写在前面
你是否注意过,在使用 Claude API 时返回的 usage 里有一个 cache_read_input_tokens 字段?或者 DeepSeek API 的 prompt_cache_hit_tokens?这些数字背后,是各大模型厂商在推理成本和延迟上的一场"暗战"。
本文将带你从 3H 视角------What(是什么)、Why(为什么)、How(怎么用)------系统性地拆解 Prompt Caching 技术。
1. what
1.1 一句话定义
- Prompt Caching(提示缓存)是一种让 LLM 推理服务复用之前请求中已计算过的 KV Cache 的机制,避免对重复出现的 prompt 前缀重复计算,从而降低延迟和费用。要理解 Prompt Caching,首先要理解 LLM 推理中的 KV Cache。
1.2 本质:KV Cache的跨请求复用
Transformer 的 Self-Attention 计算可以简化为:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) VAttention(Q,K,V)=softmax(dk QKT)V
- Q(Query):当前 token 的"查询"------"我在找什么?"
- K(Key):每个 token 的"索引"------"我是什么?"
- V(Value):每个 token 的"内容"------"我携带什么信息?"
当模型逐个生成 token 时,每生成一个新 token,都需要用它和所有历史 token 做 Attention。如果不做优化,第 N 步要重新计算前 N-1 个 token 的 K 和 V------这会导致 O(n2)O(n^2)O(n2) 的重复计算。
KV Cache 的解决方案:把每一层已经算过的 K 和 V 矩阵存下来,新 token 只需计算自己的 Q、K、V,然后和缓存的 K、V 做 Attention 即可。
第 1 步: 计算 token₁ 的 K₁V₁ → 缓存
第 2 步: 计算 token₂ 的 K₂V₂ → 用 K₁V₁ + K₂V₂ 做 Attention → 缓存
第 3 步: 计算 token₃ 的 K₃V₃ → 用 K₁V₁ + K₂V₂ + K₃V₃ 做 Attention → 缓存
...KV Cache 是按 token 序列位置计算的,前缀相同的序列,其前缀部分的 KV Cache 也完全相同。
请求 1: [system] → [user: "北京有什么好吃的?"]
请求 2: [system] → [user: "北京有什么好玩的?"]
↑
前缀 "[system]" 完全相同
→ KV Cache 可以复用!这就是 Prompt Caching 的核心原理------连续前缀匹配。API 服务端在收到新请求时,检查前缀是否与之前缓存的 KV Cache 一致,一致则直接复用,跳过 Prefill 阶段的计算。
2. why
2.1 越来越长的上下文
-
Agent 框架:LangGraph、CrewAI 等框架注入大量工具定义、角色约束、格式规范,动辄 2000+ tokens
-
RAG 应用:每次请求都携带相同的知识库上下文、few-shot 示例
-
Multi-turn 对话:历史对话轮次随会话增长而膨胀
-
多 Skill/多工具场景:工具 JSON Schema 定义巨大,10 个工具轻松 10,000+ tokens
-
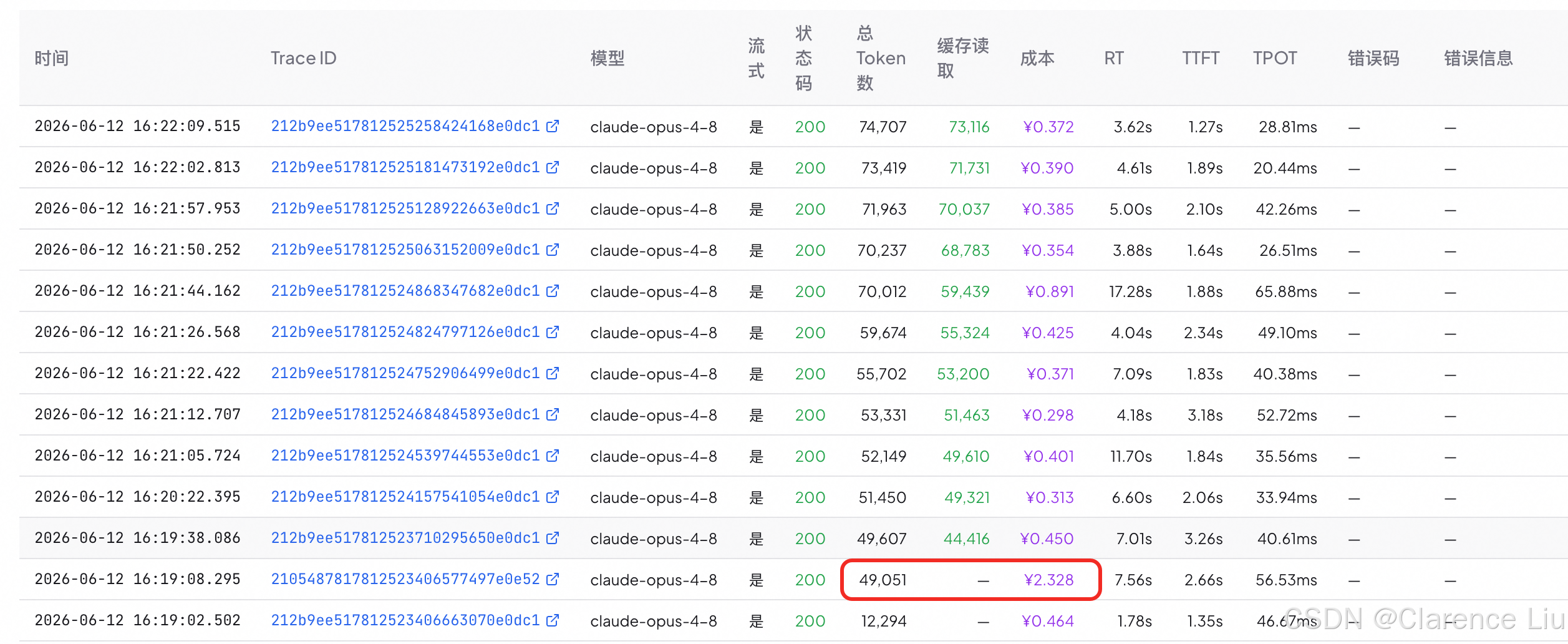
下面是一轮Agent的模型调用花费,可以看到,对于同一个模型,不使用cache和使用cache,在token数越来越多的情况下,呈线性倍数增长,以claude 4.8为例,在token达到5w的时候,不使用cache的成本已经增大到8倍
2.2 核心价值
💰 成本降低
| 厂商 | 缓存命中折扣 | 典型节省 |
|---|---|---|
| Anthropic Claude | 缓存写入 +25%,读取 -90% | 频繁复用场景节省 60-80% |
| OpenAI | 自动缓存,命中 token -50% | 长 system prompt 场景显著 |
| DeepSeek | 磁盘缓存,命中 token 按缓存价计 | 多轮对话场景大幅节省 |
| Google Gemini | 独立 Context Cache API,按缓存时间计费 | 按量付费弹性更大 |
⚡ 延迟优化
以 Anthropic Claude 为例,官方数据显示缓存命中的请求首 token 延迟(TTFT)可降低 80% 以上。因为 Prefill 阶段(首次编码 prompt)是推理中最耗时的部分,复用了 KV Cache 就跳过了这个最重的计算。
