目录
[2.LangChain 流式传输流程分析](#2.LangChain 流式传输流程分析)
[2.1 LangChain 请求 OpenAI 使用什么协议?](#2.1 LangChain 请求 OpenAI 使用什么协议?)
[2.2LangChain 如何支持流式传输?](#2.2LangChain 如何支持流式传输?)
[2.3 OpenAI 返回的块是什么格式,如何转换成 AIMessageChunk ?](#2.3 OpenAI 返回的块是什么格式,如何转换成 AIMessageChunk ?)
[维度三:状态维护与生命周期的解耦(Stateless vs Stateful)](#维度三:状态维护与生命周期的解耦(Stateless vs Stateful))
[WebSocket 缺陷](#WebSocket 缺陷)
[SSE 原生优势](#SSE 原生优势)
前言:
在传统Web应用中,用户发起请求,服务器处理完毕后一次性返回数据。但在大语言模型(LLM)时代,尤其是随着 DeepSeek-R1、o1 等推理模型(Reasoning Models)的普及,一个长文本或复杂推理的生成可能需要数十秒甚至数分钟。
如果采用传统的"等待-响应"模式,用户将面临漫长的白屏焦虑,首字延迟(TTFT, Time to First Token)高到无法接受。因此,流式传输成为了大模型应用的底层标配 。它不仅是前端的"打字机动画",更是一场从模型微观生成到宏观网络传输的全链路流水线(Pipeline)优化。
所以在学习Langchain的过程中,我感觉到流式推理底层的流式传输,或许能为我们打开一种新的剖解AI agent一个个封装的途径,以小窥大,所以写一下自己的所得。
1.SSE协议的前置了解
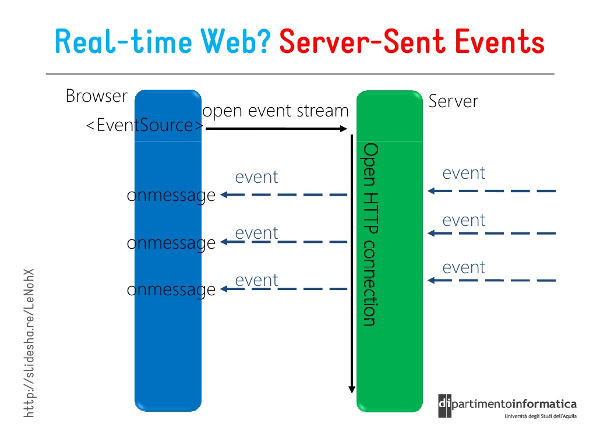
HTTP 协议本身设计为无状态的请求-响应模式,严格来说,是无法做到服务器主动推送消息到客户端,但通过 Server-Sent Events (服务器发送事件,简称 SSE)技术可实现 流式传输 ,允许服
务器主动向浏览器推送数据流。
也就是说,服务器向客户端声明,接下来要发送的是流消息(streaming),这时客⼾端不会关闭连接, 会⼀直等待服务器发送过来新的数据流。
SSE(Server-Sent Events)是⼀种基于 HTTP 的轻量级实时通信协议,浏览器可以通过内置的
EventSource API 接收并处理这些实时事件。
核心特点
- **基于HTTP协议。**复用标准HTTP/HTTPS协议,无需额外端口或协议,兼容性好且易于部署。
- **单向通信机制。**SSE仅支持服务器向客户端的单向数据推送,客户端通过普通HTTP请求建立连接后,服务器可持续发送数据流,但客户端无法通过同一连接向服务器发送数据。
- **自动重连机制。**支持断线重连,连接中断时,浏览器会自动尝试重新连接(支持retry字段指定重连间隔)。
- 自定义消息类型。 客户端发起请求后,服务器保持连接开放,响应头设置Content-Type:text/event-stream,标识为事件流格式,持续推送事件流。
当我们梳理完 SSE 的技术特点后会发现,它与嵌入式数据库领域的常青树 SQLite 拥有一个惊人一致的底层核心特质------极致的轻量化(Lightweight) 。这种轻量化并不是牺牲功能,而是在特定高频场景下,通过做减法来达到性能和部署的最高性价比。
数据格式
既然 SSE 和 SQLite 一样追求极致的轻量化,那它在网络层传输时必然不会引入复杂的二进制帧协议。实际上,SSE 的数据格式纯粹得令人发指------它就是纯文本流(Text Stream)。
当大模型后端(如 OpenAI、DeepSeek 或我们自己的 FastAPI 服务)准备好推流时,首先需要在 HTTP 响应头(Response Headers)中做出如下声明,告诉浏览器:"准备好,接下来的数据没有总长度,是个无尽的事件流":
Content-Type: text/event-stream; charset=utf-8
Cache-Control: no-cache这就是我们的HTTP请求头,那再看我们的消息部分。
每一次发送的消息,由若干个message组成,每个message之间由\n\n分隔,表示这一次的消息我已经发完了。而每个message内部由若干行组成,每一行都是如下格式:
[field]: value\nField可以取值为:
- data必需:数据内容
- event非必需:表示自定义的事件类型,默认是message事件
- id非必需:数据标识符,相当于每一条数据的编号
- retry非必需:指定浏览器重新发起连接的时间间隔
除此之外,还可以有冒号:开头的行,来表示注释。
如:
event: foo\n
data: a foo event\n\n
data: an unnamed event\n\n
