OpenMed 调研:被"医疗 AI"标题低估的本地化临床 NLP 工具链(2026)
TL;DR
- 场景:医疗 AI 系统接入,需要解决临床文本结构化、PII/PHI 检测、去标识化、批处理和本地部署
- 结论:OpenMed 当前最有价值的不是"医疗问答",而是医疗文本基础设施组件;定位是中间件层而非诊断层
- 产出:OpenMed 能做什么/不能做什么的边界、推荐接入架构、模型加载安全规范、中文场景评估清单
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| 临床 NER(疾病/药物/基因/解剖实体) | ✅ 已验证 | v1.3.0 起跨平台,PyTorch + MLX 双后端 |
| PII 检测(姓名/电话/SSN/邮箱) | ✅ 已验证 | v1.3.0(2026-04-29)Faker-backed 脱敏,PyTorch/MLX 全平台 |
| 多语言隐私过滤(16 语言) | ✅ 已验证 | v1.4.0(2026-05-11)OpenMed Multilingual Privacy Filter |
| Nemotron-PII 模型族 | ✅ 已验证 | v1.3.0 起新增 PyTorch/MLX artifacts |
| privacy-filter trust boundary 修复 | ✅ 已验证 | v1.5.2(2026-05-27)发布,限制 trust_remote_code=True 触发条件 |
| 端侧推理 Apple Silicon MLX | ✅ 已验证 | v1.3.0 起 MLX 8-bit/全精度版本,OpenMedKit/Swift 同源 |
| 中文临床病历 NER | ⚠️ 待验证 | 官方材料未重点覆盖中文,需自建评估集 |
| Assertion 否定/怀疑识别 | ⚠️ 待验证 | 当前模型擅长实体抽取,否定/时态需后处理 |
| FHIR / ICD-10 / SNOMED CT 映射 | ❌ 暂不支持 | 需后处理层做术语标准化 |
| 临床决策/诊断推理 | ❌ 暂不支持 | OpenMed 明确定位为结构化与脱敏层 |
| 医学影像分割 | ❌ 不在范围 | 仅文本处理,无 CV 能力 |
文章正文
摘要:OpenMed 很容易被"open-source healthcare AI"这个标签误读成医疗 ChatGPT,但它当前更值得关注的价值并不是诊断问答,而是临床文本的结构化、PII/PHI 检测、去标识化、批处理和本地部署。它基于 Python / Swift 生态,使用 BERT、ELECTRA、DeBERTa 等 encoder transformer 做医学实体识别和隐私信息处理,并提供 REST 服务、模型注册表、Apple MLX / OpenMedKit 等能力。本文从工程落地角度拆解 OpenMed 能做什么、不能做什么、适合放在医疗 AI 系统的哪一层,以及为什么模型加载安全和中文场景评估必须被认真对待。
关键词:OpenMed、医疗 AI、本地化临床 NLP、医学实体识别、PII 检测、PHI 去标识化、clinical NER、biomedical NLP、医疗数据脱敏、Apple MLX、OpenMedKit、医疗文本结构化、AI 合规

1. 先给结论:OpenMed 不是医疗 ChatGPT
如果只看项目介绍里的 "open-source healthcare AI",OpenMed 很容易被理解成一个医疗问答大模型,或者一个可以直接替医生诊断的聊天机器人。
这个理解不准确。
OpenMed 当前最核心、最可靠的价值,是临床文本的结构化处理。它更像一个面向医疗场景的 NLP 工具链:输入病历摘要、临床记录、科研文献片段、药物说明、检查记录,输出疾病、药物、基因、蛋白、解剖部位、肿瘤相关实体、个人身份信息等结构化结果。
换句话说,它解决的是医疗 AI 系统里非常底层但非常关键的问题:如何把非结构化医疗文本变成机器可以处理、检索、审计和脱敏的数据。
这比"模型会不会聊天"更接近真实落地。医院、药企、科研团队要做 AI,第一步往往不是让模型直接给患者建议,而是先把文本里的实体、身份信息、时间线和敏感字段抽出来。
2. 医疗 AI 为什么需要 local-first
医疗 AI 和普通 AI 应用最大的区别不是模型参数量,而是数据边界。