🔧 架构简化
有了 Prompt Caching,应用层不需要做复杂的 prompt 拼接优化------直接把完整的 system prompt + tools + 历史对话一股脑扔进去,缓存机制自动处理重复计算。
3. how
3.1 Anthropic Claude:显式标记的"精准控制"模式
- 核心机制:
cache_control断点标记
Anthropic 的方案最"程序员友好"------你需要显式地在 prompt 内容块上标记 cache_control,告诉 API:"这个位置之前的内容,请帮我缓存"。
- 下面是一个
claude-code的输出例子,目前claude支持打4个cache_control,claude-code的设计是,system prompt打两个,最前面这个 是稳定不变的内容,例如角色定义、核心指令、工具说明等 - 第二个cache_control包括git status、日期、用户工作目录、memory 内容,每次会话可能不同
json
{
"system": [
{
"type": "text",
"text": "[billing-header: redacted]"
},
{
"type": "text",
"text": "[system prompt block 1: identity]",
"cache_control": {
"type": "ephemeral"
}
},
{
"type": "text",
"text": "[system prompt block 2: instructions + memory + environment]",
"cache_control": {
"type": "ephemeral"
}
}
],
"tools": [
{
"name": "Agent",
"description": "[tool description redacted]",
"input_schema": { "type": "object", "properties": {} }
},
{
"name": "AnotherTool",
"description": "[tool description redacted]",
"input_schema": { "type": "object", "properties": {} }
}
],
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "[system-reminder block redacted]"
},
{
"type": "text",
"text": "[user message content redacted]"
}
]
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "[assistant response redacted]"
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"content": "[tool result content redacted]",
"tool_use_id": "toolu_xxx",
"cache_control": {
"type": "ephemeral"
}
}
]
}
],
"stream": true
}3.2 OpenAI:自动化的"无感缓存"
OpenAI 的方案是四个厂商里最"无感"的------全自动,你什么都不用做。
核心机制:
- API 自动检测请求之间的前缀重叠
- 对 >=1024 tokens 的缓存命中 token 自动打 50% 折扣
- 缓存由 OpenAI 服务端管理,对用户完全透明
定价:
- 缓存命中:所有模型统一 -50% 折扣
- 无额外写入费用
优缺点:
| 优点 | 缺点 |
|---|---|
| 零配置,开箱即用 | 无法精确控制缓存范围 |
| 自动优化,持续改进 | 失效时间不透明 |
| 无额外写入成本 | 缓存策略不支持自定义 |
适用场景: 所有 OpenAI API 用户自动受益,尤其适合不想操心缓存配置的团队。
3.3 Google Gemini:独立的"Context Cache API"
Gemini 的方案最"工程化"------缓存是一个独立的一等公民资源,有自己的 API 生命周期。
核心机制:
python
import google.generativeai as genai
# 1. 创建缓存
cache = genai.caching.CachedContent.create(
