大家好,我是上好佳佳佳呀~
在上一篇文章中,我们搞定了 RAG 流程的前两步:用 Loader 把各类文档加载进来,再用 Splitter 切成语义完整的小块。现在,手里已经有了一堆"原料",但计算机不认识汉字,只认得数字,这些文本块要怎么才能被检索到呢?
今天我们就来攻克 RAG 管道中最核心的两个环节:Embedding(文本向量化) 和 VectorStore(向量存储与检索)。我们会把"文本转成向量、存进数据库、再根据问题搜出来"这条链路彻底走通。最后,我还会用一个完整的代码示例,演示如何用 LCEL 的管道符 | 把所有零件串联成一条生产可用的 RAG 链。
准备好了吗?我们开始学习吧~
文章目录
- 前言
- [1. Embedding:从文本到向量](#1. Embedding:从文本到向量)
-
- [1.1 什么是 Embedding?](#1.1 什么是 Embedding?)
- [1.2 Embedding 在 RAG 管道中的角色](#1.2 Embedding 在 RAG 管道中的角色)
- [1.3 常用的 Embedding 模型](#1.3 常用的 Embedding 模型)
- [1.4 核心用法:embed_documents 与 embed_query](#1.4 核心用法:embed_documents 与 embed_query)
- [2. VectorStore:向量存储与检索](#2. VectorStore:向量存储与检索)
-
- [2.1 为什么需要专门的向量数据库?](#2.1 为什么需要专门的向量数据库?)
- [2.2 LangChain 中的 VectorStore 体系](#2.2 LangChain 中的 VectorStore 体系)
- [2.3 VectorStore 的统一接口](#2.3 VectorStore 的统一接口)
- [2.4 用 InMemoryVectorStore 理解接口用法](#2.4 用 InMemoryVectorStore 理解接口用法)
-
- [2.4.1 写入:add_documents vs add_texts](#2.4.1 写入:add_documents vs add_texts)
- [2.4.2 基础检索:similarity_search](#2.4.2 基础检索:similarity_search)
- [2.4.3 带分数检索:similarity_search_with_score](#2.4.3 带分数检索:similarity_search_with_score)
- [2.4.4 多样性检索:max_marginal_relevance_search](#2.4.4 多样性检索:max_marginal_relevance_search)
- [2.4.5 删除向量:delete](#2.4.5 删除向量:delete)
- [2.4.5 InMemoryVectorStore 完整代码示例](#2.4.5 InMemoryVectorStore 完整代码示例)
- [2.5 Chroma 的使用](#2.5 Chroma 的使用)
- [2.6 主流向量数据库一览](#2.6 主流向量数据库一览)
- [3. 用 LCEL 串联成 RAG 链](#3. 用 LCEL 串联成 RAG 链)
-
- [3.1 从最简链起步回顾链知识](#3.1 从最简链起步回顾链知识)
- [3.2 VectorStore 为什么不能直接放入链中?](#3.2 VectorStore 为什么不能直接放入链中?)
- [3.3 解决方案:as_retriever() + 字典构造 + RunnablePassthrough + lambda](#3.3 解决方案:as_retriever() + 字典构造 + RunnablePassthrough + lambda)
-
- [3.3.1 as_retriever():让 VectorStore 变成 Runnable](#3.3.1 as_retriever():让 VectorStore 变成 Runnable)
- [3.3.2 字典构造、RunnablePassthrough、lambda](#3.3.2 字典构造、RunnablePassthrough、lambda)
- [3.4 完整组装](#3.4 完整组装)
前言
在上一篇文章中,我们走完了 RAG 流程的前两个关键基础:
📄 各类文档 → ① Document Loader(加载) → ② Text Splitter(切分)现在已经有了一堆切好的 Document 小块,每个 chunk 语义完整、大小适中、还带着 metadata 溯源信息。但这只是"准备好了原料",接下来要解决两个核心问题:
- 怎么让机器"理解"这些文本? 计算机不认识汉字,只认识数字。需要把文本转成向量,这就是 Embedding(向量化),并且无论是索引阶段还是检索阶段都需要向量化这个工具:需要把小块数据向量化存储到向量数据库中,用户提出的问题需要向量化再进行向量数据库中的检索。
- 怎么高效存储和检索这些向量? 百万级别的向量,不可能每次检索都全量比对。需要专门的向量数据库,这就是 VectorStore(向量存储)
本文就聚焦这两个环节,把 RAG 管道继续向前推进。
💡 如果你之前看过我关于 Embedding 的博客,第一部分Embedding模型用法可以快速复习巩固。如果你是第一次接触 Embedding 概念,第一部分会帮你建立最核心的认知地基。
1. Embedding:从文本到向量
1.1 什么是 Embedding?
计算机擅长的是矩阵和张量运算,而自然语言是非结构化的。Embedding 的本质就是:把一段文本映射成一个固定长度的浮点数向量,使得语义相近的文本在向量空间中距离也相近。
也就是说,"语义相似"≈"向量距离近"。
那么,如何度量"向量距离"呢?通常使用余弦相似度(Cosine Similarity),它衡量的是两个向量在方向上的接近程度,公式为:
c o s i n e s i m i l a r i t y ( A , B ) = A ⋅ B ∥ A ∥ ⋅ ∥ B ∥ cosine\ similarity(A, B) = \frac{A \cdot B}{\|A\| \cdot \|B\|} cosine similarity(A,B)=∥A∥⋅∥B∥A⋅B
其中:
- A ⋅ B A \cdot B A⋅B 表示向量 A 和 B 的点积
- ∥ A ∥ ⋅ ∥ B ∥ \|A\| \cdot \|B\| ∥A∥⋅∥B∥ 分别表示向量 A 和 B 的模长(欧几里得范数)
- 公式计算的是两个向量夹角的余弦值
为什么要除以模长的乘积?
