前言
做市场、运营、竞品分析的朋友想必都有同款困扰:每天定时刷竞品售价、查关键词排名、搜集行业动态,一遍遍手动打开网页、复制整理数据,耗时又低效,一旦平台有反爬限制,还经常拿不到完整信息。
如今自动化工具普及的当下,手动采集市场情报早已过时 。今天就教大家用 Bright Data + 扣子Coze(Coze) 组合,依托++Bright Data MCP++ 能力+Coze可视化工作流,零代码搭建全自动市场情报Bot ,实现竞品监控、SERP排名抓取、行业新闻聚合全自动化,数据还能自动推送至办公软件,彻底解放双手。
一、为什么Coze原生工具,满足不了专业数据采集?
扣子Coze本身自带搜索、基础抓取能力,适合简单日常查询,但面对电商、搜索引擎、行业站点等复杂场景,短板十分明显。我们通过表格直观对比,看看接入Bright Data前后的能力差距:
|----------|-----------------|---------------------------------|
| 对比维度 | Coze 原生内置工具 | Coze + Bright Data(MCP/API) |
| 反爬能力 | 弱,高频访问易被封禁、IP拦截 | 企业级代理池,规避反爬,稳定抓取 |
| 数据覆盖 | 仅支持通用公开搜索,平台受限 | 支持电商、搜索引擎、资讯站等全平台 |
| 数据质量 | 内容杂乱,无结构化整理 | 自动清洗、格式化输出标准结构化数据 |
| 并发&稳定性 | 单次抓取量低,易中断 | 高并发采集,7×24小时稳定运行 |
| 拓展性 | 功能固定,无法深度定制 | 支持MCP、SERP API灵活对接,适配各类场景 |
简单来说:纯Coze只能做"轻量查询",搭配Bright Data后,才能成为专业的自动化数据采集、竞品监控工具 ,也是目前无代码搭建市场情报Bot的最优组合。
二、整体架构:一条链路看懂全流程
整套方案架构简单清晰,无需复杂开发,完整数据流如下:
用户触发/定时任务 → Coze Bot工作流 → 调用Bright Data MCP/API → 目标网站采集数据 → 数据清洗结构化 → 自动推送至企业微信/飞书/钉钉
全程由两大核心组件驱动:Coze负责流程编排、触发、消息推送 ,Bright Data负责底层网页抓取、SERP查询、反爬防护 ,二者通过标准接口无缝集成,普通用户也能快速上手。
三、前期前置准备(缺一不可)
开始实战前,先备好基础账号与配置信息,全程无技术门槛:
- 扣子Coze账号 :登录Coze平台,开启Bot与工作流编辑权限;
- ++Bright Data账号++ :完成注册、获取MCP服务配置信息;
- 确定输出渠道:提前配置企业微信/飞书/钉钉机器人,用于接收自动推送数据;
- 梳理采集目标:明确需要监控的竞品链接、核心关键词、行业资讯站点。
- 快速搭建排名监控Bot
依托 Bright Data MC中的search_engine + Coze 工作流,无需手动翻页查排名、统计数据。可批量监控指定关键词在搜索引擎的位次、收录情况、页面展示信息,自动对比历史数据标注排名涨跌,定时生成报表并推送至办公工具。
全程零代码运行,7×24 小时稳定抓取,既能跟踪自身站点流量词表现,也可监控竞品关键词布局,帮你实时掌握搜索流量动向。
1、 获取MCP地址
Bright Data MCP 是面向 AI Agent 的实时 Web 访问能力层,支持 60+ 工具,可帮助 Agent 获取实时网页内容,同时降低封禁、限流与 CAPTCHA 干扰。
(1)登录到++Bright Data++ 控制面板之后,选择左侧菜单中的MCP,然后点击配置MCP
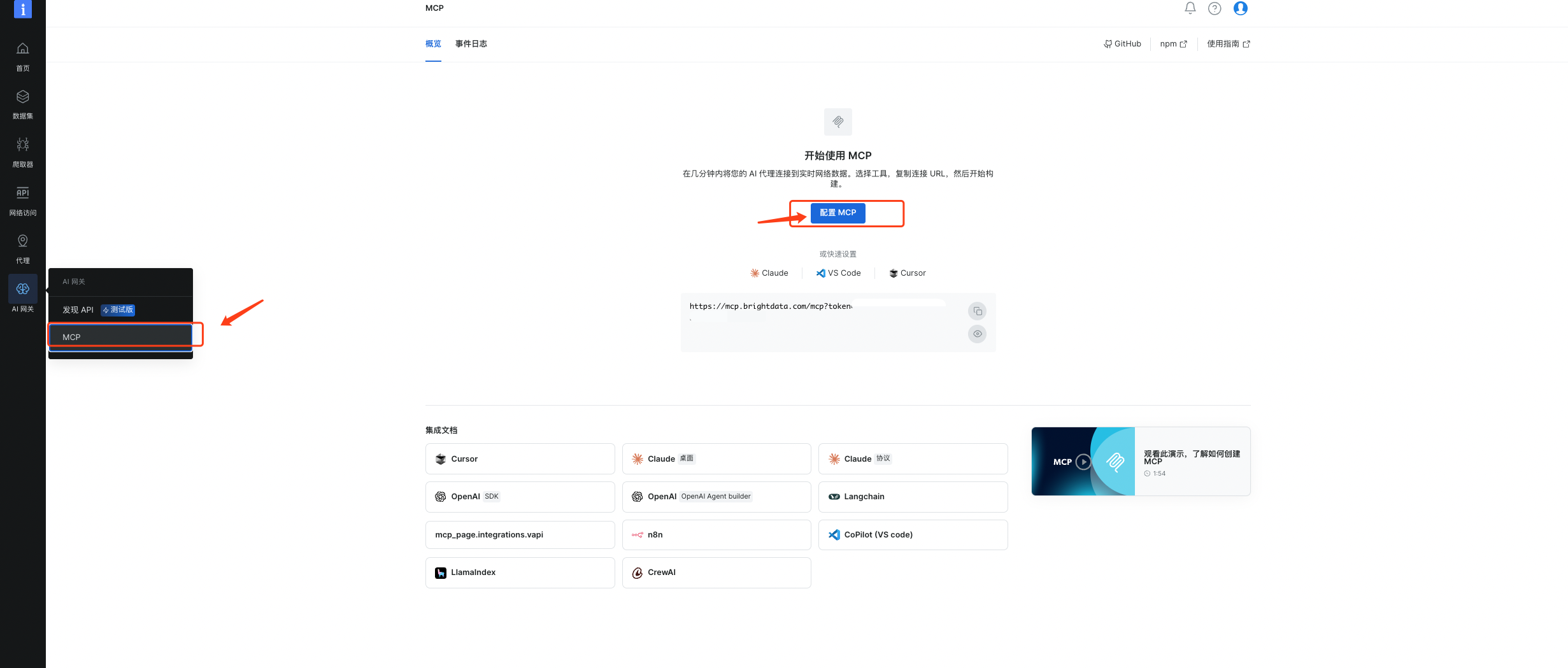
(2)选择我们需要的工具,然后点击继续配置
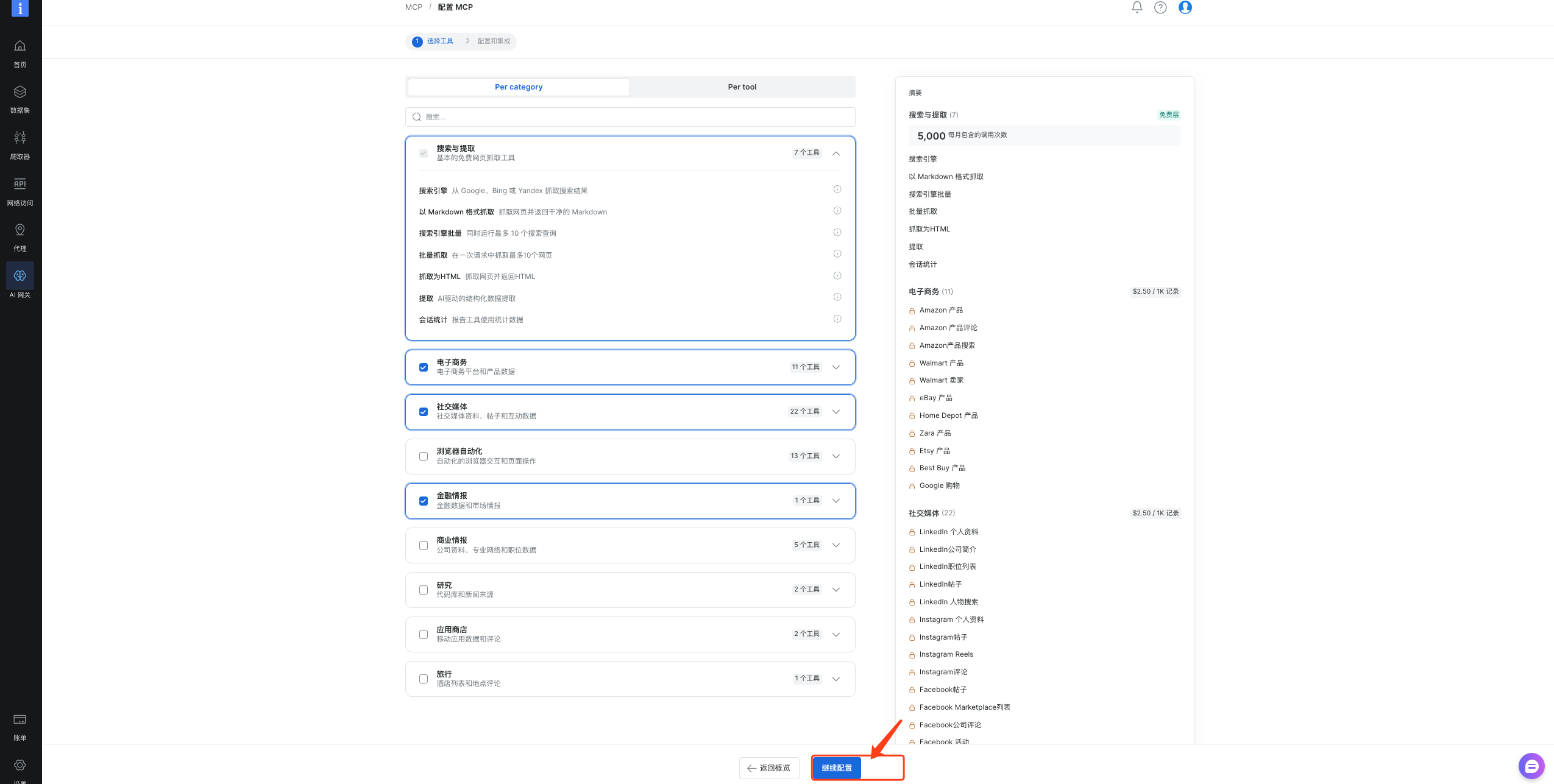 (3)接下来就可以看到MCP已经配置好了,点击复制就可以使用
(3)接下来就可以看到MCP已经配置好了,点击复制就可以使用
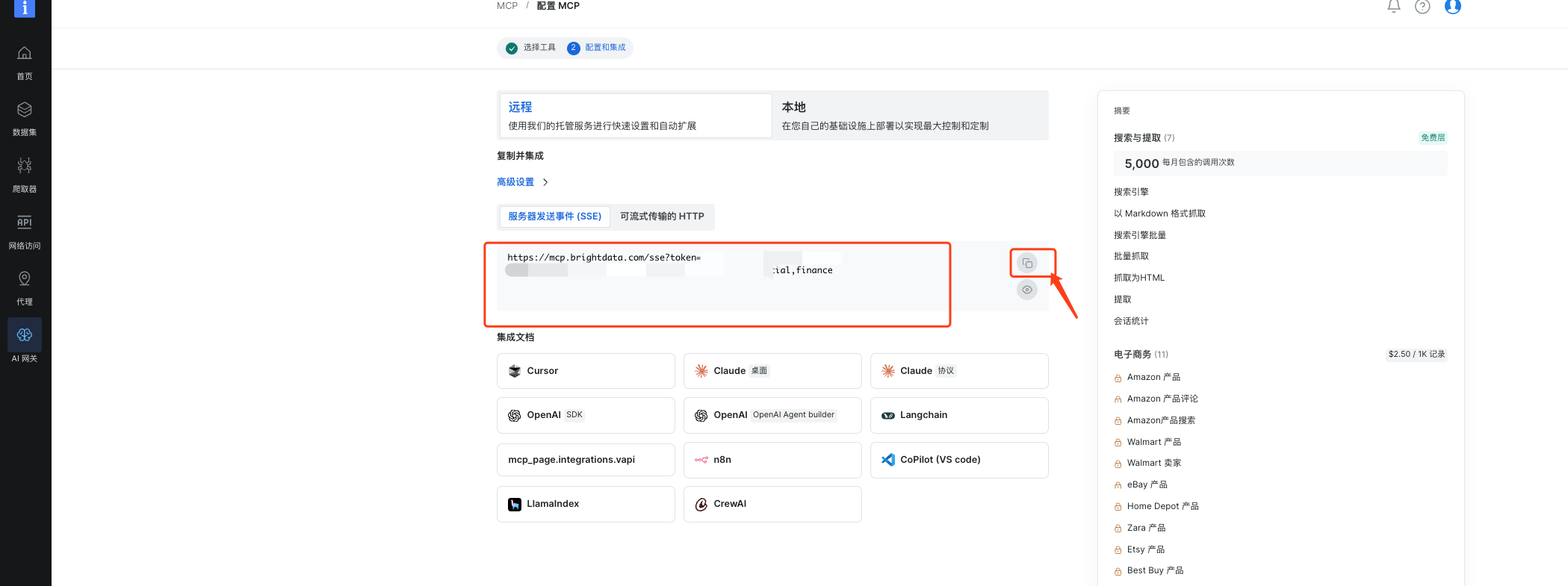
2、 添加MCP
1、选择资源库,点击右上角的添加资源,选择插件
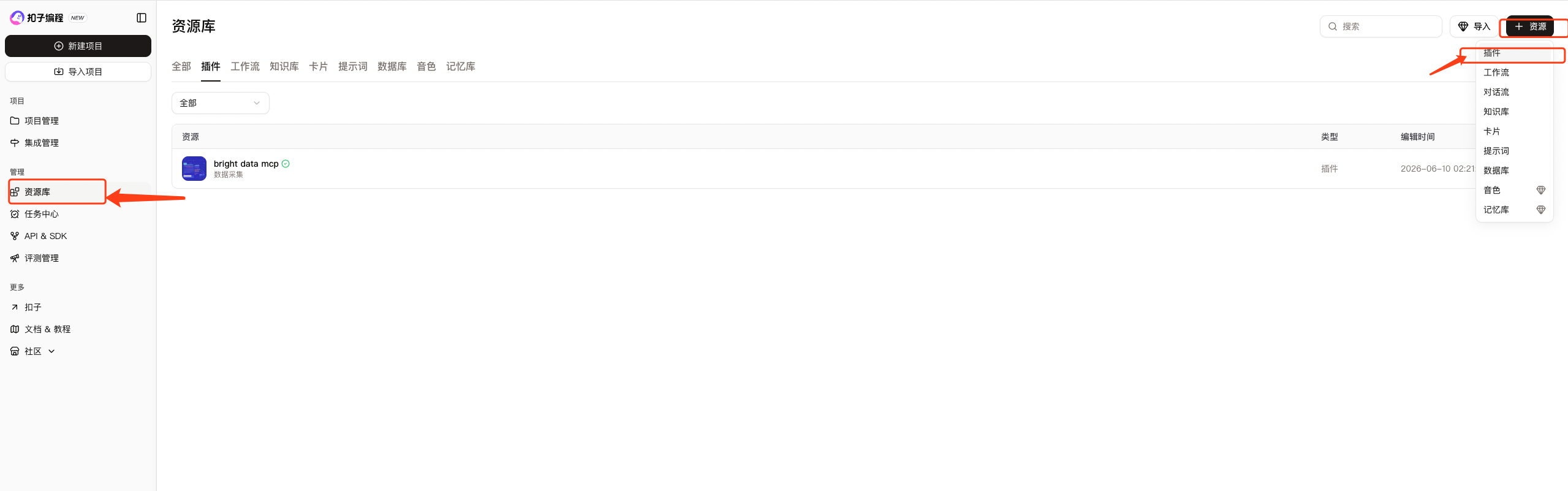
2、填写插件信息
插件名称、介绍、插件描述,选择插件类型为MCP,填写插件的URL以及授权方式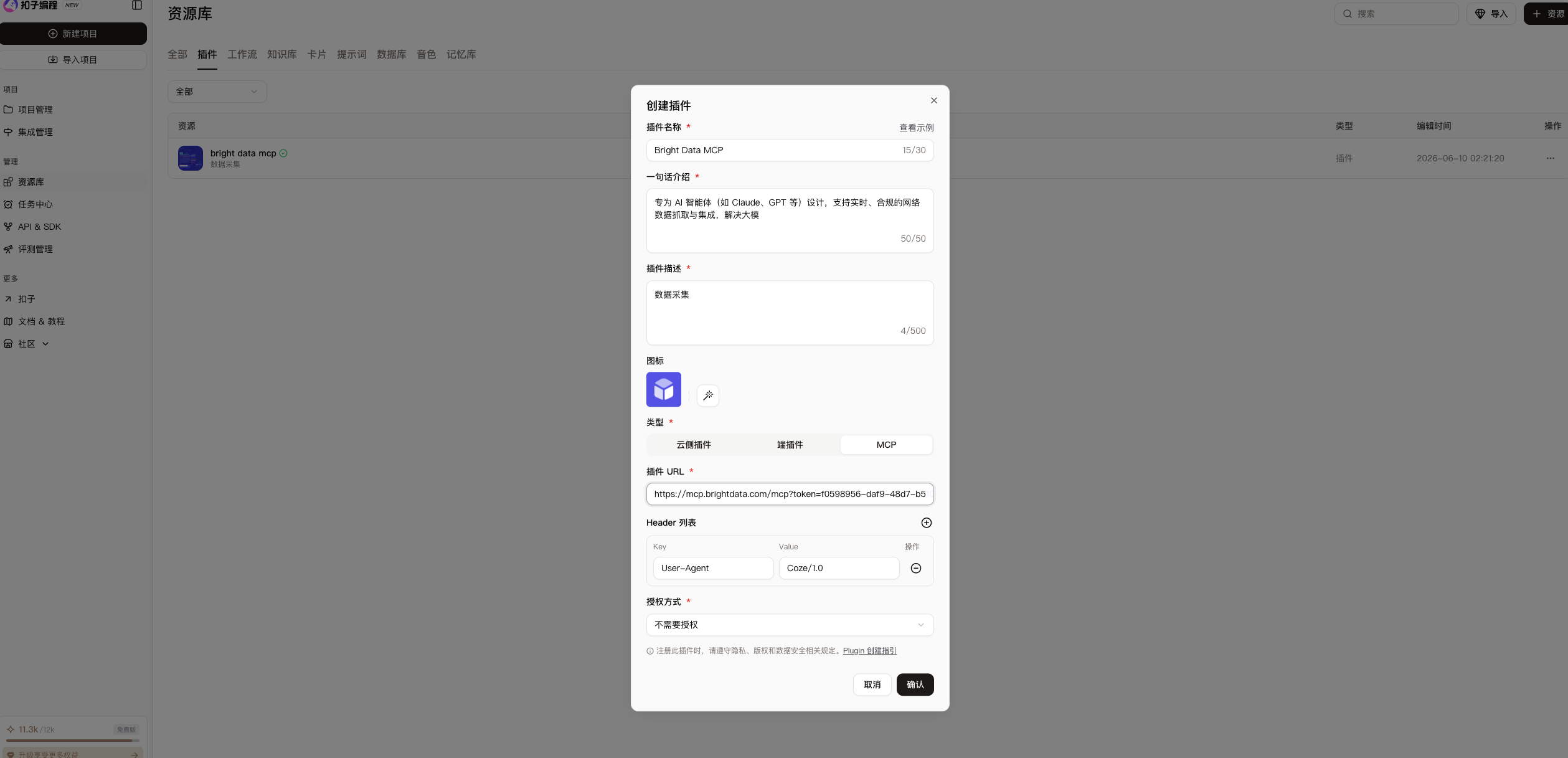
3、 创建工作流
1、新建项目,选择工作流开发
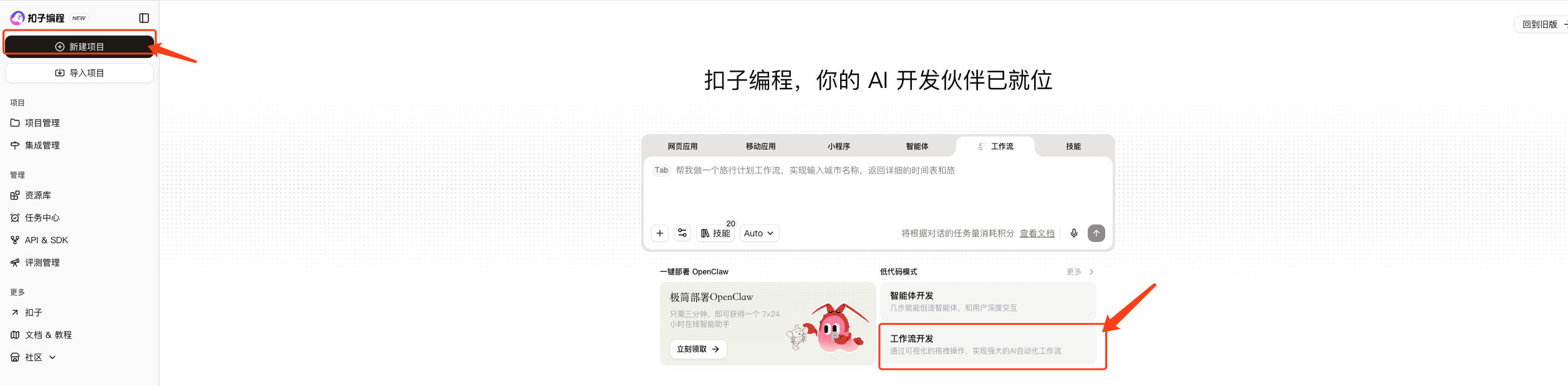 2、填写工作流名称以及描述
2、填写工作流名称以及描述
 3、设计工作流设置开始节点的变量名
3、设计工作流设置开始节点的变量名
 添加插件节点
添加插件节点
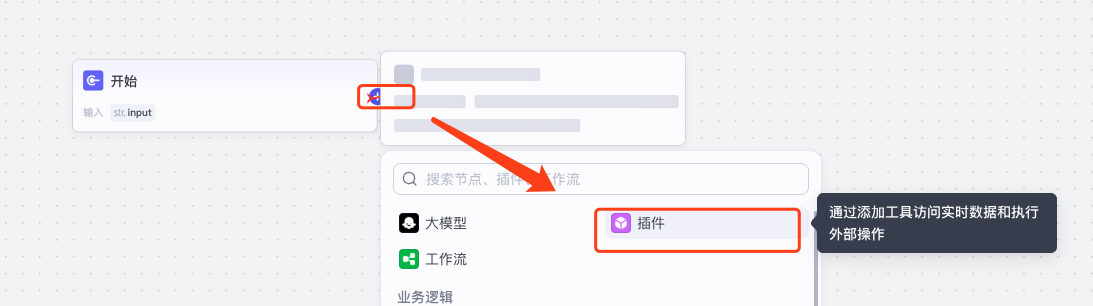
选择资源库中刚刚添加的mcp工具,这里我选择search_engine
- search_engine从谷歌、必应或Yandex中删除搜索结果。以JSON或Markdown格式返回SERP结果(URL、标题、描述),非常适合收集当前信息、新闻和详细的搜索结果。
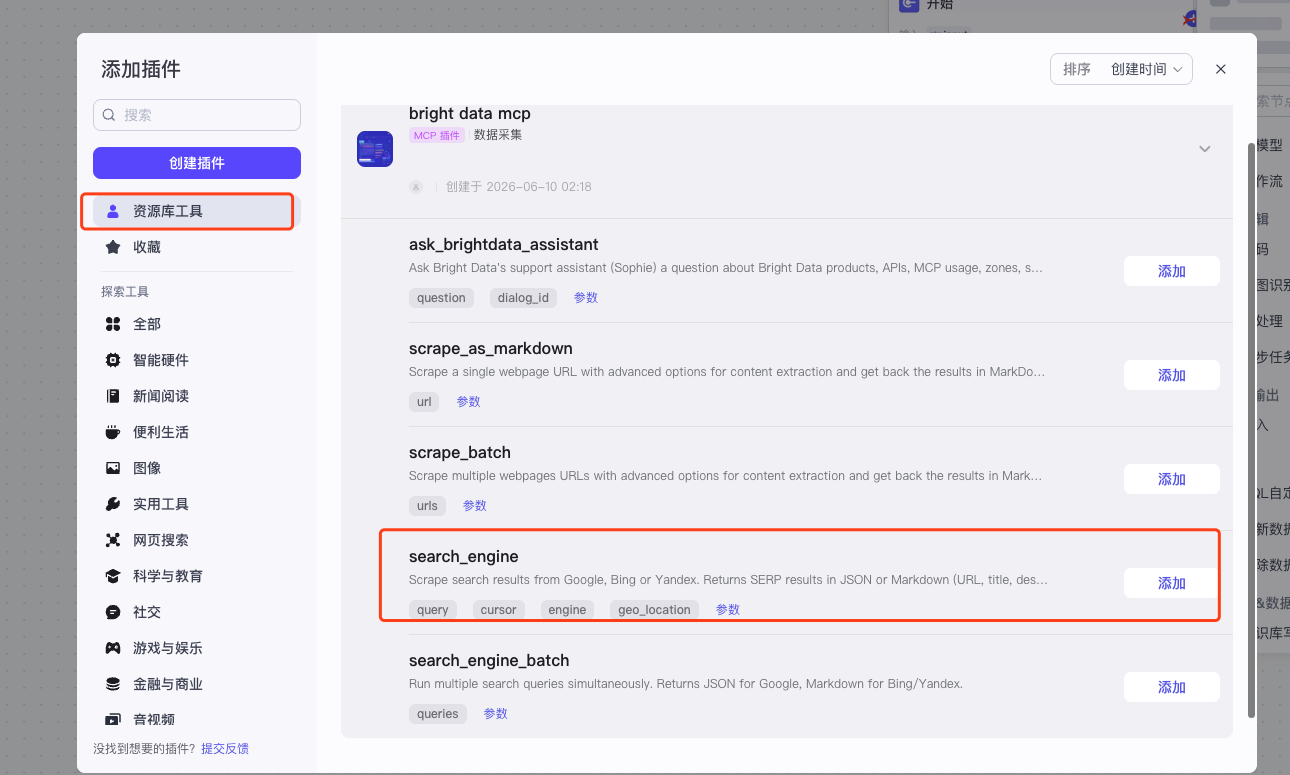 设置插件节点的输入,这里engin 我选择 google,geo_location 为us,query 为开始节点的input,我们可以看到输出为 content ,类型为数组。下面介绍一下变量的含义
设置插件节点的输入,这里engin 我选择 google,geo_location 为us,query 为开始节点的input,我们可以看到输出为 content ,类型为数组。下面介绍一下变量的含义
- engine:可以选择"google"、"bing"、"yande"搜索引擎
- geo_location:地理定位结果的2个字母的国家代码(例如"美国"、"英国")
- query:输入的变量
- cursor:下一页的分页光标
 content输出结果如下
content输出结果如下
javascript
{
"content": [
{
"type": "text",
"text": "{\n \"organic\": [\n {\n \"link\": \"https://zhuanlan.zhihu.com/p/670574382\",\n \"title\": \"国内外知名大模型及应用------模型/应用维度(2026/06/10)\",\n \"description\": \"4 days ago --- 混合推理模型虽然已占据市场主流,但不少模型的通用板和thinking版并不是同时发布,所以还是要拆分为一个通用模型和一个推理模型。 OCR模型、3D模型还不足以 ...Read more\"\n },\n {\n \"link\": \"https://www.datalearner.com/leaderboards\",\n \"title\": \"AI大模型评测排行榜\",\n \"description\": \"聚合ARC-AGI-2、HLE、AIME 2025、SWE-bench Verified、τ²-Bench 等主流基准的实时排名,覆盖综合榜与数学、编程、Agent 分类排行榜。\"\n },\n {\n \"link\": \"https://jimmysong.io/zh/book/ai-handbook/llm/model-overview/\",\n \"title\": \"主流开源大模型对比与选型指南(Llama、Qwen、DeepSeek)\",\n \"description\": \"Nov 2, 2025 --- 通用对话模型(General Chat Models) · 代码生成模型(Code