0. 前言
在性能优化领域,Linux从来不是一个黑盒系统。内核将几乎所有关键的运行时信息都暴露在/proc和/sys文件系统中,配合一系列命令行工具,工程师可以精确地观测系统的真实运行状态。对于高性能计算、数据库、AI推理等场景,性能问题往往不在算法本身,而在于系统资源的实际分配方式与预期是否一致。
本文的目标是:让读者理解CPU上下文切换的完整机制,掌握核心观测工具的使用方法,并建立起系统化的性能分析思维。
1. CPU上下文切换的触发场景
CPU上下文切换是操作系统实现多任务并发的核心机制。当内核决定暂停当前任务、切换到另一个任务执行时,必须保存当前任务的CPU寄存器状态和程序计数器,然后加载新任务的上下文信息。这个过程虽然在微秒级别完成,但频繁的切换会带来显著的性能开销。
结合上下文切换的类型和进程生命周期,可以归纳出以下五种典型的触发场景:
1.1 时间片耗尽
现代操作系统采用时间片轮转调度算法,将CPU执行时间划分为固定长度的时间片(通常为几毫秒到几十毫秒)。每个可运行的进程被分配一个时间片,当时间片用完后,无论任务是否完成,调度器都会强制挂起当前进程,切换到下一个就绪进程。这是最常见的上下文切换场景,也是系统在无外部事件干预下的默认行为。
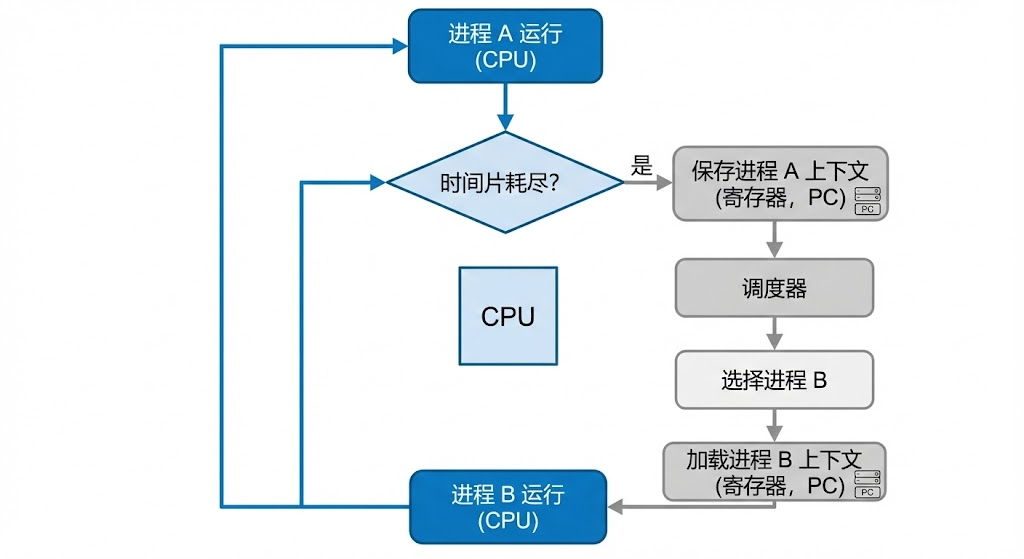
1.2 主动让出CPU
进程可以通过系统调用主动放弃CPU使用权。最典型的例子是调用sleep()函数,进程会进入睡眠状态,等待指定时间后被唤醒。此外,当进程调用阻塞式I/O操作(如read()读取磁盘文件)时,由于I/O操作耗时较长,进程会主动让出CPU,等待I/O完成后再被调度执行。
c
// 示例:进程主动让出CPU的几种方式
#include <unistd.h>
#include <sched.h>
// 方式1:sleep系统调用
sleep(1); // 睡眠1秒,主动让出CPU
// 方式2:sched_yield显式让出
sched_yield(); // 让出CPU给同优先级的其他进程
// 方式3:阻塞式I/O
char buf[1024];
read(fd, buf, sizeof(buf)); // 等待I/O完成,期间让出CPU1.3 优先级抢占
Linux调度器支持进程优先级机制。当一个高优先级进程变为可运行状态时(例如从睡眠中被唤醒),调度器会立即抢占当前正在运行的低优先级进程,将CPU分配给高优先级进程。实时进程(SCHED_FIFO、SCHED_RR调度策略)具有比普通进程更高的优先级,可以抢占任何普通进程。
1.4 资源等待
当进程请求的系统资源暂时不可用时,进程会被挂起等待。常见的资源等待场景包括:等待互斥锁(mutex)、等待信号量(semaphore)、等待内存分配、等待网络数据到达等。资源等待导致的上下文切换通常意味着系统存在资源竞争或资源不足的问题。
1.5 硬件中断
当外部硬件设备(如网卡、磁盘控制器、定时器)产生中断信号时,CPU会暂停当前任务,转而执行中断处理程序。中断处理完成后,可能会唤醒等待该事件的进程,从而触发进程调度和上下文切换。硬件中断是系统响应外部事件的核心机制,但过于频繁的中断也会影响系统性能。
1. 使用vmstat观察系统级上下文切换
vmstat(Virtual Memory Statistics)是Linux系统中最常用的性能监控工具之一,它能够提供系统整体的进程、内存、交换分区、I/O和CPU使用情况的统计信息。对于上下文切换分析而言,vmstat是首选的入门级工具。
2.1 vmstat基本用法
vmstat命令的基本语法为vmstat [间隔秒数] [执行次数]。以下是一个典型的输出示例:
bash
# 每3秒输出一次系统状态
root@node:~# vmstat 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 477767936 883712 9970296 0 0 0 2 0 0 0 0 99 0 0
0 0 0 477766688 883716 9970120 0 0 0 12 380 754 0 0 100 0 0
0 0 0 477770016 883716 9970292 0 0 0 0 1956 4706 1 1 98 0 02.2 关键指标解读
在vmstat的输出中,与CPU上下文切换直接相关的指标位于procs和system两个区域:
procs区域(进程状态):
| 指标 | 含义 | 分析要点 |
|---|---|---|
| r | 运行队列中的进程数(正在运行+等待CPU的进程) | 若持续大于CPU核心数,说明CPU资源紧张 |
| b | 处于不可中断睡眠状态的进程数 | 通常在等待I/O,若持续较高说明I/O存在瓶颈 |
system区域(系统活动):
| 指标 | 含义 | 分析要点 |
|---|---|---|
| in | 每秒中断次数(包括时钟中断) | 反映硬件事件的频率 |
| cs | 每秒上下文切换次数 | 核心指标,过高说明切换开销大 |
cpu区域(CPU使用率):
| 指标 | 含义 | 分析要点 |
|---|---|---|
| us | 用户态CPU使用率 | 应用程序消耗的CPU时间 |
| sy | 内核态CPU使用率 | 系统调用、上下文切换消耗的CPU时间 |
| id | CPU空闲率 | 系统整体负载的直观反映 |
