需求
项目上有个对上传的报告做总结和实时提问的功能。
分析
但是目前大模型对文件的处理还达不到秒级别实时处理,也即是每次问答我都要把文件传给大模型。这样性能损耗太大,效率也很低。
因此,考虑到文件是不会轻易改变的,所以就做成异步处理。后台对文件做RAG分片处理。每个分别生成embedding向量。然后通过cosine做余弦相似度检索,再拼接检索的内容到大模型分析。
文件
=》 分片+embedding向量
=》问题转成向量
=》循环处理:cosine(每个分片向量,问题向量)
=》系统提示词(提示词:你是一个文档助手,请跟我给的内容,总结出我的问题。)
+ 检索结果+问题
=》 LLM大模型 =》 流式结果这里测试分片大小用的是500个字符,重叠值是80
int size = 500, overlap = 80;当然还可以设置检索的topK等内容。最终结果还是根据自己项目不断测试,达到满意结果
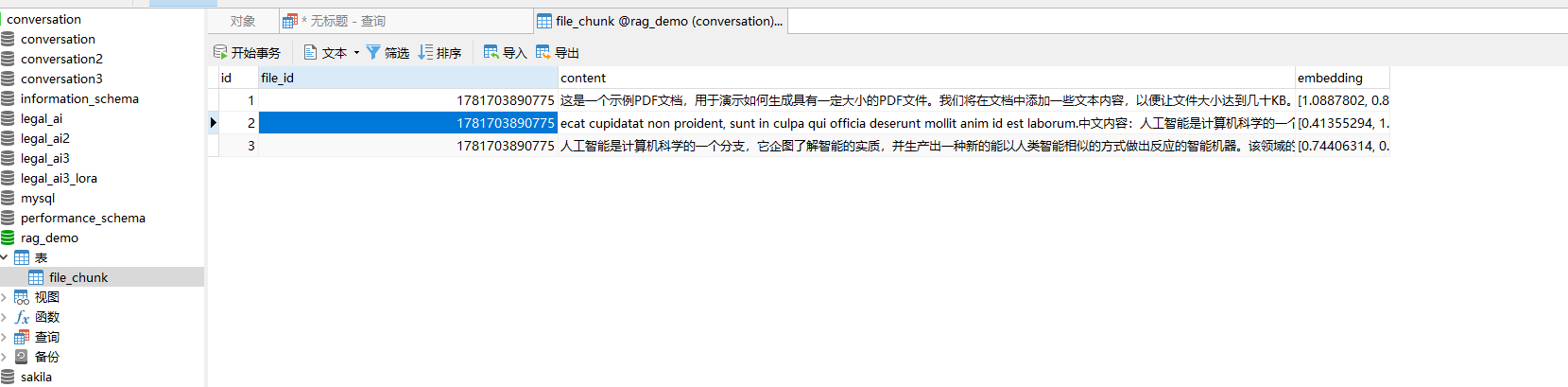
分片结果和向量数据库:
源码地址
https://download.csdn.net/download/csdnliuxin123524/92994992
源码
数据表
CREATE DATABASE rag_demo;
USE rag_demo;
CREATE TABLE file_chunk (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
file_id BIGINT,
content TEXT,
embedding JSON
);代码目录
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>rag-file</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<spring.boot.version>2.7.18</spring.boot.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring Boot -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- JDBC(必须) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- ✅ MySQL 驱动(Java 8 专用) -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<!-- Apache Tika -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>2.9.1</version>
</dependency>
<!-- HTTP -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSON -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>application.yml
server:
port: 8080
spring:
datasource:
url: jdbc:mysql://localhost:3306/rag_demo?useSSL=false&serverTimezone=UTC
username: root
password: root
ollama:
base-url: http://localhost:11434
embed-model: nomic-embed-text
chat-model: qwen:7bRagDemoApplicationpackage org.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableScheduling
public class RagDemoApplication {
public static void main(String[] args) {
SpringApplication.run(RagDemoApplication.class, args);
}
}
package org.example.dao;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Map;
@Repository
public class ChunkDao {
@Autowired
private JdbcTemplate jdbc;
private final ObjectMapper mapper = new ObjectMapper();
public void save(Long fileId, String content, float[] vec) throws Exception {
String sql = "INSERT INTO file_chunk (file_id, content, embedding) VALUES (?, ?, ?)";
jdbc.update(sql, fileId, content, mapper.writeValueAsString(vec));
}
public List<Map<String, Object>> findByFileId(Long fileId) {
return jdbc.queryForList("SELECT * FROM file_chunk WHERE file_id = ?", fileId);
}
}
package org.example.service;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
@Service
public class ChunkService {
/**
* 滑动窗口分片
*/
public List<String> split(String text) {
int size = 500, overlap = 80;
List<String> chunks = new ArrayList();
int start = 0;
while (start < text.length()) {
int end = Math.min(start + size, text.length());
chunks.add(text.substring(start, end));
start += size - overlap;
}
return chunks;
}
}
package org.example.service;
import org.apache.commons.io.IOUtils;
import org.apache.tika.Tika;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.BufferedInputStream;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
/**
* 文件解析服务
* 支持:Word / PDF / TXT / ZIP(内嵌文本)
*/
@Service
public class FileParseService {
private static final Logger log = LoggerFactory.getLogger(FileParseService.class);
private static final Tika tika = new Tika();
/**
* 解析 Word / PDF / ZIP(自动识别)
*/
public String parse(MultipartFile file) throws Exception {
if (file == null || file.isEmpty()) {
log.warn("文件为空");
return "";
}
String filename = file.getOriginalFilename();
log.info("开始解析文件:{}", filename);
// ✅ 关键:复制字节,防止流被消费
byte[] bytes = file.getBytes();
// ZIP 特殊处理
if (filename != null && filename.toLowerCase().endsWith(".zip")) {
return parseZip(bytes);
}
// Word / PDF / TXT
try (InputStream is = new BufferedInputStream(new ByteArrayInputStream(bytes))) {
AutoDetectParser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler(-1); // 不限制大小
Metadata metadata = new Metadata();
parser.parse(is, handler, metadata, new ParseContext());
String content = handler.toString();
log.info("解析成功,文本长度:{}", content.length());
return content;
} catch (Exception e) {
log.error("Tika 解析失败,启用备用解析", e);
return tika.parseToString(new ByteArrayInputStream(bytes));
}
}
private String parseZip(byte[] bytes) throws Exception {
StringBuilder sb = new StringBuilder();
try (ZipInputStream zis = new ZipInputStream(
new ByteArrayInputStream(bytes), StandardCharsets.UTF_8)) {
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null) {
if (!entry.isDirectory() && entry.getName().endsWith(".txt")) {
sb.append(IOUtils.toString(zis, StandardCharsets.UTF_8));
}
}
}
return sb.toString();
}
}
package org.example.service;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ArrayNode;
import okhttp3.*;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Service
public class OllamaService {
@Value("${ollama.base-url}")
private String baseUrl;
private final OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(10, TimeUnit.SECONDS) // TCP 建连
.readTimeout(90, TimeUnit.SECONDS) // ⭐ 关键:LLM 推理必须长
.writeTimeout(30, TimeUnit.SECONDS) // 发请求体
.callTimeout(120, TimeUnit.SECONDS) // 兜底总超时
.retryOnConnectionFailure(false) // Ollama 本地调用,失败不重试
.build();
private final ObjectMapper mapper = new ObjectMapper();
/** 生成向量 */
public float[] embed(String text) throws Exception {
Map<String, Object> map = new HashMap();
map.put("model", "nomic-embed-text");
map.put("prompt", text);
String body = mapper.writeValueAsString(
map
);
Request req = new Request.Builder()
.url(baseUrl + "/api/embeddings")
.post(RequestBody.create(body, MediaType.parse("application/json")))
.build();
Response res = client.newCall(req).execute();
JsonNode node = mapper.readTree(res.body().string());
ArrayNode arr = (ArrayNode) node.get("embedding");
float[] vec = new float[arr.size()];
for (int i = 0; i < arr.size(); i++) {
vec[i] = arr.get(i).floatValue();
}
return vec;
}
/** 调用 Qwen 聊天 */
public String chat(String prompt) throws Exception {
System.out.println("提示词:"+prompt);
Map<String, Object> map = new HashMap();
map.put("model", "qwen2.5:7b");
map.put("prompt", prompt);
map.put("stream", false);
String body = mapper.writeValueAsString(
map
);
Request req = new Request.Builder()
.url(baseUrl + "/api/generate")
.post(RequestBody.create(body, MediaType.parse("application/json")))
.build();
Response res = client.newCall(req).execute();
JsonNode node = mapper.readTree(res.body().string());
return node.get("response").asText();
}
}
package org.example.service;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ArrayNode;
import org.example.dao.ChunkDao;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
@Service
public class RagService {
@Autowired
private ChunkDao dao;
@Autowired private OllamaService ollama;
public String ask(Long fileId, String question) throws Exception {
float[] qVec = ollama.embed(question);
List<Map<String, Object>> chunks = dao.findByFileId(fileId);
Map<String, Object> best = chunks.stream()
.max(Comparator.comparingDouble(c -> {
try {
return cosine(qVec, toFloatArray(c.get("embedding").toString()));
} catch (Exception e) {
throw new RuntimeException(e);
}
}))
.orElseThrow(() -> new RuntimeException("未找到文档"));
String prompt = "你是一个文档助手,请跟我给的内容,总结出我的问题。\n内容:" + best.get("content") + "\n问题:" + question;
return ollama.chat(prompt);
}
private float[] toFloatArray(String json) throws Exception {
ArrayNode arr = (ArrayNode) new ObjectMapper().readTree(json);
float[] v = new float[arr.size()];
for (int i = 0; i < arr.size(); i++) v[i] = arr.get(i).floatValue();
return v;
}
private double cosine(float[] a, float[] b) {
double dot = 0, na = 0, nb = 0;
for (int i = 0; i < a.length; i++) {
dot += a[i] * b[i];
na += a[i] * a[i];
nb += b[i] * b[i];
}
return dot / (Math.sqrt(na) * Math.sqrt(nb));
}
}
package org.example.controller;
import org.example.dao.ChunkDao;
import org.example.service.ChunkService;
import org.example.service.FileParseService;
import org.example.service.OllamaService;
import org.example.service.RagService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
@RestController
@RequestMapping("/file")
public class FileController {
@Autowired
private FileParseService parser;
@Autowired private ChunkService chunker;
@Autowired private OllamaService ollama;
@Autowired private ChunkDao dao;
@Autowired private RagService rag;
@PostMapping("/upload")
public String upload(@RequestParam MultipartFile file) throws Exception {
String text = parser.parse(file);
List<String> chunks = chunker.split(text);
long fileId = System.currentTimeMillis();
for (String c : chunks) {
dao.save(fileId, c, ollama.embed(c));
}
return "fileId=" + fileId;
}
@GetMapping("/ask")
public String ask(@RequestParam Long fileId, @RequestParam String q) throws Exception {
return rag.ask(fileId, q);
}
}测试
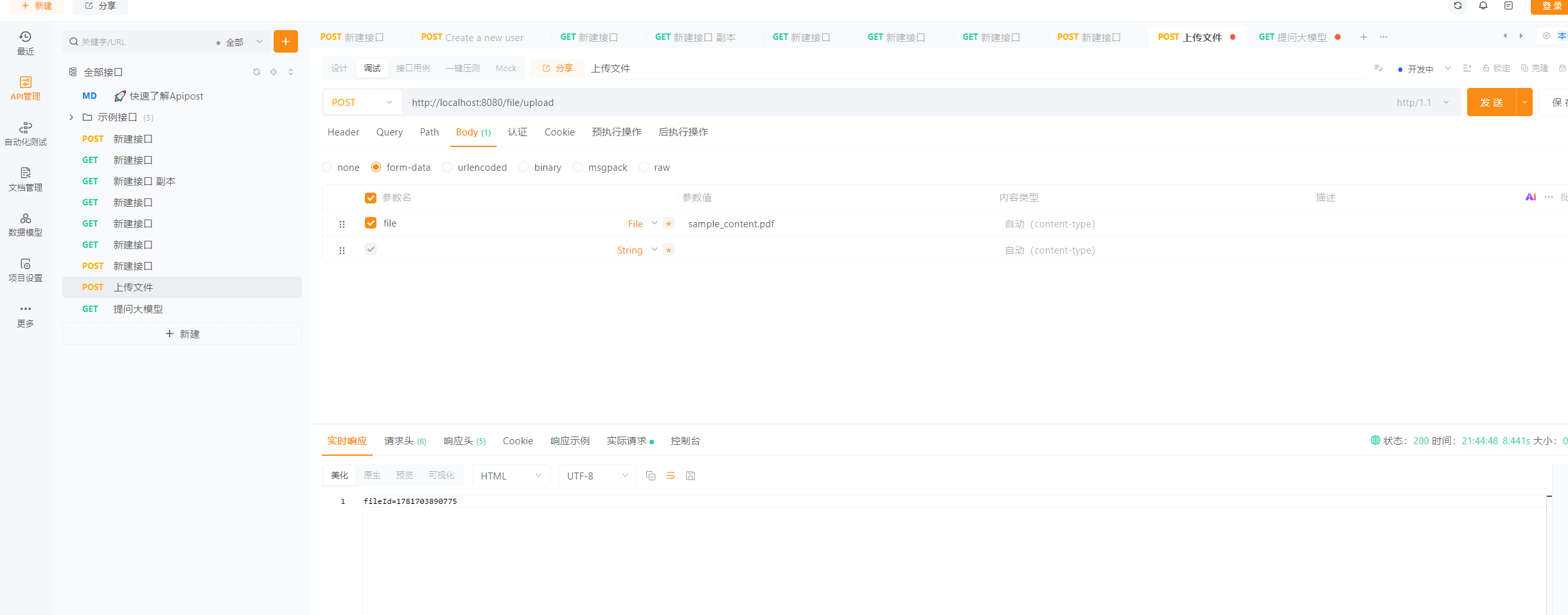
http://localhost:8080/file/upload
http://localhost:8080/file/ask?fileId=1781703890775&q=人工智能的未来是什么?
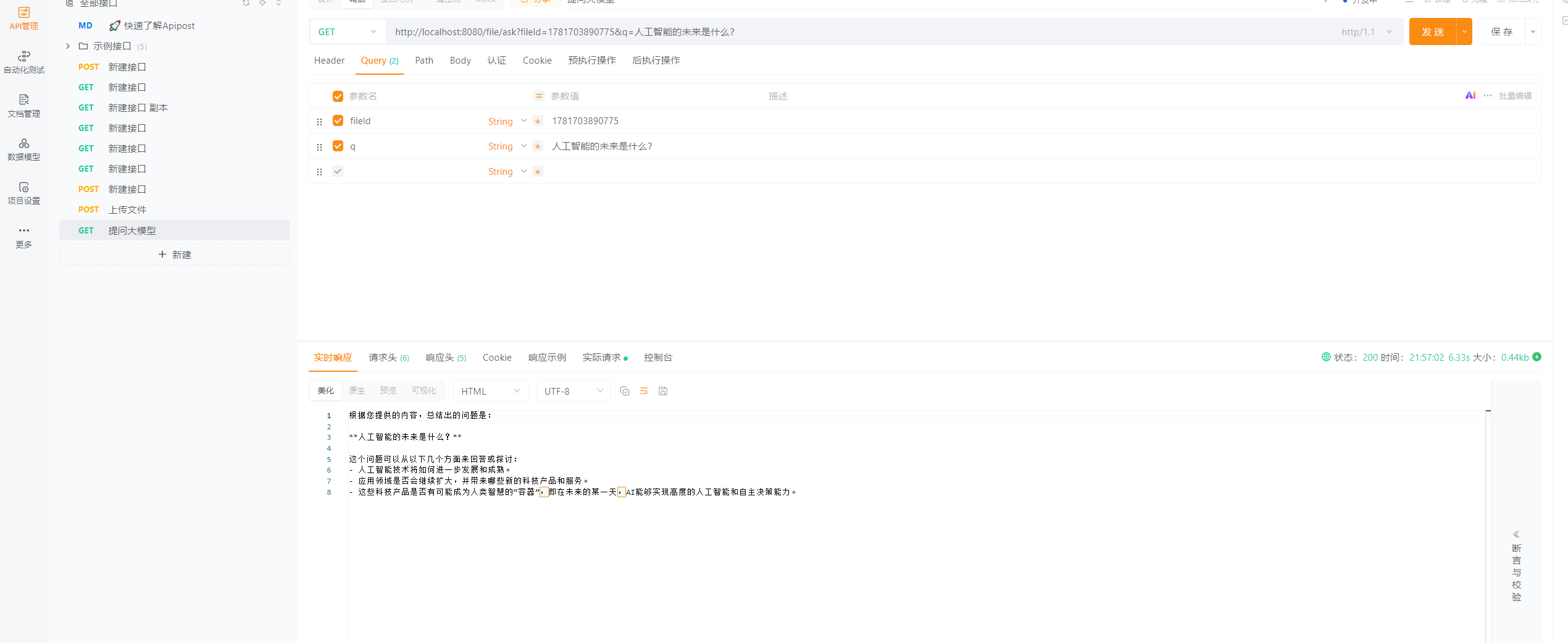
请求LLM大模型的提示词:
提示词:你是一个文档助手,请跟我给的内容,总结出我的问题。
内容:人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。
该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大。
可以设想,未来人工智能带来的科技产品,将会是人类智慧的"容器"。
问题:人工智能的未来是什么?