给 RAG 检索装上"主题指南针":大块文本照样精准命中,延迟还砍了 5 倍
解读论文:MCompassRAG: Topic Metadata as a Semantic Compass for Paragraph-Level Retrieval
论文链接:https://arxiv.org/pdf/2606.18508
项目代码:https://github.com/AmirAbaskohi/MCompassRAG

研究背景:RAG 检索一直绕不开的"鱼与熊掌"
做过 RAG 的人都知道,整个系统好不好用,很大程度上取决于一个看似不起眼的决定------文档到底切成多大的块(chunk)。
这里面藏着一个老大难的权衡。你要是把文本切得很碎(比如一句话或者一小段),检索是精准了,但候选块的数量会爆炸式增长,索引和搜索都变慢、变贵;反过来,块切得大一点,候选数量是降下来了、效率也上去了,可问题随之而来:一个大块里往往糅杂了好几个主题和不同的话语角色,把它压成一个向量之后,语义就"糊"了。结果就是相似度分数变得很吵------真正相关的证据被一堆无关文字稀释掉,而那些只沾点边的块反倒可能被检索出来。
这个矛盾在当下越来越火的**深度研究(deep research)**任务里尤其要命。这类 Agent 要在海量、异构的语料上反复发起检索,对"又快又准"的要求被拉到极致,传统那套在固定大小块上做密集检索的做法明显扛不住。
过去大家解决这个问题的思路,基本是往"把块做得更细、更结构化、更分层"这个方向走:命题级检索把文档拆成原子单元,LLM 引导式分块去优化切块边界,RAPTOR 这类方法干脆搭一棵多层抽象的树来检索。这些招确实有效,但代价也很现实------要么增加预处理成本,要么得多维护一套索引,要么在推理时插进额外的打分、筛选乃至 LLM 重排环节,平白多出一大截延迟。对那些要反复检索的深度研究 Agent 来说,这种延迟是难以承受的。
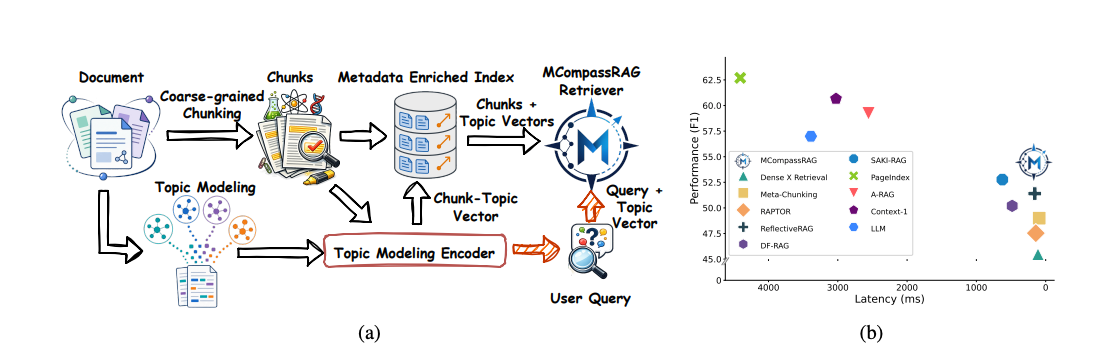
MCompassRAG 这篇论文走了一条不太一样的路:它不去把块切得更碎,也不堆叠分层结构或者依赖昂贵的检索后过滤,而是想办法让"粗块"本身变得更好搜。具体做法是给每个块附上一组主题元数据(topic metadata),让它像一个"语义指南针"一样,告诉检索器这个大块里到底覆盖了哪些主要的语义方向。这样一来,检索就不必只盯着那个糊成一团的块向量,而是能看清块内部的语义结构。
论文的三点核心贡献可以这么概括:第一,提出了 MCompassRAG 这个用主题元数据来增强粗粒度检索的框架,关键是不增加检索的搜索空间 就让大块更精确可搜;第二,设计了一套元数据"选择 + 抽象"机制,先从语料级的元数据库里挑出和查询最相关的主题信号,再把它们浓缩成一个紧凑的查询主题向量;第三,把一个 LLM 老师蒸馏进轻量级的学生检索器,用极端多标签(extreme multi-label)的目标来训练,推理时完全不需要再调用 LLM,却能保住老师大部分的检索质量。最终的成绩单很漂亮:六个检索基准上信息效率(IE)平均提升 8.24%,相比最强的 LLM 类 RAG 基线,延迟低了 5 倍以上。
