AI Agent就是拦截在LLM跟人类或者是LLM要执行环境之间的一个介面,但是LLM的输入长度是有限的,不能够吃无限长的输入, 所以AI Agent做的事情就是选择给LLM看的输入内容(即AI Agent筛选后的长度合适的输入,不能太长也不能太短)。
但是,仅仅做到长度合适是远远不够的。如何在多轮交互和海量工具反馈中,确保给到 LLM 的上下文既精准又不冗余?这就需要上下文工程(Context Engineering)。
Context Engineering会做哪些操作呢??
1.压缩
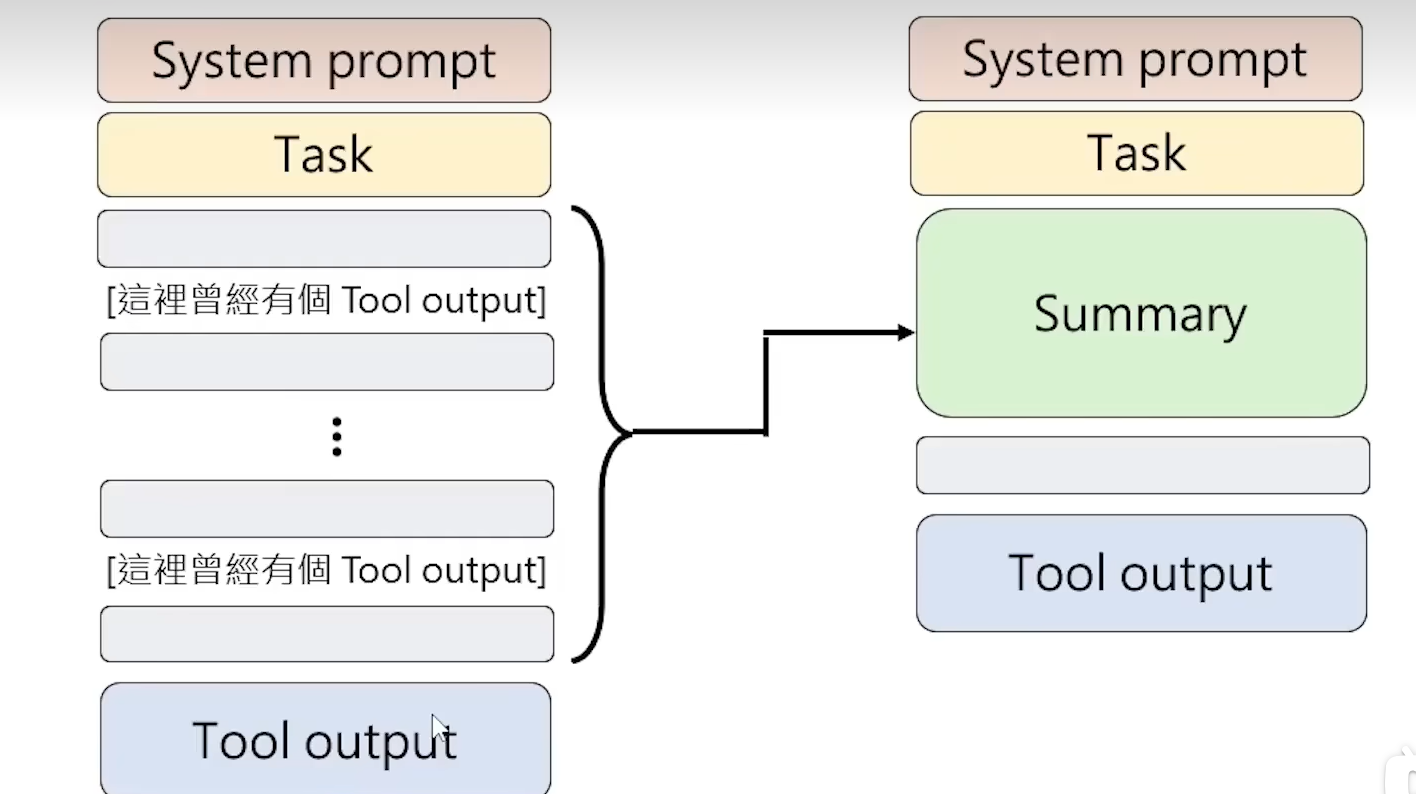