event: end\n
data: a bar event\n\n那了解了SSE的核心,我们接下来就来看一下Langchain的流式传输流程。
2.LangChain 流式传输流程分析
前文我们也提到,LangChain 并不会自行定义或生成底层网络传输协议,它的网络通信完全依赖两层底层组件:一是大模型厂商(例如 OpenAI)提供的服务接口协议,二是业务应用所搭载的 Web 框架(例如 FastAPI)所遵循的网络规范。
基于这一架构,LangChain 具备流式输出能力的核心逻辑可以拆解为两点:
- 流式数据的源头由大模型服务商提供:厂商侧原生支持 SSE 等流式传输机制,能够分段返回模型生成内容;
- LangChain 仅做封装与数据标准化处理:它封装了厂商流式接口的调用逻辑,持续接收分段返回的数据,再统一解析、封装为标准的 AIMessageChunk 消息块,向上层业务提供统一格式的流式数据,屏蔽不同大模型厂商接口的差异化。
接下来我们将会通过分析相关源码探索整个传输流程。整个过程我们以OpenAI举例,其他大模型方式也是类似的。当我们向OpenAI发起流式请求,LangChain实际上会通过BaseChatOpenAI 类中的 _stream() 方法发起调用。
具体完整源码在class langchain_openai.chat_models.base.BaseChatOpenAI
python
def _stream(
self,
messages: list[BaseMessage], # 输⼊消息列表
stop: Optional[list[str]] = None, # 可选的停⽌词列表,⽤于指定⽣成终⽌条件
run_manager: Optional[CallbackManagerForLLMRun] = None, # 回调管理器,⽤于处理⽣成过程中的回调事件
*,
stream_usage: Optional[bool] = None, # 是否流式返回使⽤量统计信息
**kwargs: Any, # 其他可选参数
) -> Iterator[ChatGenerationChunk]:
# 1. 流式配置
kwargs["stream"] = True # 强制启⽤流式模式
stream_usage = self._should_stream_usage(stream_usage,** kwargs)
# 2. 请求构建
payload = self._get_request_payload(messages, stop=stop, **kwargs)
# 注意这⾥定义了AIMessageChunk传输块
default_chunk_class: type[BaseMessageChunk] = AIMessageChunk
base_generation_info = {}
# 3. 发起调⽤
# 3.1 指定 response_format 调⽤
if "response_format" in payload:
response_stream = self.root_client.beta.chat.completions.stream(**payload)
context_manager = response_stream
# 3.2 普通流式调⽤
else:
response = self.client.create(**payload)
context_manager = response
# 4. 响应处理
try:
with context_manager as response:
for chunk in response:
# 4.1 将 OpenAI 数据块转换为 AIMessageChunk 数据块
generation_chunk = self._convert_chunk_to_generation_chunk(
chunk,
default_chunk_class,
base_generation_info if is_first_chunk else {},
)
if generation_chunk is None:
continue
# 4.2 触发新token回调
if run_manager:
run_manager.on_llm_new_token(
generation_chunk.text,
chunk=generation_chunk,
logprobs=logprobs,
)
# 4.3 产出⽣成块
yield generation_chunk
# 5. 处理OpenAI API错误异常
except openai.BadRequestError as e:
_handle_openai_bad_request(e)从上述流程看来,这就是流式逐块产生AIMessageChunk 聊天消息的核心方法。那么接下来看三个问题:发起调用时,
- 底层使用什么协议?
