
核心结论
批处理不是简单把多个请求拼成一个 batch,而是在吞吐、首 token 延迟、每 token 延迟、显存、KV cache、调度公平性和业务 SLA 之间做取舍。传统模型里,批处理主要解决"GPU 一次处理多个样本";LLM 服务里,批处理还要解决"prefill 和 decode 两种阶段如何混排、KV cache 如何分配和复用、不同长度请求如何避免互相拖累、p99 如何不被长请求打爆"。
更准确的一句话是:
text
批处理收益 = 请求分布 × token budget × KV 管理 × 调度策略 × SLA 约束
第 0 层:30 秒理解
把 LLM 服务想成一个高峰期车站:
| 策略 | 类比 | 适合场景 | 风险 |
|---|---|---|---|
| 无批处理 | 一辆车只载一个人 | 调试、极低并发 | GPU 空转,成本高 |
| 静态批处理 | 固定班车,等满发车 | 离线批量推理 | 低负载等待,长短混合浪费 |
| 动态批处理 | 根据人流临时发车 | 普通在线推理 | 参数复杂,p99 要控制 |
| 连续批处理 | 车不停靠太久,乘客动态上下 | LLM 高并发 decode | KV 管理和公平性复杂 |
| Cache-aware batching | 同路线乘客优先同车 | RAG、共享系统 prompt、多轮对话 | cache key 正确性和失效策略 |
最重要的三个指标:
text
吞吐:单位时间完成多少 token 或请求
延迟:TTFT、TPOT、E2E、p95/p99
goodput:在 SLO 内完成的有效吞吐如果一个策略让 tokens/s 提高,但 p99 超过 SLA,那么它对在线业务不一定是好策略。
第 1 层:基础概念
1.1 批处理到底在优化什么
GPU 擅长并行计算。单请求推理常常无法让 GPU 吃满,批处理把多个请求放在同一步执行,让矩阵乘法更大、kernel 更少、吞吐更高。
但 LLM 不是普通分类模型。每个请求有:
| 变量 | 对批处理的影响 |
|---|---|
| prompt 长度 | 决定 prefill 计算和首 token 延迟 |
| output 长度 | 决定 decode 占用时长 |
| KV cache 大小 | 决定并发上限和显存碎片 |
| sampling 参数 | 影响推测解码接受率和计算路径 |
| priority/SLO | 决定是否能等待、是否能被长请求阻塞 |
| prefix 重复度 | 决定 prefix cache 是否有收益 |
因此现代 LLM serving 通常不是"batch size=32"这么简单,而是同时设置:
text
max_num_seqs
max_num_batched_tokens
max_queue_delay_ms
max_model_len
KV block size
prefill/decode scheduling policy
priority / deadline / admission control1.2 静态批、动态批、连续批
