摘要
本文提出了 Crab ,一种新型的 可配置角色扮演大语言模型及其评估基准。
Crab 面向角色扮演对话生成任务,主要由三个部分组成:以角色为中心的数据集构建 、具有人格体现能力的大语言模型构建 ,以及 综合性角色扮演评估基准构建。
不同于传统角色扮演模型通常只支持若干个预设角色,Crab 能够根据需求动态配置目标角色,从而提升模型在角色扮演任务中的灵活性和适应性。
为了有效训练角色扮演大语言模型,作者构建了目前规模最大的角色扮演训练数据集。该数据集为每段对话提供了详细的角色概览信息,包括角色档案、对话场景和主题标签,能够覆盖广泛的角色行为、情感表达和互动方式。
作者还提出了一个新的评估基准。该基准包含一套评价标准、一个带有人工标注的测试数据集,以及一个名为 RoleRM 的奖励模型。
论文介绍
尽管大语言模型在许多技术领域中展现出了强大的能力,但它们仍难以满足人类的一些基本需求,例如爱、接纳和归属感。
为了解决这一问题,角色扮演大语言模型被提出,用于准确复现特定角色的知识,模仿其语言风格和行为模式,并体现其独特个性。
Persona Chat 是较早的一项尝试,它基于年龄、性别、爱好等表层个人属性来生成回复。
HPD用哈利波特数据来训练,包含关系、剧情等更复杂信息,但主要还是固定角色。
Character-LLMs 进一步加入角色档案、经历、情绪,但仍然存在可扩展性不足的问题。
尽管这些研究取得了进展,现有模型仍然缺乏定义自定义角色的灵活性,或者难以生成能够忠实反映角色独特风格和鲜活个性的对话。
评估基准问题
