仓库简介
- 名字: TorchCode
- 定位: "Crack the PyTorch interview" ------ 帮你通过ML/AI岗位的代码面试
- 形式: 基于Jupyter Notebook,每道题有题目描述 + 自动判分
- 题目数量: 40道(覆盖面试最高频的PyTorch手写题)
- 原仓库顺序有点混乱,按照功能模块进行了划分:
- 基础层组件:01, 02, 04, 07, 08, 17, 19
- 注意力机制:05, 06, 09, 10, 11, 12, 14, 23, 24, 25
- 网络构建块:03, 13, 15, 18, 22, 27, 28
- 训练相关:20, 21, 29, 30, 31
- 损失函数:16, 37, 38, 39
- 推理/生成策略:32, 33, 34
- 高效训练/推理:26, 36
- 数据预处理/分词:35
- 基础机器学习:40
基础层组件
1、relu(easy)
f(x)=max(0,x)
解决梯度消失问题;稀疏激活性
def relu(x: torch.Tensor) -> torch.Tensor:
return x * (x > 0).float()
#标准 ReLU
#作为函数直接调用
import torch.nn.functional as F
x = torch.tensor([-1.0, 0.0, 2.0])
output = F.relu(x)
#作为网络层使用
import torch
import torch.nn as nn
output = nn.ReLU(x) 19、GELU (easy)
Gaussian Error Linear Unit,高斯误差线性单元激活函数,在最近的Transformer模型(谷歌的BERT和OpenAI的GPT-2)中得到了应用.
详细介绍:GELU 激活函数详细介绍-CSDN博客
def my_gelu(x):
return x*0.5*(1+torch.erf(x/math.sqrt(2)))2、softmax(easy)
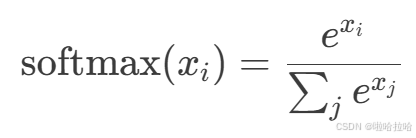
输出值在 0~1 之间且和为 1,多分类网络的最后一层,配合交叉熵损失训练
def my_softmax(x: torch.Tensor, dim: int = -1) -> torch.Tensor:
x_max=torch.max(x,dim=dim,keepdim=True)[0]
return torch.exp(x-x_max)/torch.sum(torch.exp(x-x_max),dim=dim,keepdim=True)-
torch.max(x, ...)返回一个普通元组(values, indices),所以用[0]索引第一个元素。-
values是具体的值,indices是对应位置的索引
x = torch.tensor([1., 3., 2.]) # 方式 A:函数形式 -> 普通元组 result = torch.max(x, dim=0) print(result[0]) # 取出最大值 tensor(3.) print(type(result)) # <class 'torch.return_types.max'>(也是个namedtuple,但常当元组用) # 方式 B:张量方法 -> 命名元组 result2 = x.max(dim=0) print(result2.values) # 取出最大值 tensor(3.) print(result2.indices) # 取出索引 tensor(1) -
dim
沿着哪个维度进行压缩,对于一个形状为 (batch, features) 的张量,dim=0 会消掉 batch 轴,对每一列(跨行)操作;dim=1 会消掉 features 轴,对每一行(跨列)操作。
结果张量的形状 = 原始形状 去掉 这个轴。
Softmax 要让每一行归一化,跨列操作,就是要在一行内部,把几个列的值变成概率。所以需要消灭列轴,在每一行内部分别做计算 → dim=1(或 dim=-1)。
keepdim
是否保持维度(默认 keepdim=False),就是消灭了一个轴,要不要在结果里给这个轴留个"空位"(长度变成1)。核心用途是方便后续的广播运算。
所以凡是计算结果还要放回原张量做元素运算的,就用 keepdim=True。
x = torch.tensor([[1., 2., 3.],
[4., 5., 6.]])
torch.sum(x, dim=1, keepdim=False) # tensor([ 6., 15.]) 形状 [2]
torch.sum(x, dim=1, keepdim=True) # tensor([[6.], [15.]]) 形状 [2, 1]
x = torch.tensor([1.0, 2.0, 3.0])
print(x.shape) #torch.Size([3])
print(x.max(dim=0).values,x.max(dim=0).indices) #tensor(3.) tensor(2)
print(x.max(dim=0,keepdim=True).values) #tensor([3.])直接实现:
#torch.nn.Softmax 是一个类(模块),不是函数,必须先实例化它,再把输入张量传进去调用。
#属于 nn.Module,可以放进 nn.Sequential
ans1 = torch.nn.Softmax(dim=0)(x)
#F.softmax 是函数,可直接调用,必须写dim
ans2 = torch.nn.functional.softmax(x, dim=0)4、LayerNorm(medium)
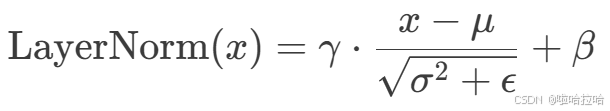
输入 x 形状任意,在最后一个维度上归一化。gamma 和 beta 的大小与最后一个维度相同(即可以广播到 x 形状)。eps 是防止除零的小常数。gamma和beta是缩放参数和平移参数。
def my_layer_norm(x, gamma, beta, eps=1e-5):
mu=torch.mean(x,dim=-1,keepdim=True)
segma=torch.mean((x-mu)**2,dim=-1,keepdim=True)
return gamma*(x-mu)/torch.sqrt(segma+eps)+beta
def my_layer_norm(x, gamma, beta, eps=1e-5):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)#有偏估计
x_norm = (x - mean) / torch.sqrt(var + eps)
return gamma * x_norm + beta由于神经网络训练时每一层的输入是不断变化的,会导致内部协变量偏移,梯度不稳定,易饱和或消失。层归一化就是对每一层的输出沿着特征维度进行标准化,使样本各个特征均值为0,标准差为1,,然后再做可学习的缩放和平移。让每一层的输入分布稳定,训练更平稳、更快。
对于输入张量 (..., D),最后一个维度 D 通常就是特征维度。
-
图像 (卷积后):形状
(batch, channels, height, width),BatchNorm 沿(batch, height, width)对每个 channel 分别求统计量。LayerNorm 则是对每个样本独立 ,把(channels, height, width)整个展平后求均值和方差,然后归一化。 -
序列数据(NLP) :形状
(batch, seq_len, hidden_dim),最后一个维度hidden_dim是一个 token 的特征向量。LayerNorm 对这个向量的所有元素做标准化,即每个 token 独立归一化。
为什么是沿最后一个维度?