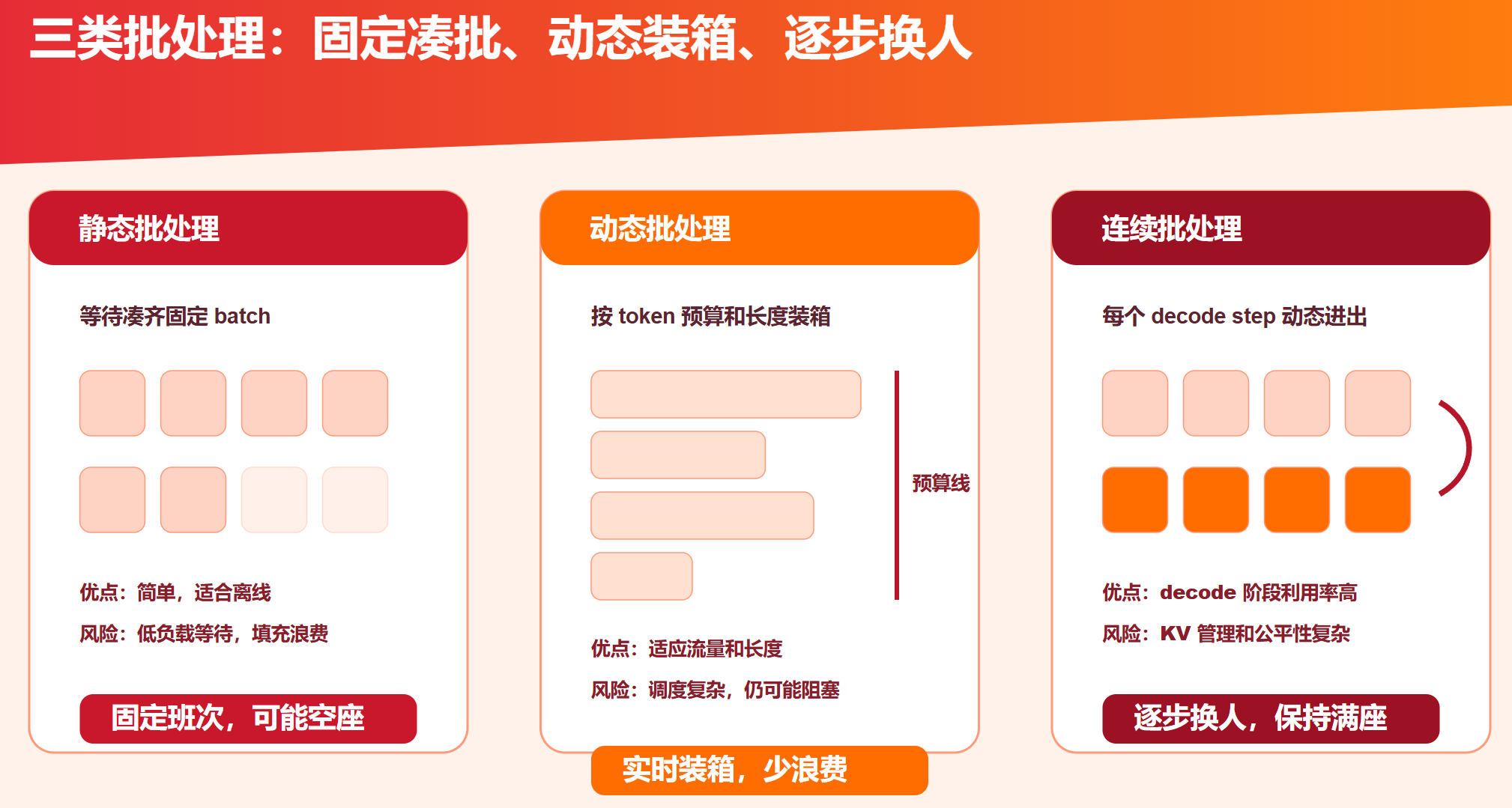
| 类型 | 怎么工作 | 优点 | 缺点 | 适合场景 |
|---|---|---|---|---|
| 静态批处理 | 固定 batch size,等够再跑 | 简单、离线吞吐高 | 等待凑批、padding 浪费 | 离线 embedding、分类、批量生成 |
| 动态批处理 | 在等待窗口内按资源和请求特征组 batch | 平衡吞吐和延迟 | 参数多,需要观测 | 在线 API、Triton/Ray Serve 类服务 |
| 连续批处理 | 每个 decode step 动态加入/移除序列 | 高并发 LLM decode 利用率高 | KV 管理复杂,公平性难 | vLLM/TGI/SGLang/TensorRT-LLM |
| Cache-aware batching | 按 prefix/KV block 复用组织请求 | 降低重复 prefill | 缓存一致性和路由复杂 | RAG、多轮对话、代码助手 |
1.3 Padding 不是唯一方案
传统 batching 常把不同长度输入 padding 到同一长度,再用 attention mask 忽略 padding。这样简单,但长短混合时浪费严重。
LLM serving 中常见替代方案包括:
| 方法 | 说明 |
|---|---|
| 长度分桶 | 相近长度请求一起跑,减少 padding |
| packed prefill | 把多个 prompt 拼成 packed token 序列,由位置和 mask 区分 |
| paged KV | decode 阶段通过 block table 管理每个序列的 KV cache |
| chunked prefill | 长 prompt 切块,避免阻塞 decode |
| prefix cache | 相同前缀复用已经算好的 KV |
第 2 层:Token Budget 比 Batch Size 更重要

2.1 为什么不能只看请求数
两个 batch 都有 8 个请求,但成本可能差几十倍:
text
Batch A: 8 个请求,每个 prompt 128 tokens
Batch B: 8 个请求,每个 prompt 8192 tokens对 LLM 来说,batch size 只是序列数,batched tokens 才更接近 prefill 的计算和显存压力。decode 阶段还要看 KV cache 长度,因为每个新 token 需要读取历史 KV。
2.2 常用预算约束
| 参数 | 含义 | 影响 |
|---|---|---|
max_num_seqs |
同时活跃的序列数 | 并发和调度开销 |
max_num_batched_tokens |
一次调度最多处理多少 token | prefill 吞吐、显存和 p99 |
max_model_len |
最大上下文长度 | KV cache 上限 |
| queue delay | 最多等多久凑批 | TTFT 和吞吐 |
