一、本章学习目标
-
描述 MapReduce 的 map → shuffle → reduce 数据流
-
说清楚 coordinator 如何调度任务、维护状态
-
分析 worker crash 后的重试策略
-
说明临时文件、原子重命名、locality、backup task 的作用
二、Word Count词频统计
1、引入
词频统计的特点:
- 输入:大规模文档集合
- 输出:各单词的出现次数
单机词频统计的局限:
当数据规模增大后,单机方案面临:
-
输入数据无法全部载入内存
-
单机 CPU 算不过来
-
中间结果也放不下
使用MapReduce可以有效解决以上困难
MapReduce将单机问题分解为可以并行的子任务:
- 将输入切分为多个独立分片
- 各分片由独立的map任务并行处理
- 中间结果经过shuffle后由reduce任务聚合
核心思想:数据并行
MapReduce 的核心逻辑:把超大的整体数据,切成很多份小数据块,分给多台机器同时并行计算,最后再汇总结果
整套流程分成 Map(分治计算)→ Shuffle(分拣转运)→ Reduce(汇总合并) 三大步
2、详细流程
第一阶段:切分输入
-
输入数据被切成多个 split(分片)
-
每个 split 对应一个 map 任务
-
不同 map 任务可以并行执行
-
coordinator 负责分配
map 任务的执行逻辑(map 任务主要做什么?)
-
读取一个 input split 的内容
-
调用用户定义的
map函数 -
生成中间 key/value 对
输入: "hello world hello"
输出: ("hello", "1"), ("world", "1"), ("hello", "1")
map 函数:
Go
func Map(key string, value string) []KeyValue {
kva := []KeyValue{}
for _, w := range range strings.Fields(value) {
kva = append(kva, KeyValue{Key: w, Value: "1"})
}
return kva
}注:return kva 为返回值(key / value 对列表)
注意:map 阶段生成的结果并非是最终结果
同一个单词可能出现在多个 map worker 的输出中,需要后面聚合
第二阶段:按 Key 分桶(Partition)
每个 map worker 在执行完 map 任务后,把中间结果分成 R 份(R = reduce 任务数量)
常用分区函数:
hash(key) mod R
关键 :同一个 key 的所有值必须落入同一个分区(这样才能让同一个 reduce 任务聚合同一个单词)
为什么不把全部结果集中到一台机器?
-
单点瓶颈,网络拥塞
-
reduce 无法并行
分桶对 Reduce 端的意义:
-
同一 key 的所有中间值落入同一 reduce 分区
-
不同 key 的值可分布至不同 reduce worker
-
各 reduce 任务可以独立并行完成聚合
分桶让 reduce 可以并行执行
第三阶段:Shuffle(数据重分发)
什么是 shuffle?
Shuffle 是 map 和 reduce 之间的数据重分发阶段:
-
map worker 把中间结果写入本地磁盘
-
reduce worker 跨节点拉取属于自己分区的数据
-
本质是一次 all-to-all 数据传输
但注意:网络带宽与磁盘 I/O 均是潜在瓶颈
第四阶段:排序与分组
reduce 在 shuffle 过程中拉取完自己分区的数据后
在执行聚合操作前,先要对中间数据进行排序:
- 按 key 升序排序
- 将具有相同 key 的 value 聚集为连续区段
- 从而保证 reduce 函数可以顺序处理每个 key 对应的完整 value
为什么要排序?
-
不排序:同一个 key 的值散落在各处,不好聚合
-
排序后:同一个 key 的值连续排列 ,reduce 可以顺序扫描
第五阶段:Reduce聚合
每个 reduce 任务:
-
接收属于自己分区的所有中间数据
-
排序、分组
-
调用
reduce函数 -
输出最终结果
输入: "hello", "1", "1", "1", "1"
输出: "hello", "4"
reduce 函数:
Go
func Reduce(key string, values []string) string {
return strconv.Itoa(len(values))
}注:return的返回值(该 key 的聚合结果)
reduce 阶段的输出:
- 每个 reduce 任务写入一个独立的输出文件
- 一共会产生 R 个输出文件,这个写入过程天然并行
总结(MapReduce的标准执行路径)
- coordinator 将 input split 分配给 map worker
- map worker 在本地磁盘写入中间文件
- reduce worker 跨节点拉去对应分区的中间数据
- reduce worker 对数据进行排序、分组、并调用 reduce 函数
- 最后输出写入全局文件系统
输入分片(M 个 split)
↓ map 阶段(并行)
中间 key/value 对(按分区存于本地磁盘)
↓ shuffle 阶段(all-to-all 网络传输)
各 reduce 分区的中间数据集合
↓ 排序 + reduce 阶段(并行)
输出文件(R 个)
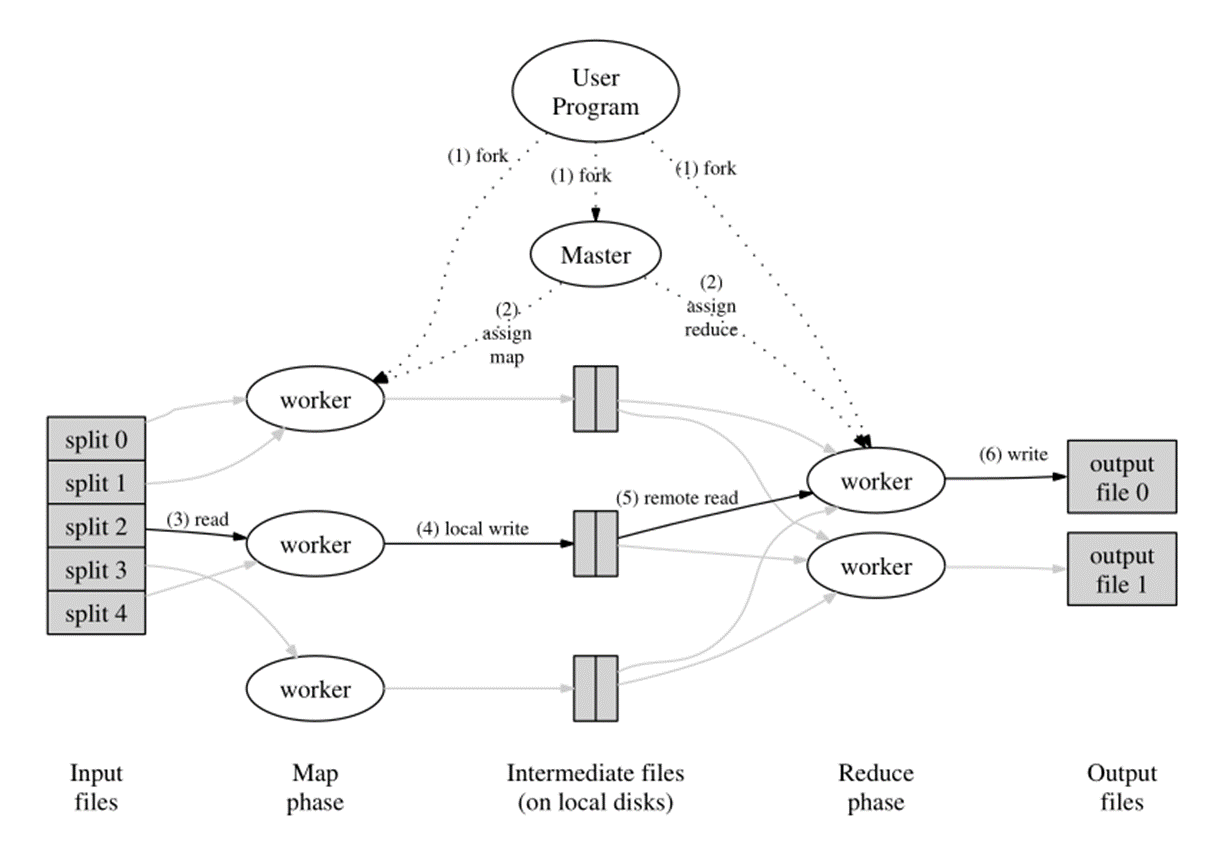
3、Coordinator 的作用
coordinator 是分布式作业的调度与记账中心
它负责:
-
决定哪个 worker 执行哪个任务
-
追踪哪些任务已完成
-
向 reduce 端通报中间文件的位置信息
但 coordinator 不参与业务计算:
-
不执行 map 函数
-
不执行 reduce 函数
他只负责:1.任务调度;2.状态维护;3.元信息转发
coordinator 为每个任务维护三个状态:
| 状态 | 含义 |
|---|---|
| idle | 还没分配 |
| in-progress | 已分配,正在执行 |
| completed | 已完成,结果可用 |
completed 状态不可省略:如果只有 idle/in-progress,coordinator 无法确认任务是否真的结束了,导致 reduce 端无法判断 map 结果是否可用
除了任务状态,coordinator 还要记录:
-
每个 map 任务在哪个 worker 上执行(谁现在在做)
-
各 map 任务的中间文件的位置(map 之后放到哪了)
-
各 reduce 任务的当前状态及是否具备启动条件
中间文件位置由 coordinator 统一管理
reduce 端在拉取数据时需要知道:
-
目标节点的网络地址
-
具体的文件路径
-
对应的 map 任务编号
coordinator 转发的是文件位置,不是文件内容。 真实数据由 worker 之间直接传输。
4、 Worker的执行循环:
for {
向 coordinator 请求任务
如果是 map 任务:执行 map,写入本地中间文件
如果是 reduce 任务:拉取数据,执行 reduce,写入输出
向 coordinator 报告完成
}
5、调度目标:最大化资源利用效率
-
有空闲 worker 就尽快分配任务
-
有可调度任务时,避免资源空转
-
尽可能维持较高的并行度
6、任务粒度:任务数量应 > worker 数量
10 台 worker,不要只分 10 个任务:
-
快的 worker 可以多干(干完一个再领一个)
-
慢的 worker 不会拖累整体
-
故障后重试的代价更小
7、工程实践中的经验参数
-
每个 map 任务通常对应 16 MB 至 64 MB 的输入数据
-
M 与 R 通常均大于 worker 数量
-
R 的取值同时决定最终输出文件的数量
8、worker 故障后的处理
1)故障检测机制
coordinator 用超时检测:
-
周期性向 worker 发送探测请求
-
超过规定时间没收到响应 → 将该 worker 标记为 failed
2)检测到故障后的第一步
coordinator 立即做两件事:
-
把该 worker 上 in-progress 状态的任务退回到 idle状态
-
更新 worker 状态记录,将其重新放入待调度队列
-
重新分配给别人,由其他 worker 重新执行,从而确保作业继续向前推进
3)map 和 reduce 的处理规则一样吗?
| 任务类型 | 故障时怎么处理 | 原因 |
|---|---|---|
| map in-progress | 重新调度 | coordinator 不知道它执行到哪了 |
| reduce in-progress | 重新调度 | 同上 |
| map completed | 可能需要重新执行 | 输出在故障节点的本地磁盘上,reduce 读不到了 |
| reduce completed | 通常不需要重新执行 | 输出在全局文件系统(GFS/HDFS)上,其他节点能读到 |
为什么 map 完成的结果也会丢?
-
map 中间结果写的是 本地磁盘
-
优点:写入速度快,无需网络传输
-
代价:worker 故障后,该节点的中间文件随之不可访问
-
-
worker 一挂,本地磁盘就访问不了了
-
所以已完成 map 任务也要重新执行
为什么 reduce 完成的结果不丢?
-
reduce 输出写的是 全局文件系统(GFS/HDFS)
-
worker 挂了,文件还在,其他节点依然可以访问
Coordinator如何处理旧结果和新结果的共存
- 不删除旧文件
- coordinator 仅发布当前认可的中间文件位置元信息
- reduce 端依据 coordinator 提供的最新位置进行数据拉取
9、如何防止读到半成品文件?
如果 worker 执行到一半挂了,留下一堆不完整的文件怎么办?
答:临时文件 + 原子提交
Map 中间数据、Reduce 输出结果均先写入带临时标识文件,未完成计算绝不生成正式输出,隔离残缺、不完整数据
原子重命名定义:文件改名是不可分割的原子操作,只有成功 / 失败两种状态,无中间错乱
整套机制解决三大分布式痛点
- 任务崩溃不会残留损坏正式文件
- 多机器并行执行同一任务时,不会互相覆盖结果
- 保证 Job 全部完成后,完整数据集才对外可见
Go
// 先写临时文件
tmp, _ := os.CreateTemp("", "mr-out-tmp-*")
// ... 写入 reduce 结果 ...
// 写入完成后,原子提交
os.Rename(tmp.Name(), fmt.Sprintf("mr-out-%d", reduceTaskId))10、与之前提到的故障语义的关联
| 故障语义 | MapReduce 的应对 |
|---|---|
| timeout 不等同于未执行 | 重新调度任务,但有状态机保护 |
| retry 可能导致重复执行 | 用临时文件 + 原子提交保证结果正确 |
11、结果正确性的前提:确定性函数
如果 map 和 reduce 函数都是确定性 的(相同输入、多次执行产生相同输出),则最终结果与一次无故障的顺序执行结果等价
什么是确定性函数?
确定性函数满足:1.相同输入;2.相同程序逻辑;3.多次执行产生相同输出
非确定性函数的风险:
-
同一个 map 任务执行两次可能产生不同结果
-
不同 reduce 可能消费不同执行版本的结果
-
结果的可推理性降低
12、性能优化
1)Locality(数据本地性)
即:优先把 map 任务调度到存有该数据副本的 worker 上
好处:本地读文件比跨网络读快得多
2)Partition 函数
默认:hash(key) % R,把 key 均匀分配到各个 reduce
3)分区排序
每个 reduce 分区内,系统保证:
- 中间 key/value 按 key 升序处理
- 最终各分区输出文件亦为有序
- 便于下游按 key 进行查找或合并
4)Combiner(本地预聚合)
在 map 端先做一次局部聚合,减少 shuffle 的数据量。
如:Word Count 中,一个 map worker 产生了 1000 个 ("the", 1),在 map 端先合成 ("the", 1000),再传给 reduce。
|--------|---------------|---------------|
| 属性 | Combiner | Reduce |
| 执行位置 | map worker 本地 | reduce worker |
| 目的 | 缩减中间数据量 | 产生最终输出 |
| 调用时机 | map 完成后 | shuffle 完成后 |
5)尾部延迟 & Straggler 问题
什么是尾部延迟?
作业临近结束时,往往不因故障而阻塞,而因慢节点而延迟
产生慢节点的原因:
- 机器磁盘性能下降
- 节点上运行多个竞争资源的进程
- CPU、内存或网络带宽被其他任务占用
什么是 Straggler ?
Straggler 指执行速度异常缓慢的 worker
如何解决以上两个问题?
Backup Task(推测执行)
当作业接近完成时,系统对尚未完成的慢任务采取以下措施:
- 为其启动一个备份执行(backup task)
- 原执行与备份执行并发运行
- 以先完成者的结果为准,另一方的执行结果丢弃
代价 vs 收益:
-
代价:少量额外计算资源
-
收益:显著缩短作业尾部时间
三、总结
MapReduce 的适用场景
-
大规模离线批处理
-
各输入记录之间相对独立
-
可以接受批量计算完成后再拿结果
不适合:
| 场景 | 原因 |
|---|---|
| 迭代式算法(机器学习、图计算) | 每轮都要完整读写磁盘,太慢 |
| 实时流处理 | 调度和 shuffle 开销太大 |
| 低延迟交互式查询 | 响应时间太长 |
| 强依赖共享可变状态 | MapReduce 不擅长处理共享状态 |
回顾开头提出的问题:
| 问题 | 答案 |
|---|---|
| worker 故障后重新调度哪些任务? | in-progress 任务退回 idle 重新调度;已完成 map 任务若结果在本地磁盘,也须重做 |
| 已完成中间结果是否可信? | map 中间结果在本地磁盘,worker 挂了就不可访问;reduce 结果在全局文件系统,可信 |
| 整个作业是否须从头重做? | 不用,只重做受影响的任务 |
核心概念速记:
-
数据流:map → shuffle → reduce
-
状态机:idle → in-progress → completed
-
容错:超时检测 + 任务重试 + 临时文件 + 原子重命名
-
优化:locality + combiner + backup task