前言
这是很多初学者在掌握 pd.read_csv() 和 df.head() 之后的真实困境。因为真实数据从来不是干干净净、整整齐齐的:
有缺失值(有的年份 GDP 没记录);
有重复行(数据不小心追加了两遍);
需要合并多张表(GDP 数据一张表,人口数据另一张表);
需要分组统计(分别看中国、日本、美国各自的 GDP 趋势)。
本文是 Pandas 系列的第三篇,在前两篇(数据结构与索引、基本操作与运算)的基础上,进入真实数据清洗与聚合分析的核心领域。
DataFrame数据的增删改查操作
导包并加载数据:
python
import pandas as pd
data = pd.read_csv('./1960-2019全球GDP数据.csv',encoding='gbk')
print(data.head())
增加列
方式一: 通过直接赋值的方式添加新列
python
# 拷贝一份data
data_copy = data.copy()
# 新增一列固定值
data_copy['new_col_1'] = 33
# 新增列数据数量必须和行数相等(可以用range或已有列计算)
# 假设data的行数为len(data)
data_copy['new_col_2'] = range(len(data)) # 或 [i for i in range(len(data))]
# 新增列使用已有列计算(比如年份*2,假设有year列)
data_copy['new_col_3'] = data_copy['year'] * 2
# 查看新增列后的df和原df
print(data_copy.head())
print(data.head())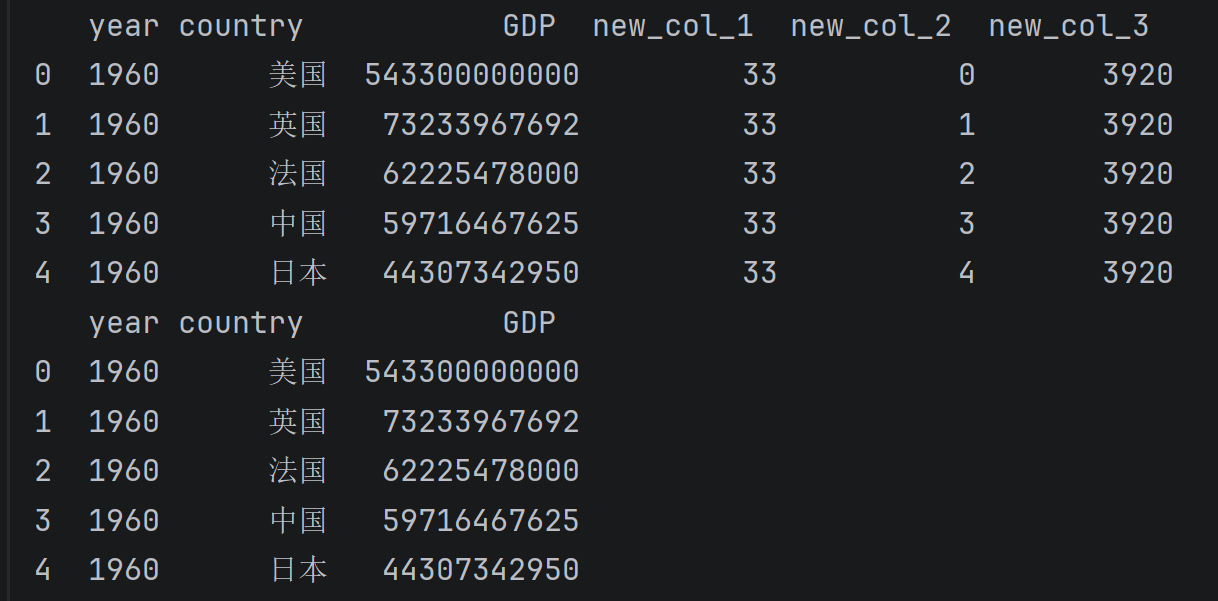
方式二: data.assign函数添加列
python
# 1.新增一列固定值
dataOne = data.assign(new0=88)
print(dataOne[['country', 'year', 'new0']].head())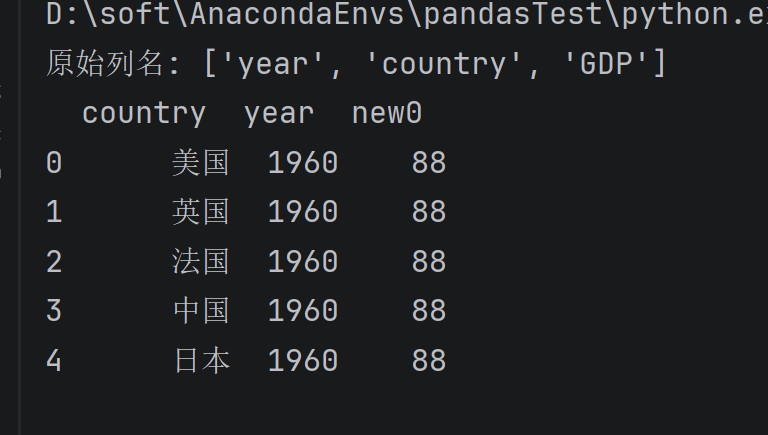
python
# 2. 新增一列,使用一组数据(数量必须与行数相等)
# 写死 [1,2,3,4,5] 会报错,这里动态生成等长序列
dataTwo = data.assign(new1=list(i for i in range(len(data))))
print("\n新增序号列后,前5行:")
print(dataTwo.head())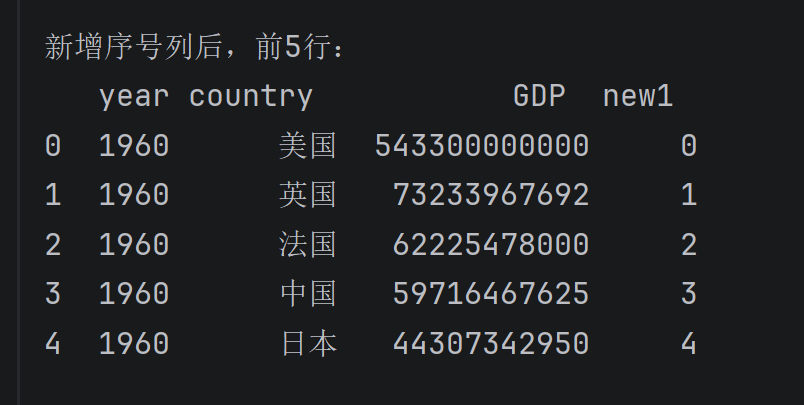
python
# 3. 新增一列,使用 Series 对象(索引会自动对齐)
# 创建一个索引与 data 相同的 Series(默认整数索引一致)
series = pd.Series(range(len(data)),index=data.index)
dataThree= data.assign(new2=series)
print(dataThree[['country', 'year', 'new2']].head())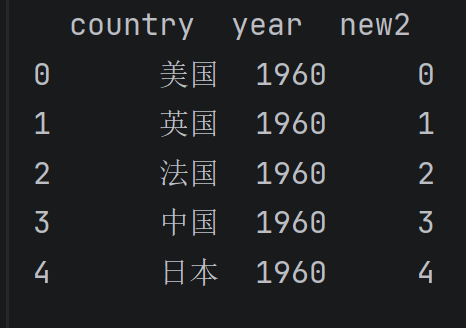
python
dataFour = data.assign(new3=data['year']+data['GDP'])
print("\n新增计算列 year+GDP 后:")