相关工作:别人在改块、改查询,它在加"路标"
要理解 MCompassRAG 的定位,得先看看它和现有工作的区别在哪。
第一条线是检索粒度和结构化检索 。RAG 的核心设计选择就是检索单元的粗细:细的精确但搜索空间大、容易丢上下文;粗的保留上下文、候选少,但密集相似度会因为主题混杂而变吵。围绕这个权衡,已有的工作包括命题级检索(DenseX)、LLM 引导和自适应分块、查询自适应的粒度选择,以及跨抽象层级的分层检索(RAPTOR)。也有一些系统通过丰富检索到的证据来减少上下文碎片化,或者在选择阶段追求多样性和覆盖度。这些方法都挺有效,但通病是要么需要更细的索引,要么要自适应选择、分层结构、额外打分阶段,要么依赖 LLM 过滤。MCompassRAG 的不同在于,它保住了粗粒度检索的效率,只是用主题级元数据让大块变得更好搜。
第二条线是语义引导和高效检索。这类工作不动分块策略,而是去改查询或检索过程,比如 HyDE 这种生成"假想答案"的查询增强、查询扩展、把复杂问题拆成多步的分解式检索,还有反复检索、重排、做充分性判断的自适应迭代检索。这些方法在查询本身信息不足时很管用,但普遍会引入额外的推理时计算。另外还有生成侧的效率优化,在检索之后对上下文做压缩或重组来降低解码成本。
论文反复强调 MCompassRAG 和这些方向是正交的 :它既不额外生成查询文本,也不反复检索或在检索后压缩上下文,而是在检索之前,用语料里挖出来的主题元数据作为一个紧凑的语义向导,把检索引向和查询相关的主题方向------而且全程不需要推理时的 LLM 调用,还能和查询扩展、迭代检索、重排、上下文压缩这些技术兼容叠加使用。
核心方法:主题指南针是怎么造出来的
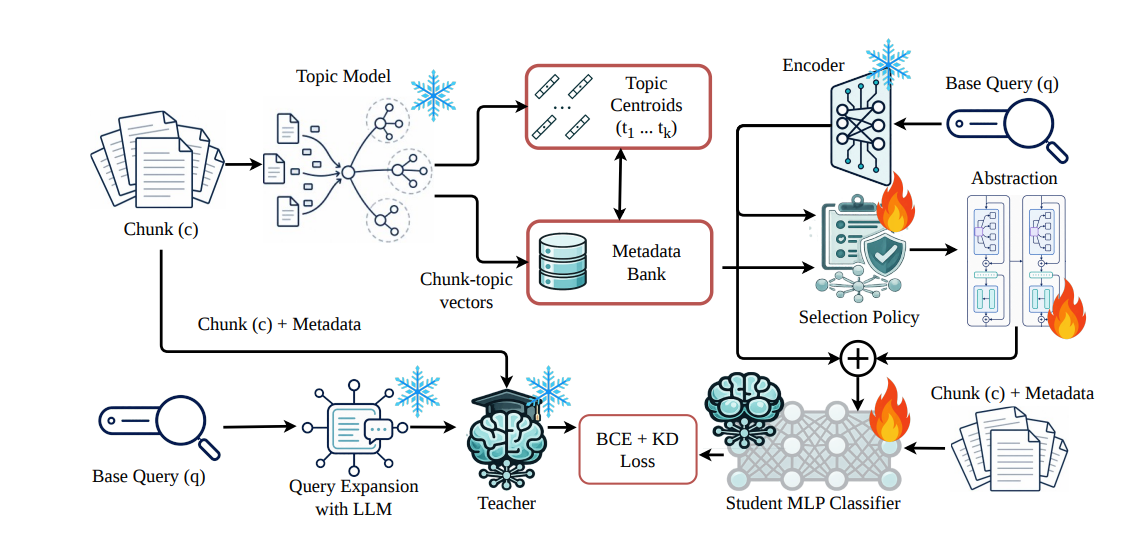
整个 MCompassRAG 的目标很直接:给定一堆块 C={c1,...,cN}\mathcal{C} = \{c_1, \ldots, c_N\}C={c1,...,cN} 和一个查询 qqq,找出最能为回答查询提供证据的 top-kkk 个块。它的关键改动是------给查询和块都加上主题级元数据,让检索器能分辨出一个大块里到底哪个语义方向跟查询有关。
第一步:建一个"主题元数据库"
论文先用一个主题模型为每个块算出一个主题分布 θc∈RK\boldsymbol{\theta}c \in \mathbb{R}^Kθc∈RK,其中 θc,r\theta{c,r}θc,r 表示主题 rrr 在块 ccc 里的强度。同时每个主题都有一个质心向量 tk∈Rd\mathbf{t}_k \in \mathbb{R}^dtk∈Rd,它落在和检索器同一个嵌入空间里,相当于这个主题的"原型"。因为块比查询长、信息也更全,所以它的主题分布可以离线、可靠地算好并缓存下来,存成一个语料级的元数据库:
M={θc1,...,θcN}. \mathcal{M} = \{\boldsymbol{\theta}{c_1}, \ldots, \boldsymbol{\theta}{c_N}\}. M={θc1,...,θcN}.
这个库的意义在于,它给整个语料画了一张"语义地图"。当一个新查询进来时,因为查询本身太短、它自己的主题分布并不可靠,MCompassRAG 不直接用查询的主题分布,而是从这张地图里挑出相关的主题分布,再抽象成一个紧凑的查询侧主题表示。
第二步:选择 + 抽象,把查询变得"主题感知"
查询先被学生编码器 fψf_\psifψ 编码成 eq=fψ(q)\mathbf{e}q = f\psi(q)eq=fψ(q)。然后每个元数据条目被转成一个嵌入空间的摘要 mi=∑k=1Kθci,ktk\mathbf{m}i = \sum{k=1}^{K} \theta_{c_i, k} \mathbf{t}_kmi=∑k=1Kθci,ktk,选择器给查询和每个摘要打一个相容性分数:
ai=ws⊤eq;mi+bs, a_i = \mathbf{w}_s^\top \\mathbf{e}_q; \\mathbf{m}_i + b_s, ai=ws⊤eq;mi+bs,
再经过 softmax 得到 sis_isi,挑出 top-LLL 个条目。接着把这些选出来的主题分布堆起来,过一个两层的 Transformer 编码器,再做平均池化,得到一个去噪后、更平滑的查询主题分布 θ^q\widehat{\boldsymbol{\theta}}_qθ q:
θ^q=1L∑ℓ=1LHℓ(2). \widehat{\boldsymbol{\theta}}q = \frac{1}{L} \sum{\ell=1}^{L} \mathbf{H}_\ell^{(2)}. θ q=L1ℓ=1∑LHℓ(2).
这一步很关键:选择负责挑出相关的元数据,抽象负责把它们融合去噪------两者缺一不可。最后,块的表示拼成 rc=ec;gc\mathbf{r}_c = \\mathbf{e}_c; \\mathbf{g}_crc=ec;gc,查询的表示拼成 rq=eq;gq\mathbf{r}_q = \\mathbf{e}_q; \\mathbf{g}_qrq=eq;gq,其中 g\mathbf{g}g 都是由各自 top-MMM 个主题的质心加权聚合而来。
第三步:当成"极端多标签分类"来做检索
学生检索器用一个三层 MLP 给每个查询-块对打分:
z(q,c)=MLPϕ(rq;rc). z(q, c) = \text{MLP}_\phi(\\mathbf{r}_q; \\mathbf{r}_c). z(q,c)=MLPϕ(rq;rc).