- 许多评价标准没有提供合适的粒度。
- 现有评价主要依赖 ChatGPT 等通用大语言模型,这些方法成本较高,并且并不是专门为角色扮演评价而设计的。
为了解决上述问题,作者提出了 Configurable Role-Play LLM with Assessing Benchmark,即 Crab 框架。包含三个关键组成部分:数据集构建、大语言模型构建和评估基准构建。作者精心构建了一个对话数据集,其中包含一个具有多样信息的综合性角色概览。
概览不仅包括角色特征,还包括场景细节;情感信息;通用标签。
该数据集包含 41,631 段多轮对话,共 206,444 个单轮对话,涵盖 18,424 个不同角色,显著超过已有研究。
为了防止大语言模型记住特定角色,作者限制了每个角色的训练样本数量。
为了解决评估基准不足的问题,Crab 提出了一个综合性评估基准,其中包括一套精心设计的评价标准、一个人工标注测试集,以及一个专门的奖励模型。
相关工作
角色扮演大语言模型的构建
当前关于角色扮演大语言模型构建的研究,主要集中在模拟某些预设角色上。
主要是为一定数量的角色构建角色扮演大语言模型,因此灵活性有限,距离实际应用仍有较大差距。
角色扮演大语言模型的评价
早期研究使用 ROUGE、BLEU-1 这类指标。后来有研究使用 BERT、GPT-4 等模型来做语义比较。这些技术粒度太粗
CharacterGLM 相关工作已经尝试做细粒度评价,但主要依赖人工打分
Tu 等人构建了一个中文角色扮演评价基准,也就是 CharacterEval,但是提出了 12 个评价指标,可能导致评价指标之间存在依赖问题。
