AutoPrompt:Prompt 调优全自动,3 条管线覆盖分类/生成/Benchmark,GPT-4 几分钟不到 1 美元,arXiv 论文方法落地
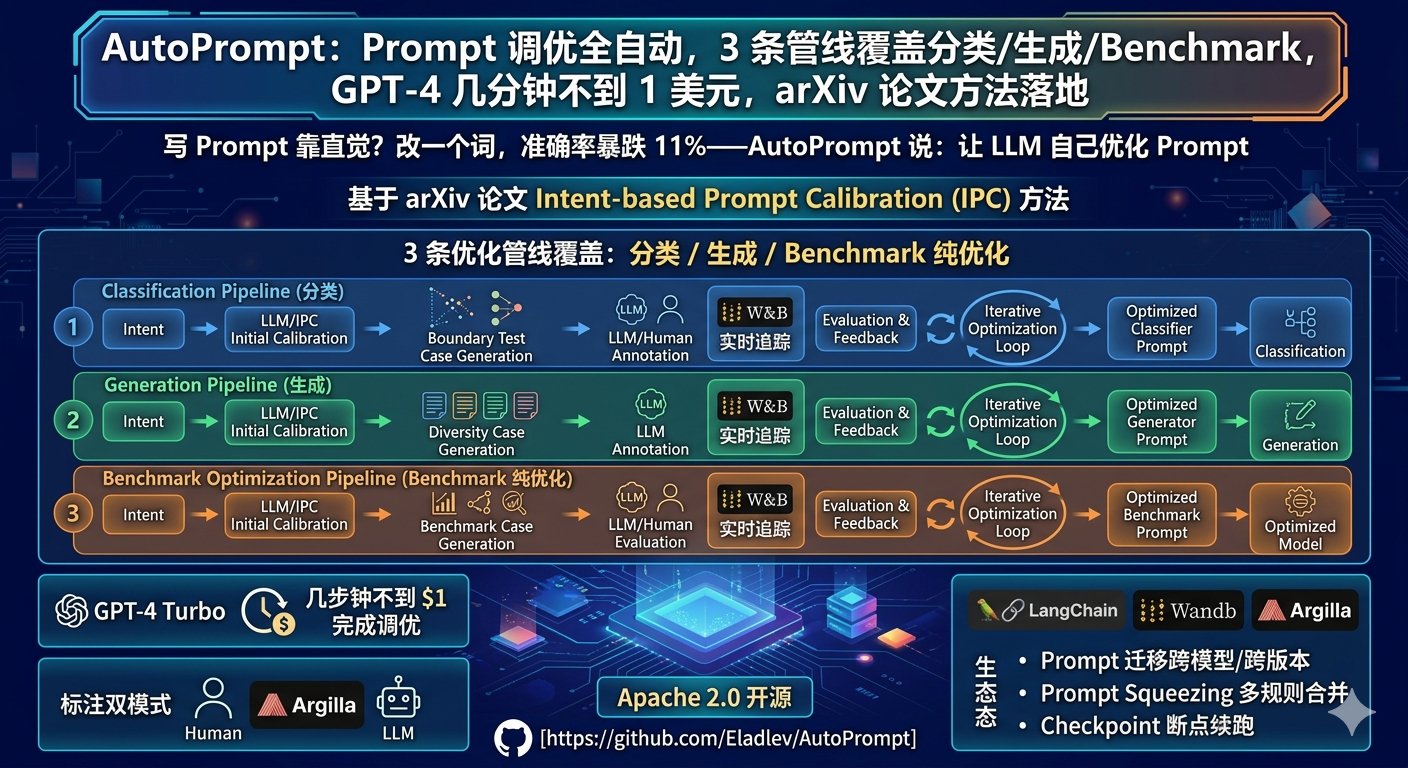
💡 写 Prompt 靠直觉?改一个词,准确率暴跌 11%------AutoPrompt 说:让 LLM 自己优化 Prompt。基于 arXiv 论文 Intent-based Prompt Calibration (IPC) 方法;3 条优化管线:分类/生成/Benchmark 纯优化;自动生成边界测试用例 → 标注 → 评估 → 迭代改进;GPT-4 Turbo 几分钟完成,成本不到 $1;支持人工标注(Argilla) + LLM 标注双模式;W&B 实时追踪优化进度;LangChain/Wandb/Argilla 生态集成;Prompt 迁移跨模型/跨版本;Prompt Squeezing 多规则合并;Checkpoint 断点续跑;Apache 2.0 开源。
📌 目录
[1. AutoPrompt 是什么?](#1. AutoPrompt 是什么?)