AI Agent把本来很长的历史记录缩短,在整个历史记录里面扣除system prompt部分, 将比较久远的历史记录通过某一个LLM变为Summary,然后再继续添加新的咨询。
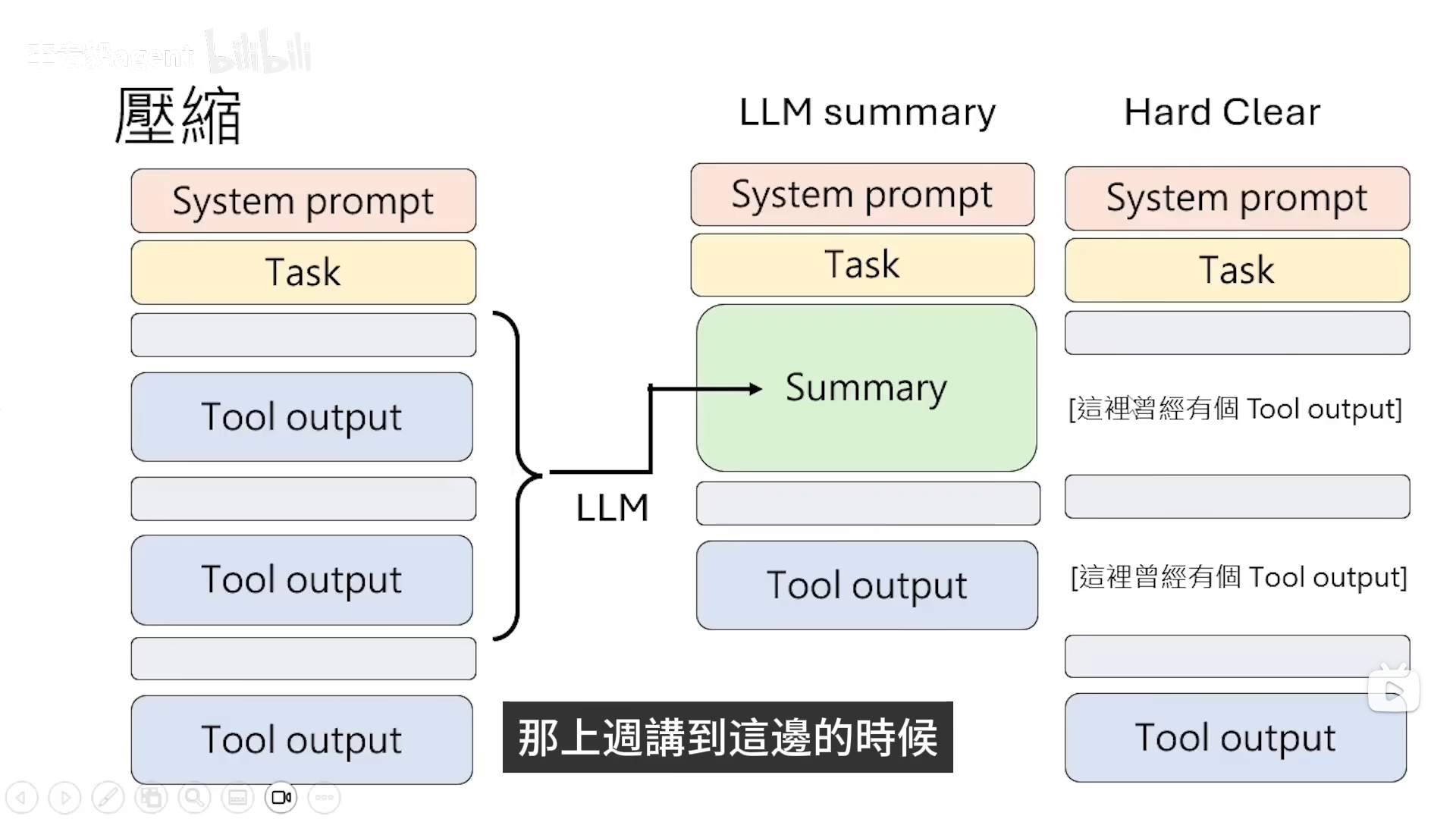
Open Claw中还有一种压缩文本长度处理方式,即当文本中存在一段长篇大论的工具使用段落时,直接展示这个曾经有个工具使用输出。
虽然压缩在某种程度上可以省钱,但是由于有一些步骤不见了,导致某些步骤是否执行过存在疑问,所以它会重复执行,导致执行的步骤反而变得多了,且Summary可能会导致压缩崩溃(压缩前本来可以做对的,但是压缩后做不对)------解决方法是在LLM中输入一个feedback(即哪些是人类关注内容的保留规则,ACON (Agent Context Optimization) ,没调参数 ACON论文)。
在论文中有提到,不同的压缩方式是可以同时进行的,做好的策略就是,在前期的时候,先用observation masking(观察遮蔽/观察屏蔽) 方法把工具的输出换掉,但是文本会越来越长,在长到一定程度的时候,再用summarization的方式。
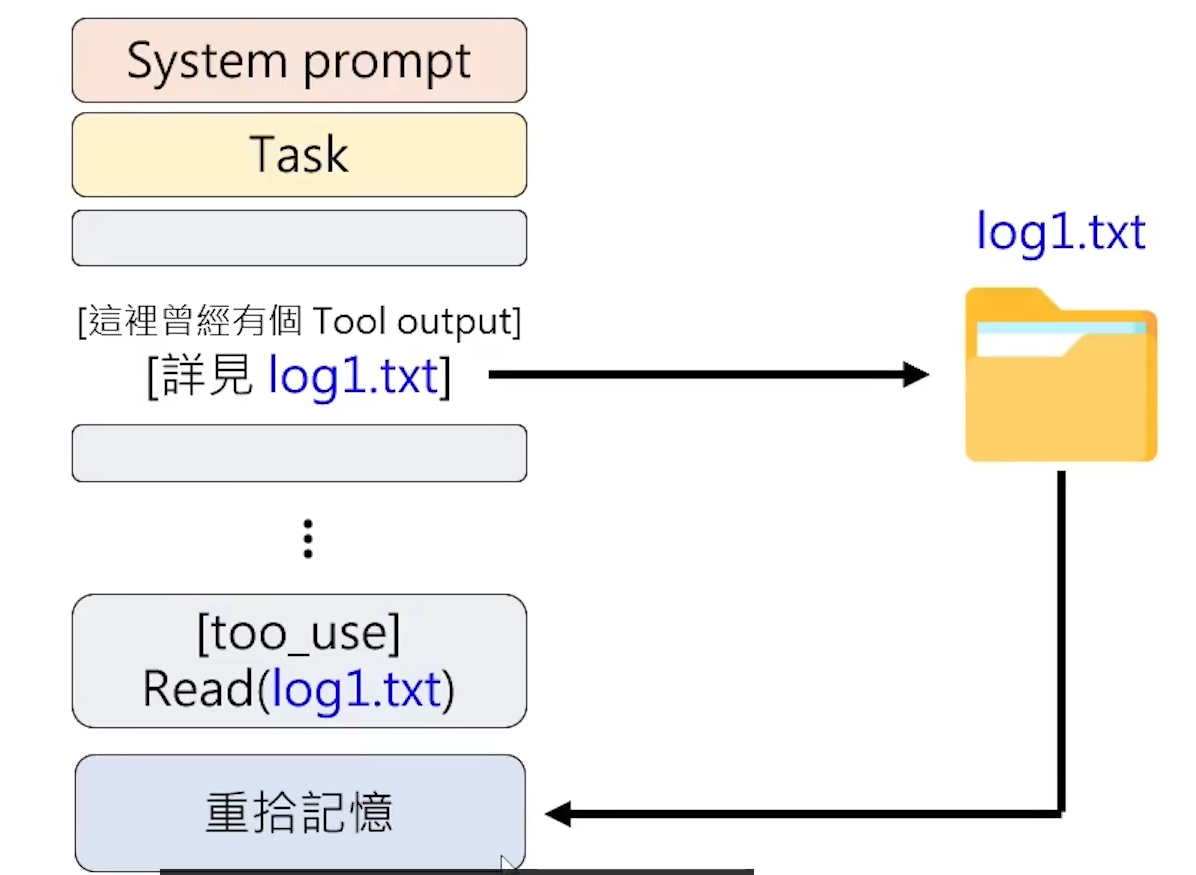
AI Agent中处理的文本内容包含两部分不同的咨询,一种是会被直接丢进LLM中的咨询,一部分是不会被丢进LLM中,存在硬盘中,即:
什么时候进行压缩?
