一、先看整体机制图
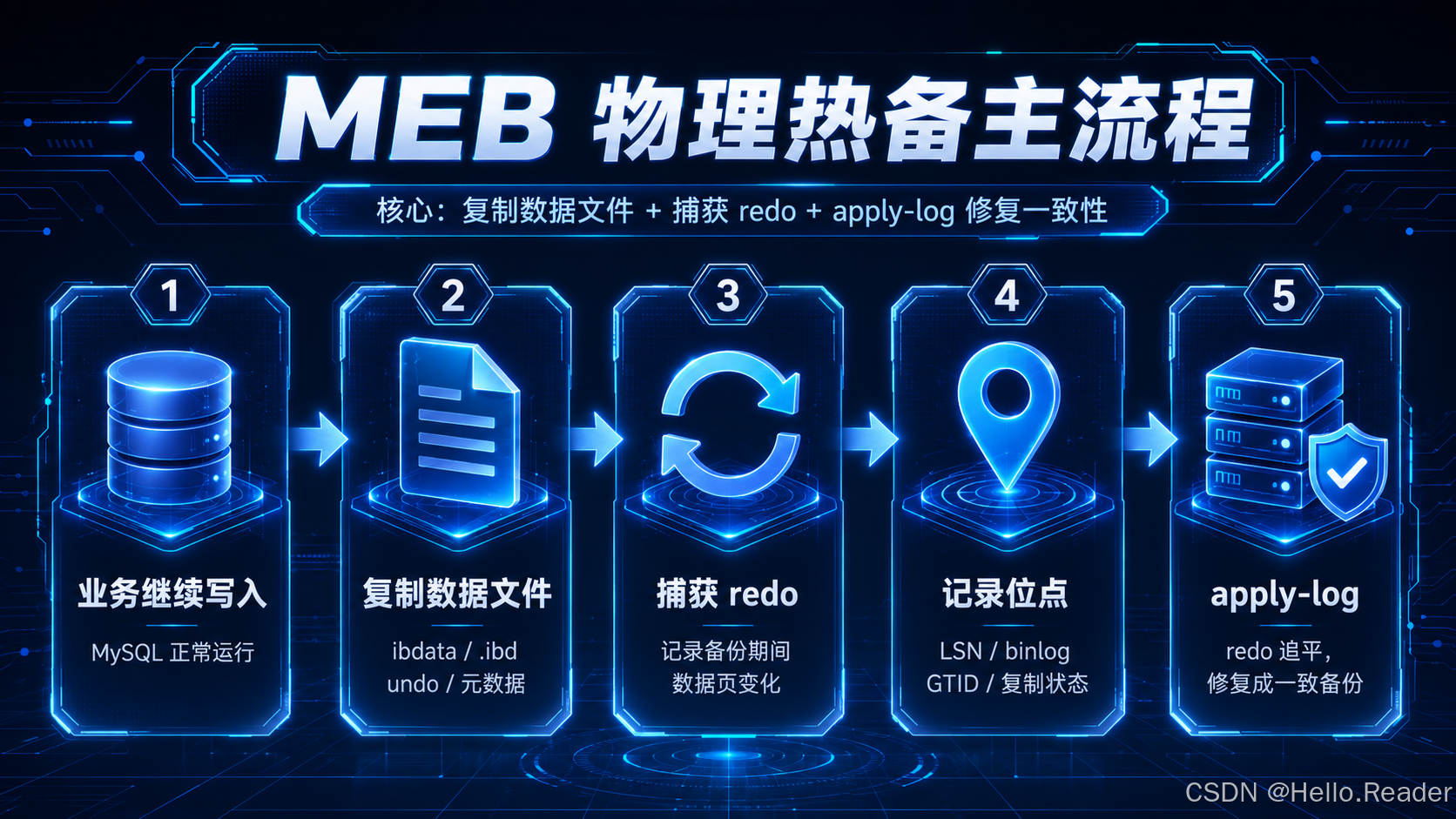
这张图可以先记住三个关键词:
- 物理文件:备份的是数据文件,不是 SQL 文本;
- redo:记录备份过程中 InnoDB 发生的变化;
- apply-log:把 raw backup 修复成一致状态。
只要理解这三个点,MEB 的底层机制就基本通了。
二、MEB 备份的不是 SQL,而是 MySQL 数据文件
MEB 和 mysqldump 最大的区别在于:
mysqldump:逐库、逐表、逐行导出 SQL;- MEB:直接复制 MySQL 数据目录中的物理文件。
典型备份内容如下:
| 文件 / 信息 | 作用 | 为什么重要 |
|---|---|---|
ibdata* |
InnoDB 系统表空间 | 保存系统级 InnoDB 元数据和部分表数据 |
*.ibd |
独立表空间文件 | 一张表或一个分区对应的数据与索引页 |
undo tablespace |
回滚与 MVCC 相关信息 | 保证事务一致性恢复 |
ibbackup_logfile |
MEB 生成的备份日志文件 | 保存备份期间需要应用到备份集的 InnoDB 变化 |
binlog |
二进制日志 | 用于时间点恢复、主从复制位点恢复 |
backup-my.cnf |
备份配置元数据 | 记录恢复所需的数据文件布局信息 |
因为是物理备份,大库场景下它通常比逻辑导出快很多。恢复时也不需要重新执行海量 SQL,而是把文件恢复回数据目录,再让 MySQL 基于一致的数据文件启动。
三、为什么在线写入时也能备份?
这里有一个关键问题:
如果数据库正在写入,MEB 一边复制
.ibd文件,一边业务还在提交事务,那复制出来的文件岂不是前后时间点不一致?
答案是:是的,刚复制出来的备份并不是最终可恢复状态。
这个阶段的备份通常可以理解为 raw backup。它只是"原始物理副本",不代表天然就是一致快照。
MEB 之所以能保证最终一致,是因为它会记录备份期间 InnoDB 产生的 redo 变化。
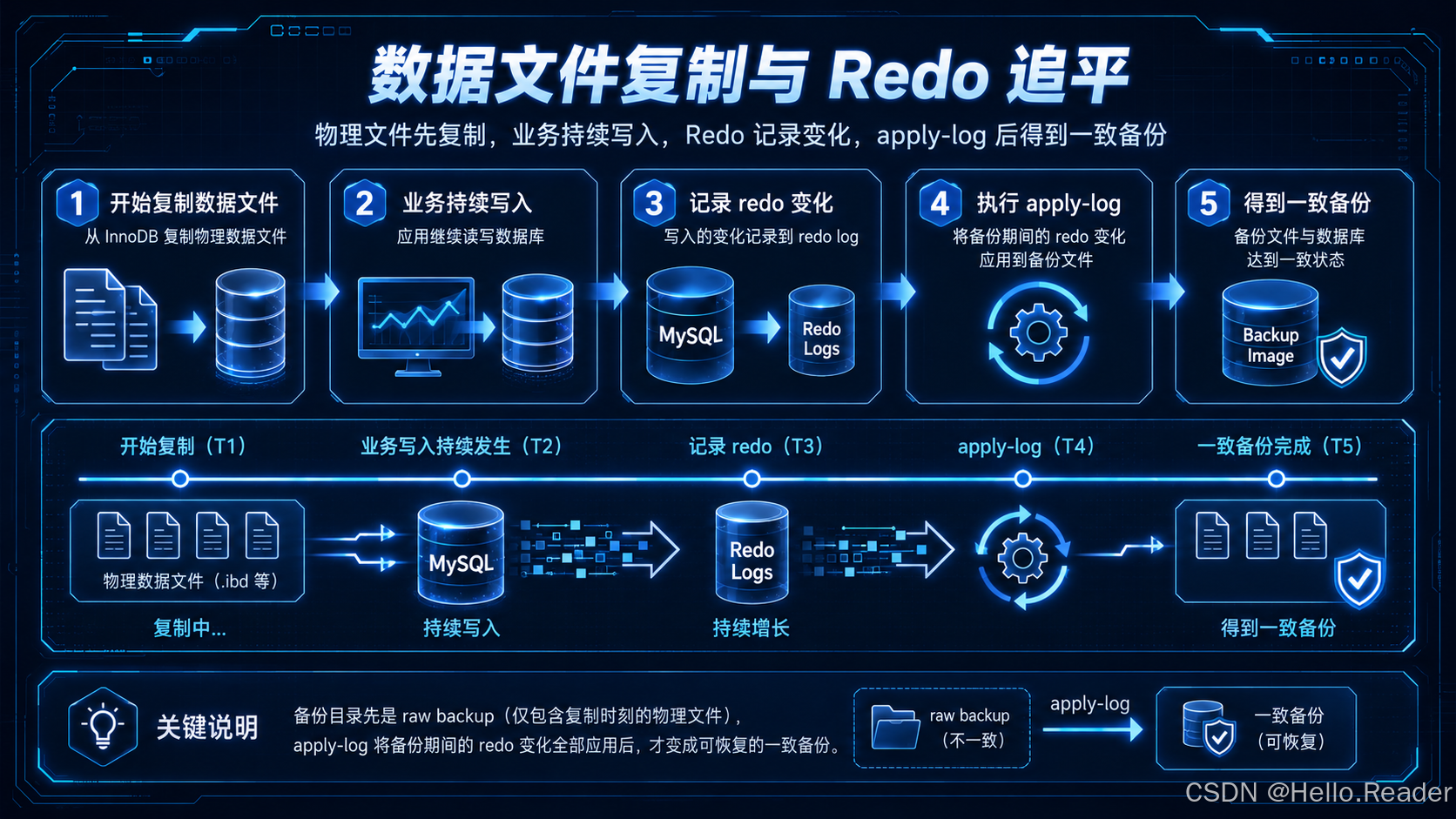
可以这样理解:
- MEB 开始复制 InnoDB 数据文件;
- 业务继续提交事务;
- InnoDB 会持续产生 redo;
- MEB 捕获备份期间需要的 redo 信息;
- 备份结束后,再通过
apply-log把这些变化补到备份文件里。
这个过程和 MySQL 异常宕机后的 InnoDB crash recovery 思路很像:
数据文件可能不是完全一致的,但只要 redo 信息完整,就可以把它恢复到一致状态。
四、apply-log 到底做了什么?
MEB 备份完成后,经常会看到下面这个命令:
bash
mysqlbackup \
--backup-dir=/data/backup/full_20260618 \
apply-log这个步骤就是把备份期间记录下来的 InnoDB 变化应用到物理备份文件中。
简单来说:
text
raw backup
+ redo changes
= prepared backup其中:
- raw backup:刚复制出来的原始物理备份;
- redo changes:备份期间发生的 InnoDB 修改;
- prepared backup:已经完成一致性修复、可以拿去恢复的备份。
为什么不能跳过 apply-log?
因为直接复制数据文件时,不同文件可能来自不同时间点。
例如:
text
表 A 的 .ibd 文件可能是 10:00:01 复制的
表 B 的 .ibd 文件可能是 10:00:08 复制的
业务事务在 10:00:03 ~ 10:00:07 之间仍然持续提交如果没有 redo 追平,这份备份就可能处于"不完整、不一致"的状态。
所以,apply-log 的意义就是:
- 把备份期间提交的事务变化补进去;
- 回滚未完成事务相关状态;
- 让整个备份集变成同一个逻辑时间点上的一致数据集。
五、增量备份为什么能只备变化数据?
MEB 的增量备份核心依赖 LSN ,也就是 Log Sequence Number。
你可以把 LSN 理解成 InnoDB redo 日志的全局递增位置。
假设上一次备份结束时:

text
end_lsn = 100000下一次做增量备份时,MEB 只需要处理:
text
LSN > 100000 之后发生变化的数据也就是说,增量备份不是简单地"看哪张表变了",而是基于 InnoDB 的变化位置判断哪些数据页需要进入增量备份。
示例命令:
bash
# 全量备份,并在备份后直接完成 apply-log
mysqlbackup \
--backup-dir=/data/backup/full \
backup-and-apply-log
# 基于上一次全量备份做增量备份
mysqlbackup \
--backup-dir=/data/backup/inc_01 \
--incremental \
--incremental-base=dir:/data/backup/full \
backup恢复时通常是:
text
全量备份
+ 增量 1
+ 增量 2
+ 增量 3
+ apply-log
= 最终可恢复备份这个机制非常适合大库场景。因为每天都做全量备份成本太高,而基于 LSN 的增量备份可以显著减少备份数据量和备份窗口。
六、redo 和 binlog 分别解决什么问题?
很多人容易把 redo 和 binlog 混在一起。它们都是日志,但作用完全不同。
| 日志 | 主要用途 | 在 MEB 中的作用 |
|---|---|---|
redo log |
保证 InnoDB 崩溃恢复与物理一致性 | 用于 apply-log,把 raw backup 修复成 prepared backup |
binlog |
记录逻辑变更事件,用于复制和时间点恢复 | 用于 PITR,例如恢复到误删数据之前的某个时间点 |
一句话区分:
redo 是让这份物理备份自己一致;binlog 是让你可以继续向后追时间点。
举个例子:
text
凌晨 02:00 做了一次全量备份
上午 10:15 误删了一批业务数据如果你只恢复 02:00 的全量备份,那么 02:00 到 10:15 之间的正常业务数据也会丢失。
更合理的做法是:
- 先恢复 02:00 的全量备份;
- 再用 binlog 回放 02:00 到 10:14:59 的正常变更;
- 跳过 10:15 的误删操作;
- 最终恢复到误删前的状态。
这就是 binlog 在备份体系中的价值。
七、恢复流程应该怎么理解?
MEB 恢复通常有三类场景。
1. 只恢复全量备份
如果备份阶段已经执行过 apply-log,可以直接恢复:
bash
mysqlbackup \
--backup-dir=/data/backup/full \
copy-back如果备份还没有执行 apply-log,也可以在恢复时一并处理:
bash
mysqlbackup \
--backup-dir=/data/backup/full \
copy-back-and-apply-log2. 全量 + 多个增量恢复
bash
# 先准备全量备份
mysqlbackup \
--backup-dir=/data/backup/full \
apply-log
# 依次应用增量备份
mysqlbackup \
--backup-dir=/data/backup/full \
--incremental-backup-dir=/data/backup/inc_01 \
apply-incremental-backup
mysqlbackup \
--backup-dir=/data/backup/full \
--incremental-backup-dir=/data/backup/inc_02 \
apply-incremental-backup
# 最后恢复
mysqlbackup \
--backup-dir=/data/backup/full \
copy-back实际生产中要注意:
- 增量必须按顺序应用;
- 不要跳过中间增量;
- 恢复前要确认目标 MySQL 已停止;
- 原数据目录要提前备份或清空;
- 恢复后要检查权限、配置、server_uuid、复制状态等信息。
3. 恢复到误操作之前
这种就是典型的 PITR,Point-In-Time Recovery,时间点恢复。
常见步骤:
text
1. 恢复最近一次全量备份
2. 应用后续增量备份
3. 使用 binlog 回放到指定时间点
4. 跳过误操作 SQL
5. 启动 MySQL 并校验业务数据八、和 mysqldump、XtraBackup 的区别
| 工具 | 类型 | 核心机制 | 适合场景 |
|---|---|---|---|
mysqldump |
逻辑备份 | 导出 SQL 语句 | 小库、迁移、结构导出 |
MySQL Enterprise Backup |
物理备份 | 复制数据文件 + redo apply-log | 企业版 MySQL、大库在线备份 |
Percona XtraBackup |
物理备份 | 复制数据文件 + redo prepare | 社区版 MySQL、Percona 环境 |
简单理解:
text
mysqldump 是把数据"导出来"
MEB 是把数据库"复制出来",再用日志修正到一致状态
XtraBackup 的核心思路与 MEB 类似,但它来自 Percona 体系如果公司已经购买 MySQL Enterprise,MEB 的优势是官方支持、版本适配和企业环境集成。
如果使用的是社区版 MySQL,很多团队会选择 XtraBackup 作为物理热备方案。
九、生产环境使用建议
MEB 机制虽然强,但生产环境不能只会执行命令,还要形成备份体系。
建议至少关注下面这些点:
| 检查项 | 建议 |
|---|---|
| 备份频率 | 大库常见做法是定期全量 + 高频增量 |
| binlog 保留 | binlog 保留时间要覆盖恢复窗口 |
| 备份校验 | 定期执行恢复演练,而不是只看备份成功日志 |
| 权限控制 | 备份目录、binlog、配置文件都要控制权限 |
| 异地容灾 | 备份不要只放在本机磁盘 |
| 监控告警 | 备份失败、耗时异常、备份空间不足都要告警 |
| 恢复文档 | 恢复步骤要文档化,避免故障时临场摸索 |
尤其要强调一点:
没有做过恢复演练的备份,不算真正可靠的备份。
很多事故不是因为没有备份,而是因为真正恢复时才发现:
- 备份文件不完整;
- binlog 缺了一段;
- 增量顺序不清楚;
- 恢复命令没人熟;
- 业务停机窗口无法接受。
所以,备份方案一定要和恢复演练一起设计。
十、最后总结
MySQL Enterprise Backup 的底层机制可以总结成一句话:
在线复制 InnoDB 物理数据文件,同时记录备份期间产生的 redo/binlog/LSN 等信息,最后通过 apply-log 把不一致的原始物理副本修复成一个一致时间点的可恢复备份。
再压缩一下:
- 物理备份:复制的是数据文件,不是 SQL;
- 热备能力:InnoDB 可以在业务读写过程中备份;
- 一致性来源:redo + apply-log;
- 增量判断:依赖 LSN 和变化页;
- 时间点恢复:依赖 binlog;
- 生产可靠性:取决于备份、校验、演练、监控、异地存储是否完整。
如果用一句最直白的话解释 MEB:
mysqldump是把库"导出来",MEB 是把库"复制出来",再用 InnoDB 日志把它修到一致。
参考资料
- MySQL Enterprise Backup 官方用户手册
- mysqlbackup 命令说明
- MySQL Enterprise Backup 备份文件说明
- MySQL Enterprise Backup 增量备份说明
- InnoDB redo log 与 crash recovery 相关文档