向量的点积可以理解为"A 在 B 方向上的投影长度乘以 B 的模长"。如果直接用点积判断相似性,会出现一个问题:向量越长,点积越大,即便方向不同也可能得分较高。而余弦相似度通过除以两个模长,将向量归一化到单位长度,仅比较方向,彻底撇除了长度影响。最终结果落在 -1, 1 之间,1 表示方向完全相同(夹角 0°),0 表示正交,-1 表示方向相反。
可见,余弦相似度只关心方向夹角,不在乎向量本身的绝对长度,这正是我们需要的语义相似性度量。
什么是向量的维度? 维度即向量的长度(数字个数)。比如一个 384 维向量就是用 384 个浮点数表示一段文本。维度越高,能编码的语义信息越丰富,但存储和计算也更昂贵。可以类比为"分辨率":384P、1024P、3072P 代表了信息密度的不同。
1.2 Embedding 在 RAG 管道中的角色
在 RAG 系统中,Embedding 出现了两次,且两次的任务完全一样:把文本变成向量:
- 离线阶段(知识库构建):
切分好的 Document chunk → Embedding 模型 → 向量 → 存入 VectorStore - 在线阶段(用户提问):
用户问题 → Embedding 模型 → 查询向量 → 在 VectorStore 中找最相似的向量
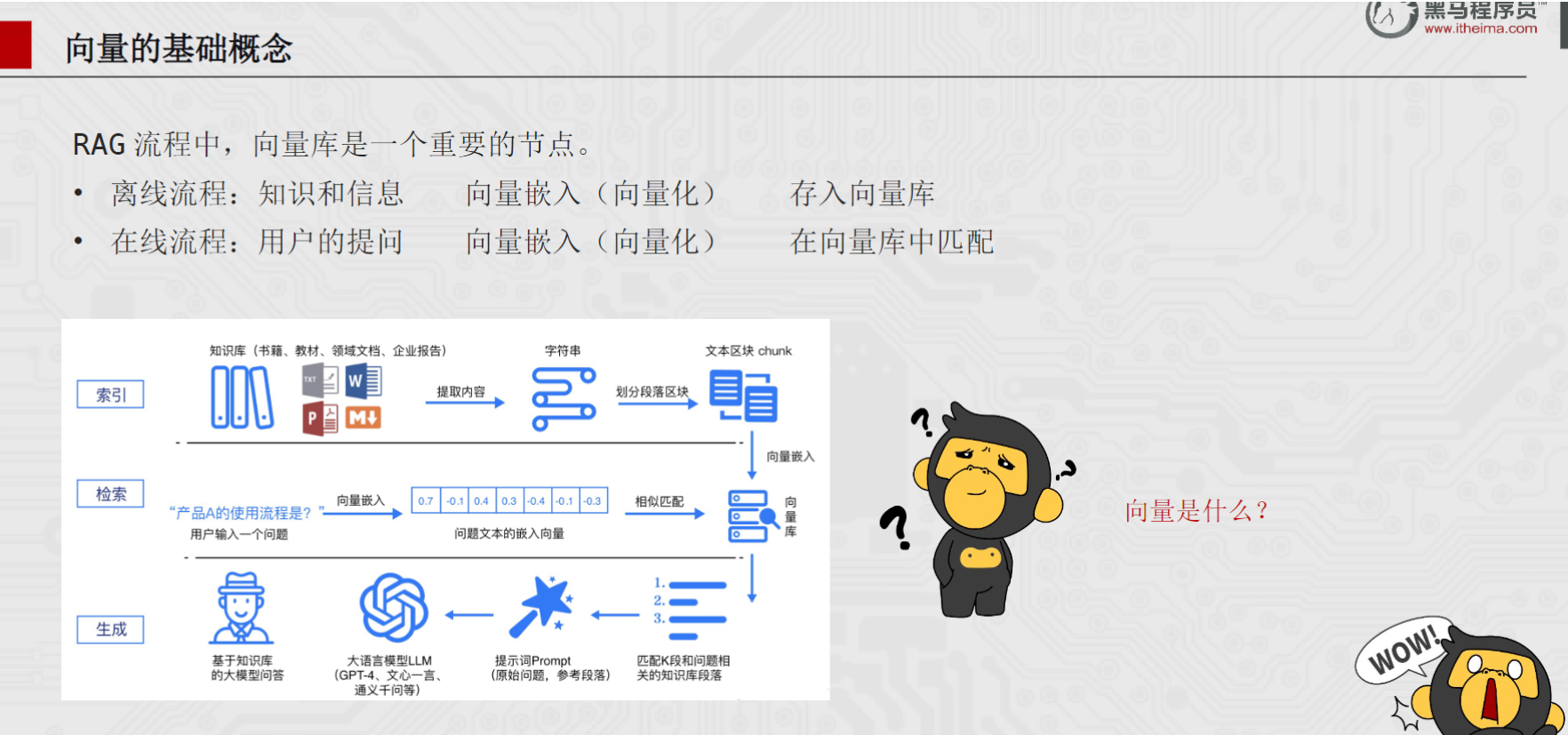
关键认知:两次必须使用同一个 Embedding 模型!
