C++ STL 详解:vector 的使用、扩容、迭代器失效与底层模拟实现

🔥 星恒随风: 个人主页 ❄️ 个人专栏: 《指针合集》 | 《C语言基础》 | 《数据结构》 | 《机器学习导论》 | 《前端基础》 | 《python基础》 | 《C++从入门到入土》 ✨ 数据即知识,压缩即智能
文章目录
- [C++ STL 详解:vector 的使用、扩容、迭代器失效与底层模拟实现](#C++ STL 详解:vector 的使用、扩容、迭代器失效与底层模拟实现)
-
- 前言
- [一、vector 是什么?](#一、vector 是什么?)
- [二、vector 的基本定义方式](#二、vector 的基本定义方式)
-
- [1. 无参构造](#1. 无参构造)
- [2. 指定元素个数和初始值](#2. 指定元素个数和初始值)
- [3. 拷贝构造](#3. 拷贝构造)
- [4. 迭代器区间构造](#4. 迭代器区间构造)
- [三、vector 的遍历方式](#三、vector 的遍历方式)
-
- [1. 下标遍历](#1. 下标遍历)
- [2. 迭代器遍历](#2. 迭代器遍历)
- [3. 范围 for](#3. 范围 for)
- [四、size 和 capacity 的区别](#四、size 和 capacity 的区别)
-
- [1. size:有效元素个数](#1. size:有效元素个数)
- [2. capacity:底层容量](#2. capacity:底层容量)
- [五、vector 为什么需要扩容?](#五、vector 为什么需要扩容?)
- [六、vector 的扩容倍数是不是固定的?](#六、vector 的扩容倍数是不是固定的?)
- [七、reserve 和 resize 的区别](#七、reserve 和 resize 的区别)
-
- [1. reserve:只改变容量,不改变有效元素个数](#1. reserve:只改变容量,不改变有效元素个数)
- [2. resize:改变有效元素个数](#2. resize:改变有效元素个数)
- [八、vector 的增删查改接口](#八、vector 的增删查改接口)
-
- [1. push_back:尾插](#1. push_back:尾插)
- [2. pop_back:尾删](#2. pop_back:尾删)
- [3. operator\[\]:下标访问](#3. operator[]:下标访问)
- [4. find:查找元素](#4. find:查找元素)
- [5. insert:在指定位置之前插入](#5. insert:在指定位置之前插入)
- [6. erase:删除指定位置元素](#6. erase:删除指定位置元素)
- [7. swap:交换两个 vector](#7. swap:交换两个 vector)
- [九、vector 的迭代器失效问题](#九、vector 的迭代器失效问题)
-
- [1. 哪些操作可能导致迭代器失效?](#1. 哪些操作可能导致迭代器失效?)
- [十、erase 删除元素时的正确写法](#十、erase 删除元素时的正确写法)
- 十一、不同编译器下,迭代器失效的表现可能不同
- [十二、vector 在 OJ 中的常见用法](#十二、vector 在 OJ 中的常见用法)
-
- [1. 只出现一次的数字](#1. 只出现一次的数字)
- [2. 杨辉三角](#2. 杨辉三角)
- [十三、二维 vector 怎么理解?](#十三、二维 vector 怎么理解?)
- [十四、vector 的底层结构](#十四、vector 的底层结构)
- [十五、模拟实现 vector 的基本框架](#十五、模拟实现 vector 的基本框架)
- [十六、push_back 的基本逻辑](#十六、push_back 的基本逻辑)
- [十七、为什么模拟 vector 时不能随便用 memcpy?](#十七、为什么模拟 vector 时不能随便用 memcpy?)
- [十八、vector 的优点和缺点](#十八、vector 的优点和缺点)
-
- [1. 优点](#1. 优点)
- [2. 缺点](#2. 缺点)
- [十九、vector 使用建议](#十九、vector 使用建议)
-
- [1. 能用下标时,下标访问很方便](#1. 能用下标时,下标访问很方便)
- [2. 只读遍历时,范围 for 更简洁](#2. 只读遍历时,范围 for 更简洁)
- [3. 修改元素时,使用引用](#3. 修改元素时,使用引用)
- [4. 已知数据规模时,提前 reserve](#4. 已知数据规模时,提前 reserve)
- [5. 删除元素时,注意 erase 返回值](#5. 删除元素时,注意 erase 返回值)
- 二十、常见面试问题整理
-
- [1. vector 和数组有什么区别?](#1. vector 和数组有什么区别?)
- [2. vector 的底层是不是连续空间?](#2. vector 的底层是不是连续空间?)
- [3. vector 扩容一定是 2 倍吗?](#3. vector 扩容一定是 2 倍吗?)
- [4. reserve 和 resize 的区别?](#4. reserve 和 resize 的区别?)
- [5. push_back 会不会导致迭代器失效?](#5. push_back 会不会导致迭代器失效?)
- [6. erase 之后迭代器为什么要接收返回值?](#6. erase 之后迭代器为什么要接收返回值?)
- [7. 为什么不能用 memcpy 拷贝 vector 中的对象?](#7. 为什么不能用 memcpy 拷贝 vector 中的对象?)
- 总结
前言
在 C++ 里,如果只让我们选一个最常用的 STL 容器,vector 大概率会排在第一位。
它像数组一样支持下标访问,又比原生数组灵活,可以自动扩容,也能配合 STL 算法一起使用。刷题、写项目、处理一组连续数据时,vector 基本都是绕不开的。
很多同学刚学 vector 时,容易停留在"会用 push_back、会用下标访问"的阶段。但真正写代码时,下面这些问题也很重要:
size()和capacity()到底有什么区别?reserve()和resize()为什么不能混用?- 为什么
push_back之后,原来的迭代器可能会失效? - 为什么删除
vector中的元素时,it = v.erase(it)才是更稳的写法? vector<vector<int>>这种二维数组底层到底是什么样?- 自己模拟实现
vector时,为什么不能随便用memcpy拷贝对象?
这篇文章就围绕这些问题,把 vector 从"会用"讲到"知道为什么这么用"。
一、vector 是什么?
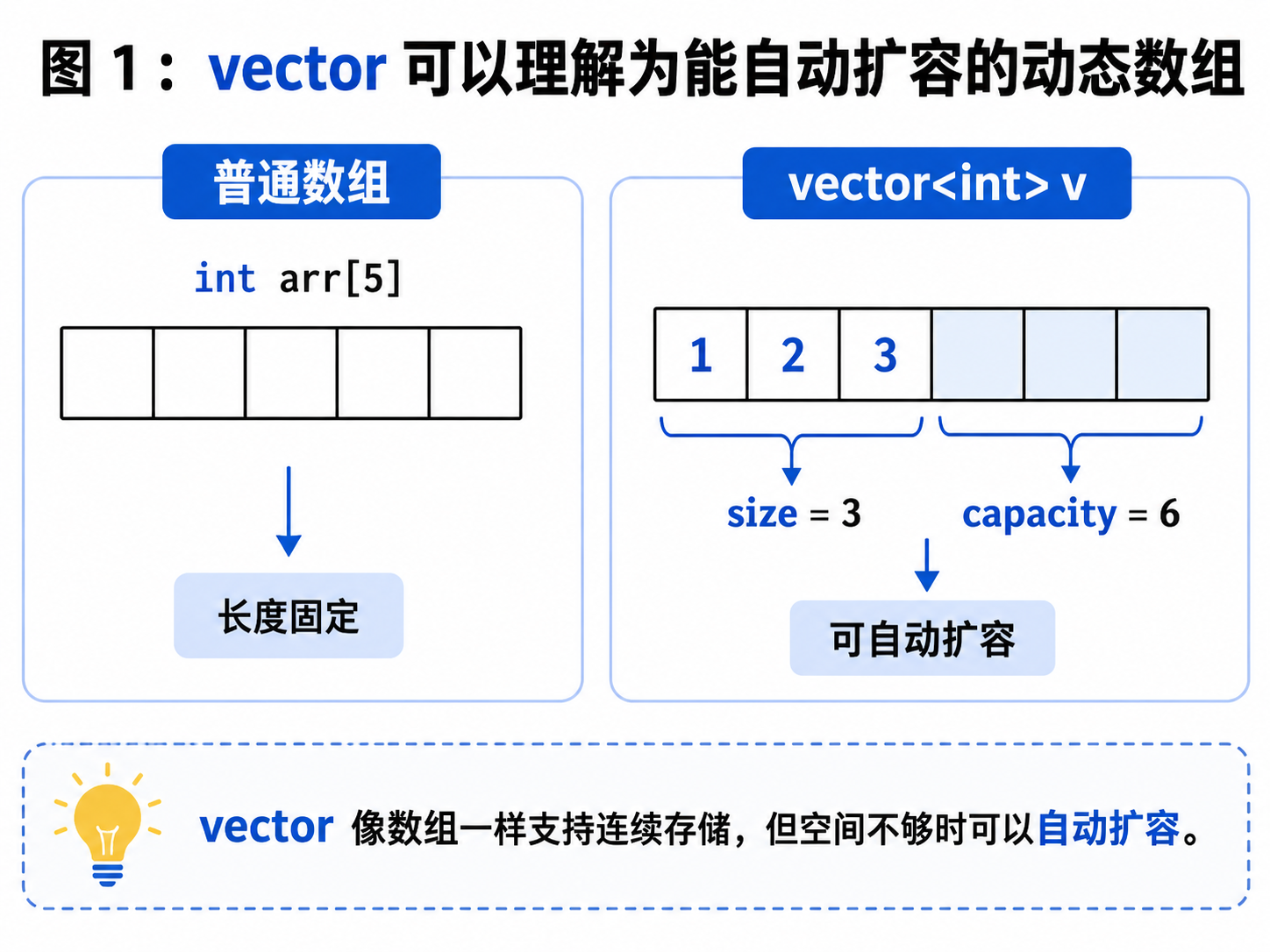
vector 是 C++ STL 中的一个顺序容器,可以理解为"可以自动扩容的动态数组"。
普通数组的长度在创建时通常就固定了:
cpp
int arr[10];如果后面发现 10 个空间不够,就比较麻烦。
而 vector 可以根据元素数量自动管理空间:
cpp
#include <vector>
using namespace std;
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);你可以先不关心底层到底开了多少空间,直接往里面插入数据。空间不够时,vector 会自己扩容。
二、vector 的基本定义方式
使用 vector 前,需要包含头文件:
cpp
#include <vector>常见定义方式如下:
cpp
vector<int> v1; // 空 vector
vector<int> v2(5, 10); // 5 个元素,每个都是 10
vector<int> v3(v2); // 拷贝构造
vector<int> v4(v2.begin(), v2.end()); // 使用迭代器区间构造分别来看。
1. 无参构造
cpp
vector<int> v;这是最常见写法。创建一个空的 vector<int>,后续可以通过 push_back 插入元素。
cpp
v.push_back(1);
v.push_back(2);
v.push_back(3);2. 指定元素个数和初始值
cpp
vector<int> v(5, 10);表示创建一个 vector,里面有 5 个元素,每个元素都是 10。
也就是:
cpp
[10, 10, 10, 10, 10]3. 拷贝构造
cpp
vector<int> v1{1, 2, 3};
vector<int> v2(v1);v2 会拷贝 v1 的内容。
注意,这里的拷贝是容器级别的拷贝。对于 int 这种内置类型没什么问题;但如果元素类型是自定义类,就会调用对应对象的拷贝构造。
4. 迭代器区间构造
cpp
vector<int> v1{1, 2, 3, 4, 5};
vector<int> v2(v1.begin(), v1.end());这种写法表示用 [begin, end) 区间内的元素构造新 vector。
这里要注意:STL 中大多数区间都是左闭右开。
也就是包含 begin() 指向的位置,不包含 end() 指向的位置。
三、vector 的遍历方式
1. 下标遍历
vector 支持像数组一样使用 [] 访问元素。
cpp
vector<int> v{1, 2, 3, 4};
for (size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}这是刷题里非常常见的写法。
优点是直观,能拿到下标,适合需要访问 v[i]、v[i - 1]、v[i + 1] 这类场景。
2. 迭代器遍历
cpp
vector<int> v{1, 2, 3, 4};
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}begin() 返回第一个元素的位置。
end() 返回最后一个元素的下一个位置。
注意:end() 本身不指向有效元素,它只是一个边界标记。
所以遍历时通常写:
cpp
it != v.end()而不是:
cpp
it <= v.end()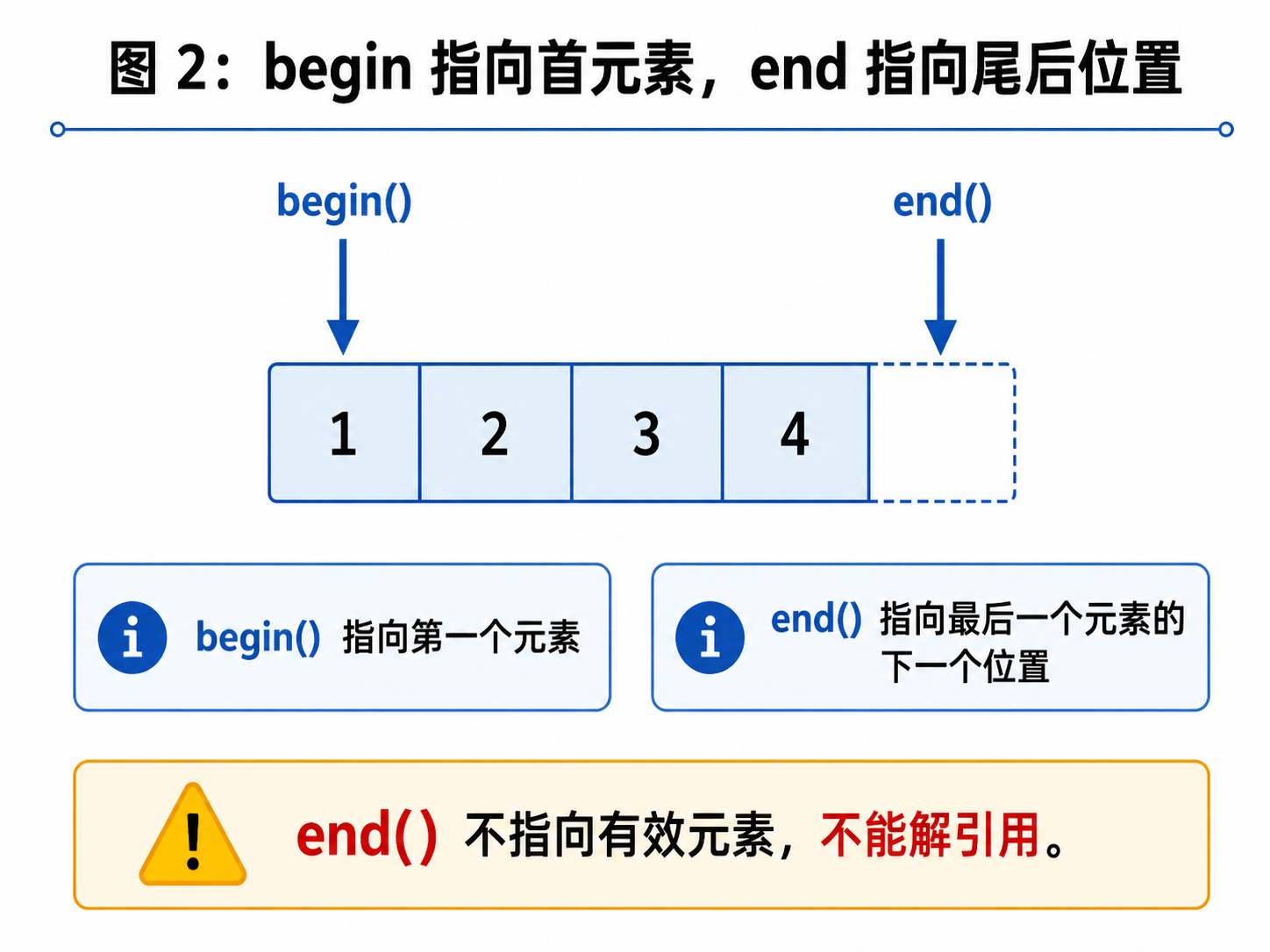
3. 范围 for
cpp
vector<int> v{1, 2, 3, 4};
for (auto e : v)
{
cout << e << " ";
}如果只是读取元素,这种写法最简洁。
如果想修改元素,需要使用引用:
cpp
for (auto& e : v)
{
e *= 2;
}如果不加 &,e 只是元素的拷贝,修改 e 不会影响原 vector。
四、size 和 capacity 的区别
学 vector 必须分清两个概念:
cpp
size()
capacity()它们看起来都和"大小"有关,但含义完全不同。
1. size:有效元素个数
cpp
vector<int> v{1, 2, 3};
cout << v.size() << endl;输出:
cpp
3size() 表示当前 vector 中实际存了多少个有效元素。
2. capacity:底层容量
cpp
cout << v.capacity() << endl;capacity() 表示 vector 当前底层空间最多能容纳多少个元素。
比如:
cpp
size = 3
capacity = 4这表示当前有 3 个有效元素,但底层空间可以放 4 个元素。如果再插入一个元素,可能不需要扩容。

五、vector 为什么需要扩容?
vector 的底层通常是一段连续空间。
假设一开始空间只能放 4 个元素:
text
[1][2][3][4]如果这时继续 push_back(5),原来的空间放不下了,vector 就需要扩容。
扩容的大致过程是:
- 重新申请一块更大的空间
- 把旧空间里的元素搬到新空间
- 释放旧空间
- 把新元素插入进去
所以,扩容不是简单地"在后面多接一个格子"。因为内存中原空间后面不一定刚好有可用空间。
这也是为什么频繁扩容会影响效率。
六、vector 的扩容倍数是不是固定的?
很多同学会记一句话:vector 扩容是 2 倍扩容。
这个说法不严谨。
不同编译器、不同 STL 实现的扩容策略可能不一样。比如有的实现接近 1.5 倍增长,有的实现接近 2 倍增长。我们不应该把某一种实现当成标准规定。
更准确的说法是:
vector 会在空间不够时重新分配更大的连续空间,但具体增长倍数由 STL 实现决定。
这点在面试和考试中很容易被问到。
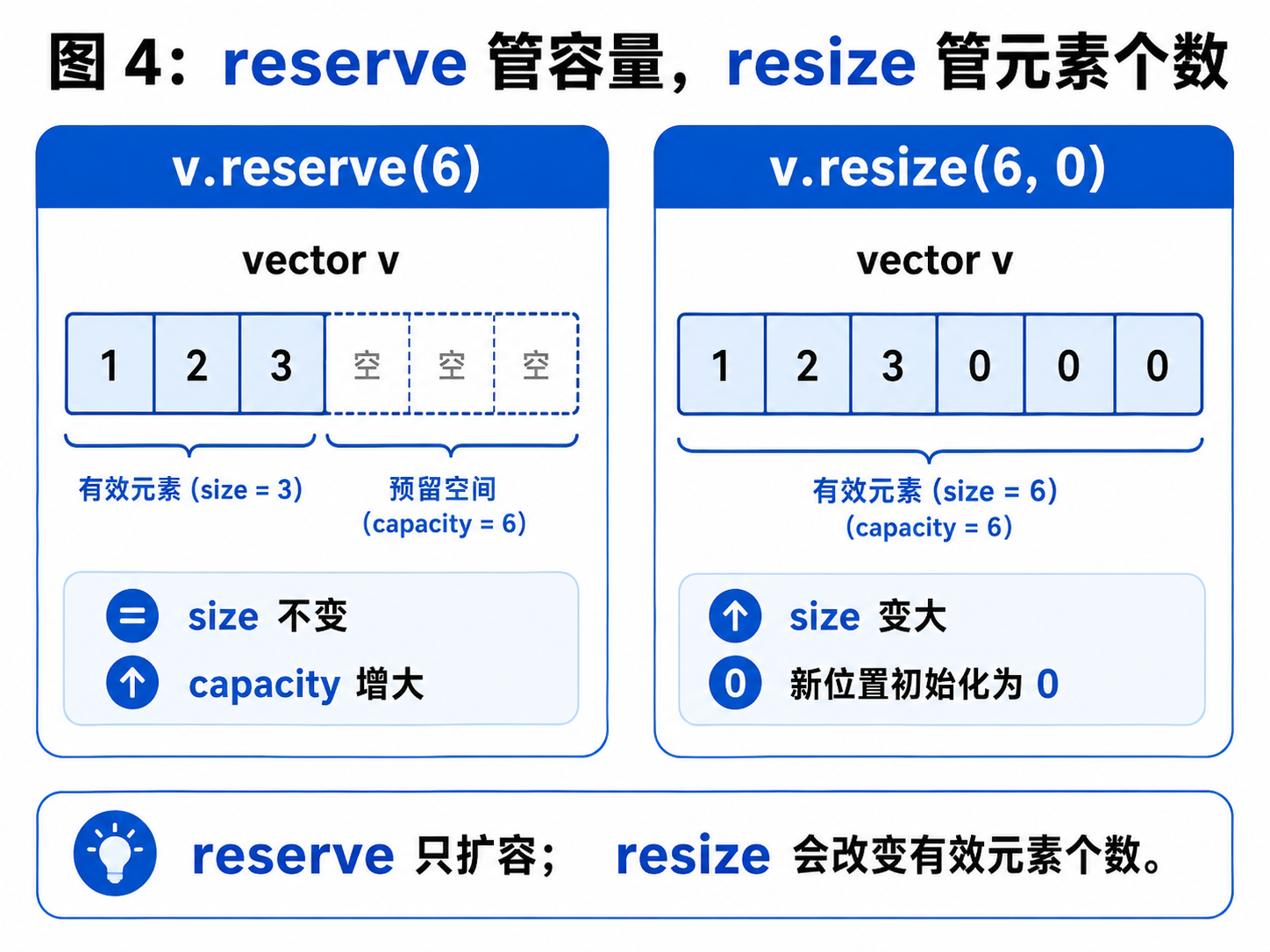
七、reserve 和 resize 的区别
这是 vector 中非常容易混淆的一组接口。
1. reserve:只改变容量,不改变有效元素个数
cpp
vector<int> v;
v.reserve(100);
cout << v.size() << endl; // 0
cout << v.capacity() << endl; // 至少 100reserve(100) 的意思是:提前开好至少能容纳 100 个元素的空间。
但它不会创建 100 个有效元素。
所以此时不能这样访问:
cpp
v[0] = 10; // 错误写法,size 还是 0,没有有效元素正确插入方式还是:
cpp
v.push_back(10);reserve 的主要作用是优化性能。
如果你提前知道大概要插入多少个元素,可以先 reserve,减少中途扩容的次数。
cpp
vector<int> v;
v.reserve(10000);
for (int i = 0; i < 10000; ++i)
{
v.push_back(i);
}这样比边插入边多次扩容更稳。
2. resize:改变有效元素个数
cpp
vector<int> v;
v.resize(5, 10);这会让 vector 里面有 5 个有效元素,每个新增元素都是 10。
也就是:
cpp
[10, 10, 10, 10, 10]这时:
cpp
cout << v.size() << endl; // 5resize 会真正改变 size。
如果 resize 变大,多出来的位置会被初始化。
如果 resize 变小,多余的元素会被删除。
八、vector 的增删查改接口
1. push_back:尾插
cpp
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);结果:
cpp
[1, 2, 3]push_back 是最常用的插入方式。
因为在尾部插入通常比较高效。
2. pop_back:尾删
cpp
vector<int> v{1, 2, 3};
v.pop_back();结果:
cpp
[1, 2]注意,pop_back() 不会返回被删除的元素。
如果想先拿到最后一个元素,可以这样写:
cpp
int x = v.back();
v.pop_back();3. operator\[\]:下标访问
cpp
vector<int> v{1, 2, 3};
cout << v[0] << endl;
v[1] = 20;operator[] 使用起来像数组,很方便。
但它不会做越界检查。
如果想要带越界检查的访问方式,可以使用:
cpp
v.at(0);at() 在越界时会抛异常,不过刷题时更常用 []。
4. find:查找元素
需要注意:find 不是 vector 的成员函数,而是 <algorithm> 里的算法。
cpp
#include <algorithm>
vector<int> v{1, 2, 3, 4};
auto pos = find(v.begin(), v.end(), 3);
if (pos != v.end())
{
cout << "找到了: " << *pos << endl;
}find 返回的是迭代器。
如果找到了,返回目标元素位置。
如果没找到,返回 v.end()。
5. insert:在指定位置之前插入
cpp
vector<int> v{1, 2, 3};
v.insert(v.begin(), 0);结果:
cpp
[0, 1, 2, 3]insert(pos, val) 是在 pos 之前插入元素。
中间插入通常会导致后面的元素整体往后移动,所以效率没有尾插高。
6. erase:删除指定位置元素
cpp
vector<int> v{1, 2, 3, 4};
auto it = find(v.begin(), v.end(), 3);
if (it != v.end())
{
v.erase(it);
}结果:
cpp
[1, 2, 4]erase 删除元素后,后面的元素会向前移动。
这一点和迭代器失效有关,后面重点讲。
7. swap:交换两个 vector
cpp
vector<int> v1{1, 2, 3};
vector<int> v2{10, 20};
v1.swap(v2);交换后:
cpp
v1 = [10, 20]
v2 = [1, 2, 3]swap 通常不是逐个元素交换,而是交换底层资源,因此效率很高。
九、vector 的迭代器失效问题
这是 vector 中最容易踩坑的部分。
先说结论:
只要某个操作导致 vector 底层空间重新分配,原来的迭代器、指针、引用都可能失效。
为什么?
因为 vector 底层是连续空间。
当空间不够时,它会申请一块新空间,然后把旧数据搬过去,再释放旧空间。
如果你之前保存了一个迭代器:
cpp
auto it = v.begin();这个迭代器本质上指向旧空间中的某个位置。
扩容之后,旧空间可能已经被释放了。
这时你再使用 it,就相当于访问一块已经失效的内存。
轻则输出奇怪结果,重则程序崩溃。

1. 哪些操作可能导致迭代器失效?
常见包括:
cpp
reserve
resize
push_back
insert
assign这些操作都有可能导致扩容。
注意,不是每次 push_back 都一定导致迭代器失效。只有当 push_back 触发扩容时,才会导致原迭代器失效。
但实际写代码时,不建议依赖"这次刚好没扩容"。
更稳妥的习惯是:
修改 vector 结构后,如果还想用迭代器,重新获取迭代器。
例如:
cpp
auto it = v.begin();
v.reserve(100);
// 原 it 可能已经失效
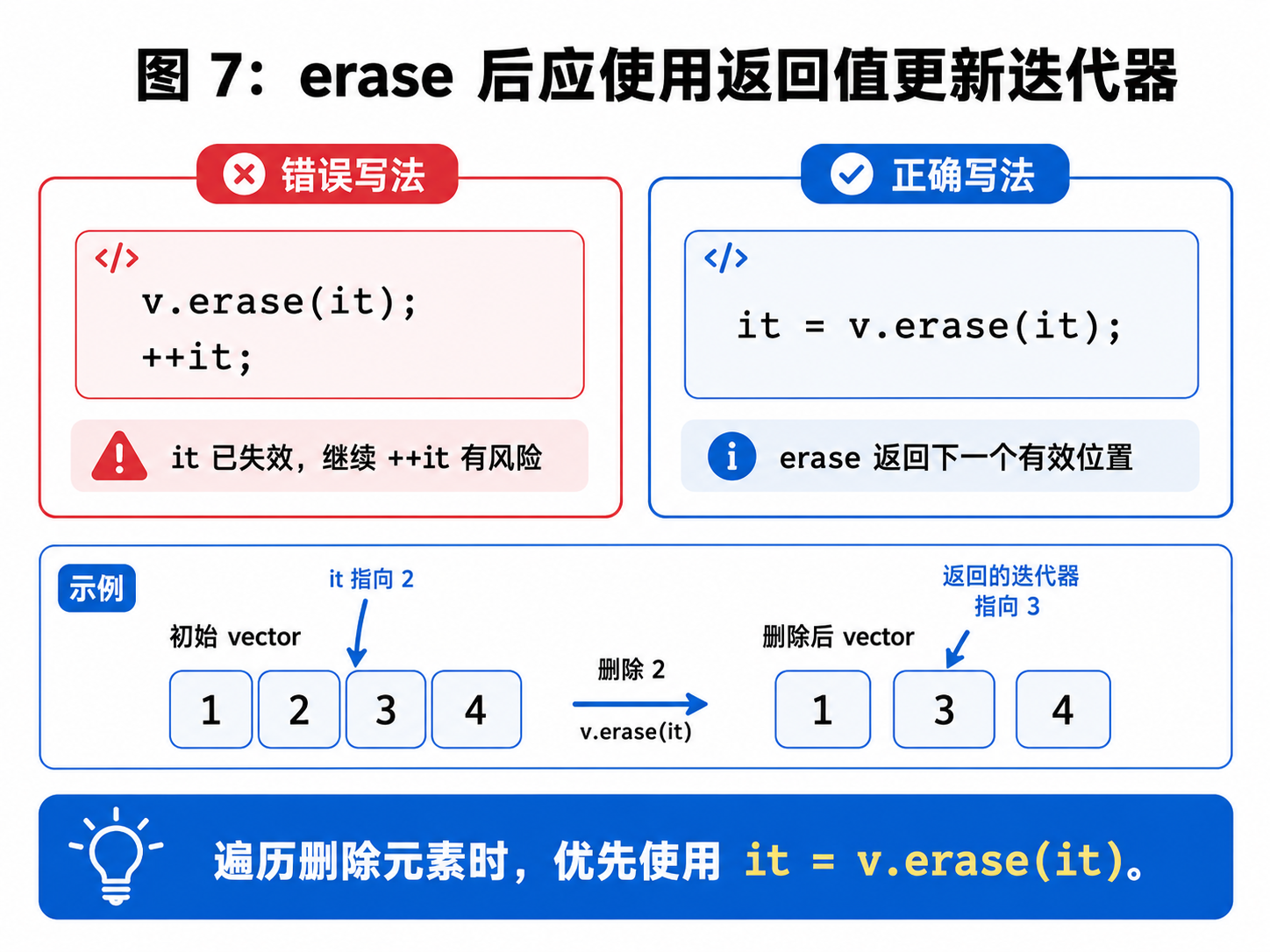
it = v.begin(); // 重新获取十、erase 删除元素时的正确写法
看下面这段代码,目标是删除 vector 中所有偶数:
cpp
vector<int> v{1, 2, 3, 4};
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}这段代码是有问题的。
问题在于:
cpp
v.erase(it);执行后,it 指向的位置已经被删除,原来的 it 失效了。
后面再执行:
cpp
++it;就可能出问题。
正确写法是:
cpp
vector<int> v{1, 2, 3, 4};
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.erase(it);
}
else
{
++it;
}
}为什么这样写?
因为 erase 会返回被删除位置后面那个元素的新迭代器。
例如:
cpp
[1, 2, 3, 4]
^
it 指向 2删除 2 后:
cpp
[1, 3, 4]
^
erase 返回指向 3 的迭代器所以写成:
cpp
it = v.erase(it);才能继续安全遍历。
十一、不同编译器下,迭代器失效的表现可能不同
有时候你会发现:同样一段迭代器失效的代码,在 VS 下崩溃,在 Linux g++ 下好像还能跑。
这并不说明代码是正确的。
迭代器失效之后,继续使用它,本质上就是未定义行为。
未定义行为的意思是:程序可能崩溃,也可能不崩溃,也可能输出看起来正常的结果,也可能输出一堆奇怪数据。
所以不要用"我的电脑上能跑"来证明代码没问题。
对于 vector,更稳的写法是:
- 扩容后,不继续使用旧迭代器
- 删除元素后,使用
erase的返回值 - 修改容器结构时,对迭代器保持警惕
十二、vector 在 OJ 中的常见用法
1. 只出现一次的数字
题目大意:
一个数组中,除了某个数字只出现一次,其他数字都出现两次,找出那个只出现一次的数字。
可以利用异或:
cpp
class Solution {
public:
int singleNumber(vector<int>& nums) {
int value = 0;
for (auto e : nums)
{
value ^= e;
}
return value;
}
};异或有两个性质:
cpp
x ^ x = 0
x ^ 0 = x所以成对出现的数字会互相抵消,最后剩下的就是只出现一次的数字。
2. 杨辉三角
杨辉三角非常适合用二维 vector。
cpp
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv(numRows);
for (int i = 0; i < numRows; ++i)
{
vv[i].resize(i + 1, 1);
}
for (int i = 2; i < numRows; ++i)
{
for (int j = 1; j < i; ++j)
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
return vv;
}
};核心思路:
- 每一行的元素个数是
i + 1 - 每一行开头和结尾都是 1
- 中间元素等于上一行相邻两个元素之和
也就是:
cpp
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];这里用到了:
cpp
vector<vector<int>>
resize
operator[]这几个 vector 常用能力。
十三、二维 vector 怎么理解?
很多人看到:
cpp
vector<vector<int>> vv;会下意识把它理解成一个普通二维数组。
但严格来说,它不是传统意义上的连续二维数组。
它更像是:
text
vv 是一个 vector
vv 里面的每个元素,又是一个 vector<int>例如:
cpp
vector<vector<int>> vv(5);这表示 vv 里有 5 个元素,每个元素都是一个空的 vector<int>。
此时可以想象成:
text
vv[0] -> 空 vector
vv[1] -> 空 vector
vv[2] -> 空 vector
vv[3] -> 空 vector
vv[4] -> 空 vector如果执行:
cpp
for (int i = 0; i < 5; ++i)
{
vv[i].resize(i + 1, 1);
}就会变成类似杨辉三角的形态:
text
vv[0] -> [1]
vv[1] -> [1, 1]
vv[2] -> [1, 1, 1]
vv[3] -> [1, 1, 1, 1]
vv[4] -> [1, 1, 1, 1, 1]注意,每一行都是一个独立的 vector<int>,每一行内部是连续的,但不保证所有行在内存中连成一整块。
这点和原生二维数组不一样。
十四、vector 的底层结构
一个简化版的 vector,底层一般可以抽象成三个指针:
cpp
_start
_finish
_end_of_storage它们分别表示:
text
_start :指向底层空间的起始位置
_finish :指向最后一个有效元素的下一个位置
_end_of_storage :指向底层容量的末尾位置可以这样理解:
text
_start _finish _end_of_storage
| | |
v v v
[1][2][3][4][有效数据结束][空闲空间][空闲空间][容量结束]于是:
cpp
size = _finish - _start
capacity = _end_of_storage - _start这就是为什么 vector 能够 O(1) 获取 size() 和 capacity()。
也是为什么 operator[] 可以像数组一样快速访问:
cpp
v[i] 等价于 *(_start + i)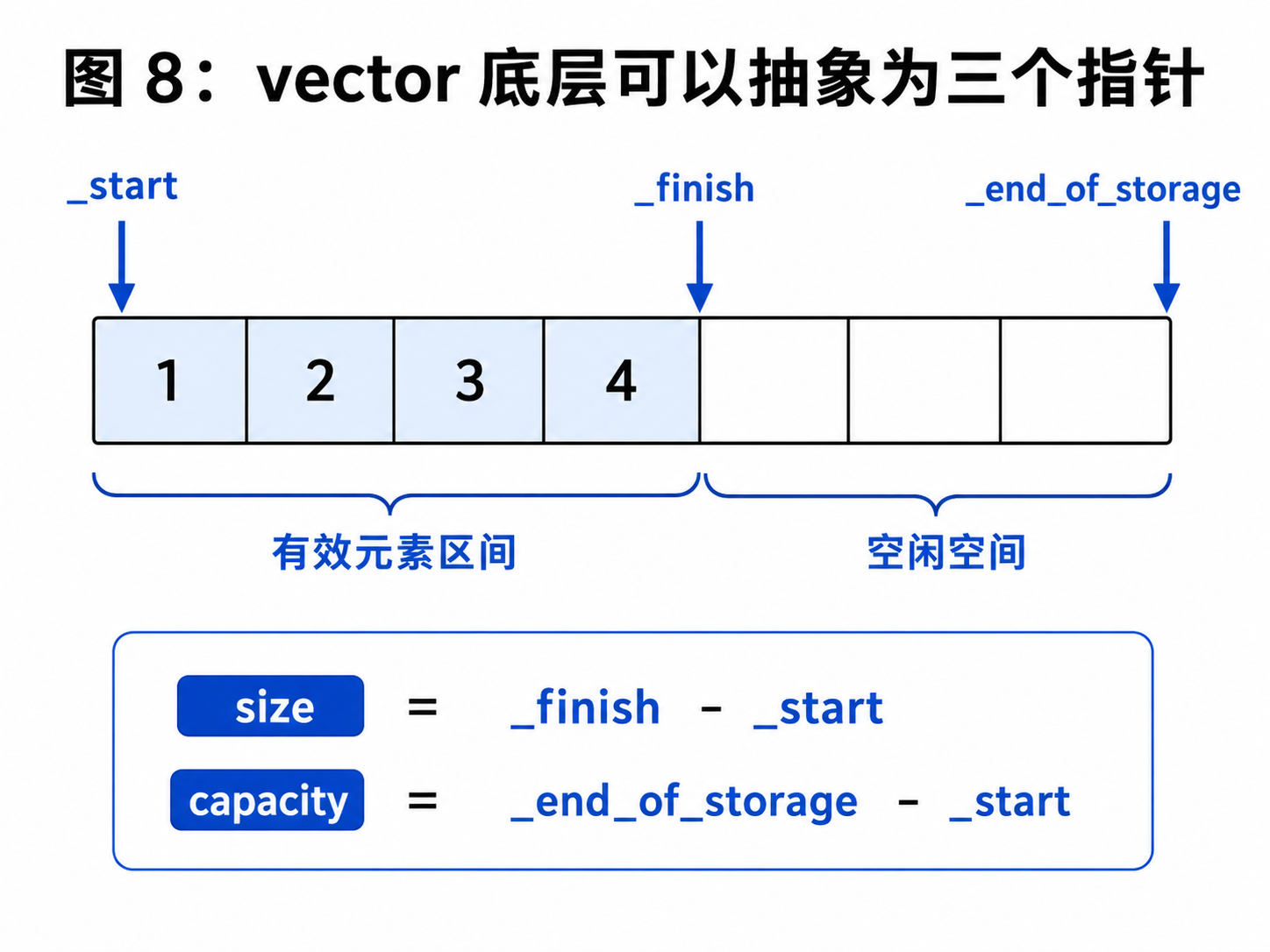
十五、模拟实现 vector 的基本框架
一个简化版本的 vector 类可以这样设计:
cpp
namespace bit
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
vector()
: _start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _end_of_storage - _start;
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}这里 iterator 直接使用了 T*。
这也解释了为什么 vector 迭代器失效本质上就是"指针失效"。
十六、push_back 的基本逻辑
push_back 的逻辑大致是:
- 如果空间满了,先扩容
- 在
_finish位置构造新元素 _finish++
简化写法:
cpp
void push_back(const T& x)
{
if (_finish == _end_of_storage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = x;
++_finish;
}这段只是帮助理解,真实 STL 实现会更复杂,需要考虑对象构造、异常安全、allocator 等问题。
十七、为什么模拟 vector 时不能随便用 memcpy?
