一、引言
1.1 核心概念定义
规范化理论是关系数据库架构设计的核心方法论,用于指导设计结构合理、数据冗余度低、操作异常少的关系模式,解决插入异常、删除异常、更新异常和数据冗余四类典型问题。作为软考高级系统架构设计师考试中数据库架构设计模块的高频考点,占数据库相关分值的 30%-40%,常以案例分析题、选择题形式出现,重点考察范式判断、候选码求解和模式分解方案设计能力。
1.2 历史发展脉络
规范化理论由 IBM 研究员 E.F.Codd 于 1971 年首次提出,同年推出第一范式(1NF)和第二范式(2NF),1974 年 Codd 与 Raymond Boyce 共同提出第三范式(3NF)和 BCNF 范式,后续学术界逐步完善了第四范式(4NF)、第五范式(5NF),形成了完整的关系数据库规范化体系,目前已成为 ISO/IEC 9075 关系数据库国际标准的核心组成部分。
1.3 本文知识点覆盖
本文将系统讲解函数依赖定义与分类、Armstrong 公理系统、候选码求解方法、四级范式判定标准、模式分解设计原则五大核心知识点,并结合典型例题展开分析,覆盖软考全部相关考点。
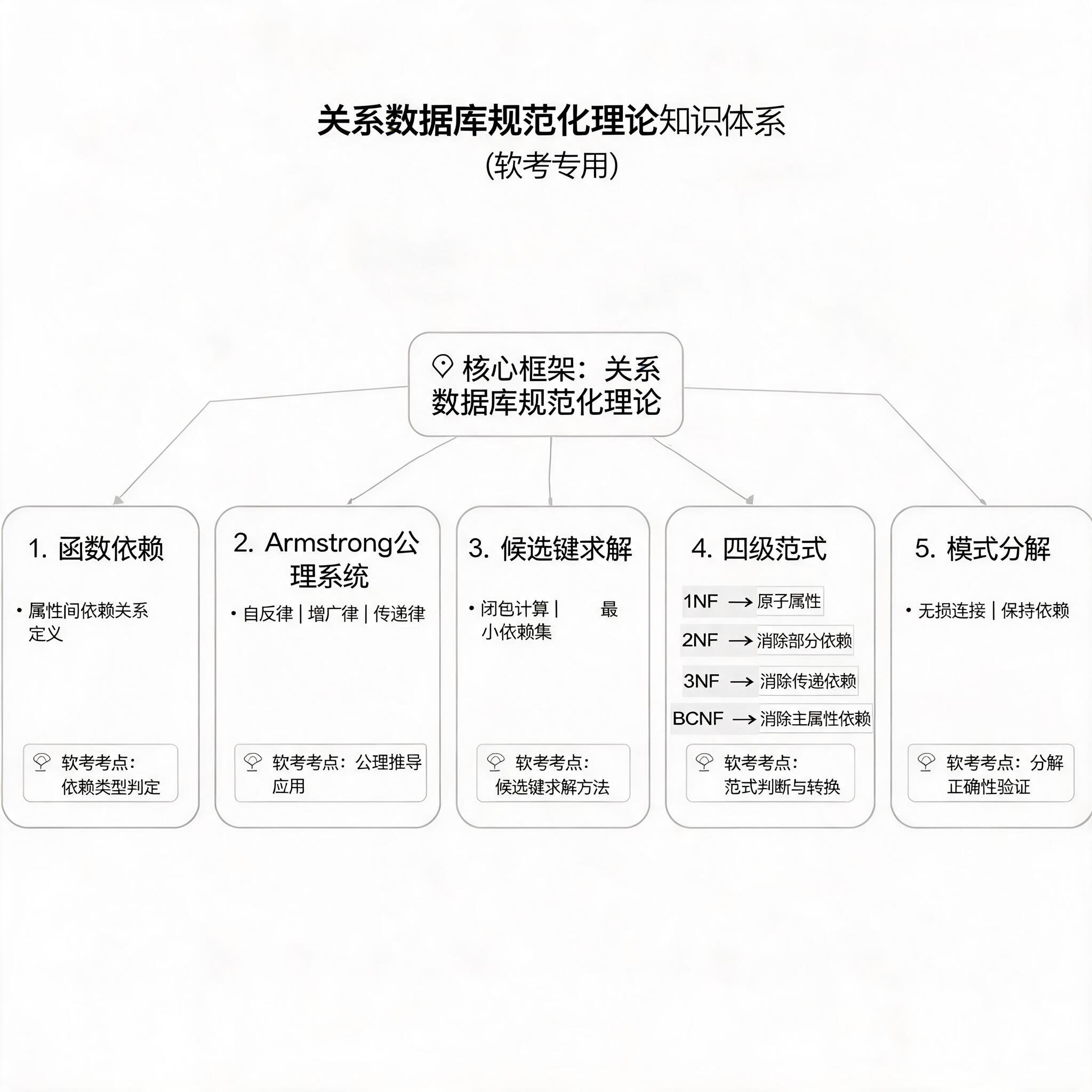 规范化理论知识体系框架图
规范化理论知识体系框架图
二、函数依赖核心原理
2.1 基本定义与语义
