传统 OCR 模板匹配法
传统 OCR 模板匹配法是计算机视觉领域最经典的轻量级字符识别方案,属于基于相似性度量的无监督识别技术,是工业界规整印刷体字符识别场景的首选方案。该方法的核心逻辑是先构建标准化的字符模板库,再通过像素级相似性度量算法,将待识别字符与模板库中的所有标准模板逐一匹配,选取相似度最高的模板对应字符作为识别结果,全程无需标注数据与模型训练,仅通过基础的图像处理运算即可完成端到端的字符识别。
本文基于 OpenCV 实现完整的模板匹配法信用卡数字识别系统,整体流程分为三大核心模块:标准化数字模板库构建、信用卡图像预处理与字符分割、模板匹配与结果输出。本文将结合代码逐行详解模板库构建模块的完整实现原理与调试细节,为后续识别流程提供标准化的匹配基准。
模板库构建
把一张带 0-9 的模板图,处理成了标准化的、可直接用于匹配的数字模板字典,是整个信用卡识别项目的基础。
导入工具库
python
import numpy as np # 数值计算库,OpenCV处理图像本质是处理numpy数组
import argparse # 命令行参数工具:不用改代码,直接在终端传图片路径
import cv2 # OpenCV核心库,所有图像处理的函数都在这里
import myutils # 你自己写的工具库(后面会用到里面的轮廓排序函数)导入同目录下自己写的myutils.py工具文件
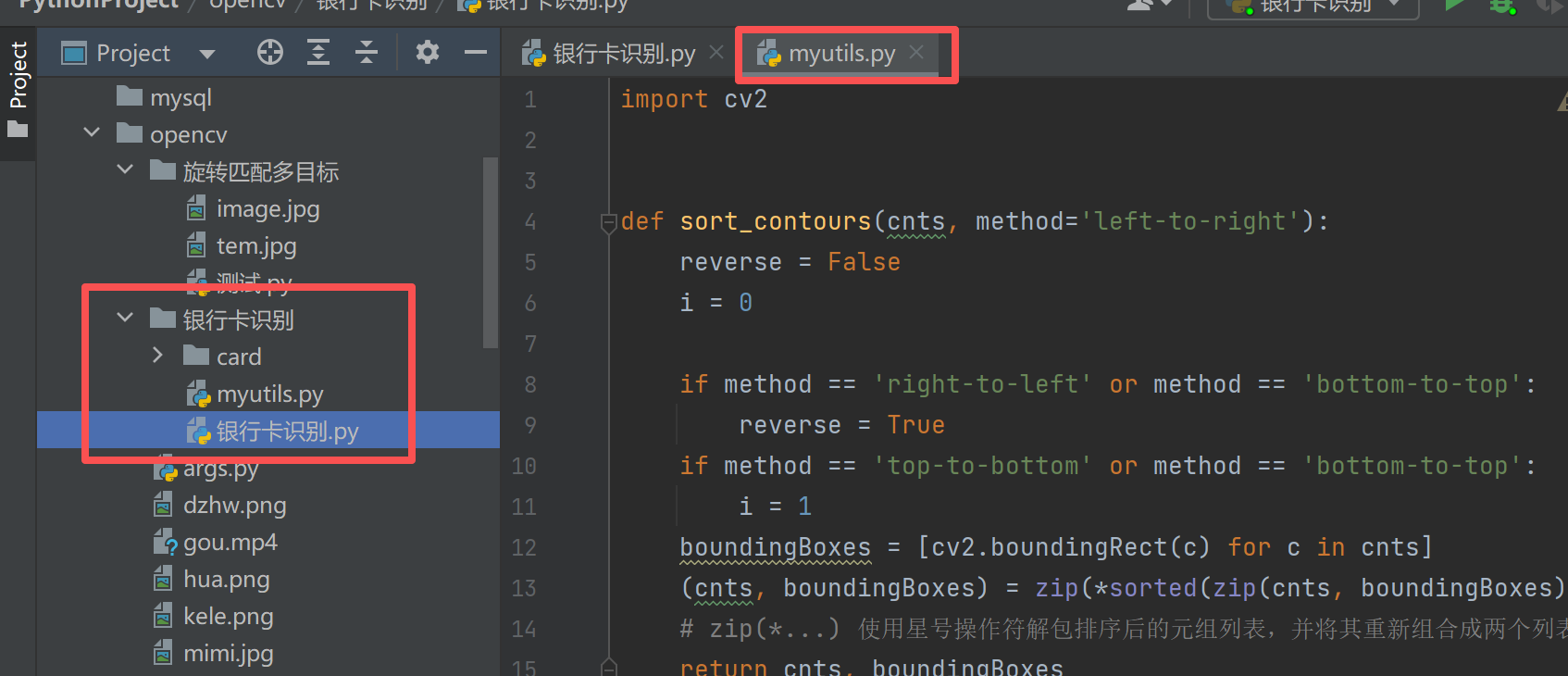
import argparse命令行参数工具使用方式:不用改代码,直接在终端传图片路径
- 方法 1(PyCharm 配置):打开「Run/Debug Configurations」,在
Parameters栏填写:-i card/card1.png -t card/kahao.png - 方法 2(终端运行):在终端执行命令:
python 银行卡识别.py -i card/card1.png -t card/kahao.png
命令行参数解析
python
ap = argparse.ArgumentParser()
# 加两个必传参数:-i 是你要识别的信用卡图片路径,-t 是0-9数字模板图的路径
ap.add_argument("--image", "-i", required=True, help="path to input image")
ap.add_argument("--template", "-t", required=True, help="path to template OCR-A image")
args = vars(ap.parse_args()) 创建一个参数解析器对象,所有参数都挂在这个对象上,规则是绑定在这个ap工具上的,不是全局的。面向对象思想:先创建实例,再给实例加属性 / 方法。你可以用同一个模具,造多个工具,每个工具加不同的规则,互不干扰。ap1和ap2都是同一个模具造的,但是上面挂的规则完全不一样,各干各的活,互不影响 ------ 这就是面向对象的优势:把工具和规则绑定,不会乱。
python
# 举个栗子
# 造第一个工具,收图片参数
ap1 = argparse.ArgumentParser()
ap1.add_argument("--image", required=True)
# 造第二个工具,收视频参数
ap2 = argparse.ArgumentParser()
ap2.add_argument("--video", required=True)ap对象就是一个「参数容器」,收参数、查参数、整理参数
required=True:必须传这个参数,不传就报错
help="xxx":终端输入python xxx.py -h时,显示的参数说明
ap.parse_args():解析终端输入的参数,返回一个Namespace对象,格式是Namespace(image='1.png', template='t.png')
vars():Python 内置函数,把对象的所有属性和值,转成键值对字典 ,转完格式是{"image": "1.png", "template": "t.png"}
为什么转字典?用args["image"]取值比args.image更灵活。现在就可以直接用args["image"]、args["template"]取路径了
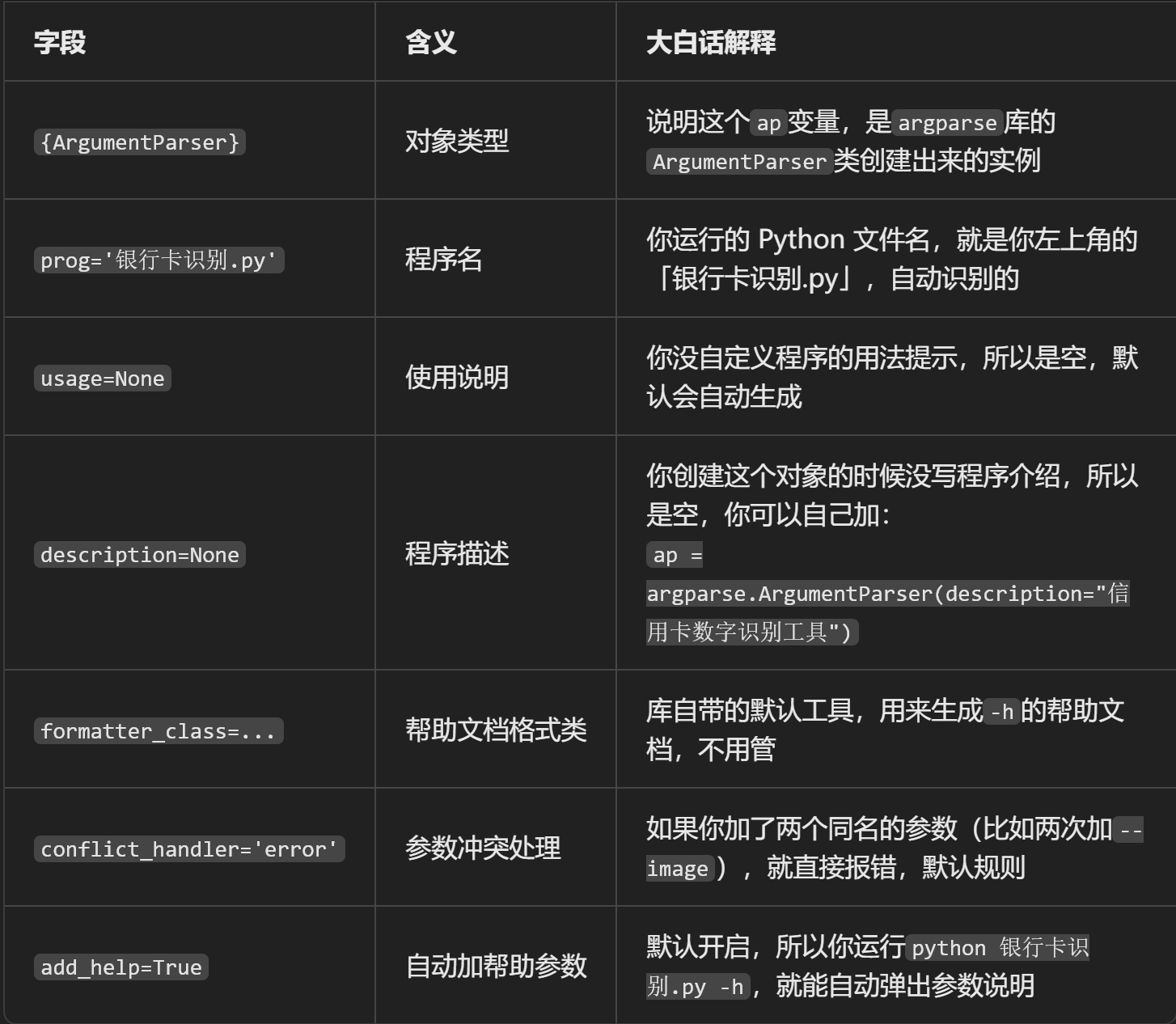

发卡行映射字典
