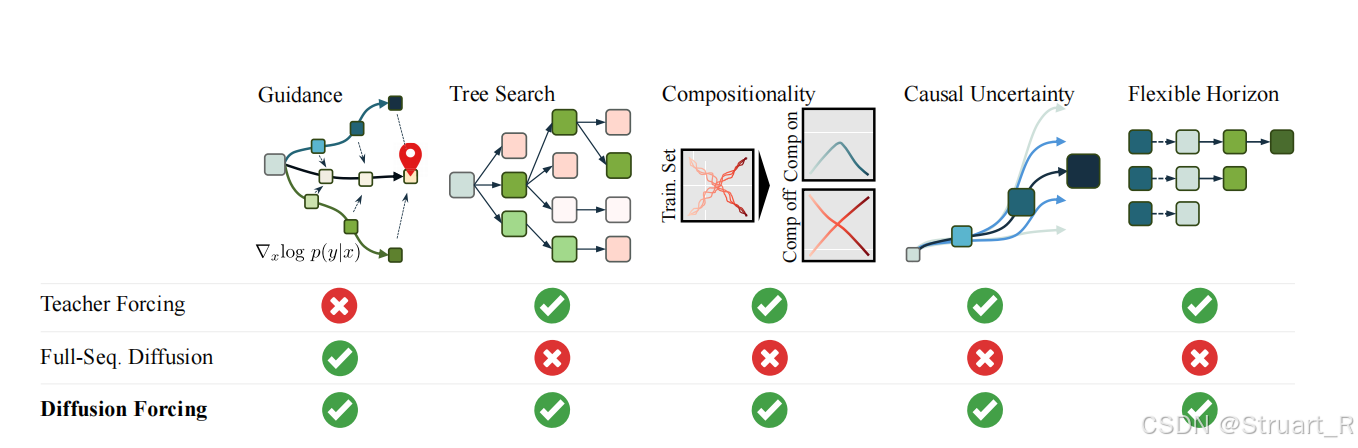
这三篇论文都是在解决全序列扩散与AR模型的争议,如何实现更稳定的长序列视频生成。
一、Diffusion Forcing
1、概述
这个论文批判了当下两类模型,一个是next-token prediction中基于teacher forcing训练的方法(gpt),该方法虽然可以实现因果,流式,支持变长,但是必须完全相信上一帧,last token的结果,这就导致如果上一帧出错,后续帧会像滚雪球一样逐渐偏离,无法主动纠错。一个是full-seq diffusion方法(sora),该方法提前知道视频的长度,可以根据文本引导调节,但是全局非因果,不能接受流式,不能完成实时交互。
contribution:它把 "自回归逐 token 生成" 和 "扩散去噪" 焊在一起,但不是简单拼接,而是通过一条关键设计,每个 token 独立采样不同噪声级别,让因果模型既拥有扩散的分布建模能力,又不丢失 AR 的变长/流式/因果属性。
2、方法
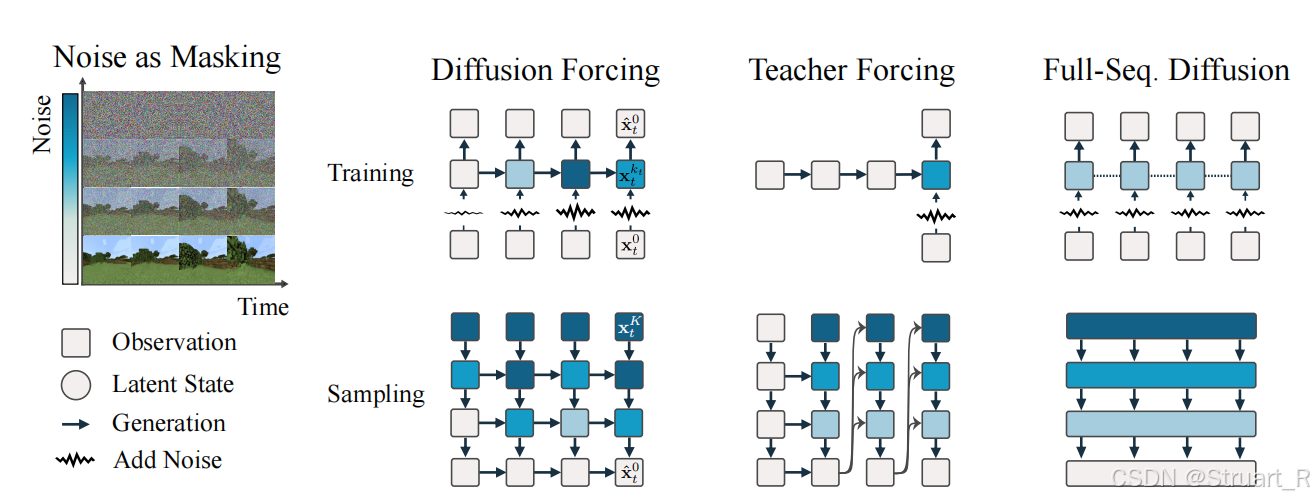
对比三种方法
首先我们对比这三种方法(生成4帧视频),左侧的Noise as masking指出颜色越深的代表带噪声更多,白色为干净图片:
Teacher Forcing:训练过程前几帧必须是干净的,不带噪声的,推理根据前n-1帧的预测来生成第n帧,容易出现误差累积
Full-seq Diffusion:训练过程序列长度不可变,根据固定的噪声序列来去噪生成视频,不可流式。
Diffusion Forcing:对每一帧单独处理噪声,学习不同噪声下的生成效果,推理过程中我们可以指定某些帧已知(不处理),其他帧(全蓝)全噪声,让他生成中间的过程。这种方法不在乎哪一帧未知,只要保证因果链,就可以在任何位置插入去噪过程。
加噪过程
传统扩散是"时间同步"(所有帧同时到达第k步),而 DF 是"帧级异步"(每一帧独立采样自己的kt)。
加噪过程与DDPM一致: ,其中
是第t帧原始真实图像,
是噪声级别,0到1000的整数,
是噪声调度系数,数值越大,图像越模糊。
是随机噪声。
加噪过程的系数怎么计算的:
|----------------------------------------------|-------|-------------------------------------------------------------------|
| 符号 | 含义 | 计算公式 |
| | 噪声率 | 人为规定(线性、余弦、sigmoid等) |
| | 保留率 |
|
| | 累积保留率 |
|
通过指定每一个t,可以控制每一帧的加噪强度,也就是让模型学会,即使上一帧很糊,下一帧也能预测对。根据加噪过程最终会得到一组序列
预测噪声
基于这一组序列,状态更新隐变量,其中k_t作为噪声添加强度,或者图片清晰度来指导状态跟新。
观测模型根据隐变量来预测噪声 ,并用MSE来计算损失
。