函数依赖是指关系模式中属性之间的约束关系,设 R (U,F) 是属性集 U 上的关系模式,X、Y 是 U 的子集,若对于 R 的任意两个元组 u、v,当 u X=v X 时必有 u Y=v Y,则称 X 函数决定 Y,记为 X→Y,其中 X 称为决定因素,Y 称为依赖因素。函数依赖本质上反映了业务规则的约束,例如 "学号唯一确定学生姓名" 就是典型的函数依赖。
2.2 函数依赖分类
(1)完全函数依赖
若 X→Y,且对于 X 的任意真子集 X',都不存在 X'→Y,则称 Y 完全依赖于 X,记为 X→FY。例如在学生选课关系中,(学号,课程号)→成绩,单独的学号或课程号都无法确定成绩,因此成绩完全依赖于 (学号,课程号)。
(2)部分函数依赖
若 X→Y,但 Y 不完全依赖于 X,则称 Y 部分依赖于 X,记为 X→PY。例如 (学号,课程号)→学分,而单独的课程号即可确定学分,因此学分部分依赖于 (学号,课程号),这类依赖是产生数据冗余的主要原因之一。
(3)传递函数依赖
若 X→Y,Y→Z,且 Y 不包含于 X,Y 不能函数决定 X,则称 Z 传递依赖于 X,记为 X→TZ。例如学号→系号,系号→系名,且系号无法决定学号,因此系名传递依赖于学号,这类依赖会导致更新异常。
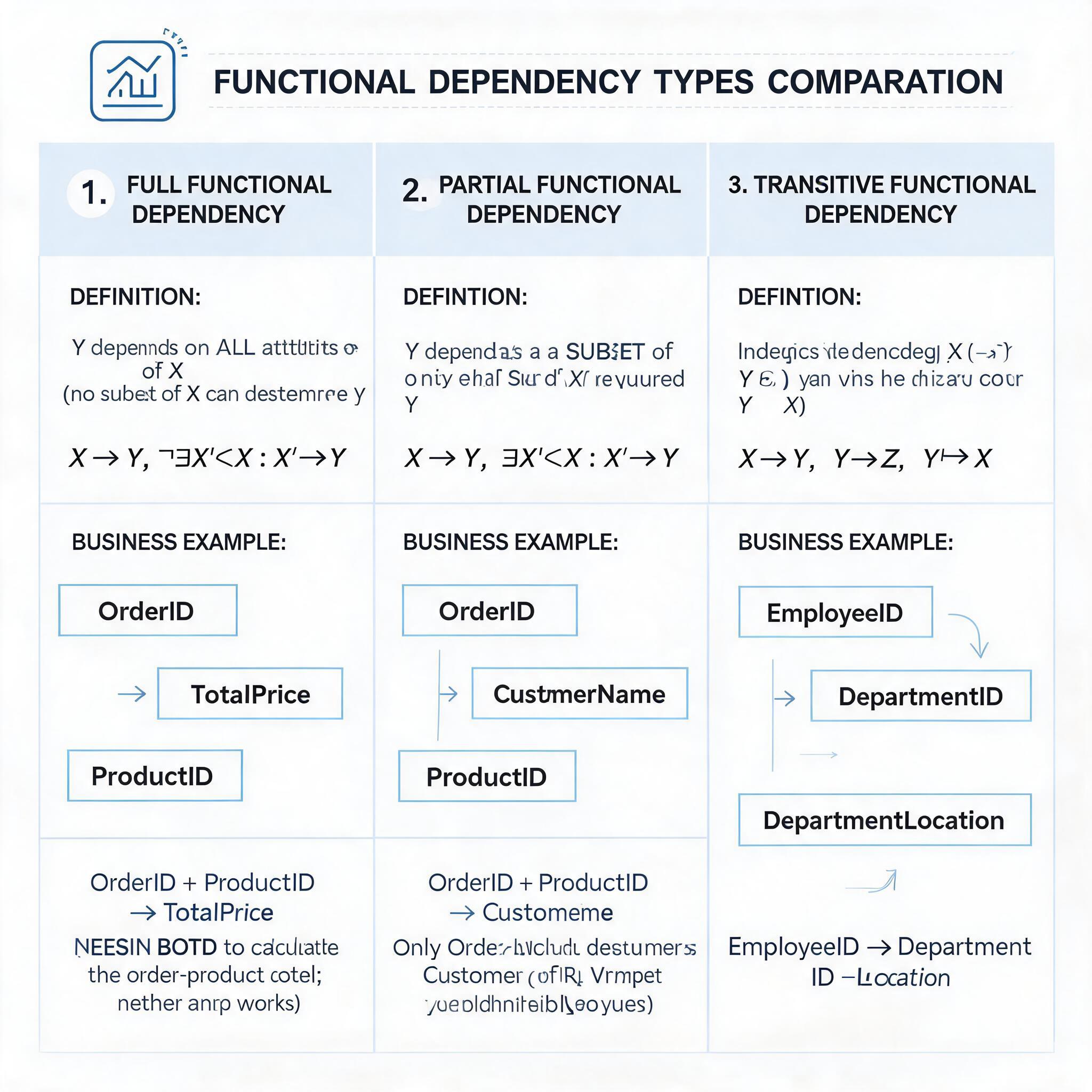 三类函数依赖关系对比示意图
三类函数依赖关系对比示意图
三、Armstrong 公理系统与依赖推导
3.1 基本公理规则
Armstrong 公理是推导函数依赖的完备形式化系统,包含三条基本规则:
(1)自反律
若 Y⊆X⊆U,则 X→Y 成立,这类依赖也称为平凡函数依赖,不反映新的业务约束,例如 (学号,姓名)→学号是必然成立的。
(2)增广律
若 X→Y 且 Z⊆U,则 XZ→YZ 成立,即在函数依赖两侧增加相同属性,依赖关系仍然有效,例如学号→姓名,可推导得到 (学号,课程号)→(姓名,课程号)。
(3)传递律
若 X→Y 且 Y→Z,则 X→Z 成立,是传递依赖的理论基础。
3.2 导出推论
由三条基本公理可推导得到三条实用推论,大幅提升依赖推导效率:
(1)合并规则
若 X→Y 且 X→Z,则 X→YZ 成立,例如学号→姓名,学号→系号,可推导得到学号→(姓名,系号)。
(2)伪传递规则
若 X→Y 且 WY→Z,则 XW→Z 成立,例如学号→系号,(系号,专业)→系主任,可推导得到 (学号,专业)→系主任。
(3)分解规则
若 X→Y 且 Z⊆Y,则 X→Z 成立,例如学号→(姓名,系号),可推导得到学号→姓名、学号→系号。
3.3 公理的完备性与正确性
Armstrong 公理已被证明是正确且完备的:正确性指从给定的函数依赖集 F 出发,利用公理推导的所有依赖都必然属于 F 的闭包F+;完备性指F+中的所有依赖都可以通过公理推导得到,是后续候选码求解、模式分解的理论基础。
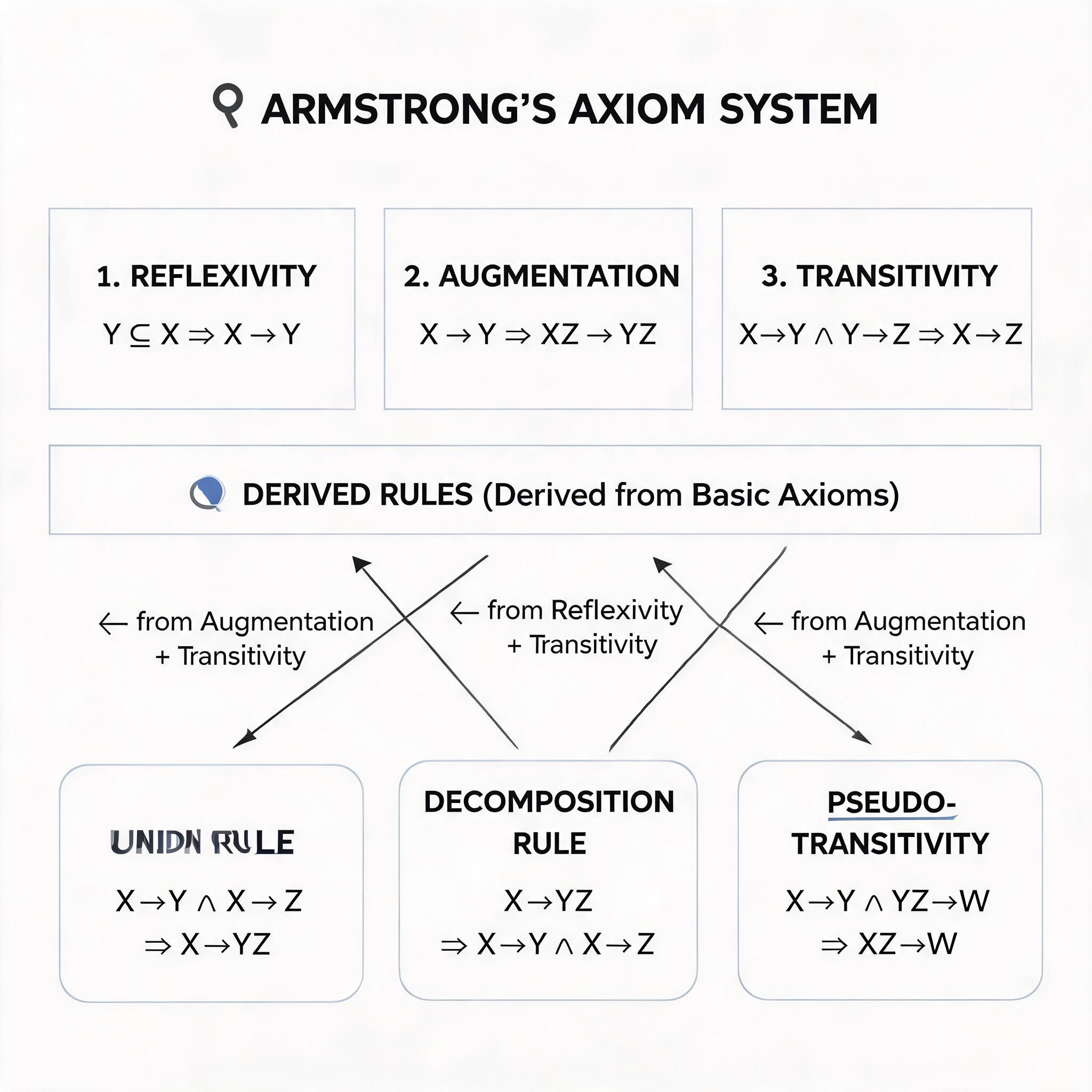 Armstrong 公理推导逻辑关系图
