1 引言
论文链接:https://arxiv.org/pdf/2306.15595.pdf
基于旋转位置编码(Rotary Position Embedding,RoPE)1 的大模型普遍存在长度外推缺陷,超出预训练上下文窗口的长文本输入会严重破坏模型生成效果,重新训练长上下文模型算力成本高昂。针对这一痛点,位置插值(Position Interpolation, PI)2 给出了轻量化解决方案:通过缩放位置索引把超长序列映射到模型见过的位置分布内,搭配少量微调就能大幅拓展模型可处理文本长度,实现简单、工程落地门槛低,成为 RoPE1 长上下文扩展的基础方法。下文详细讲解 PI2 的设计逻辑、计算方式与实际使用效果。
2 PI
假设要将预训练上下文窗口大小 拓展为
,则目标位置索引
会按以下公式压缩到训练范围内以避免朴素外推:
其中缩放结果 作为 RoPE1 的输入位置索引,可以为实数。
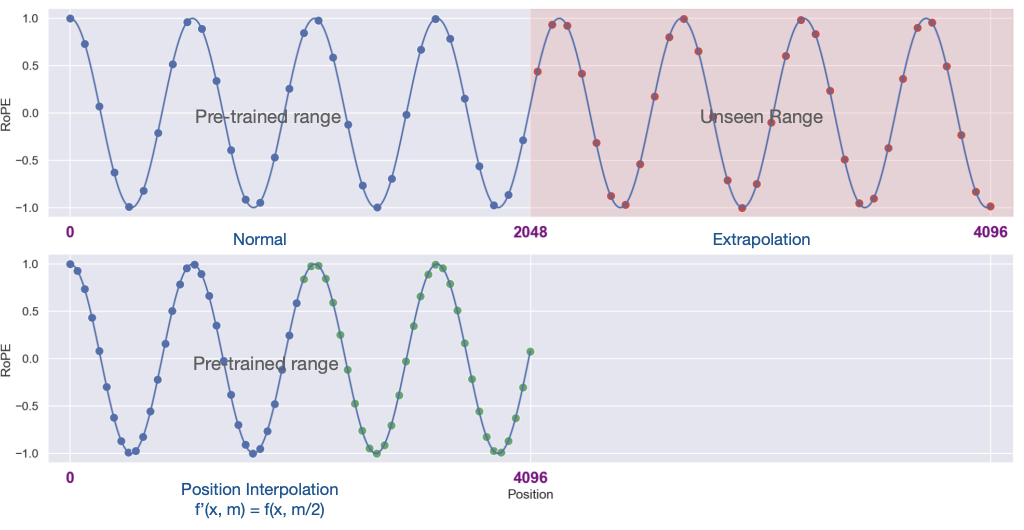
图2-1 PI 示例2
如图 2-1 所示,PI2 方法通过将位置信息从 0,4096 范围压缩至 0,2048 内,使模型能够高效处理更长文本,其效果相当于处理 2048 个 token。其中上图展示了预训练 Llama3 模型在上下文窗口大小为 2048 时使用 RoPE1 的常规情况:蓝色点代表预训练范围内的位置索引,红色点则表示超出预训练范围的 4096 范围内未见位置索引。而下图则展示了 PI2 的结果,其中位置索引被缩小了一半,即将原本 0, 4096 范围的位置索引映射到 0, 2048,以适应模型的预训练范围。
图 2-1 中 PI2 方法的关键在于将位置索引缩放一半,将 0,4096 映射到 0,2048 范围内,从而适配模型的预训练范围。这一机制通过对输入位置进行缩放,使模型无需架构改动即可处理超出原始训练范围的输入。具体而言,当原始上下文窗口为 2048 而目标窗口为 4096 时,所有位置索引均除以 2,为序列中的每个位置生成唯一且缩放后的新索引。
微调模型以适应新的上下文窗口尺寸,优化其对 PI2 的适应能力。通过这种方式,模型在长文档摘要等任务中的表现将得到提升,即使处理超出原始训练限制的上下文也能保持稳定高效。这种微调通常基于大规模文本语料库进行。
3 总结
本文完整梳理了 PI2 的核心原理、运算逻辑与落地效果。针对 RoPE1 原生直接外推长文本失效的痛点,PI2 摒弃直接使用未训练超大位置索引的思路,通过线性缩放所有位置索引,将超长序列的位置区间压缩至模型预训练范围,从理论上大幅降低注意力分数失控风险。该方案无需改动 Transformer4 主干网络、不新增模型参数,仅需极少量微调即可将 LLaMA3 等模型上下文窗口拓展至 32768。大量实验证明,经过 PI2 微调的模型在长文本建模、长文档摘要、长距离信息检索任务上效果提升显著;仅在原始短文本基准上存在轻微性能衰减。作为 RoPE1 长上下文扩展的奠基性方案,PI2 实现成本极低、工程兼容性强,也为后续优化方法提供了核心设计思路,是本地部署、轻量化扩展开源大模型上下文的主流实用方案。
参考文献
1 Su J, Ahmed M, Lu Y, et al. Roformer: Enhanced transformer with rotary position embeddingJ. Neurocomputing, 2024, 568: 127063.
2 Chen S, Wong S, Chen L, et al. Extending context window of large language models via positional interpolationJ. arXiv preprint arXiv:2306.15595, 2023.
3 Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language modelsJ. arXiv preprint arXiv:2302.13971, 2023.
4 Vaswani A, Shazeer N, Parmar N, et al. Attention is all you needJ. Advances in neural information processing systems, 2017, 30.