| KV block budget | 可用 KV blocks | 并发和 OOM 风险 |
| prefill chunk size | 长 prompt 分块大小 | TTFT/TPOT 平衡 |
2.3 简单的动态批装箱骨架
下面的代码只表达调度思想,不代表完整 LLM serving 实现。
python
def build_token_budget_batch(queue, max_num_seqs, max_num_batched_tokens):
batch = []
used_tokens = 0
for req in sorted(queue, key=lambda r: r.deadline_ms):
tokens = req.prefill_tokens if not req.prefilled else 1
if len(batch) >= max_num_seqs:
break
if used_tokens + tokens > max_num_batched_tokens:
continue
batch.append(req)
used_tokens += tokens
return batch真实系统还要考虑 KV block 是否足够、prefix cache 是否命中、priority、公平性、请求取消、streaming、LoRA adapter、工具调用和多租户隔离。
第 3 层:Prefill 与 Decode 要分开看
3.1 Prefill 阶段
prefill 处理 prompt,通常一次处理很多 token,GEMM 大,attention 序列长。它更偏计算密集,FlashAttention/SDPA、packed prefill、prefix cache 和 chunked prefill 很重要。
prefill 的主要目标是降低 TTFT,但如果一次塞入太长的 prefill,会阻塞已经在流式输出的 decode 请求,导致 TPOT 抖动。
3.2 Decode 阶段
decode 每步为每个活跃请求生成一个或少量 token。它更容易受 KV cache 读带宽、小矩阵效率和调度开销限制。
连续批处理的核心就是 iteration-level scheduling:
text
每个 decode step:
移除已完成请求
加入新 decode 请求
在 token/KV budget 内选择 prefill chunk
运行一次模型 step
更新 KV cache 和输出流3.3 Chunked Prefill
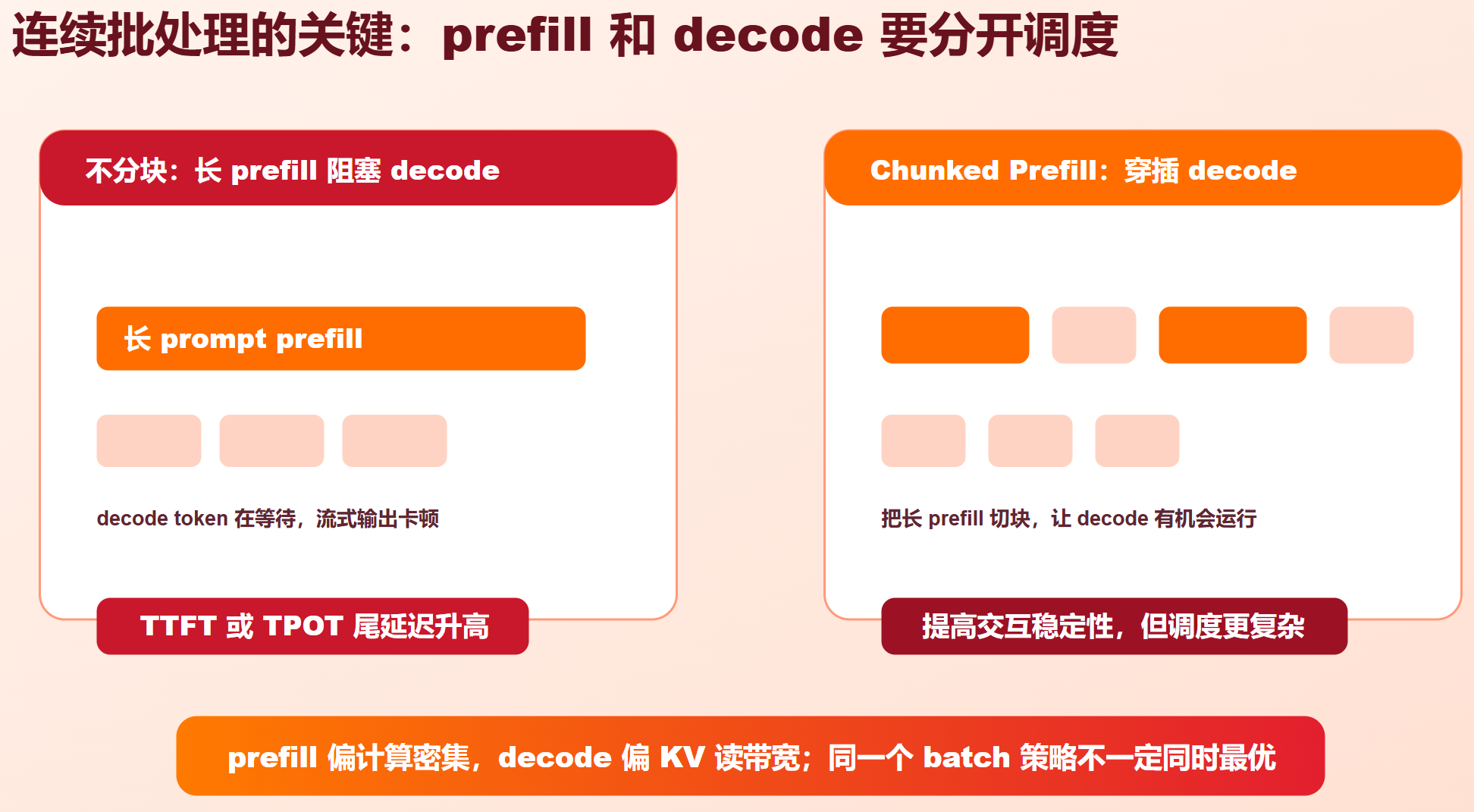
长 prompt 会造成大块 prefill 任务。如果直接一次性执行,decode 请求会等待很久。chunked prefill 把长 prompt 切成多块,让 decode 任务穿插执行。
| 策略 | 收益 | 风险 |
|---|---|---|
| 不切 prefill | prefill 效率高,实现简单 | decode 卡顿,TPOT 尾延迟升高 |
| chunked prefill | decode 更平滑,p99 更可控 | prefill 总耗时可能略升,调度复杂 |
| prefill/decode 分离 | 两类资源池分别优化 | 系统复杂,跨池 KV 传输和路由难 |
Sarathi、DeepSpeed-FastGen 的 SplitFuse、DistServe 等工作都围绕这个核心矛盾:如何兼顾 prefill 的吞吐和 decode 的稳定。
第 4 层:KV Block 与 Cache-Aware Scheduling

4.1 PagedAttention 的意义
在 LLM 服务里,KV cache 是每个请求持续占用的主要显存之一。PagedAttention 把 KV cache 切成 blocks,通过 block table 管理逻辑序列到物理 blocks 的映射。
它解决的是:
| 问题 | Paged KV 的作用 |
|---|---|
| 输出长度不可预知 | 按需增加 block,不必预留最大长度 |
| 请求完成时间不同 | 完成后释放 blocks |
| beam/parallel sampling | 前缀 blocks 可共享,分叉时 copy-on-write |
| 显存碎片 | 逻辑连续不要求物理连续 |
PagedAttention 不是单纯 attention 算法,而是 KV cache 内存管理和 serving scheduler 的基础设施。
4.2 Prefix Cache
很多请求共享相同前缀:
text
system prompt + tool schema + RAG 模板 + 公司规则 + 用户问题prefix cache 可以复用公共前缀的 KV,减少重复 prefill,降低 TTFT。vLLM 的 automatic prefix caching、TensorRT-LLM 的 KV cache reuse、SGLang 的 RadixAttention 都是围绕"前缀可复用"展开。
但 prefix cache 必须严格校验:
| 检查项 | 为什么 |
|---|---|
| tokenizer 和 chat template | 一个空格或特殊 token 不同都会导致 cache 不等价 |
| tool schema 版本 | 工具定义变化必须失效 |
| LoRA/adapter id | 不同 adapter 的 KV 不能混用 |
| sampling 参数 | 通常不影响 prefill KV,但会影响后续 decode |
| tenant/security 边界 | 多租户共享缓存要小心数据隔离 |
4.3 Cache-Aware Batching
当多个请求有相同或相近前缀时,把它们调度到同一 worker 或同一时间窗口,可以提高 cache hit rate。SGLang 的 RadixAttention 用前缀树组织 KV cache,配合 cache-aware scheduling,减少重复计算。
这说明现代 batching 不只是"长度相近放一起",还要问:
text
谁和谁共享 prefix?