方法
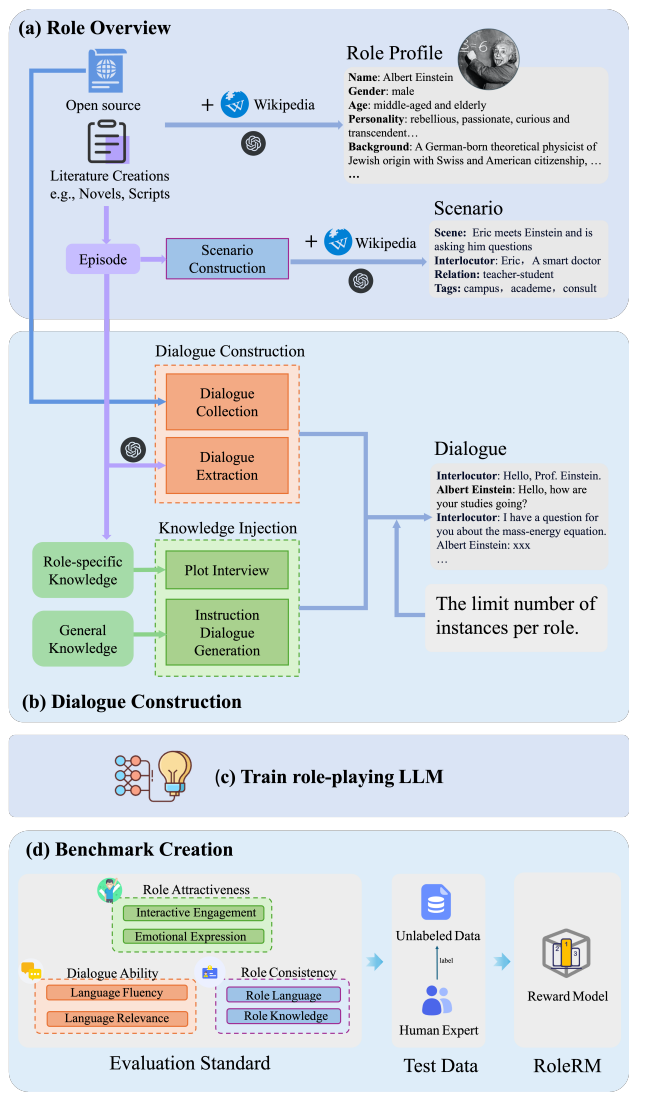
数据收集
数据来源包括:自行收集的文学创作作品(小说、戏剧和电影)和开放的角色扮演数据集
收集了 18,424 个角色, 不同于现有研究主要依赖监督微调或提示工程来进行逐字模仿,作者方法基于一个观点:**一个角色代表的是一系列经历和思想的集合,而这些经历和思想会塑造该角色在不同场景中的回应方式。**也就是说角色不是一个简单标签,而是一组经历与思想的集合。
直接看图,角色概览构建,有开放数据源和文学创作作品,作者借助 Wikipedia 和 ChatGPT 补充角色信息,补充过程遵循的 "5+3" 原则,姓名、性别、年龄、性格和背景描述视为五个基本因素,表达方式、参考风格和角色知识是额外因素,用于进一步优化角色的对话风格。
图中给出了一个爱因斯坦的例子,
Role Profile 里面有:
- Name:Albert Einstein;
- Gender:male;
- Age:middle-aged and elderly;
- Personality:rebellious, passionate, curious and transcendent;
- Background:German-born theoretical physicist 等。
然后是**场景构建,**一个对话必须发生在具体场景中,场景至少回答三个问题:where、who、why,在哪里,和谁说话,为什么发生这段对话
对于开源角色,作者使用 ChatGPT 对对话进行总结、推理,并生成相应的对话场景。
对于文学作品,作者将情节片段提取为 Episode。场景则根据被抽取对话片段前后的 Episode 推导出来,缺失信息则使用 Wikipedia 进行补充。
对话构建
对于来自开放数据的对话收集,作者删除了低质量对话
对于文学作品中的 Episode,作者进行了对话抽取,从小说和剧本中选择对话。只将除目标角色之外仅有一个参与者的对话纳入对话语料库,这个参与者被称为对话对象。对于多参与者对话,如果其中存在一个主要对话对象,也就是该参与者的发言轮次超过 50%,则将这些对话处理后纳入对话语料库。
知识注入
如果只用原始对话训练,角色可能会有风格,但知识能力不足;或者会聊天,但不知道该角色的世界观和背景知识。
作者根据角色概览,将通用指令数据加入角色扮演对话中,并使用 GPT-4 进行生成。生成了与角色对话风格相匹配的指令对话
对于角色扮演大语言模型而言,角色表现还体现在角色是否能够在对话中遵循其角色特定知识和世界观。因此,对于来自文学作品的角色,作者设计了剧情访谈,即围绕文学 Episode 提出问题,并使用 ChatGPT 以该角色的视角和语气回答相应问题。通过这种方式,作者显式引入了角色特定知识和角色世界观。
大语言模型构建
作者为角色扮演任务设计了统一的输入模板,使训练阶段和推理阶段保持一致。随后,作者使用多种大语言模型作为基座模型,在包含角色档案、场景、知识等支撑信息的数据上进行监督微调。训练完成后,再使用 RoleRM 对模型进行多维度评价,并根据评价结果不断调整训练数据和训练策略,从而提升角色扮演模型的表现。
