AI驱动数仓建设的Harness工程实践------本体建模、知识分层与上下文工程
NC65,5312张表,179个模块。字段名长这样:cinvoicecustid、fstatusflag、nsummny。你让Claude Code来建DWD层,它连哪张表存销售额都找不到。
这不是模型的问题。是知识没到位。
这篇讲的是我怎么在一个盐业集团的数仓项目里,用一套文件化的工程方法把业务知识喂给AI,让它从"瞎编"变成"能干活"。方法拆成三块:本体建模、知识分层、上下文递送。我叫它Harness工程。
第一章 NC65的5312张表
项目开局
盐业集团的数仓,8个业务主题,NC65-ERP抽数,建ODS/DWD/DWS/ADS四层,最后出BI看板。资料不算少:需求文档、203个指标的指标库、架构图、NC65环境配置。
打开Oracle数据字典,情况就不太对。NC65是个老ERP,5312张表、179个模块,表名两字母缩写标模块(so=销售、po=采购、mm=生产、ic=库存、ar=应收、ia=成本核算),字段名是匈牙利命名法的变体加上业务缩写。大概长这样:
lua
bd_customer -- 客户档案
so_saleinvoice_b -- 主子表的子表,_b是NC65惯例
cinvoicecustid -- c开头=字符型外键
fstatusflag -- f开头=整型标记位
pk_org -- pk_前缀=主键指标库里写"销售额(含税)",对应哪张表的哪个字段?nsummny(价税合计)还是nmny(不含税金额)还是ntaxmny(税额)?指标库和源表之间那层映射关系,基本只在实施顾问脑子里。
让AI直接上场
这类ERP建模我做过不少,套路熟。但这次想试一下:让AI当主力,看能走多远。
直接把NC65的so_saleinvoice(销售发票主表)和so_saleinvoice_b(子表)DDL丢给Claude Code,让它写DWD层清洗ETL。
翻车了,在意料之中:
字段靠猜。 模型不知道fstatusflag在销售模块什么意思,编了WHERE fstatusflag = 1。实际上NC65不同模块状态码含义完全不同------销售模块fbillstatus IN (2,3,4)才是有效单据,生产模块IN (1,2,3),库存模块IN (2,3)。
JOIN靠编。 不知道NC65主子表用pk/fk字段关联,编了个外键名。实际关联键是so_saleinvoice_b.cinvoiceid = so_saleinvoice.csaleinvoiceid,c前缀+业务缩写这种风格,没见过NC65的猜不到。
行级陷阱全漏。 NC65有大量要过滤的噪声行------isinit='Y'是系统初始化数据、frowtype IN (5,6)是费用行不参与数量统计、_audit后缀表才是审核过的。这些规则散落在实施文档和老顾问脑子里,模型一条不知道。
口径随机选。 指标库写"销售额",NC65有nsummny(价税合计)、nmny(不含税)、ntaxmny(税额),模型随便挑了一个。
问题在哪
不是模型笨。是它根本没拿到正确的信息。
模型在上下文窗口内工作,窗口之外的东西一律看不见。5312张表、179个模块的业务知识,一条没进它的上下文。它只带着通用ERP常识进场,而这家企业的NC65私有规则------字段命名惯例、状态码差异、行级过滤规则------全是空白。
幻觉就是模型用通用常识填私有知识的空白。
这个问题可以工程化地解:把散在源系统元数据、业务专家脑子里、零散文档中的知识,转成机器可读的文件,每次会话精确递到模型面前。
第二章 三件套
为什么"递文件"比"多解释"管用
三个基本事实:
-
上下文窗口是模型的全部工作台。 桌面上有的它看得见,没有的靠训练记忆猜。NC65字段语义不在公开语料里,只能猜,猜就是幻觉。
-
注意力会稀释。 900页字典全摊上去,模型反而抓不住重点。得分场景只递"此刻最相关的那几页"。
-
结构化比散文好用。 YAML、JOIN Map这类格式,比写一段话"这两张表可以关联"强得多------歧义少,模型能精准对齐。
想清楚这三点,做法就出来了:控制递什么、什么时候递、递多少。这就是我说的Harness工程。
三大件
拆开看,三个工位:
| 工位 | 解决的问题 | 核心产出 |
|---|---|---|
| 本体建模 | 知识长什么样 | 领域本体:概念/关系/约束/推理规则 |
| 金字塔知识图谱 | 知识怎么分层按需取用 | L1→L5分层 + frontmatter + 字符预算 |
| 文件化Harness | 知识怎么精确递到模型眼前 | CLAUDE.md + MCP双库 + 自动字典 + 血缘图 |
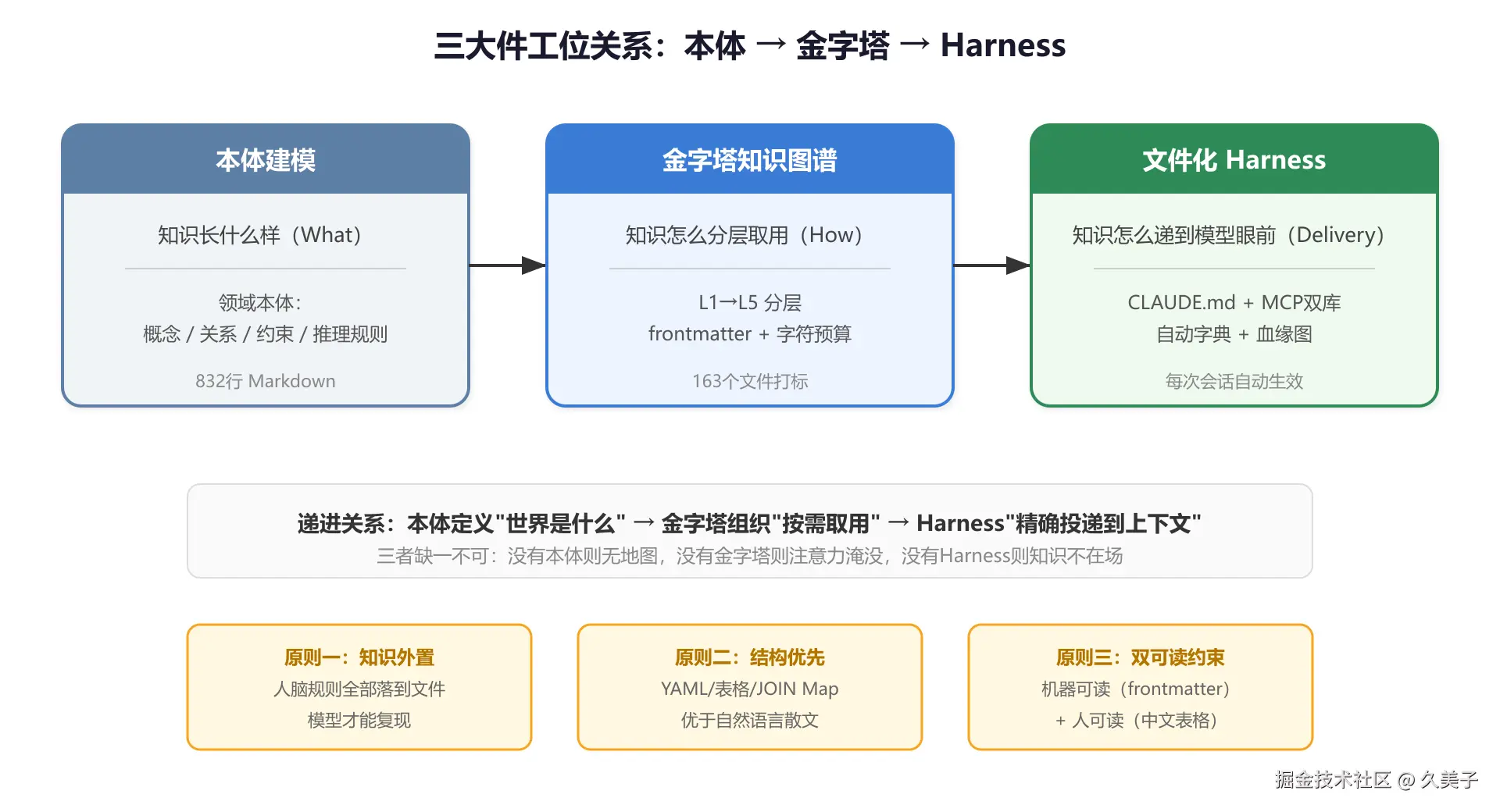
三者递进:本体定义业务知识,金字塔把它组织成按需取的层次,Harness负责每次会话精确投递。
三条原则
- 知识外置。 只存在脑子里的规则模型复现不了,全部落文件。
- 结构优先。 能用YAML/表格/Map表达的,不写散文。
- 双重可读。 文件既要脚本能扫(frontmatter),也要人能看(中文表格)。
按项目推进顺序,下面逐步展开。
第三章 本体先行
为什么不先建表
传统数仓项目上来就是画ER图、定分层、建表。但打算让AI当主力的话,顺序得改。
AI不缺写SQL的能力,缺的是业务理解。哪些实体存在、什么关系、哪些字段能JOIN、状态码什么含义------这些不先显式化,AI每次都在信息不全的状态下干活,你得不断纠偏。
所以我第一件事是建本体------把业务知识从隐性变成显性,从散文变成结构。dltHub有句话说得对:本体是地图,Prompt是路径。AI不缺规划路径的能力,缺的是地图。
本体比ER图多管什么
ER图只管结构------表、字段、外键。本体还管:
- 语义 :
cinvoicecustid不是随机字段名,是"发票上的开票客户主键",指向bd_customer.pk_customer - 规则 :物料在
bd_bom.FK_PRODUCT位置→产成品;在FK_INVENTORY位置→原料 - 约束 :
dws_inventory_daily(日粒度)和dws_sales_production_month(月粒度)不能直接JOIN - 推理:库存可销天数<安全库存天数→黄色预警;<=0→红色预警
这些ER图表达不了,但恰恰是AI最容易错的地方。
四层结构
最终产出是一份832行的Markdown本体文件,四层结构。
第一层:概念层
把业务世界的东西分类:
| 类别 | 含义 | 数仓对应 | 数量 |
|---|---|---|---|
| 业务实体 | 长期存在的主数据(客户/物料/组织/仓库...) | DIM层 | 19个 |
| 业务事件 | 经营活动产生的单据(订单/发票/工单/凭证...) | DWD层 | 18个 |
| 分析对象 | 为决策构建的派生概念(客户价值/库存预警/评分...) | DWS/ADS层 | 11个 |
每个概念对应具体表名和标识字段。AI提到"客户"时直接定位dim_bd_customer的pk_customer,不用猜。
另外有四棵分类树(物料分类、客户分类、组织结构、会计科目)。有了树形结构AI能做层级推理------知道"220301是2203的子科目",做预收款穿透分析时自动理解科目上下级。
第二层:关系层
AI干活时最常碰到的问题:这两张表能不能关联,用什么字段JOIN。
答案组织成JOIN Map:
erlang
dwd_nc_saleinvoice (销售发票,已退化冗余):
.ORG_ID ≈ dim_org_orgs.pk_org (已冗余ORG_NAME)
.FK_CUSTOMER ≈ dim_bd_customer.pk_customer
.PRODUCT_ID ≈ dim_bd_material.pk_material
.DEPT_ID ≈ dim_org_dept.pk_dept (已冗余DEPT_NAME)
注意: 本表ETL已退化所有维度名称,DWS层直接聚合无需再JOIN DIM
dwd_gl_prepayment (预收凭证):
.PK_ORG → dim_org_orgs.pk_org
.FK_CUSTOMER → dim_bd_customer.pk_customer
.ACCOUNTCODE → dim_bd_account.CODE
注意: 无DIRECTION字段,通过DEBITAMOUNT/CREDITAMOUNT区分借贷建这张Map时踩了个大坑:项目里命名风格不统一 。早期建的销售宽表用ORG_ID,后面的采购/生产表用FK_ORG,预收款表用PK_ORG,库存表物料字段叫FK_INVENTORY不叫FK_MATERIAL------指向的是同一张维度表。
没有这张地图,AI和人写跨表JOIN几乎必踩坑。这其实是本体建模最值钱的副产品:把隐含的不一致摆到明面上。