谁的 KV blocks 已在本 worker?
谁有更紧的 SLO deadline?
谁等待太久可能饥饿?第 5 层:传统动态批:Triton、Ray Serve 与普通模型
5.1 Triton Dynamic Batching
NVIDIA Triton Inference Server 的 dynamic batching 面向通用模型服务:在一个很短的 queue delay 内收集多个请求,按 preferred_batch_size、max_queue_delay_microseconds 等配置组 batch。
适合:
| 场景 | 说明 |
|---|---|
| CNN/embedding/reranker | 输入形状相近,batch 后吞吐提升明显 |
| 离线或准实时推理 | 可以接受几毫秒等待 |
| 多实例模型服务 | 可与 instance group 并行 |
不适合直接等同于 LLM 连续批处理。Triton 也有 sequence batching、iterative sequence 等机制,但 LLM serving 通常还需要专门的 KV cache 管理和 decode 调度。
5.2 Ray Serve Dynamic Request Batching
Ray Serve 支持 @serve.batch,可以设置 max_batch_size、batch_wait_timeout_s,也支持动态调整部分 batching 参数。它适合把普通 Python 推理函数批量化,尤其是 embedding、rerank、分类、图像等服务。
LLM serving 可以使用 Ray 做外围路由、autoscaling、多模型服务,但底层高性能 LLM decode 往往仍依赖 vLLM、TensorRT-LLM、TGI 或 SGLang 这类专用引擎。
5.3 普通模型和 LLM 的区别
| 项目 | 普通模型动态批 | LLM 连续批 |
|---|---|---|
| 请求生命周期 | 一次 forward 后完成 | 多个 decode step 后完成 |
| 状态 | 通常无状态 | 每个请求有 KV cache 状态 |
| batch 单位 | 样本数或输入 token | prefill tokens、decode seqs、KV blocks |
| 队列策略 | queue delay 凑 batch | iteration-level scheduling |
| 主要风险 | padding、等待 | KV OOM、long request blocking、p99 抖动 |
第 6 层:现代 LLM Serving 栈
6.1 vLLM
vLLM 的核心贡献包括 PagedAttention、continuous batching、automatic prefix caching、chunked prefill、speculative decoding、多种量化和 OpenAI-compatible serving。它适合大多数需要快速落地的高并发 LLM 服务。
关键调参方向:
| 参数方向 | 关注点 |
|---|---|
| 最大活跃序列数 | 并发与调度开销 |
| 最大批内 token | prefill 吞吐与 p99 |
| KV block size | 显存碎片和 block 管理开销 |
| prefix cache | TTFT 和缓存命中 |
| chunked prefill | decode 平滑度 |
6.2 TensorRT-LLM
TensorRT-LLM 深度绑定 NVIDIA GPU,支持 in-flight batching、paged KV cache、KV cache reuse、FP8/INT8/INT4、tensor/pipeline parallel 等。它适合对 NVIDIA 平台有极致性能需求的生产部署,但 engine 构建、版本管理和模型适配成本更高。
6.3 SGLang
SGLang 关注结构化语言模型程序的高效执行,RadixAttention 把 KV cache 组织成 radix tree 来复用公共前缀,并结合调度减少重复 prefill。它对 agent、工具调用、多轮程序化 prompt、RAG pipeline 很有吸引力。
6.4 TGI、LMCache 与其他组件
Text Generation Inference、LMCache、Triton、Ray Serve、KServe 等可以出现在不同层:
| 层级 | 代表 | 作用 |
|---|---|---|
| LLM kernel/engine | vLLM、TensorRT-LLM、SGLang、TGI | decode、KV、batching |
| 通用 serving | Triton、Ray Serve、KServe | API、动态批、autoscale |
| KV/prefix cache | LMCache、engine 内置 cache | 跨请求或跨节点复用 |
| 路由和网关 | 自研 gateway、K8s、service mesh | 多租户、限流、SLO |
第 7 层:多租户、优先级与 Admission Control
批处理会让请求互相影响。生产环境通常要处理:
| 问题 | 解决方向 |
|---|---|
| 长请求拖慢短请求 | shortest-job-first、chunked prefill、max tokens 限制 |
| 高优先级请求被排队 | priority queue、deadline scheduling |
| 某租户占满 KV cache | per-tenant quota、admission control |
| 请求无限等待 | aging、timeout、preemption |
| 负载突增 | shed load、降级模型、限制 max_new_tokens |
7.1 Goodput 比 Throughput 更接近业务价值
Throughput 只统计产出多少 token,Goodput 统计在 SLO 内完成的有效 token 或请求:
text
goodput = SLO 内完成的 tokens / 时间如果系统靠超大 batch 提高 tokens/s,但大多数请求超过 p99 SLA,那么 goodput 可能下降。
7.2 Admission Control
admission control 是上线系统的必要保护:当 KV cache、队列长度、p99 或 GPU memory 达到阈值时,新请求应该排队、降级、转移或拒绝,而不是让所有请求一起变慢。
一个简单策略:
python
def should_admit(queue_len, kv_blocks_free, request_tokens, limits):
if queue_len >= limits["max_queue_len"]:
return False
if kv_blocks_free < request_tokens // limits["tokens_per_block"] + limits["reserve_blocks"]:
return False
return True真实系统还要按租户、优先级、模型、adapter 和区域做隔离。
第 8 层:策略选择
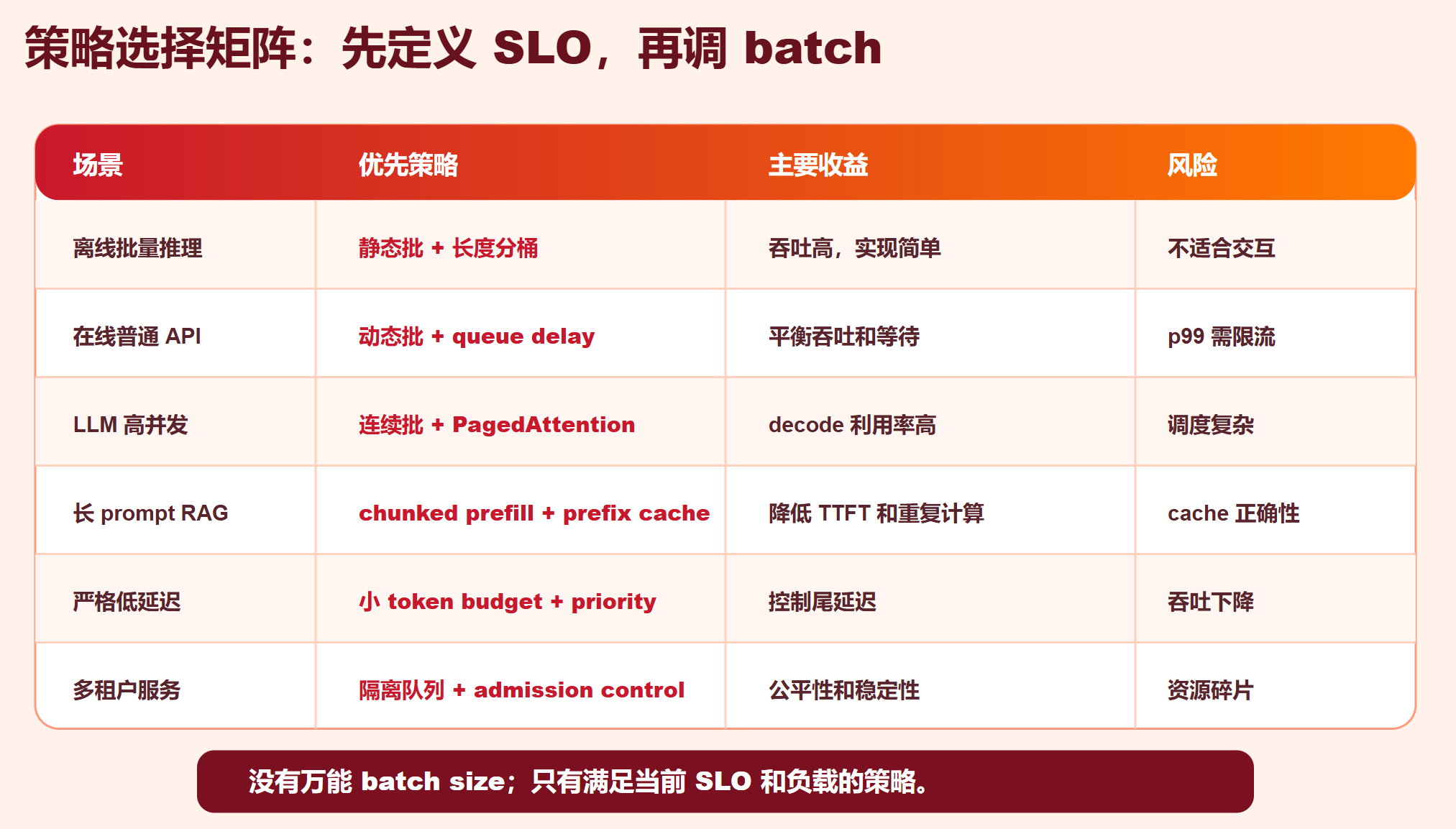
| 场景 | 推荐策略 | 说明 |
|---|---|---|
| 离线 embedding/分类 | 静态批 + 长度分桶 | 吞吐优先,延迟不敏感 |
| 在线普通模型 API | 动态批 + 短 queue delay | 典型 Triton/Ray Serve 模式 |
| LLM 高并发聊天 | 连续批 + PagedAttention | decode 阶段保持 GPU 忙碌 |
| 长 prompt RAG | prefix cache + chunked prefill | 降低 TTFT,避免 decode 卡顿 |
| 多租户企业服务 | per-tenant queue + priority + quota | 控制公平性和资源隔离 |
| 严格低延迟 | 小 token budget + deadline scheduling | 牺牲部分吞吐换 p99 |
| 超长上下文 | paged KV + KV 量化/offload + admission control | 防 OOM 和显存碎片 |
| 多 GPU 服务 | prefill/decode 分离或并行引擎 | 需要路由和 KV 传输设计 |
第 9 层:评估与代码骨架

9.1 核心指标
| 指标 | 含义 | 为什么重要 |
|---|---|---|
| TTFT | 首 token 延迟 | 用户是否等得住 |
| TPOT/ITL | 输出 token 间隔 | 流式是否顺滑 |
| E2E latency | 端到端完成时间 | 总体验 |
| p95/p99 | 尾延迟 | SLA 和稳定性 |
| tokens/s | 总吞吐 | 成本 |
| goodput | SLO 内有效吞吐 | 真实业务产能 |
| queue time | 排队等待 | 批处理副作用 |
| KV block usage | KV 占用和碎片 | 并发上限 |
| prefix hit rate | 前缀缓存命中率 | RAG/多轮收益 |
| OOM / timeout / cancel rate | 失败率 | 可用性 |
9.2 批策略报告骨架
python
def summarize_batching_run(events):
completed = [e for e in events if e["status"] == "ok"]
slo_ok = [e for e in completed if e["e2e_ms"] <= e["slo_ms"]]
total_output_tokens = sum(e["output_tokens"] for e in completed)
slo_output_tokens = sum(e["output_tokens"] for e in slo_ok)
duration_s = max(e["end_s"] for e in events) - min(e["start_s"] for e in events)
return {
"requests_completed": len(completed),
"tokens_per_s": total_output_tokens / max(duration_s, 1e-9),
"goodput_tokens_per_s": slo_output_tokens / max(duration_s, 1e-9),
"p99_ttft_ms": percentile([e["ttft_ms"] for e in completed], 99),
"p99_tpot_ms": percentile([e["tpot_ms"] for e in completed], 99),
"p99_queue_ms": percentile([e["queue_ms"] for e in completed], 99),
}9.3 上线闸门
python
def pass_batching_gate(metrics, limits):
return (
metrics["goodput_tokens_per_s"] >= limits["min_goodput_tokens_per_s"]
and metrics["p99_ttft_ms"] <= limits["max_p99_ttft_ms"]
and metrics["p99_tpot_ms"] <= limits["max_p99_tpot_ms"]
and metrics["oom_rate"] == 0
and metrics["timeout_rate"] <= limits["max_timeout_rate"]
and metrics["fairness_violation_rate"] <= limits["max_fairness_violation_rate"]
)评估必须固定:
- 模型、tokenizer、chat template、采样参数。
- 硬件、驱动、CUDA、推理引擎版本。
- 到达率、burst 模式、prompt 长度分布、输出长度分布。
- batch 参数、KV block 参数、prefix cache、chunked prefill、priority policy。
- 多租户比例、取消请求比例、超时策略。
第 10 层:常见问题
10.1 GPU 利用率低
| 可能原因 | 处理 |
|---|---|
| 活跃请求少 | 增加 queue delay 或合并实例 |
| batch 按请求数限制过小 | 调大 token budget 和 max seqs |
| decode 小矩阵效率低 | 连续批处理、speculative decoding、GQA/MQA 架构 |
| tokenizer/API 成为瓶颈 | tokenizer 批量化、异步队列、减少同步 |
| prefix cache 未命中 | 检查模板一致性和路由 |
10.2 p99 延迟高
| 可能原因 | 处理 |
|---|---|
| queue delay 太大 | 降低最大等待时间 |
| 长 prefill 阻塞 decode | chunked prefill 或 prefill/decode 分离 |
| 长输出占满 KV blocks | max_new_tokens、admission control、priority |
| 低优先级请求饥饿 | aging 和公平性约束 |
| 过大 batch 追求吞吐 | 以 goodput 和 p99 重新调参 |
10.3 OOM 或显存碎片
| 可能原因 | 处理 |
|---|---|
| KV cache 过大 | 降低并发、KV 量化、GQA/MQA 模型、限制上下文 |
| 预留最大长度太浪费 | 使用 paged KV 或动态分配 |
| 长短请求混合 | 长度分桶、token budget、单独长上下文池 |
| prefix cache 过大 | LRU/TTL、按租户配额、监控命中率 |
10.4 吞吐高但用户体验差
这通常是只优化 tokens/s 的结果。改用:
text
目标函数 = goodput - p99 penalty - timeout penalty - fairness penalty - cost在线系统应优先满足 SLA,再追求吞吐最大化。
总结
批处理与动态批策略的核心不是找到一个万能 batch size,而是让系统在真实负载下稳定地产生有效吞吐。
最稳的决策顺序是:
text
先定义 SLO
-> 再分析 prompt/output 长度和到达率
-> 再设置 token budget、queue delay、KV block 策略
-> 再决定静态批、动态批、连续批或 cache-aware batching
-> 最后用 goodput、p99、OOM、fairness 做验收静态批适合离线吞吐,动态批适合普通在线服务,连续批适合 LLM decode,高级 LLM serving 还要加入 PagedAttention、prefix cache、chunked prefill、priority queue、admission control 和多租户隔离。真正成熟的批策略不是"GPU 利用率最高",而是在用户可接受的延迟内,把每一块 GPU 显存、每一次 kernel、每一个 KV block 都用在有效请求上。
参考资料
- Gyeong-In Yu et al., "Orca: A Distributed Serving System for Transformer-Based Generative Models," OSDI 2022.
- Woosuk Kwon et al., "Efficient Memory Management for Large Language Model Serving with PagedAttention," SOSP 2023.
- vLLM Documentation, Automatic Prefix Caching, Paged Attention, and scheduler-related docs.
- NVIDIA Triton Inference Server Documentation, Dynamic Batcher.
- Ray Serve Documentation, Dynamic Request Batching.
- NVIDIA, TensorRT-LLM Documentation, in-flight batching and paged KV cache.
- Ying Sheng et al., "SGLang: Efficient Execution of Structured Language Model Programs," 2023.
- Yuhan Liu et al., "DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving," 2024.
- Amey Agrawal et al., "Sarathi-Serve: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills," 2024.
- DeepSpeed Team, DeepSpeed-FastGen / Dynamic SplitFuse, 2024.
- Hugging Face, Text Generation Inference Documentation.
- LMCache Documentation, KV cache reuse for LLM serving.