在前人的论文中发现,LLM不喜欢做压缩(抹除记忆),所以LLM不会自主进行压缩,只有写死的规则可以(当长度超过某个上限时进行压缩),如果想要LLM自主使用压缩工具,必须通过训练才可以(需要微调模型才能做到)。
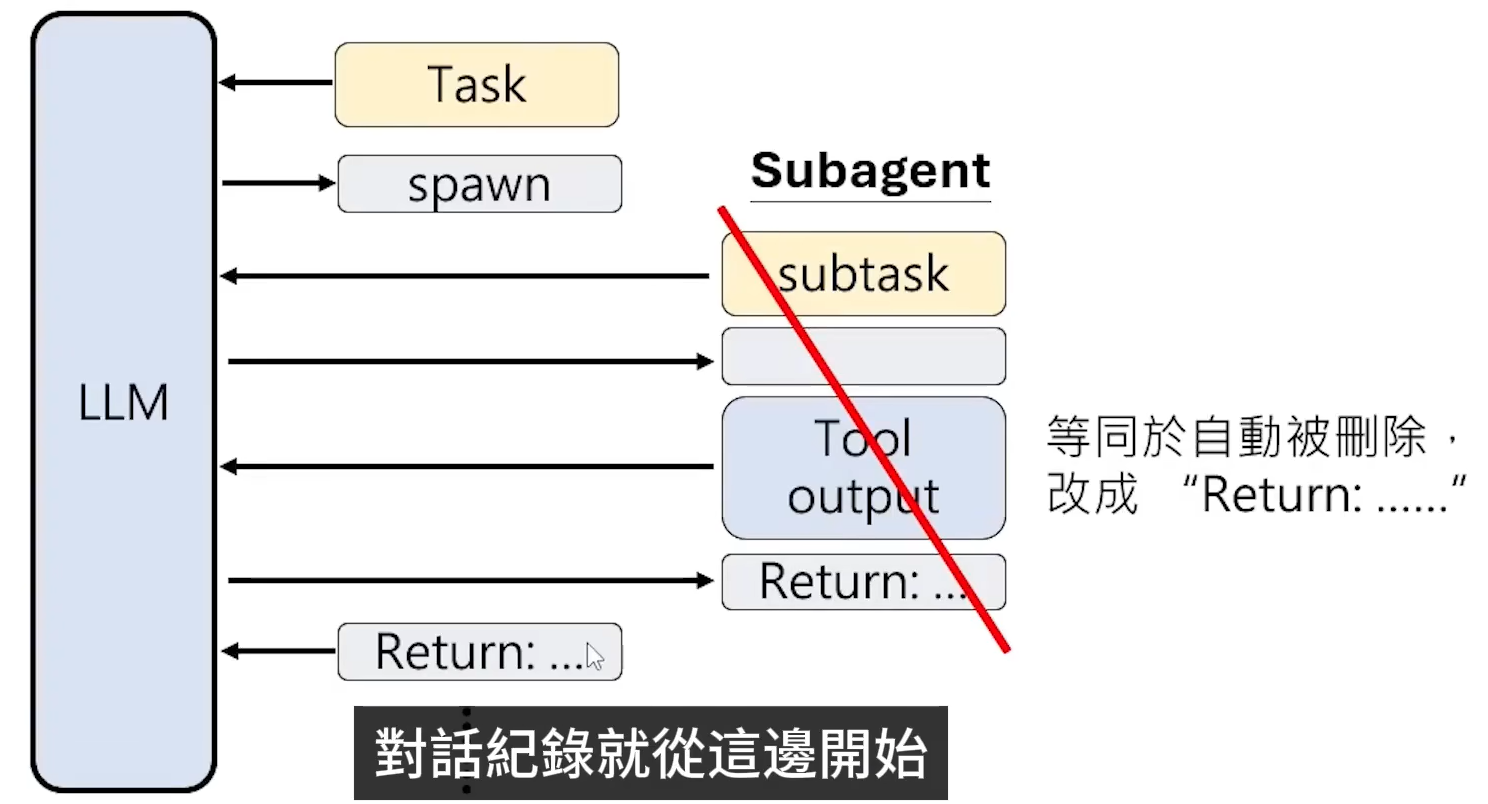
Subagent压缩
