介绍:
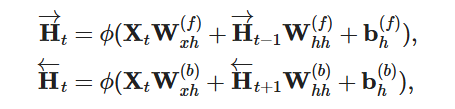
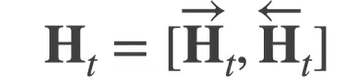


这里换成注意力就是bert了
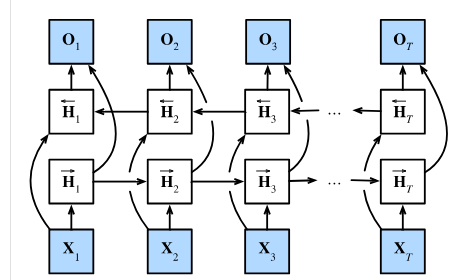
双向意味着两个隐状态层,并行计算隐状态,但是隐状态传播方向相反 可以理解为一次数据反着放,一次数据正着放,然后两个rnn的output用来concat到一起,维度倍增然后加一个输出
这里其实图画为简洁更不好理解了,两个层是分开算输出的,正向层和以前一样,反向层第一输入的X值是一句话的最后一个词,然后到第一个词。然后输出相加时将反向的输出转一下相加就得到了。 因为正反向间的H相互之间没有依赖关系,直接连接就好
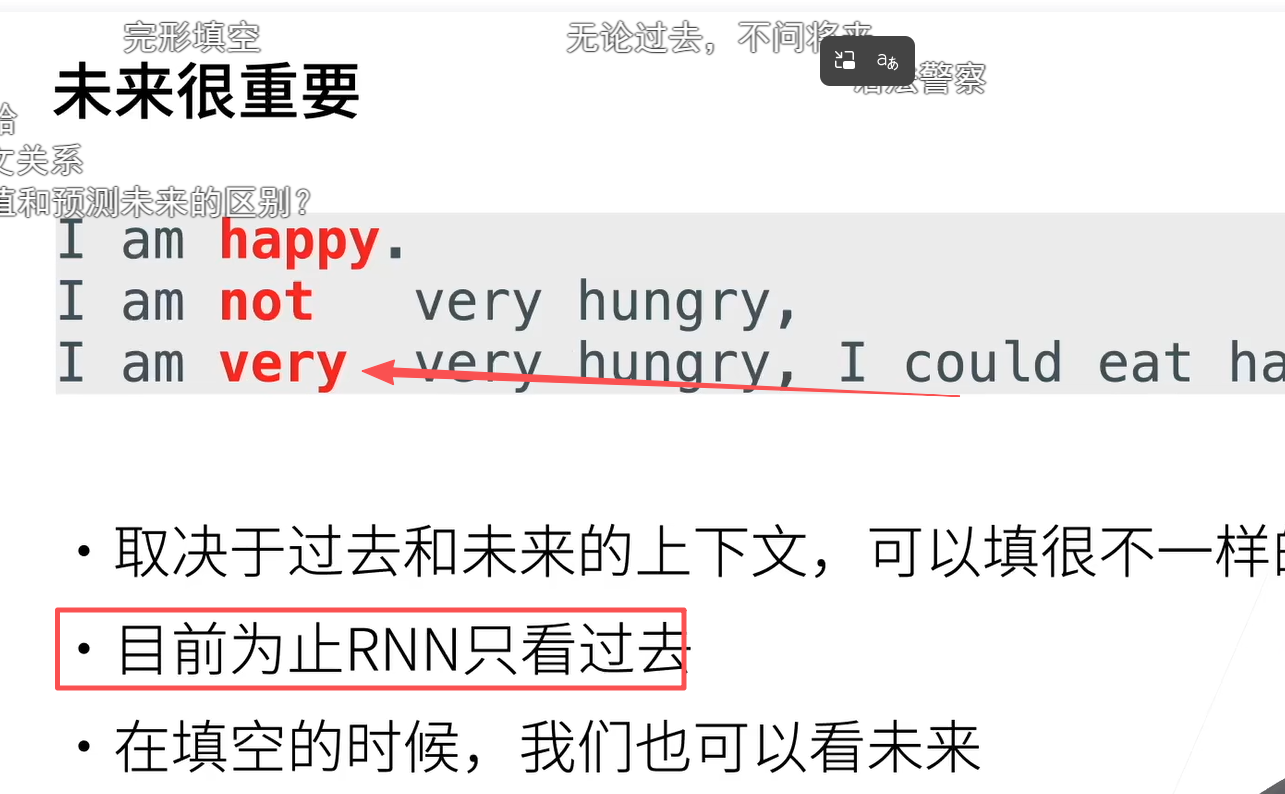
感觉相当是检查, 后面写好了, 再回看前面的 每个方向的H可以独立先计算(并行),最后再每个时刻计算输出
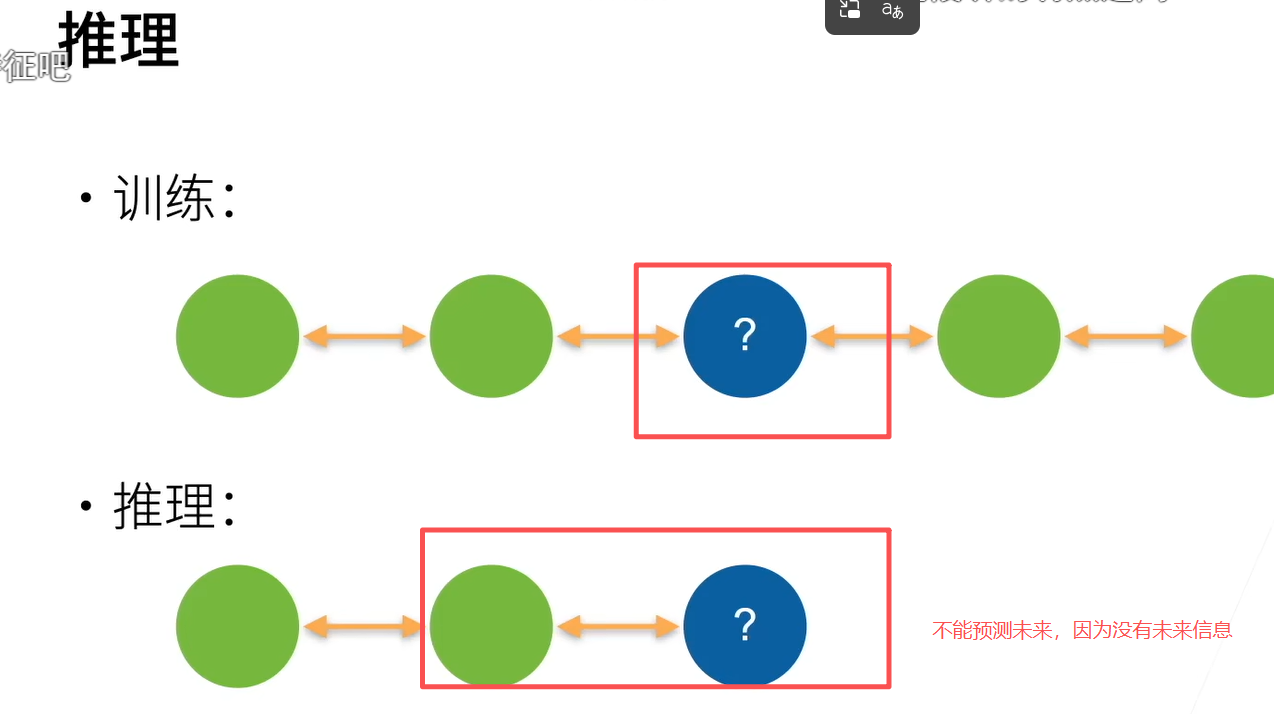
因为未来信息都没知道

这句话里的**"先后计算"** ,说的是:要把一条完整序列全部看完,才能把 Bi‑RNN 的正向链和反向链都"跑完";并且一般实现上会先把正向从头到尾算一遍,再把反向从尾到头算一遍------这两次"整条序列的遍历"在你代码逻辑上有个先后顺序。
实现与应用:
