lululemon官网门店查询页面采用纯静态HTML架构,门店数据在服务端渲染时直接嵌入页面源代码,而非通过XHR异步加载或前端JavaScript动态渲染。该页面以城市为一级分组,以折叠面板展示门店明细,城市名称、门店序号、店名、详细地址、联系电话等字段均以纯文本形式存在于DOM结构中,无鉴权、无加密、无分页接口。
基于此特征,数据采集流程可简化为三个环节:首先,通过requests库发起标准HTTP GET请求获取完整HTML文本,无需处理Session、Token或签名参数;其次,利用re正则模块或BeautifulSoup解析器对页面源码进行结构化清洗,按城市分组逐条提取门店名称、地址、电话等字段;最后,将解析结果以UTF-8-sig编码写入CSV文件,完成数据持久化。整个过程不涉及浏览器模拟、API逆向或动态渲染等待,单次请求即可获取全量数据。
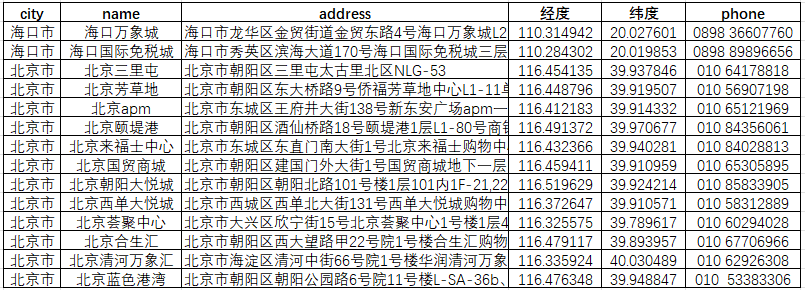
采集结果包含门店名称、所在城市、详细地址、联系电话四个核心字段。基于该数据集,可进一步调用高德或百度地理编码API将地址转换为经纬度坐标(GCJ-02坐标系),再通过coord-convert库转换为WGS84坐标系以满足ArcGIS等专业GIS平台的可视化要求。后续分析方向包括城市层级分布统计、区域渗透率计算、空间聚类识别以及同类品牌门店网络的叠置对比,为零售品牌渠道布局研究提供结构化数据基础。
首先,我们找到网点数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
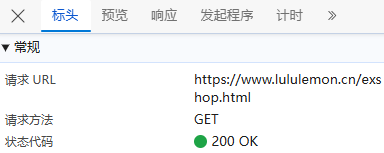
负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里就没有负载;
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据直接就在html的页面里;

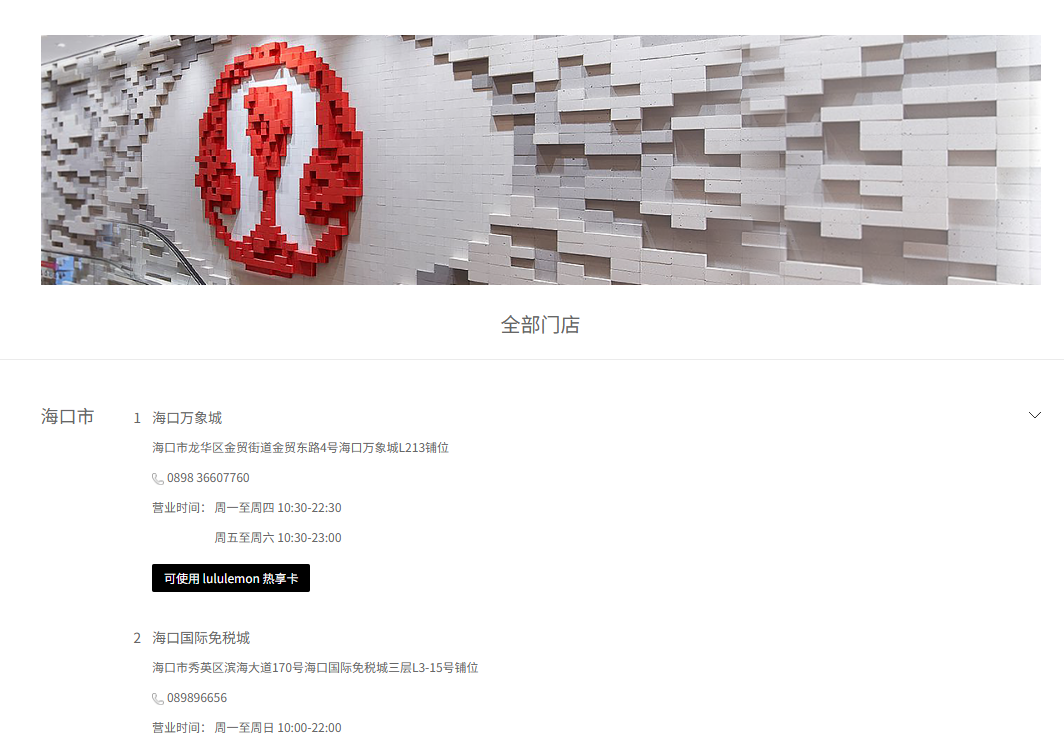
一页看尽 49 座城市
打开 lululemon 中国大陆官网的门店查询页面 ,会看到一个干净的城市列表:北京市、上海市、深圳市......点开任意城市的折叠面板,该城市下所有门店的名称、地址、联系电话一字排开。
这不是 Ajax 加载,不是前端渲染------这是一张纯静态 HTML 页面。服务端在响应请求时,已经把全国 49 座城市、205 家门店的全部信息写进了 HTML 标签里。
这意味着一件事:不需要模拟浏览器,不需要伪造请求头,甚至不需要解析 JSON。 一个普通的 HTTP GET 请求就能拿到全部数据。
第一步:利用requests库发送HTTP请求获取所有门店列表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
python
import urllib.request
import re
import csv
import ssl
import os
URL = "https://www.lululemon.cn/exshop.html"
OUTPUT_DIR = os.path.dirname(os.path.abspath(__file__))
OUTPUT_CSV = os.path.join(OUTPUT_DIR, "lululemon_stores.csv")
ctx = ssl.create_default_context()
headers = {"User-Agent": "Mozilla/5.0"}
req = urllib.request.Request(URL, headers=headers)
with urllib.request.urlopen(req, timeout=30, context=ctx) as r:
html = r.read().decode("utf-8")
# 去除 HTML 标签,按行拆分纯文本
text = re.sub(r"<[^>]+>", "\n", html)
lines = [l.strip() for l in text.split("\n") if l.strip()]
stores = []
current_city = ""
i = 0
# 定位到门店区域
while i < len(lines) and "全部门店" not in lines[i]:
i += 1
i += 1
while i < len(lines):
line = lines[i]
# 遇到底部导航则结束
if any(kw in line for kw in ["门店查找", "浏览全部门店", "关注我们"]):
break
# 城市名:纯中文 + "市"或"省"结尾
if re.match(r"^[\u4e00-\u9fa5]+(市|省)$", line):
current_city = line
i += 1
continue
# 门店编号:纯数字,且当前已有城市名
if re.match(r"^\d+$", line) and current_city:
i += 1
if i >= len(lines):
break
name = lines[i]
i += 1
if i >= len(lines):
break
address = lines[i]
i += 1
if i >= len(lines):
break
phone = lines[i] if re.match(r"^\d", lines[i]) else ""
if phone:
i += 1
# 跳过营业时间和附加信息
while i < len(lines) and any(
kw in lines[i]
for kw in ["营业时间", "周一", "周二", "可使用", "离境退税", "Tax"]
):
i += 1
# === 地址智能补全逻辑 ===
full_address = address
city_clean = current_city.rstrip("市省") # 如 "北京市" -> "北京"
city_with_shi = city_clean + "市" # "北京" -> "北京市"
city_with_sheng = city_clean + "省" # "广东" -> "广东省"
# 检查地址是否已包含完整城市名(如"北京市"、"广东省")
if not (current_city in address or city_with_shi in address or city_with_sheng in address):
# 如果都不包含,则在地址前加上城市名
full_address = current_city + address
stores.append(
{
"city": current_city,
"name": name,
"address": full_address,
"phone": phone,
}
)
continue
i += 1
# 保存 CSV
with open(OUTPUT_CSV, "w", newline="", encoding="utf-8-sig") as f:
w = csv.DictWriter(f, fieldnames=["city", "name", "address", "phone"])
w.writeheader()
w.writerows(stores)
# 统计
cities = {}
for s in stores:
cities[s["city"]] = cities.get(s["city"], 0) + 1
print(f"完成:{len(stores)} 家门店,{len(cities)} 座城市")
print(f"TOP 5: {dict(sorted(cities.items(), key=lambda x: -x[1])[:5])}")
print(f"CSV: {OUTPUT_CSV}")数据会以csv表格的形式,保存在运行脚本的目录下,表格名:cfmoto_stores.csv;(注:文中数据截至 2026 年 6 月)
数据标签包括:city(所在城市)、name(门店名称)、address(地址)、phone(联系方式),其他一些非关键标签,这里省略;

第二步 :坐标编码,由于门店数据使用的是详细地址,为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的地址转换成地址转经纬度,可以用免费这个网站:批量转换工具:https://piliang.cc0.top/geocoding;
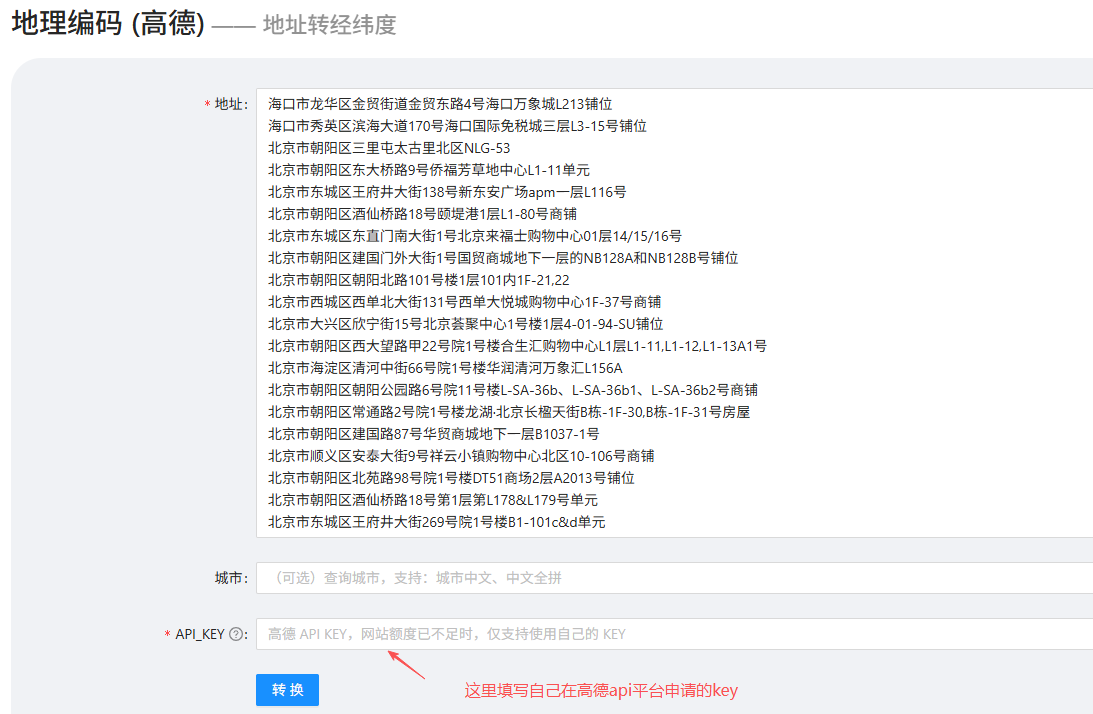
这里我们得到的坐标是高德坐标系(GCJ-02),需要转换成wgs84坐标系,我们可以利用coord-convert库中的gcj2wgs(lng, lat)函数;
第三步:可视化,这里我们把转换好的坐标进行可视化,这里使用arcgis进行实现;
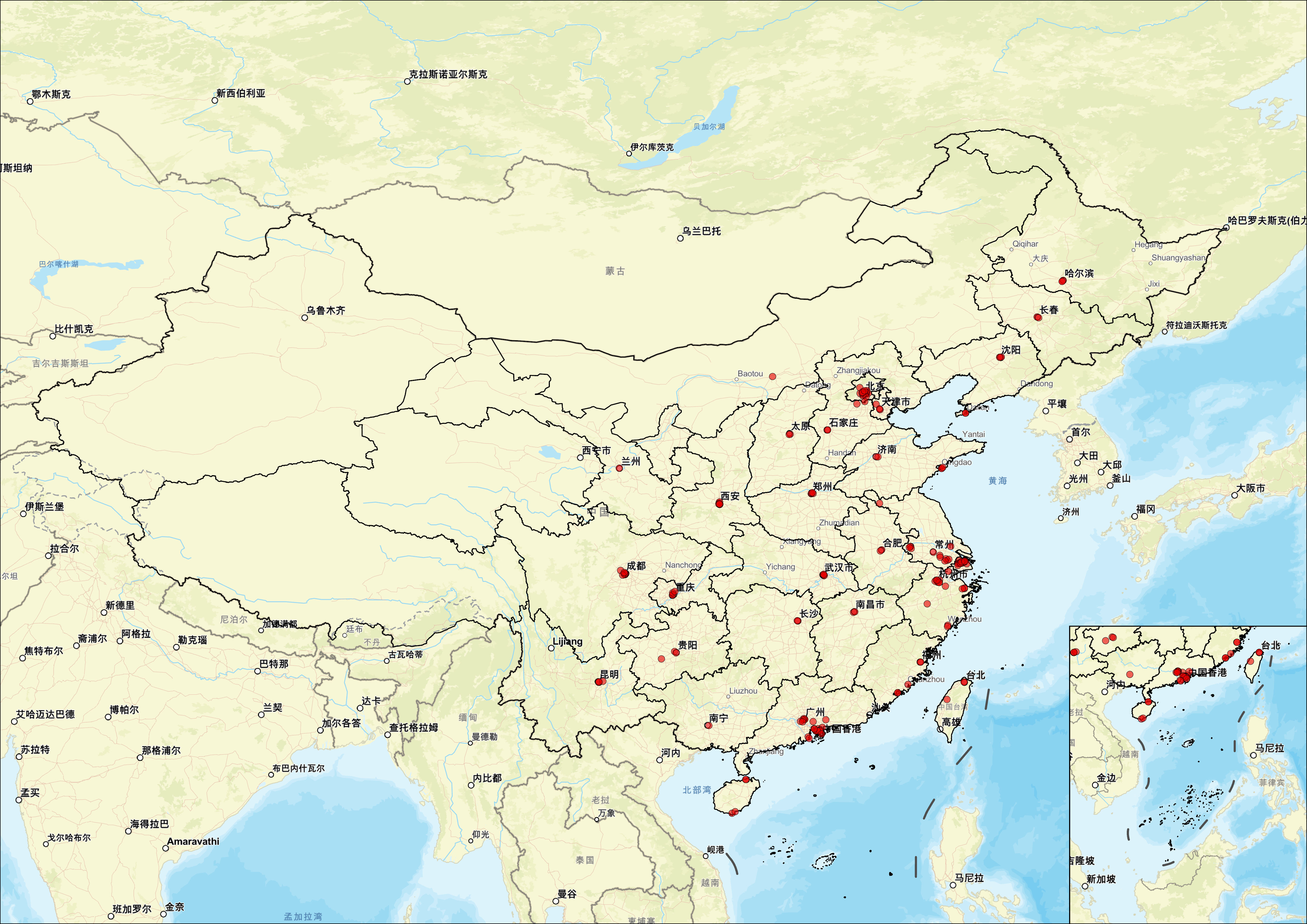
接下来,我们进行看图说话:
一、总体格局:高度集中的头部城市主导型分布
从总量来看,204家门店分布于50座城市,平均每城约4家,但实际分布极不均衡。上海以32家居首,北京26家紧随其后,深圳14家位列第三,三城合计72家,占总量的35.3%。前五城(上海、北京、深圳、成都、杭州)合计89家,占比43.6%;前十城合计约130家,占比达63.7%。这一数据清晰地表明,lululemon在中国大陆的门店布局呈现典型的"头部集中"特征------少数几座一线与新一线城市承载了品牌六成以上的线下渠道资源。这种格局与品牌的高端定位和直营模式高度吻合:核心城市拥有更成熟的高端购物中心基础设施、更庞大的中高收入消费群体以及更强的品牌溢价承受力,是直营零售品牌实现单店高产出与品牌形象塑造的最优选择。值得注意的是,上海以32家的绝对优势领跑全国,不仅反映了其作为中国消费中心城市的经济地位,也与该市高端商业地产的高度集聚(如静安嘉里、国金中心、兴业太古汇、港汇恒隆等)形成直接对应。
二、城市层级分布:一线与新一线为绝对主体,下沉尚未开启
按城市层级观察,lululemon的门店布局呈现"橄榄型"结构------顶端为超一线城市(北上广深),中部为新一线及强二线城市,而广大三线及以下城市尚未纳入布局版图。四大一线城市(北京、上海、广州、深圳)合计77家,占总量的37.7%,其中广州仅5家,与其他三城差距悬殊,或与广深两地消费习惯差异及商圈供给结构有关。新一线城市中,成都9家、杭州8家、西安7家、武汉5家、重庆5家、南京4家、苏州4家、天津3家、青岛3家、宁波3家,构成第二梯队。这些城市均为区域经济中心,拥有成熟的商业综合体和活跃的年轻消费群体,是品牌在超一线城市之外的核心阵地。值得关注的是,部分经济总量领先的城市门店数量并不突出,例如苏州(GDP全国第六)仅4家、南京4家,而成都、杭州等消费型城市则门店密度更高,反映出品牌选址逻辑不仅看重经济总量,更关注城市商业活力、消费文化氛围及年轻客群聚集度。截至目前,lululemon尚未进入任何普通地级市,说明品牌在当前阶段仍以"聚焦核心城市、单店深耕"为优先策略,渠道下沉尚未正式启动。
三、省级分布与区域差异:东部密集、中部稀疏、西部点缀
按省份汇总,门店覆盖25个省级行政区(含直辖市及台湾省),但区域差异极为显著。上海(32家)与北京(26家)构成第一梯队;广东(深圳14家、广州5家、佛山2家、东莞1家、珠海1家,共23家)紧随其后;浙江(杭州8家、宁波3家、温州2家、金华1家、绍兴1家、嘉兴1家,共16家)和江苏(南京4家、苏州4家、无锡2家、常州1家、南通1家、徐州1家,共13家)分列其后。这四个省级单元合计84家,占总量的41.2%。若将京津冀、长三角、珠三角三大城市群合并计算,占比超过七成。与之形成鲜明对比的是中西部及东北地区:四川(仅成都9家)、陕西(西安7家)、湖北(武汉5家)、重庆(5家)为核心据点,但各省门店数量相对有限;而内蒙古、甘肃、贵州、山西、吉林、黑龙江等省份仅有省会城市开设1-2家门店;西藏、青海、宁夏、新疆、广西等省份尚无门店。这一分布格局与区域经济发展水平、人均可支配收入及高端零售商业地产的成熟度高度正相关。从城市群视角看,长三角地区(上海+浙江+江苏)合计61家,占总量近三成,是品牌在中国密度最高的区域市场,反映出长三角地区在高收入人群密度、商业设施供给及消费文化方面的综合优势。
