本文汇总介绍几款LLM数据处理框架。
Data-Juicer
项目主页,一个专为LLMs和多模态大模型设计的一站式、高性能、可扩展的开源(GitHub,6.5K Star,379 Fork)数据处理与治理框架。已成为支撑Qwen系列大模型训练数据pipeline的核心工具。文档。
目标是解决大模型训练中海量、异构、低质原始数据(如网页、论坛、百科、图文对、音视频)到高质量、安全、合规训练语料的转化难题,覆盖从采集、清洗、过滤、去重、增强到格式标准化的全链路。
特性
- 多模态原生支持。提供统一Dataset抽象,屏蔽模态差异。支持:
- 纯文本:
- 图像:OCR、美学评分、NSFW检测、图文相关性过滤
- 音频:语音识别(ASR)、静音检测、音频质量评估
- 视频:关键帧提取、字幕识别、场景分类
- 图文混合文档(PDF/Word/PPT):结构化解析+内容对齐
- 丰富内置算子(Operators)。提供100+可组合的预定义算子,覆盖常见数据处理需求:
| 类别 | 示例算子 |
|---|---|
| 过滤 | 语言识别、敏感词过滤、低信息量文本剔除 |
| 清洗 | HTML标签去除、乱码修复(ftfy)、PII脱敏 |
| 增强 | 回译(BackTranslation)、问答对生成 |
| 去重 | MinHash-LSH(近似去重)、ExactDedup(精确去重) |
| 质量评估 | Perplexity评分、CLIP图文相似度、图像清晰度 |
| 格式转换 | JSONL↔Parquet、多模态样本对齐 |
- 灵活Pipeline编排。使用YAML配置文件定义处理流程:
yaml
dataset_path: ./raw_data.jsonl
np: 8 # 并行进程数
ops:
- LanguageIdFilter:
lang: en
min_ratio: 0.8
- PiiRedactionOp:
entity_types: [PERSON, PHONE, EMAIL]
- DocumentMinhashDeduplicator:
hash_bits: 128支持条件分支、循环、自定义算子扩展。
- 高性能与可扩展
- 单机&分布式:支持本地多进程、Ray集群、Slurm作业调度
- 流式处理:内存占用低,适合TB/PB级数据
- 高效I/O:基于Apache Arrow和memory mapping,减少磁盘瓶颈
- 实测性能:在1280核CPU集群上,2.8小时完成5TB文本去重
- 安全与合规
- 内置PII(个人身份信息)识别与脱敏模块,符合GDPR、中国《个人信息保护法》
- 支持敏感内容过滤(政治、暴力、色情等)
- 提供数据血缘追踪,便于审计
- 与大模型生态深度集成
- 输出格式直接兼容HuggingFace Datasets、ModelScope
- 支持为Qwen、Llama、InternLM等主流模型定制数据模板
- 可生成用于SFT、RLHF、DPO的指令微调数据
应用场景
- 大语言模型预训练语料清洗:清洗Common Crawl、Wikipedia、The Pile等、去除低质、重复、含PII的网页
- 多模态模型训练数据构建:从网络图文对中筛选高相关性样本(CLIP score > 0.3)、视频-字幕对齐,提取高质量教学视频
- 指令微调数据生成:自动生成"问题-答案"对、过滤不安全或事实错误的样本
- 企业私有数据治理:内部文档脱敏后用于RAG或微调、构建合规的知识库
实战