| 命名模式 | 适用表 | 组织字段 | 物料字段 |
|---|---|---|---|
| 销售宽表风格 | dwd_nc_saleinvoice, dwd_nc_saleorder | ORG_ID | PRODUCT_ID |
| 标准FK风格 | dwd_pu_, dwd_mm_, dwd_ar_* | FK_ORG | FK_MATERIAL |
| 库存/建议风格 | dws_inventory_daily, ads_*_suggestion | FK_ORG | FK_INVENTORY |
| 预收款风格 | dwd_gl_prepayment | PK_ORG | --- |
关系层还包括跨主题域桥接。8个主题不是孤立的------销售和生产靠"同一物料的销量vs产量"打通,生产和采购靠"BOM展开"打通,销售和应收靠"开票产生应收"打通。写进本体,AI做跨域分析就有路走。
第三层:属性约束层
三类约束,都是AI容易踩的坑:
-
魔术值 ------
enablestate=2才是启用、latest='Y'才是最新版本、pk_customer='~NONE~'表示没挂客户辅助核算。不写明AI永远猜不到。 -
枚举值域 ------
IS_VALID就两个值'是'/'否',DATATYPE就两种'开票'/'订单'。写清楚了AI不会编造第三个值。 -
粒度约束------每张表有且仅有一个粒度定义:
| 表 | 一行代表什么 |
|---|---|
| dwd_nc_saleinvoice | 一张发票的一行明细 |
| dws_customer_value | 一个组织+一个客户+一个月 |
| dws_inventory_daily | 一个组织+一个物料+一天 |
| ads_production_suggestion | 一个组织+一个物料(当日快照) |
粒度不同的表不能直接JOIN。本体里标注了"dws_inventory_daily(日) JOIN dws_sales_production_month(月) = 陷阱",AI读到会主动规避。
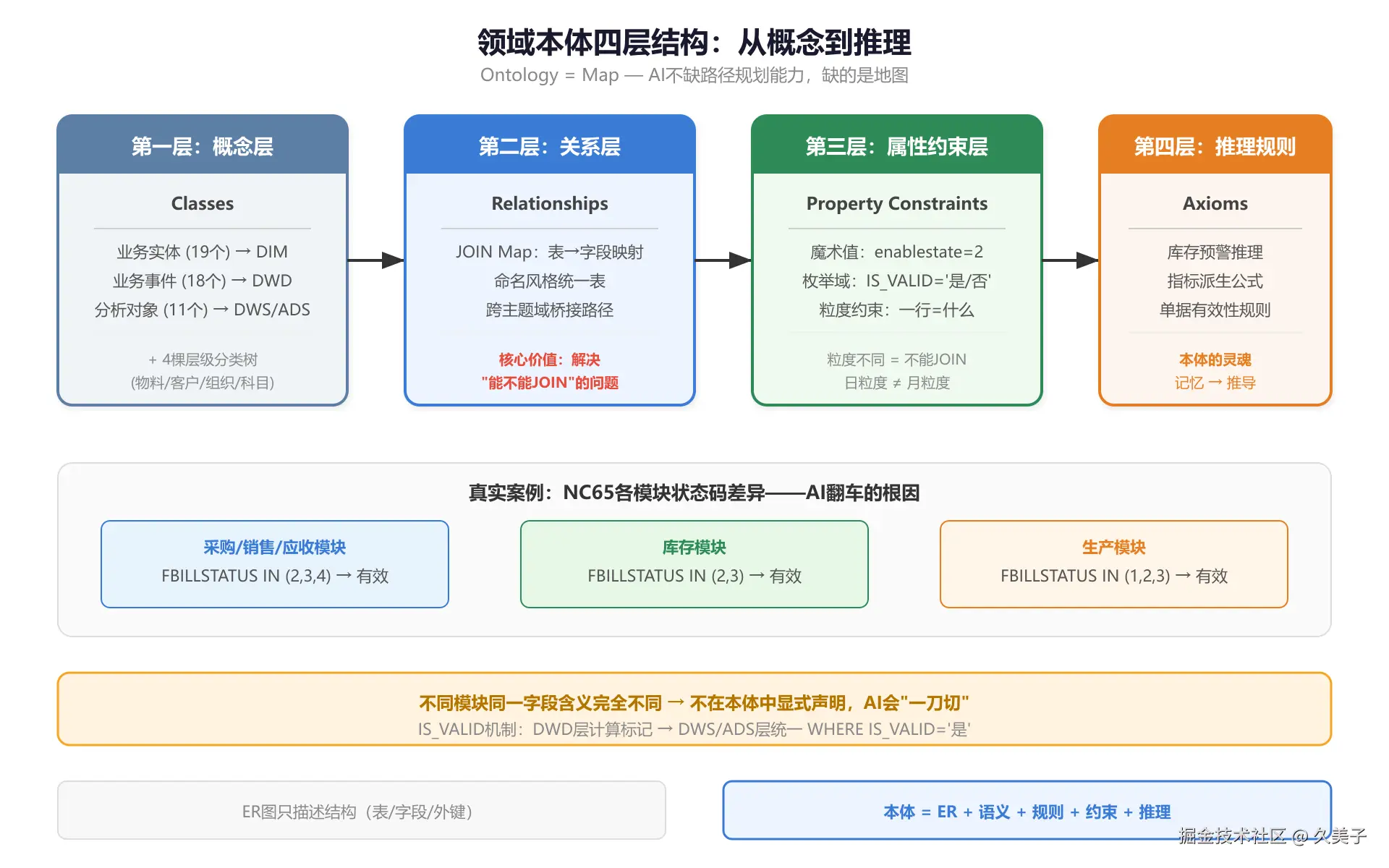
第四层:推理规则层
有推理规则,AI不只是记住知识,还能推导结论。举几个实际用到的:
yaml
# 库存预警状态推理
- IF 可销天数 < 安全库存天数 AND > 0 → 黄色预警(库存偏低)
- IF 可销天数 <= 0 → 红色预警(缺货)
- IF 可销天数 > 安全库存天数 × 3 → 蓝色预警(库存积压)
# 指标派生
- 毛利率 = (销售额 - 销售成本) / 销售额
- 客户经理综合得分 = 业绩×40% + 过程×30% + 回款×30%
- 采购建议量 = Σ(生产建议量 × BOM单位用量) - 原料现存量
# 单据有效性(跨模块差异)
- 采购/销售/应收: FBILLSTATUS IN (2,3,4) → IS_VALID='是'
- 库存: FBILLSTATUS IN (2,3) → IS_VALID='是'
- 生产: FBILLSTATUS IN (1,2,3) → IS_VALID='是'最后这条就是第一章翻车的根因。不同模块状态码含义不同,本体不写清楚AI就一刀切。
本体怎么喂给模型
写完不等于用上。832行全塞进去模型反而抓不住重点,得分场景注入:
- 建模任务 → 喂概念层 + JOIN Map
- 写ETL → 喂属性约束 + 行级过滤规则
- 写DWS/ADS → 喂推理规则 + 粒度约束
具体怎么分层投递,第五章展开。
第四章 文件化Harness
本体解决了"知识是什么",但知识要起作用,得变成模型每次进场都能读到的工程化文件。
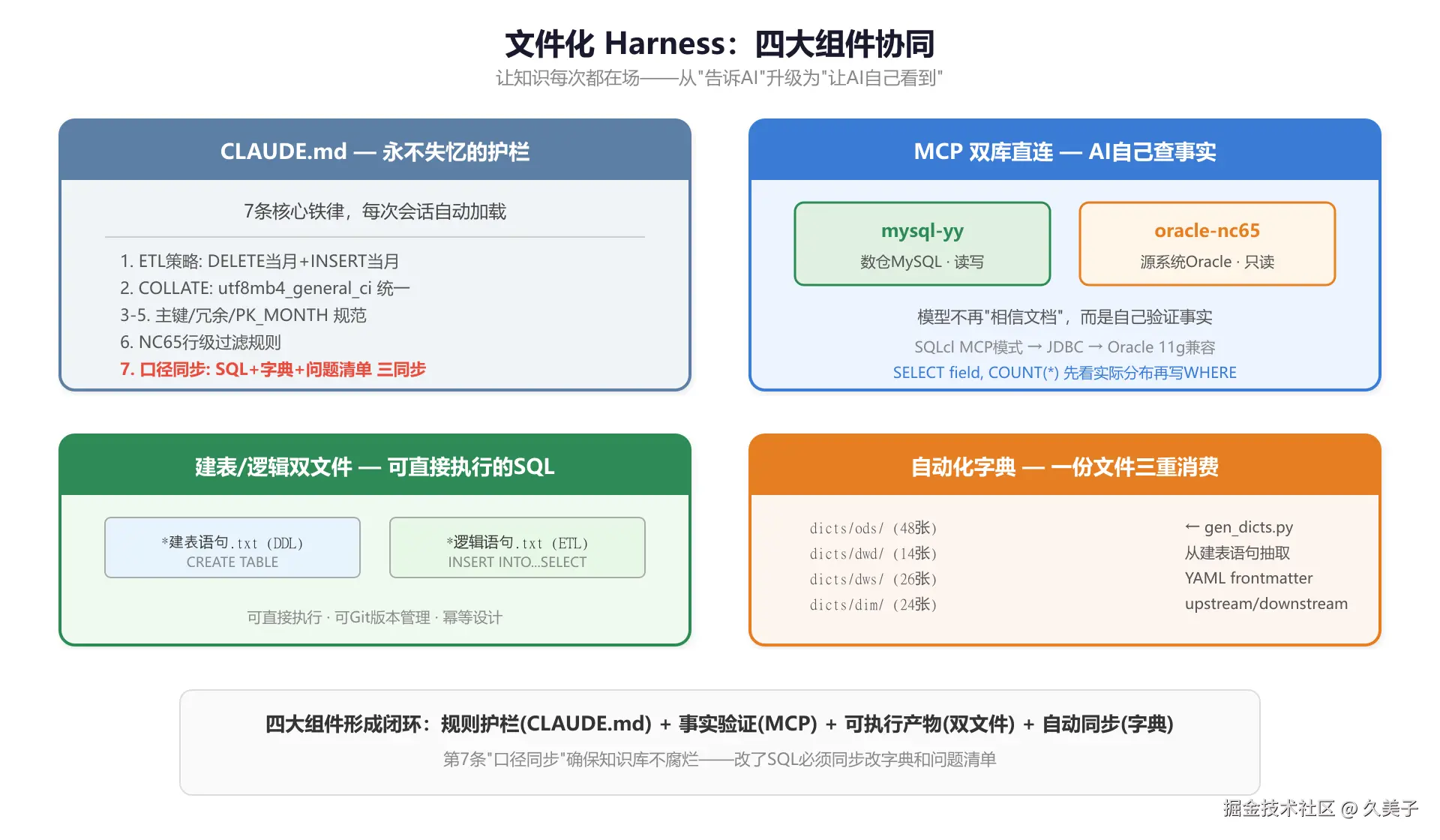
CLAUDE.md
Claude Code支持项目级CLAUDE.md------每次打开项目第一件事读它。我把铁律浓缩成7条写进去:
markdown
# 核心规则
1. ETL更新策略 --- DWS/ADS统一DELETE当月+INSERT当月,禁用TRUNCATE
2. COLLATE --- 全库统一utf8mb4_general_ci,禁止0900_ai_ci
3. 主键 --- DWS/ADS层统一ID AUTO_INCREMENT,业务键降为普通索引
4. DWD必须冗余 --- ORG_CODE/NAME、MATERIAL_CODE/NAME/CLASS/SPEC
5. PK_MONTH --- 所有DWD表必须有PK_MONTH字段 + idx_pk_month索引
6. NC65行级过滤 --- frowtype IN(5,6)费用行排除;isinit='Y'初始化行排除
7. 口径同步 --- 改SQL必须同步改字典和问题清单每次会话开始自动读到,模型不需要记住这些。相当于一个永不丢失的护栏。
第7条特别重要。不加这条约束的话,AI改SQL不改字典的情况会频繁发生,知识库悄悄腐烂,你都不知道什么时候开始歪的。
MCP双库直连
第二个关键组件。配了两个MCP Server:
mysql-yy:连数仓MySQL,读写------AI能直接建表、跑INSERToracle-nc65:连NC65源系统Oracle,只读------AI能查源表结构和数据
效果是模型不只相信文档,还能自己验证。写WHERE之前先SELECT field, COUNT(*) GROUP BY field看实际值分布,不是瞎编。
Oracle这边配的时候踩了坑------NC65是Oracle 11g,Node.js/Python的thin驱动都不支持老版本认证协议。最后用了Oracle官方的SQLcl MCP模式 (sql -mcp启动,基于JDBC),支持所有版本,天然只读。配一次后面不管了。
MCP带来的变化是:从告诉AI世界什么样,变成让AI自己看到世界什么样。
建表/逻辑双文件
每张表对应两个文件:
sql
04_数据建模/01_销售综合/
├── dws_sales_collection建表语句.txt ← DDL (CREATE TABLE)
└── dws_sales_collection逻辑语句.txt ← ETL (INSERT INTO...SELECT)看着简单,解决三个问题:直接能跑(AI生成完整SQL贴DataGrip执行)、全部进Git(口径变更有diff)、DELETE+INSERT保证幂等(重跑不出事,回补改时间条件就行)。
IS_VALID机制
NC65各模块fbillstatus含义不同,这是改不了的现实。DWD层硬过滤吧,将来口径变了没法回补;不过滤吧,DWS聚合每张表都得记不同的状态码规则。
解法是加IS_VALID标记:
- DWD层:不过滤,保留所有行,计算
IS_VALID字段('是'/'否') - DWS/ADS层:统一
WHERE IS_VALID = '是'
具体计算规则写在本体推理规则层里,各模块各取所需。来源为_audit后缀表(NC65审核视图)的DWD表,IS_VALID无条件设'是'。
DWS/ADS的开发者(包括AI)只需无脑写WHERE IS_VALID = '是',不用关心底下各模块状态码差异。
维度退化
DWD层就把维度名称冗余进来。dwd_nc_saleinvoice在ETL时JOIN了11张DIM表,组织名、客户名、物料名直接写入。
好处是DWS聚合直接GROUP BY ORG_NAME,不用再JOIN维度表。对AI来说,DWS的SQL从"JOIN 5张表"简化成"单表GROUP BY",出错概率降一个量级。
代价是DWD表更宽。我们最大的DWD表375万行、月增4万行,扛得住。
自动化字典生成
手写字典必然和建表语句脱节,脱节就是错。写了tools/gen_dicts.py,从建表语句批量抽取字段信息生成标准格式Markdown字典:
r
dicts/
├── ods/ # 48张ODS源表字典
├── dwd/ # 14张DWD明细表字典
├── dws/ # 26张DWS汇总表字典
├── dim/ # 24张DIM维度表字典
└── ads/ # ADS应用层字典每篇字典带YAML frontmatter,记录upstream/downstream血缘:
yaml
---
project: 客户综合
layer: dws
upstream: ["dwd_nc_saleinvoice", "dwd_sa_salecost"]
downstream: []
type: 字典
domain: 客户
governed_by: ["[[某盐业数仓建设规范]]"]
---这些frontmatter不只是装饰------它们是金字塔知识图谱的索引标签,也是血缘图谱的数据源。一份文件,三重消费。
第五章 金字塔知识图谱
全塞进去反而变笨
项目做到这个阶段,已经有134篇表字典、7篇规范、8份主题设计、1份本体、若干案例。全塞进上下文会怎样?
试了。模型反而变笨。窗口再大注意力也会稀释------7条核心规则被淹没在20万字字典里,模型看见了但没注意到。
需要一个调度层:不是堆上去,是根据当前任务只递最相关的那几页。
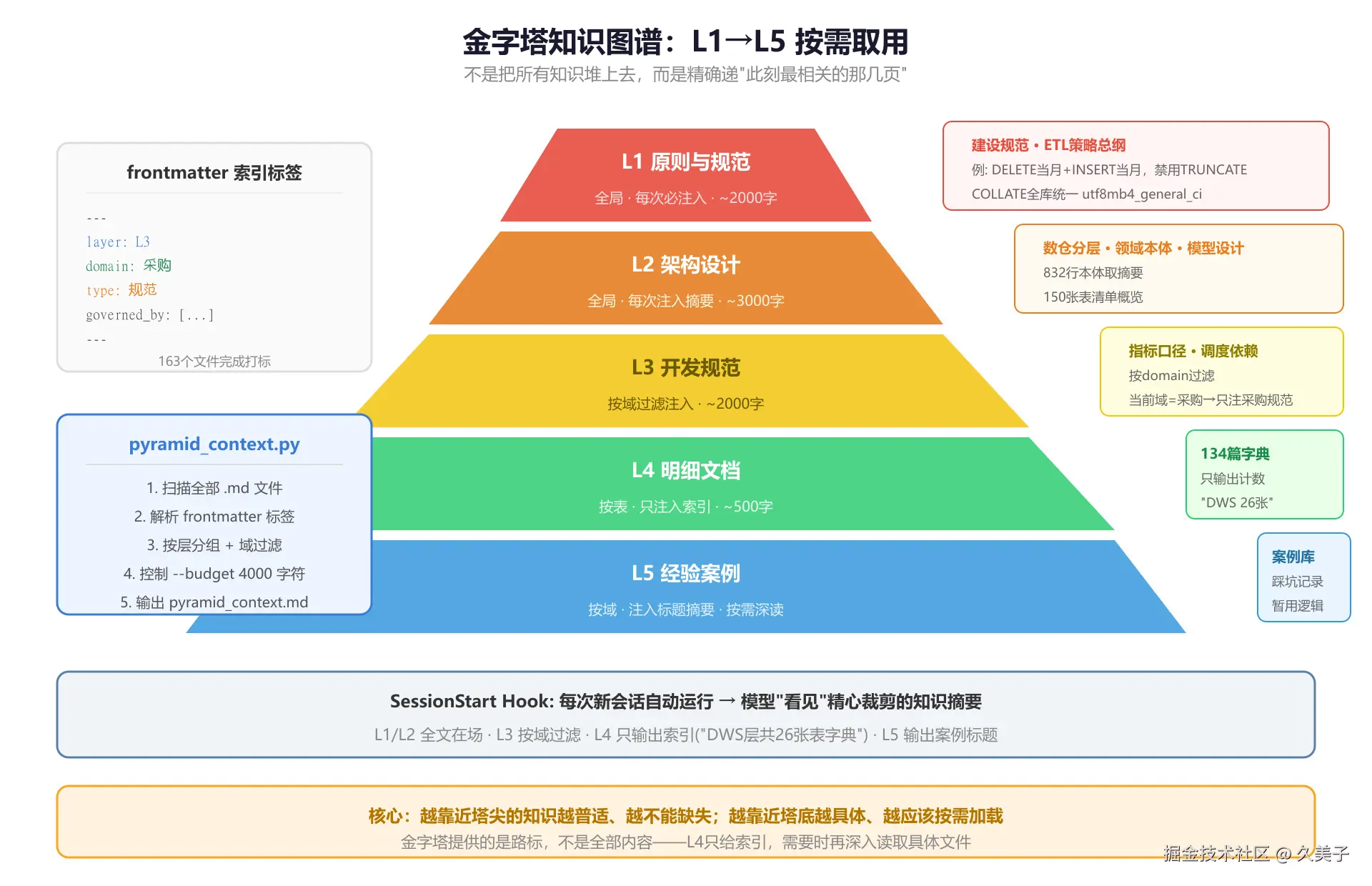
L1→L5 五层模型
按抽象程度分成5层:
bash
/\
/ L1 \ 原则与规范(全局):建设规范、ETL策略总纲
/------\ → 每次会话必定注入,约2000字
/ L2 \ 架构设计(全局):数仓分层、领域本体、模型设计
/----------\ → 每次会话注入摘要,约3000字
/ L3 \ 开发规范(按域):指标口径、调度依赖、MCP配置
/--------------\ → 按当前任务域过滤注入,约2000字
/ L4 \明细文档(按表):134张表字典、字段含义、血缘
/------------------\→ 只注入计数和索引,按需深入,约500字
L5 经验案例(按域):踩坑案例、暂用逻辑、问题清单
→ 注入摘要标题,遇到类似问题时深读越靠塔尖越普适、越不能缺;越靠塔底越具体、越应该按需加载。
frontmatter
技术实现:每篇Markdown顶部加YAML frontmatter:
yaml
---
layer: L3
domain: 采购
type: 规范
project: 某盐业集团
governed_by: ["[[某盐业数仓建设规范]]"]
---layer标层次、domain标业务域、governed_by标受谁治理。加了这些标签,自然语言文档就变成了脚本可检索的结构化对象。
163个文件的打标用Python脚本批量跑的(tools/tag_pyramid_salt.py),基于路径和内容自动推断层级。
pyramid_context.py
核心引擎是tools/pyramid_context.py,配置成Claude Code的SessionStart Hook,每次新会话自动跑:
- 扫全部
.md文件 - 解析frontmatter
- 按层分组:L1-L2输出完整摘要,L3按域过滤,L4只输出计数,L5输出案例标题
- 控制总输出在4000字符以内
- 结果写入
.claude/pyramid_context.md
配置方式:
json
{
"hooks": {
"SessionStart": [{
"type": "command",
"command": "python tools/pyramid_context.py --budget 4000 --output .claude/pyramid_context.md"
}]
}
}每次新会话,模型自动看到一份裁剪过的知识摘要------全局规范一定在,134篇字典只以"dws层共26张表字典"这种索引形式出现,需要时再去读具体文件。
为什么L4只输出计数?134篇字典全文超10万字,全塞进去就回到注意力淹没的问题了。模型知道"这里有字典"就行,需要时自己去dicts/dws/下面找。金字塔提供的是路标,不是全部内容。
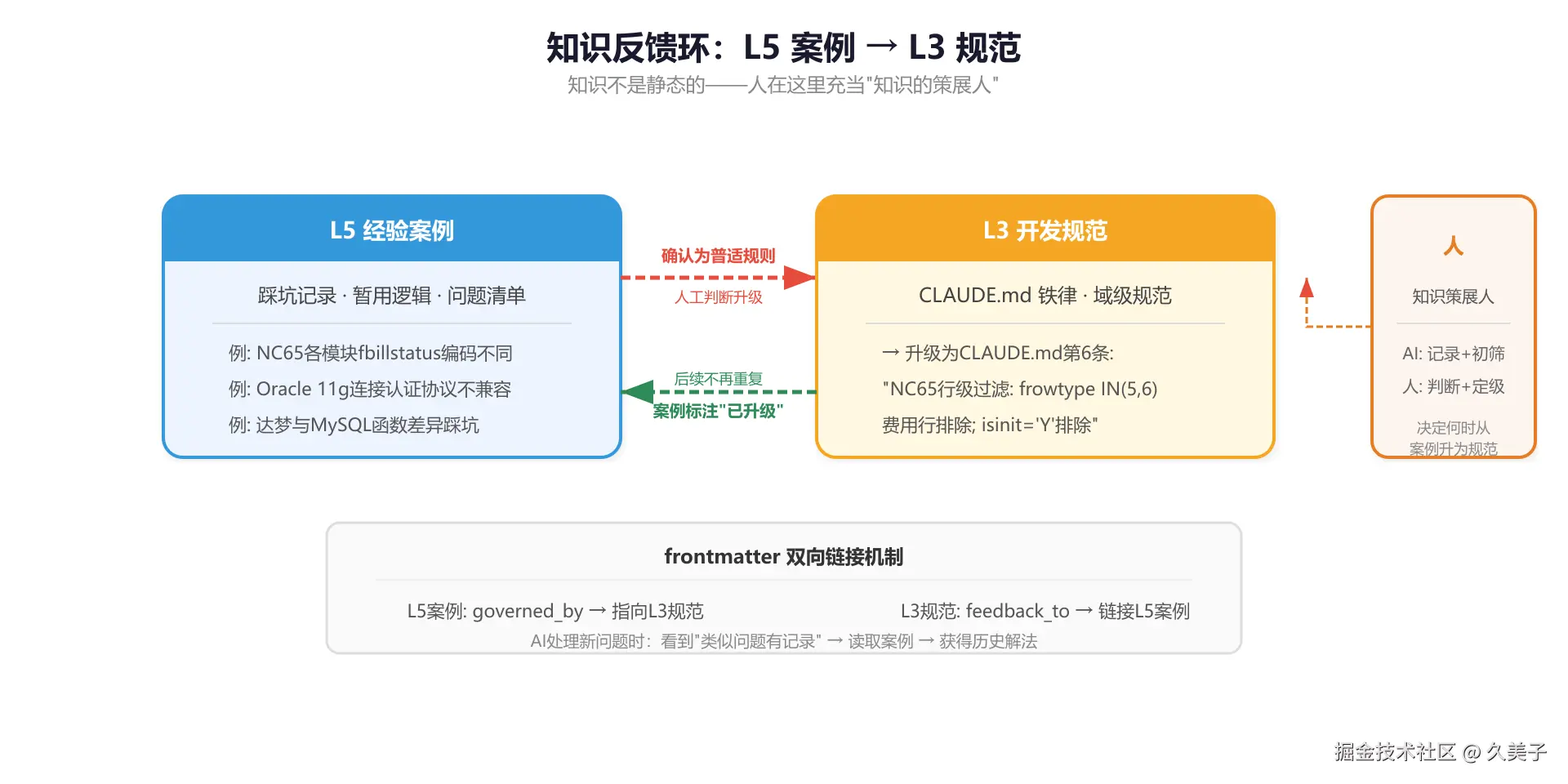
反馈环
知识不是写完就不动了。项目推进中不断踩坑:
- NC65各模块fbillstatus编码不同 → 先记为L5案例
- 确认是通用规则 → 升级为L3规范(写进CLAUDE.md)
- 升级后 → 案例标注"已升级",不再重复提醒
AI处理新问题时能看到案例库有类似记录,读案例拿历史解法。积累到一定程度,我来判断要不要升级为规范。AI记录,人定级。
第六章 规模化复制
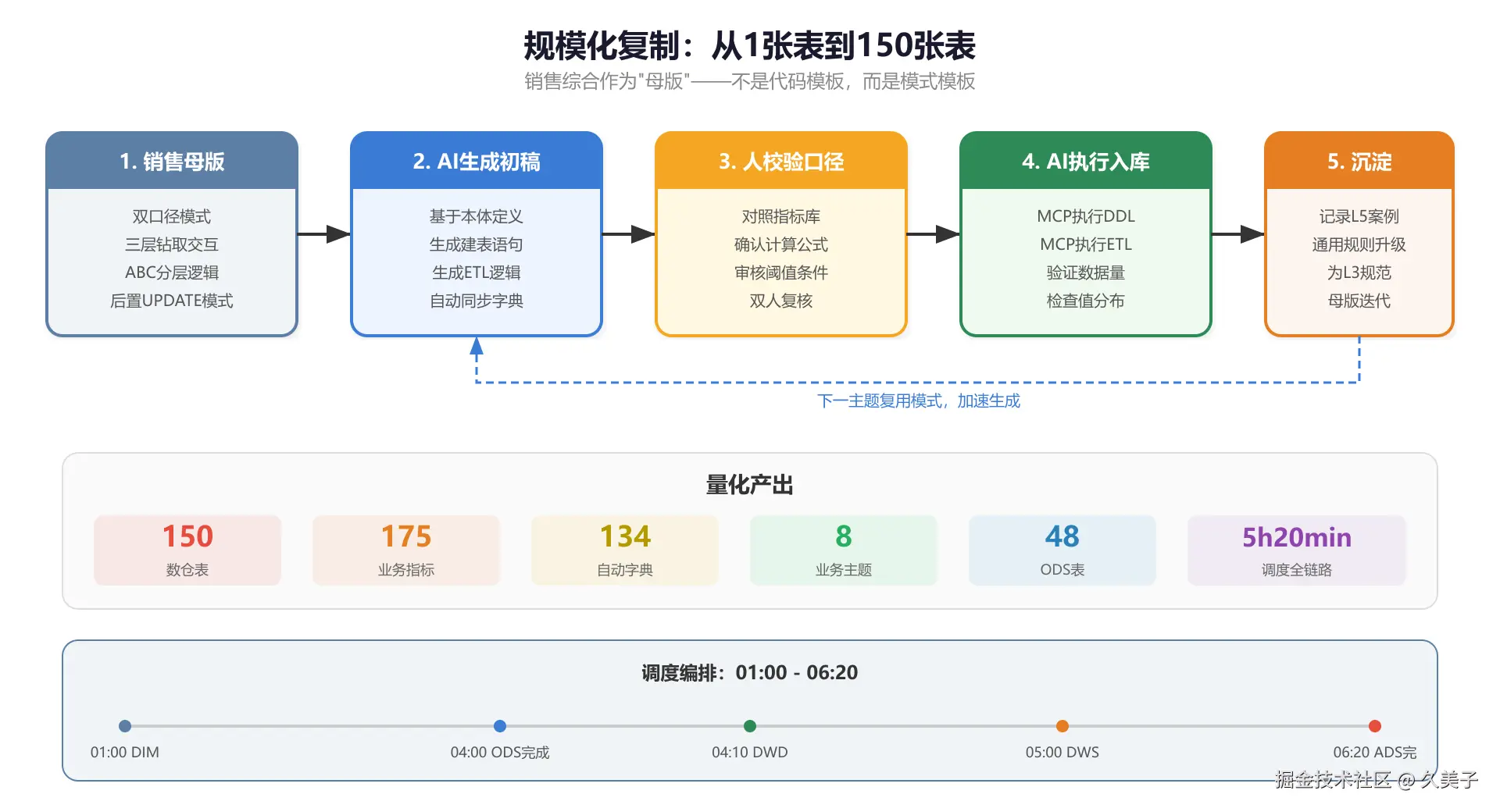
销售综合当母版
8个主题里销售综合最先做完,自然成了后面7个主题的母版。不是代码模板,是模式模板:
| 模式 | 销售综合中的实现 | 可复用性 |
|---|---|---|
| 双口径 | DATATYPE='开票'/'订单',同一张DWS表存两种口径 | 适用于任何有多数据源口径的主题 |
| 三层钻取 | 看板总览→一级报表(聚合)→二/三级(明细穿透) | 所有主题统一交互模式 |
| ABC分层 | 累计占比80%=A/97%=B/余下=C | 适用于客户、物料、供应商分层 |
| 后置UPDATE | INSERT后用UPDATE+窗口函数算环比/同比/标签 | 适用于所有需要跨行计算的DWS |
| DELETE+INSERT | 按PK_MONTH删当月再插入 | 所有DWS/ADS统一策略 |
有了母版+本体+Harness,后续主题节奏就稳了:AI基于本体出初稿 → 人校验口径 → AI通过MCP执行入库 → 人抽样验收(DWS聚合值=DWD明细合计)→ 踩坑沉淀为案例。
一次性规划48张ODS
开工前我和同事从203个指标反推需要NC65哪些模块、哪些表,一次性敲定48张ODS的抽取范围。
事后看这个决策是对的。传统项目可以边做边加ODS,但AI模式下本体需要尽早看到全貌------ODS范围不全,本体的关系层和跨域桥接就不准确,后面每个主题的生成质量都打折。
48张ODS覆盖6大NC65模块:
| NC65模块 | ODS表数 | 覆盖业务 |
|---|---|---|
| IC(库存) | 12 | 出入库、现存量、收发存 |
| SO(销售) | 6 | 订单、发票、发货 |
| PO(采购) | 8 | 订单、到货、入库、结算 |
| AR(应收) | 4 | 应收单、收款单 |
| MM(生产) | 4 | 工单、完工报告 |
| IA(成本) | 8 | 产成品入库、发出商品、明细账 |
| GL(总账) | 2 | 凭证明细 |
| BD(基础) | 4 | BOM、币种、组织 |
调度编排
150张表不能一起跑。按实际行数分了四档,设计了一条01:00-06:20的调度时间线:
makefile
01:00 DIM层全量快照(25张,27万行,3min)
↓
04:00 ── NC65 ODS抽取完成分界线 ──
↓
04:10 DWD第一批(轻中量表,全并行,3min)
04:25 DWD第二批(大表错峰:ar_receivable 375万行、sa_out 174万行...)
04:40 DWD第三批(多表JOIN:saleinvoice 40万行 JOIN 11张DIM)
↓
05:00 DWS第一批(轻量,<1万行输出)
05:15 DWS第二批(中量,1-6万行,含窗口函数)
05:35 DWS第三批(大表:ar_collection 131万行)
05:55 DWS第四批(二级依赖,需前置DWS完成)
↓
06:00 ADS第一批
06:10 ADS第二批
06:20 ADS第三批 ── 全链路完成 ──排批逻辑:大表错峰避IO争抢、二级依赖单独排、每批间留10分钟buffer。调度初版AI可以生成,但最终分档和错峰得人根据实际负载定。
最终产出
| 维度 | 数量 |
|---|---|
| 数仓表 | 150张(ODS 53 + DIM 30 + DWD 26 + DWS 32 + ADS 9) |
| 业务指标 | 175个,覆盖8主题 |
| 自动生成字典 | 134篇Markdown |
| NC65模块字典 | 180个模块(chm→Markdown转换) |
| ETL脚本 | 每表DDL+ETL成对,全部可直接执行 |
| 调度编排 | 01:00-06:20,5小时20分钟全链路 |
第七章 反思
AI为主不等于全自动
跑下来,AI确实干了大部分体力活------DDL生成、ETL编写、字典维护、SQL试错。但三条线人不能让。
业务口径的定义权。 "客户活跃度"30天还是60天算活跃?ABC分类按80%/97%切还是70%/90%切?安全库存定30天还是45天?这些是业务决策,AI只能执行不能拍板。项目里有份"暂用逻辑登记表",专门记临时定的阈值,等业务方确认后再固化。
本体与规范的治理权。 本体写错了后面全错------JOIN Map里一个字段名写岔,后续所有AI生成的SQL都跟着歪。版本管理、重大变更评审,必须人把关。我和同事的分工:我管建模和ETL,他管语义模型和前端报表。每张DWS表完成后两个人手动复核表名、字段名、口径。
验收与上线决策权。 AI跑的SQL人验过才能上线。标准动作是层级间校验:DWS聚合值必须等于DWD明细合计,不等就说明ETL有bug。
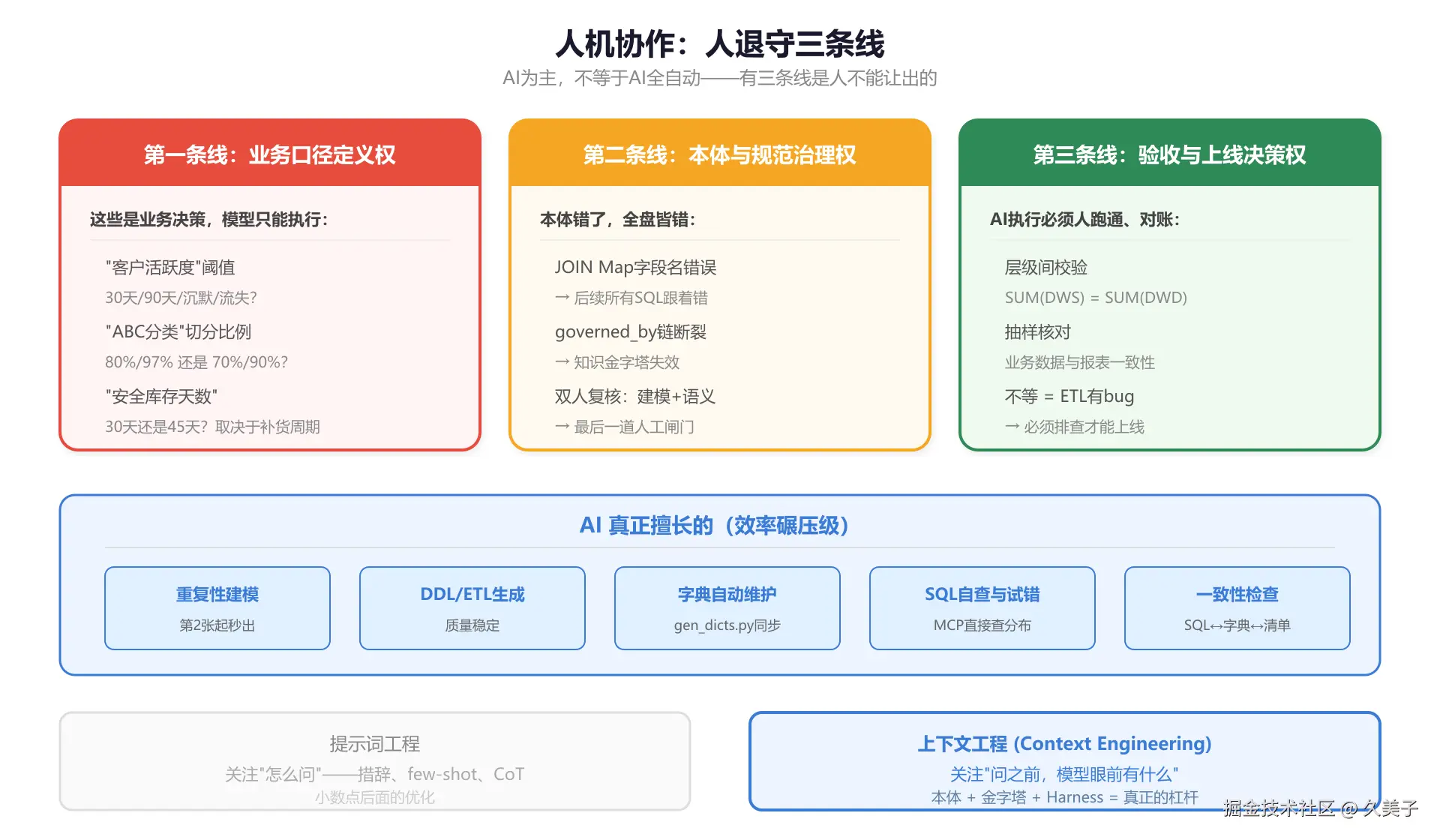
AI擅长的
让出三条线之后,AI在这些地方优势明显:相似结构的DWS表第二张起几乎秒出;给定粒度+指标公式后DDL/ETL生成质量很稳定;改了DDL重跑脚本字典就同步;MCP直接查字段分布验JOIN条件不需要人转发;改了口径自动检查字典和问题清单要不要跟着改。
从提示词工程到上下文工程
做了这个项目之后对"提示词"的看法变了。
很多人还在纠结提示词怎么写------措辞、few-shot、CoT。有用,但在企业级场景只是小数点后面的优化。真正的杠杆是上下文工程:问之前,先把模型面前的世界布置成它能答对的样子。
提示词工程关注怎么问。上下文工程关注问之前模型面前摆着什么。
本文这套东西------本体、金字塔、Harness------本质上都是上下文工程。与其让模型更聪明地猜,不如让世界更清楚地呈现。
适用边界
几个局限:
-
强依赖源系统可被结构化描述。 NC65这种成熟ERP适合------表结构稳定、规则明确。高度非结构化、规则漂移快的业务,本体维护成本会反噬。
-
前期成本高。 写本体、建Harness、转字典、打frontmatter,前期是慢工。回报在后期规模化复用------做到第3个主题时开始感受加速,第5个主题起明显。只做一两张表的话这套投入不划算。
-
