2026国产时序数据库选型指南:当"融合多模"成为破局关键
在"数字中国"与工业物联网的双重浪潮下,时序数据库早已不是小众技术。2026年的国产赛道,谁能在性能之外给出更优解?本文带你一览主流产品格局,并深度拆解金仓数据库的"融合多模"差异化打法。
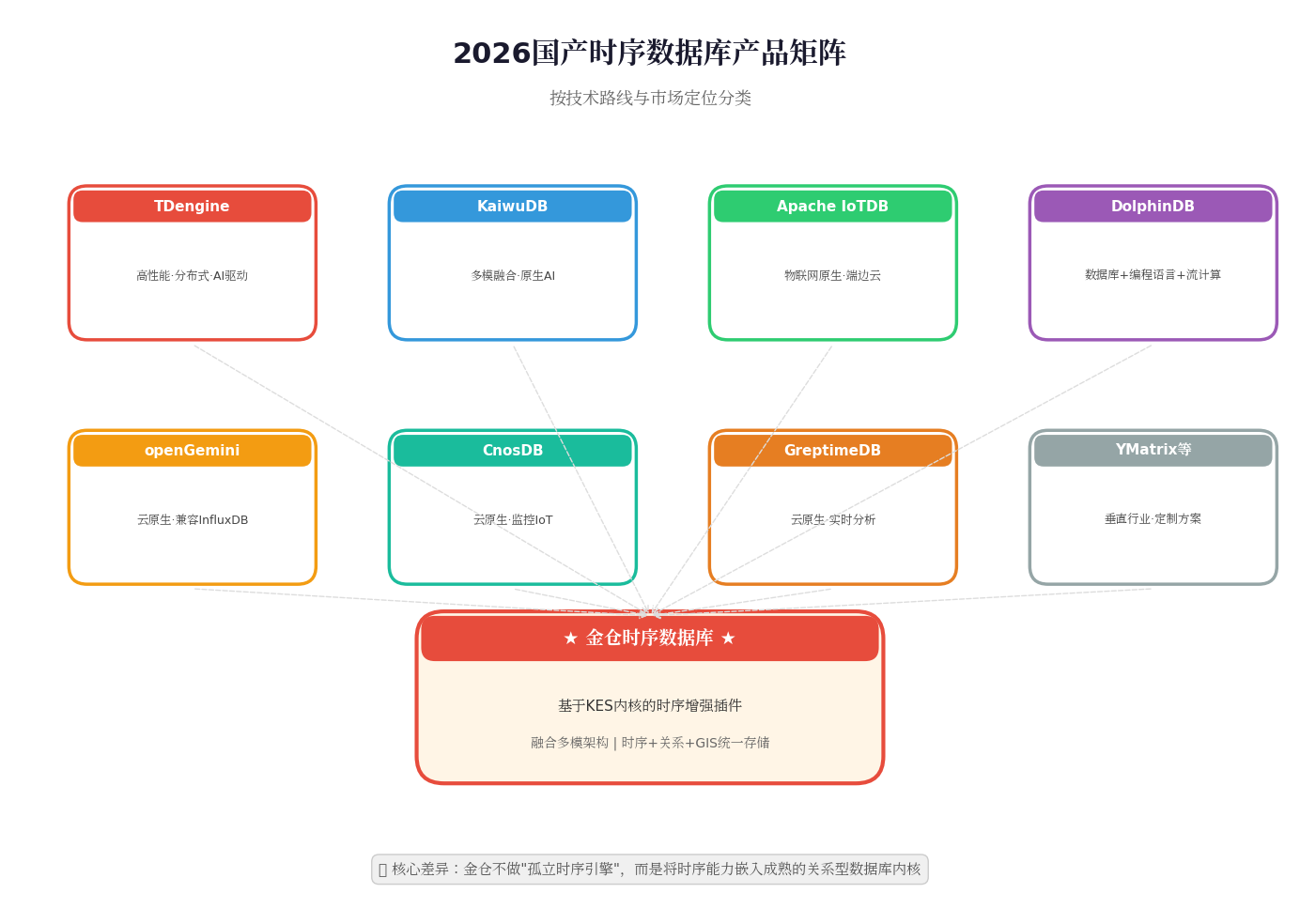
一、2026国产时序数据库全景图:百花齐放,各显神通
经过几年的野蛮生长,国产时序数据库市场已告别"概念验证"阶段,进入精耕细作的成熟期。当前主流产品按技术路线可大致分为以下几类:
| 数据库 | 厂商/社区 | 核心标签 |
|---|---|---|
| TDengine | 涛思数据 | 高性能分布式,AI驱动工业大数据平台,开源生态开放 |
| KaiwuDB | 浪潮云弈 | 分布式多模融合,时序+关系+文档统一处理,原生AI |
| Apache IoTDB | 清华/Apache | 物联网原生,"端-边-云"协同,树形数据模型 |
| DolphinDB | 智臾科技 | 数据库+编程语言+流计算,金融量化领域强势 |
| openGemini | 华为云 | 开源多模态,兼容InfluxDB,云原生高性能 |
| CnosDB | 诺司时空 | 云原生,支持分布式/集中式,监控与IoT场景 |
| GreptimeDB | 格睿科技 | 云原生分布式,主打实时分析 |
| YMatrix/RealHistorian等 | 四维纵横/紫金桥等 | 垂直行业深耕,定制化解决方案 |
| 金仓时序数据库 | 中电科金仓 | 基于KES内核的时序增强插件,融合多模架构 |
💡 一句话总结 :专业时序库在极致性能上内卷,金仓选择了一条"不孤立"的路------把时序能力嵌入成熟的关系型数据库内核。
二、深度拆解:金仓的"融合多模"到底强在哪?
大多数时序数据库选择"专精一路":极致的写入吞吐、极致的压缩比、极致的查询速度。金仓的思路却不一样------它不想让你为时序数据单独搭一套基础设施。
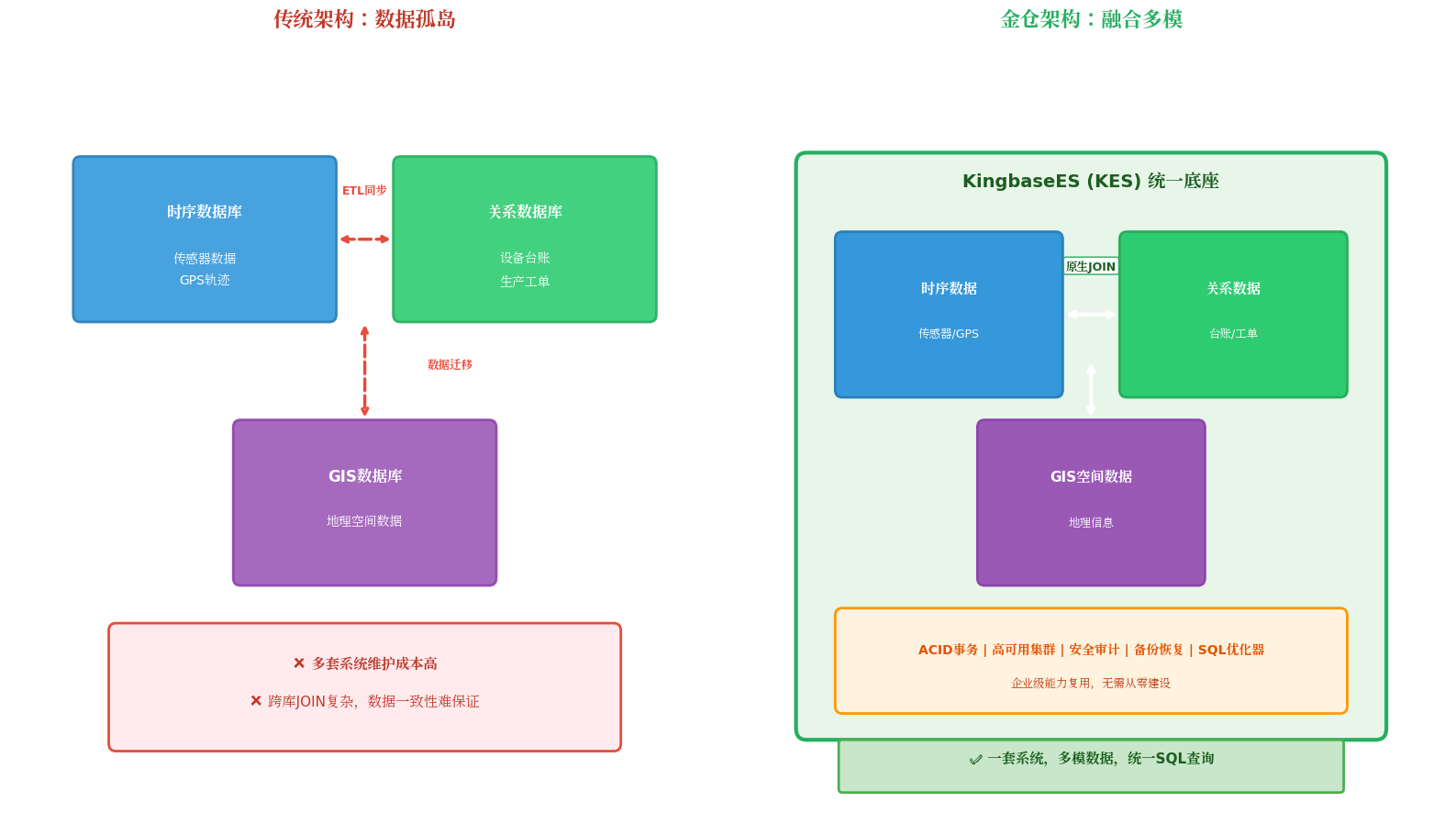
1. 内核级融合:时序数据不再是"孤岛"
传统架构下,传感器数据存在时序库,设备台账、工单信息存在关系库。要做关联分析?先ETL、再同步、再清洗,链路长得让人绝望。
金仓的做法是:时序组件直接长在 KingbaseES(KES)内核上。
- 统一底座:一套KES集群,同时承载时序表和关系表,无需额外部署
- 原生JOIN:用标准SQL(兼容Oracle/PostgreSQL语法)直接跨时序表和关系表做复杂关联查询,告别繁琐的数据搬运
- 丰富类型 :除了数值、时间戳,原生支持JSON、GIS空间数据、数组等复杂类型,工业场景里的"异构数据"一站搞定
2. 企业级能力"开箱即用"
很多专业时序库在分布式、高可用、安全审计上需要从头建设。金仓时序组件直接复用KES沉淀多年的企业级能力:
- ACID事务:时序数据写入享受完整事务保证,金融、电力调度等强一致性场景不再妥协
- 高可用架构:读写分离、共享存储、分布式集群------时序数据直接"拎包入住"
- 安全体系:行列级权限控制、数据加密、审计日志,合规要求轻松满足
- 运维生态:备份恢复、监控运维、数据迁移工具(KDTS)全部复用,团队学习成本趋近于零
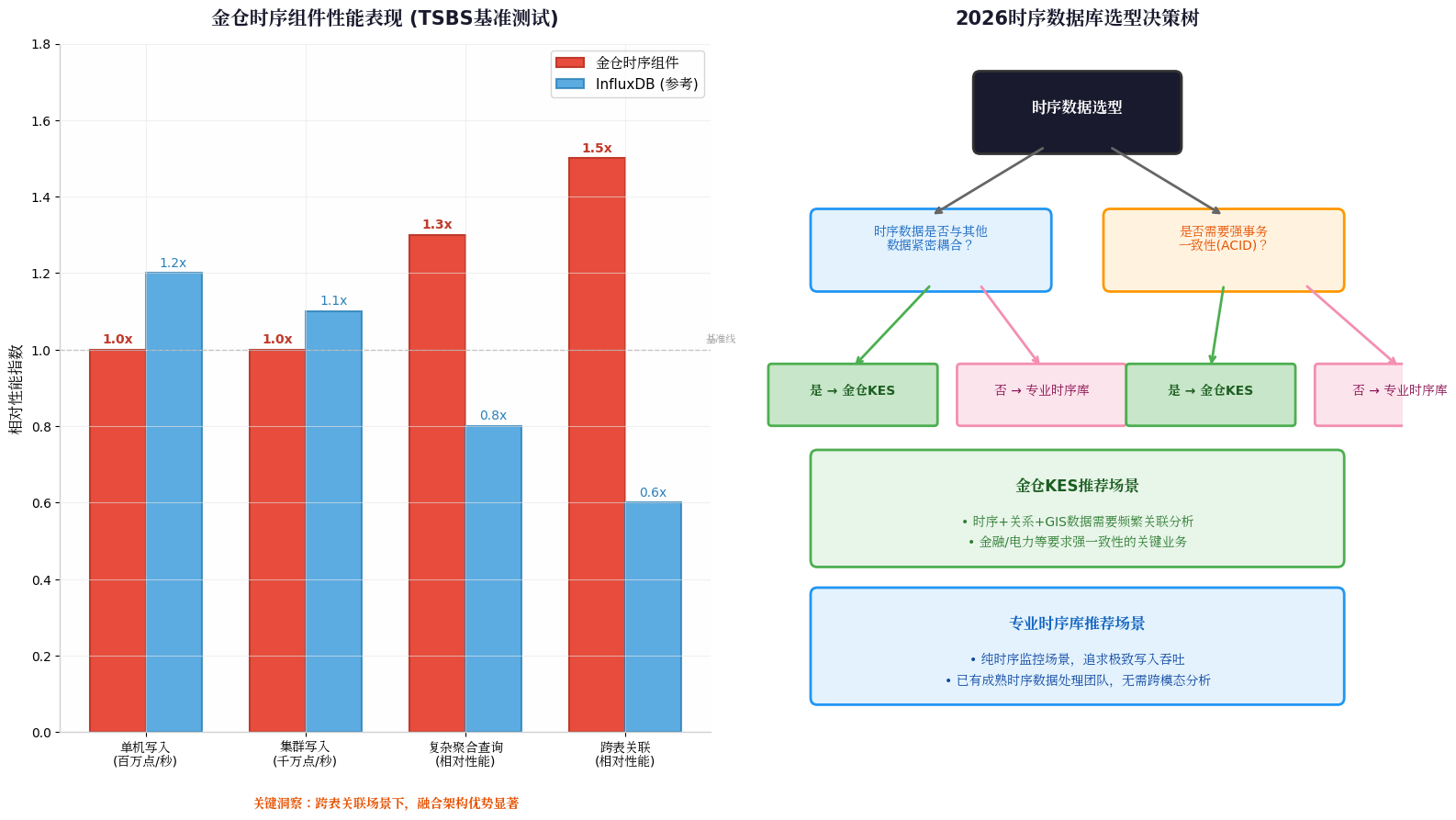
3. 复杂场景下的"反常识"性能
根据金仓官方披露的TSBS测试数据(对比InfluxDB),其表现有几个亮点:
| 维度 | 表现 |
|---|---|
| 写入吞吐 | 单机百万级、集群千万级数据点/秒(优化分区+并行插入) |
| 复杂查询 | 多维度聚合、跨表关联场景下,凭借成熟SQL优化器,性能显著优于部分原生时序库 |
关键洞察:如果你的场景是"纯时序监控",专业时序库可能更极致;但如果你的场景是**"时序数据+业务数据深度整合分析"**,金仓的SQL优化器和融合架构反而能打出"组合拳"优势。
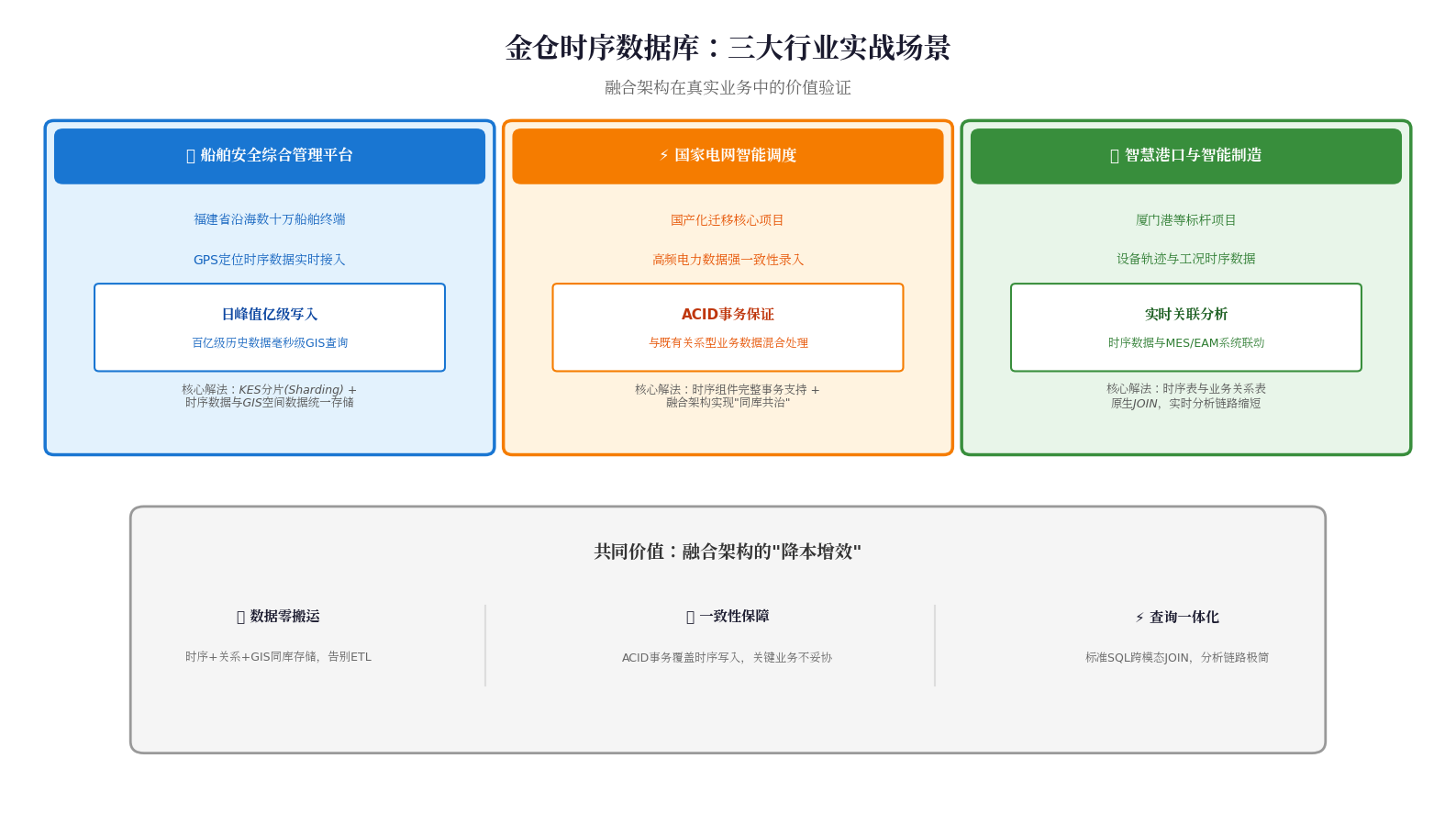
三、实战落地:融合架构在哪些场景"真香"?
金仓时序组件的差异化优势,在以下三类场景中体现得尤为明显:
🚢 场景一:福建省船舶安全综合管理平台
- 挑战:沿海数十万船舶终端的GPS定位时序数据,日峰值亿级写入,百亿级历史数据需毫秒级地理空间查询