普通应用可以把用户输入发到云端 API。医疗场景不一样。病历号、姓名、电话、身份证、医保号、出生日期、住院记录、医生备注、检查报告,都可能属于敏感数据。系统设计错误,不只是技术问题,还会变成合规、安全、伦理和责任问题。
所以医疗 AI 的核心矛盾是:
- 模型越强,越想用云端能力。
- 数据越敏感,越不能随便离开本地环境。
OpenMed 的卖点之一就是 local-first。它强调模型可以运行在自己的设备、服务器、VPC、院内部署环境甚至 air-gapped 隔离环境中,推理阶段不需要把患者数据发送给外部服务。
这不能自动等于合规,但它把数据流向变得更可控。部署方仍然需要做权限、审计、日志、加密、审批、人工复核和合规文档,但至少架构上不必从"把原始病历交给第三方 API"开始。
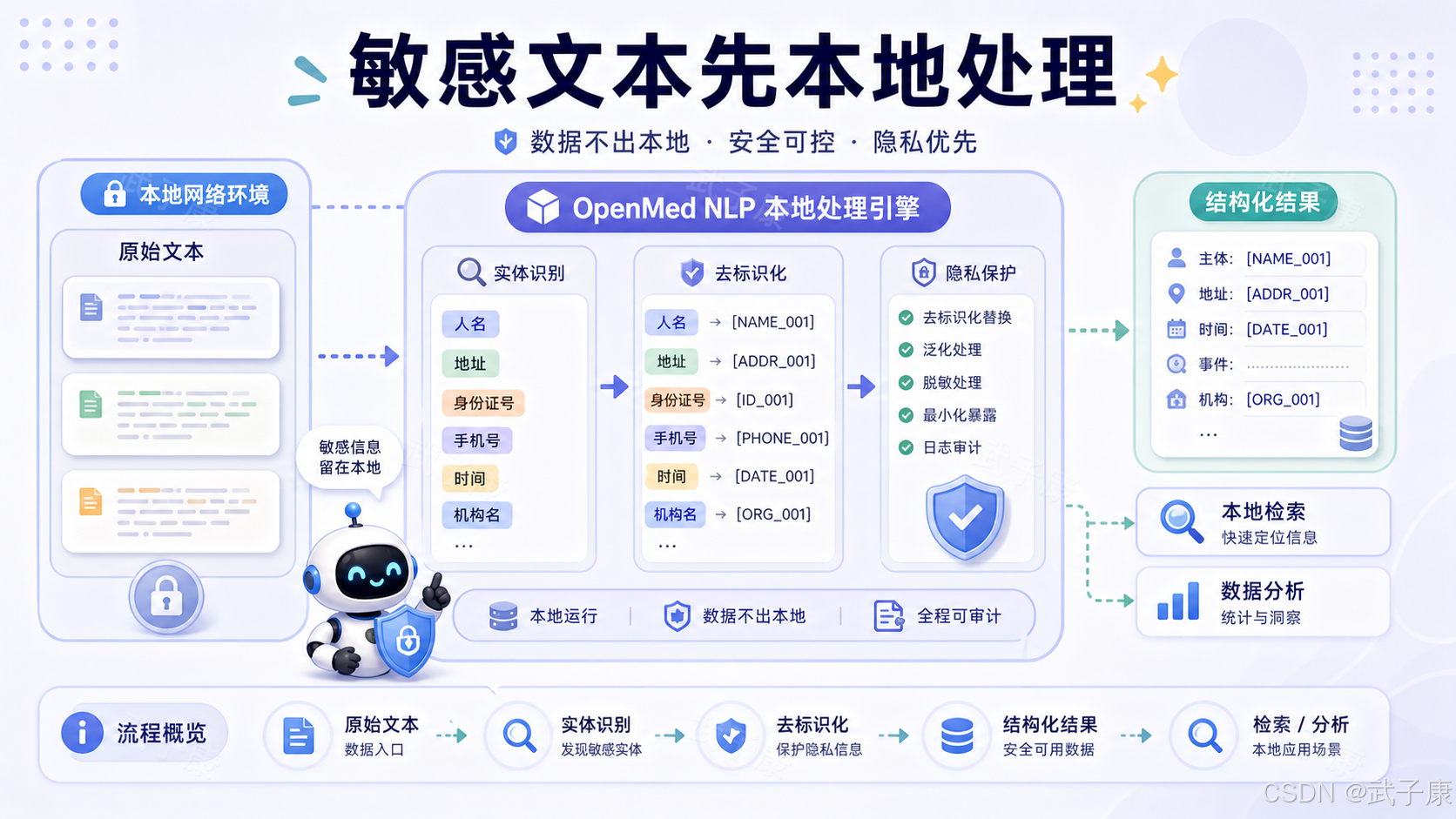
3. OpenMed 能做什么
OpenMed 可以分成五层看。
第一层是医学实体识别。它可以从文本里抽取疾病、药物、治疗方式、基因、蛋白、解剖部位、肿瘤相关概念等实体。例如官方文档中的调用方式接近:
python
from openmed import analyze_text
result = analyze_text(
"Patient started on imatinib for chronic myeloid leukemia.",
model_name="disease_detection_superclinical",
)
for entity in result.entities:
print(entity.label, entity.text, entity.confidence)第二层是 PII / PHI 识别。PII 是 personally identifiable information,PHI 是医疗场景中的 protected health information。医疗文本中最危险的往往不是疾病名称,而是患者姓名、生日、电话、邮箱、地址、证件号、病历号、医保号。
第三层是去标识化。OpenMed 提供 extract_pii、deidentify 等接口,可以做 mask、replace、hash、shift_dates 等处理。不同方式适合不同场景:展示给大模型前可以 mask,保留可读性可以 replace,研究时间线可以 shift_dates。
第四层是批处理。真实医疗数据不是一条文本,而是一批病历、一批文献、一批药物报告。OpenMed 提供 BatchProcessor、process_batch 等能力,用于批量处理文本、文件和目录。
第五层是服务化和端侧能力。它支持 FastAPI / Uvicorn 暴露 REST 服务,也支持 Apple MLX、Swift / OpenMedKit 等方向,尝试把本地医疗 NLP 带到 Apple Silicon 和端侧应用。
这几层组合起来,OpenMed 更像医疗文本中间件,而不是完整医疗应用。
4. 为什么说它的核心是"结构化"
医疗文本 AI 可以拆成很多层:
- 实体抽取:文本里有哪些疾病、药物、基因、检查指标?
- 断言识别:这个疾病是确诊、否认、怀疑,还是家族史?
- 关系抽取:某种药物治疗了哪个疾病?某个基因和哪个肿瘤相关?
- 总结问答:把结构化信息组织成解释、摘要或辅助建议。
- 临床决策:进入更高风险的判断链路。
OpenMed 当前最适合放在前几层:NER、PII 检测、去标识化、批处理、服务化。
这也决定了它不应该被当成"自动医生"。例如"患者否认糖尿病史"中出现了"糖尿病",实体抽取模型可能会识别出疾病实体,但这不等于患者确诊糖尿病。真实系统还需要 negation、assertion、temporal status、人工审核和业务规则。
所以更合理的使用方式是:
- 医生写病程记录,系统自动抽取疾病和药物。
- 科研人员处理 PubMed 摘要,先抽取药物、疾病、基因候选。
- 医院数据分析前,先做 PII 检测和去标识化。
- 药企处理不良反应报告,先把实体结构化。
- 院内大模型接触原始文本前,先经过脱敏层。
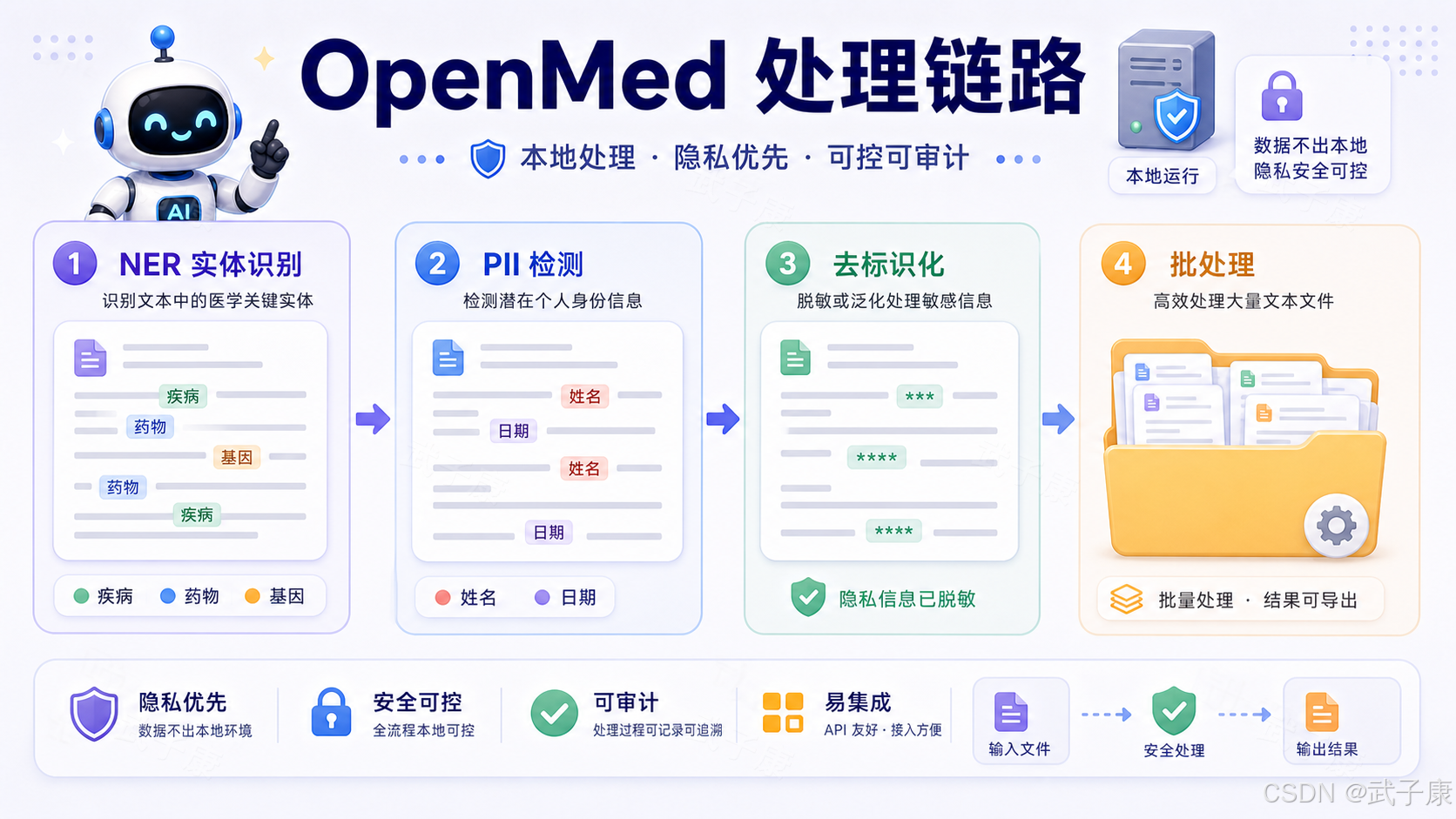
5. 模型体系:覆盖面广,但不能跳过评估
OpenMed 的模型库覆盖 clinical NLP、biomedical NLP、PII detection、de-identification、medical reasoning datasets、zero-shot clinical entity extraction 等方向。典型模型包括疾病检测、药物检测、PII 检测、解剖实体、基因实体等。
论文方向也主要围绕 biomedical NER,而不是临床诊断大模型。公开论文描述了在 PubMed、arXiv、MIMIC-III 等来源构建 biomedical passages,进行领域自适应预训练,并结合 LoRA 做任务微调,在多个 biomedical NER benchmark 上取得较好结果。
但这里必须谨慎:
第一,benchmark 不等于院内真实效果。不同医院、科室、语言、病历模板、缩写习惯都会影响表现。
第二,NER 不等于理解临床语境。抽出"肺炎"这个词,不代表模型知道它是确诊、排除还是疑似。
第三,模型多会带来治理成本。哪个任务用哪个模型?阈值多少?版本怎么固定?结果如何审计?失败如何回退?这些都不是模型下载后自动解决的问题。
OpenMed 的 model registry 做了一些工程封装,例如 category、specialization、recommended confidence、Hugging Face ID 等元信息。这说明项目不是只把模型堆出来,也在考虑调用体验和模型治理。
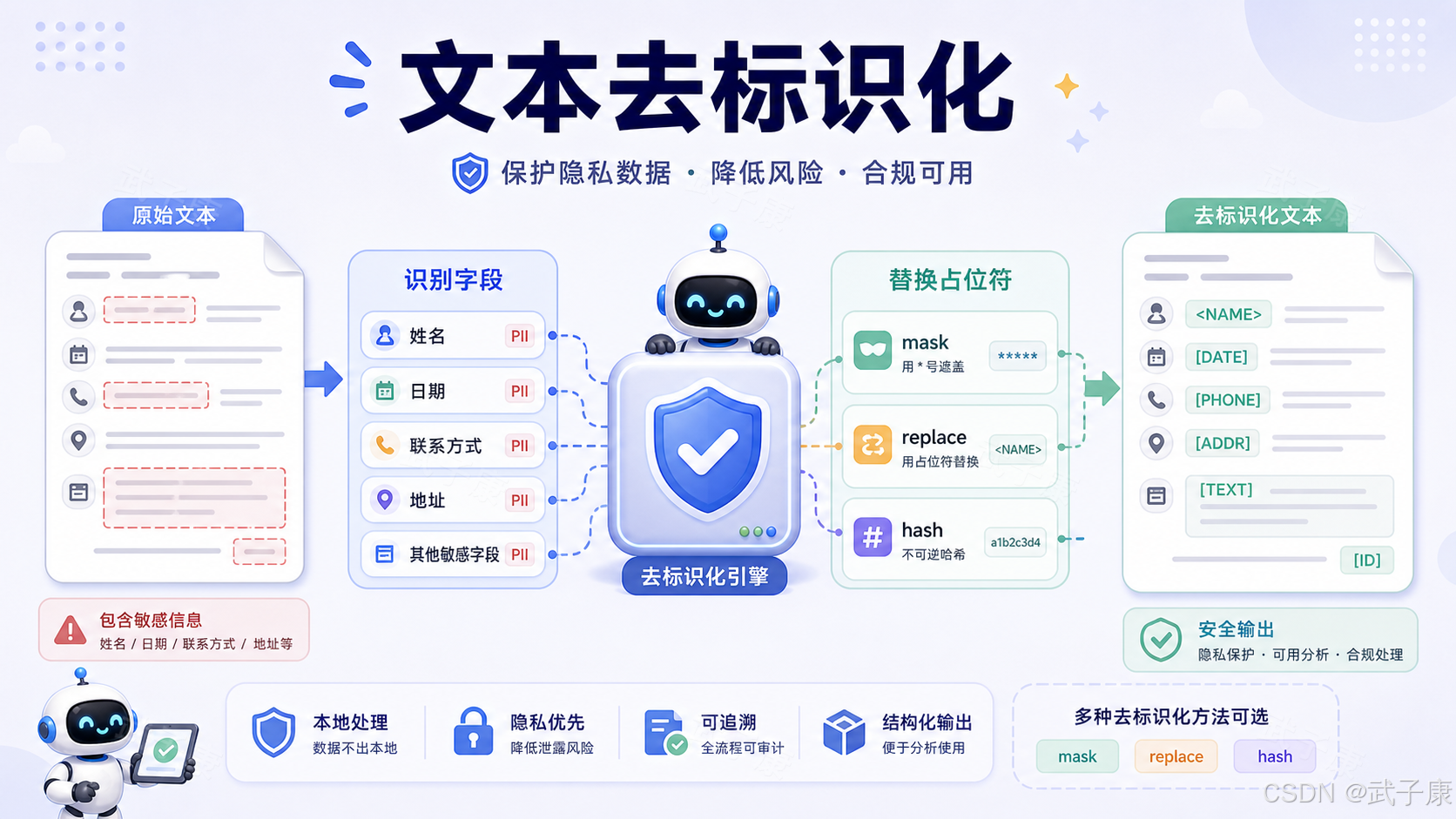
6. PII 检测与去标识化:最值得优先研究
如果只选一个最值得优先研究的 OpenMed 功能,我会选 PII 检测与去标识化。
原因很直接:医疗数据的第一道门槛就是脱敏。
很多医疗 AI 项目无法推进,不是因为模型不够强,而是因为数据无法安全进入模型流程。医院内部科研分析要脱敏,病历进入大模型总结前要脱敏,数据给算法团队训练前要脱敏,跨部门合作更要脱敏。
OpenMed 支持多种处理方法:
python
from openmed import extract_pii, deidentify
text = "Patient John Doe, DOB 01/15/1970, phone (555) 123-4567."
pii = extract_pii(
text,
model_name="pii_detection",
use_smart_merging=True,
)
safe_text = deidentify(text, method="mask")mask 适合把敏感信息替换成标签;replace 适合用格式相似的假数据保留可读性;hash 适合做不可逆匹配;shift_dates 适合隐藏真实日期但保留相对时间间隔。
OpenMed 还强调 smart entity merging,用来处理 tokenizer 把 SSN、日期、电话切碎的问题。这是脱敏系统的关键细节。医疗系统最怕的不是模型"不够聪明",而是漏脱敏一个字段。
7. 中文医疗场景:不能默认可用
OpenMed 的公开文档和叙事重点并不是中文临床文本。它可能支持多语言 PII 相关能力,也提到一些 locale-aware validators,但中文病历、中文检查报告、中文缩写、中文医院模板并不是当前公开材料里的重点。
中文用户尤其要注意:不要因为项目叫医疗 AI,就默认它能处理中文病历。
如果要在中文医疗场景使用,必须自己做评估集,至少覆盖:
- 门诊病历。
- 出院小结。
- 检查报告。
- 影像描述。
- 用药记录。
- 既往史、家族史、过敏史。
- "否认高血压"这类否定表达。
- "考虑肺炎可能"这类不确定表达。
- "肺 Ca""冠心病""糖尿病"等缩写和俗称。
只有在这些数据上测试召回率、准确率、漏脱敏率、误脱敏率,才能判断它能否进入生产链路。
这不是 OpenMed 独有的问题,而是所有医疗 NLP 工具都绕不开的问题。医疗文本高度本地化,语言、机构、科室和模板都会改变模型表现。
8. 工程接入:不要让用户随便传 model_name
OpenMed 的工程体验比较完整:Python API、BatchProcessor、REST 服务、模型注册表、本地模型路径、配置和 Apple 端能力都有涉及。
但是生产接入时,一个原则非常重要:不要让外部请求直接控制 model_name。
AI 服务里的模型加载不是安全中立行为。很多人以为加载模型只是下载权重,但在 Hugging Face 生态里,一些模型需要自定义 Python 代码,trust_remote_code=True 本质上就是允许执行远程仓库代码。如果模型名可以被不可信用户影响,就可能变成代码执行入口。
OpenMed 1.5.2 的 release notes 明确提到修复了 privacy-filter remote-code trust boundary 问题:只有一方可信 privacy-filter 标识和显式配置的可信模型可以走 trust_remote_code=True 路径,避免任意模型名触发远程代码信任。
这件事对所有 AI 工程都很有警示意义。生产部署 OpenMed 时,建议:
- 使用 1.5.2 或更高版本。
- 服务端维护模型白名单。
- 前端只传业务枚举,例如 disease、pharma、pii。
- 后端把业务枚举映射到固定模型路径。
- 生产环境优先使用本地模型目录。
- 模型下载放在构建或发布阶段,不放在请求阶段。
- 日志不要记录原始敏感文本。
- 容器或进程用最小权限运行。
- 记录模型加载行为和版本。
9. Apple MLX 与 Swift:端侧医疗 NLP 的线索
OpenMed 比很多 Python 医疗 NLP 项目多走了一步:它不仅面向服务器,也面向 Apple 端设备。
项目支持 Python MLX 和 Swift / OpenMedKit 路线。对于 Apple Silicon Mac、iPhone、iPad 上的本地推理,这很有想象力。比如医生端工具可以在本地对一段文本做 OCR、PII 检测、脱敏、实体抽取,原始文本尽量不离开设备。
但也要克制。OpenMed 文档提到 MLX 架构覆盖仍在推进中,不应该理解成所有 OpenMed 模型都已经完美支持 MLX 和 iOS。
比较合理的态度是:它提供了端侧医疗 NLP 的探索入口,但生产系统仍然需要逐模型、逐设备、逐场景验证。
10. 推荐接入架构
如果把 OpenMed 接入真实系统,可以拆成五层:
第一层,输入层。来源可能是医生输入、OCR 文档、科研文本、EHR 导出的病历、药物说明书、PubMed 摘要。
第二层,预处理层。包括文本清洗、编码统一、长度切分、段落识别、语言识别、无效内容过滤。
第三层,OpenMed 推理层。运行 NER、PII 检测、去标识化、批处理。这里必须固定模型版本,配置白名单,避免日志记录敏感原文。
第四层,后处理层。包括实体合并、置信度过滤、否定规则、上下文判断、术语标准化,映射到 ICD、UMLS、SNOMED CT 或内部字典。
第五层,业务层。包括结构化入库、搜索索引、知识图谱、临床摘要、大模型问答、科研统计、人工审核界面。
OpenMed 主要负责第三层。它不能替代后处理、人工审核、合规流程和临床责任边界。
11. 适合谁研究
OpenMed 适合四类人:
- 医疗 AI 开发者:做病历摘要、临床搜索、知识图谱、院内大模型助手。
- 后端工程师:研究 AI 能力服务化、模型生命周期、批处理、REST 接口。
- 数据工程师:清洗医疗文本、抽取实体、构造训练数据、脱敏数据集。
- Apple 本地 AI 开发者:关注 MLX、Swift、本地隐私计算和端侧医疗 NLP。
不适合的人也很明确:
- 想找"直接给患者看病的 AI 医生"。
- 想找中文医疗问答模型。
- 想找医学影像分割框架。
- 没有能力做评估、安全隔离和合规流程,却想直接接入真实患者数据。
12. 技术优点与边界
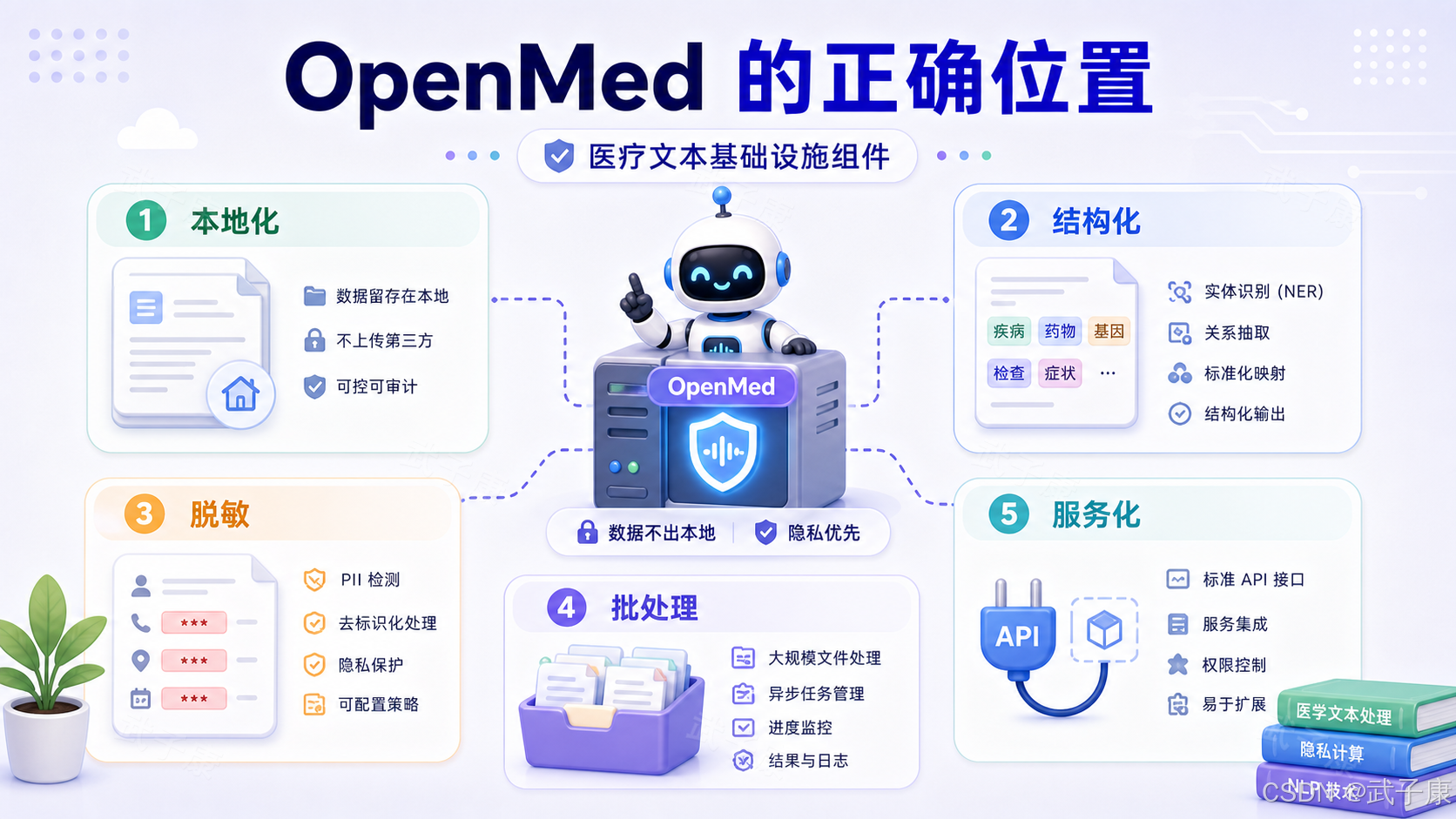
OpenMed 的优点是方向务实:本地优先、任务明确、工程封装较完整、Apache-2.0 许可证友好、模型覆盖广,并且切中了医疗 AI 真实落地的第一道门槛:结构化和脱敏。
它的边界也必须写清楚:
- NER 结果不能当诊断结论。
- 英文和多语言能力不代表中文医疗能力。
- 脱敏不能只靠模型,还要规则、字典、校验器、人工抽检和审计。
- 动态模型加载有安全风险。
- 开源项目不等于临床认证。
- "production-ready""state-of-the-art" 之类表述必须回到自己的数据集上验证。
一句话:OpenMed 值得研究,但它应该是医疗文本处理链路中的结构化与隐私保护层,不是最终临床判断层。
13. 总结
OpenMed 的关键词不是医疗聊天机器人,而是本地化、结构化、脱敏、可部署。
它适合处理临床文本、科研文本、药物文本和医疗敏感信息。它提供 Python SDK、REST 服务、批处理、模型注册表、PII 检测、去标识化、Apple MLX 和 Swift 端能力。它的模型体系覆盖疾病、药物、基因、蛋白、肿瘤、解剖、PII 等方向。
但它不能被误解成能直接诊断的 AI 医生。它的输出需要评估、校验、后处理和人工审核。尤其在中文医疗场景、真实患者数据、生产部署和安全隔离方面,必须严肃测试。
如果未来 OpenMed 继续补齐 assertion detection、关系抽取、FHIR 集成、ICD/CPT/UMLS 映射、benchmark suite 和模型评估工具,它有机会从"医疗 NER 工具包"进一步演化成"医疗文本 AI 基础设施"。