Armstrong 公理推导逻辑关系图
四、候选码求解方法与例题解析
4.1 候选码定义
候选码是关系模式中的属性或属性组,能够完全函数决定所有其他属性,且不存在真子集满足该条件,主码从候选码中选择。候选码包含的属性称为主属性,不包含在任何候选码中的属性称为非主属性。
4.2 标准求解步骤
(1)属性分类
首先将关系模式中的属性分为四类:
- L 类:仅出现在函数依赖左部的属性,必然属于候选码
- R 类:仅出现在函数依赖右部的属性,必然不属于候选码
- N 类:未出现在任何函数依赖中的属性,必然属于候选码
- LR 类:同时出现在函数依赖左右部的属性,需进一步判断
(2)基础集构造
将 L 类和 N 类属性组成基础集 X,计算 X 的闭包X+,若X+包含所有属性,则 X 为候选码。
(3)扩展验证
若X+未包含所有属性,则依次将 LR 类属性加入 X,重新计算闭包,直到闭包包含所有属性,得到最小属性组即为候选码。
4.3 典型例题解析
例题:关系模式 R (A,B,C,D,E),函数依赖集 F={A→C, BC→D, D→B, C→E},求解候选码。
- 分类:L 类属性为 A,R 类属性为 E,LR 类属性为 B、C、D,无 N 类属性
- 基础集 X={A},计算A+:A→C,C→E,得到 {A,C,E},未覆盖所有属性