- 如何支持流式传输?
- 返回的块是什么格式,如何转换成AIMessageChunk?
这三个问题都掌握后,整个流式传输的流程就都能理解了。
2.1 LangChain 请求 OpenAI 使用什么协议?
回答这个问题,需要看LangChain关于OpenAI的客户端是怎么定义的。让我们找到class
langchain_openai.chat_models._client_utils.SyncHttpxclientwrapper , 如下:
python
import openai
import os
class _SyncHttpxClientWrapper(openai.DefaultHttpxClient):
"""Borrowed from openai._base_client"""
def __del__(self) -> None:
if self.is_closed:
return
try:
self.close()
except Exception: # noqa: S110
pass
def _build_sync_httpx_client(
base_url: Optional[str],
timeout: Any
) -> _SyncHttpxClientWrapper:
return _SyncHttpxClientWrapper(
base_url=base_url
or os.environ.get("OPENAI_BASE_URL")
or "https://api.openai.com/v1",
timeout=timeout,
)我们可以看到:
openai.DefaultHttpxClient是 OpenAI 官方 SDK 内置的同步 HTTP 请求客户端,底层基于httpx实现 HTTP 通信,定义在openai._base_client模块;- LangChain 没有自己从零封装 HTTP 请求逻辑,而是直接继承官方 SDK 的原生 HTTP 客户端,仅新增析构函数做资源自动关闭,复用 OpenAI SDK 完整的底层网络逻辑;
- 构建客户端函数
_build_sync_httpx_client沿用官方逻辑:优先传入的base_url→ 环境变量OPENAI_BASE_URL→ 官方默认地址https://api.openai.com/v1,完全对齐 OpenAI SDK 配置规则。
所以,在调用时,发起的是HTTP调用!
2.2LangChain 如何支持流式传输?
开篇我们就提到,LangChain 本身不会自定义、制定底层网络传输协议,而是完全依赖底层大模型厂商(如 OpenAI)自身定义的通信协议。
在流式接口 `_stream()` 源码第一步中,会强制传入 `stream=True` 参数。该参数作用是告知 OpenAI 服务端采用 SSE(Server-Sent Events,服务器推送事件)流式返回响应内容。开启流式后,API 会持续保持 HTTP 长连接,按固定分段格式持续下发生成数据。
举个示例:使用原生 GPT 模型发起携带 `stream=True` 的请求,提问内容为「你好,我是张三。」,服务端会分段返回多条 SSE 数据块,简化后的有效载荷序列示例如下:
python
data:{
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1717500000,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": "你好"
},
"finish_reason": null
}
]
}
data:{
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1717500000,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"delta": {
"content": ","
},
"finish_reason": null
}
]
}
data:{
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1717500000,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"delta": {
"content": "张"
},
"finish_reason": null
}
]
}
data:{
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1717500000,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"delta": {
"content": "三"
},
"finish_reason": null
}
]
}
data:{
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1717500000,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"delta": {
"content": "!"
},
"finish_reason": null
}
]
}
data:{
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1717500000,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"delta": {
"content": "请问"
},
"finish_reason": null
}
]
}
....看了上述示例,我们就可以回答第二个问题:在请求参数中配置 stream=True,即可开启 OpenAI 服务端分块流式返回数据。LangChain 正是通过 _stream() 方法的第 1、2 步骤完成该配置与请求封装逻辑。
2.3 OpenAI 返回的块是什么格式,如何转换成 AIMessageChunk ?
OpenAI 返回的数据块格式前文已经展示,将原生 API 分块数据转换为 LangChain 自定义AIMessageChunk对象,核心依靠 _convert_chunk_to_generation_chunk() 方法完成转换逻辑,关键源码如下:
python
def _convert_chunk_to_generation_chunk(
self,
chunk: dict, # 从API获取的原始数据块,示例中即为OpenAI返回SSE数据块
default_chunk_class: type, # 待创建消息块类型,示例传入AIMessageChunk
base_generation_info: Optional[dict], # 基础生成信息
) -> Optional[ChatGenerationChunk]:
# 1. 提取选择项数据
choices = (
chunk.get("choices", [])
# 兼容beta.chat.completions.stream返回结构
or chunk.get("chunk", {}).get("choices", [])
)
# 2. 处理有效选择项
choice = choices[0]
if choice["delta"] is None:
return None
# 3. 转换增量数据为消息块,将API的delta格式转换为 AIMessageChunk
message_chunk = _convert_delta_to_message_chunk(
choice["delta"], default_chunk_class
)
# 4. 构建其他生成信息
generation_info = {**base_generation_info} if base_generation_info else {}
# 省略中间无关逻辑...
# 5. 返回封装完成的流式生成块
generation_chunk = ChatGenerationChunk(
message=message_chunk, generation_info=generation_info or None
)
return generation_chunk
python
def _convert_delta_to_message_chunk(
_dict: Mapping[str, Any], default_class: type[BaseMessageChunk]
) -> BaseMessageChunk:
# 1. 提取OpenAI格式增量数据
id_ = _dict.get("id")
role = cast(str, _dict.get("role")) # 获取消息角色
content = cast(str, _dict.get("content") or "") # 获取分段文本内容
additional_kwargs: dict = {}
# 解析函数调用数据
if _dict.get("function_call"):
function_call = dict(_dict["function_call"])
if "name" in function_call and function_call["name"] is None:
function_call["name"] = ""
additional_kwargs["function_call"] = function_call
tool_call_chunks = []
# 解析工具调用分段数据
if raw_tool_calls := _dict.get("tool_calls"):
additional_kwargs["tool_calls"] = raw_tool_calls
try:
tool_call_chunks = [
tool_call_chunk(
name=rtc["function"].get("name"),
args=rtc["function"].get("arguments"),
id=rtc.get("id"),
index=rtc["index"],
)
for rtc in raw_tool_calls
]
except KeyError:
pass
# 2. 根据角色字段,构造对应LangChain消息块对象
if role == "user" or default_class == HumanMessageChunk:
return HumanMessageChunk(content=content, id=id_)
elif role == "assistant" or default_class == AIMessageChunk:
return AIMessageChunk(
content=content,
additional_kwargs=additional_kwargs,
id=id_,
tool_call_chunks=tool_call_chunks, # type: ignore[arg-type]
)
elif role in ("system", "developer") or default_class == SystemMessageChunk:
if role == "developer":
additional_kwargs = {"__openai_role__": "developer"}
else:
additional_kwargs = {}
return SystemMessageChunk(
content=content, id=id_, additional_kwargs=additional_kwargs
)
elif role == "function" or default_class == FunctionMessageChunk:
return FunctionMessageChunk(content=content, name=_dict["name"], id=id_)
elif role == "tool" or default_class == ToolMessageChunk:
return ToolMessageChunk(
content=content, tool_call_id=_dict["tool_call_id"], id=id_
)
elif role or default_class == ChatMessageChunk:
return ChatMessageChunk(content=content, role=role, id=id_)
else:
return default_class(content=content, id=id_) # type: ignore到此我们就知道了 LangChain 流式传输的完整流程与底层协议。总结一下:
- langchain-openai 包通过集成 OpenAI Python SDK,提供了一个 HTTP 客户端。
- 因此,支持 LangChain 向 OpenAI 的 API 发起调用请求。
- 若希望发起流式传输请求,则需在请求中加入 stream=True,向 OpenAI 说明以 SSE 协议进行流式返回。
- LangChain 接收 OpenAI 的 SSE 格式的响应,并将其转换为 LangChain 自封装的消息格式,如 AIMessageChunk 消息。这样就可以以统一的方式处理来自不同模型提供商(OpenAI, Anthropic 等)的流式响应。
3.总结,为什么是SSE不是WebSocket?