| wa | 等待I/O的CPU时间占比 | I/O瓶颈的重要指标 |
2.3 上下文切换的判断标准
上下文切换次数(cs)本身没有绝对的"正常值",需要结合系统配置和业务特点来判断。以下是一些经验性的参考标准:

当观察到cs值异常升高时,通常伴随着以下现象:
- sy(内核态CPU使用率)明显上升
- r(运行队列)持续大于CPU核心数
- 应用响应延迟增加
3. 使用pidstat观察进程级上下文切换
vmstat提供的是系统整体视角,当发现上下文切换异常时,需要进一步定位到具体的进程。pidstat是sysstat工具包中的一个命令,能够按进程或线程维度展示CPU、内存、I/O等详细统计信息。
3.1 pidstat基本用法
使用-w参数可以查看进程的上下文切换统计:
bash
# 每3秒输出一次进程上下文切换信息
root@node:~# pidstat -w 3
Linux 4.15.0-58-generic (node) 11/26/2025 _x86_64_ (64 CPU)
09:20:52 PM UID PID cswch/s nvcswch/s Command
09:20:55 PM 0 8 0.33 0.00 ksoftirqd/0
09:20:55 PM 0 9 12.83 0.00 rcu_sched
09:20:55 PM 0 12 0.33 0.00 watchdog/0
09:20:55 PM 0 1234 45.67 2.33 mysql
09:20:55 PM 0 5678 123.45 15.67 java3.2 自愿与非自愿上下文切换
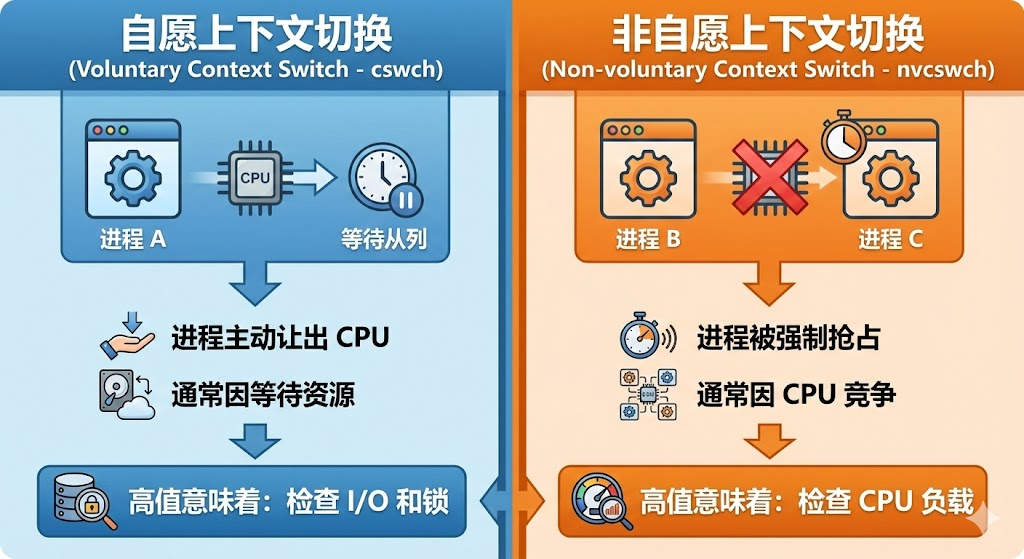
pidstat输出中最关键的两个指标是cswch和nvcswch,它们代表了两种本质不同的上下文切换类型:
cswch(voluntary context switches)- 自愿上下文切换:
自愿上下文切换是指进程主动放弃CPU而发生的切换。典型场景包括:
- 等待I/O操作完成(磁盘读写、网络收发)
- 等待锁或信号量
- 调用sleep()等主动让出CPU的系统调用
- 等待其他系统资源
当cswch值较高时,通常意味着进程在等待某种资源,需要检查I/O性能、锁竞争等问题。
nvcswch(non-voluntary context switches)- 非自愿上下文切换:
非自愿上下文切换是指进程被强制剥夺CPU而发生的切换。典型场景包括:
- 时间片耗尽被调度器抢占
- 被更高优先级进程抢占
- CPU资源竞争激烈
当nvcswch值较高时,说明系统CPU资源紧张,进程之间存在激烈的CPU竞争。
3.3 查看线程级上下文切换
在多线程应用中,问题可能出在某个特定线程上。使用-t参数可以查看线程级别的统计:
bash
# 查看线程级上下文切换(-w上下文切换 -t线程)
root@node:~# pidstat -wt 3
Linux 4.15.0-58-generic (node) 11/27/2025 _x86_64_ (64 CPU)
05:17:45 PM UID TGID TID cswch/s nvcswch/s Command
05:17:48 PM 0 8 - 10.79 0.00 ksoftirqd/0
05:17:48 PM 0 - 8 10.79 0.00 |__ksoftirqd/0
05:17:48 PM 0 9 - 107.62 0.00 rcu_sched
05:17:48 PM 0 - 9 107.62 0.00 |__rcu_sched
05:17:48 PM 0 4695 - 1.27 0.00 ntpd
05:17:48 PM 0 - 4695 1.27 0.00 |__ntpd
05:17:48 PM 0 - 4832 3.81 0.00 |__worker_thread
05:17:48 PM 0 - 4863 48.25 0.00 |__log_writer输出中的TGID(Thread Group ID)等同于进程ID,TID是线程ID。带有|__前缀的行表示该进程下的具体线程。通过这种方式,可以精确定位到哪个线程导致了上下文切换异常。
4. CPU性能问题分析方法论
掌握了vmstat和pidstat这两个核心工具后,需要建立一套系统化的分析方法。CPU性能问题的排查应当遵循"从宏观到微观、从现象到根因"的原则。
4.1 分析流程
当系统出现性能问题时,建议按照以下流程进行排查:
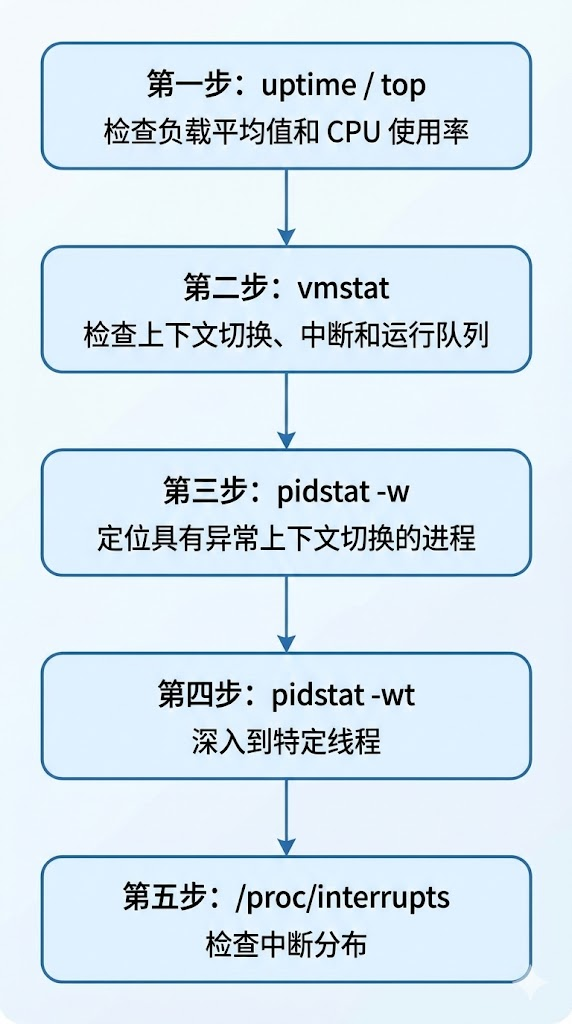
4.2 关键指标关联分析
单独看某一个指标往往难以得出结论,需要将多个指标关联起来分析:
场景一:r值高 + cs值高 + nvcswch高
这种组合说明运行队列中有大量进程在争抢CPU,导致频繁的非自愿上下文切换。根本原因是CPU资源不足,解决方案包括:优化应用减少CPU消耗、增加CPU核心数、或者将部分负载迁移到其他服务器。
场景二:cs值高 + cswch高 + wa值高
这种组合说明进程频繁因为等待I/O而让出CPU。根本原因是I/O性能瓶颈,需要检查磁盘性能、网络延迟等。
场景三:sy值高 + cs值高
内核态CPU使用率高,伴随大量上下文切换,说明系统调用过于频繁或存在内核级别的性能问题。需要使用perf等工具进一步分析内核热点。