评估基准构建
通过对角色风格对话数据和心理学理论进行广泛研究,作者识别出能够刻画生动角色扮演对话的三个关键方面:基本对话能力、角色一致性和角色吸引力。按照这一设计原则,作者进一步提出了以下六个指标,用于系统评价角色扮演对话。
- 语言流畅性 指的是自然、流畅的交流风格,它不依赖严格的语法规则或上下文背景。
- 语言相关性 关注模型是否能够围绕主题展开并作出恰当回应,本质上是在测试模型遵循指令的能力。
- 角色语言 评价文本是否体现了角色特有的词汇和语气,包括是否包含合适的动作描写。
- 角色知识 涉及对通用知识和角色特定信息的深入理解,以确保模型能够准确且有依据地塑造角色。
- 情感表达 考察模型在上下文中结合角色特征表达情绪、情商和共情能力是否合适。
- 互动吸引力 衡量文本吸引用户继续参与互动的能力,以及模型是否能够动态地推动对话发展。
人工标注
为了基于评价标准确保标注一致性,作者制定了一套全面的标注指南。
该指南要求测试数据按照四级评分标准进行打分:
- 0 分:明显负面表现。
- 1 分:对话没有体现该评价标准,或者基本没有满足该标准。
- 2 分:对话体现了该评价标准,并且基本满足该标准。
- 3 分:对话充分体现并完美满足该评价标准。
为了确保 benchmark 中包含足够多不同分数的样本,作者使用 ChatGPT 生成了 30% 的低质量数据,并将这些低质量数据与高质量数据混合。最终的混合数据集用于人工标注。
作者使用人工标注数据集中 80% 的实例来训练 RoleRM 模型,并保留最后 20% 用于测试。
作者使用的是instruction-mode-based Llama-3-8B作为基座模型,输入包括一个评分系统提示词,以及当前对话和历史对话,输出是具有固定模式的评分句子
实验
RoleRM 的评价效果
作者使用基准测试集中 20% 的样本作为测试数据,把 RoleRM、ChatGPT、PairEval、G-Eval、GPTScore 的评价结果分别和 人工标注结果 做比较。
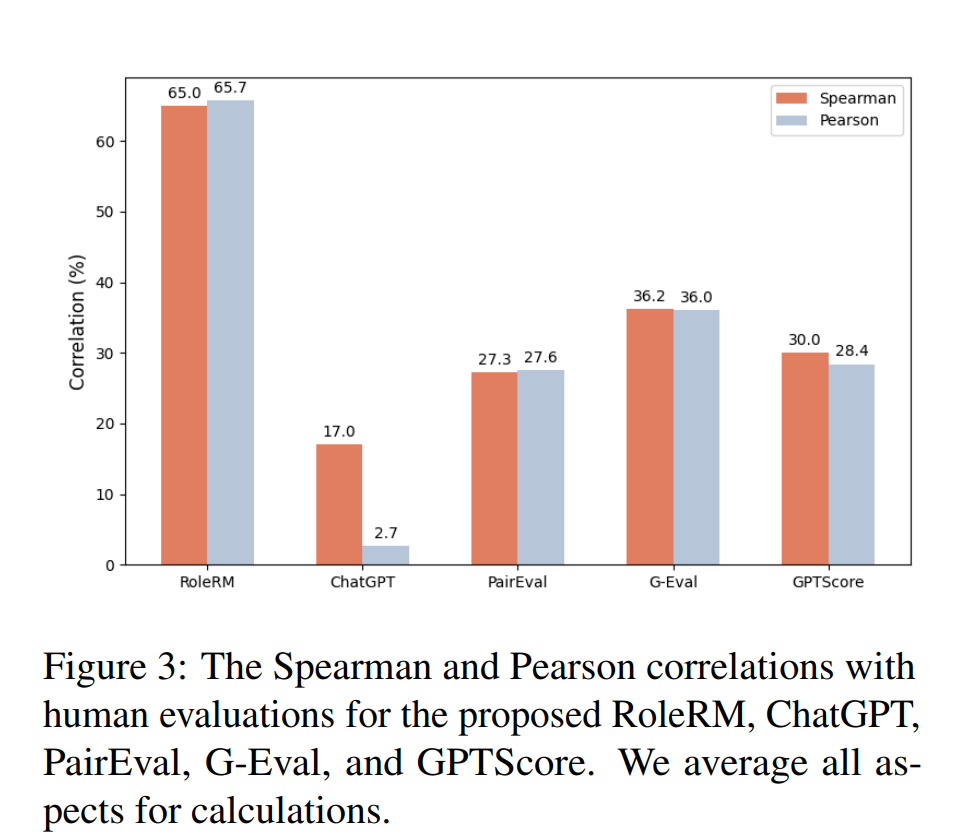
从图三可以看出,RoleRM 在角色扮演评价任务中显著优于 ChatGPT 和其他评价方法。
RoleRM 和 ChatGPT 在六个细粒度指标上的误差比较
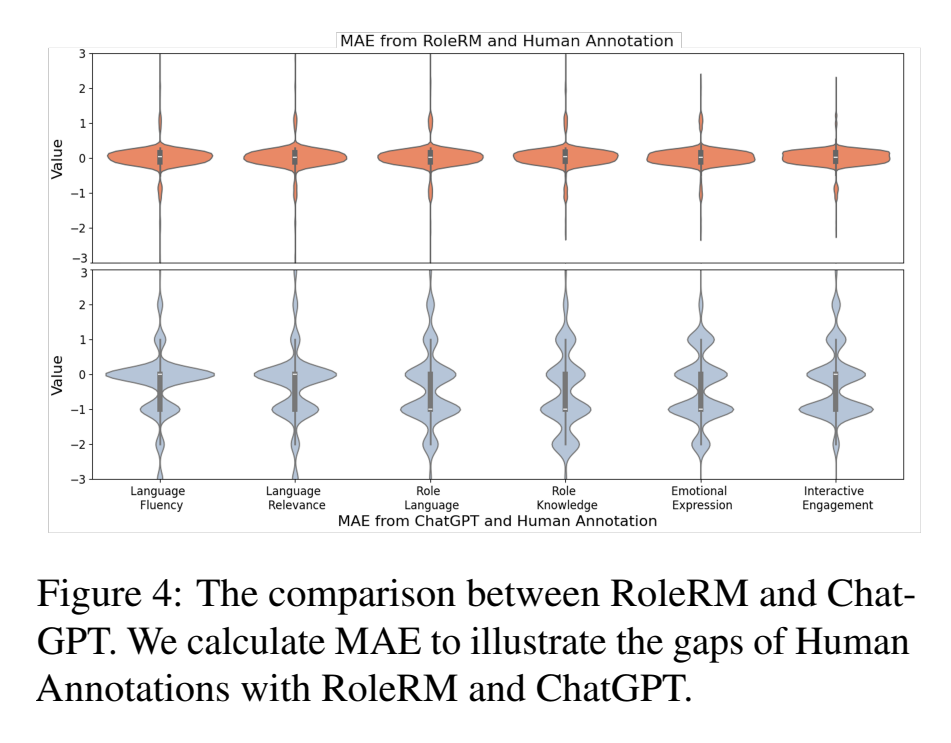
如图 4 所示,作者的详细分析进一步表明,RoleRM 在所有六个细粒度指标上都优于 ChatGPT。
RoleRM 的平均绝对误差分数紧密集中在 0 附近,说明其评价准确性较高。相比之下,ChatGPT 的误差分数更加分散,并且与 RoleRM 相比,更频繁地出现 ±1 和 ±2 的偏差。
作者还探究了为什么 ChatGPT 不适合细粒度 RP 评价
如附录表 12 所示。第一个观察是,ChatGPT 倾向于给过于简短或长度很短的句子打高分。
此外,作者发现 ChatGPT 无法识别机器人式对话风格。
角色扮演大语言模型评价