model="gemini-1.5-pro-002",
system_instruction="你是一位金融分析师...",
contents=[large_document],
ttl="3600s" # 1 小时过期
)
# 2. 使用缓存生成
model = genai.GenerativeModel.from_cached_content(cache)
response = model.generate_content("总结这份财报")关键特性:
- 独立资源管理:创建、列表、更新、删除缓存,像管理文件一样
- 可配置 TTL:从分钟到小时级
- 按缓存时长计费:按缓存存储时间付费(如 Gemini 1.5 Pro 约 $1.25/百万 token/小时),而非按请求
- 超大内容支持:适合缓存大型文档(财报、论文、书籍)
定价策略:
| 环节 | 费用 |
|---|---|
| 缓存存储 | 按 token 数量 × 存储时长计费 |
| 缓存写入 | 免费 |
| 缓存读取 | 比普通 token 便宜 ~75% |
适用场景:
- 大规模文档 Q&A(同一份文档提问多次)
- 固定上下文的高频 API 调用
- 有明确缓存生命周期的批处理任务
3.4 DeepSeek:基于磁盘的"自动通用缓存"
DeepSeek 的方案最具创新性------基于硬盘(而非 GPU 显存)的自动缓存。
核心机制:
- 默认开启,无需代码修改
- 缓存写入硬盘(不是 GPU 显存),突破显存容量限制
- 基于 Sliding Window Attention 的缓存单元管理
缓存命中规则(来自官方文档):
DeepSeek 的缓存命中遵循 "完全匹配缓存前缀单元" 原则,这比 Anthropic 的"连续前缀匹配"更严格。缓存前缀单元在以下时机持久化:
- 请求边界持久化:每轮请求会在 user 输入末尾和 assistant 输出末尾各产生一个缓存前缀单元
- 公共前缀检测:系统检测到多个请求的公共前缀后,自动持久化该公共前缀
- 固定 token 间隔切片:长文本按固定间隔切出缓存前缀单元
示例------多轮对话:
第1轮: system + "中国首都是?"
→ 缓存单元 = [system + "中国首都是?"]
第2轮: system + "中国首都是?" + "北京" + "美国首都是?"
→ 完全匹配 缓存单元 → 命中!示例------长文本 Q&A(更典型):
第1轮: system + 财报全文 + "总结关键信息"
第2轮: system + 财报全文 + "分析盈利能力"
前两轮不命中(前缀单元不同)
系统检测到公共前缀: system + 财报全文 → 持久化为缓存单元
第3轮: system + 财报全文 + "分析营收成本比"
→ 完全匹配缓存单元 → 命中!关键特性:
| 特性 | 详情 |
|---|---|
| 存储介质 | 硬盘(非 GPU 显存) |
| 开启方式 | 默认自动,零配置 |
| 命中规则 | 完全匹配缓存前缀单元 |
| 缓存清理 | 小时~天级自动清理 |
| 命中指标 | prompt_cache_hit_tokens / prompt_cache_miss_tokens |
| 保障水平 | Best-effort,不保证 100% 命中 |
设计与权衡:
- ✅ 突破显存限制,可缓存超长前缀
- ✅ 零配置,用户无感
- ❌ 磁盘读取有额外延迟(秒级写入)
- ❌ 命中规则更保守(完全匹配单元),两轮对话可能不命中
3.5 各家方案总览对比
| 维度 | Anthropic | OpenAI | Gemini | DeepSeek |
|---|---|---|---|---|
| 控制方式 | 显式标记 cache_control |
全自动 | 独立 API 管理 | 全自动 |
| 缓存粒度 | 连续前缀 | 连续前缀 | 独立内容对象 | 缓存前缀单元 |
| 存储位置 | GPU 显存 | GPU 显存 | GPU 显存 | 硬盘 |
| 命中规则 | 前缀连续匹配 | 前缀连续匹配 | 引用缓存 ID | 完全匹配单元 |
| 成本节省 | 命中 -90% | 命中 -50% | 命中 ~-75% | 命中低价 |
| 写入成本 | +25% | 无 | 无 | 无 |
| TTL | 5分钟(命中刷新) | 不透明 | 可配置 | 自动(小时~天) |
| 配置复杂度 | 中(需加标记) | 零 | 高(需管理生命周期) | 零 |
| 适合场景 | Agent 高频调用 | 通用 API | 大文档多轮 Q&A | 多轮对话、长文本分析 |