[2. Prompt 的脆弱性:一字之差,11% 暴跌](#2. Prompt 的脆弱性:一字之差,11% 暴跌)
[3. 核心方法:Intent-based Prompt Calibration](#3. 核心方法:Intent-based Prompt Calibration)
[4. 三条优化管线](#4. 三条优化管线)
[5. 安装与配置](#5. 安装与配置)
[6. 使用实战](#6. 使用实战)
[7. 标注方案:人工 vs LLM](#7. 标注方案:人工 vs LLM)
[8. 成本控制与预算管理](#8. 成本控制与预算管理)
[9. 监控与断点续跑](#9. 监控与断点续跑)
[10. 核心特性详解](#10. 核心特性详解)
[11. 竞品对比](#11. 竞品对比)
[12. 优缺点与使用建议](#12. 优缺点与使用建议)
[13. 总结](#13. 总结)
1. AutoPrompt 是什么?
AutoPrompt 是一个 Prompt 优化框架,基于 Intent-based Prompt Calibration (IPC) 方法,自动生成高质量、鲁棒的 Prompt,适用于真实生产场景。
一句话总结
AutoPrompt = Prompt 自动优化框架
= 基于 IPC 方法(arXiv 论文)
= 自动生成边界用例 → 标注 → 评估 → 改进
= 3条管线:分类 / 生成 / Benchmark
= GPT-4 几分钟 < $1
= 人工+LLM双标注
= W&B追踪 + Checkpoint续跑
= 让 LLM 自己写出更好的 Prompt
2. Prompt 的脆弱性:一字之差,11% 暴跌
AutoPrompt 用一个真实案例展示了 Prompt 的脆弱性:
Prompt A(准确率 81%)
Review the content provided and indicate whether it includes any significant
plot revelations or critical points that could reveal important elements of
the story or its outcome. Respond with "Yes" if it contains such spoilers
or critical insights, and "No" if it refrains from unveiling key story elements.
Prompt B(准确率 72%)
Review the text and determine if it provides essential revelations or critical
details about the story that would constitute a spoiler. Respond with "Yes"
for the presence of spoilers, and "No" for their absence.
对比
维度
Prompt A
Prompt B
准确率
81% 72%
差异
---
仅改了几个词
性能下降
---
-11%
核心问题:
1. Prompt Sensitivity(敏感度)→ 小改动大影响
论文:https://arxiv.org/abs/2307.09009
2. Prompt Ambiguity(歧义性)→ 同一意图多种表述
论文:https://arxiv.org/abs/2311.04205
→ 手动调 Prompt 靠直觉,不可靠
→ 需要自动化、系统化的 Prompt 优化方法
→ 这就是 AutoPrompt 的价值
3. 核心方法:Intent-based Prompt Calibration
IPC 优化流程
用户输入 迭代优化循环
┌─────────────┐ ┌──────────────────────────────┐
│ 初始 Prompt │ │ │
│ 任务描述 │──────→──────→│ 1. 生成边界测试用例 │
│ (可选)示例 │ │ 2. 标注(人工/LLM) │
└─────────────┘ │ 3. 评估 Prompt 性能 │
│ 4. LLM 建议改进 Prompt │
│ 5. 重复直到预算/迭代上限 │
└──────────────────────────────┘
│
▼
┌─────────────────┐
│ 优化后的 Prompt │
│ + 边界测试集 │
└─────────────────┘
关键创新
创新
说明
合成边界用例 不是随机采样,而是生成"最难判断"的边界样本
联合优化 数据生成 + Prompt 优化同步进行
意图校准 基于"意图"而非"字面"优化,减少歧义
最少标注 少量人工标注即可启动,LLM 辅助标注加速
成本可控 预算限制(USD 或 token 数),避免超支
4. 三条优化管线
管线
入口脚本
适用场景
特点
分类管线 run_pipeline.py文本分类、内容审核、情感分析
生成边界样本 → 标注 → 评估 → 改进