print(dataFour[['country', 'year', 'new3']].head())
python
def add(data):
# 该函数必须返回一个标量、一个与 df 等长的序列,或一个索引与 df 一致的 Series
print(f"\n自定义函数被调用,传入 data 的形状: {data.shape}")
# 这里我们返回索引值(与 data 行数一致)
return data.index.values # 返回 numpy 数组
dataFive = data.assign(new4=add(data))
print("\n新增自定义函数列 new4(即索引值)后:")
print(dataFive[['country', 'year', 'new4']].head())
# 额外:查看原 data 是否被修改(验证 assign 不改变原数据)
print("\n原始 data 仍然只有原始列:", data.columns.tolist())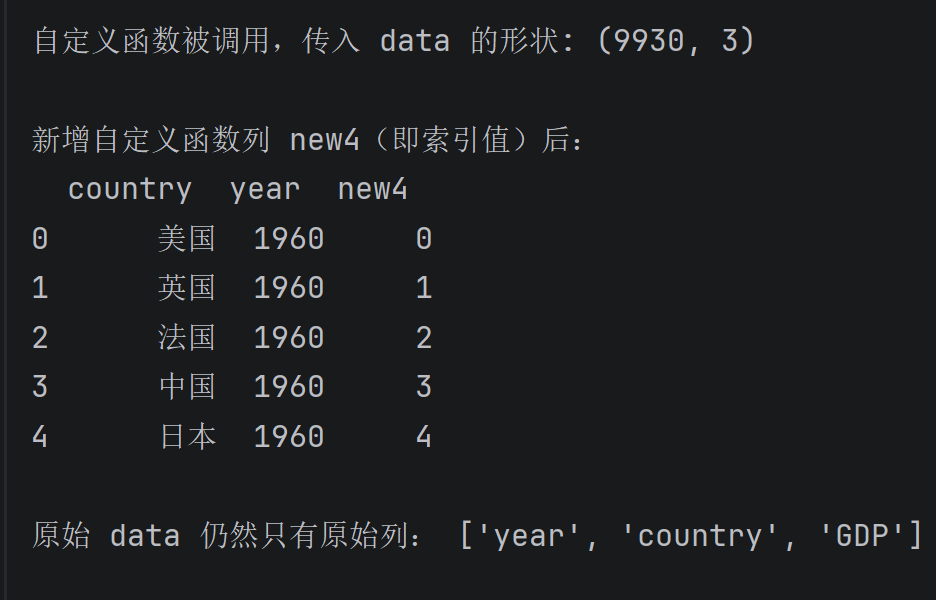
df.assign函数可以同时添加多列
python
def foo(data):
return 11
def bar(data):
return data.year+5
dataTwo = data.assign(
new0='heiehiheiheihei',
new1=list(range(len(data))),
new2=pd.Series(range(len(data)),index=data.index),
new3=data.year*2,
new4=foo(data),
new5=bar(data)
)
print(dataTwo[['country', 'year','GDP', 'new0', 'new1', 'new2', 'new3', 'new4', 'new5']].head())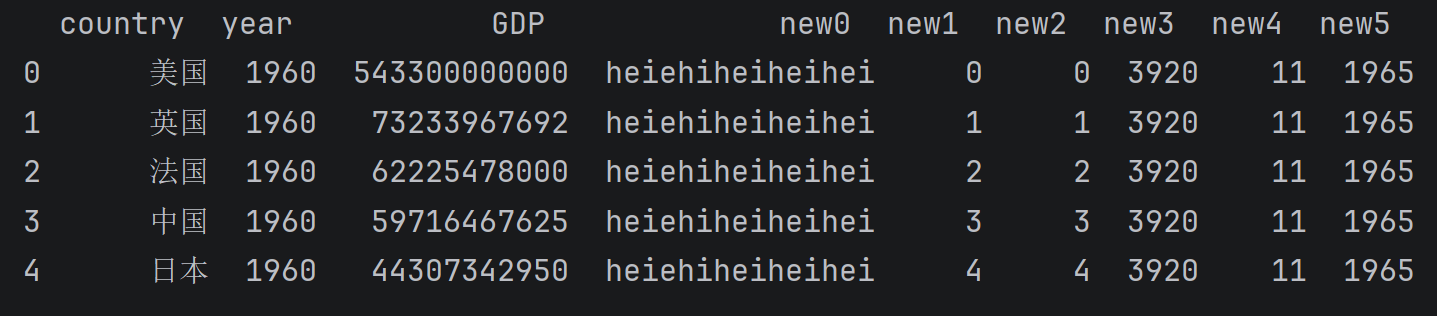
删除与去重
data.drop删除行数据
python
data.drop([0]) # 默认删除行
data.drop([0, 2, 4]) # 可以删除多行
data.GDP.drop([0, 2]) # 对series对象按索引删除data.drop删除列数据
- data.drop默认删除指定索引值的行;如果添加参数
axis=1,则删除指定列名的列
python
data.drop(['new col 3'], axis=1)使用del删除指定的列
- 注意区别:
- del是直接永久删除原df中的列【慎重使用】
- drop是返回删除后的df或seires,原df或seires没有被修改
python
del data['new col 3']Dataframe数据去重
python
import pandas as pd
data = pd.read_csv('./1960-2019全球GDP数据.csv',encoding='gbk')
print(f"原始数据行数: {len(data)}")
dataTwo = pd.concat([data, data], ignore_index=True)
print(f"追加自身后行数: {len(dataTwo )}") # 应该是原始行数的两倍
# 注意:drop_duplicates() 默认不修改原数据,需要重新赋值或加 inplace=True
dataThree = dataTwo .drop_duplicates() # 返回去重后的新 DataFrame
print(f"去重后行数: {len(dataThree)}") # 应该等于原始行数(因为重复行被删除了)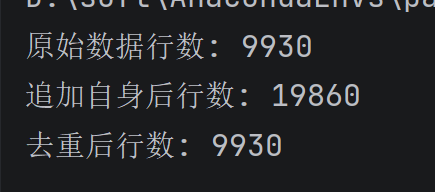
series去重
python
方式一:
data.country.drop_duplicates()
# 返回结果如下
0 美国
1 英国
2 法国
3 中国
4 日本
Name: country, dtype: object
方式二:
data.country.unique()
# 返回结果如下
array(['美国', '英国', '法国', '中国', '日本'], dtype=object)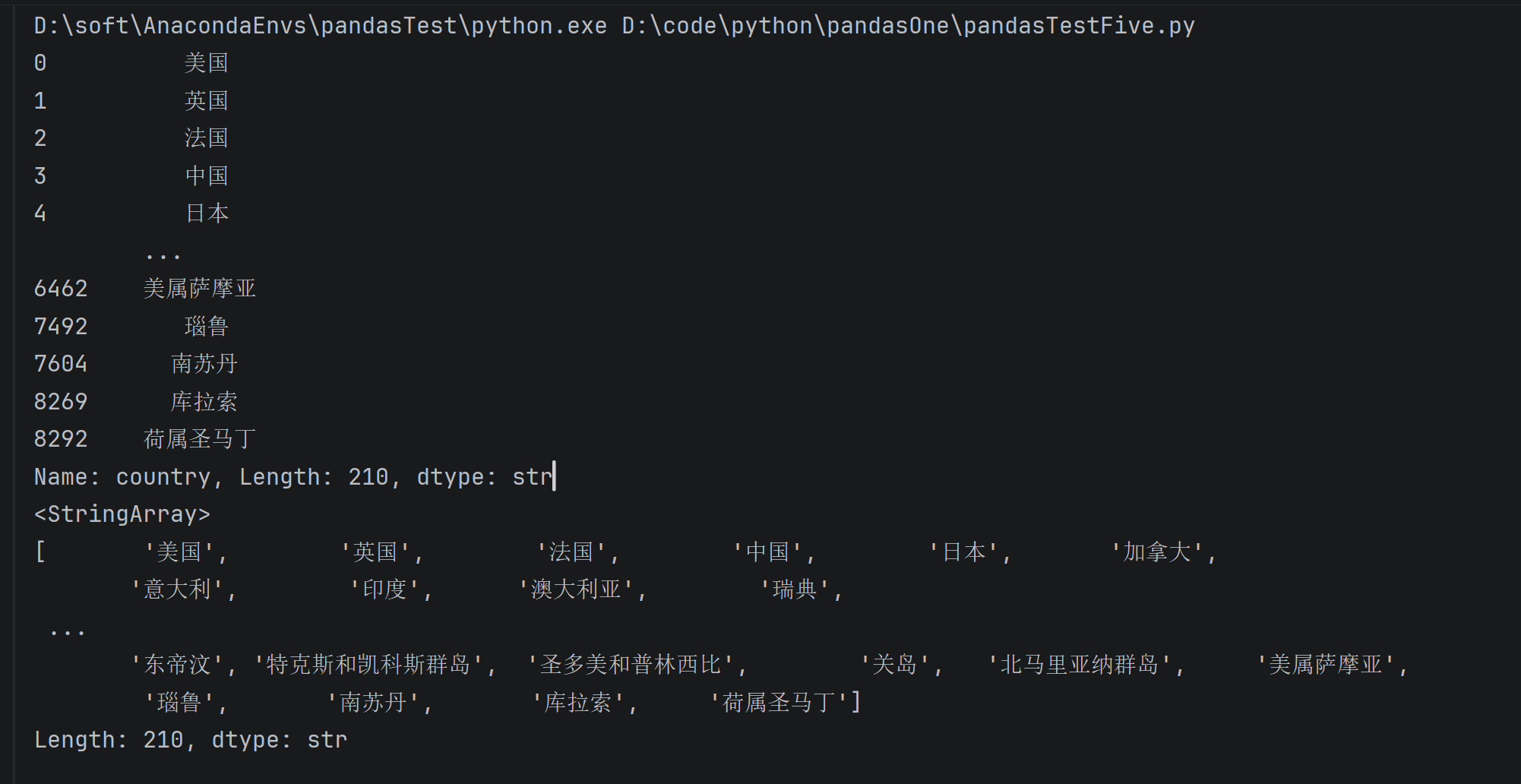
修改DataFrame中的数据
data.assign替换列
python
dataTwo = data.head(5)
print(dataTwo)
dataThree = dataTwo.assign(GDP=66)
print(dataThree)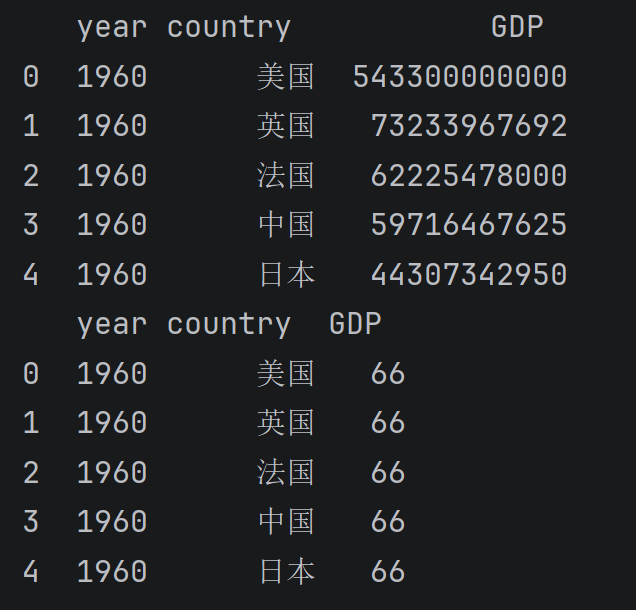
直接对原始的DF进行赋值修改处理
- 一般不建议直接修改操作
python
data = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', )
data_new = data.head()
data_new
data_new['GDP'] = [5, 4, 3, 2, 1]
data_new
data # 此时原始的df会发生改变replace函数替换数据
python
import pandas as pd
# 读取数据,选取前5行作为一个新的 DataFrame
data = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk')
dataSix = data.head()
dataSix
# Series 对象替换数据,返回的还是 Series 对象,不会对原来的 df 造成修改
dataSix['year'].replace(1960, 19600)
# 如果加上 inplace=True 参数,则会修改原始 Series(进而修改 dataSix)
dataSix['country'].replace('日本', '扶桑', inplace=True)
dataSix
# DataFrame 也可以直接调用 replace 函数,用法和 Series.replace 用法一致,只是返回的是 DataFrame 对象
dataSix.replace(1960, 19600)
dataSix查询dataFrame中的数据
从前从后取多行数据
head()
python
# 导包
import pandas as pd
# 加载csv数据,指定gbk编码格式来读取文件,返回df
data = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk')
# 默认取前5行数据
data.head()
data.head(10) # 取前10行
tail()
python
# 默认取后5行数据
data.tail()
dataTwo = df.tail(15) # 倒数15行
print(dataTwo)
获取一列或多列数据