- 解法:基于KES分片(Sharding)方案,时序数据与GIS空间数据统一存储、统一查询,无需跨系统关联
⚡ 场景二:国家电网智能电网调度系统
- 挑战:国产化迁移背景下,高频电力数据录入需强一致性,且要与大量既有关系型业务数据混合处理
- 解法:时序组件的ACID事务+融合架构,让电力时序数据与调度业务数据"同库共治"
🏭 场景三:智慧港口与智能制造厂区
- 挑战:设备轨迹、工况时序数据需与生产管理系统(MES)、设备管理系统(EAM)实时关联分析
- 解法:时序表与业务关系表原生JOIN,实时分析链路大幅缩短
四、2026选型建议:别只盯着QPS,这三点更重要
企业在2026年进行时序数据库选型时,建议跳出"唯性能论",从更宏观的视角评估:
1. 数据耦合度:你的时序数据"孤单"吗?
如果时序数据与关系数据、空间数据、JSON文档紧密耦合,需要频繁跨模态关联分析------金仓的融合多模架构能省去大量ETL和数据同步的隐性成本。
2. 团队技能栈:引入新技术的"隐性学费"
专业时序库往往意味着新的查询语言、新的运维工具、新的故障排查逻辑。如果团队已有成熟的关系型DBA体系,复用KES技能栈和工具链,TCO(总拥有成本)优势不可忽视。