如果 vector<int> 扩容,我们把旧空间的内容拷贝到新空间,似乎可以直接用 memcpy:
cpp
memcpy(newspace, _start, sizeof(T) * size());对于 int、double 这种内置类型,看起来问题不大。
但如果元素是自定义类型,尤其是管理资源的类型,就可能出大问题。
比如一个自定义 string 类内部有一个指针 _str,指向堆上的字符串空间。
如果使用 memcpy 拷贝对象,只会把指针的值原封不动拷过去。
也就是说,两个对象里的 _str 会指向同一块堆空间。
这就是浅拷贝。
后果可能是:
- 两个对象共享同一块资源
- 一个对象析构后,另一个对象的指针变成野指针
- 两个对象析构时重复释放同一块空间
- 程序崩溃
所以,只要对象涉及资源管理,就不能简单用 memcpy 做对象拷贝。
更正确的做法是逐个对象进行构造或赋值,让对象自己的拷贝构造函数发挥作用。
简化理解:
cpp
for (size_t i = 0; i < old_size; ++i)
{
newspace[i] = _start[i];
}当然,真实实现还会使用 placement new、allocator 等方式处理对象生命周期。
十八、vector 的优点和缺点
1. 优点
vector 的优点很明显:
- 支持随机访问,访问
v[i]很快 - 尾插效率高
- 自动扩容,比原生数组方便
- 内存连续,缓存友好
- 可以配合 STL 算法使用
比如:
cpp
sort(v.begin(), v.end());这就是 vector 和算法配合的典型场景。
2. 缺点
vector 也不是万能的:
- 中间插入和删除效率较低
- 扩容可能导致迭代器失效
- 扩容需要搬移元素,存在成本
- 不适合频繁在头部插入删除
如果经常在头部插入删除,可以考虑 list 或 deque。
如果需要频繁查找某个 key,可以考虑 unordered_map 或 map。
容器不是越高级越好,而是要看使用场景。
十九、vector 使用建议
1. 能用下标时,下标访问很方便
刷题时,很多场景用下标更自然:
cpp
for (size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}尤其是需要访问前后元素时:
cpp
v[i - 1]
v[i]
v[i + 1]2. 只读遍历时,范围 for 更简洁
cpp
for (auto e : v)
{
cout << e << " ";
}如果元素比较大,建议用引用,避免拷贝:
cpp
for (const auto& e : v)
{
cout << e << " ";
}3. 修改元素时,使用引用
cpp
for (auto& e : v)
{
e *= 2;
}4. 已知数据规模时,提前 reserve
cpp
vector<int> v;
v.reserve(n);这样可以减少扩容次数。
5. 删除元素时,注意 erase 返回值
cpp
auto it = v.begin();
while (it != v.end())
{
if (需要删除)
it = v.erase(it);
else
++it;
}这是必须掌握的写法。
二十、常见面试问题整理
1. vector 和数组有什么区别?
数组长度通常固定,vector 可以动态扩容。
数组不提供 STL 容器接口,vector 支持迭代器、push_back、insert、erase 等接口。
2. vector 的底层是不是连续空间?
是。vector 底层使用连续空间存储元素,因此支持高效随机访问。
3. vector 扩容一定是 2 倍吗?
不一定。具体扩容策略由 STL 实现决定,不同编译器和标准库实现可能不同。
4. reserve 和 resize 的区别?
reserve 改变容量,不改变有效元素个数。
resize 改变有效元素个数,必要时也可能扩容。
5. push_back 会不会导致迭代器失效?
如果 push_back 触发扩容,就会导致原来的迭代器、引用、指针失效。
如果没有触发扩容,通常不会影响已有元素的迭代器,但不要写依赖这种细节的脆弱代码。
6. erase 之后迭代器为什么要接收返回值?
因为被删除位置的迭代器会失效。erase 返回删除位置后面那个元素的新迭代器,所以应该写:
cpp
it = v.erase(it);7. 为什么不能用 memcpy 拷贝 vector 中的对象?
如果元素类型涉及资源管理,memcpy 只是二进制浅拷贝,可能导致多个对象共享同一块资源,最终引发重复释放、内存泄漏或程序崩溃。
总结
vector 看起来只是一个"能自动扩容的数组",但它背后涉及不少 C++ 容器的核心思想。
初学主要是理解以下三个关键问题:
size和capacity不是一回事reserve和resize不是一回事- 扩容和删除都可能带来迭代器失效