- 依次加入 LR 属性:加入 B 得到 X={A,B},计算(AB)+:A→C,C→E,BC→D,得到 {A,B,C,D,E},覆盖所有属性,且不存在更小属性组,因此候选码为 AB;加入 D 得到 X={A,D},计算(AD)+:A→C,C→E,D→B,得到 {A,B,C,D,E},同样覆盖所有属性,因此该关系模式有两个候选码:AB 和 AD,主属性为 A、B、D。
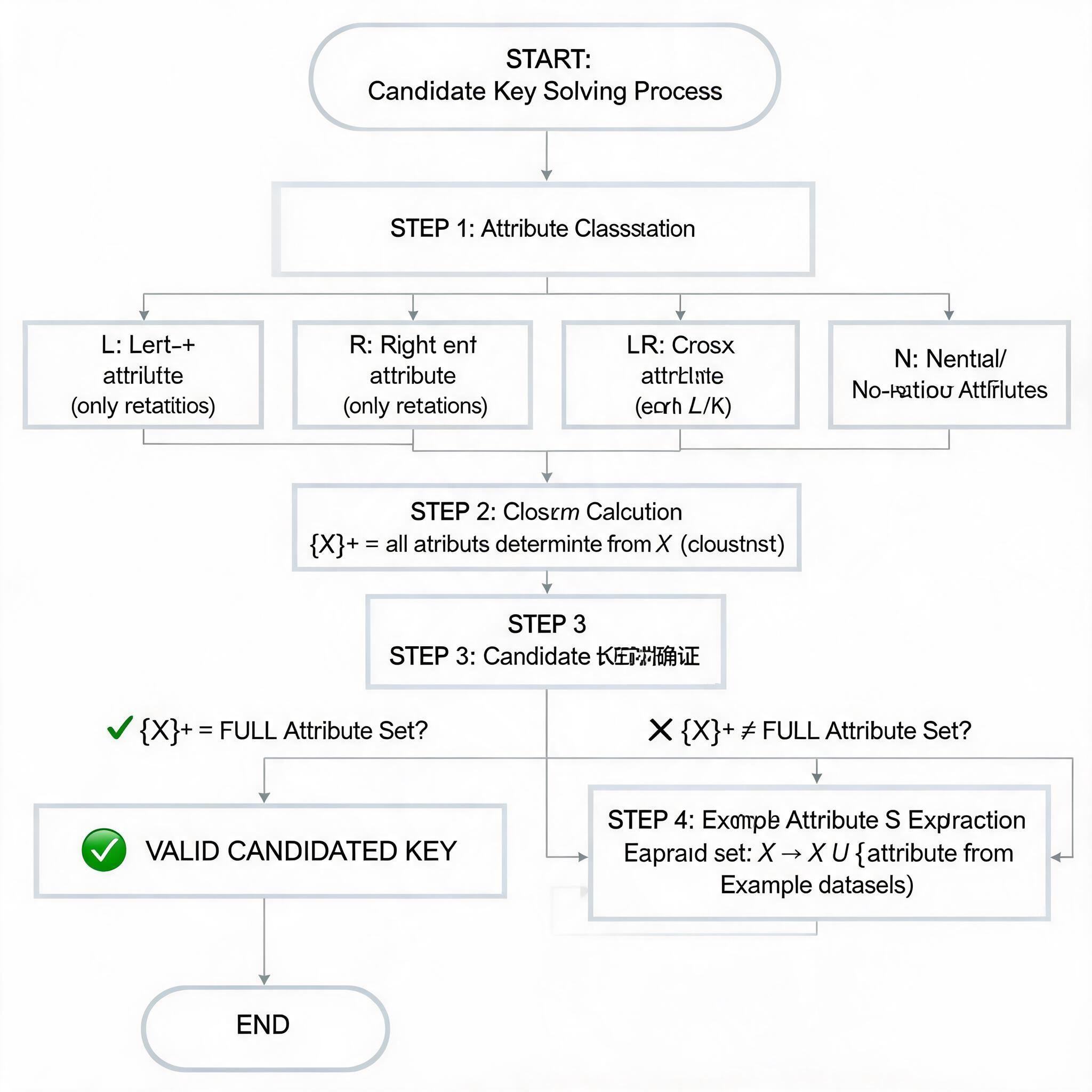 候选码求解流程图
候选码求解流程图
五、四级范式判定标准与对比
5.1 各级范式定义与判定规则
(1)第一范式(1NF)
判定规则:关系模式的所有属性都是不可再分的原子值,不存在组合属性、多值属性。1NF 是关系数据库的基本要求,例如 "员工" 属性包含 "姓名"" 工号 " 两个子属性就不满足 1NF,需要拆分。违反 1NF 会导致无法执行 SQL 查询、数据操作异常等问题。
(2)第二范式(2NF)
判定规则:在满足 1NF 的基础上,消除非主属性对候选码的部分函数依赖。例如关系模式 R (学号,课程号,姓名,学分),候选码为 (学号,课程号),存在部分依赖课程号→学分、学号→姓名,因此不满足 2NF,需要拆分为学生 (学号,姓名)、课程 (课程号,学分)、选课 (学号,课程号,成绩) 三个模式。
(3)第三范式(3NF)
判定规则:在满足 2NF 的基础上,消除非主属性对候选码的传递函数依赖。例如关系模式 R (学号,姓名,系号,系名),候选码为学号,存在传递依赖学号→系号→系名,因此不满足 3NF,需要拆分为学生 (学号,姓名,系号)、院系 (系号,系名) 两个模式。3NF 是工业界实际数据库设计中最常用的范式等级,平衡了冗余度和查询效率。
(4)BC 范式(BCNF)
判定规则:在满足 3NF 的基础上,消除主属性对候选码的部分依赖和传递依赖,即所有函数依赖的决定因素都包含候选码。BCNF 是修正的第三范式,例如关系模式 R (课程号,教师名,图书名),函数依赖集 F={课程号→教师名,(教师名,图书名)→课程号},候选码为 (课程号,图书名) 和 (教师名,图书名),主属性为课程号、教师名、图书名,不存在非主属性,因此满足 3NF,但存在依赖课程号→教师名,其决定因素课程号不包含候选码 (教师名,图书名),因此不满足 BCNF,需要拆分为授课 (课程号,教师名)、教材 (教师名,图书名) 两个模式。
5.2 范式对比分析
| 范式等级 | 消除的依赖类型 | 数据冗余度 | 异常情况 | 适用场景 |
|---|---|---|---|---|
| 1NF | 非原子属性 | 极高 | 全部四类异常 | 关系数据库基本要求 |
| 2NF | 非主属性部分依赖 | 较高 | 插入、删除、更新异常仍然存在 | 极少使用 |
| 3NF | 非主属性传递依赖 | 中等 | 仅存在少量主属性相关异常 | 多数业务系统推荐使用 |
| BCNF | 主属性部分 / 传递依赖 | 极低 | 基本消除所有异常 | 对数据一致性要求极高的核心系统 |
 各级范式递进关系与判定流程图