当前最合理的使用方式是:先识别、先脱敏、先结构化,再把结果交给后续检索、统计、知识图谱、规则系统或大模型。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
用户上传 model_name 后服务报 trust_remote_code 异常或模型被替换 |
未做模型白名单,请求直接传到 HF Hub,攻击者可触发任意模型加载 | 检查 service 层日志、HF 缓存目录、HF API 调用记录 | 1) 升级到 OpenMed ≥ 1.5.2;2) 服务端维护固定 model_id → 本地路径 映射;3) 前端只暴露业务枚举 |
| 病历中"患者否认糖尿病"被识别为糖尿病确诊 | NER 模型只做实体抽取,未做 negation/assertion | 在结果层检查 negative 标记、上下文窗口 | 在后处理层加入 negation 规则库(NegEx、ConText),或单独训练 assertion 模型 |
| 中文病历 NER 召回率极低(<30%) | 直接套用英文模型,中文 tokenizer、术语、缩写不匹配 | 用自建评估集(门诊/出院/检查/影像)跑一遍指标 | 1) 不要直接默认英文模型可用;2) 评估中文场景再决定是否接入;3) 必要时微调或换专用中文医疗 NER |
| 去标识化后 SSN/电话仍残留 | tokenizer 把敏感字段切碎,smart entity merging 未启用 | 对比原始文本与 deidentify 输出,定位漏网字段 |
开启 use_smart_merging=True;增加正则+字典双校验;人工抽检 |
| Apple Silicon 上 MLX 模型推理崩溃 | 加载了 PyTorch-only 模型,或 8-bit 量化与设备不兼容 | 检查模型后缀(-mlx)、MLX 版本、设备芯片(M1/M2/M3/M4) |
仅加载带 -mlx 后缀的模型;优先用 MLX 8-bit 版本;更新 mlx/mlx-lm 库 |
deidentify(method="replace") 输出非英文 locale 错位 |
locale-aware surrogate generator 未启用或版本 < 1.3.0 | 检查 OpenMed 版本、locale 配置 | 升级到 ≥ v1.3.0;显式传入 locale 参数;开启 locale-aware validators |
| 模型下载阶段把敏感文本写入日志 | 默认 logging 配置未脱敏,请求 trace 把原文输出 | 检索日志中的 patient name/DOB/SSN 字段 | 关闭 verbose logging;中间结果只保留 entity label;日志走脱敏通道 |
| 多语言 PII 模型在中文/葡萄牙语上效果差 | 加载了 OpenAI baseline 而非 OpenMed Multilingual Privacy Filter | 检查 model_name 是否为 privacy-filter-multilingual |
切到 OpenMed/privacy-filter-multilingual(支持 16 种语言,v1.4.0+) |
| Apple iOS 端 OpenMedKit 包体过大 | 同时打包了多个 MLX 模型权重 | 检查 .mlmodel / .mlx 文件清单 |
只打包当前场景必需的模型;用 8-bit 量化;按需懒加载 |
| 误把 OpenMed 当诊断模型直接给患者用 | 项目定位被"open-source healthcare AI"标签误导 | 审查系统架构中是否把 NER 输出作为最终建议 | 明确边界:OpenMed 只做结构化层;最终输出走人工审核或带规则的大模型层 |
作者:武子康的个人博客