一、Efficient Estimation of Word Representations in Vector Space
论文中提到了skip-gram 和 CBOW,这里重点理解skip-gram
1.1原始Skip-gram
python
import torch
import torch.nn as nn
class SkipGram(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
# Projection layer
self.embedding = nn.Embedding(
vocab_size,
embed_dim
)
# Output layer
self.output = nn.Linear(
embed_dim,
vocab_size
)
def forward(self, center_word):
h = self.embedding(center_word)
logits = self.output(h)
return logits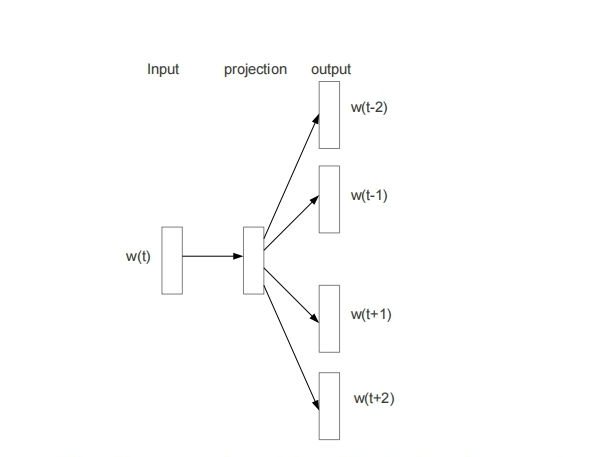
训练skip-gram
I love deep learning, windows = 2,即中心词前一个词,和后一个词
center=love, love, deep, deep
target = I , deep, love, learning
训练代码
python
model = SkipGram(vocab_size, 300)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(),
lr=1e-3
)
for center, target in loader:
logits = model(center)
loss = criterion(
logits,
target
)
optimizer.zero_grad()
loss.backward()
optimizer.step()logits = model(center) 中的logits 是 词汇表中每个词出现的概率
target 是 词汇表中,第几个词
如果窗口变成5, 例如 0:I 1:love 2:deep 3:learning 4:and 5:neural 6:networks 7:very 8:much
以 neural 为中心词,windows = 5 , 可以生成10个样本
(neural , I) (neural , love ) (neural , deep ) (neural , learning) (neural , and )
(neural , networks ) (neural , very ) (neural , much)
如果是 CBOW模式,只能生成1个样本
([w0 w1 w2 w3 w4,)
w6 w7 w8 w9 w10],
w5)
- 在word2Vec 中,windows=5指的是,左右各5个
- 根据上面的例子,可以看到CBOW的基本思想是,根据上下文,预测中心词,所以训练样本是中心词的左右各5个词,目标是中心词;Skip-Gram 是根据中心词,预测周围词,所以输入样本是这样的,中性词,左边第3个、中性词,左边第2个、中性词,左边第1个、中性词,右边第1个、中性词,右边第2个、中性词,右边第3个
二、 Distributed Representations of Words and Phrasesand their Compositionality
观察上面的网络模型发现,例如词向量的维度300,如果词汇表是10w,那么网络每次都输出10w x 300,然后softmax(10w个词),计算量很大,从我们的认知来说,其实每次预测,根本就不用将词汇表里面的词汇都预测一遍,词与之间是有联系的,真正需要更新的其实只是一个正样本词和少量负样本词。
2.1 Negative Sampling
正常情况下,skip-gram 中的 I love deep learning
中心词:love 上下文: I deep,训练对input -> target: love -> I love -> deep
预测这两个,需要在整个词表中做softmax
在 Negative Sampling 思想中,
正样本: (love, I)
负样本:(love, apple)(love, banana) (love, car) (love, tiger)(love, phone)
变成了二分类:是不是上下文词?
原来的损失函数:
−logP(wo∣wI)-logP(w_o|w_I)−logP(wo∣wI)
变成了:
logσ(−vOTvI)+∑i=1klogσ(−vNiTvI)log\sigma(-v_O^Tv_I)+\sum_{i=1}^klog\sigma(-v_{N_i}^Tv_I)logσ(−vOTvI)+i=1∑klogσ(−vNiTvI)
其中:正样本1个,负样本k个,通常k=5
SkipGramNS
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SkipGramNS(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
# syn0
self.in_embed = nn.Embedding(
vocab_size,
embed_dim
)
# syn1neg
self.out_embed = nn.Embedding(
vocab_size,
embed_dim
)
def forward(
self,
center_words,
pos_words,
neg_words
):
"""
center_words : [B]
pos_words : [B]
neg_words : [B,K]
"""
center = self.in_embed(
center_words
)
pos = self.out_embed(
pos_words
)
# 正样本
pos_score = torch.sum(
center * pos,
dim=1
)
pos_loss = F.logsigmoid(
pos_score
)
# 负样本
neg = self.out_embed(
neg_words
)
neg_score = torch.bmm(
neg,
center.unsqueeze(2)
).squeeze(2)
neg_loss = F.logsigmoid(
-neg_score
).sum(1)
loss = -(pos_loss + neg_loss)
return loss.mean()2.2、SkipGramNS我的理解
- 之前的SkipGram的输入是中心词,以及中心词的一个窗口内的上下文词,SkipGramNS需要再输入k=5该中心词的随机采样词,例如一下:
center = love
positive = I
negative = apple, car, banana, phone, tiger - 有两个词向量nn.Embedding,中心词独享一个,正样本和负样本共享一个nn.Embedding;
- 正样本分数,是正样本词向量和中心词向量的向量内积;
- 负样本分数,是负样本词向量和中心词向量的向量内积;
- 模型需要拉进正样本和中心词之间的距离,拉大负样本和中心词的距离,因此模型的loss为loss=−logσ(spos)−∑(logσ(−sneg))loss = -log\sigma(s_{pos})-\sum(log\sigma(-s_{neg}))loss=−logσ(spos)−∑(logσ(−sneg))
从而推动正样本内积越来越大、负样本内积越来越小,使中心词靠近真实上下文词,远离随机采样词。
2.3、SkipGramNS我的思考
2.3.1 、为什么中心词一个nn.Embedding,正样本和负样本一个,为什么不能三个输入共享一个;
理论上正样本、负样本和中心词,使用一个nn.Embedding也可以,这里作者之所以使用两个,是认为中心词和正负样本在整个优化过程中扮演不同的角色,如果两种角色是相互矛盾的,那么放到一起学习,学到的向量必然是不好的,分开学习,可以让两种角色的特征都学的很好;如果两种角色是相互依赖,相互促进的,那么三个共享一个nn.Embedding效果最好。有时候用几层卷积,几个分支,很多时候是根据设计者对当前任务的理解。
2.3.2、原始的SkipGram的优化目标是,为什么可以由预测词汇表中所有词的概率,求最大的那个,如此丝滑的将优化目标变为,正样本与中心词相似度-负样本与中心词相似度呢?
这里有很多思考,可以看,初版的skip-gram 最后一层的思想:所有词汇表中,我的目标词汇的概率最大,其实就是分类的思想,但是这里词汇表(类别)是如此之大,导致计算效率特别低,
1、导致计算量大的是词汇表的个数,为什么会用到词汇表的个数呢,因为最后一层使用softmax让目标词汇的概率最大,从而逼迫网络学习的词汇向量逼近目标词汇,远离非目标词汇;
2、经分析,softmax的目的其实是学习词向量,并不是真的去预测是哪个词汇,那么是不是可以跳过softmax的方法,于是NS顺势提取,就是不绕弯子了,之间在向量层上计算损失,就是输入正样本的向量与中心向量距离近,负样本向量与中心向量距离远;
3、对,这个思想和人脸中的Triplet Loss(三元组损失)是一致的,通过Triplet Loss训练后的人脸图片,可以生成人脸特征向量,用来做比对。
2.3.3 word2vec 和 lstm 、transformer的区别
1、skip-gram,的目标函数是
P(wo∣wc)P(w_o|w_c)P(wo∣wc)
例如I love deep learning,窗口=2,训练样本(love → I),(love → deep), (love → learning),所以,skip-gram只关系哪些词经常一起出现,但是它不关心语法,顺序,和长距离依赖,本质上skip-gram学的是词共现统计,而不是语言生成,结构如下:
bash
中心词id
↓
Embedding
↓
词向量 vc
↓
与目标词向量点积
↓
sigmoid
↓
loss2、LSTM是语言模型:
P(wt∣w1,...,wt−1)P(w_t|w_1,...,w_{t-1})P(wt∣w1,...,wt−1)
例如 I love deep ? 预测:learning,在lstm 中,embedding 只是输入特征,核心是隐藏层ttt_ttt携带的上下文信息,结构如下:
bash
Embedding
↓
LSTM
↓
Hidden State
↓
Linear
↓
Softmax
↓
整个词表3、Transformer也是语言模型:
P(wt∣w1,...,wt−1)P(w_t|w_1,...,w_{t-1})P(wt∣w1,...,wt−1)
但是上下文建模换成了self-Attention:
H=Attention(Q,K,V)H = Attention(Q,K,V)H=Attention(Q,K,V),所以transformer学到的特征更强
2.3.4 lstm 、transformer都有自己的nn.Embedding, word2vec的作用是什么
1、 在word2vec出现之前,词用的ID来表示,例如cat -> 1001,dog -> 2003, apple -> 501,模型不知道cat 和 dog比较接近,cat 和 apple 不接近;
2、 word2vec出来后,cat , dog, apple 使用向量表示之后,这些向量可以表示语义,所以很多模型直接拿word2vec的结果来用,例如后面之间接LSTM,经常会看到:
python
embedding = nn.Embedding.from_pretrained(
word2vec_weight
)3、后来,BERT 和 GPT 出现后,发现模型完全可以自己学Embedding,不需要先训练word2vec,再训练模型,直接端到端训练。现在大模型训练流程:
bash
文本
↓
Tokenizer
↓
随机初始化Embedding
↓
Transformer
↓
预测下一个Token4、之前说过,word2vec提取的是静态词之前的关系,后面会看到BERT Embedding GPT Embedding 等不是独立模型,它们是Transformer训练过程中产生的表示。