不同模型产出的向量存在于不同的向量空间,语义上没有任何可比性。如果用 A 模型编码文档向量,用 B 模型编码查询向量去检索,就如同"用英语提问,对方只会法语"------完全匹配不上。
1.3 常用的 Embedding 模型
LangChain 提供了统一的 Embedding 接口,屏蔽了不同厂商和开源模型的差异。以下是一些常用模型及其特点:
| 类名 | 背后模型 | 向量维度 | 适用场景 |
|---|---|---|---|
OpenAIEmbeddings |
text-embedding-3-small | 1536(可调) | 通用,效果优秀,付费 |
OpenAIEmbeddings |
text-embedding-3-large | 3072(可调) | 高精度需求,更贵 |
HuggingFaceEmbeddings |
开源模型(如 bge-large-zh) | 1024 | 中文场景优秀,本地免费部署 |
OllamaEmbeddings |
Ollama 本地模型 | 取决于模型 | 完全离线,隐私优先 |
CohereEmbeddings |
embed-v3 | 1024 | 多语言支持好 |
GoogleGenerativeAIEmbeddings |
Google 嵌入模型 | 768 | Google 生态集成 |
简化版选型指南:
- 有预算、追求效果 →
OpenAIEmbeddings(text-embedding-3-small 性价比最高) - 中文为主、本地部署 →
HuggingFaceEmbeddings(bge-large-zh 系列) - 完全离线、隐私第一 →
OllamaEmbeddings - 多语言混合 →
CohereEmbeddings或 OpenAI
1.4 核心用法:embed_documents 与 embed_query
LangChain 所有 Embedding 类都实现了两个核心方法,分别对应离线和在线场景:
python
class BaseEmbeddings:
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""将多个文档文本转为向量(离线阶段批量使用)"""
...
def embed_query(self, text: str) -> List[float]:
"""将单个查询文本转为向量(在线阶段使用)"""
...实战示例一:OpenAI Embeddings
python
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
dimensions=512, # 可选降维,省存储、提速度
)
# 离线:批量嵌入文档
doc_vectors = embeddings.embed_documents([
"员工每年享有 5 天带薪年假",
"加班需提前申请,经主管审批后方可执行",
])
print(f"编码了 {len(doc_vectors)} 个文档,每个向量维度: {len(doc_vectors[0])}")
# 输出:编码了 2 个文档,每个向量维度: 512
# 在线:嵌入用户查询
query_vector = embeddings.embed_query("年假有多少天?")
print(f"查询向量维度: {len(query_vector)}")
# 输出:查询向量维度: 512实战示例二:HuggingFace 本地模型(离线免费)
python
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5", # 中文最佳开源模型之一
model_kwargs={"device": "cuda"}, # 使用 GPU 加速
encode_kwargs={"normalize_embeddings": True}, # 向量归一化,便于余弦相似度计算
)
vectors = embeddings.embed_documents(["员工每年享有 5 天带薪年假"])
print(f"向量维度: {len(vectors[0])}")
# 输出:向量维度: 1024常用参数说明:
| 参数 | 说明 |
|---|---|
model / model_name |
指定使用的 Embedding 模型名称 |
dimensions |
(OpenAI) 可选降维,如 512 可将 1536 维压缩到 512 维,节省存储、加速检索 |
model_kwargs |
传递给底层模型的参数,如 {"device": "cuda"} 指定 GPU |
encode_kwargs |
传递给编码方法的参数,如 {"normalize_embeddings": True} 对向量做归一化 |
小结: 现在我们知道了如何把任意文本变成定长浮点数向量,并且语义相近的文本在向量空间中彼此靠近。接下来要解决的问题是:面对海量文档向量,如何高效存取和检索?
2. VectorStore:向量存储与检索
2.1 为什么需要专门的向量数据库?
最朴素的想法:将查询向量与库中所有向量逐个计算相似度,然后取 Top-K。这就是暴力检索(Brute Force)。但随着数据量增长,它的性能会急剧恶化。
向量数据库(VectorStore) 就是为了解决这个问题而生。它通过近似最近邻(ANN)算法和各种索引结构,可以在毫秒级从百万甚至十亿级向量中快速找出最相似的 Top-K。
一个直观类比:
📚 暴力检索 = 在图书馆里一本一本翻找,直到找到你要的书
🏗️ VectorStore = 图书馆的分类索引系统:先锁定哪个书架 → 哪一排 → 哪一本2.2 LangChain 中的 VectorStore 体系
LangChain 统一了多种向量存储方案,大致分为两类:
┌─────────────────────────────────────────────────────┐
│ LangChain VectorStore │
│ │
│ ┌─────────────────────┐ ┌──────────────────────┐ │
│ │ 内置 / 轻量方案 │ │ 外部专业向量数据库 │ │
│ │ │ │ │ │
│ │ · InMemoryVectorStore│ │ · Chroma │ │
│ │ · FAISS │ │ · Pinecone (云) │ │
│ │ · Annoy │ │ · Weaviate (云/本地) │ │
│ │ │ │ · Milvus (分布式) │ │
│ │ 适合:开发测试、 │ │ · Qdrant │ │
│ │ 小规模原型验证 │ │ · PGVector │ │
│ │ │ │ │ │
│ │ │ │ 适合:生产环境、 │ │
│ │ │ │ 大规模、持久化需求 │ │
│ └─────────────────────┘ └──────────────────────┘ │
└─────────────────────────────────────────────────────┘这里需要澄清一个常见疑问:Chroma 也是可以本地部署的,为什么它和 FAISS 不在同一个类别?
分类的标准并不是"本地还是云托管",而是设计理念和功能完整度。FAISS 本质上是一个高性能的向量相似度搜索库,它提供了极致的检索速度和 GPU 加速,但本身没有数据库的完整特性(如增删改查、持久化、客户端/服务器模式等),通常需要你自己去管理数据的持久化和并发。而 Chroma 是一个开源的、嵌入式的向量数据库,它不仅可以本地持久化,还内置了文档管理、元数据过滤、简单的 Web UI 等数据库级别的功能。哪怕同样是本地运行,Chroma 更像一个"数据库系统",而 FAISS 更像一个"索引引擎"。因此,在 LangChain 的语境下,把它们放在不同的类别中,是为了帮助你根据项目的复杂度和规模来选型。
2.3 VectorStore 的统一接口
LangChain 的 VectorStore 实现了统一接口,无论底层是什么数据库,Chroma、FAISS 还是 Pinecone,操作方法都相同:
python
class VectorStore:
# 写操作
def add_documents(self, documents: List[Document]) -> List[str]:
"""把 Document 列表嵌入并存入向量库,返回 ID 列表"""
...
def add_texts(self, texts: List[str], metadatas: List[dict] = None) -> List[str]:
"""把纯文本列表嵌入并存入向量库"""
...
# 检索操作
def similarity_search(self, query: str, k: int = 4) -> List[Document]:
"""相似度检索,返回最相似的 k 个 Document"""
...
def similarity_search_with_score(self, query: str, k: int = 4) -> List[Tuple[Document, float]]:
"""检索并返回相似度分数(分数越低越相似)"""
...
def max_marginal_relevance_search(self, query: str, k: int = 4, fetch_k: int = 20) -> List[Document]:
"""MMR 检索:在相似度和多样性之间平衡,避免重复内容"""
...
def as_retriever(self, **kwargs) -> VectorStoreRetriever:
"""将 VectorStore 包装为 Retriever 对象,用于融入 LCEL 链"""
...
# 管理操作
def delete(self, ids: List[str]) -> None:
"""按 ID 删除向量"""
...
# 链式调用适配
def as_retriever(self, **kwargs) -> VectorStoreRetriever: ...关键认知:
similarity_search返回的是List[Document],这意味着检索结果不仅包含文本(page_content),还完整保留了 metadata(来源文件、页码等)。这正是我们一直强调 metadata 重要的原因,最终呈现答案时,系统可以清楚地标明"这条信息来自某文件第几页"。
2.4 用 InMemoryVectorStore 理解接口用法
下面我们以 InMemoryVectorStore 为例,逐个演示每个接口的用法。因为所有 VectorStore 都遵循同一套接口,掌握了这些,后续切换任何向量库都只需要改一下初始化部分。
首先初始化一个共用的 Embedding 和 VectorStore:
python
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = InMemoryVectorStore(embedding=embeddings)2.4.1 写入:add_documents vs add_texts
这两个方法都能把数据存入向量库,区别在于传入的格式。
方式A:add_documents ( 推荐方式)
传入的是 Document 对象列表,metadata 自动保留。
python
from langchain_core.documents import Document
docs = [
Document(page_content="员工每年享有 5 天带薪年假,由部门主管审批后即可休假。",
metadata={"source": "员工手册.pdf", "page": 15}),
Document(page_content="加班需提前在 OA 系统提交申请,经主管审批后方可执行。",
metadata={"source": "员工手册.pdf", "page": 28}),
]
ids = vectorstore.add_documents(docs)
print(ids) # ['doc_0', 'doc_1']方式B:add_texts (纯文本补充方案)
当你手头只有纯文本,还没封装成 Document 对象时,可以用 add_texts,但需要单独传入 metadatas 列表,并且两个列表的长度必须一致,一一对应。
python
ids = vectorstore.add_texts(
texts=["工作满 10 年的员工,年假天数增加至 10 天。",
"公司每年组织一次全员健康体检,时间为每年 6 月。"],
metadatas=[{"source": "员工手册.pdf", "page": 15},
{"source": "员工手册.pdf", "page": 42}]
)
print(ids) # ['doc_2', 'doc_3']⚠️ 如果
add_texts不传metadatas,每条记录的 metadata 将是空字典{},后续检索到就不知道它的来源了。
2.4.2 基础检索:similarity_search
最常用的检索方法,直接输入查询文本,返回最相似的 K 个 Document。
python
query = "年假有几天?"
results = vectorstore.similarity_search(query, k=2)
for i, doc in enumerate(results, 1):
print(f"Top-{i}: {doc.page_content}")
print(f" 来源: {doc.metadata['source']} 第{doc.metadata['page']}页")返回的结果按相似度从高到低排列,第 1 个就是库中与查询向量距离最近的那条。如果库中只有几条数据,InMemoryVectorStore 这背后做的是暴力检索;换到 Chroma/FAISS 上,就是高效的 ANN 索引检索了。
python
# ---- 按 metadata 过滤检索 ----
# 例如只查来自员工手册.pdf 的内容
results = vectorstore.similarity_search(
"年假政策",
k=3,
filter={"source": "员工手册.pdf"} # 仅检索 source 为该值的文档
)2.4.3 带分数检索:similarity_search_with_score
有时我们不仅需要文档内容,还想知道检索的"把握有多大",或者想过滤掉相似度太低的结果。similarity_search_with_score 会同时返回文档和对应的分数。
python
results = vectorstore.similarity_search_with_score("年假政策", k=3)
for doc, score in results:
print(f"分数: {score:.4f} | 内容: {doc.page_content[:50]}...")⚠️ 分数解读需要留个心眼: 不同 VectorStore 对"分数"的定义可能不同。因为对向量相似性的算法不同。
InMemoryVectorStore默认返回余弦相似度,分数在 0~1 之间,越高越相似。- Chroma 默认返回 L2 欧氏距离,分数越低越相似 。
生产环境中拿到分数后,建议先用几条已知数据测试一下分数的含义和范围,再决定阈值。
2.4.4 多样性检索:max_marginal_relevance_search
默认的 similarity_search 有一个隐蔽问题:它只按相似度排序,可能返回一堆内容高度重复的 chunk。比如用户问"年假政策",Top-4 可能全是"5天年假"的不同表述,信息量只有一条。
max_marginal_relevance_search(最大边际相关性搜索,简称 MMR)会在"与查询相关"和"与已选结果不重复"之间取得平衡,返回一组既相关又互不重复的结果。
python
results = vectorstore.max_marginal_relevance_search(
"年假政策",
k=4, # 最终返回 4 条结果
fetch_k=10, # 先从库中捞 10 个最相似的候选
lambda_mult=0.5 # 0=完全多样性,1=完全按相似度,这里取平衡
)
for i, doc in enumerate(results, 1):
print(f"结果 {i}: {doc.page_content[:60]}...")MMR 参数详解:
| 参数 | 含义 | 推荐值 |
|---|---|---|
k |
最终返回的结果数 | 3~5 |
fetch_k |
候选池大小,越大可选范围越大,多样性越好 | k 的 3~5 倍(如 k=4 → fetch_k=20) |
lambda_mult |
0~1 之间。0=只要多样性,1=只要相似度 | 0.5~0.7,略微偏向相关性 |
这个方法是所有 VectorStore 的通用接口,无论底层是 Chroma、FAISS 还是 Pinecone,调用方式都完全一样。
2.4.5 删除向量:delete
当文档需要更新或下架时,可以通过 ID 精确删除对应的向量记录。
python
# 删除 ID 为 'doc_0' 和 'doc_1' 的两条向量
vectorstore.delete(ids=['doc_0', 'doc_1'])
# 删除后,再检索就不会出现这两条了
print(len(vectorstore.similarity_search("年假", k=10))) # 只剩2条2.4.5 InMemoryVectorStore 完整代码示例
python
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# ========== Step 1: 创建 ==========
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = InMemoryVectorStore(embedding=embeddings)
# ========== Step 2: 存入 ==========
docs = [
Document(page_content="员工每年享有 5 天带薪年假,由部门主管审批后即可休假。",
metadata={"source": "员工手册.pdf", "page": 15, "chapter": "休假制度"}),
Document(page_content="工作满 10 年的员工,年假天数增加至 10 天。",
metadata={"source": "员工手册.pdf", "page": 15, "chapter": "休假制度"}),
Document(page_content="加班需提前在 OA 系统提交申请,经主管审批后方可执行。加班费按基本工资的 1.5 倍计算。",
metadata={"source": "员工手册.pdf", "page": 28, "chapter": "加班制度"}),
Document(page_content="公司每年组织一次全员健康体检,时间为每年 6 月,具体安排由行政部通知。",
metadata={"source": "员工手册.pdf", "page": 42, "chapter": "员工福利"}),
]
ids = vectorstore.add_documents(docs)
print(f"存入 {len(ids)} 条,ID: {ids}")
# ========== Step 3: 各种检索 ==========
# 基础检索
print("\n--- 基础检索 ---")
for doc in vectorstore.similarity_search("年假有几天?", k=2):
print(f" {doc.page_content} (来源: {doc.metadata['source']})")
# 带分数检索
print("\n--- 带分数检索 ---")
for doc, score in vectorstore.similarity_search_with_score("年假", k=3):
print(f" [score={score:.4f}] {doc.page_content[:50]}...")
# MMR 多样性检索
print("\n--- MMR 检索 ---")
for doc in vectorstore.max_marginal_relevance_search("公司政策", k=2, fetch_k=10):
print(f" {doc.page_content[:60]}...")
