文章目录
-
- 声明
- [0. 开场:一个看起来很正常的电影网站](#0. 开场:一个看起来很正常的电影网站)
- [1. 先验证现象:样例请求为什么 401](#1. 先验证现象:样例请求为什么 401)
- [2. 找入口:先看首页加载了哪些 JS](#2. 找入口:先看首页加载了哪些 JS)
- [3. 列表页:token 是怎么被塞进请求的](#3. 列表页:token 是怎么被塞进请求的)
- [4. 详情页:URL 里的 key 是怎么来的](#4. 详情页:URL 里的 key 是怎么来的)
- [5. 详情页 token:签名对象变了](#5. 详情页 token:签名对象变了)
- [6. Python 还原:用标准库就够了](#6. Python 还原:用标准库就够了)
- [7. 这次逆向的关键证据链](#7. 这次逆向的关键证据链)
- [8. 踩坑清单:这些地方最容易浪费时间](#8. 踩坑清单:这些地方最容易浪费时间)
-
- [8.1 token 会过期](#8.1 token 会过期)
- [8.2 签名 path 不带 query](#8.2 签名 path 不带 query)
- [8.3 详情页签名 path 不带末尾斜杠](#8.3 详情页签名 path 不带末尾斜杠)
- [8.4 Base64 不是加密](#8.4 Base64 不是加密)
- [8.5 不要过早上浏览器自动化](#8.5 不要过早上浏览器自动化)
- [9. 总结](#9. 总结)
声明
本文章中所有内容仅供学习交流,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请私信我立即删除!
《JS逆向为爱发电》专栏素材征集令:十年饮冰,热血难凉 | JS逆向为爱发电
目标站点:
https://spa6.scrape.center目标参数:列表页 Ajax
token、详情页加密id/key、详情页token
0. 开场:一个看起来很正常的电影网站
这次分析的目标是 Scrape Center 的 spa6 站点,特别适合新手练习。
页面本身是一个电影列表,点进去有详情页,怎么看都像一个前端练手项目。
但是我们的直觉一般不会停在"页面能打开"这里,我们真正关心的是:
- 列表数据从哪里来?
- 请求参数有没有签名?
- 详情页 URL 里的那段奇怪字符串是不是加密 id?
- 这些参数能不能不用浏览器,直接在 Python 里生成?
打开首页后,接口形态大概是这样:
text
列表页:
https://spa6.scrape.center/api/movie/?limit=10&offset=0&token=...
详情页:
https://spa6.scrape.center/api/movie/{key}/?token=...第一眼看到 token,事情就不只是拼 URL 这么简单了。
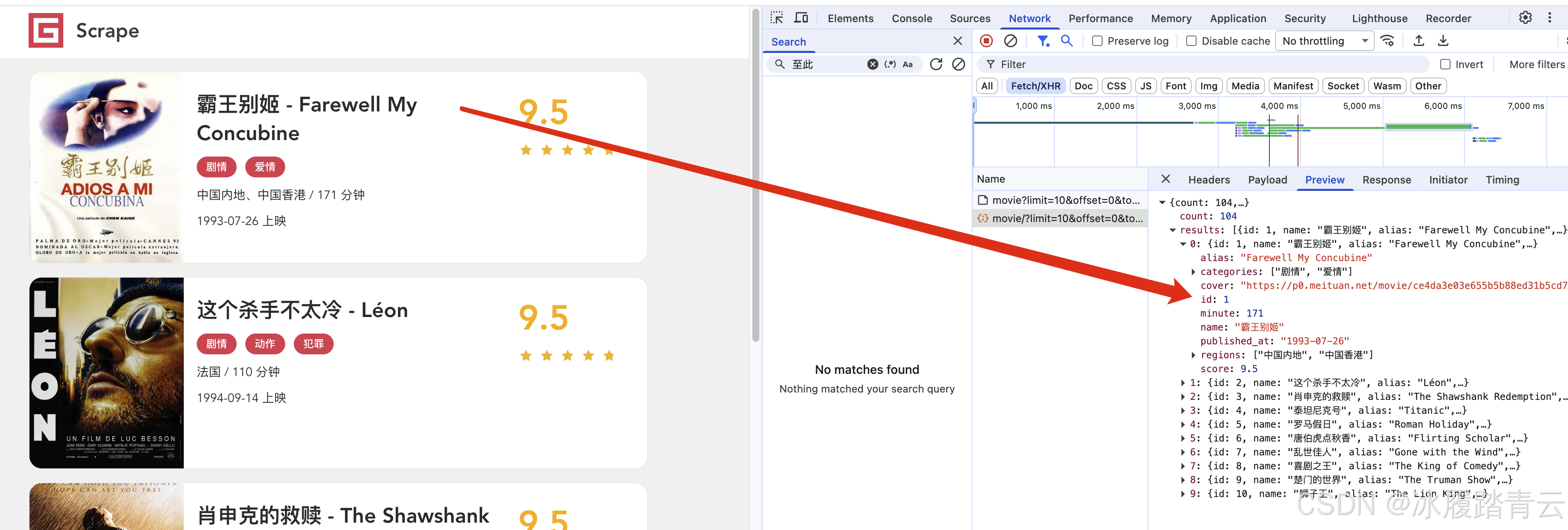
然后点进去详情接口就成这样了
第二眼看到详情接口里的 {key},基本可以确认:这里有两条线要查。
一条是 token 怎么生成,另一条是电影 id 怎么变成详情页 key。
1. 先验证现象:样例请求为什么 401
我们刚打开就抓包到了一个列表接口样例:
text
https://spa6.scrape.center/api/movie/?limit=10&offset=0&token=Y2VjNGFmYzAyNTQxZDY5ZmUzNzVmYzZkNDJjYjk2Zjc1YmNmNmNmZSwxNzgxMjM4MjQx直接请求,返回:
text
401 Unauthorized这不是接口挂了,也不是请求头少了一个"玄学字段"。先把 token 拿出来解一下 Base64:
text
cec4afc02541d69fee375fc6d42cb96f75bcf6cfe,1781238241可以看到 token 实际上由两段组成:
text
某个 40 位十六进制摘要,时间戳40 位十六进制摘要非常像 SHA1。后面的 1781238241 是秒级时间戳。既然 token 里带时间戳,那样例请求过期导致 401 就很合理了。
这里有一个很重要的判断:
先不要怀疑 Cookie、TLS、浏览器指纹。能用静态算法解释的,先把静态算法查完。
爬虫调试最怕一上来就把问题想复杂,很多时候不是站点上了高强度风控,只是前端给参数加了一个"保质期"。
2. 找入口:先看首页加载了哪些 JS
首页 HTML 很干净,核心资源如下:
html
<script src="/js/chunk-vendors.77daf991.js"></script>
<script src="/js/app.5ef0d454.js"></script>同时还有按需加载的 chunk:
html
<link href="/js/chunk-19c920f8.c3a1129d.js" rel="prefetch">
<link href="/js/chunk-2f73b8f3.8f2fc3cd.js" rel="prefetch">
<link href="/js/chunk-4dec7ef0.e4c2b130.js" rel="prefetch">这是一个典型 Vue + Webpack 项目,主包里放路由和公共逻辑,页面组件拆进异步 chunk。
从 app.5ef0d454.js 中能看到路由配置:
javascript
{
path: "/",
name: "index",
component: function () {
return Promise.all([
require.e("chunk-4dec7ef0"),
require.e("chunk-19c920f8")
]).then(...)
}
},
{
path: "/detail/:key",
name: "detail",
component: function () {
return Promise.all([
require.e("chunk-4dec7ef0"),
require.e("chunk-2f73b8f3")
]).then(...)
}
}这说明:
chunk-19c920f8是列表页组件chunk-2f73b8f3是详情页组件chunk-4dec7ef0很可能放公共加密方法
方向已经很清楚了。
3. 列表页:token 是怎么被塞进请求的
在列表页 chunk 里可以看到请求代码,整理后大概是这样:
javascript
onFetchData: function () {
var offset = (this.page - 1) * this.limit;
var token = makeToken(this.$store.state.url.index);
this.$axios.get(this.$store.state.url.index, {
params: {
limit: this.limit,
offset: offset,
token: token
}
}).then(...)
}页面 store 里定义的接口地址是:
javascript
state: {
url: {
index: "/api/movie",
detail: "/api/movie/{key}"
}
}这里有个关键点:
列表页 token 的入参不是完整 URL,也不是带 query 的 URL,而是:
text
/api/movie也就是说,limit 和 offset 不参与 token 计算。
这个地方非常容易踩坑。很多人看到接口完整 URL 是:
text
/api/movie/?limit=10&offset=0&token=...就会下意识拿完整 path + query 去签名,最后怎么试都 401。服务端内心大概是:你算得很努力,但我们不是这么约的。
继续追 makeToken,模块名是 7d92,定义在公共 chunk 里。
还原后的逻辑如下:
javascript
function makeToken() {
var timestamp = Math.round(new Date().getTime() / 1000).toString();
var args = Array.from(arguments);
args.push(timestamp);
var sha1 = CryptoJS.SHA1(args.join(",")).toString(CryptoJS.enc.Hex);
var text = [sha1, timestamp].join(",");
return Base64.encode(text);
}列表页调用时只传了一个参数:
javascript
makeToken("/api/movie")因此列表页 token 的明文结构是:
text
sha1("/api/movie,{timestamp}"),{timestamp}然后再做 Base64。
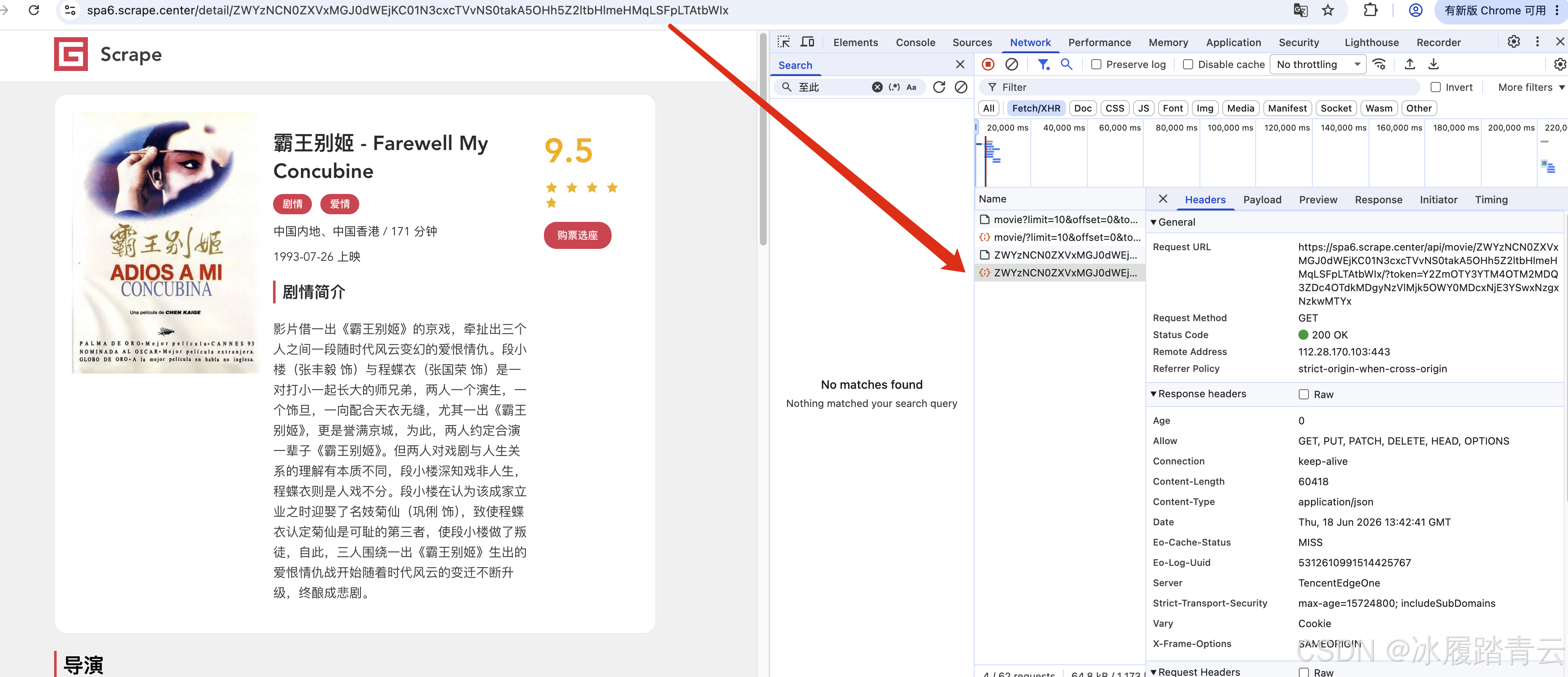
4. 详情页:URL 里的 key 是怎么来的
列表页渲染电影卡片时,有这样一段:
javascript
router-link to: {
name: "detail",
params: {
key: transfer(movie.id)
}
}这里的 transfer 就是详情页 id 加密函数,模块名是 3e22。
还原后非常直接:
javascript
var prefix = "ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb";
function transfer(id) {
return Base64.encode(prefix + id.toString());
}比如电影 id 是 1,则详情 key 的明文是:
text
ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb1Base64 后得到:
text
ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx刚好和样例详情接口里的 key 对上。
这个"加密"更准确地说是"固定前缀混淆 + Base64 编码"。它的目的不是密码学意义上的安全,而是让接口别那么一眼看穿。
5. 详情页 token:签名对象变了
详情页请求代码整理后是这样:
javascript
var path = format("/api/movie/{key}", { key: this.key });
var token = makeToken(path);
this.$axios.get(path, {
params: {
token: token
}
}).then(...)注意,详情页 token 的签名 path 是带加密 key 的:
text
/api/movie/{key}比如:
text
/api/movie/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx所以详情页 token 明文结构是:
text
sha1("/api/movie/{key},{timestamp}"),{timestamp}然后 Base64。
这里也容易犯错:详情接口实际请求 URL 里有一个末尾斜杠:
text
/api/movie/{key}/?token=...但是前端生成 token 时传入的是:
text
/api/movie/{key}不带末尾斜杠。
这类细节很不起眼,但它决定了你是拿到数据,还是继续和 401 对视。
6. Python 还原:用标准库就够了
最终不需要浏览器,不需要执行 JS,不需要 Selenium,也不需要在请求前"预热页面"。
Python 标准库就能完成:
python
import base64
import hashlib
import time
DETAIL_ID_PREFIX = "ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb"
def base64_encode(value: str) -> str:
return base64.b64encode(value.encode("utf-8")).decode("utf-8")
def make_token(path: str, timestamp: int | None = None) -> str:
ts = str(round(time.time()) if timestamp is None else timestamp)
digest = hashlib.sha1(f"{path},{ts}".encode("utf-8")).hexdigest()
return base64_encode(f"{digest},{ts}")
def encode_movie_id(movie_id: int | str) -> str:
return base64_encode(f"{DETAIL_ID_PREFIX}{movie_id}")列表页调用:
python
path = "/api/movie"
token = make_token(path)详情页调用:
python
key = encode_movie_id(1)
path = f"/api/movie/{key}"
token = make_token(path)7. 这次逆向的关键证据链
这次不靠猜,证据链很短也很硬:
- 样例 token Base64 解码后是
摘要,时间戳。 - 摘要长度 40 位,符合 SHA1 十六进制输出。
- 列表页 chunk 中明确调用
makeToken("/api/movie")。 - 公共 chunk 中
makeToken明确是SHA1(args.join(","))后 Base64。 - 列表页跳转详情时调用
transfer(movie.id)。 transfer明确是固定前缀拼接 id 后 Base64。- 纯 Python 生成新 token 后,接口返回 200,并拿到列表和详情数据。
到这里,算法就闭环了。
8. 踩坑清单:这些地方最容易浪费时间
8.1 token 会过期
抓包的 token 不是永久 token。它包含秒级时间戳,过一段时间就会 401。
所以看到 401 不要先补 Cookie,先解 token。
8.2 签名 path 不带 query
列表页签名对象是:
text
/api/movie不是:
text
/api/movie/?limit=10&offset=08.3 详情页签名 path 不带末尾斜杠
详情接口请求 URL 形如:
text
/api/movie/{key}/?token=...但 token 的 path 是:
text
/api/movie/{key}末尾斜杠这类差异,平时看着像标点符号,调接口时就是分水岭。
8.4 Base64 不是加密
详情 key 看起来很长,但 Base64 一解就露底。
这里真正参与混淆的是固定前缀,Base64 只是把明文包装成 URL 里更"像参数"的样子。
8.5 不要过早上浏览器自动化
这类站点最优雅的解法是协议还原,浏览器可以用来观察,但最终业务调用不应该依赖浏览器。
否则本来一秒跑完的请求,最后变成"先打开页面、等加载、等 JS、再抓 token"。代码看起来很忙,效率很感人。
9. 总结
spa6.scrape.center 这次的参数逻辑可以总结为:
text
列表 token:
Base64(SHA1("/api/movie,{timestamp}") + "," + timestamp)
详情 key:
Base64("ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb" + movie_id)
详情 token:
Base64(SHA1("/api/movie/{key},{timestamp}") + "," + timestamp)它不是复杂反爬,更像一个适合训练基本功的签名题:
- 先抓接口,看参数结构。
- 再读前端 chunk,定位调用入口。
- 然后还原最小算法。
- 最后用纯协议代码验证。
爬虫逆向的核心不是把工具开满,而是把证据串起来。
当你知道服务端到底校验什么,请求就会变得很朴素。