LLM) · 多模态模型(Vision / Audio / Image Generation) · 领域专用模型(Domain LLM).Read more\"\n },\n {\n \"link\": \"https://www.awoo.ai/zh-hant/blog/mainstream-llm-intro/\",\n \"title\": \"大型語言模型有哪些?2026 主流LLM 清單、差異比較與企業選 ...\",\n \"description\": \"Feb 23, 2026 --- 當今主流的大型語言模型(LLM) 有哪些? · OpenAI:GPT-5 系列 · Anthropic:Claude 4.6 系列 · Google DeepMind:Gemini 3 Pro / Ultra · Meta:Llama 4 · Mistral ...Read more\"\n },\n {\n \"link\": \"https://blog.csdn.net/qq_30776829/article/details/138141880\",\n \"title\": \"全球AI大模型盘点(全网首发) 原创\",\n \"description\": \"Apr 24, 2024 --- 1、ChatGPT. ChatGPT 是人工智能公司OpenAI 基于GPT-3.5 研发的大规模对话式语言模型,目前处于测试阶段,拥有OpenAI 账户即可免费使用。 · 2、Claude · 3、 ...Read more\"\n },\n {\n \"link\": \"https://www.waytoagi.com/question/80027\",\n \"title\": \"目前主流的AI大模型有哪些\",\n \"description\": \"目前主流的AI 大模型主要有以下几种:. OpenAI 系列:包括GPT-3.5 和GPT-4 等。GPT-3.5 在11 月启动了当前的AI 热潮,GPT-4 功能更强大。ChatGPT 也属于OpenAI 系列。Read more\"\n },\n {\n \"link\": \"https://yeasy.gitbook.io/ai_beginner_guide/di-er-bu-fen-he-xin-ji-shu-jie-xi/06_llm/6.5_major_llms\",\n \"title\": \"6.5 主流大模型| 零基础学AI | AI Beginner Guide\",\n \"description\": \"1 day ago --- OpenAI (GPT 系列). 特点:综合能力和产品生态通常都很强,工具链较完整。 · Anthropic (Claude 系列). 特点:在长文本理解、写作、代码任务上常有突出表现, ...Read more\"\n },\n {\n \"link\": \"https://botpress.com/tw/blog/best-large-language-models\",\n \"title\": \"2026年十大最佳大型語言模型(LLM)\",\n \"description\": \"Oct 19, 2024 --- OpenAI · Anthropic · Google DeepMind · Meta · DeepSeek · xAI · Mistral.Read more\"\n },\n {\n \"link\": \"https://www.ibm.com/cn-zh/think/topics/large-language-models-list\",\n \"title\": \"大语言模型(LLM) 的列表\",\n \"description\": \"Anthropic 的Claude 语言模型是全球性能最高的模型之一。Anthropic 于2021 年由前OpenAI 员工创立,最初是一个AI 安全研究实验室,其模型开发方法基于独特的宪法AI 概念。Read more\"\n },\n {\n \"link\": \"https://www.dtinsight.com.cn/nd.jsp?id=3608\",\n \"title\": \"2025年全球AI大模型综合排名Top 20新鲜出炉| DT指数\",\n \"description\": \"2025年全球AI大模型综合排名(Top 20) ; 1, GPT-4.5, OpenAI(美国), 总分80.4(理科87.3/文科77.1),支持32K上下文,复杂逻辑推理领先 ; 2, Claude 3.7 Sonnet, Anthropic(美国) ...Read more\"\n }\n ],\n \"current_page\": 1\n}"
}
]
}接下来添加大模型节点
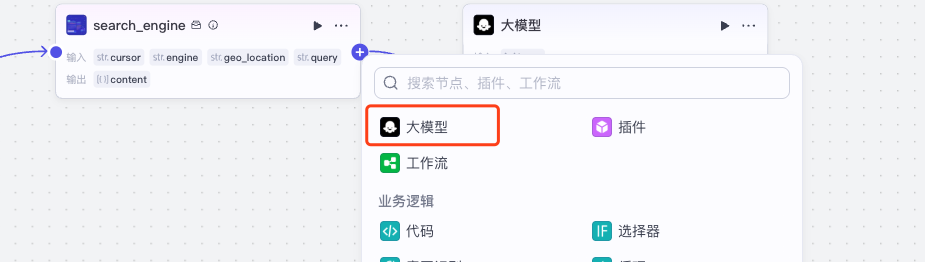
设置大模型节点属性,包括大模型的输入变量,系统提示词,用户提示词,输出变量
- 输入:输入需要添加到提示词的信息,这些信息可以被下方的提示词引用
- 视觉理解输入:用于视觉理解的输入,传入图片url,并在Prompt中引用该输入,举例:"图片{{变量名}}中有什么?"