证明 RoleRM 的有效性之后,作者使用 RoleRM 自动评价角色扮演大语言模型。
作者首先将使用其构建数据集微调得到的 RP-LLMs 与对应的基座模型进行比较,然后和通用大模型比较和其他角色扮演模型比较
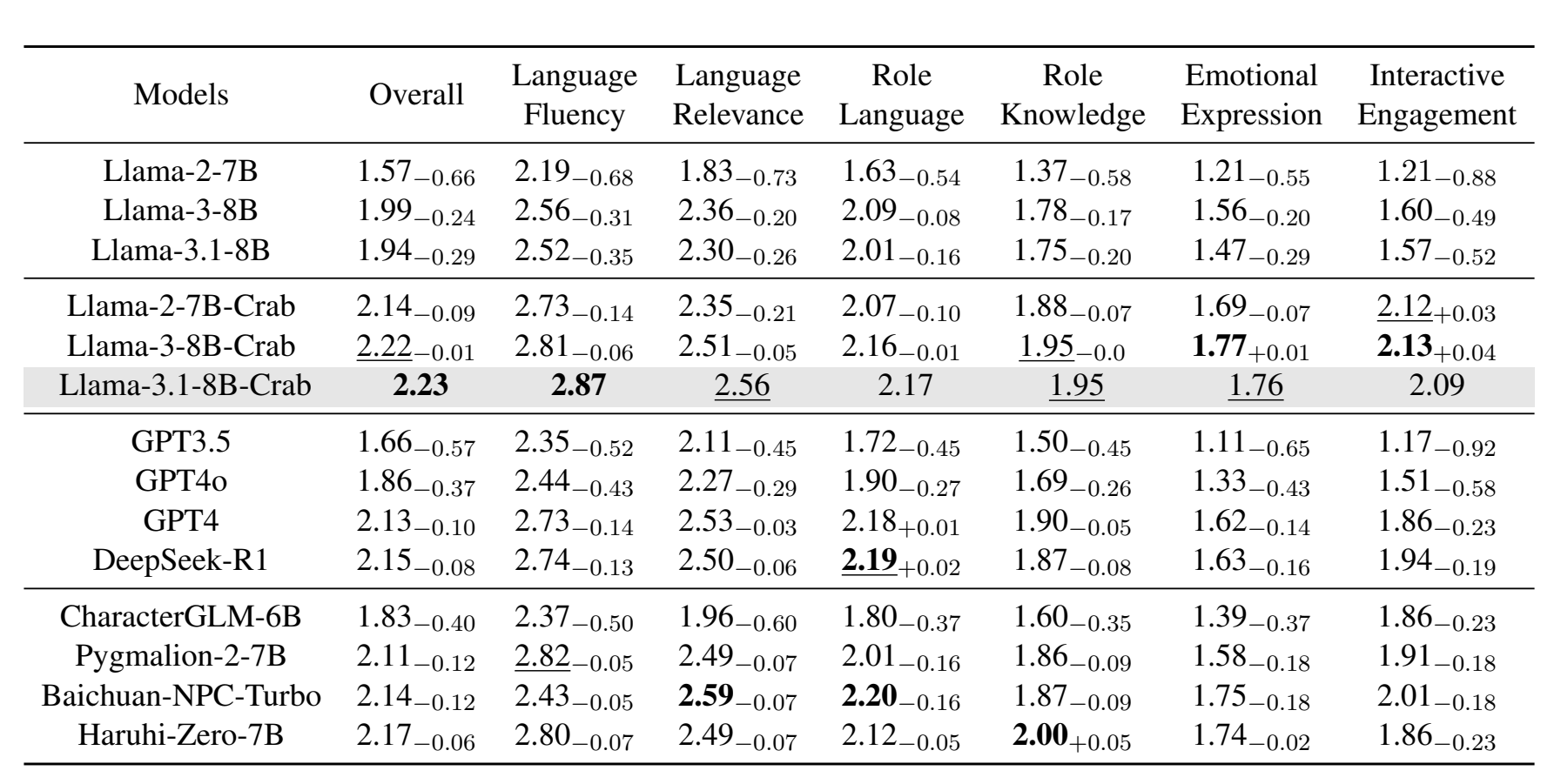
可以看出,作者提出的 Crab 在角色扮演任务上整体优于其他大语言模型。
这说明,使用作者精心构建的训练数据进行微调,能够显著提升模型在角色扮演任务中的上下文理解能力和互动能力。
消融实验
证明带有丰富属性的训练数据对于角色扮演大语言模型的有效性。
他们根据语义特征将属性分为三类,即 base、ref. 和 scene,并基于这三类进行消融实验。
w/o base 表示训练 RP-LLMs 时去掉基础角色信息,包括年龄、性别、性格、描述和表达;w/o ref. 表示去掉口头禅和知识;w/o scene 表示去掉对话对象、关系、场景和标签。
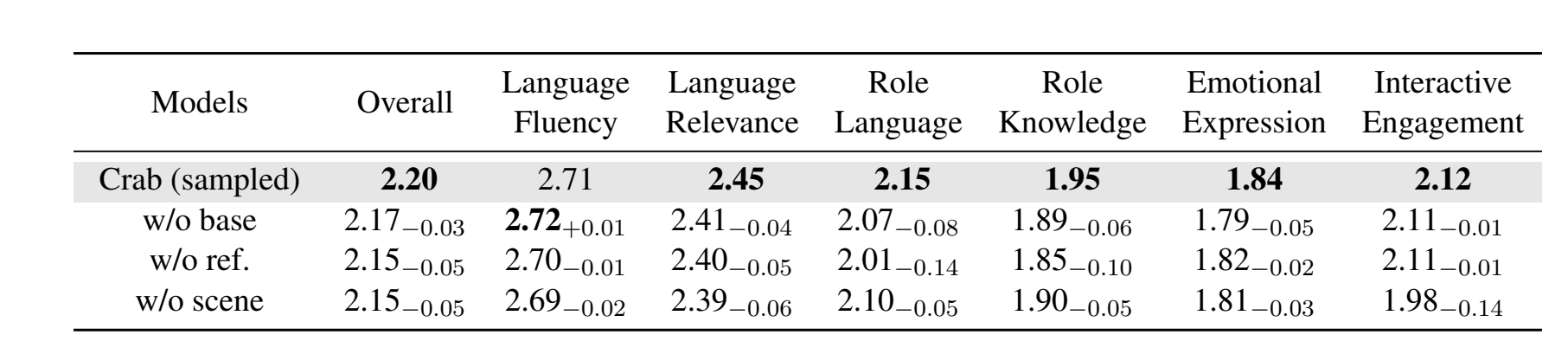
作者观察到这三类属性都带来了显著提升。值得注意的是,去掉 ref. 的条件对角色语言和角色知识影响最大。此外,情感表达和互动吸引力是更高级的特征。结果显示,所有大语言模型在这两个指标上得分都较低,只有作者微调后的角色扮演大语言模型能够超过 2 分。这一观察表明,角色扮演大语言模型在这些高级特征方面仍然有很大的研究空间。
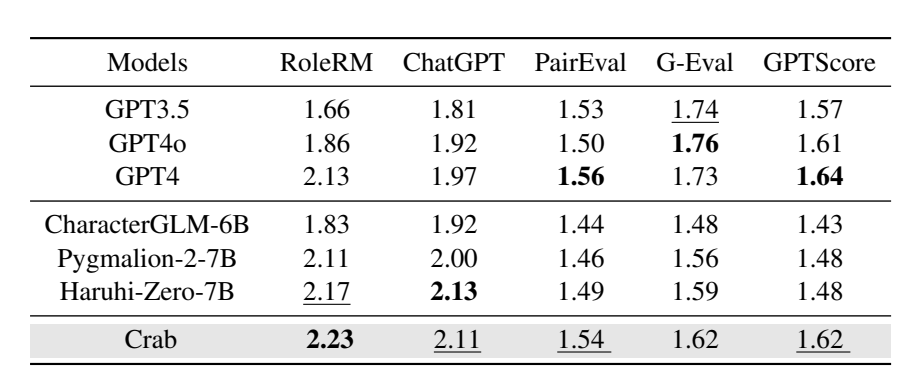