获取一列数据data[col_name]等同于data.col_name
python
data['GDP']
data.GDP
# 注意!如果列名字符串中间有空格的,只能使用df['country']这种形式获取多列数据df[[col_name1,col_name2,...]]
python
data[['country', 'GDP']] # 返回新的data索引下标切片取行
data[start:stop:step]:
data[start:stop:step]==df[起始行下标:结束行下标:步长], 遵循顾头不顾尾原则(包含起始行,不包含结束行),步长默认为1
python
dataFour = data.head(10) # 取原data前10行数据作为dataFour,默认自增索引由0到9
dataFour[0:3] # 取前3行
dataFour[:5:2] # 取前5行,步长为2
dataFour[1::3] # 取第2行到最后所有行,步长为3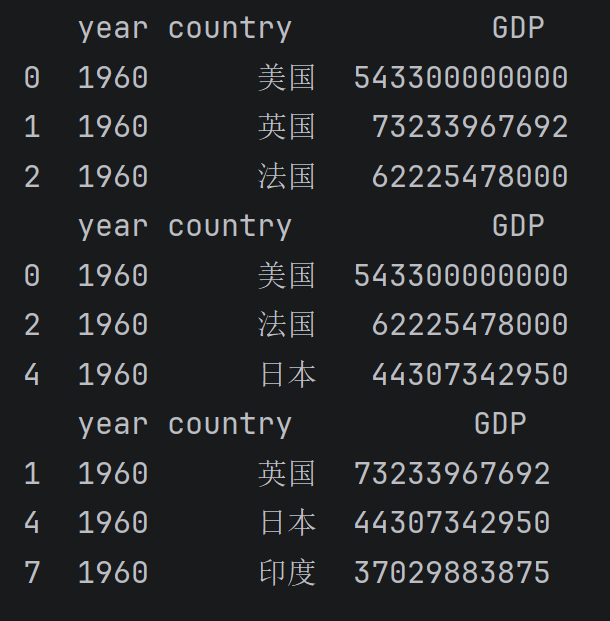
查询函数获取子集: data.query()
data.query(判断表达式)可以依据判断表达式返回的符合条件的data子集- 与
data[布尔值向量]效果相同- 特别注意
data.query()中传入的字符串格式
python
data.query('country=="帕劳"')
data[data['country']=='帕劳']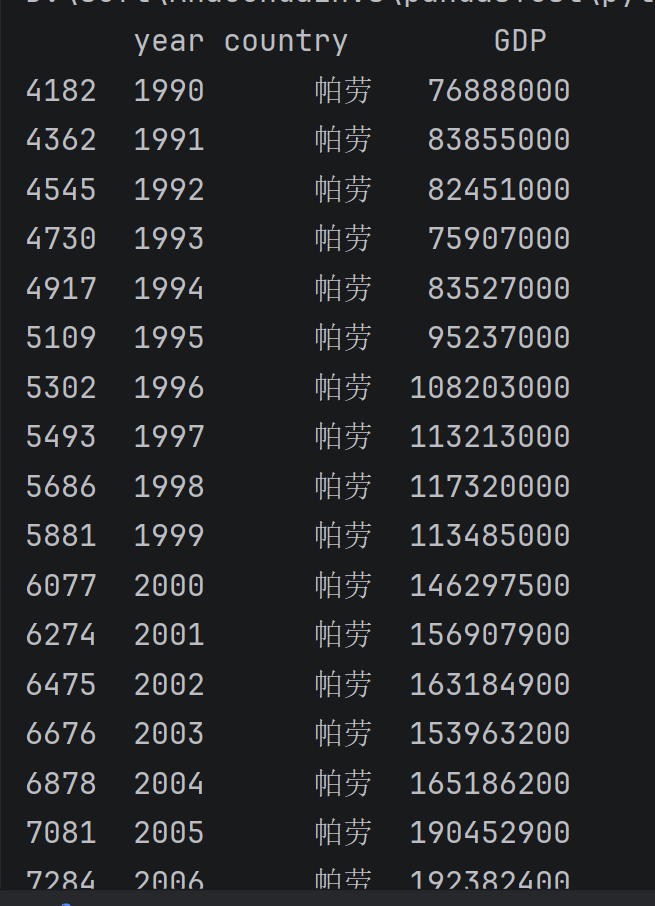
查询中国, 美国 日本 三国 2015年至2019年的数据
python
data.query('country=="中国" or country=="日本" or country=="美国"').query('year in [2015, 2016, 2017, 2018, 2019]'
data.query('(country=="中国" or country=="日本" or country=="美国") and year in [2015, 2016, 2017, 2018, 2019]')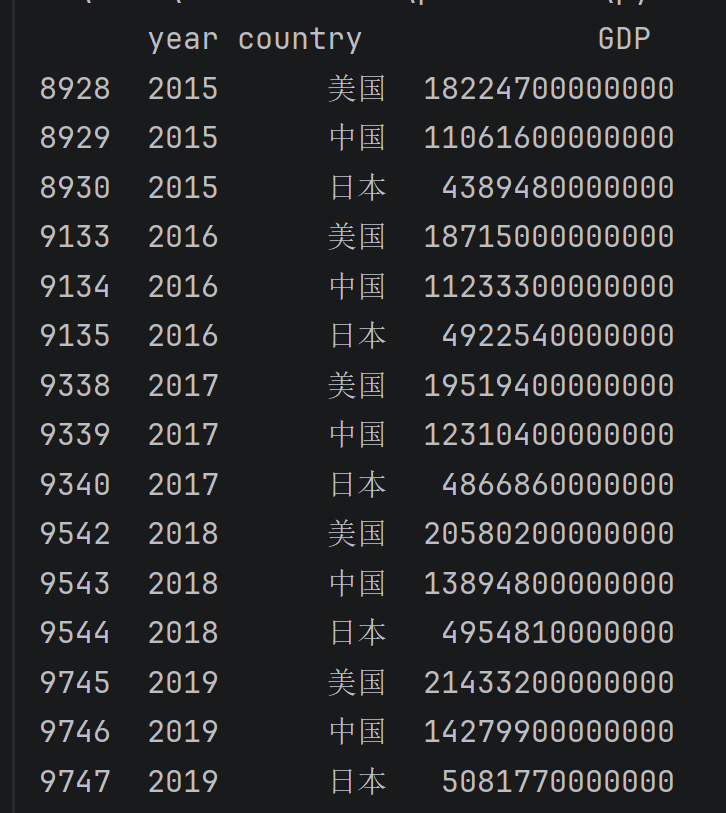
排序函数
sort_values函数: 按照指定的一列或多列的值进行排序
python
# 按GDP列的数值由小到大进行排序
data.sort_values(['GDP'])
# 按GDP列的数值由大到小进行排序
data.sort_values(['GDP'], ascending=False) # 倒序, ascending默认为True
# 先对year年份进行由小到大排序,再对GDP由小到大排序
data.sort_values(['year', 'GDP'])
- rank函数:
- rank函数用法:
DataFrame.rank()或Series.rank()- rank函数返回值:以Series或者DataFrame的类型返回数据的排名(哪个类型调用返回哪个类型)
- rank函数包含有6个参数:
- axis:设置沿着哪个轴计算排名(0或者1),默认为0按纵轴计算排名
- numeric_only:是否仅仅计算数字型的columns,默认为False
- na_option :NaN值是否参与排序及如何排序,固定参数:keep top bottom
- keep: NaN值保留原有位置
- top: NaN值全部放在前边
- bottom: NaN值全部放在最后
- ascending:设定升序排还是降序排,默认True升序
- pct:是否以排名的百分比显示排名(所有排名与最大排名的百分比),默认False
- method:排名评分的计算方式,固定值参数,常用固定值如下:
- average : 默认值,排名评分不连续;数值相同的评分一致,都为平均值
- min : 排名评分不连续;数值相同的评分一致,都为最小值
- max : 排名评分不连续;数值相同的评分一致,都为最大值
- dense : 排名评分是连续的;数值相同的评分一致
python
data.rank()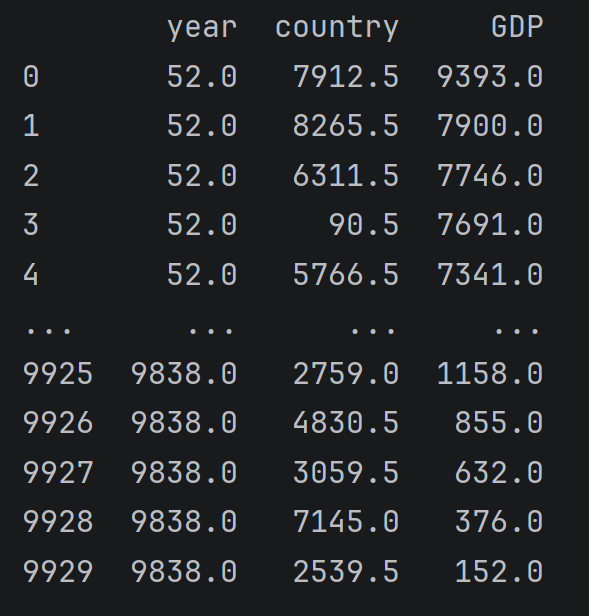
python
data.rank(axis=0)列内排名
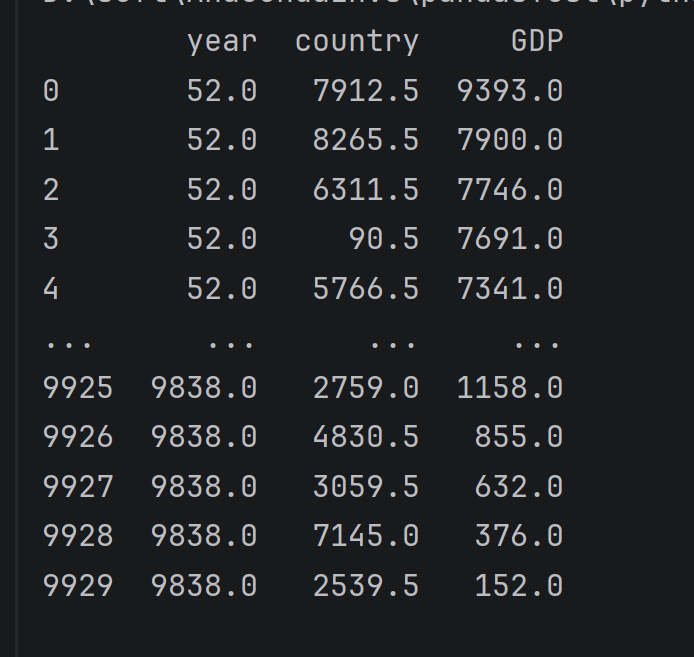
python
data.rank(numeric_only=True)# 只对数值类型的列进行统计)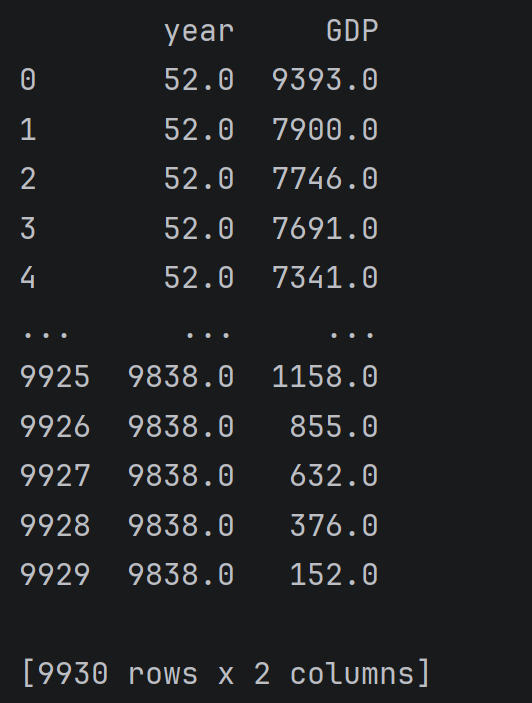
python
data.rank(ascending=False) # 降序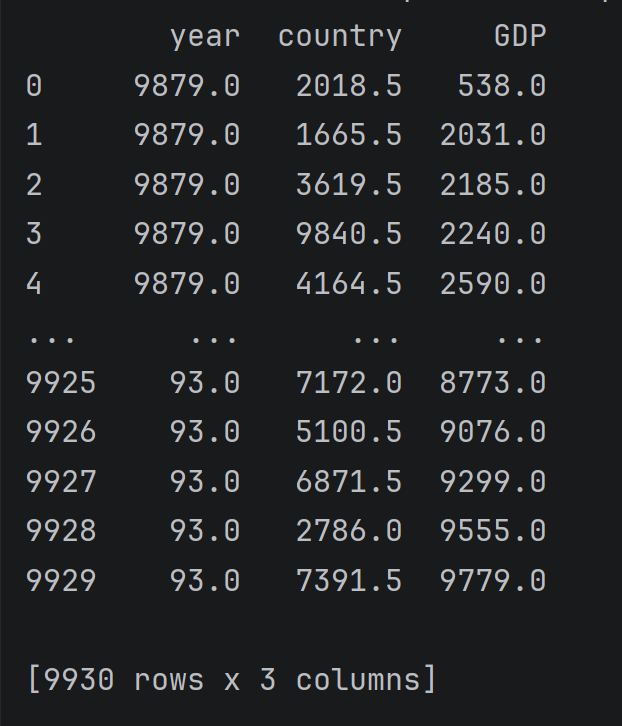
python
data.rank(pct=True)
# 以最高分作为1,放回百分数形式的评分,pct参数默认为False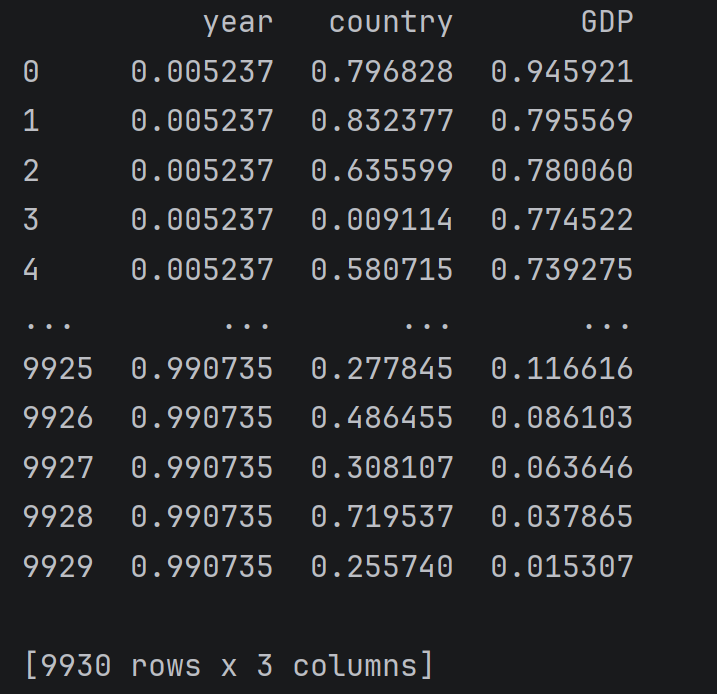
python
data.rank(method='average')
data.rank(method='min')
data.rank(method='max')
data.rank(method='dense')method='average':默认值。为并列值分配平均排名。
method='min':为并列值分配最小的排名。
method='max':为并列值分配最大的排名。
method='dense':分配排名,使得下一个值在上一名次上+1,且不跳号(最密集)。
python
import pandas as pd
s = pd.Series([10, 20, 20, 30])
print(s.rank(method='average')) # 输出: [1.0, 2.5, 2.5, 4.0]
print(s.rank(method='min')) # 输出: [1.0, 2.0, 2.0, 4.0]
print(s.rank(method='max')) # 输出: [1.0, 3.0, 3.0, 4.0]
print(s.rank(method='dense')) # 输出: [1.0, 2.0, 2.0, 3.0]聚合函数:
常用聚合函数有:
- min 最小值
- max 最大值
- mean 平均值
- sum 求和
- count 求个数
python
data['year'].min()
python
data.min()
高级处理-缺失值处理
如何处理NAN
- 获取缺失值的标记方式(NaN或者其他标记方式)
- 如果缺失值的标记方式是NaN
- 判断数据中是否包含NaN:
- pd.isnull(df),
- pd.notnull(df)
- 存在缺失值nan:
- 1、删除存在缺失值的:dropna(axis='rows')
- 注:不会修改原数据,需要接受返回值
- 2、替换缺失值:fillna(value, inplace=True)
- value:替换成的值
- inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
- 1、删除存在缺失值的:dropna(axis='rows')
- 判断数据中是否包含NaN:
- 如果缺失值没有使用NaN标记,比如使用"?"
- 先替换'?'为np.nan,然后继续处理
电影数据的缺失值处理
电影数据文件获取
python
df = pd.read_csv('./movie.csv')判断缺失值是否存在
python
pd.notnull(df)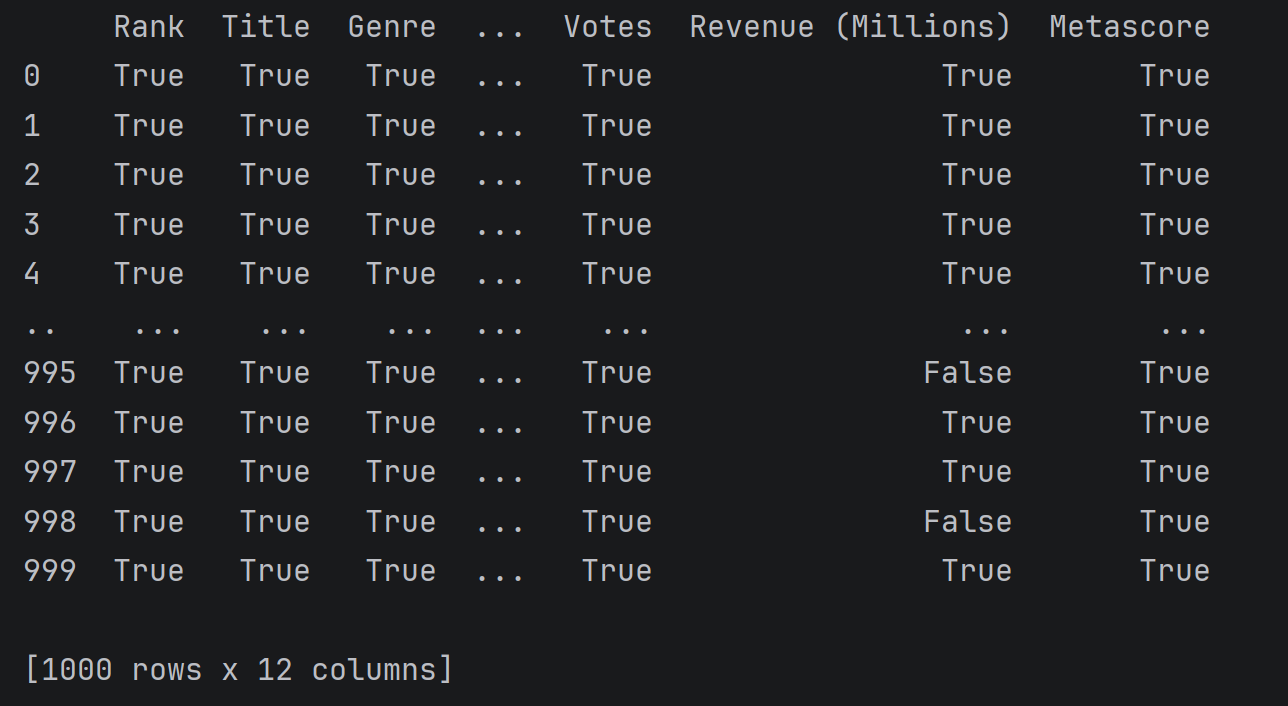
np.all(pd.notnull(df)) 的作用是:检查 DataFrame(或 Series)中是否所有单元格都不是空值(NaN)。如果全部有数据,返回 True;只要存在一个缺失值(NaN),就返回 False。
Pandas 提供了两种完全等价的写法,你可以混用:
- pd.isnull(df)(函数式风格)
- df.isnull()(对象方法风格,更推荐)
存在缺失值nan,并且是np.nan
删除
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
python
# 不修改原数据
df.dropna()
# 可以定义新的变量接受或者用原来的变量名
data = df.dropna()获取空值行 => ① row_with_null = df.isnull().any(axis=1) ② dfrow_with_null
- df.isnull():标记出每一个空单元格(True 表示空)。
- .any(axis=1):沿着行(横向)看,只要这一行里有一个 True,该行就标记为 True。返回一个布尔型 Series。
- dfrow_with_null:通过布尔索引,把那些有问题的"坏行"全部筛选出来展示。
替换缺失值
python
# 替换存在缺失值的样本的两列
# 替换填充平均值,中位数
df['Revenue (Millions)'].fillna(df['Revenue (Millions)'].mean(), inplace=True)- df'Revenue (Millions)':选择 DataFrame df 中的一列(Series)。
- .fillna(...):Pandas Series/DataFrame 的一个方法,用于填充缺失值(NaN)。
- df'Revenue (Millions)'.mean():fillna 方法的参数,计算同一列的平均值,用作填充值。
- inplace=True:fillna 的一个参数,指示是否修改原始 DataFrame(df),而不是返回副本。
替换所有缺失值
python
for i in df.columns:
if np.all(pd.notnull(df[i])) == False:
print(i)
df[i].fillna(df[i].mean(), inplace=True)不是缺失值nan,有默认标记的
python
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")数据在读取时,可能会报如下错误:
python
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)>解决办法:
python
# 全局取消证书验证
import ssl
ssl._create_default_https_context = ssl._create_unverified_context处理思路分析
- 1、先替换'?'为np.nan
- df.replace(to_replace=, value=)
- to_replace:替换前的值
- value:替换后的值
- df.replace(to_replace=, value=)
python
# 把一些其它值标记的缺失值,替换成np.nan
wis = wis.replace(to_replace='?', value=np.nan)2、在进行缺失值的处理
python
# 删除
wis = wis.dropna()小结
- isnull、notnull判断是否存在缺失值
- np.any(pd.isnull(movie)) # 里面如果有一个缺失值,就返回True
- np.all(pd.notnull(movie)) # 里面如果有一个缺失值,就返回False
- dropna删除np.nan标记的缺失值
- movie.dropna()
- fillna填充缺失值
- moviei.fillna(value=moviei.mean(), inplace=True)
- replace替换具体某些值
- wis.replace(to_replace="?", value=np.NaN)
高级处理-数据合并
pd.concat实现数据合并
pd.concat(data1, data2, axis=1)
- 按照行或列进行合并,axis=0为列索引,axis=1为行索引

python
# 按照行索引进行
pd.concat([data, dummies], axis=1)data, dummies:一个列表,包含要拼接的两个 DataFrame。
axis=1:指定拼接方向。
- axis=0(默认)是纵向拼接(增加行)。
- axis=1 是横向拼接(增加列)。
pd.merge
pd.merge(left, right, how='inner', on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrameright: 另一个DataFrameon: 指定的共同键- how:按照什么方式连接
python
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])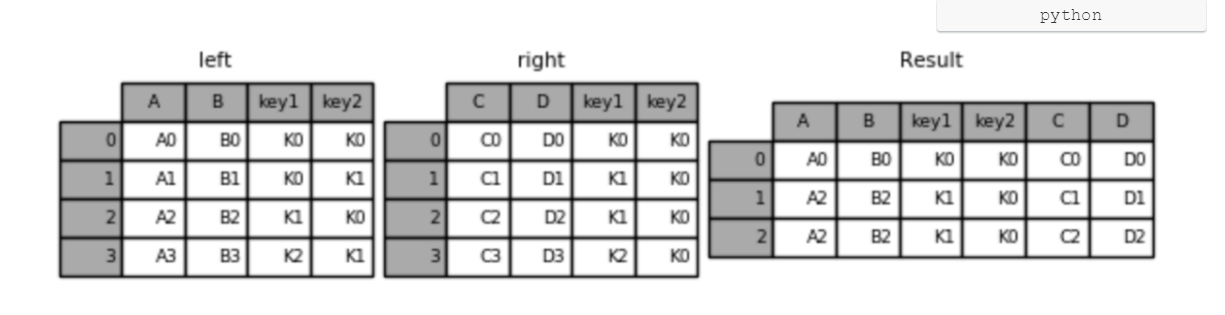
左连接
python
result = pd.merge(left, right, how='left', on=['key1', 'key2'])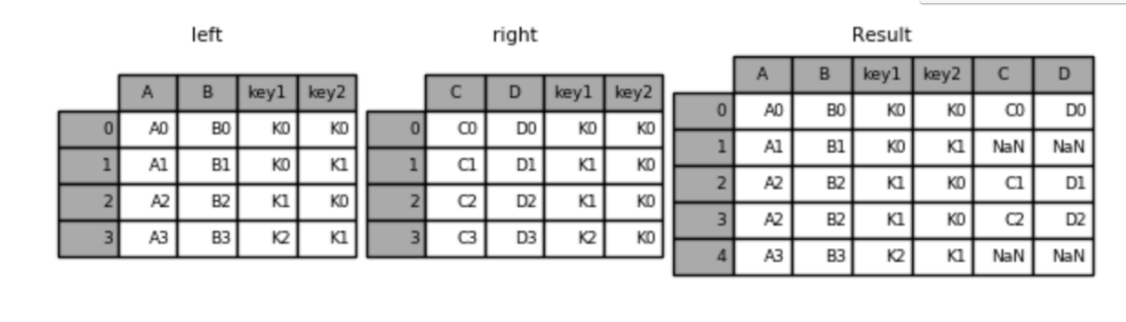
右连接
python
result = pd.merge(left, right, how='right', on=['key1', 'key2'])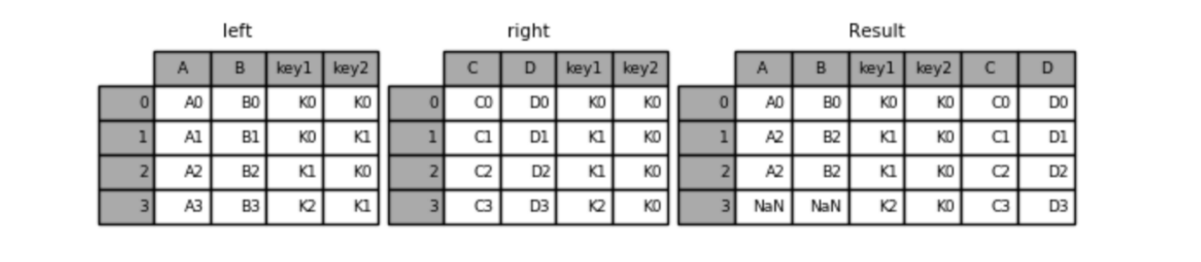
外连接
python
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])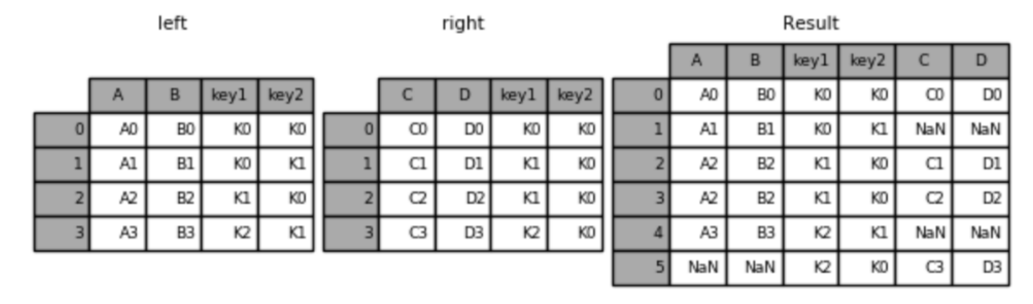
高级处理-数据分组
数据准备
加载优衣库的销售数据集,包含了不同城市优衣库门店的所有产品类别的销售记录,数据字段说明如下
- store_id 门店随机id
- city 城市
- channel 销售渠道 网购自提 门店购买
- gender_group 客户性别 男女
- age_group 客户年龄段
- wkd_ind 购买发生的时间(周末,周间)
- product 产品类别
- customer 客户数量
- revenue 销售金额
- order 订单数量
- quant 购买产品的数量
- unit_cost 成本(制作+运营)
python
# 导包 加载数据集
import pandas as pd
df = pd.read_csv('../数据集/uniqlo.csv')groupby分组聚合
df.groupby分组函数返回分组对象
【基于一列进行分组】
python
gs = df.groupby(['gender_group'])
print(gs)
print(gs['city'])
【基于多列进行分组】
python
gs = df.groupby(['gender_group', 'city'])
print(gs)
分组后获取各个组内的数据
- 2.1 取出每组第一条或最后一条数据
python
gs = df.groupby(['gender_group', 'channel'])
print(gs.first())# 取出每组第一条数据
print(gs.last()) # 取出每组最后一条数据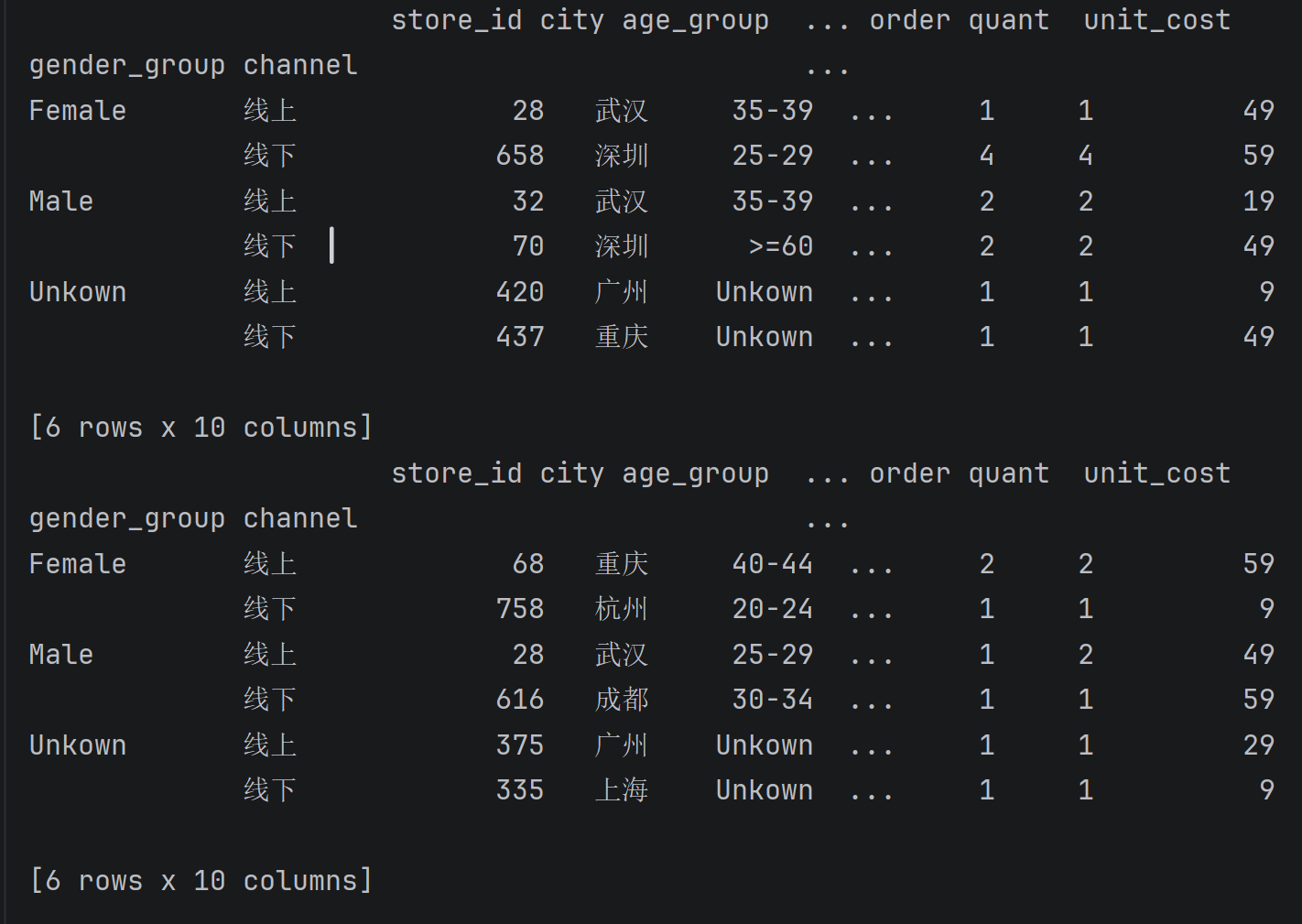
分组后获取所有组的数据
pythongs = df.groupby(['gender_group', 'channel']) for name, group in gs: print(f"组名: {name}") print(f"该组数据形状: {group.shape}") print(group) print("-" * 30)
按分组依据获取其中一组
python
gs.get_group(('Female', '线上'))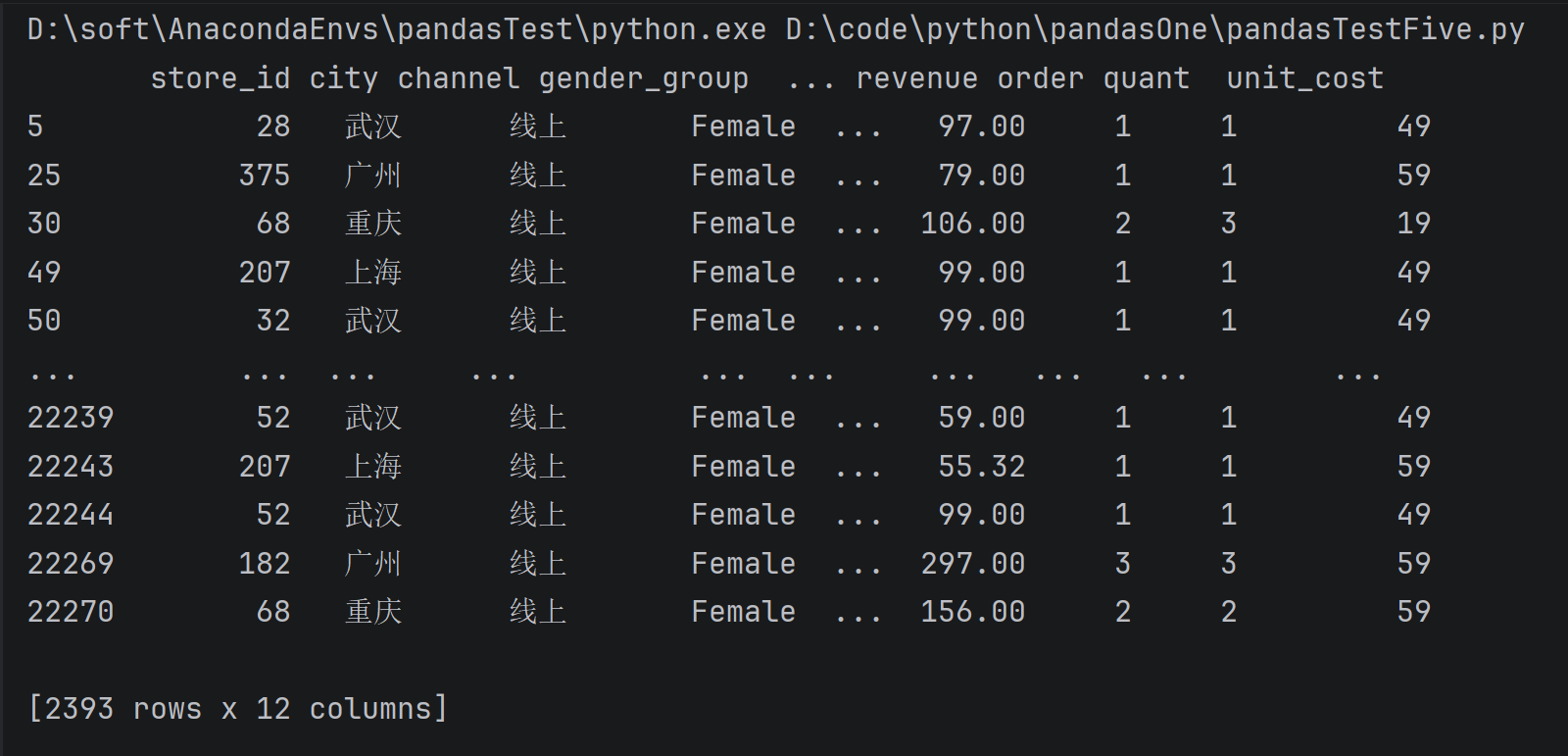
分组聚合
格式:分组后对多列分别使用不同的聚合函数
python
df.groupby(['列名1', '列名2']).agg({
'指定列1':'聚合函数名',
'指定列2':'聚合函数名',
'指定列3':'聚合函数名'
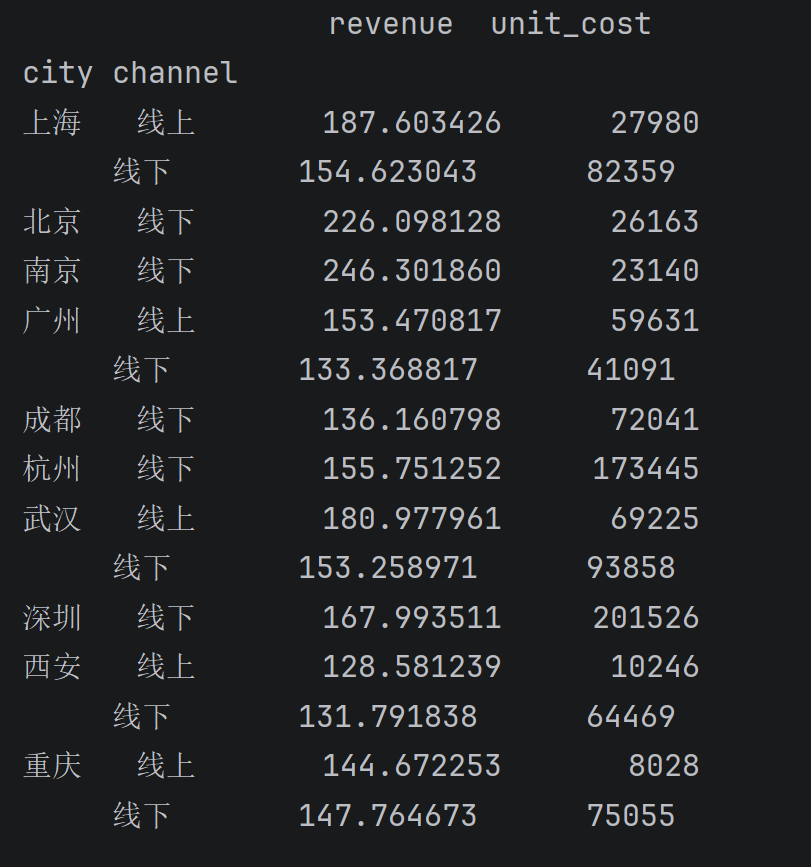
})- 按城市和线上线下划分,分别计算销售金额的平均值、成本的总和
python
df.groupby(['city', 'channel']).agg({
'revenue':'mean',
'unit_cost':'sum'
})
分组过滤操作
格式:
python
df.groupby(['列名1',...]).filter(
lambda x: dosomething returun True or False
)案例: 按城市分组,查询每组销售金额平均值大于200的全部数据
python
df.groupby(['city']).filter(lambda s: s['revenue'].mean() > 200)
df.groupby(['city'])['revenue'].filter(lambda s: s.mean() > 200)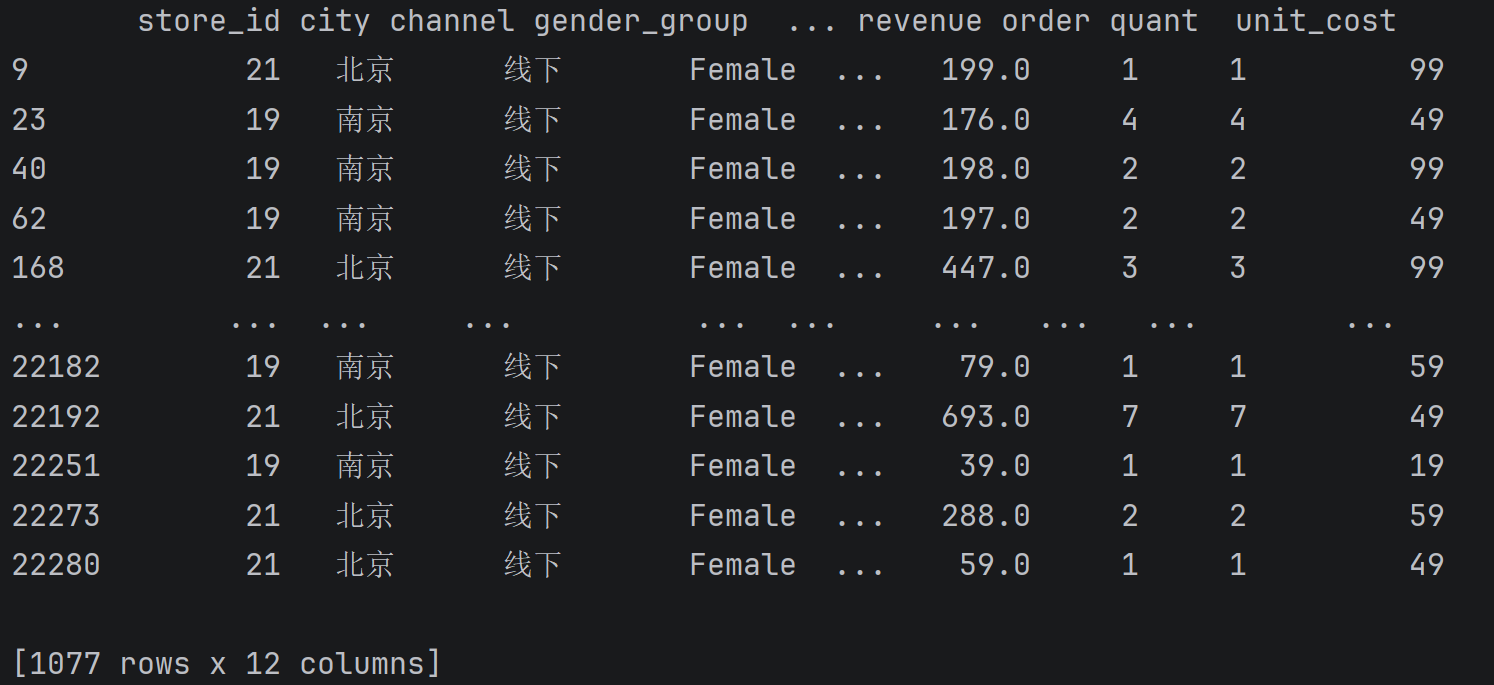
总结
希望本文能成为你数据清洗与分组分析路上的可靠指南。遇到任何具体的数据处理难题,欢迎随时查阅这篇"参数地图"。🚀