因为最后一个维度代表了同一语义单元(一个像素点的所有通道、一个 token 的嵌入)的所有特征值 。LayerNorm 的核心思想是:在一个样本内部,对不同特征之间的分布进行归一化,从而消除特征之间的尺度差异,让每个样本自己内部的特征分布稳定。
相比之下:
-
BatchNorm 是在同一个特征通道上,跨 batch 的不同样本做归一化,消除样本间的差异。
-
LayerNorm 是在同一个样本内,跨所有特征做归一化,消除特征间的差异。
7、BatchNorm(medium)

要求:
-
x: (N, D) ,归一化每个特征在batch中的所有样本。
-
在dim=0上计算均值和方差,unbiased=False(即除以N)。
-
训练模式下:使用batch统计量,并更新running_mean和running_var in-place。更新方式:running = (1 - momentum) * running + momentum * batch_stat
-
推理模式(training=False):使用running_mean和running_var,不更新。
-
必须支持autograd,对于x, gamma, beta;running_mean和running_var应视为buffer,不需要梯度(更新时不涉及梯度计算)
✏️ YOUR IMPLEMENTATION HERE
def my_batch_norm(
x,
gamma,
beta,
running_mean,
running_var,
eps=1e-5,
momentum=0.1,
training=True,
):
if training:
x_mean=x.mean(dim=0)#[D]
x_var=x.var(dim=0,unbiased=False)#[D]#要实现真正的原地修改,必须使用能直接改变张量内容的操作 #running_mean 和 running_var 是统计量,不是可学习参数,不应该参与梯度图。 # PyTorch 的 BatchNorm 也是把 running statistics 当作 buffer 来维护,而不是参数 #running_mean.copy_(new_tensor) → 将 new_tensor 的值复制到 running_mean 的底层存储。 # with torch.no_grad(): # running_mean.copy_((1-momentum)*running_mean+momentum*x_mean) # running_var.copy_((1-momentum)*running_var+momentum*x_var) #running_mean[:] = new_tensor → 切片赋值,也是原地。 # with torch.no_grad(): # running_mean[:]=(1-momentum)*running_mean+momentum*x_mean # running_var[:]=(1-momentum)*running_var+momentum*x_var # running_mean.mul_(1 - momentum).add_(momentum * x_mean) → 原地运算符 _()。 with torch.no_grad(): running_mean.mul_(1-momentum).add_(momentum*x_mean) running_var.mul_(1-momentum).add_(momentum*x_var) return gamma*((x-x_mean)/torch.sqrt(x_var+eps))+beta else: return gamma*((x-running_mean)/torch.sqrt(running_var+eps))+beta # Replace this
这样写不对:running_mean = (1 - momentum) * running_mean + momentum * x_mean
在 Python 中,变量只是指向对象的标签 。右边表达式创建了一个全新的张量 ,然后让左边的变量 running_mean 指向这个新张量。原来的那个张量并没有被修改 ,只是 running_mean 这个标签贴到了新物体上。函数外部的旧张量没有任何变化。
8、RMSNorm(medium)
均方根归一化

沿特征维度求均值
def rms_norm(x, weight, eps=1e-6):
rms_x=torch.sqrt(torch.mean(x**2,dim=-1,keepdim=True)+eps)
return x/rms_x*weight- 不计算均值,避免减法,提高数值稳定性;仅计算平方和,计算量更小
- 适用于 NLP 任务,特别是 Transformer 结构
相比 LayerNorm,RMSNorm 只使用 RMS 进行缩放,不做均值归一化,计算更高效。
PyTorch 的张量运算符(+, -, *, /)默认都是逐元素操作,矩阵乘法必须使用 @、torch.matmul 或 torch.bmm。
广播机制从最后的维度开始比较,如果某个张量缺少维度,就在左边补 1。让不同形状的张量能够自动对齐,然后逐元素运算,无需手动复制。
17、dropout(easy)
p是丢弃的概率
class MyDropout(nn.Module):
def __init__(self,p):
super().__init__()
self.p=p
def forward(self,x):
if self.training:
#torch.rand_like(x) 返回一个与 x 形状相同、数据都在 [0, 1) 区间均匀分布的张量。
#相当于 torch.rand(x.shape),但避免了手动指定形状,代码更简洁且能自动跟随 x 的设备、数据类型
mask=torch.rand_like(x)>self.p
# 对保留的神经元放大 1/(1-p)倍,训练时的输出期望值与推理时完全相同
return x*mask/(1-self.p)
else:
return x
d=MyDropout(0.5)
d.train()
x=torch.ones(10)
print("train:",d(x))
d.eval()
print("val:",d(x))只要类继承自 nn.Module(或任何有构造函数的类),就必须调用 super().__init__()。
self.training 是 nn.Module 的一个内置布尔属性,自动存在 ,用于标识当前是训练还是评估模式。在自定义的 forward 中,直接通过 self.training 判断即可,无需自己创建。
-
调用
model.train()→self.training设为True -
调用
model.eval()→self.training设为False

注意力机制
5、Softmax Attention(hard)
缩放点积注意力:
对于每个batch,计算(seq_q, d_k) x (d_k, seq_k) -> (seq_q, seq_k),得到attn_logits shape (batch, seq_q, seq_k)。
self-attention (seq_q == seq_k) and cross-attention (seq_q != seq_k)。
def scaled_dot_product_attention(
Q: torch.Tensor, # (batch, seq_q, d_k)