python
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置"bidirective=True"来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)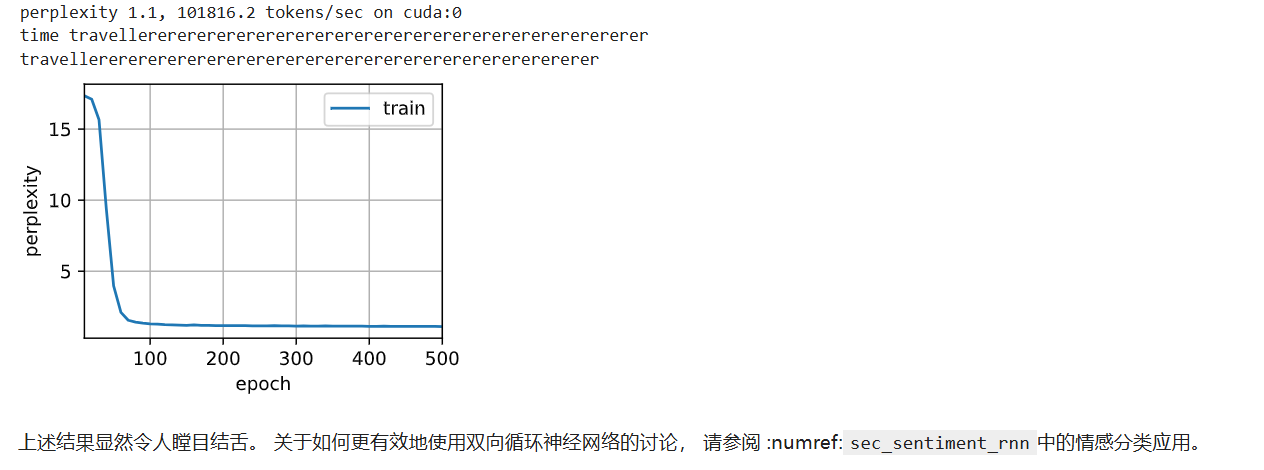
尽管模型产出的困惑度是合理的 可以看到预测结果很差 一般都是应用于翻译 完形填空
双向 RNN 在处理"预测下一个词"(语言模型)这类任务时,天生就存在一个致命的逻辑悖论,这直接导致了模型虽然考试分数高(困惑度低),但实际表现却很离谱的现象。
- 核心原因:双向模型"偷看了答案"
语言模型的核心任务是:给定前面的词,预测下一个词。
-
单向 RNN(正确逻辑):看到"今天天气很",只能根据前面的信息预测"好"、"热"或"冷"。这是符合人类语言习惯的。
-
双向 RNN(作弊逻辑):当它要计算"今天天气很?"中的问号时,它不仅看了前面的"今天天气很",还同时看了后面的上下文。
-
如果后面紧接着出现了"好",双向 RNN 就会利用后面的信息强行锁定前面的预测结果为"好"。
-
如果后面跟着的是"糟糕",它又会把前面的预测改成"糟糕"。
-
后果 :双向 RNN 总是试图让全局序列的概率最大化。它为了达到这个目标,会忽略"因果律",只要后面出现了某个词,它就强行让前面预测那个词。这导致它生成的文本往往是一团乱麻,比如图中的 time travellererererere...(因为模型发现 er这个词在后面高频出现,就疯狂重复预测它),虽然这种重复在统计上可能凑出了较低的困惑度,但完全不符合语法和逻辑。
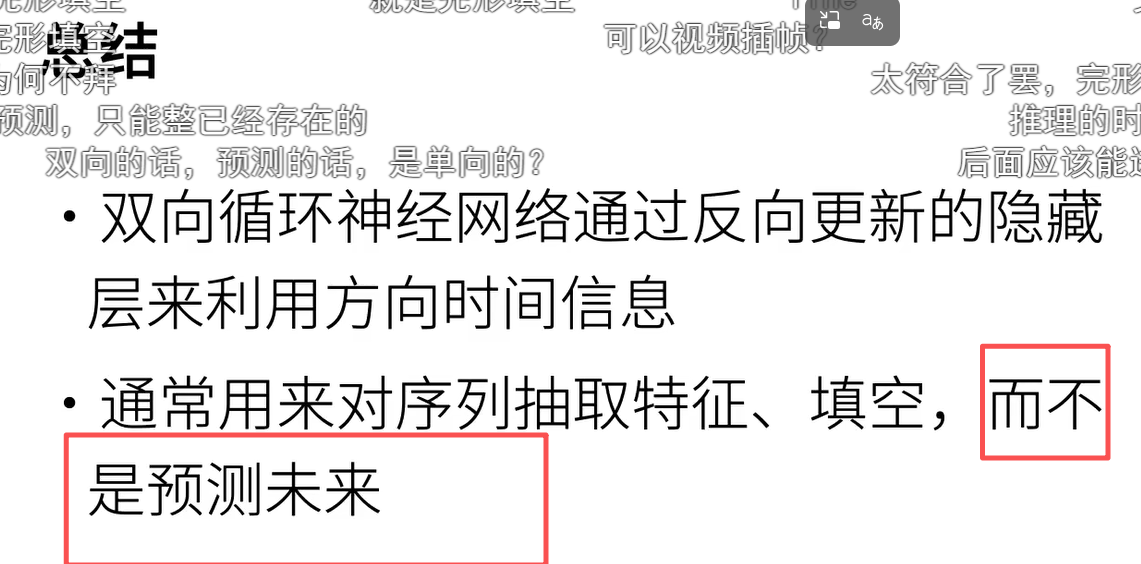
双向循环神经网络的一个关键特性是:使用来自序列两端的信息来估计输出。 也就是说,我们使用来自过去和未来的观测信息来预测当前的观测。 但是在对下一个词元进行预测的情况中,这样的模型并不是我们所需的。 因为在预测下一个词元时,我们终究无法知道下一个词元的下文是什么, 所以将不会得到很好的精度。
具体地说,在训练期间,我们能够利用过去和未来的数据来估计现在空缺的词; 而在测试期间,我们只有过去的数据,因此精度将会很差。 下面的实验将说明这一点。
另一个严重问题是,双向循环神经网络的计算速度非常慢。 其主要原因是网络的前向传播需要在双向层中进行前向和后向递归, 并且网络的反向传播还依赖于前向传播的结果。 因此,梯度求解将有一个非常长的链。
双向层的使用在实践中非常少,并且仅仅应用于部分场合。 例如,填充缺失的单词、词元注释(例如,用于命名实体识别) 以及作为序列处理流水线中的一个步骤对序列进行编码(例如,用于机器翻译)。 在 :numref:sec_bert和 :numref:sec_sentiment_rnn中, 我们将介绍如何使用双向循环神经网络编码文本序列。