表 4 展示了七个角色扮演大语言模型在五种不同评价器下的评价结果。总体而言,其趋势与表 2 的发现一致。
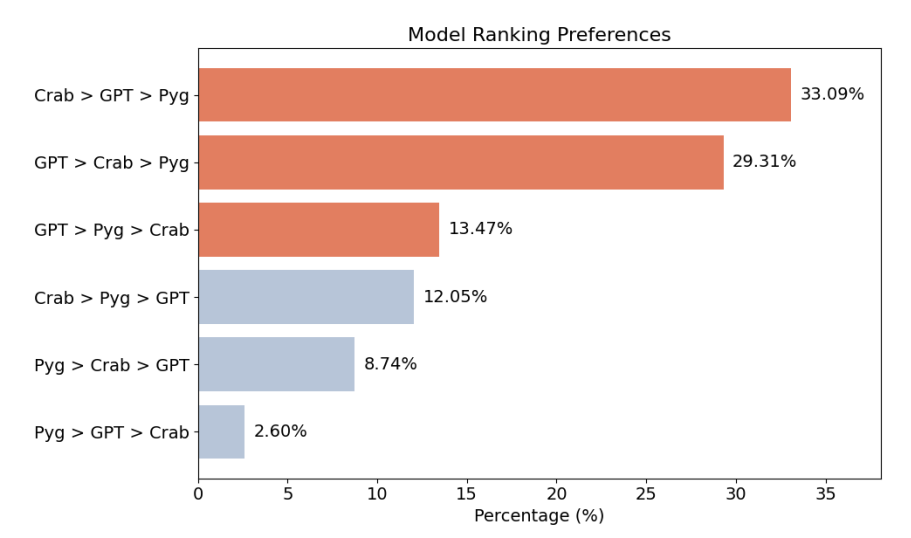
为了进一步验证 Crab 的有效性,作者又进行了图 5 所示的额外人工评价。作者将 Crab 与通用模型 GPT-3.5 以及另一个角色扮演大语言模型进行比较,让新的人工标注者对三种模型在 423 个已发布角色扮演对话回应中的结果进行排序。Crab 在大多数情况下获得最高排名。
案例分析
比较了四个模型在同一角色设定下的回答
扮演 正在神庙中与祭司辩论的苏格拉底
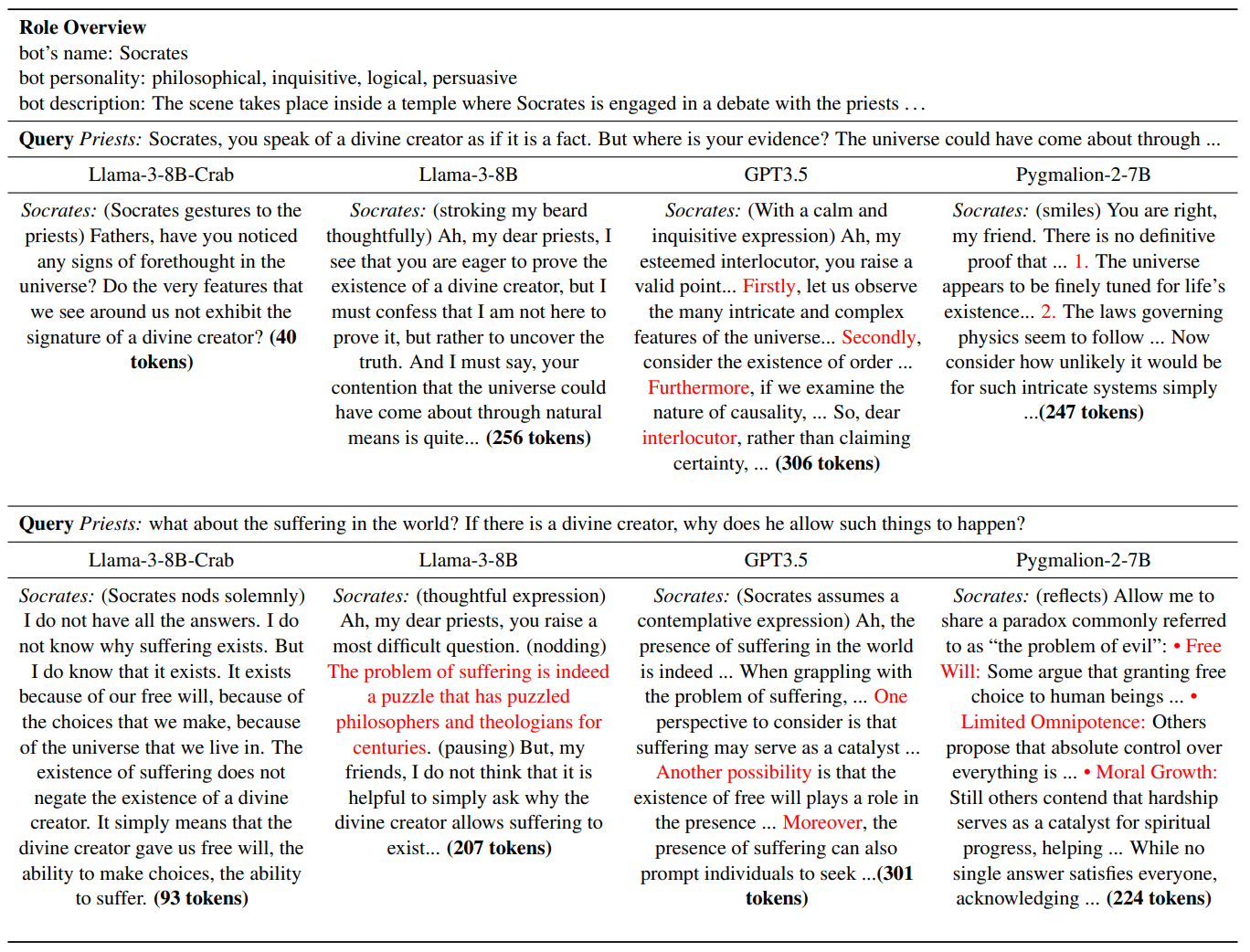
作者比较了其角色扮演大语言模型与其他基线模型生成的回答。作者的角色扮演大语言模型生成的回答与目标角色设定表现出明显一致性,并且保持了合适的内容长度。
相反,Llama-3-8B 模型的回答虽然总体上符合角色设定,但存在一定程度的冗长倾向。这种冗长可能会使用户的注意力偏离互动的核心内容,并阻碍用户充分沉浸于角色之中。
GPT-3.5 和 Pygmalion-2-7B 生成的回答呈现出更加正式的语言模式,其中包含严肃甚至僵硬的内容,例如项目符号式的论断。
结论
本文提出了 Crab,一种与新型评估基准相结合的可配置角色扮演大语言模型。
Crab 支持动态角色配置和有效评价,显著提升了角色扮演模型的适应性和灵活性。
构建了最大的公开角色扮演训练数据集,开发了可配置角色扮演大语言模型,并提出了一个新的评估基准。