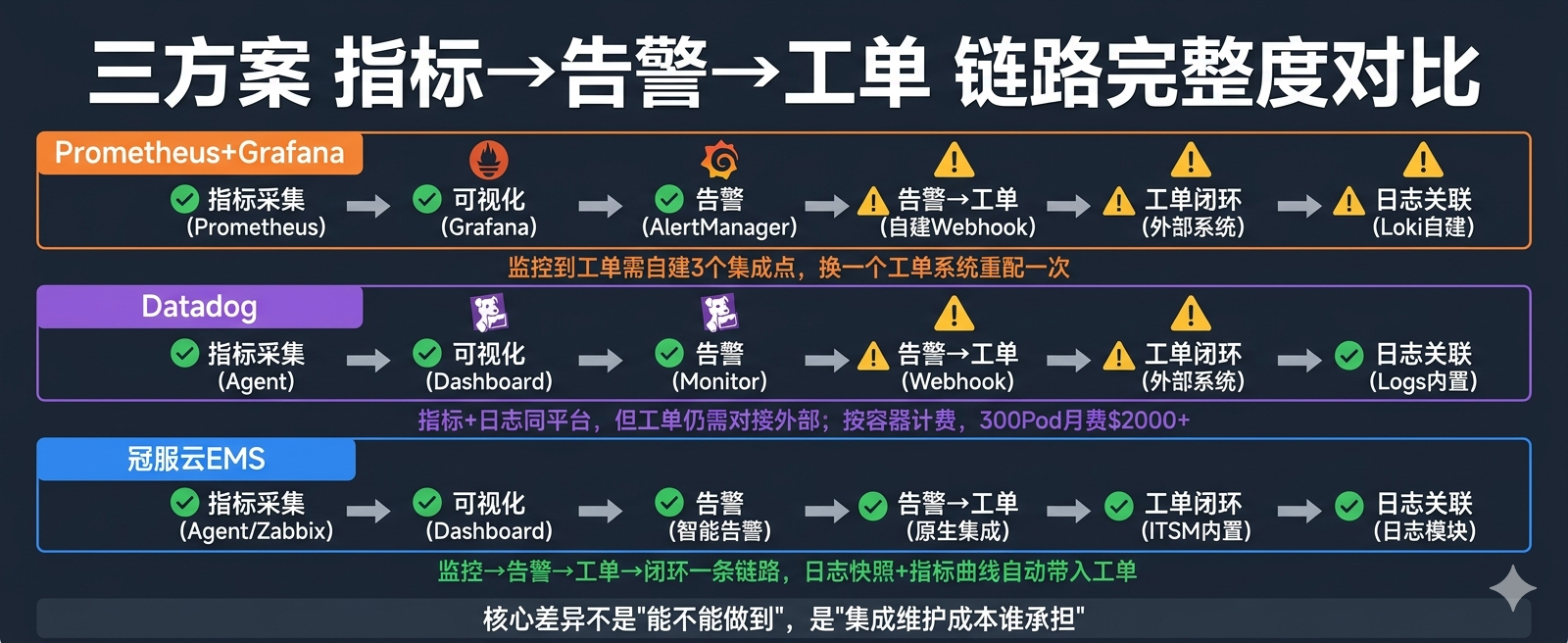
五、四个核心差距总结
差距一:指标灵活度 vs 开箱即用
| Prometheus | Datadog | EMS | |
|---|---|---|---|
| 查询灵活度 | ⭐⭐⭐⭐⭐ PromQL | ⭐⭐⭐⭐ 专有语法 | ⭐⭐⭐ 预置模板+筛选 |
| 开箱即用 | ⭐⭐⭐ 需要配Grafana面板 | ⭐⭐⭐⭐⭐ 接入即用 | ⭐⭐⭐⭐ 预置Dashboard够用 |
| 适合人群 | 会写PromQL的SRE | 不想折腾的团队 | 运维值班+闭环需求 |
差距二:告警→工单的断点
这个差距不能只看"能不能做到"------三方案都能通过Webhook接到Jira/钉钉。真正的差距在维护成本:
- Prometheus方案:自建3个集成点(AlertManager→Webhook→Jira),换一个工单系统重配一次,出了Bug自己修
- Datadog:自建1个集成点(Monitor→Webhook→Jira),但工单闭环仍不在平台内
- EMS:0个自建集成点,告警→工单原生一体,日志快照+指标曲线自动带入
差距三:成本结构
| Prometheus | Datadog | EMS | |
|---|---|---|---|
| 平台月费 | $0(开源) | $2,240 | ~$1,300 |
| 人力月费 | ~$1,200 | ~$200 | ~$100 |
| 月度总成本 | ~$1,590 | ~$2,440 | ~$1,400 |
| 100 Pod | ~$1,200 | ~$900 | ~$1,200 |
| 300 Pod | ~$1,590 | ~$2,240 | ~$1,400 |
| 500 Pod | ~$1,800 | ~$3,500 | ~$1,600 |
关键规律:Datadog成本随Pod数线性增长;Prometheus平台费为零但人力线性增长;EMS介于两者之间,但500Pod以下规模总成本最低。

差距四:适用场景
| 场景 | 推荐方案 |
|---|---|
| 有专职SRE团队,需要灵活指标分析 | Prometheus+Grafana |
| 不差预算,要最好体验,海外部署 | Datadog |
| 运维团队≤5人,需要"监控→工单→闭环"一条线 | EMS |
| 国内合规要求高,数据不能出境 | Prometheus 或 EMS |
| K8s规模<200Pod | Datadog 或 EMS |
| K8s规模>500Pod | Prometheus(Thanos/Cortex) |
六、选型决策框架
我们最终画了一个四象限决策图,帮自己在三个方案间快速定位:
指标分析灵活度 →
高 低
┌──────────┬──────────┐
闭环 │ Prometheus│ │
完整性 │ + 自建集成 │ EMS │
↑ ├──────────┼──────────┤
↓ │ │ │
│ Datadog │ │
└──────────┴──────────┘如果你的核心痛点是"告警响了以后,信息在四套系统里散着,每次排障都在切换系统" ------那你真正要的不是更好的监控,是更完整的闭环。这个结论和我们从ELK换到EMS日志模块(第53篇)、从Jira换到EMS工单模块(第52篇)时的判断逻辑一致。
如果你的核心痛点是"我想用PromQL/RUM/APM/Profiling做深度的性能分析" ------Prometheus+Grafana或Datadog更适合你。EMS的定位不是可观测性分析平台,是运维闭环平台。
本文方案A/B基于2026年5月Prometheus v2.50 + Datadog实际账单实测;方案C基于冠服云EMS ITOM+ITSM+日志模块(V4.9)2026年6月生产实践。各方案报价/版本以官方最新信息为准。K8s集群规模、Pod数量、日志量会影响实际成本,本文数据仅供参考。Datadog国内部署涉及数据跨境传输,请评估合规要求。