这个设计很巧妙------它把检索直接当成一个极端多标签分类问题:每个块就是一个候选标签,一个查询可能对应多个相关块。

训练:让学生"猜"出老师才知道的上下文
训练这块是整篇论文的点睛之笔。研究者用 GPT-4o 为每个块生成一个基础查询 qiq_iqi 和一个扩展查询 q~i\widetilde{q}_iq i------扩展查询会从相邻块里补充一些背景信息,但不泄露答案。然后用 Qwen3-32B 当 LLM 老师,老师看的是信息更全的扩展查询 来判断相关性,学生只能看到基础查询。
这种"信息不对称"是故意设计的:它逼着学生通过主题元数据的选择和抽象,去自己恢复那段缺失的上下文。训练目标把硬标签的交叉熵和软蒸馏结合起来:
L=(1−α) LBCE+α LKD, \mathcal{L} = (1 - \alpha)\,\mathcal{L}{\text{BCE}} + \alpha\,\mathcal{L}{\text{KD}}, L=(1−α)LBCE+αLKD,
其中蒸馏项让学生去对齐老师的软分数:
LKD=KL(σ(zT/τ) ∥ σ(z/τ)). \mathcal{L}_{\text{KD}} = \text{KL}\big(\sigma(z^{\text{T}}/\tau) \,\|\, \sigma(z/\tau)\big). LKD=KL(σ(zT/τ)∥σ(z/τ)).
训练时只更新元数据选择器、抽象模块和 MLP 分类器,编码器、主题质心、缓存的主题分布全部冻结。到了推理阶段,因为所有块的嵌入、主题分布、增强表示都已离线算好,在线只需要做轻量的选择、抽象和打分,一次 LLM 调用都不用。
实验效果:逼近"开挂"的 LLM 检索器,成本却低得多
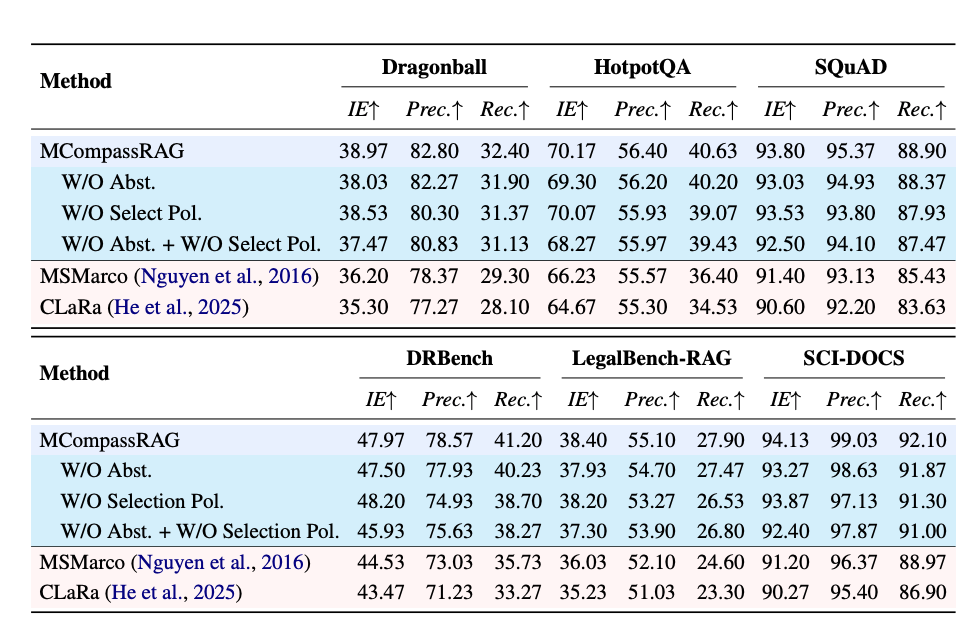
论文用 Qwen3-Embedding-4B 当学生编码器、Qwen3-32B 当老师和最终生成器,主题模型用的是 CEMTM(K=100K=100K=100),在六个检索基准 + LongBenchV2 上做了相当全面的评测。评价指标里最核心的是信息效率 IE@k = Precision@k × Recall@k。
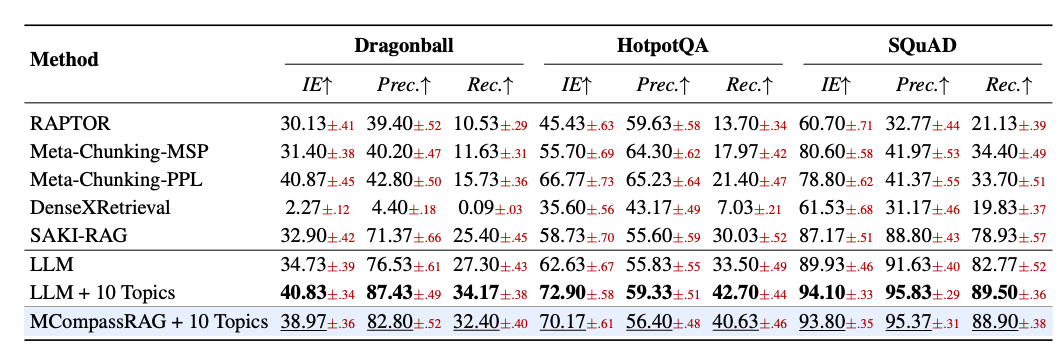
先看检索质量。带 10 个主题信号的 MCompassRAG 在每一个基准、每一个指标上都稳定超过了所有非 LLM 基线 。提升最明显的是那些更难的多跳基准:在 DRBench 上,它的 IE 做到 47.97,而最强的非 LLM 基线 SAKI-RAG 只有 37.47。更有意思的是,它已经非常接近 LLM + 10 Topics 这个"作弊上界"------后者在检索时真的调用了完整的 LLM,而 MCompassRAG 完全不用:在 SCI-DOCS 上 IE 差距不到 1 分(94.13 vs. 94.67),SQuAD 上也只差 0.3 分,其余基准也都在 2--3 分以内。论文特别指出,纯文本 LLM 和"LLM + 主题"两行之间一直存在的稳定差距,恰恰证明了主题元数据本身就携带了超出原始块嵌入的引导价值,而 MCompassRAG 是通过轻量蒸馏、而非运行时的 LLM 推理,高效地榨出了这部分价值。
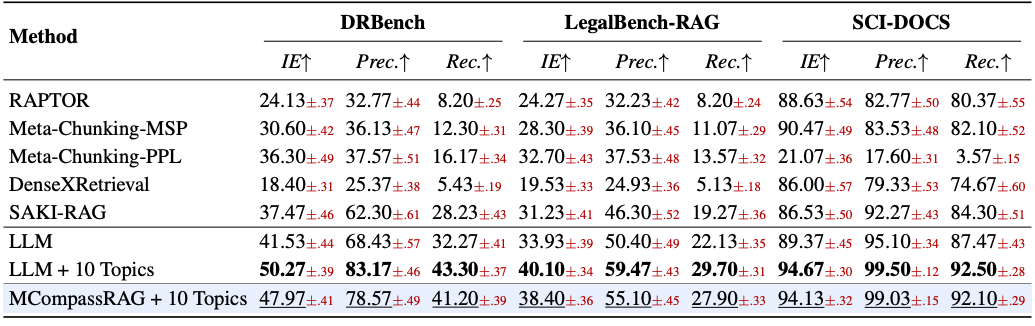
再看下游表现和效率,这是它真正的杀手锏。MCompassRAG 平均每个查询只用 4126 个 token、端到端延迟 174ms ,比两个最强的高效基线 SAKI-RAG(5584 token、925ms)和 REFRAG(7800 token、720ms)都要省、要快得多,而生成质量依然有竞争力。跟那些长上下文方法比,它的 token 用量更是只有 PageIndex 和 LLM 基线的十分之一不到,生成分数却没拉开太大差距。它和那几个高质量方法之间剩下的一点差距,主要来自对方在推理时用了 LLM 重排或上下文选择------而 MCompassRAG 靠纯主题引导的检索,就把这部分质量大半找了回来。