3. 事务一致性:你的场景能"最终一致"吗?
金融、电力、工业控制等关键业务对数据强一致性有硬性要求。大多数原生时序库在ACID支持上相对薄弱,金仓的完整事务支持是独特的安全垫。
结语:时序数据库的下半场,"融合"与"智能"是关键词
2026年的国产时序数据库赛道,已经不再是"谁能写得更快的"单一维度竞赛。
TDengine、IoTDB、DolphinDB们在各自的优势领地持续深耕,而金仓用**"融合多模架构"走出了一条差异化路径------它未必是"万能钥匙",但对于 业务逻辑复杂、数据形态多样、对事务一致性和系统整合有高要求的企业级用户而言,它提供了一个将时序能力平滑、稳健地嵌入现有数据核心**的优秀选择。
这背后体现的,正是国产基础软件在架构设计上的深度思考:不做为了不同而不同的创新,做为了解决真实痛点而务实的创新。
🔮 展望未来:随着AI for Data、实时智能分析的普及,时序数据库的下一个战场将是"智能"与"融合"的化学反应------如何更好地将时序处理能力与多模数据、AI框架、流批计算无缝结合,是所有厂商共同的课题,也是选型时需要前置考虑的"未来兼容性"。
你在时序数据库选型中遇到过哪些坑?欢迎在评论区交流讨论!