当然最终的total loss也转变为每一帧的loss相加,在论文里用了Fused SNR Re-weighting这个方法来保证loss贡献受噪声强度影响,防止突变的某一帧梯度过大绑架整体不收敛。
采样
就是生成过程,传统的扩散过程是同时对4张图片(一个序列)同时从噪声生成图片,而DF方法是先生成第一张,然后根据第一张生成第二张,根据第一、二张生成第三张。
并且对于特定帧已知的采样,他维护了一个二维网格(调度矩阵),行为去噪时间步,列为视频帧,如果已知一、四帧,生成二、三帧,那么让一、四帧k=0,二三帧从k=1000然后逐渐降到0。
3、不足
-
RNN 的并行化困境 :DF 的核心是用 RNN 维护 zt。这意味着训练和推理都无法像 Transformer 那样并行处理时间轴。生成 1000 帧就需要滚 1000 步 RNN。这是 DF 目前最大的工程瓶颈。(长序列灾难性遗忘)
-
Transformer 化的可能性 :Appendix提到可以用 Transformer 实现,但强调必须配合因果掩码。这里有个隐藏技巧:通过控制未来帧的噪声级别
来实现"软因果"(未来帧设为高噪,信息泄露为零)。这是将 DF 扩展到 Large Scale 的关键。
-
帧堆叠(Frame Stacking):在Appendix中,为了减少计算,他们把相邻几帧打包成一个 Token。这不是简单的拼接,而是为了适配 Diffusion 模型对"冗余数据"的偏好。如果不做帧堆叠,直接预测单帧,训练可能会非常不稳定。
二、Causvid
1、概述
motivation:以往的DiT模型训练要求过大,并且难以实现流式。
contribution:拿一个已经训好的、强大的双向注意力视频 DiT(如 CogVideoX),用最小的改动把它变成因果自回归 streaming 模型,然后通过 asymmetric DMD 蒸馏把 50-step 压到 4-step,配上 KV cache 跑到 9.4 FPS 单卡实时流式生成。
2、方法
DMD蒸馏
AR-DiT:没有固定的论文介绍AR-DiT,可以理解为块内full attn+块间Causal attn,旨在降低计算量,同时利用Transformer架构来更快的训练。
DMD:不再强制学生模型精确复制教师模型(多步扩散模型)从噪声到图像的复杂关系,只需要让学生模型生成的图像在数据分布上与教师模型的输出无法区分。最小化教师输出数据分布与学生模型输出分布之间的KL散度。这相比于直接pixel-align的mse算法,DMD算法可以让学生学习到教师模型的思维方式。
分数score计算为预测视频分布的对数梯度:,比如
将梯度差对学生模型参数的偏导进行更新学生模型:
学生模型初始化
学生模型直接蒸馏可能会不稳定,所以Causvid设计了一个初始化策略,使用预训练的教师模型,生成一小批数据对,学生模型在这一小批数据对上进行预训练。
后续隔一段时间更新吧,忙忘了
参考文献:
2407.01392 Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion