文章目录
定义
目前关于大模型(Large Models)并没有统一的定义,通常是指参数规模庞大(顶尖大模型参数可达万亿)、训练数据庞大、能力强大的深度神经网络模型。
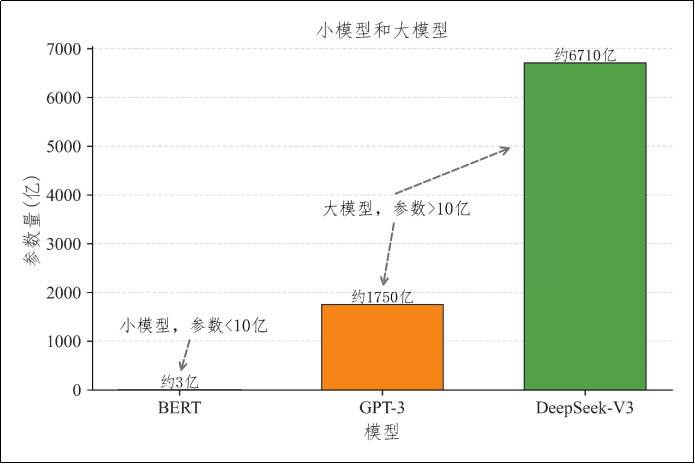
1)参数规模庞大
大模型的参数量通常在10亿以上,目前顶尖模型的参数规模已达万亿级别。
2)训练数据庞大
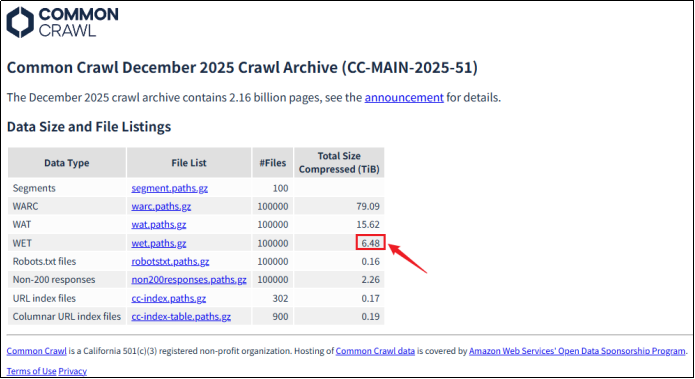
Common Crawl是大模型中的大语言模型预训练阶段的数据来源之一,它是一个公共网络爬虫项目,每隔1-2个月会发布一次主爬取的文件,包含了部分网页的快照,是互联网数据的子集。
WET是对网页内容进行抽取和清洗之后的数据,通常作为大模型预训练数据集的构建起点。完整的数据集可能包含若干次主爬取的WET,还可能包含其它渠道获取的数据。
3)能力强大
传统模型针对特定任务设计,泛化能力有限,通常只能完成单一任务 ,如:情感分析、实体标注等。
而大模型具备强大的跨任务泛化能力,单一大模型可以解决大多数传统模型可以完成的任务。
为什么会出现大模型?
大模型的出现并非偶然,而是数据、算力与模型架构协同演进的结果。
1)数据够多:训练范式的改变使得训练数据规模获得了数量级上的跃迁
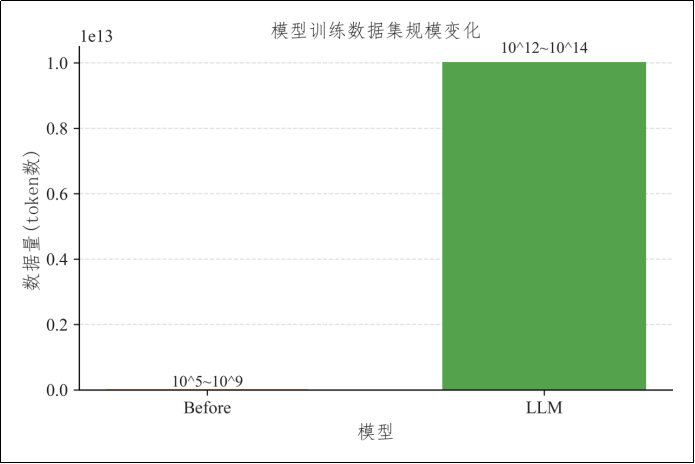
传统监督学习高度依赖人工标注数据(对原始数据进行标记、分类、注释或结构化的过程,便于机器可识别和理解),获取成本高、规模受限。
- 分类标注:为整张图像分配类别标签(人工标注为"猫"、"狗")
- 命名实体识别:标注文本中的人名、地名、组织名等实体
而大模型 主要采用自监督学习范式(如"预测下一个token"),能够直接利用海量的未标注文本与多模态数据,可用数据规模获得了数量级上的跃迁 。
如Qwen3的预训练阶段使用了约36T个token(近似理解为词)的语料,这一数据规模远超传统机器学习时代的训练数据总量。
2)算力够强:GPU/TPU等并行计算设备性能发展与分布式训练成熟
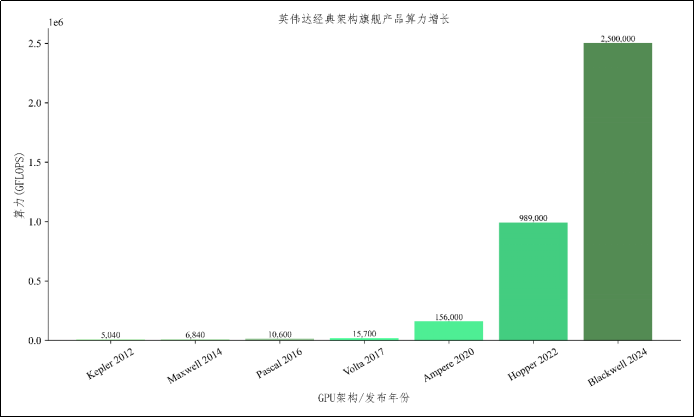
上图的纵轴是32位浮点数的计算性能(可能是FP32或BF32,取最大)。
- 深度学习训练本质是大规模矩阵运算 ,这类计算具有高度并行性,与GPU/TPU的硬件架构天然契合。
- 与此同时,数据并行、张量并行、流水线并行等分布式训练体系日趋成熟,使得跨节点、跨集群训练超大规模参数模型成为可能。
3)架构合理:Transformer架构的出现
Transformer架构摒弃了强序列依赖的递归计算方式,支持并行 计算。并且在模型规模、数据规模、训练步数 (计算量)提升时展现出稳定的性能收益(即良好的"可扩展性",如下图所示,图中的Test Loss表示损失函数的值,用于衡量模型性能,损失越小模型越强)。
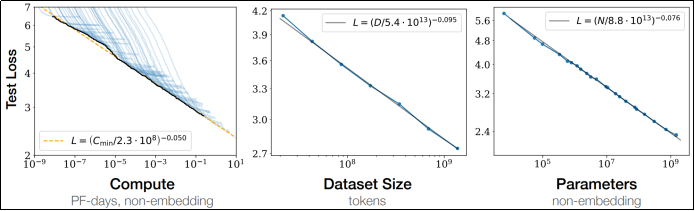
4)总结
综上,数据规模的跃迁、算力基础设施的发展,和Transformer架构优异的可扩展性,共同推动了模型规模和性能的持续膨胀,迎来了"大模型时代"。
大模型计量单位
在大语言模型(LLM)及更一般的大模型研究中,通常从参数规模、训练数据集规模和计算规模三个维度来度量模型的规模。
1)参数规模(Parameters Scale)
大模型参数规模通常以B为单位,B是Billion的缩写,即10亿,10⁹。
如Qwen3-235B模型参数量为235B,即2350亿。
2)训练数据集规模
多模态模型的数据集格式五花八门,无法用统一单位度量,此处只讨论LLM。
LLM的训练是在文本语料上进行的,语料处理的第一步是分词为一系列token,所以通常用token的数量衡量LLM训练数据集规模。
1B token=10⁹ token=10亿token
1T token=10³ B token=10¹² token=1万亿token
LLM的数据集规模通常用T token作为单位,如Qwen3预训练数据集规模为36Ttoken。
3)计算规模
计算规模是指大模型训练消耗的计算量。
大模型是一系列浮点数的组合,训练过程涉及大量浮点数运算,因此计算规模通常用FLOPs(Floating Point Operations,浮点运算次数)来衡量。
1FLOPs=1次浮点运算
1PFLOPs=10¹⁵ FLOPs
1EFLOPs=10³ PFLOPs=10¹⁸ FLOPs
现代顶尖的基础模型(LLM)通常用EFLOPs作为单位。计算规模通常不公开。
计算规模和硬件平台无关,描述模型理论上做了多少计算。
4)算力
算力是指"能算多快",是指计算设备(显卡)单位时间内完成浮点运算的能力。单位通常是FLOPS(Floating Point Operations Per Second,每秒钟完成的浮点运算次数)。
现代GPU性能强大,通常用PFLOPS或TFLOPS作为算力单位。
1P = 10³T = 10⁶G = 10⁹M = 10¹²K = 10¹⁵
1PFLOPS = 10¹⁵FLOPS
1TFLOPS = 10¹²FLOPS
浮点数有多种规格,如FP64、FP32、TF32等,同一款显卡在不同浮点数规格下的算力不同,因此在描述算力时,通常需要标注对应的浮点数规格 。
如英伟达B200显卡的单卡
- TF32算力为2.5PFLOPS
- FP32算力为80TFLOPS
- FP64算力为40TFLOPS
随着硬件性能的发展,目前顶尖显卡的算力已迈入PFLOPS级别。