# ========== Step 4: 删除 ==========
vectorstore.delete(ids=[ids[3]]) # 删掉体检那条
print(f"\n删除后剩余: {len(vectorstore._store)} 条")2.5 Chroma 的使用
Chroma 是一个开源的 AI 原生向量数据库,LangChain 对其有深度集成。它非常适合入门和中小规模项目:
python
# pip install chromadb langchain-chroma
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# ===== Step 1: 准备数据(复用前面的知识)=====
loader = TextLoader("./员工手册.txt", encoding="utf-8")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
print(f"切成了 {len(chunks)} 个小块")
# ===== Step 2: 初始化 Embedding 和 Chroma =====
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 模式 A:内存模式(临时测试,程序结束数据消失)
vectorstore = Chroma(
collection_name="company_policies", # 集合名,类似表名
embedding_function=embeddings, # 指定 Embedding 模型
# 不传 persist_directory → 内存模式
)
# 模式 B:持久化模式(数据存磁盘,程序重启后依然存在)
vectorstore = Chroma(
collection_name="company_policies",
embedding_function=embeddings,
persist_directory="./chroma_db", # 指定持久化目录
)
# ===== Step 3: 存入文档 =====
ids = vectorstore.add_documents(chunks)
print(f"存入了 {len(ids)} 条向量")
# ===== Step 4: 检索 =====
results = vectorstore.similarity_search("年假有多少天?", k=3)
results_with_score = vectorstore.similarity_search_with_score("年假有多少天?", k=3)
mmr_results = vectorstore.max_marginal_relevance_search("公司政策", k=3, fetch_k=15)
# Chroma 默认分数是 L2 距离,越低越相似
for doc, score in results_with_score:
print(f"L2距离: {score:.4f} | {doc.page_content[:60]}...")Chroma 分数解读:
similarity_search_with_score返回的分数取决于距离度量方式。默认是 L2 距离(欧氏距离),数值越低越相似 。如果希望使用余弦相似度,可以在创建 Chroma 时传入collection_metadata={"hnsw:space": "cosine"}。
2.6 主流向量数据库一览
除了 Chroma,LangChain 还支持众多向量数据库,它们各有特色:
| 向量数据库 | 类型 | 部署方式 | 适合规模 | 特色 | 安装 |
|---|---|---|---|---|---|
| Chroma | 嵌入式/服务 | 本地进程 | 小~中型 | 零配置、自带 UI、深度集成 | pip install chromadb |
| FAISS | 索引库 | 本地文件 | 小~超大型 | 极速、GPU 加速、久经考验 | pip install faiss-cpu |
| Pinecone | 云服务 | SaaS | 中~超大型 | 全托管、免运维、企业级 | pip install pinecone-client |
| Weaviate | 数据库 | 本地/云 | 中~大型 | 混合搜索(向量+关键词)、GraphQL | pip install weaviate-client |
| Milvus | 数据库 | 本地/云 | 大~超大型 | 分布式、十亿级、超高性能 | pip install pymilvus |
| Qdrant | 数据库 | 本地/云 | 中~大型 | 高性能、Rust 编写、过滤能力强 | pip install qdrant-client |
| PGVector | PostgreSQL 扩展 | 本地/云 | 中~大型 | 复用现有 PG 基础设施 | pip install pgvector |
| Redis | 缓存/数据库 | 本地/云 | 中~大型 | 超低延迟、适合高并发实时场景 | pip install redis |
简单选型建议:
- 学习、原型验证 → Chroma
- 单机高性能需求 → FAISS(纯C++,速度第一)
- 正式生产环境,需要托管 → Pinecone 或 Qdrant
- 十亿级超大规模 → Milvus
3. 用 LCEL 串联成 RAG 链
前面我们已经掌握了 Embedding(文本→向量)和 VectorStore(存储+检索)。按理说应该可以搭建一个简单 RAG 了:用户问题 → 向量检索 → 获取相关文档 → 塞给 LLM 生成回答。
但实际编写链式代码时,你可能会碰到这个困惑:每个零件都会用,但不知道如何用 LCEL 的 | 把它们串起来。这一节我们就从一个最简单的翻译任务链开始,一步步理解为何和如何构造字典、透传数据、转换类型,最终拼出一条完整的 RAG 链。
回顾知识 :在 LangChain 的 LCEL中,管道
|连接各个组件时有两条铁律:
- 铁律① :管道中每一个环节都必须是
Runnable子类- 铁律②:前一个环节的输出类型,必须与后一个环节的输入类型匹配
3.1 从最简链起步回顾链知识
先不管 RAG,只看一个极简链:用户输入句子和目标语言,LLM 翻译。
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 定义 Prompt 模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译助手,请把用户输入的句子翻译成{target_language}。"),
("human", "{sentence}"),
])
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 串联成链
chain = prompt | llm | StrOutputParser()
# 调用
result = chain.invoke({
"sentence": "今天天气真好,我们去爬山吧。",
"target_language": "English",
})
print(result) # → "The weather is really nice today, let's go hiking."验证两条铁律:
| 环节 | 是 Runnable? | 输入 | 输出 |
|---|---|---|---|
prompt (ChatPromptTemplate) |
✅ | dict (如 {"sentence":"...","target_language":"..."}) |
ChatPromptValue |
llm (ChatOpenAI) |
✅ | ChatPromptValue (兼容类型) |
AIMessage |
StrOutputParser |
✅ | AIMessage |
str |
一切完美匹配,所以 prompt | llm | StrOutputParser() 能正常工作。
3.2 VectorStore 为什么不能直接放入链中?
当我们思考如何将RAG流程写入链中,一个很自然的想法是:VectorStore 的 similarity_search 输入是 str,输出是 List[Document],能不能直接写 vectorstore | prompt | llm 呢?答案是不能,原因有二:
原因一:VectorStore 本身不是 Runnable
VectorStore 是一个封装类,没有实现 invoke 等 Runnable 接口,所以语法上就无法放入管道。
原因二:输入输出类型也不匹配
即使强行包装成 Runnable,数据流依然断裂:
VectorStore.similarity_search(query: str, k: int = 4) → List[Document]
↑ 只有 query 这一个输入 ↓ 只输出文档列表
但 Prompt 需要的是 dict 类型,并且prompt 需要的内容是: {"question": str, "context": str, ...} 不止需要检索输出的内容 context,还需要用户的question问题。简单总结原因二:
| 问题 | 具体表现 |
|---|---|
| 类型不匹配 | List[Document] 无法被 Prompt 模板直接消费 |
| 数据丢失 | 用户原始输入(如目标语言等任务问题需求)经过检索环节后丢失,无法透传给下游 |
3.3 解决方案:as_retriever() + 字典构造 + RunnablePassthrough + lambda
3.3.1 as_retriever():让 VectorStore 变成 Runnable
为了解决第一个问题,所有 VectorStore 都提供了一个 as_retriever() 方法,它会返回一个 VectorStoreRetriever 对象,该对象是 Runnable 的子类,实现了统一的 invoke 接口: invoke(query: str) → List[Document]。于是铁律①满足了。
python
retriever = vectorstore.as_retriever()
# 现在 retriever 是 Runnable 了,可以放进链里
# 直接调用 invoke,验证它是 Runnable
docs = retriever.invoke("年假有几天?") # 输入字符串,输出 List[Document]这就是
as_retriever()是"VectorStore 通向 LangChain 链的出口"的原因。
关键认知:
- invoke 背后自动完成了两件事:用 VectorStore 内置的 Embedding 模型把查询向量化,然后执行相似度检索。你无需手动调 embed_query。正因为它绑定了创建时的 Embedding 模型,所以同一套文档和查询使用同一个 VectorStore(即同一个 Embedding 模型),否则语义空间对不上。
- invoke 的输入是 str,输出是 ListDocument。这满足铁律①(是 Runnable)。
3.3.2 字典构造、RunnablePassthrough、lambda
有了 retriever,语法上可行了,但数据流仍然有问题:
retriever.invoke(query) → List[Document]
│
▼
prompt 需要 dict {"context": ..., "sentence": ..., "target_language": ...}
│
类型对不上! 且 sentence、target_language 被 retriever 丢弃了铁律②在这里失败,需要中间层来转换。要修补这个断层,我们需要在 retriever 和 prompt 之间插入一个"中间层",它必须同时解决两个问题:
| 问题 | 具体表现 |
|---|---|
| 类型不匹配 | retriever 输出 List[Document],prompt 需要 dict |
| 数据丢失 | 用户输入里的 sentence、target_language 经过 retriever 后就没了,prompt 拿不到 |
修补思路:
我们需要一种机制,能够:
- (解决类型不匹配)最后把这些字段汇聚成一个 dict {"context", "sentence", "target_language"},送给 prompt
- (解决数据丢失)保留原始输入的各个字段,用RunnablePassthrough(),提取 sentence 和 target_language 并透传
- (解决dict中context类型不匹配) 把 retriever 检索到的
List[Document]转成一段字符串,填入context
LangChain 为这三个需求分别提供了三个内置工具:字典构造 {...} 、RunnablePassthrough 、lambda 函数。下面逐一来看它们分别对应哪个问题、怎么用。
① 字典构造 {...} : 解决"最终要输出一个 dict"的问题
LCEL 中,用大括号 {...} 包裹的内容会被自动解析成一个 RunnableParallel 对象,它会把接收到的输入 完整复制给每一个分支,然后每个分支各取所需。它的作用是把多路处理结果合并成一个 dict。
直接看最简单的例子:
python
from langchain_core.runnables import RunnablePassthrough
# 假设输入是 {"name": "Alice", "age": 25}
demo = {
"username": lambda x: x["name"].upper(), # 取 name 并大写
"userage": RunnablePassthrough().pick("age") # 原样透传 age
}
print(demo.invoke({"name": "Alice", "age": 25}))
# → {'username': 'ALICE', 'userage': 25}这就解决了一个核心矛盾: 链的后续环节(prompt)要求输入是 dict,而我们可以用 {...} 手动构造出这个 dict。在我们的场景里,这个 dict 就是 {"context": ..., "sentence": ..., "target_language": ...}。
② RunnablePassthrough :解决"原始数据怎么原封不动往下传"的问题
有的字段(比如 sentence、target_language)我们不想做任何处理,只是想"从输入里取出来,原样放到输出 dict 里"。RunnablePassthrough 就是干这件事的:它把接收到的输入不做任何修改,直接透传。
python
passthrough = RunnablePassthrough()
print(passthrough.invoke("hello")) # → "hello"如果要只取 dict 中的某个字段,可以用 .pick():
python
pick_sentence = RunnablePassthrough().pick("sentence")
print(pick_sentence.invoke({"sentence": "天气真好", "other": 123})) # → "天气真好"在我们的链里,"sentence" 和 "target_language" 就靠它从原始输入里提取出来,原样填入最终 dict。
③ lambda 函数 : 解决"类型转换"问题
retriever 的输出是 List[Document],但 prompt 的 context 变量需要一个字符串。我们需要一个自定义的函数把文档列表格式化成一段文本。最轻量的方式就是用一个 lambda,LCEL 会自动把它包装成 RunnableLambda。详细lambda 自定义函数见这篇笔记。
先定义一个格式化函数:
python
def format_docs(docs):
"""把 Document 列表拼接成上下文字符串"""
return "\n\n".join(f"[资料{i}] {doc.page_content}" for i, doc in enumerate(docs, 1))然后在链里直接用 lambda x: format_docs(...) 即可完成转换。这样,List[Document] 就被无缝转成了 str,完美匹配 context 字段的类型需求。
3.4 完整组装
前面我们讲解了三个工具的基本使用,现在把它们组合起来解决我们的翻译任务链。
不过在动手写完整代码之前,先理解一个至关重要的数据流细节:
{...} 字典它把接收到的输入,完整复制一份,分发给每一个分支。这意味着 如果你的分支里放的是 retriever,它会收到整个 dict , 但 retriever 的 invoke 签名是 invoke(query: str),只接受字符串,不接受 dict。所以不能直接写,除非我们的问题就是一个直接的str,直接revoke的就是一个str:
python
# ❌ 不能这样写
"context": retriever要解决这个问题,就需要在分支内部把 "sentence" 字段从 dict 中提取出来,再传给 retriever。怎么做?有两种完全等价的写法。
写法 A:lambda 包装
python
# 辅助函数:格式化检索到的文档
def format_docs(docs):
return "\n\n".join(
f"[资料{i}] {doc.page_content}" for i, doc in enumerate(docs, 1)
)
"context": lambda x: format_docs(retriever.invoke(x["sentence"]))执行流程拆解:
- 分支收到完整 dict,赋值给
x x["sentence"]提取出字符串- 这个字符串作为参数,手动调用
retriever.invoke(...) retriever执行检索,返回List[Document]format_docs(...)把文档列表格式化成一段文本
这里有两个关键认知:
retriever.invoke(x["sentence"])里面的invoke不是链的入口invoke,而是我们在分支内部主动调用retriever这个 Runnable 对象的方法。- 链的入口
rag_chain.invoke(dict)把整个 dict 送进字典构造;字典构造再把 dict 完整复制给每个分支;我们写的这个分支传入给lambda参数x,然后执行lambda匿名函数。
写法 B:纯管道(我设想的 retriever | func 思路)
这种写法更"LCEL 化",但需要一个适配器来把 dict 转成 str:
python
from langchain_core.runnables import RunnablePassthrough
"context": RunnablePassthrough().pick("sentence") | retriever | (lambda docs: format_docs(docs))执行流程拆解:
RunnablePassthrough().pick("sentence"):从 dict 中取出"sentence"字段 → 输出一个str| retriever:接收这个str,执行检索 → 输出List[Document]| (lambda docs: format_docs(docs)):接收文档列表,格式化成str
完整代码
python
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 辅助函数:格式化检索到的文档
def format_docs(docs):
if not docs:
return "无参考资料"
return "\n\n".join(
f"[资料{i}] {doc.page_content}" for i, doc in enumerate(docs, 1)
)
# ===== 完整 RAG 链 =====
rag_chain = (
{
# 分支1:检索 + 格式化 → 填入 "context"
"context": lambda x: format_docs(
retriever.invoke(x["sentence"])
),
# 分支2:透传原始句子 → 填入 "sentence"
"sentence": RunnablePassthrough().pick("sentence"),
# 分支3:透传目标语言 → 填入 "target_language"
"target_language": RunnablePassthrough().pick("target_language"),
}
| prompt
| llm
| StrOutputParser()
)
# 调用
result = rag_chain.invoke({
"sentence": "The API returned a 500 internal server error due to null pointer exception.",
"target_language": "中文"
})
print(result)回顾整条 RAG 数据处理管道,我们把知识串联起来:
text
📄 各类文档(PDF / TXT / CSV / JSON / 网页)
│
▼
┌─────────────────────────────────────┐
│ ① Document Loader(数据加载) │
└─────────────────────────────────────┘
│ List[Document]
▼
┌─────────────────────────────────────┐
│ ② Text Splitter(文本切分) │
└─────────────────────────────────────┘
│ List[Document](小块)
▼
┌─────────────────────────────────────┐
│ ③ Embedding(向量化)🤖 │
│ · 文本 → 向量 │
│ · 语义相似 ≈ 向量距离近 │
│ · 离线用 embed_documents() │
│ · 在线用 embed_query() │
│ · 两次必须用同一个模型! │
└─────────────────────────────────────┘
│ List[float] × N
▼
┌─────────────────────────────────────┐
│ ④ VectorStore(向量存储与检索) │
│ · 存储:add_documents / add_texts │
│ · 检索:similarity_search │
│ · 高级:MMR(多样性)、分数过滤 │
│ · Chroma → 快速入门 │
│ · FAISS → 高性能本地 │
│ · Pinecone/Milvus → 生产级 │
└─────────────────────────────────────┘
│ List[Document](最相关的 K 个)
▼
┌─────────────────────────────────────┐
│ ⑤ Prompt 融合 + LLM 生成 │
│ · 问题 + 检索到的文档 → LLM │
│ · LangChain Chain 串联全流程 │
└─────────────────────────────────────┘以上为个人学习总结,旨在梳理个人理解。如有疏漏或不当之处,欢迎指正与交流。如果文章对你有帮助,别忘了点个赞、留个言,让更多的小伙伴看到~ 我们下篇再见!