K: torch.Tensor, # (batch, seq_k, d_k)
V: torch.Tensor, # (batch, seq_k, d_v)
) -> torch.Tensor: # (batch, seq_q, d_v)
d_k=Q.size(-1)
weight=torch.softmax(torch.bmm(Q,K.transpose(1,2))/math.sqrt(d_k),dim=-1)
return torch.bmm(weight,V)x.size(dim)可以直接获取某维度的大小,返回int;``x.shape不支持索引,要取某个维度的大小需要写x.shape[0],它返回的还是int,作用一样- 张量计算用
torch.sqrt,纯数值用math.sqrt。 dim=-1表示沿着最后一维(即seq_k方向)做 softmax,使每个 query 对所有 key 的注意力权重和为 1。.transpose只能交换两个维度,.permute(*dims)可以直接指定新维度的顺序torch.bmm是严格批量矩阵乘法,只能输入 3D 张量,形状必须为(b, n, m)和(b, m, p),输出(b, n, p),batch 维度必须完全相等。
@(即 torch.matmul)是通用矩阵乘法,支持任意维度 ≥ 1 的张量 。自动广播:当两个输入的批量维度不完全一致时,会按照广播规则扩展。
-
规则简要概括:
-
如果两个输入都是 1D → 内积(返回标量)。
-
如果一个是 1D 另一个是 2D → 矩阵-向量乘法(返回 1D)。
-
如果都是 2D → 普通矩阵乘法。
-
如果至少一个是 >2D → 执行批量矩阵乘法,将最后两维看作矩阵,前面的所有维度视为批量维度,可广播。
-
6、Multi-Head Attention(hard)
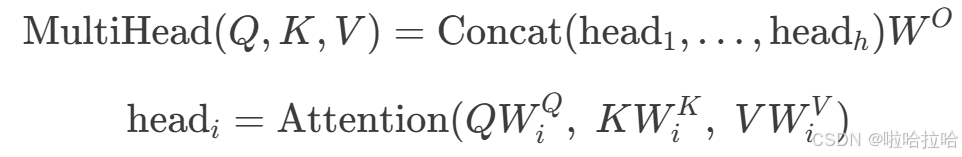
class MultiHeadAttention:
def __init__(self,d_model:int,num_heads:int):
self.d_k=d_model//num_heads #//是整数除法,/是浮点数除法,这里必须是整数
self.d_model=d_model
self.num_heads=num_heads
self.W_q=nn.Linear(d_model,d_model)
self.W_k=nn.Linear(d_model,d_model)
self.W_v=nn.Linear(d_model,d_model)
self.W_o=nn.Linear(d_model,d_model)
def forward(self,Q,K,V):
bs,seq_q,_=Q.shape
seq_k=K.size(1)
q=self.W_q(Q)
q=q.view(bs,seq_q,self.num_heads,self.d_k).transpose(1,2)
k=self.W_k(K)
k=k.view(bs,seq_k,self.num_heads,self.d_k).transpose(1,2)
v=self.W_v(V)
v=v.view(bs,seq_k,self.num_heads,self.d_k).transpose(1,2)
attn_score=torch.softmax(torch.matmul(q,k.transpose(2,3))/math.sqrt(self.d_k),dim=-1) attn=torch.matmul(attn_score,v).transpose(1,2).contiguous().view(bs,seq_q,self.d_model)
return self.W_o(attn).view:把一个张量的维度按指定的新形状重新排列,但是不改变底层数据,与原理的张量共享。transpose会导致内存不连续,需要contiguous()
-
元素总数必须匹配 :
view()要求新形状的元素总数与原张量相同,否则会抛出错误。 -
连续内存要求 :在某些情况下,张量需要是连续的(contiguous)才能使用
view()。如果遇到错误,可以先调用contiguous()再调用view(),例如:tensor.contiguous().view(...)。 -
-1的含义 :
-1表示该维度的大小由其他维度和元素总数自动推断,常用于批量处理或未知大小的输入。torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, kdim=None, vdim=None, batch_first=True)
embed_dim (int): 输入嵌入维度。
num_heads (int): 注意力头的数量。
dropout (float): dropout 概率。默认为 0。
kdim (int): 键向量的维度。默认为 None(与 embed_dim 相同)。
vdim (int): 值向量的维度。默认为 None(与 embed_dim 相同)。
batch_first (bool): 如果为 True,输入输出第一维是 batch。默认为 True。
# 编码器输出作为 K, V
encoder_out = torch.randn(2, 15, 512) # (batch, src_len, embed_dim)
# 解码器输入作为 Q
decoder_in = torch.randn(2, 10, 512) # (batch, tgt_len, embed_dim)
mha = nn.MultiheadAttention(embed_dim=512, num_heads=8, batch_first=True)
output, attn_weights = mha(decoder_in, encoder_out, encoder_out)
print(output.shape) # (2, 10, 512)
print(attn_weights.shape) # (2, 10, 15)9、Causal/Masked Self-Attention(hard)
因果自注意力机制,它是 GPT、Transformer Decoder、语言模型生成任务里最核心的注意力形式。第 i 个 token 只能看见自己和自己之前的 token,不能看见未来 token。语言模型是自回归生成的,Transformer 原论文在 decoder 里使用了 masked multi-head attention,目的也是防止位置看到后续位置,从而保持自回归生成的合法性。
在Causal Self-Attention 中的掩码mask的作用可以总结为以下亮点:
-
防止信息泄漏:确保模型在预测当前标记时不会使用未来信息。
-
支持自回归生成:允许模型一次生成一个文本标记,只关注已经生成的标记。
普通的自注意力这种适合 BERT / ViT / Encoder,因为它们通常可以一次看到完整输入。
def causal_attention(Q, K, V):
seq_q=Q.size(1)
_,seq_k,d_k=K.shape
#torch.triu(..., diagonal=0) 保留主对角线及以上(j >= i),这会屏蔽当前位置(j = i)的注意力,但允许看到自身。
# 我们需要每个 token 能看自己,所以必须屏蔽 j > i,即 diagonal=1
mask=torch.triu(torch.ones(seq_q,seq_k),diagonal=1).bool()
score=torch.bmm(Q,K.transpose(1,2))
#masked_fill只支持布尔变量
score=score.masked_fill(mask,float("-inf"))
weight=torch.softmax(score/math.sqrt(d_k),dim=-1)
return torch.bmm(weight,V)PyTorch 的 scaled_dot_product_attention 里有 is_causal=True 参数,官方文档说明它会使用 causal masking;当 mask 是方阵时,本质上就是下三角注意力结构。
out = F.scaled_dot_product_attention(
q, k, v,
is_causal=True
)masked_fill 用于根据布尔掩码将指定位置替换为给定值。
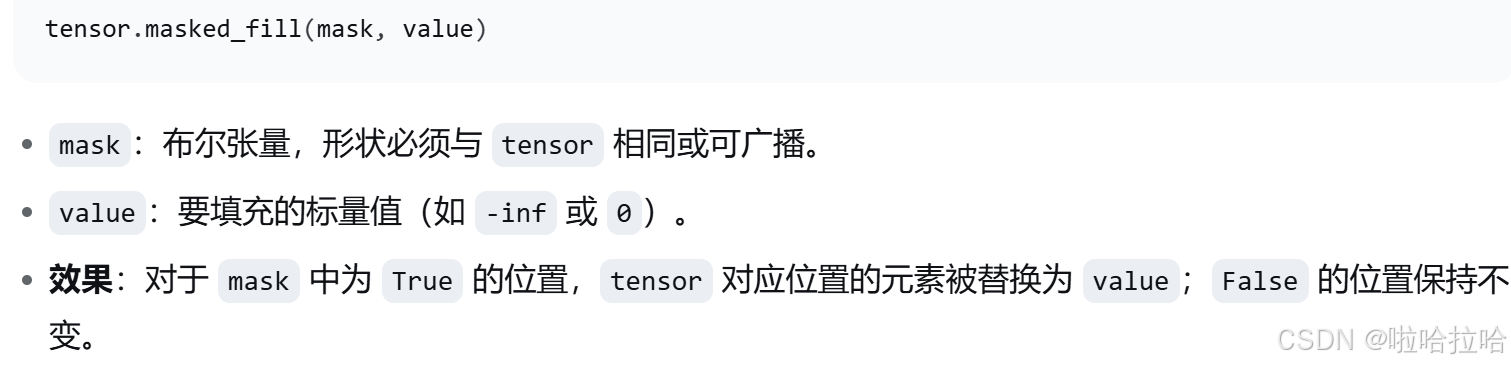
torch.triu 是 upper triangle (上三角矩阵),用于提取矩阵的上三角部分。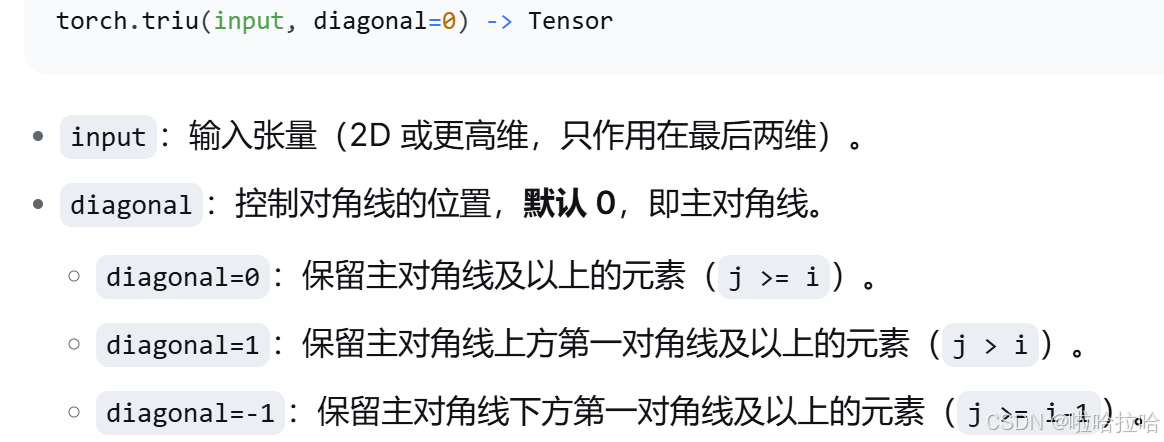
10、Grouped Query Attention(hard)
分组查询注意力
当 num_kv_heads == num_heads 时,repeat_interleave 次数为 1,KV 头数不变,行为退化为标准多头注意力,且 W_k/W_v 输出维度恰好等于 d_model,与 MHA 一致。GQA 显著减少 K、V 投影的参数量和 KV 缓存大小,是现代大模型(如 LLaMA 2 70B 使用 num_kv_heads=8)的关键优化。
class GroupQueryAttention(nn.Module):
def __init__(self,d_model,num_heads,num_kv_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
assert num_heads % num_kv_heads == 0, "num_heads must be divisible by num_kv_heads"
self.d_model=d_model
self.d_k=d_model//num_heads
self.num_heads=num_heads
self.num_kv_heads=num_kv_heads
self.W_q=nn.Linear(d_model,d_model)
self.W_k=nn.Linear(d_model,self.d_k*num_kv_heads)
self.W_v=nn.Linear(d_model,self.d_k*num_kv_heads)
self.W_o=nn.Linear(d_model,d_model)
def forward(self,x):
bs,seq,d=x.shape
q=self.W_q(x).view(bs,seq,self.num_heads,self.d_k).transpose(1,2)
k=self.W_k(x).view(bs,seq,self.num_kv_heads,self.d_k).transpose(1,2)
v=self.W_v(x).view(bs,seq,self.num_kv_heads,self.d_k).transpose(1,2)
k_reap=self.num_heads//self.num_kv_heads
k=torch.repeat_interleave(k,k_reap,dim=1)
v=torch.repeat_interleave(v,k_reap,dim=1)
score=torch.matmul(q,k.transpose(-2,-1))/math.sqrt(self.d_k)
weight=torch.softmax(score,dim=-1)
attn=torch.matmul(weight,v).transpose(1,2).contiguous().view(bs,seq,self.d_model)
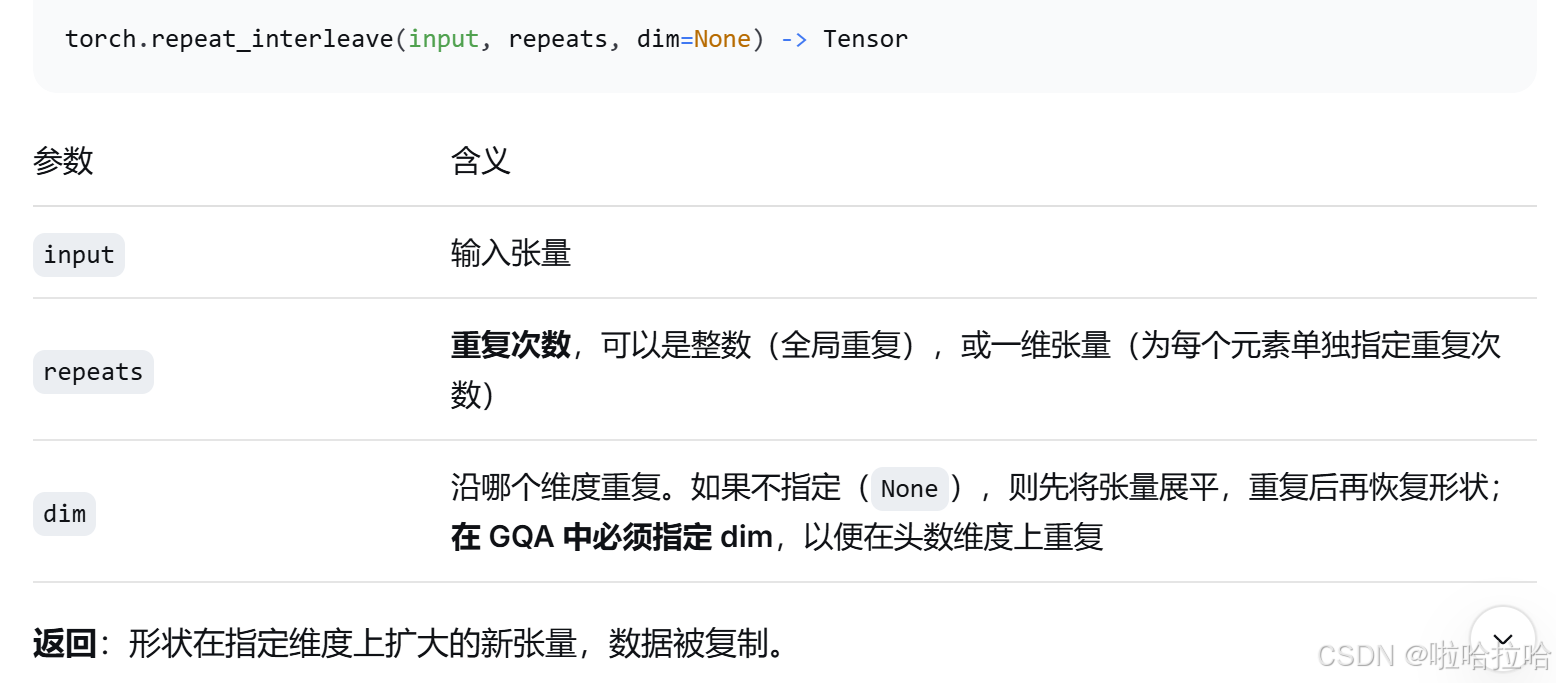
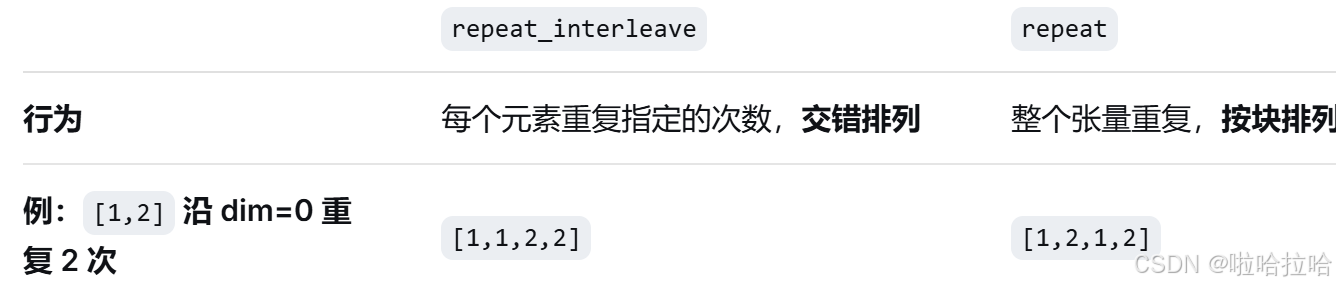
return self.W_o(attn)torch.repeat_interleave 是 PyTorch 中用于沿指定维度重复张量元素的函数,在分组查询注意力(GQA)中,它用于将少量的 KV 头复制多份,以匹配更多的 Q 头。
11、Sliding Window Attention(hard)
滑动窗口注意力
不能使用稀疏注意力库;用 -inf 屏蔽窗口外的位置;window_size=0 时只允许自注意力(输出应该等于 V,因为 softmax 后对角线为 1。
def sliding_window_attention(Q, K, V, window_size):
seq_q = Q.size(1)
seq_k = K.size(1)
scale = math.sqrt(K.size(-1))
scores = torch.matmul(Q, K.transpose(-2, -1)) / scale # (B, seq_q, seq_k)
# 生成设备一致的掩码
row = torch.arange(seq_q, device=Q.device).unsqueeze(1) # (seq_q, 1)
col = torch.arange(seq_k, device=Q.device).unsqueeze(0) # (1, seq_k)
mask = (torch.abs(row - col) > window_size).bool() # (seq_q, seq_k)
scores = scores.masked_fill(mask, float('-inf')) # 广播至 batch 维度
attn_weights = torch.softmax(scores, dim=-1)
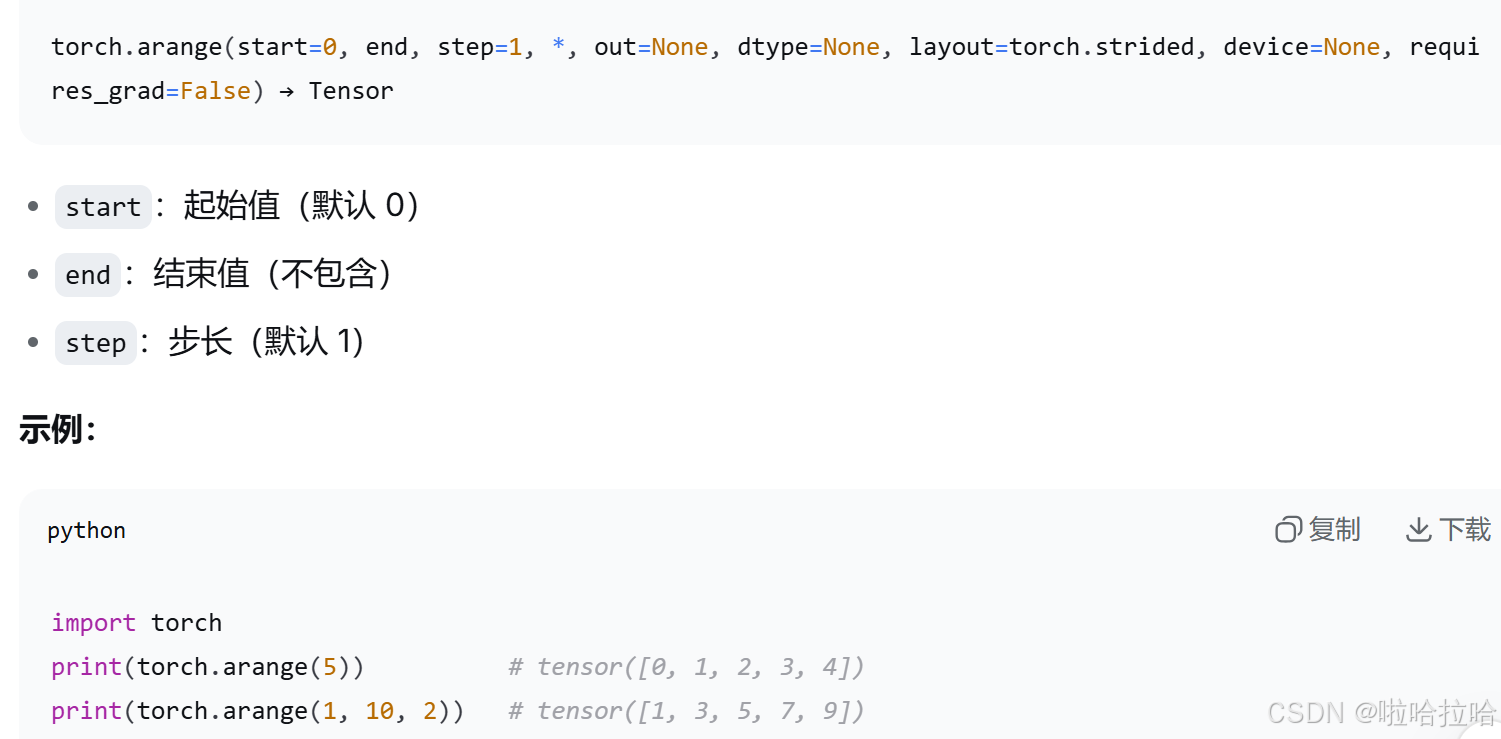
return torch.matmul(attn_weights, V)torch.arange 是 PyTorch 中用来创建等差序列张量的函数
.unsqueeze(dim) 是一个张量方法,用于**在指定位置插入一个大小为 1 的维度,**插入的维度大小为 1,不会改变元素总数,只是重新解释形状。
12、Linear Self-Attention(hard)
线性注意力:相比Softmax Attention,Linear Attention的改进点:
- 替换原始的softmax为其他激活函数,将
设置为elu(⋅)函数,不设置为relu(⋅)是为了避免在x为负时梯度为0。
- Attention的计算由左乘改为右乘,将复杂度由O(n*n*d)降低为O(d*d*n)
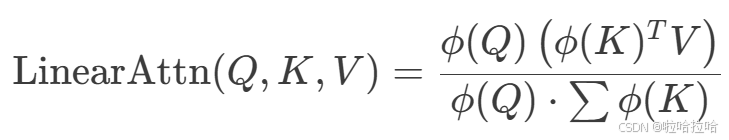
用在了MiniMax模型中
def linear_attention(Q, K, V):
e_q=F.elu(Q)+1
e_k=F.elu(K)+1
shang=torch.matmul(e_q,torch.matmul(e_k.transpose(-2,-1),V))
xia=(e_q*torch.sum(e_k,dim=1,keepdim=True)).sum(dim=-1,keepdim=True)
return shang /xia