各级范式递进关系与判定流程图
六、模式分解设计原则与判定方法
6.1 分解的两个核心目标
(1)无损连接性
指分解后的多个关系模式通过自然连接可以还原为原关系,不丢失数据信息。判定方法:对于分解为两个关系模式 R1 和 R2 的情况,若 R1∩R2 能够函数决定 R1-R2 或 R2-R1,则分解是无损的。例如关系模式 R (A,B,C),F={A→B},分解为 R1 (A,B)、R2 (A,C),R1∩R2={A},A→B=R1-R2,因此是无损分解。
(2)保持函数依赖性
指分解后的函数依赖集的并集与原函数依赖集等价,不丢失业务约束。判定方法:对原依赖集 F 中的每个依赖 X→Y,验证 X 在分解后的某个关系模式中的闭包包含 Y 即可。例如关系模式 R (A,B,C),F={A→B, B→C},分解为 R1 (A,B)、R2 (B,C),两个依赖分别在两个模式中保留,因此保持函数依赖;若分解为 R1 (A,B)、R2 (A,C),则丢失了依赖 B→C,不满足保持函数依赖。
6.2 分解方案设计原则
- 3NF 分解:要求同时满足无损连接和保持函数依赖,是工业界最常用的分解方案,能够保证数据一致性的同时保留所有业务约束
- BCNF 分解:仅能保证无损连接,无法保证保持函数依赖,适用于对数据一致性要求极高、允许牺牲部分约束检查效率的场景
- 反规范化设计:在高并发场景下,为了降低连接开销,可适当降低范式等级,通过冗余数据提升查询性能,例如在订单表中冗余存储用户名称,避免关联查询用户表,是电商系统、大数据系统的常用优化手段。
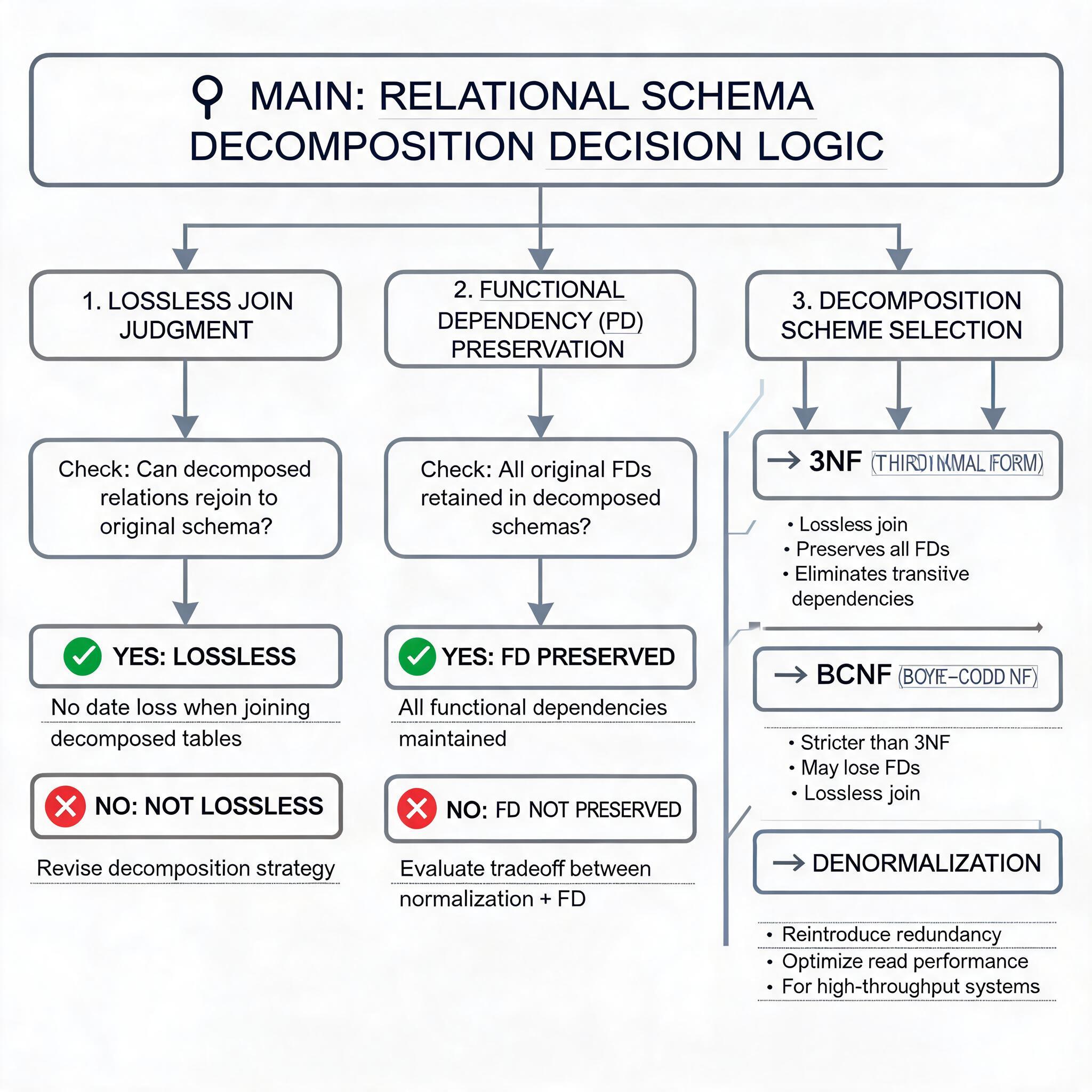 模式分解判定逻辑示意图
模式分解判定逻辑示意图
七、总结与软考备考建议
7.1 核心知识点提炼
- 函数依赖分为完全依赖、部分依赖、传递依赖三类,是规范化的基础
- Armstrong 公理包含 3 条基本规则和 3 条导出规则,是依赖推导的理论基础
- 候选码求解通过属性分类、闭包计算完成,重点掌握 L 类、N 类属性必然属于候选码的特性
- 四级范式逐级消除不同类型的依赖,3NF 和 BCNF 是考察重点
- 模式分解需同时满足无损连接和保持函数依赖两个核心目标
7.2 软考考试重点提示
- 高频考点:候选码求解、范式等级判定、模式分解无损性判断,占数据库考点分值的 40%,案例分析题常要求根据业务场景设计符合 3NF 的关系模式
- 易错点:BCNF 与 3NF 的区别、传递依赖的判定、多候选码场景下的主属性识别
- 答题技巧:先对属性分类求解候选码,再识别主属性和非主属性,依次判断是否存在部分依赖、传递依赖,逐步确定范式等级
7.3 实践应用建议
- 业务系统数据库设计优先采用 3NF,平衡冗余度和查询效率
- 高并发查询场景可通过反规范化冗余常用属性,配合数据同步机制保证一致性
- 核心交易系统可采用 BCNF,减少数据异常风险,配合缓存、读写分离提升性能。