模型仍会犯错。 Harness降低幻觉频率和烈度,但不归零。IS_VALID就是"即便错了也不污染下游"的兜底设计。
-
知识库腐烂。 文件不更新=知识过时=误导模型。CLAUDE.md第7条"口径同步"就是为了对抗这个,但它依赖纪律,纪律依赖人。
第八章 小结
NC65的5312张表、看不懂的字段名、各模块不同的状态码、散在文档和人脑里的口径------模型进场时面前是空的。
这套Harness做的事:本体建模把知识变成地图,金字塔分层让知识按需取用,文件化Harness让知识每次都在场。
先别急着让AI写代码。先看看它该看到的东西,你写成文件了没有。
附录
A. 关键术语表
| 术语 | 含义 |
|---|---|
| Harness | 控制AI行为的工程化约束框架(护栏+知识+递送机制的总称) |
| 本体(Ontology) | 领域概念+关系+规则的形式化描述,机器可读可推理 |
| MCP | Model Context Protocol,AI连接外部数据源的标准协议 |
| frontmatter | Markdown文件顶部的YAML元数据,用于知识分层索引 |
| FK_ | 外键字段前缀,指向维度表主键 |
| PK_MONTH | 统计月份字段(yyyy-MM),所有DWD/DWS/ADS必有 |
| IS_VALID | DWD层有效性标记,DWS/ADS层统一过滤'是' |
| DATATYPE | 口径类型标记('开票'=发票确认/'订单'=订单签订) |
| BOM | 物料清单,定义产成品由哪些原料及用量组成 |
| DSO | 应收账款周转天数(Days Sales Outstanding) |
B. 项目文件结构
bash
SALT/
├── CLAUDE.md ← AI操作手册(7条铁律)
├── .mcp.json ← MCP双库连接配置
├── 08_交付文档/
│ ├── 领域本体.md ← 832行领域地图
│ ├── 数据模型设计文档.md ← 分层架构+150张表清单
│ └── 指标口径字典.md ← 175个指标计算公式
├── 04_数据建模/ ← 建表语句+ETL逻辑(成对txt)
├── dicts/ ← 134篇自动生成字典
├── 03_逻辑文档/ ← 调度依赖+问题清单
├── tools/
│ ├── pyramid_context.py ← 金字塔知识组装器
│ ├── gen_dicts.py ← 字典自动生成
│ └── tag_pyramid_salt.py ← frontmatter批量打标
└── docs/business-docs/案例沉淀/ ← L5经验案例库C. 延伸阅读
- 上下文工程:从Prompt Engineering到Context Engineering的范式转移
- 本体建模:dltHub "Ontology Engineering: why it's back, and why agents need it"
- 语义层vs本体:Aloudata "本体论 vs 语义层:两种AI业务语义底座"
- LOM大型本体模型:用友AI Lab "Construct, Align, and Reason"(arxiv 2602.00029)
- Kimball数仓方法论:维度建模经典,本项目的分层设计底座