python
FIRST_NUMBER = {"3": "American Express", # 卡号3开头:美国运通
"4": "Visa", # 4开头:Visa
"5": "MasterCard", # 5开头:万事达
"6": "Discover Card"} # 6开头:发现卡识别完信用卡卡号后,看第一位数字是什么,就能判断是哪家银行的卡,这是信用卡号的国际规则。
工具函数:显示图片
python
def cv_show(name, img):
cv2.imshow(name, img) # 弹出一个窗口,名字是name,显示img这张图(numpy 数组)
cv2.waitKey(0) # 等待你按任意键,才会关掉窗口(0=无限等)定义一个显示图像的工具函数,调用时只写一行cv_show()就行。
模板图片处理
python
img = cv2.imread(args["template"]) # 读取你传的模板图(模板图长这样:一行排着0 1 2 3 ... 9 十个数字)
cv_show('img', img) # 显示原始模板图,看看读对了没
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 彩色图转灰度图:彩色是3通道,转成1通道,后面二值化、找轮廓只能用灰度图
cv_show('ref', ref)调用工具函数,显示原始模板图,把彩色模板图转成灰度图,并显示灰度图。


反相 二值化,黑底白字
python
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
cv_show('ref', ref)灰度图转二值图,并且反相成黑底白字。cv2.threshold(输入图, 阈值, 最大值, 阈值类型),小于 10 归为一类,大于 10 归为一类,像素值 > 阈值 → 设为 0(黑),像素值 ≤ 阈值 → 设为最大值(白),原本白底黑字的模板图,变成黑底白字,数字是白色,背景是黑色。
这个函数返回两个值 ,第一个是用的阈值,第二个才是处理完的二值图,所以必须取[1]
为什么要黑底白字?cv2.findContours()默认找白色物体的轮廓,黑底白字才能准确框住数字
显示二值化后的图

找数字的轮廓
python
refCnts = cv2.findContours(ref, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]查找二值图中所有数字的外轮廓
- cv2.findContours(输入图, 轮廓检索模式, 轮廓近似方法)。输入图:必须是单通道二值图,灰度图 / 彩色图都会报错
cv2.RETR_EXTERNAL:只检索最外层轮廓,忽略数字内部的孔洞(比如 0、6、8、9 中间的洞),我们只要数字的外框cv2.CHAIN_APPROX_SIMPLE:压缩轮廓点,比如矩形轮廓只保留 4 个角的坐标,不用存整条边的所有点- OpenCV3.x 版本:返回
(图像, 轮廓, 层级)→ 轮廓是索引 1,OpenCV4.x 版本:返回(轮廓, 层级)→ 轮廓是索引 0,统一取[-2](倒数第二个),所有版本都能拿到轮廓,不用管版本号
python
cv2.drawContours(img, refCnts, -1, color=(0, 0, 255), thickness=3)
cv_show('refCnts', img)把找到的轮廓,画在原始彩色模板图上
- 第一个参数:要画轮廓的底图
- 第二个参数:轮廓列表
- 第三个参数
-1:画所有轮廓,写 0 就是画第 0 个轮廓,1 就是第 1 个,以此类推 color=(0, 0, 255):轮廓颜色,OpenCV 是 BGR 格式,所以这个是纯红色thickness=3:轮廓线的粗细,单位是像素
显示画了轮廓的图

给轮廓排序
python
refCnts = myutils.sort_contours(refCnts, method="left-to-right")[0]把轮廓按「从左到右」的顺序排序
cv2.findContours()找出来的轮廓顺序是乱的,不是 0→1→2→...→9 的顺序,sort_contours原理:拿到每个轮廓的外接矩形左上角 x 坐标,按 x 从小到大排序,x 越小越靠左,返回值取[0]:这个函数返回(排序后的轮廓列表, 排序后的 boundingRect 列表),我们只要轮廓,所以取第一个。