通过前文对 LangChain 核心源码的拆解,我们可以上升一下维度 从调用栈、数据结构转换和状态机三个维度,推导出大模型流式传输必然选择 SSE(而不是 WebSocket)的深层技术必然性:
维度一:底层依赖的统一性
根据前文源码,LangChain 的 _SyncHttpxClientWrapper 直接继承 OpenAI SDK 的 DefaultHttpxClient,底层通信完全依托基于标准 HTTP 的 httpx 库。 如果改用 WebSocket: 需要新增 websockets、aiohttp 等 WebSocket 专用第三方库,同时改造厂商 API 网关,和当前 RESTful HTTP 整体架构冲突。
现有架构优势: 仅需一行 kwargs["stream"] = True,无需修改已有 HTTP 连接、无需新增依赖,服务端就能直接切换成长连接流式响应,最大化复用标准 80/443 端口的 HTTP/HTTPS 架构。
维度二:数据流向与对象转换的单向性
从 _convert_delta_to_message_chunk 源码可看出,数据流是纯单向流水线:
流程特征: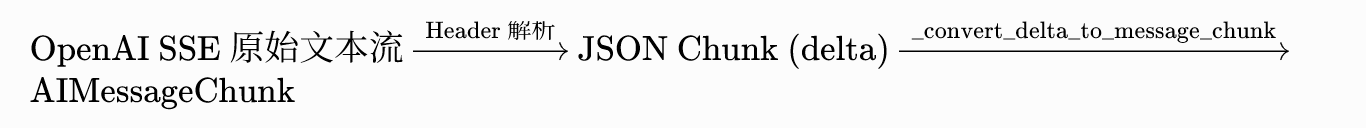
- 客户端通过
_stream()一次性提交完整请求载荷; - 服务端持续单向产出
AIMessageChunk并通过 yield 推送; - 整个流式生命周期,客户端不需要反向发送任何指令、数据。
WebSocket 全双工双向能力在此场景完全冗余,额外的帧封包、拆包逻辑会增加 CPU 性能损耗。
维度三:状态维护与生命周期的解耦(Stateless vs Stateful)
在分布式 AI、Agent 业务中,Nginx、K8s Ingress 等网关稳定性十分关键。
WebSocket 缺陷
属于有状态连接,握手后客户端固定绑定单一后端实例;大模型推理时常达数十秒至数分钟,极易触发网关超时断开,集群扩容、负载均衡难以平滑处理。
SSE 原生优势
代码中 with context_manager as response: 上下文依然保留标准 HTTP 语义:
- 出现
openai.BadRequestError等异常时,可直接复用 HTTP 标准异常捕获、网关重试能力; - SSE 自带 retry 机制,断连后客户端携带
chatcmpl-xxx事件 ID 自动重连恢复生成; - 传输层流式、应用层接近无状态,对长耗时推理模型容错能力更强。