- 系统提示词:为对话提供系统级指导,如设定人设和回复逻辑。
- 用户提示词:向模型提供用户指令,如查询或任何基于文本输入的提问。
- 输出:大模型运行完成后生成的内容
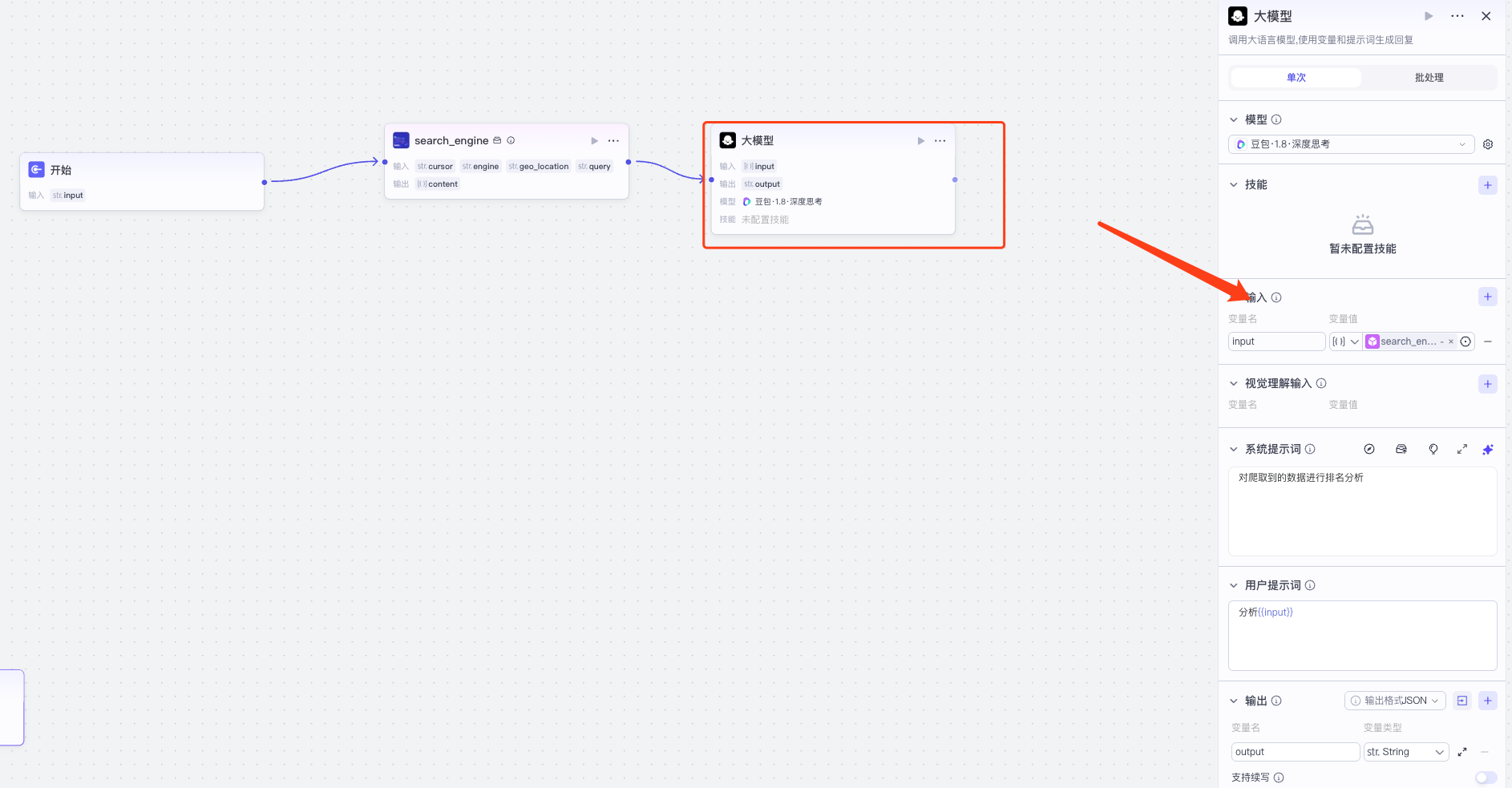
设置完成之后,就要设置结束节点,输出变量为大模型的输出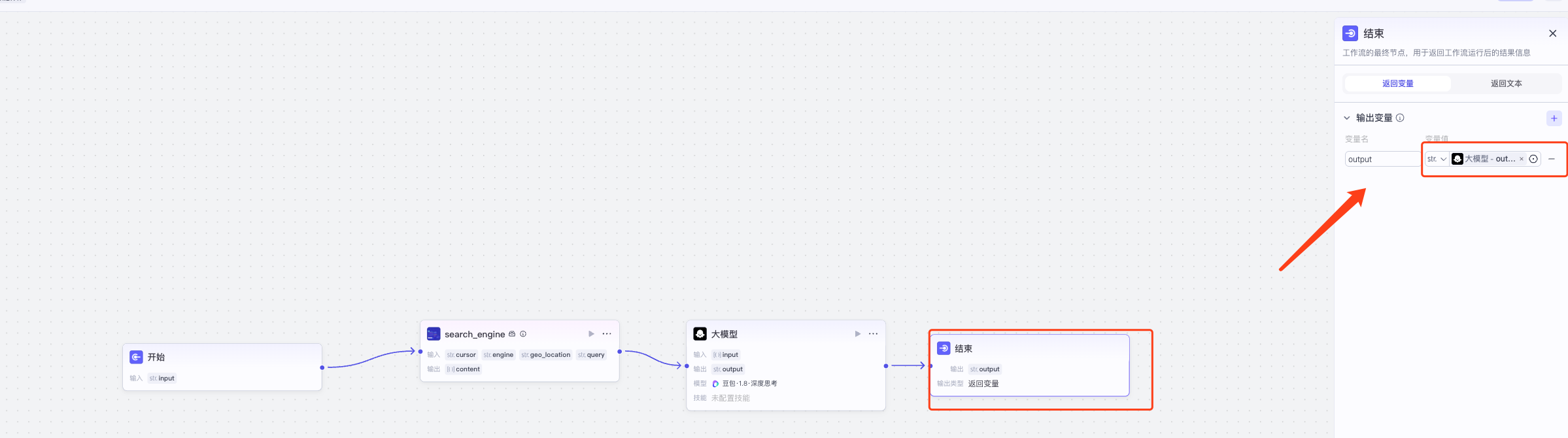
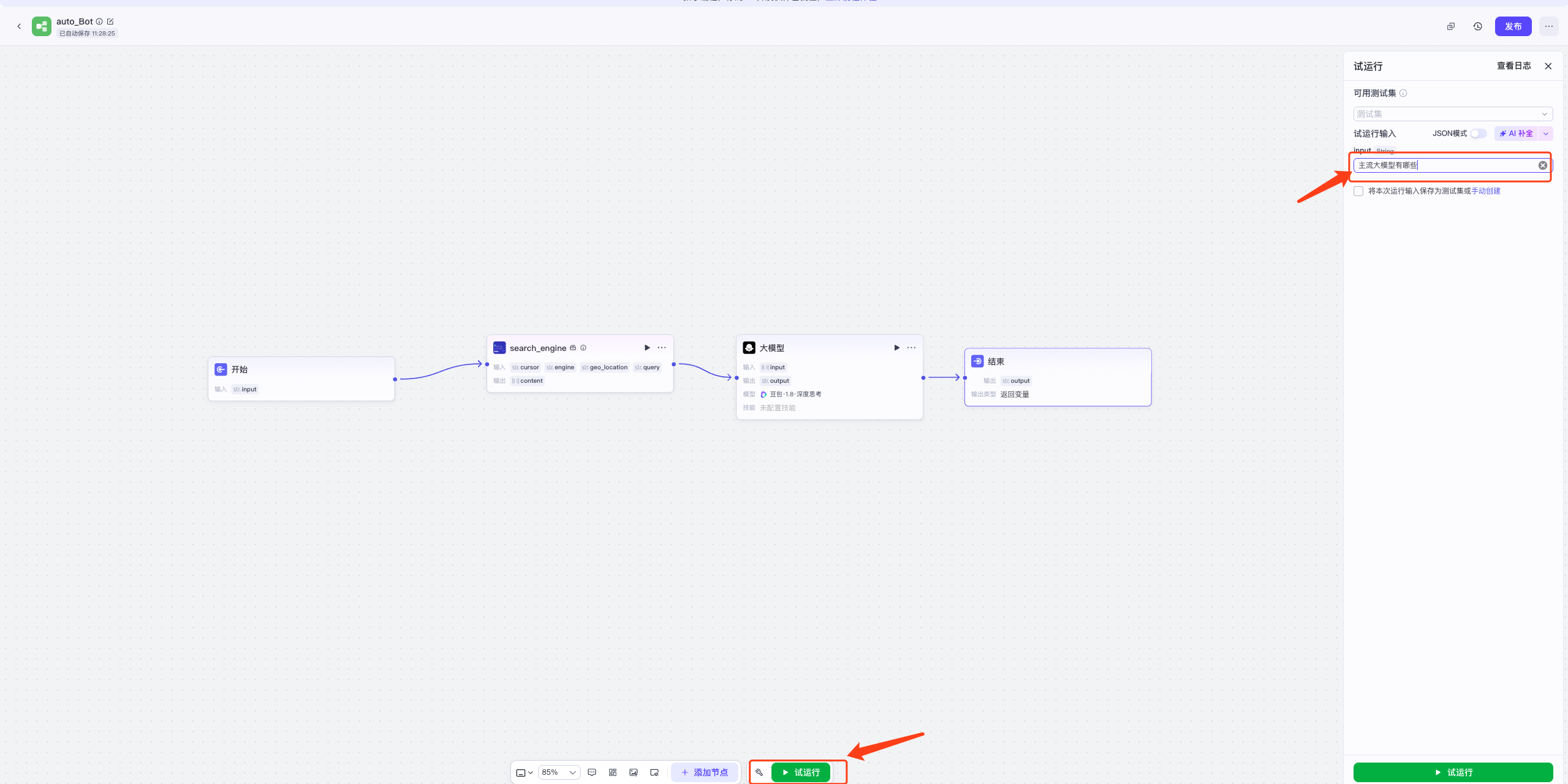
接下来试运行一下,输入:主流大模型有哪些?
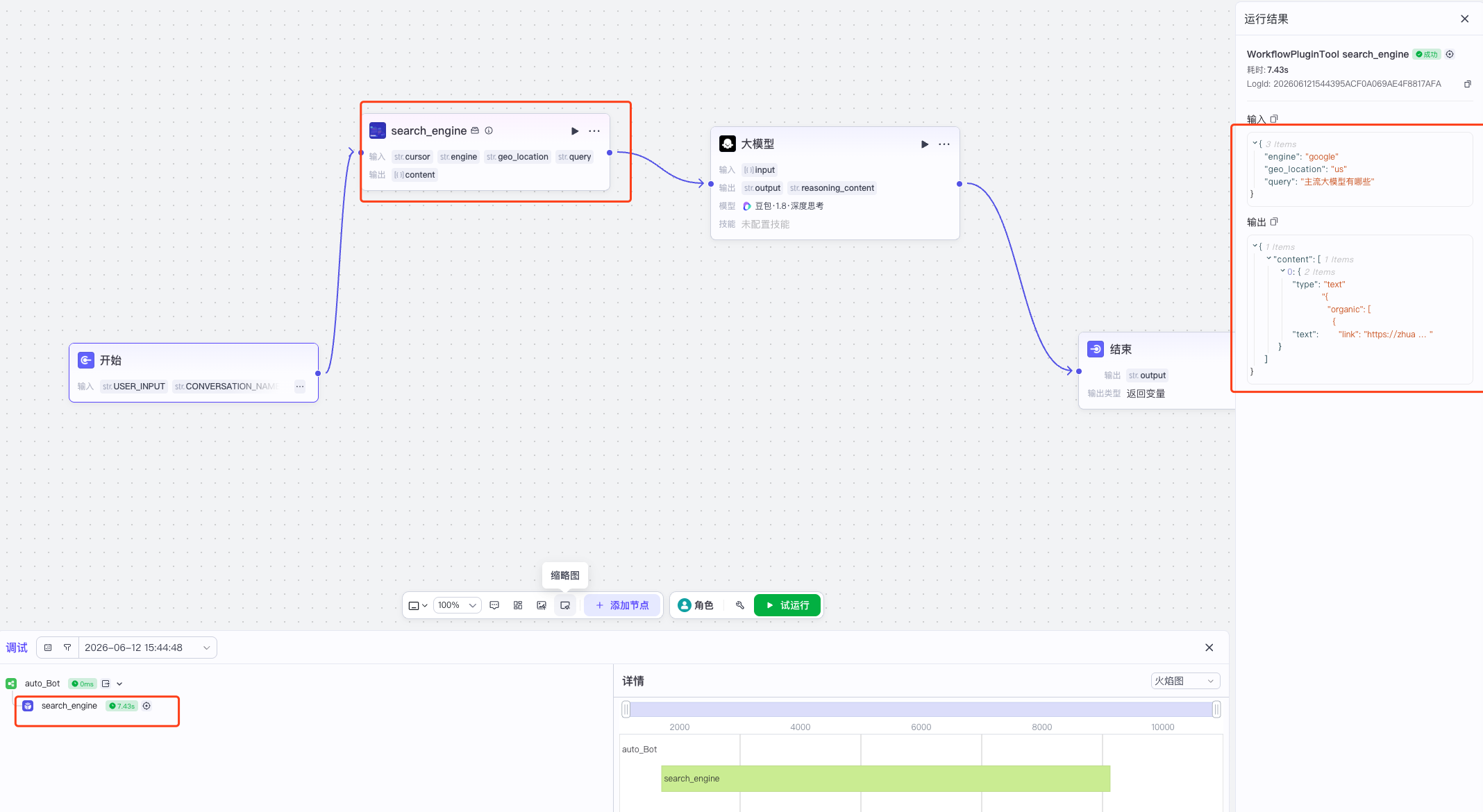
我们可以看到调用MCP的具体输出
最终输出结果进行预览,可以看到主流大模型在搜索引擎中的提到次数的排名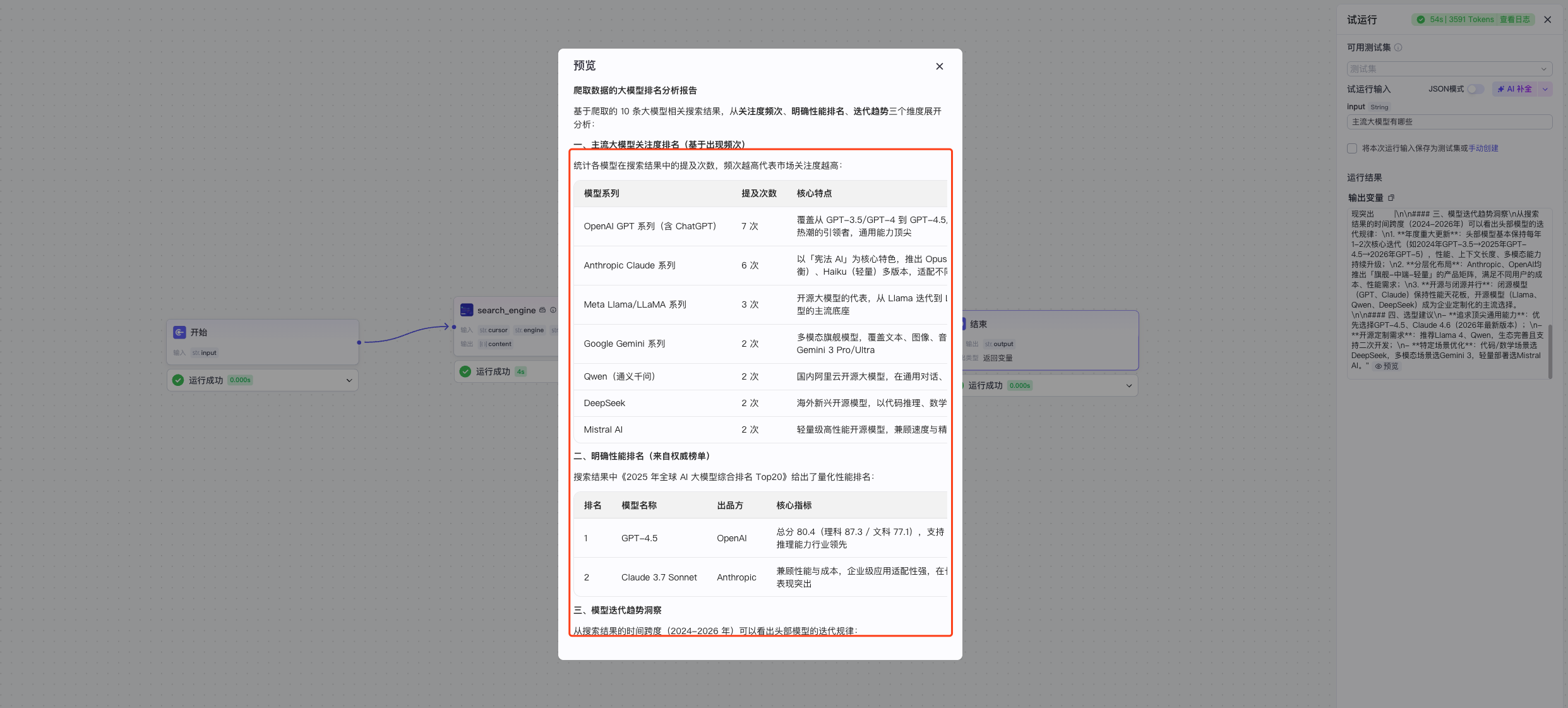 然后点击右上角的发布,就可以到资源库中看到了