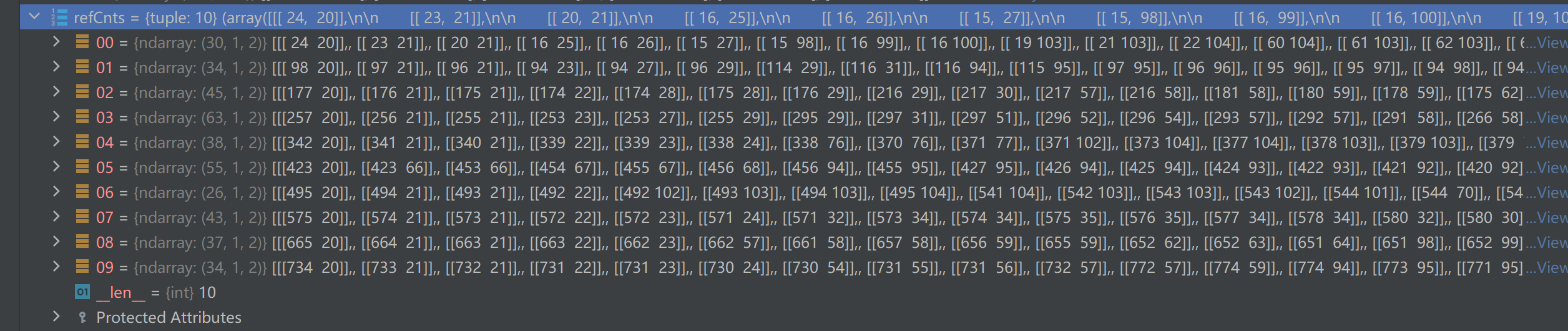
顺序是从左到右排好的:第 0 个是最左边的数字 0,第 1 个是数字 1,... 第 9 个是最右边的数字 9,是我们要的顺序。
挨个抠出每个数字,存成模板字典
python
digits = {} # 最终的模板字典:key=数字(0-9),value=对应数字的小图
for (i, c) in enumerate(refCnts):
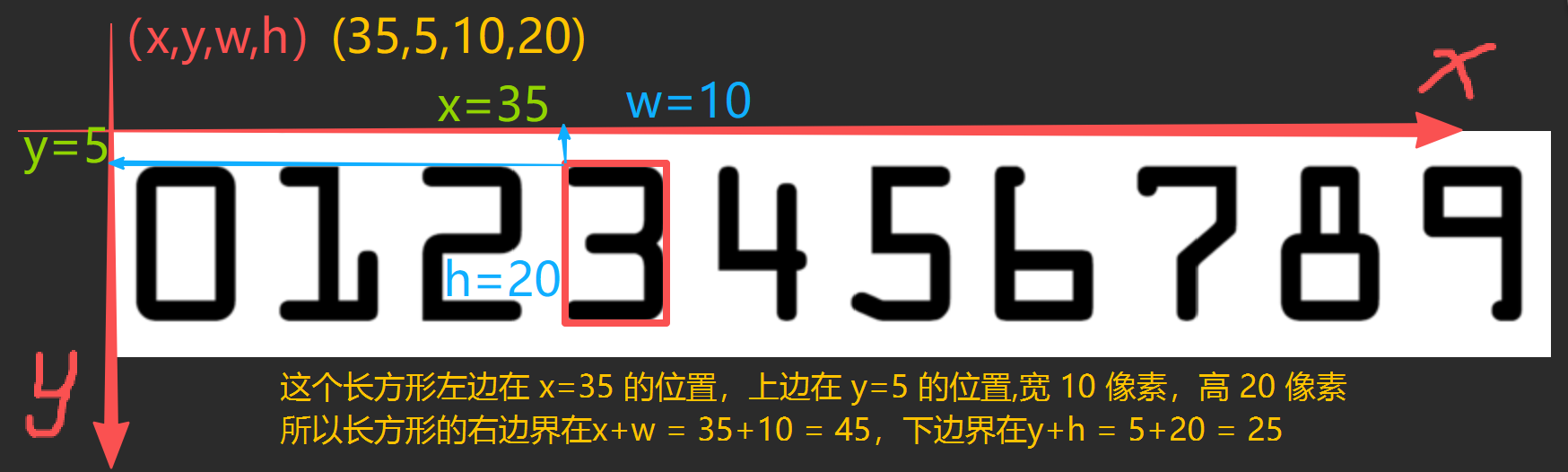
(x, y, w, h) = cv2.boundingRect(c) # 给每个轮廓,套一个最小的矩形框,返回框的左上角坐标(x,y)、宽w、高h
roi = ref[y:y + h, x:x + w] # 从二值图里,把这个矩形区域抠出来------就是单个数字的小图!
roi = cv2.resize(roi, dsize=(57, 88)) # 把所有数字模板,统一resize成57宽×88高!
cv_show('ro', roi) # 调试:看看抠出来的单个数字对不对
digits[i] = roi # 存到字典里,i就是0-9的数字
print(digits)遍历排序后的每一个轮廓,i 是索引(0-9,刚好对应数字 0-9),c 是单个轮廓
enumerate():Python 内置函数,遍历列表时同时返回「索引 + 元素」,不用自己写计数器 i=i+1
boundingRect是轮廓最常用的函数,作用是把不规则的轮廓,转成规则的矩形,方便裁剪- 返回值顺序固定:(x, y, w, h),x 是左边界,y 是上边界
给轮廓套一个最小的外接矩形,返回矩形的左上角坐标 (x,y)、宽度 w、高度 h
用 numpy 切片,从二值图里把数字的矩形区域抠出来,就是单个数字的小图,numpy 切片规则:数组[行范围, 列范围],图像的行对应 y 轴(高度),列对应 x 轴(宽度),所以是[y方向, x方向]
把所有抠出来的数字,统一 resize 成 57 宽 ×88 高的固定大小 (模板匹配的前提)】
- 模板匹配的本质是两张图逐像素做相似度计算,大小不一样根本没法比!
dsize=(宽, 高):注意这里是宽在前,高在后,和 numpy 切片的 (y,x) 顺序相反,OpenCV 所有尺寸参数都是 (宽,高)- 默认用双线性插值,resize 后数字不会变形
显示抠出来的单个数字模板
把处理好的数字模板,存入字典,索引 i 就是对应的数字(0-9)
打印字典,确认 10 个模板都存进去了
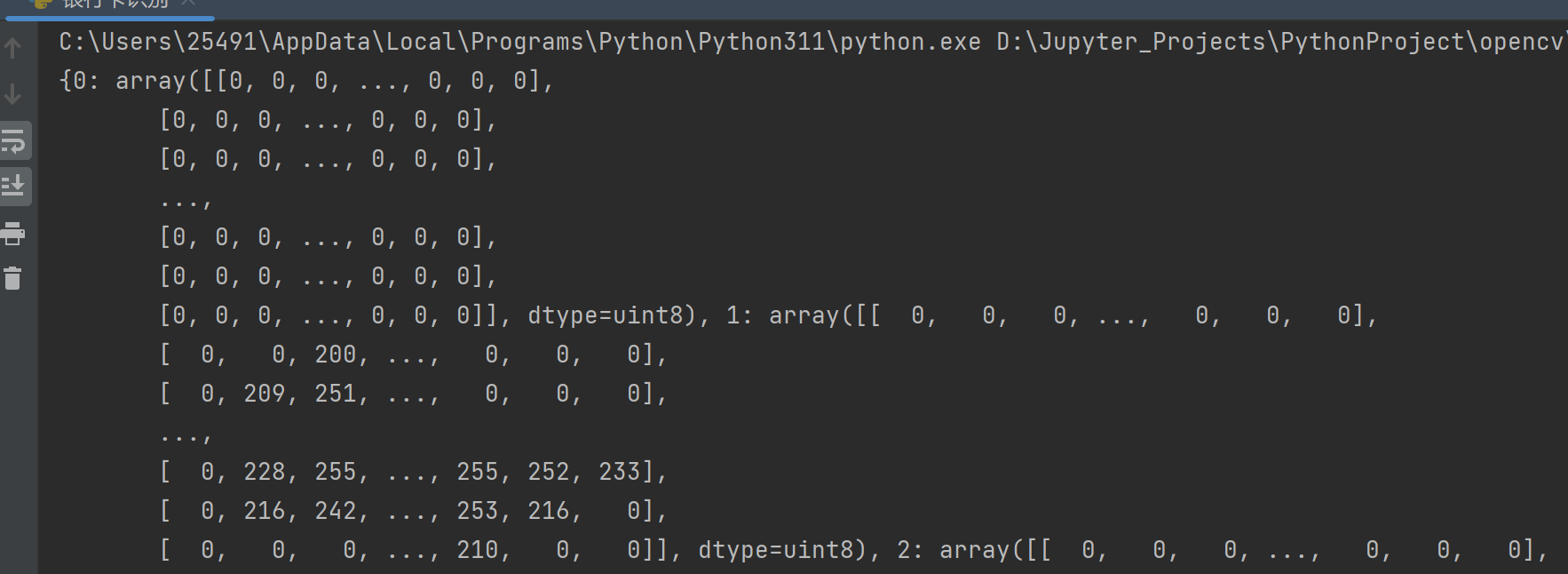
原来的二值图确实只有0(黑)和255(白),但是执行cv2.resize(roi, dsize=(57, 88))的时候,OpenCV 默认用的是双线性插值算法:
- 插值就是:把小图放大 / 缩小时,不是简单的复制 / 删除像素,而是计算相邻像素的平均值,让边缘更平滑
- 比如数字边缘的两个相邻像素,一个是 0(黑背景),一个是 255(白数字),插值后就会算出
209、251、228这种中间灰度值 - 这些中间值,全部都在数字的边缘位置,就是插值产生的平滑过渡,数字主体还是 255,背景还是 0。