生成管线 run_generation_pipeline.py文本生成、评论撰写、摘要
先训练 Ranker → 再用 Ranker 优化 Prompt
Benchmark 管线 run_benchmark_optimization.py已有标注数据集
跳过生成和标注,纯优化循环
分类管线详解
流程:
初始 Prompt → 生成边界样本 → 人工/LLM 标注
→ 评估当前 Prompt 准确率 → LLM 建议改进 Prompt
→ 下一轮迭代
适用:内容审核、垃圾检测、情感分类、多标签分类
生成管线详解
流程:
初始 Prompt → 训练 Ranker Prompt
→ 生成样本 → Ranker 打分
→ 评估 → 改进 Prompt → 下一轮
关键:生成任务没有"标准答案",需先学习评判标准
→ Ranker 相当于自动化的质量评审
Benchmark 管线详解
流程:
已有标注数据 → predict → evaluate → refine
→ 纯优化循环,无需生成和标注
适用场景:
✅ 已有标注数据集
✅ 想快速迭代
✅ 针对特定数据集微调 Prompt
5. 安装与配置
系统要求
要求
说明
Python
≤ 3.10 (重要!)
LLM
推荐 GPT-4,也支持其他提供商和开源模型
API Key
OpenAI API Key
安装步骤
# Step 1: 克隆项目
git clone git@github.com:Eladlev/AutoPrompt.git
cd AutoPrompt
# Step 2: 安装依赖(三选一)
# 方式 A: Conda(推荐)
conda env create -f environment_dev.yml
conda activate AutoPrompt
# 方式 B: pip
pip install -r requirements.txt
# 方式 C: pipenv
pip install pipenv
pipenv sync
配置 LLM
# config/llm_env.yml
openai_api_key: "sk-xxxxxxxxxxxxxxxxx"
配置标签
# config/config_default.yml
dataset:
label_schema: ["Yes", "No"]
6. 使用实战
场景 1:电影剧透分类(经典分类任务)
python run_pipeline.py \
--prompt "Does this movie review contain a spoiler? answer Yes or No" \
--task_description "Assistant is an expert classifier that will classify a movie review, and let the user know if it contains a spoiler for the reviewed movie or not." \
--num_steps 30
场景 2:电影评论生成(生成任务)
python run_generation_pipeline.py \
--prompt "Write a good and comprehensive movie review about a specific movie." \
--task_description "Assistant is a large language model that is tasked with writing movie reviews."
场景 3:已有标注数据优化(Benchmark 模式)
# 准备数据集 data.csv:
# text,annotation
# "The movie was absolutely fantastic!",Yes
# "Waste of time and money.",No
python run_benchmark_optimization.py \
--dataset path/to/your_data.csv \
--prompt "Is this movie review positive? Answer Yes or No." \
--task_description "Classify movie reviews as positive or negative." \
--labels Yes No \
--num_steps 10 \
--output results.json
Benchmark 模式参数
参数
说明
默认值
--datasetCSV 文件路径(text + annotation 列)
必填
--prompt初始 Prompt
交互式输入
--task_description任务描述
交互式输入
--labels标签体系
Yes No
--num_steps优化迭代次数
10
--output结果输出 JSON
benchmark_results.json
--config配置文件
config/config_benchmark.yml
优化结果
输出内容:
1. 优化后的 Prompt(校准版)
2. 边界测试集(含挑战性样本)