四、特殊渠道:机场店布局与交通枢纽策略
表格数据中一个值得单独分析的现象是机场门店的密集出现。统计显示,lululemon已在9座机场开设门店,包括北京大兴国际机场、上海虹桥国际机场、深圳宝安国际机场(T3航站楼及卫星厅共2家)、广州白云国际机场(T2航站楼)、成都双流国际机场、昆明长水国际机场及重庆江北国际机场(T3航站楼)。机场店的数量占门店总量的约4.4%,且均为安检区内的高客流位置,表明品牌将高净值差旅人群视为重要客群触点。这一策略与lululemon的"运动生活方式"定位高度契合------频繁出差的商务旅客及旅行爱好者往往对运动休闲服饰有较高的场景需求,且机场消费场景具有"目的性强、停留时间充裕、客单价较高"的特征,适合高端运动品牌的转化。此外,机场作为城市门户,其零售店铺本身亦具有品牌展示和形象塑造的功能,对品牌在区域市场的影响力辐射亦有辅助作用。值得注意的是,机场店目前仅分布在核心枢纽城市,尚未进入区域级机场,表明该渠道仍属品牌高端客群触达的补充手段,而非主力布局方向。
| 排名 | 省份 | 门店数 | 特征 |
|---|---|---|---|
| 🥇 | 上海 | 32 | 中国消费之都,品牌旗舰密度最高 |
| 🥈 | 北京 | 26 | 北方核心枢纽,高端商圈全覆盖 |
| 🥉 | 广东 | 23 | 深广双核驱动,珠三角消费引擎 |
| 4 | 浙江 | 16 | 民营经济活跃,杭甬温多点开花 |
| 5 | 江苏 | 13 | 长三角腹地,苏南城市群协同 |
| 6 | 四川 | 9 | 西南门户,成都一城独大 |
| 7 | 陕西 | 7 | 西北桥头堡,西安引领西部消费 |
| 8 | 湖北 | 5 | 中部支点,武汉辐射华中 |
| 9 | 重庆 | 5 | 西部唯一直辖市,商业活力强劲 |
| 10 | 山东 | 5 | 北方经济大省,青岛济南双核 |
-
城市覆盖率 :共覆盖 50 座城市,除上海、北京、天津、重庆四个直辖市外,其余均为省会或计划单列市(如深圳、宁波、青岛、大连、厦门),尚未进入任何普通地级市。
-
区域集中度:TOP 3(上海+北京+广东)合计 81 家,占总量的 39.7%;TOP 10 省份合计 141 家,占总量的 69.1%。
-
西部渗透:四川、陕西、重庆三省合计 21 家,是西部唯一成规模的区域,其余西部省份(甘肃、贵州、云南、内蒙古等)均为省会单店。
-
机场特殊渠道:9 家机场店分布在北京大兴、上海虹桥、深圳宝安、广州白云、成都双流、昆明长水、重庆江北,占总量的 4.4%。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。