14、KV Cache Attention(hrad)
实现带有KV缓存的多头注意力:
-
当 cache=None (prefill, 即第一次前向,输入整个序列或部分序列): 应用因果掩码,返回所有K/V作为缓存。
-
当 cache 提供 (decode, 增量生成): 将新的K/V与缓存的连接,无需因果掩码(因为通常是单token解码,序列长度1)。增量解码必须产生与完整前向传递相同的结果。
-
KV 缓存通常只在推理模式 或微调时冻结历史场景使用。
在标准 Transformer 解码时,每次生成新 token 时需要 重新计算所有之前 token 的 K 和 V ,并与当前 token 进行注意力计算。计算复杂度是 O(n²)。
而 KV Cache 通过存储 K 和 V 的历史值,避免重复计算只需计算 新 token 的 K 和 V ,然后将其与缓存的值结合使用。计算复杂度下降到 O(n)
class KVCacheAttention(nn.Module):
def __init__(self,d_model,num_heads):
super().__init__()
self.d_model=d_model
self.num_heads=num_heads
self.d_k=d_model//num_heads
self.W_q=nn.Linear(d_model,d_model)
self.W_k=nn.Linear(d_model,d_model)
self.W_v=nn.Linear(d_model,d_model)
self.W_o=nn.Linear(d_model,d_model)
def forward(self,x,cache=None):
bs,seq,_=x.shape
q=self.W_q(x)
k=self.W_k(x)
v=self.W_v(x)
q=q.view(bs,seq,self.num_heads,self.d_k).transpose(1,2)
k=k.view(bs,seq,self.num_heads,self.d_k).transpose(1,2)
v=v.view(bs,seq,self.num_heads,self.d_k).transpose(1,2)
if cache:
k_past,v_past=cache
#要把过去的键 k_past 和当前新计算的键 k 在序列维度上拼接
k=torch.cat([k_past,k],dim=2)
v=torch.cat([v_past,v],dim=2)
scores=torch.matmul(q,k.transpose(-2,-1))/math.sqrt(self.d_k)
mask=torch.triu(torch.ones(seq,k.shape[2]),diagonal=(k.shape[2]-seq+1)).bool()
scores=scores.masked_fill(mask,float("-inf"))
weights=torch.softmax(scores,dim=-1)
output=self.W_o(torch.matmul(weights,v).transpose(1,2).contiguous().view(bs,seq,self.d_model))
return output,(k.detach(),v.detach())torch.cat 是 PyTorch 中用于沿指定维度拼接多个张量的函数。张量没有 append 方法

tensor.detach() 是 PyTorch 中的方法,作用:从当前计算图中"剥离"出一个新的张量,新张量与旧张量共享数据,但不再参与梯度计算。
23、Multi-Head Cross-Attention(medium)
交叉注意力不需要因果掩码,因为解码器可以看到所有编码器位置。只需实现标准的缩放点积注意力,无掩码,这里Q和KV的序列长度可能不同。
class MultiHeadCrossAttention(nn.Module):
def __init__(self,d_model,num_heads):
super().__init__()
self.d_k=d_model//num_heads
self.num_heads=num_heads
self.W_q=nn.Linear(d_model,d_model)
self.W_k=nn.Linear(d_model,d_model)
self.W_v=nn.Linear(d_model,d_model)
self.W_o=nn.Linear(d_model,d_model)
def forward(self,x_q,x_kv):
bs,seq_q,d_model=x_q.size()
seq_k=x_kv.size(1)
q=self.W_q(x_q).view(bs,seq_q,self.num_heads,self.d_k).transpose(1,2)
k=self.W_k(x_kv).view(bs,seq_k,self.num_heads,self.d_k).transpose(1,2)
v=self.W_v(x_kv).view(bs,seq_k,self.num_heads,self.d_k).transpose(1,2)
scores=torch.matmul(q,k.transpose(-2,-1))/math.sqrt(self.d_k)
weights=torch.softmax(scores,dim=-1)
attn=torch.matmul(weights,v).transpose(1,2).contiguous().view(bs,seq_q,d_model)
return self.W_o(attn)数据来源不同
-
自注意力:Q、K、V 全部来自同一个输入序列(例如解码器自己之前生成的 token)。
-
交叉注意力:Q 来自解码器(当前要生成的查询),K 和 V 来自编码器(已经处理完的源序列,例如翻译中的原文表示)。这使得解码器在生成每个输出 token 时,都能"查阅"编码器捕获的全局源信息。
掩码不同
-
自注意力(解码器内)通常需要因果掩码,防止当前位置看到未来 token。
-
交叉注意力通常无掩码(或仅 padding 掩码),因为编码器的所有位置都是已知且可被并行访问的,解码器可以自由地关注源序列的任何位置。
24、Rotary Position Embedding(hard)
旋转位置编码:通过旋转变换为向量注入位置信息,使两个向量的内积只依赖于它们的相对位置。
从公式看 Attention 只关心 token 之间的权重关系,不关心它们的顺序。但语言是有顺序的,顺序不同意思完全不同。因此,需要位置编码(Position Encoding, PE)来告诉模型每个 token 在序列中的位置。
绝对位置编码:给每个位置一个固定编号
相对位置编码:关注两个 token 之间的距离,保持(某些)语义的不变性

输入 q, k 的形状 (B, S, D),D 是偶数。
将 D 维特征分成 D/2 对。每一对对应一个旋转角度,角度由位置索引 pos 和维度索引 i 决定。公式为:θ = pos / 10000^(2i/D),其中 i 是配对索引(0,1,...,D/2-1),pos 是序列中的位置。
对每一对 (x0, x1),应用旋转:x0' = x0 * cosθ - x1 * sinθ;x1' = x0 * sinθ + x1 * cosθ
def apply_rope(q, k):
bs,seq,dim=q.size()
pos=torch.arange(seq,device=q.device).unsqueeze(1).float()
group=torch.arange(0,dim,2,device=q.device).float()
freqs=1.0/(10000**(group/dim))
angles=pos*freqs
cos_a=torch.cos(angles)
sin_a=torch.sin(angles)
def rotate(x):
x1,x2=x[...,0::2],x[...,1::2]
return torch.stack([x1*cos_a-x2*sin_a,x1*sin_a+x2*cos_a],dim=-1).flatten(-2)
return rotate(q),rotate(k)25、Flash Attention(hard)
不是一种新的注意力机制,更高效地计算标准 attention 的 GPU 算法,算出来的结果仍然是标准 scaled dot-product attention,只是避免显式生成巨大的 N × N 注意力矩阵,从而显著节省显存并加速长序列训练/推理
实现一个分块注意力(block/tiled attention)且使用了在线softmax算法;将Q分块,K和V也分块,对于每个Q块,我们遍历所有K/V块。
online softmax 是不需要一次性看到所有分数,而是可以一块一块读入分数,并动态更新最终 softmax 所需的信息。
online softmax 做的就是这件事:新块来了,更新全局最大值,把旧结果按新最大值重新缩放,加上新块的贡献。它维护两个核心量:m = 当前见过的最大值,l = 当前 softmax 分母
FLOPs 指 floating point operations,也就是浮点运算次数,= 算了多少次乘法、加法。
torch.full:创建指定形状的张量,所有元素都等于 fill_value

网络构建块
3、linear layer(medium)
实现简单的全连接线性层
-
输入
x:形状(batch_size, in_features) -
输出
y:形状(batch_size, out_features) -
偏置
b:形状(out_features,),自动广播到每一行 -
权重W:形状(out_features, in_features)
requires_grad:默认是False,当希望这个张量是可训练的参数,即需要 PyTorch 自动计算它的梯度,并在优化器里更新它的值时,必须设为True
torch.randn(*size) 生成一个服从标准正态分布 N(0, 1) 的随机张量。
@ 是 Python 的矩阵乘法运算符,等价于调用 torch.matmul(a, b)。
class SimpleLinear:
def __init__(self,in_features,out_features):
std=1.0/math.sqrt(in_features)#标准差
self.weight = torch.randn(out_features, in_features, requires_grad=True) * std #标准正太分布,均值 0,标准差为std
self.bias = torch.zeros(out_features, requires_grad=True)
def forward(self,x):
return x@self.weight.T+self.bias
layer=SimpleLinear(3,4)
print(layer.weight)
print(layer.bias)
print(layer.forward(torch.randn(2,3)))广播机制:
广播(Broadcasting) 是 PyTorch/NumPy 对不同形状的张量进行逐元素运算时,自动扩展维度使形状兼容的规则。广播不复制数据,是高效的内存视图操作。
核心步骤:
-
从最后一个维度向前比较两个张量的形状。
-
如果维度相等,或其中一个为 1,则兼容(该维度可以复制扩展)。
-
如果某个张量缺少维度,会在前面补 1。
-
然后各自在长度为 1 的维度上复制,最后进行逐元素操作。
13、GPT-2 Transformer Block(hard)
GPT-2 的 Transformer Block 可以理解为一个只包含 decoder 结构的 Transformer 层。
输入 x→ LayerNorm→ Causal Self-Attention→ 残差连接→ LayerNorm→ MLP / FFN→ 残差连接→ 输出 x
也就是:x = x + causal_self_attention(layer_norm_1(x));x = x + mlp(layer_norm_2(x))
LayerNorm 是在最后一维 C 上做归一化,输出shape不变
GPT-2 的 MLP 是一个两层前馈网络:Linear(C → 4C) → GELU→ Linear(4C → C),它对每个 token 独立作用,不在 token 之间交换信息。
class GPT2Block(nn.Module):
def __init__(self,d_model,num_heads):
super().__init__()
self.d_model=d_model
self.num_heads=num_heads
self.d_k=d_model//num_heads
self.W_q=nn.Linear(d_model,d_model)
self.W_k=nn.Linear(d_model,d_model)
self.W_v=nn.Linear(d_model,d_model)
self.W_o=nn.Linear(d_model,d_model)
self.ln1=nn.LayerNorm(d_model)
self.ln2=nn.LayerNorm(d_model)
self.mlp=nn.Sequential(nn.Linear(d_model,4*d_model),nn.GELU(),nn.Linear(4*d_model,d_model))
def forward(self,x):
bs,seq,_=x.size()
x_ln1=self.ln1(x)
x_q=self.W_q(x_ln1).view(bs,seq,self.num_heads,self.d_k).transpose(1,2)
x_k=self.W_k(x_ln1).view(bs,seq,self.num_heads,self.d_k).transpose(1,2)
x_v=self.W_v(x_ln1).view(bs,seq,self.num_heads,self.d_k).transpose(1,2)
score=torch.matmul(x_q,x_k.transpose(-2,-1))/math.sqrt(self.d_k)
mask=torch.triu(torch.ones(seq,seq),diagonal=1).bool()
score=score.masked_fill(mask,float("-inf"))
weight=torch.softmax(score,dim=-1)
attn=torch.matmul(weight,x_v).transpose(1,2).contiguous().view(bs,seq,self.d_model)
x1=x+self.W_o(attn)
x_ln2=self.ln2(x1)
return x1+self.mlp(x_ln2)15、SwiGLU MLP(medium)
普通 MLP 是"升维 → 激活 → 降维";SwiGLU MLP 是"两路线性升维,其中一路作为门控,二者逐元素相乘后再降维"。
class SwiGLUMLP(nn.Module):
def __init__(self,d_model,d_ff):
super().__init__()
self.gate_proj=nn.Linear(d_model,d_ff)
self.up_proj=nn.Linear(d_model,d_ff)
self.down_proj=nn.Linear(d_ff,d_model)
def forward(self,x):
return self.down_proj(F.silu(self.gate_proj(x))*self.up_proj(x))18、Embedding layer(easy)
在Transformer中,把每个 Token映射到高维向量空间的工作是由嵌入层来实现的。
嵌入层的核心是一个 简单的查找表:
-
输入:一个整数索引(代表某个单词、某个 token 等)。
-
输出:该索引对应的 密集向量(embedding vector)。
class MyEmbedding(nn.Module):
def init(self,num_embeddings,embedding_dim):
super().init()
self.weight=nn.Parameter(torch.randn(num_embeddings,embedding_dim))def forward(self,indices): return self.weight[indices]torch.nn.Embedding(num_embeddings, embedding_dim,
padding_idx=None, max_norm=None, norm_type=2.0,
scale_grad_by_freq=False, sparse=False,
_weight=None, _freeze=False, device=None, dtype=None)
nn.Parameter 是当它被赋值给一个 nn.Module 的属性时,会自动被加入到模的 parameters() 列表中,从而可以被优化器自动跟踪和更新。在嵌入层里,权重矩阵(查找表)需要被训练 ,所以必须用 nn.Parameter 包裹,这样它才能成为模型的一部分,并在训练中不断更新。
22、2D Convolution(medium)
实现2D卷积,不能用F.conv2d或nn.Conv2d,但可以用F.pad做填充,需要支持步幅和填充。
2D 卷积就是用一个小的卷积核,在图像上滑动,对局部区域做加权求和,从而提取局部特征。
对于多通道输入(比如 RGB 彩色图像有 3 个通道,或者中间层的特征图有很多通道),每个卷积核也有相同的通道数,它会在 所有输入通道 上做加权求和,最后输出一个单通道的特征图。如果有多个卷积核,每个核输出一个通道,那么输出就有多个通道。
x:输入张量,形状 (B, C_in, H, W),weight:卷积核张量,形状 (C_out, C_in, kH, kW)
def my_conv2d(x, weight, bias=None, stride=1, padding=0):
bs,c_in,h,w=x.size()
c_out,_,kh,kw=weight.size()
if padding>0:
x=F.pad(x,(padding,padding,padding,padding))
patches=F.unfold(x,kernel_size=(kh,kw),stride=stride)
w_mat=weight.view(c_out,-1)#变成 (C_out, C_in * kH * kW),每一行就是一个卷积核展开后的向量
out=w_mat@patches#把卷积变为矩阵乘法
if bias is not None:
out+=bias.view(1,-1,1)#自动复制到 batch 维度和位置维度,然后逐元素相加。
h_out=math.floor((h+2*padding-kh)/stride)+1
w_out=math.floor((w+2*padding-kw)/stride)+1
out=out.view(bs,c_out,h_out,w_out)
return out
def my_conv2d(x, weight, bias=None, stride=1, padding=0):
if padding > 0:
x = F.pad(x, [padding] * 4)
B, C_in, H, W = x.shape
C_out, _, kH, kW = weight.shape
H_out = (H - kH) // stride + 1
W_out = (W - kW) // stride + 1
patches = x.unfold(2, kH, stride).unfold(3, kW, stride)
out = torch.einsum('bihwjk,oijk->bohw', patches, weight)
if bias is not None:
out = out + bias.view(1, -1, 1, 1)
return outF.pad 是 PyTorch 中用于在张量周围填充的函数,参数顺序是从最后一维开始倒着往前指定的,
对于 4D 输入 (B, C, H, W),我们只想填充最后两维(H 和 W),所以参数是:(pad_W_left, pad_W_right, pad_H_top, pad_H_bottom)
F.unfold 是 im2col 的实现。它接收一个 4D 张量 (B, C, H, W),用大小为 (kh, kw) 的窗口滑动,步长为 stride,在每个位置把窗口内的所有像素(C * kh * kw 个值)拉成一个列向量。
然后将这些列向量拼起来,输出形状为:(B, C * kh * kw, L),其中 L 是输出特征图的总元素个数(H_out * W_out)
27、ViT Patch Embedding(medium)
要求实现一个PatchEmbedding类,继承自nn.Module。输入是图像(B, C, H, W),输出是(B, num_patches, embed_dim)。算法是:将图像切分成非重叠的patch,每个patch大小为patch_size x patch_size,然后将每个patch展平成一维向量(CPP),然后通过线性层投影到embed_dim。
Vision Transformer (ViT) 把图像当作"词序列"来处理。它把一张图像分割成一个个patch,每个块就像 NLP 中的一个 token。然后通过线性投影将每个块映射到一个高维向量(embedding),后续的 Transformer 编码器就能像处理文本一样处理图像。
class PatchEmbedding(nn.Module):
def __init__(self,img_size,patch_size,in_channels,embed_dim):
super().__init__()
self.patch_size=patch_size
self.num_patches=(img_size//patch_size)**2
self.proj=nn.Linear(in_channels*patch_size*patch_size,embed_dim)
def forward(self,x):
bs,c,h,w=x.size()
#直接用 .view() 并不能正确地将图像划分成空间上连续的图像块(patch)。
# 虽然它不会报错,但它产生的序列是错误的,会导致模型无法理解图像的空间结构。
#直接 x.view(B, num_patches, C*P*P),PyTorch 会按照内存顺序把整个张量展平再重新切分。
# 这样得到的每个"块"实际上是从一整行像素中截取的一段,而不是一个空间上连通的方形区域。
#x=x.view(bs,self.num_patches,-1)
x=x.reshape(bs,c,h//self.patch_size,self.patch_size,w//self.patch_size,self.patch_size)
x=x.permute(0,2,4,1,3,5)
x=x.reshape(bs,self.num_patches,-1)
return self.proj(x)
# def forward(self, x):
# # x: (B, C, H, W)
# patches = F.unfold(x, kernel_size=self.patch_size, stride=self.patch_size)
# # patches shape: (B, C*P*P, N) 其中 N = num_patches
# patches = patches.transpose(1, 2) # (B, N, C*P*P)
# return self.proj(patches)
# def forward(self, x):
# x = rearrange(x, 'b c (h p1) (w p2) -> b (h w) (c p1 p2)',
# p1=self.patch_size, p2=self.patch_size)
# return self.proj(x)transpose(dim0, dim1):只能交换两个维度。
permute(*dims) :可以按任意顺序排列所有维度,经过 permute 后张量不再连续,必须用 reshape 或先 .contiguous().view()
如果是多通道 或更大的图 ,比如一张 2×2 的 3 通道图 (RGB),内存顺序是:R_A, R_B, R_C, R_D, G_A, G_B, G_C, G_D, B_A, B_B, B_C, B_D;即先存所有像素的 R,再存所有 G,再存所有 B。
我们希望切成 4 个 1×1 的块,每个块应该是该像素的 RGB 三个值,即:
块 1:[R_A, G_A, B_A]
块 2:[R_B, G_B, B_B]
块 3:[R_C, G_C, B_C]
块 4:[R_D, G_D, B_D]
现在如果写 x.view(1, 4, 3),PyTorch 按内存顺序切:
-
前 3 个数:
R_A, R_B, R_C→ 第一个块[R_A, R_B, R_C],错了! 这根本不是同一个像素的 RGB。 -
接下来的三个数:
R_D, G_A, G_B→ 第二个块
直接 view 会把不同位置的 R、G、B 胡乱拼在一起,因为内存里不同通道的像素是分开存储的,而不是按像素位置交错存储。
所以,正确的方法必须重新排列内存,让每个 patch 的数据在内存里先连续起来,然后再展平。
reshape(B,C,H//P,P,W//P,P) 是把二维坐标 h,wh,wh,w 拆成 patch 坐标和 patch 内部坐标,再通过 permute 把每个二维 patch 聚到一起。
28、MoE(hard)
实现一个 Mixture of Experts 层,具有 Mixtral/Switch Transformer 风格。对输入序列中的每个 token,用 router 选择 top-k 个 expert,然后只让这些 expert 处理该 token,最后把这些 expert 的输出加权相加。
一个典型 MoE 层由两部分组成:Router / Gate:决定用哪些专家,Experts:多个专家网络。输入 token,Router 判断该 token 应该交给哪些专家,只激活 Top-k 个专家,专家输出加权融合,得到最终输出。
Router 是一个小网络,输入 token 表示 xxx,输出每个专家的分数,表示这个 token 对 N个专家的打分。然后经过 softmax得到每个专家的选择概率。如果使用 Top-1 routing,就选择概率最高的专家,如果使用 Top-2 routing,就选择概率最高的两个专家。
Switch Transformer 就是典型的 Top-1 MoE 思路。
MoE 最大的优势是:增加模型参数量,但不同比例地增加计算量。
MoE 最大的问题之一是:Router 可能总是把 token 分给少数几个专家,导致部分专家过载,部分专家几乎不用。所以 MoE 通常会加入 load balancing loss
负载均衡损失的目标是:鼓励 router 尽量均匀地使用不同专家。
class MixtureOfExperts(nn.Module):
def __init__(self,d_model,d_ff,num_experts,top_k=2):
super().__init__()
self.num_experts=num_experts
self.top_k=top_k
self.router=nn.Linear(d_model,num_experts)
self.experts=nn.ModuleList([nn.Sequential(
nn.Linear(d_model,d_ff),
nn.ReLU(),
nn.Linear(d_ff,d_model)
) for _ in range(num_experts)])
def forward(self,x):
bs,seq,dim=x.size()
x_flat=x.view(-1,dim)
logits=self.router(x_flat)
top_val,top_ids=logits.topk(self.top_k,dim=-1)
weights=torch.softmax(top_val,dim=-1)
output=torch.zeros_like(x_flat)
for k in range(self.top_k):
for e in range(len(self.experts)):
mask=(top_ids[:,k]==e)
if mask.any():
output[mask]+=weights[mask,k:k+1]*self.experts[e](x_flat[mask])
return output.reshape(bs,seq,dim)nn.ModuleList 是 PyTorch 提供的一个容器,专门用来装 nn.Module 的子类
tensor.topk(k, dim) 沿指定维度找出最大的 k 个值及其索引,返回一个命名元组 (values, indices)
x_flat[mask]布尔索引只关注第一维(最外层维度)。当用布尔张量索引时,被索引的张量和掩码的维度可以不同 ,掩码的形状必须与被索引张量的第一维长度相同, 结果会返回掩码为 True 的位置所对应的所有行(保持后面的维度不变)。
x = torch.randn(4, 3, 2) # (4, 3, 2)
mask = torch.tensor([True, False, False, True]) # (4,)
y = x[mask] # 形状 (2, 3, 2) --- 保留了第0和第3个"样本"