3. 准确率报告
4. 优化历史记录
存储路径:默认 dump 目录
7. 标注方案:人工 vs LLM
方案对比
方案
工具
精度
成本
速度
人工标注 Argilla V1
⭐⭐⭐⭐⭐
高
慢
LLM 标注 GPT-3.5/4
⭐⭐⭐⭐
低
快
Argilla 人工标注配置
# Docker 部署 Argilla V1(注意:用 v1.29.0,不是 latest!)
docker run -d -p 6900:6900 argilla/argilla-quickstart:v1.29.0
# 或者用 HuggingFace Spaces 快速部署
# 复制这个 Space: https://huggingface.co/spaces/Eladlev/test4
LLM 标注配置
# config/config_default.yml → annotator 部分
# 设置 LLM 为标注器(跳过人工标注环节)
选择建议:
首次使用 / 追求精度 → Argilla 人工标注
快速迭代 / 大批量 → LLM 标注
最佳实践 → 先人工标注少量 → 再用 LLM 放大
8. 成本控制与预算管理
成本估算
配置
优化成本
时间
GPT-4 Turbo + 30步
< $1 几分钟
GPT-3.5 标注 + GPT-4 优化
更低
稍长
预算设置
# 在配置文件中设置预算上限
max_usage: 5 # OpenAI: 美元上限; 其他LLM: token数上限
成本控制策略:
1. 设置 max_usage 预算上限 → 超出自动停止
2. 减少 num_steps → 减少迭代次数
3. 用 GPT-3.5 做标注/预测 → 降低标注成本
4. 用 GPT-4 做优化 → 优化质量更高
5. Benchmark 模式 → 跳过生成/标注,最省钱
9. 监控与断点续跑
W&B 实时监控
# 配置 W&B(详见安装文档)
# 实时追踪:
# - 每轮准确率变化
# - Prompt 演进历史
# - 样本生成进度
Checkpoint 断点续跑
# 自动保存最近优化状态到 dump 路径
# 设置输出路径
python run_pipeline.py --output_dump ./my_checkpoint
# 从 checkpoint 恢复
python run_pipeline.py --load_path ./my_checkpoint
断点续跑场景:
✅ 优化中途网络断开
✅ 预算用完,追加预算后继续
✅ 想在已有结果基础上多跑几轮
✅ 迁移到不同机器继续优化
10. 核心特性详解
10.1 Prompt Squeezing(压缩合并)
场景:你有多个规则 Prompt,想合并为一个高效 Prompt
规则1: "检测是否包含剧透"
规则2: "检测是否包含广告"
规则3: "检测是否包含仇恨言论"
→ Squeezing 合并为一个 Prompt:
"分析文本,判断是否包含剧透、广告或仇恨言论"
优势:
✅ 减少推理调用次数
✅ 降低延迟
✅ 统一标注标准
10.2 Prompt 迁移(跨模型/跨版本)
场景:从 GPT-3.5 迁移到 GPT-4,或从 OpenAI 迁移到开源模型
问题:同一 Prompt 在不同模型上表现差异巨大
解决:AutoPrompt 在目标模型上重新校准 Prompt
→ 自动适配新模型的"理解方式"
→ 确保迁移后性能不降
10.3 边界用例生成
核心创新:不是随机采样,而是生成"最难的"边界样本
随机采样:简单样本多,测不出 Prompt 短板
边界生成:专门生成模棱两可、难以判断的样本
示例(剧透检测):
❌ 随机样本:"这部电影太好看了!"(明显无剧透)
✅ 边界样本:"男主在最后的选择让人意外,但也很合理"
(可能剧透也可能不是,真正的边界)
→ 边界样本最能暴露 Prompt 的问题
→ 优化更有针对性
11. 竞品对比
对比维度
AutoPrompt DSPy
PromptPerfect
OpenAI Playground
方法论
IPC(论文支撑) 声明式编程
商业黑盒
手动调试
优化方式
边界用例+迭代校准
编译器式
未知
人工试错
分类优化
✅
✅
✅
✅
生成优化
✅ Ranker