Subagent可视为自主压缩的行为,当模型到某个时间,产生一个使用工具的指令------spawn繁殖的时候,可以产生一个Subagent。当Subagent执行return之后,之前所做的事情全部从contex中被抹除,可视为自主压缩。(使用RL对LLM进行训练,且添加reward机制)
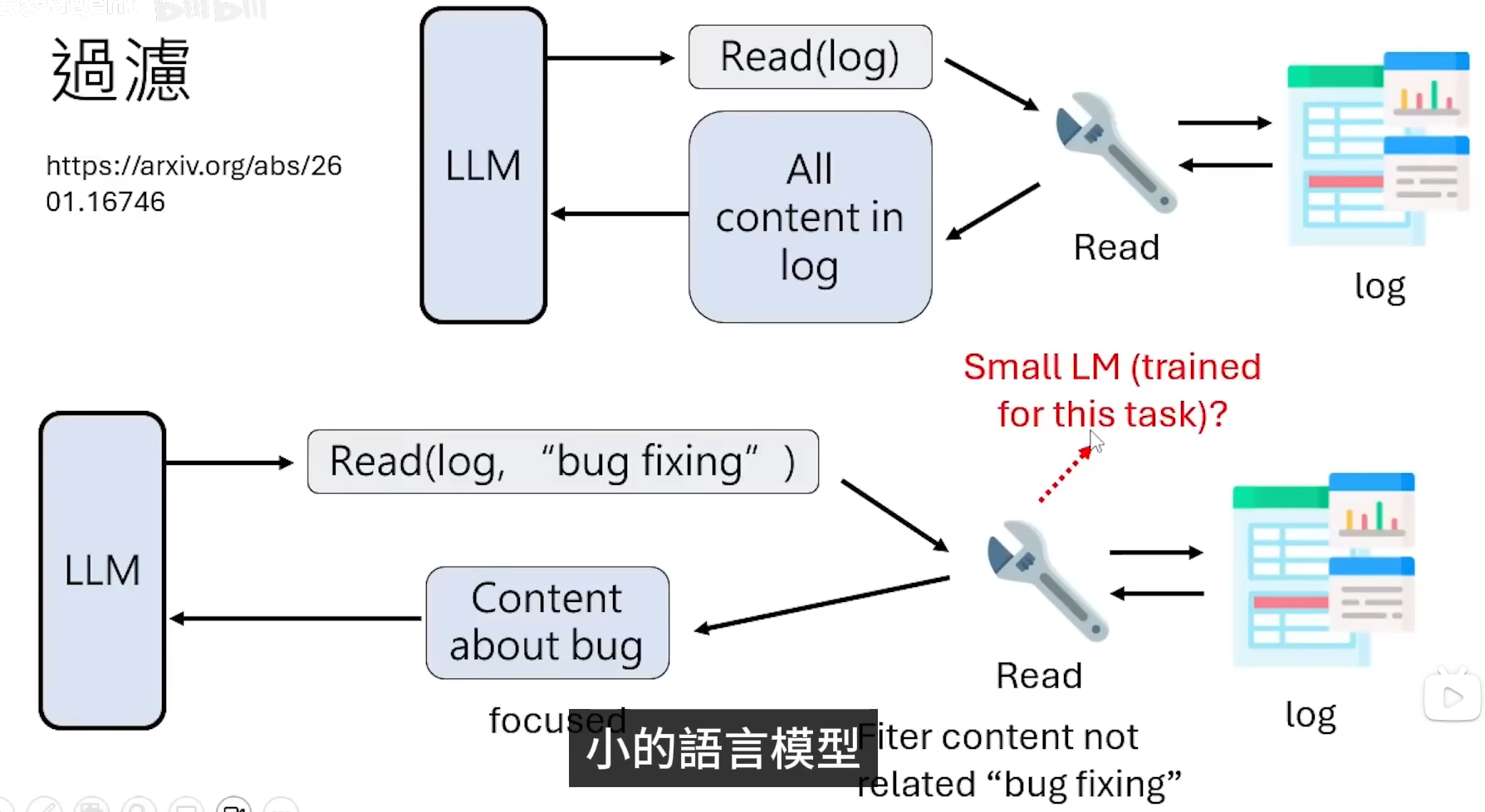
2.过滤
外界文件的输入导致context过长,那么一开始就不要那么多文字进入context,做出过滤操作。
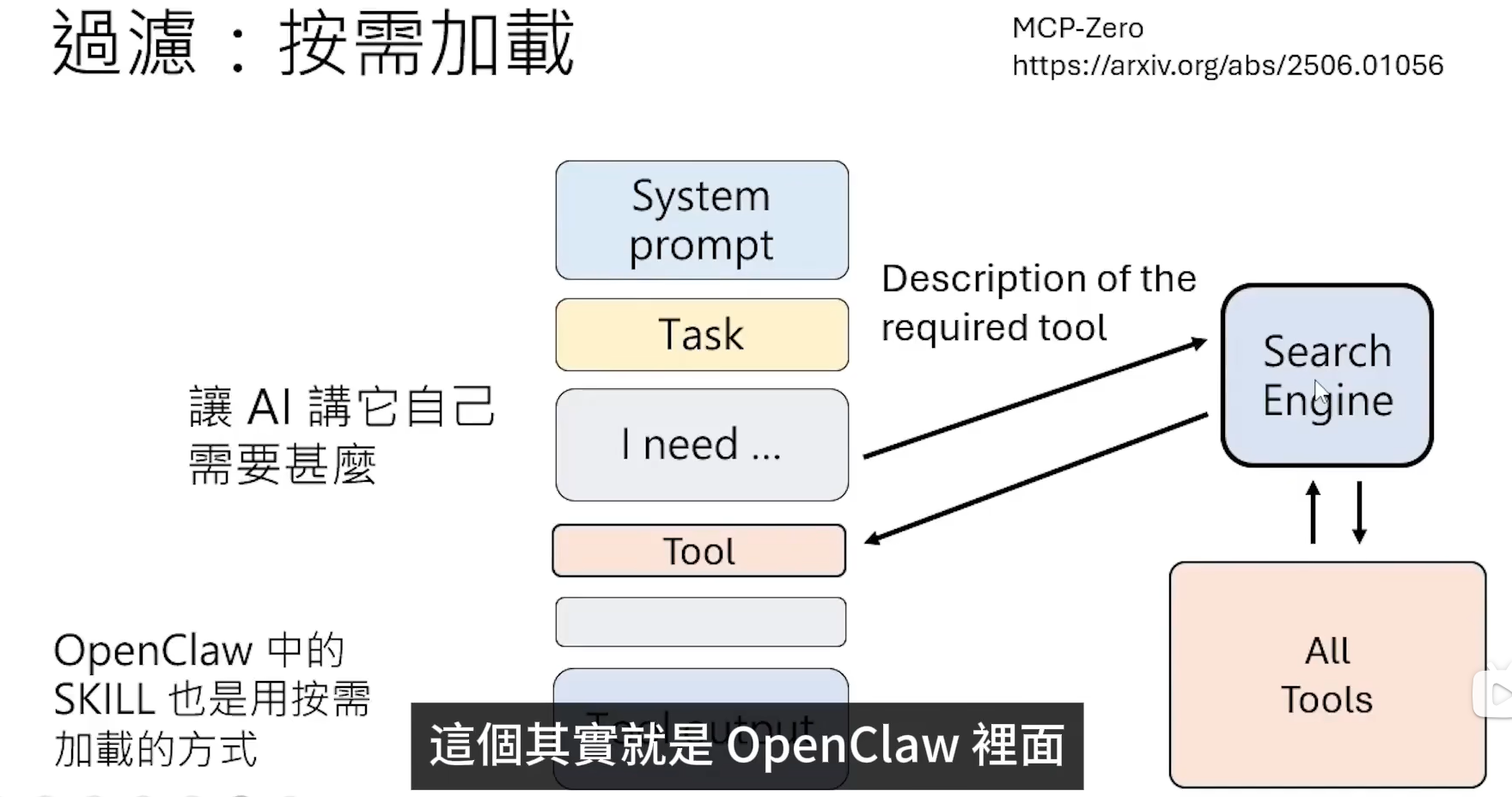
按需加载
当LLM接收到一个任务后,让LLM自主思考使用哪些工具,按需调用。