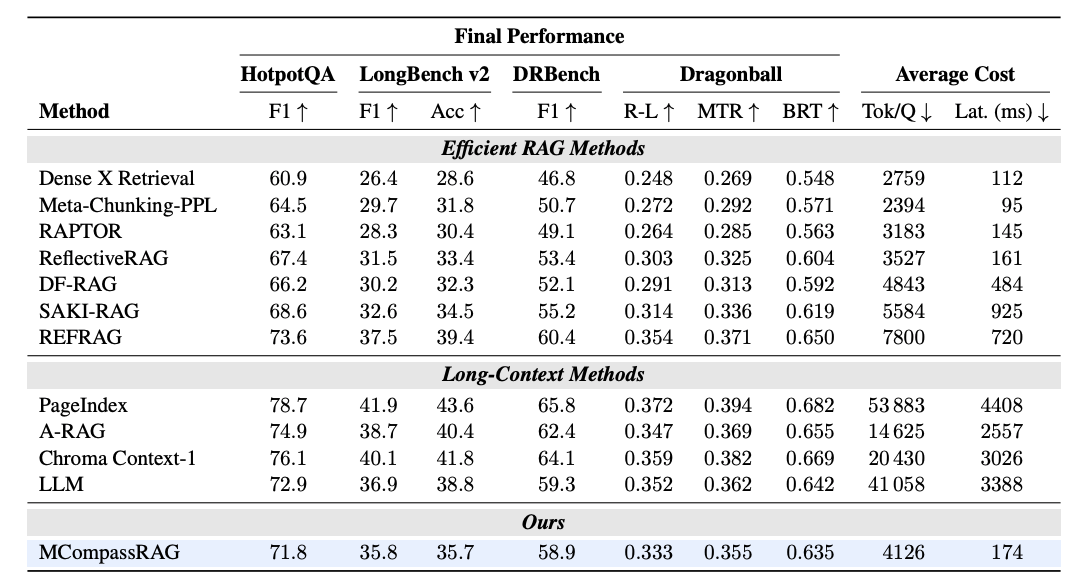
消融实验也讲了几个有用的结论。选择策略和抽象模块两个都必须有 ,少了任何一个 IE 都会掉,两个都去掉掉得最狠。主题数量上存在一个甜点区------大概 12 到 15 个主题 时 IE 最高,再多反而会引入噪声、稀释原本的查询-块信号。更让人安心的是泛化性:哪怕完全不用目标基准的数据、只在 MS Marco 或 CLaRa 这类通用数据上训练,它依然能大幅超过所有非 LLM 基线,说明这套蒸馏流程学到的是可迁移的检索行为,而不是死记某个基准的套路------这对实际部署到新领域、不用额外标注非常重要。此外,换不同的嵌入模型、换不同的主题模型(ETM、CWTM、DSL-Topic、CEMTM),结论都站得住,说明增益不是单靠一个强 backbone 撑起来的。
论文附录里还放了两个很直观的定性例子(比如 M&A 合同里"Superior Proposal"和"Acquisition Proposal"两个定义因为用词高度重叠,纯余弦相似度会选错,而主题信号能把正确的那个顶到第一名)。
论文总结
与其把文本切得更碎、或在检索时插一个昂贵的 LLM 来重排,不如给粗块贴上"主题元数据"当指南针------既保留了大块的效率,又拿回了精准检索的质量,而且推理时一次 LLM 都不用调。
说白了,它把"块要切多大"这道一直让人头疼的二选一题,换了个思路绕了过去:不在块的尺寸上较劲,而是给块加一层语义路标。这也让它特别适合那些要反复检索、对延迟极度敏感的深度研究 Agent 场景------效率优势会随着检索轮数不断累积放大。