有限
✅
✅
已有数据优化
✅ Benchmark模式
✅
❌
❌
合成数据生成
✅ 边界用例
❌
❌
❌
人工标注集成
✅ Argilla
❌
❌
❌
LLM标注
✅
❌
❌
❌
成本控制
✅ 预算上限
❌
付费
手动
W&B监控
✅
❌
❌
❌
断点续跑
✅ Checkpoint
❌
❌
❌
Prompt迁移
✅
有限
❌
❌
Prompt Squeezing
✅
❌
❌
❌
开源
✅ Apache 2.0
✅ MIT
❌
---
学术论文
✅ arXiv 2402.03099
✅
❌
❌
关键差异化
AutoPrompt vs DSPy:
✅ 专注 Prompt 优化 vs 声明式编程框架
✅ 边界用例生成 vs 无合成数据
✅ 生成管线有 Ranker vs 有限生成支持
✅ 人工标注集成 vs 无
AutoPrompt vs PromptPerfect:
✅ 开源 vs 商业黑盒
✅ 论文方法 vs 未知方法
✅ 预算控制 vs 付费使用
✅ 可自部署 vs SaaS only
AutoPrompt vs 手动调优:
✅ 自动化迭代 vs 手动试错
✅ 系统化评估 vs 靠直觉
✅ 边界用例 vs 随意测试
✅ 可复现 vs 不可复现
12. 优缺点与使用建议
✅ 优点
维度
评分
说明
方法论
⭐⭐⭐⭐⭐
IPC 论文支撑,边界用例创新
管线覆盖
⭐⭐⭐⭐⭐
分类/生成/Benchmark 3条管线
成本控制
⭐⭐⭐⭐⭐
< $1 优化,预算上限可配
标注灵活
⭐⭐⭐⭐
人工(Argilla) + LLM 双模式
可观测性
⭐⭐⭐⭐
W&B 监控 + Checkpoint
生态集成
⭐⭐⭐⭐
LangChain/Wandb/Argilla
学术背书
⭐⭐⭐⭐⭐
arXiv 论文 + 引用格式
⚠️ 注意事项
事项
说明
Python 版本
必须 ≤ 3.10 ,3.11+ 不兼容
Argilla 版本
仅兼容 V1 ,不支持 V2
GPT-4 成本
大量迭代可能累积成本,务必设预算
优化波动
准确率可能波动,需多跑几轮找最优
不保证完美
框架改善可靠性,但不保证100%正确
安装方式
无 pip install,需 git clone
💡 使用建议
先跑 Benchmark 模式 :已有标注数据 → 最快上手设预算上限 :max_usage 防止超支用 GPT-4 优化 + GPT-3.5 标注 :性价比最优多跑几轮 :--num_steps 30,准确率波动是正常的max_samples 配合 :50样本 + 30步 = 25轮纯优化开启 W&B :可视化优化过程,及时发现最优 Prompt用 Checkpoint :长时间优化务必开启,防中断丢失Prompt 迁移先校准 :换模型时重新跑一遍优化
13. 总结
AutoPrompt 是 Prompt 优化领域的学术驱动实战框架 :
📄 IPC 论文方法 :arXiv 2402.03099,边界用例生成 + 迭代校准
🔄 3条管线 :分类 / 生成(Ranker) / Benchmark(纯优化)
💰 超低成本 :GPT-4 Turbo 几分钟 < $1
🎯 边界用例创新 :不是随机采样,而是生成最难的测试样本
👥 双标注模式 :Argilla 人工 + LLM 自动,灵活搭配
📊 可观测 :W&B 监控 + Checkpoint 断点续跑
🔗 生态集成 :LangChain / Wandb / Argilla 无缝对接
⚙️ 高级特性 :Prompt Squeezing 合并 / Prompt 迁移跨模型
📜 Apache 2.0 :完全开源,可商用
推荐指数:⭐⭐⭐⭐⭐
Prompt 工程不该靠直觉。AutoPrompt 用系统化的方法------边界用例生成、迭代校准、量化评估------让 Prompt 优化从玄学变成工程。几分钟、不到1美元,就能得到比手动调优更鲁棒的 Prompt。
📢 项目地址:https://github.com/Eladlev/AutoPrompt
📄 论文:arXiv 2402.03099
标签:#GitHub #AutoPrompt #Prompt优化 #IPC #LLM #PromptEngineering #开源项目 #AI工具