基于pip安装:
bash
pip install "py-data-juicer[nlp,vision,generic]"
dj-run --config your_pipeline.yamlPython SDK集成示例:
py
from data_juicer import Executor
executor = Executor(config="pipeline.yaml")
executor.run()DataFlow
论文,开源(GitHub,5K Star,560 Fork)LLM数据处理加工的框架,以模块化、可复用的系统级抽象为核心,提供近200个可重用算子和6个跨文本、数学推理、代码、Text-to-SQL等领域的通用管道,支持PyTorch风格的管道构建API,并通过DataFlow-Agent实现自然语言到可执行管道的自动转换。文档。
类似产品:NeMo Curator。
核心优势
- LLM驱动优先,将LLM生成与精炼作为一等公民,支持细粒度语义控制,而现有框架以过滤/清洗为主;
- 编程模型更灵活,采用PyTorch风格的模块化API,支持IDE友好开发、断点续跑和编译优化,而非依赖配置文件;
- 自动化能力更强,通过DataFlow-Agent实现自然语言到管道的自动生成与调试,支持算子合成,而现有框架缺乏深度自动化能力。
论文中已有实验证明效果,其在多个任务中表现优异,如T2S任务执行精度超SynSQL +3%,代码基准测试平均提升+7%,仅10K样本的DataFlow-Instruct-10K数据集可让基础模型性能超越1M Infinity-Instruct数据训练的模型,为数据中心型AI开发提供可靠、可复现且可扩展的解决方案。
架构
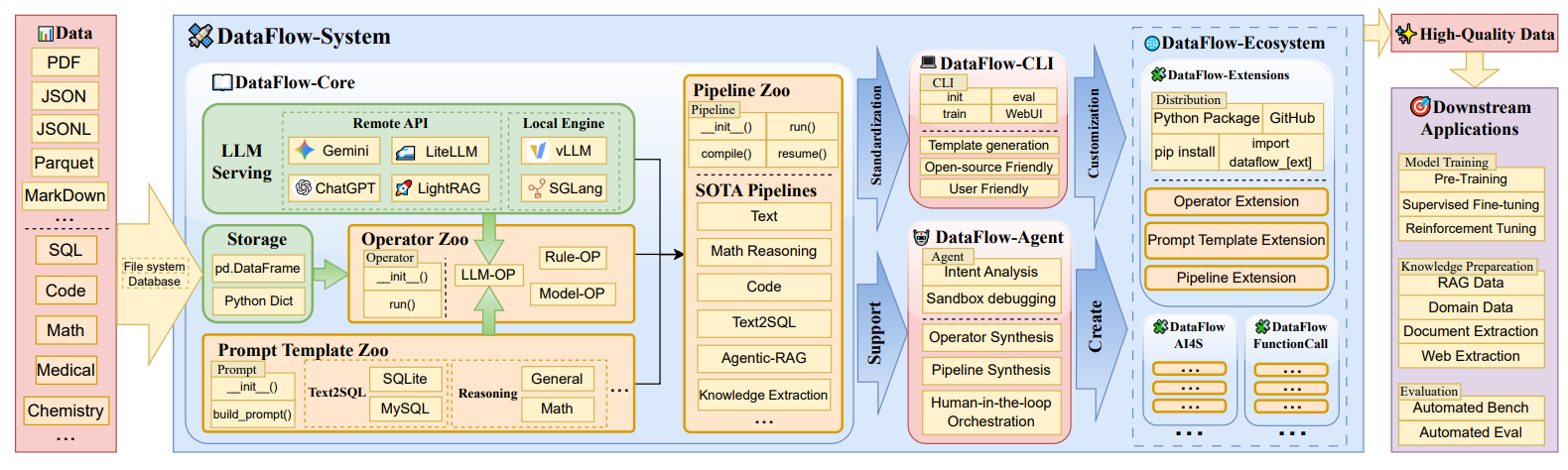
解读
- 全局存储抽象:采用表格化数据表示,提供read/write统一接口,支持多存储后端(文件系统、数据库等)。
- 分层编程接口:
- LLM服务API:统一本地引擎(vLLM、SGLang)和在线API(ChatGPT、Gemini)调用。
- 算子接口:两阶段设计(初始化+执行),支持键值对形式的灵活I/O绑定。
- 提示模板接口:解耦提示构建与算子逻辑,支持跨场景复用。
- 管道接口:PyTorch风格,支持编译优化、断点续跑。
- 算子分类:按功能分为生成(Generator)、评估(Evaluator)、过滤(Filter)、精炼(Refiner)四类,共近200个可重用算子。
- 扩展支持:支持第三方算子、管道扩展,提供CLI脚手架工具。
关键组件
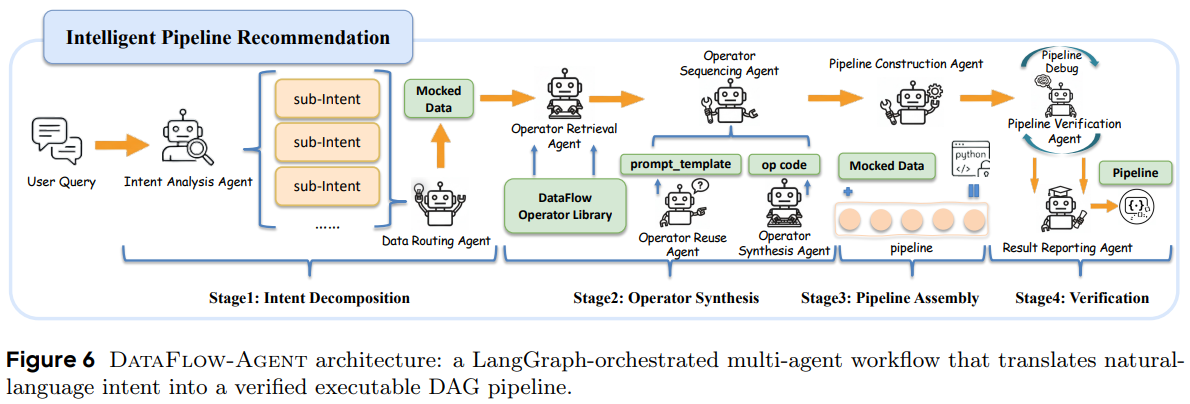
- DataFlow-Agent:基于LangGraph的多代理系统,支持自然语言指令自动生成、调试可执行管道,核心流程为意图分解→算子合成→管道组装→验证。可提高自动化能力,对非专业开发者也更友好,还能自动化调试和优化,减少人工干预。
- DataFlow-Ecosystem:支持Python包形式的扩展,通过CLI工具快速搭建算子、管道项目。
管道类型
| 管道类型 | 核心功能 | 关键实验结果 |
|---|---|---|
| 文本数据准备 | 预训练数据过滤、SFT数据合成/过滤、对话生成 | 30Btokens训练平均得分35.69(超Random等基线);DataFlow-Chat-15K超ShareGPT/UltraChat |
| 数学推理数据准备 | 问题合成、质量验证、CoT生成 | MATH、GSM8K、AIME数据集1-3分提升;10K样本训练平均得分55.7(超Open-R1、Synthetic-1) |
| 代码数据准备 | 代码指令合成、精炼 | 基准测试平均提升7%;DataFlow-Code-10K使Qwen2.5-14B平均得分达51.0 |
| T2S数据准备 | SQL生成/增强、问题生成、一致性过滤 | 超SynSQL+3%执行精度;EHRSQL基准提升31.8% |
| Agentic RAG数据准备 | 多跳问题生成、质量筛选 | 10K样本数据集OOD平均得分超HotpotQA、Musique等人类标注数据集 |
| 知识提取 | 医疗文本清洗、QA合成 | PubMedQA准确率53.40%,超CoT(36.40%)和RAG(43.33%) |
发展方向:
- 多模态扩展:支持表格、图、多模态数据。
- 领域定制:开发DataFlow-AI4S、工业级定制版本。
- 生态完善:推进社区贡献,形成标准化数据准备协议。
NeMo
NeMo Curator
开源(GitHub,1.6K Star,287 Fork)数据预处理与清洗工具。
主要功能:
- 数据去重:精确/模糊/子字符串去重
- 质量过滤:基于内容质量的分类和筛选
- 语言检测:多语言文本识别和分类
- 多模态处理:文本、图像、视频、音频的统一处理框架
- GPU加速:利用NVIDIA RAPIDS进行GPU加速处理
- 分布式执行:支持Ray集群的分布式处理
技术特点:
- 流水线架构:模块化的Stage设计,支持流式执行
- 生产就绪:在Nemotron模型训练中实际应用
- 性能优化:针对大规模数据集优化(如RedPajama v2)
应用场景:
- 为LLM训练准备大规模数据集
- 从原始数据(如Common Crawl)中提取高质量内容
- 多模态数据集的统一预处理
- 企业级数据清洗流水线
| 维度 | NeMo Curator | NeMoData Designer |
|---|---|---|
| 核心任务 | 数据清洗和筛选 | 数据生成和创造 |
| 输入数据 | 大规模原始数据 | 种子数据或无数据 |
| 输出数据 | 清洗后的高质量数据 | 新生成的合成数据 |
| 处理方向 | 减法(过滤、去重) | 加法(生成、扩充) |
| 技术重点 | 性能优化、GPU加速 | 质量控制、关系建模 |
| 典型用例 | 准备训练数据集 | 创建测试数据集 |
| 数据流向 | 原始数据→高质量数据 | 种子数据→扩展数据 |
| 复杂度 | 处理大规模数据的复杂性 | 生成逻辑的复杂性 |
NeMo DataDesigner
一个生产级开源(GitHub,2K Star,185 Fork)合成数据生成编排框架。核心目标:从零开始、或基于少量种子数据,可控、可验证、可版本化地生成高质量结构化数据集,天然支持模型蒸馏(Knowledge Distillation)场景下的许可合规合成数据管道。与OpenRouter的Distillable Models、Nemotron系列模型无缝配合,已成为HuggingFace上众多顶级开源合成数据集背后的生成引擎。官方文档。
围绕统计分布控制、字段强依赖、质量验证、许可合规、Agent自动化五大维度构建,真正把合成数据从"一次性实验"变成可复现、可规模化、可用于生产蒸馏训练的工业标准。
主要功能:
- 合成数据生成:从零生成或基于种子数据扩展
- 关系控制:字段间的依赖关系和相关性控制
- 质量验证:内置Python、SQL和自定义验证器
- 评分系统:使用LLM-as-a-judge进行质量评估
- 快速迭代:预览模式支持快速原型开发
特点
- 工业级可控性:统计分布+字段依赖
- 异步引擎:细胞级异步执行,重叠独立列处理
- 质量闭环:Validator+LLM Judge双保险
- 灵活配置:支持多种采样器和LLM模型
- 蒸馏原生合规:
enforce_distillable_text解决许可痛点 - Agent友好:技能集成,让AI帮你写代码生成数据
- 轻量易部署:
pip安装即用,支持本地/云端任意OpenAI-兼容模型
应用场景
- 模型蒸馏数据生成:教师模型(Nemotron/Llama等)生成结构化QA对、指令-响应对,用于学生模型知识迁移
- 业务结构化数据集:产品评论、客户画像、知识问答、多语言对话、模拟日志等
- 种子数据增强:少量真实数据→海量变体,同时保持统计分布
- 隐私合规场景:生成替代真实用户数据的测试集
- Agent/RAG原型验证:快速构建领域特定数据集
原理
AI模型训练(尤其是SFT、DPO、蒸馏)痛点:
- 真实数据稀缺、隐私敏感、许可受限;
- 随机prompt生成的数据分布不可控、字段无逻辑关联、质量无法验证;
- 数据不可版本化、不可复现、难以规模化;
- 蒸馏时许可合规风险高(Teacher模型生成的数据可能不允许用于Student训练)。
五大核心价值直接对症:
- 从零或种子数据生成高质量合成数据集:支持统计采样+LLM生成+种子扩充三种方式
- 字段依赖关系强控制:通过Jinja模板实现列间逻辑关联,保证数据真实性和一致性
- 内置全链路质量保障:Python/SQL/自定义验证器 + LLM-as-a-Judge自动评分
- 许可合规蒸馏管道原生支持:
enforce_distillable_text=True等机制,直接对接OpenRouter Distillable Models - Agent技能与CLI自动化:支持CC等Agent一键描述需求→自动生成Schema+验证+数据集
DataDesigner让合成数据生成升级为声明式、可追踪、可规模化的生产级管道,NVIDIA内部用它构建Nemotron模型的预训练/后训练数据集。
项目采用ConfigBuilder + Column定义的核心设计模式,主流程为:
定义Schema(列配置) → 预览迭代 → 正式生成 → 验证评分 → 导出数据集
-
三种Column生成方式(源码级核心)
- SamplerColumn:统计采样器,控制精确分布(Category、Numeric、Person demographics等)
- LLMTextColumn:LLM动态生成文本,支持
{``{ previous_column }}字段依赖引用 - Seed-based Column:基于用户提供的少量真实种子数据进行增强/变体生成
-
字段依赖与提示词模板示例:
py
config_builder.add_column(
dd.SamplerColumnConfig(
name="product_category",
sampler_type=dd.SamplerType.CATEGORY,
params=dd.CategorySamplerParams(values=["Electronics", "Clothing", ...])
)
)
config_builder.add_column(
dd.LLMTextColumnConfig(
name="review",
model_alias="nvidia-text",
prompt="Write a brief product review for a {{ product_category }} item you recently purchased."
)
)- 质量验证与评分
- 内置Validators:Python函数、SQL查询、自定义本地/远程Validator
- LLM-as-a-Judge:用另一个LLM对生成结果打分(完整性、准确性、无幻觉等)
- Preview模式:生成少量样本快速迭代配置,避免浪费Token
- 模型Provider与配置。支持NVIDIA Build API、OpenAI、OpenRouter、任意OpenAI兼容端点,CLI一键管理:
bash
data-designer config providers
data-designer config models
data-designer config list- Agent技能集成(
.skills/data-designer/目录):npx skills add NVIDIA-NeMo/DataDesigner
安装后可在CC等Agent中直接输入需求,如生成一个产品Q&A数据集,Agent自动完成Schema设计、验证和生成。
DataDesigner采用纯Python声明式框架设计(98.7% Python),仓库结构清晰(architecture/、docs/、packages/、skills/、tests_e2e/等)。
核心组件:
- DataDesignerConfigBuilder:声明式API,所有列配置、依赖、验证规则均在此定义,支持版本化
- ModelProvider抽象层:统一封装NVIDIA/OpenAI/OpenRouter,支持
extra_body参数(如{"provider": {"enforce_distillable_text": True}}) - Generation Engine:内置批处理、并行、重试、规模化机制,自动处理长上下文与Token限制
- Validation & Scoring Pipeline:可链式组合多个Validator + LLM Judge
- Telemetry(可选关闭):仅收集模型别名与Token统计,用于社区洞察热门模型
蒸馏专用扩展,在ModelConfig中加入:
py
extra_body = {
"provider": {
"enforce_distillable_text": True, # 确保生成数据可合法用于蒸馏
"only": ["deepinfra"] # 限制仅使用支持蒸馏的端点
}
}结合OpenRouter的Distillable Models集合,直接生成Teacher→Synthetic Data→Student全链路许可合规数据。NVIDIA官方示例Notebook(product-question-answer-generator_OR_v3.ipynb)就是完整蒸馏管道演示。
整个架构体现配置即代码(Config-as-Code)、声明式、版本化、可审计的工程思想,为企业级RAG、Agent、推荐系统等场景提供可落地的合成数据基础设施。
实战
提供多种部署方式:
- pip:
pip install data-designer - 源码:适合二次开发
bash
git clone https://github.com/NVIDIA-NeMo/DataDesigner.git
cd DataDesigner
make install必须要设置环境变量
export NVIDIA_API_KEY="nvapi-xxx"
# 或 export OPENAI_API_KEY=... / OPENROUTER_API_KEY=...
export NEMO_TELEMETRY_ENABLED=false # 可选关闭遥测完整快速示例(生成产品评论数据集):
py
import data_designer.config as dd
from data_designer.interface import DataDesigner
data_designer = DataDesigner()
config_builder = dd.DataDesignerConfigBuilder()
# 步骤1:采样类别
config_builder.add_column(
dd.SamplerColumnConfig(
name="product_category",
sampler_type=dd.SamplerType.CATEGORY,
params=dd.CategorySamplerParams(
values=["Electronics", "Clothing", "Home & Kitchen", "Books"]
)
)
)
# 步骤2:LLM生成评论(依赖上一步)
config_builder.add_column(
dd.LLMTextColumnConfig(
name="review",
model_alias="nvidia-text",
prompt="Write a brief product review for a {{ product_category }} item you recently purchased."
)
)
# 预览迭代
preview = data_designer.preview(config_builder=config_builder)
preview.display_sample_record()
# 正式生成(规模化)
# dataset = data_designer.generate(config_builder=config_builder, num_records=10000)生成后可直接导出CSV/JSONL,用于NeMo Microservices的Knowledge Distillation Job或Hugging Face Trainer。
NeMo DataDesigner把合成数据生成提升到声明式、合规、可规模化的新高度,尤其在模型蒸馏、隐私保护、领域定制化Agent场景下价值巨大。