然后点击右上角的发布,就可以到资源库中看到了

五、 FAQ
- Bright Data MCP 免费吗?
支持免费体验,可用于 AI Agent 获取实时网页能力。
- Coze 可以直接做网页采集吗?
适合基础场景,复杂反爬建议结合 Bright Data。
- 为什么不用代理直接抓 Google?
搜索结果采集建议使用 SERP API。
- Bright Data 支持哪些搜索引擎?
支持 Google、Bing、DuckDuckGo、Yandex。
- 零代码方案适合哪些团队?
市场、运营、SEO、竞品分析团队。
六、成本对比分析:自动化大幅降本
很多人担心自动化工具成本过高,我们结合人力成本与工具资费做客观对比:
1、传统手动模式
专人每日做竞品采集、数据整理、报表汇总,单岗位每日耗费 2~3 小时,长期人力成本居高不下,且效率低下、容易出错。
2、Bright Data + Coze 自动化模式
- Coze:免费层即可满足个人、中小团队日常使用,零基础费用;
- Bright Data:采用按量付费模式,仅根据实际采集用量计费,小体量监控成本极低;综合下来,对低频监控场景,按量计费模式通常可降低重复人工操作成本;实际费用取决于采集频率、目标站点复杂度与数据规模。
七、总结
在市场竞争越来越激烈的当下,数据自动化采集、竞品实时监控 已经成为运营、市场、SEO岗位的必备能力。借助 ++Bright Data MCP++ + 扣子Coze ,不用写一行代码,就能搭建专业级市场情报Bot,把重复机械的工作全部交给工具,把时间留给策略分析。
想要快速上手的朋友,可以通过下方专属链接注册Bright Data,搭配本文配套的工作流文件、配置教程,即刻搭建属于自己的全自动数据采集系统。
👉 立即前往: