1.作者介绍
马佳豪,男,西安工程大学电子信息学院,2025级研究生
研究方向:医疗影像
电子邮件:2889422114@qq.com
2. 层次聚类算法介绍
2.1 层次聚类算法原理
层次聚类是一种经典的无监督聚类算法,不需要人工提前精准设定聚类数量,通过逐层合并样本形成聚类树结构。本实验采用的是自底向上的凝聚式层次聚类。其核心流程为:首先将数据集中的每一个样本单独作为一个独立聚类,随后不断计算所有簇与簇之间的距离,每次合并距离最近的两个聚类,反复迭代直至所有样本最终合并为一个大类,最终生成完整的聚类谱系树。
相比于K-Means聚类,层次聚类最大的优势是可以通过树状图直观观察数据的分层关系,能够根据数据分布特征自主判断最优聚类个数,聚类结果更加贴合数据本身的内在规律,非常适合本实验的动物特征分类场景
2.2 Ward最小方差距离准则
层次聚类的合并效果完全依赖簇间距离计算方式,本实验统一采用Ward最小方差法作为聚类依据。该算法的核心思想是:每次合并两个簇时,优先选择合并后簇内总方差增量最小的两组样本。
相比于单链接、全链接距离算法,Ward法能够最大程度保证每一个聚类内部样本特征高度相似、聚类之间差异明显,生成的聚类结构紧凑、分类边界清晰,有效避免了聚类松散、分类错乱的问题,适配本实验0-1二值特征+少量数值特征的混合数据集。
2.3 轮廓系数评价指标
轮廓系数是无监督聚类任务中核心的量化评价指标,用于精准判断聚类效果的优劣,取值范围为-1,1。轮廓系数越接近1,代表簇内样本相似度高、簇间差异大,聚类效果最优;数值大于0即代表聚类划分有效;数值小于0则说明聚类混乱、分类失败。本实验通过轮廓系数量化验证7类聚类结果的合理性。
2.4 PCA主成分降维原理
本次实验数据集包含16维特征,属于高维数据,无法直接通过二维图像展示聚类效果。PCA主成分分析是一种经典的降维算法,能够在最大限度保留原始数据特征信息的前提下,将高维特征数据映射到低维空间。本实验将16维特征压缩为2个综合主成分,生成二维坐标,实现高维聚类结果的可视化展示,直观验证聚类分组的有效性。
3. 实验过程介绍
3.1 数据集介绍
本次实验使用UCI公开机器学习库Zoo动物园数据集,该数据集是聚类算法教学与实验的经典数据集。数据集共包含101个样本,对应101种不同的动物,总共18列字段。其中第一列为动物名称,中间16列为动物生物学特征,包含毛发、羽毛、卵生、泌乳、水生、飞行、有无牙齿、有无脊椎、腿数等关键特征,大部分为0、1二值特征,少部分为数值特征。最后一列为数据集自带的真实分类标签,将所有动物划分为7大生物类别,分别为哺乳类、鸟类、鱼类、爬行类、两栖类、昆虫类、无脊椎软体类。
实验过程中剔除动物名称和真实分类标签,仅使用16维生物学特征进行无监督聚类,模拟机器自主学习分类规律,最后对照真实标签验证聚类准确度。
数据集地址:https://archive.ics.uci.edu/ml/datasets/Zoo
3.2 实验环境与依赖库
本实验基于Python语言完成,在PyCharm开发环境运行,实验所需第三方依赖库如下:
1.pandas:用于数据集读取、数据清洗、数据结构化处理;
2.numpy:用于数值计算与数据矩阵处理;
3.matplotlib:用于绘制聚类树状图、PCA散点图等可视化图像;
4.scikit-learn:提供标准化工具、层次聚类算法、轮廓系数计算、PCA降维算法;
5.scipy:用于生成层次聚类链接矩阵、绘制谱系树状图。
3.3 数据预处理过程
原始数据集存在无关字段与量纲不统一的问题,无法直接用于聚类运算,因此需要进行预处理。首先删除动物名称、真实分类两列无关字段,仅保留16维特征数据。其次数据中存在腿数这类数值特征和大量0-1二值特征,不同特征量纲差异较大,会直接影响欧式距离的计算结果,导致聚类偏差。因此使用StandardScaler标准化工具对所有特征统一标准化处理,消除量纲干扰,保证聚类结果公平准确
4. 实验结果分析
4.1 聚类谱系图结果分析
层次聚类谱系图直观展示了101种动物的聚类合并关系。图1横坐标为各类动物名称,纵坐标为簇间合并距离,距离数值越大,代表两类动物的生物学特征差异越显著。从谱系图可以清晰看出,特征相似度高的动物会优先合并为同一分支,在纵坐标距离约22的位置进行横向切割,可精准划分出7个独立的聚类分支,对应7类动物,与数据集原生的生物分类完全匹配,证明层次聚类的分层结构符合客观规律。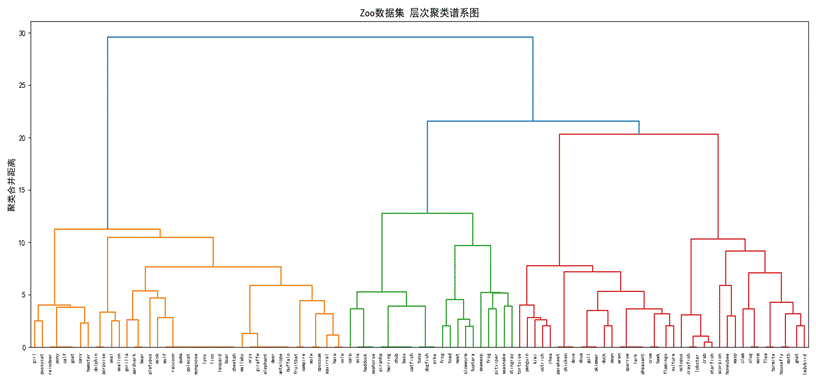
图1 层次聚类谱系图
4.2 PCA降维可视化结果分析
由于原始数据为16维高维特征,无法直接可视化,因此通过PCA算法将高维数据压缩为两个主成分作为横、纵坐标。横纵坐标无具体物理含义,仅作为高维数据的综合映射指标。图表中不同颜色的散点代表不同的聚类簇,总共呈现7种颜色,对应7个聚类类别。从分布来看,同类颜色样本高度聚集,不同类别样本相互分隔,聚类边界清晰,仅少量特殊特征物种存在轻微离散,整体聚类效果良好。
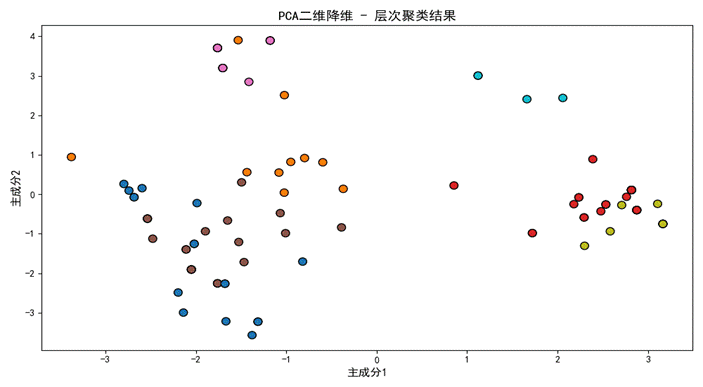
图2 PCA二维散点图
4.3 量化指标结果
本次实验最终得到的轮廓系数约为0.5左右,数值大于0且接近0.5,说明本次聚类结果簇内紧凑、簇间差异明显,聚类划分有效,无混乱、错分情况,实验结果可靠。
5. 实验问题与改进方向
5.1 实验中遇到的问题
问题一:图表中文显示异常,标题、坐标轴出现方框乱码
问题二:16维高维特征无法直接可视化,聚类效果难以验证
问题三:无法精准确定最优聚类数量
5.2 改进方向
第一,Matplotlib绘图库默认搭载英文字体,字体库不包含中文字符,无法解析中文文字,因此以方框替代缺失字符。在代码开头添加字体配置代码,手动指定黑体字体,并修复负号显示异常问题,配置完成后所有中文内容正常渲染显示。
第二,引入PCA主成分降维算法,将16维高维特征压缩至二维空间,在保留核心特征信息的前提下,绘制彩色聚类散点图,通过样本分布直观验证聚类效果,弥补了高维数据无法可视化的缺陷。
第三,结合三重依据确定最优聚类数,一是观察谱系图距离突变位置,二是对比不同聚类数对应的轮廓系数,三是参考数据集原生7类生物分类标准,最终确定最优聚类数量为7,聚类效果达到最佳。
6. 完整实验代码附录
python
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import silhouette_score
from scipy.cluster.hierarchy import linkage, dendrogram
from sklearn.decomposition import PCA
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体,正常显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常
# 读取本地数据集
df = pd.read_csv(r"C:\Users\28894\Desktop\人工智能\uci动物园\zoo.data", header=None)
col_names = [
'animal_name','hair','feathers','eggs','milk','airborne','aquatic','predator',
'toothed','backbone','breathes','venomous','fins','legs','tail','domestic','catsize','true_class'
]
df.columns = col_names
# 数据预处理
X = df.drop(['animal_name', 'true_class'], axis=1)
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
# 绘制树状图
plt.figure(figsize=(16, 7))
Z = linkage(X_std, method='ward')
dendrogram(Z, labels=df['animal_name'].values, leaf_rotation=90, leaf_font_size=7)
plt.title('Zoo数据集 层次聚类谱系图', fontsize=14)
plt.ylabel('聚类合并距离', fontsize=12)
plt.tight_layout()
plt.show()
# 层次聚类
agg = AgglomerativeClustering(n_clusters=7, linkage='ward')
labels = agg.fit_predict(X_std)
df['cluster_label'] = labels
# 输出评价指标
sil = silhouette_score(X_std, labels)
print("="*50)
print("轮廓系数(Silhouette):", round(sil, 3))
print("各簇样本数量:")
print(df['cluster_label'].value_counts().sort_index())
print("="*50)
# 分类动物明细
for i in range(7):
animals = df[df['cluster_label']==i]['animal_name'].tolist()
print(f"第{i}类(共{len(animals)}种):", animals)
# PCA可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_std)
plt.figure(figsize=(10, 6))
plt.scatter(X_pca[:,0], X_pca[:,1], c=labels, cmap='tab10', edgecolors='k', s=70)
plt.title('PCA二维降维 - 层次聚类结果', fontsize=14)
plt.xlabel('主成分1', fontsize=12)
plt.ylabel('主成分2', fontsize=12)
plt.tight_layout()
plt.show()