HPA 基于 CPU/内存或自定义指标伸缩,但很多场景的负载并非由资源使用驱动,而是由外部事件触发:消息队列积压、定时任务到来、Kafka 主题的消息数量激增。KEDA(Kubernetes Event-Driven Autoscaler) 专门解决这类问题,它能够根据事件源(如 RabbitMQ、Kafka、Redis、AWS SQS)的指标驱动 Pod 伸缩,甚至支持缩容到 0。本文详细讲解 KEDA 的架构、核心概念、常用 Scaler 以及部署配置方法。
一、什么是 KEDA?
KEDA(Kubernetes Event-Driven Autoscaler)是一个 CNCF 毕业项目,它扩展了 Kubernetes 的自动伸缩能力,使 Pod 能够根据外部事件源的指标进行伸缩。KEDA 不是 HPA 的替代品,而是HPA 的补充和增强------它充当事件源与 HPA 之间的桥梁。
KEDA 的核心价值:
事件驱动:基于队列长度、消息积压、定时任务等外部事件伸缩。
支持缩容到 0:没有事件时,Pod 可以缩容到 0,极大节省资源。
丰富的 Scaler 生态:支持 50+ 内置 Scaler,覆盖 Kafka、RabbitMQ、Redis、AWS SQS、Azure Service Bus、Prometheus、Cron 等。
二、KEDA 架构与核心概念
2.1 核心组件
KEDA 由两个主要组件构成:
Agent:运行在每个节点上,负责激活和停用 HPA。
Metrics Server:提供外部指标给 HPA,使 HPA 能够基于事件源指标伸缩。
2.2 核心 CRD
CRD 作用
ScaledObject 定义伸缩目标(Deployment/StatefulSet)、触发器(Scaler)和伸缩策略
ScaledJob 类似 ScaledObject,但针对 Job 类型的工作负载
工作流程:
KEDA 从事件源(如 Kafka)拉取指标(如消息积压数量)。
KEDA 将这些指标转换为 HPA 可识别的格式,通过 Metrics Server 暴露。
HPA 根据指标计算期望副本数,并更新工作负载。
当没有事件时,KEDA 可将副本数缩容到 0。
三、安装 KEDA
3.1 使用 Helm 安装(推荐)
bash
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace3.2 验证安装
bash
kubectl get pods -n keda
kubectl get crd | grep keda四、常用 Scaler 配置示例
4.1 Kafka Scaler
根据 Kafka 主题的消息积压(lag)伸缩消费者 Pod。
前置条件:Kafka 集群已部署,消费者应用已就绪。
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-consumer-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kafka-consumer
minReplicaCount: 0 # 允许缩容到 0
maxReplicaCount: 10
triggers:
- type: kafka
metadata:
bootstrapServers: kafka-cluster:9092
consumerGroup: my-consumer-group
topic: my-topic
lagThreshold: "10" # 每个分区积压超过 10 条时扩容
partitionLagThreshold: "10"
offsetResetPolicy: latestlagThreshold:所有分区的总积压量阈值。
当积压超过 10 条时,KEDA 触发扩容;积压消除后缩容。
4.2 RabbitMQ Scaler
根据 RabbitMQ 队列长度伸缩消费者。
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: rabbitmq-consumer
minReplicaCount: 0
maxReplicaCount: 20
triggers:
- type: rabbitmq
metadata:
host: "amqp://guest:guest@rabbitmq.default.svc.cluster.local:5672"
queueName: my-queue
mode: QueueLength
value: "20" # 队列长度超过 20 时扩容4.3 AWS SQS Scaler
根据 SQS 队列的 ApproximateNumberOfMessages 伸缩。
yaml
triggers:
- type: aws-sqs-queue
metadata:
queueURL: "https://sqs.region.amazonaws.com/account-id/my-queue"
queueLength: "5"
awsRegion: "us-east-1"
identityOwner: "pod" # 使用 Pod 的 IAM 角色(IRSA)4.4 Cron Scaler(定时伸缩)
适用于有周期性流量峰值的场景。
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: cron
metadata:
timezone: Asia/Shanghai
start: "30 8 * * *" # 每天 8:30 扩容
end: "30 18 * * *" # 每天 18:30 缩容
desiredReplicas: "10"4.5 Prometheus Scaler
基于 Prometheus 中的任意自定义指标伸缩,是 HPA 自定义指标能力的补充。
yaml
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus.default:9090
metricName: http_requests_total
threshold: "100"
query: |
sum(rate(http_requests_total{app="my-app"}[2m]))五、缩容到 0 的注意事项
KEDA 支持将副本数缩容到 0,但需要满足以下条件:
minReplicaCount: 0。
工作负载类型支持 0 副本(Deployment 支持,StatefulSet 需谨慎)。
应用的启动时间不能太长(冷启动延迟会影响用户体验)。
缩容到 0 的典型场景:
消息队列消费者(没有消息时无需运行)。
定时任务(非调度时段无需运行)。
开发/测试环境(节省资源)。
六、KEDA 与 HPA 的关系
KEDA 不是替代 HPA,而是在 HPA 之上增加了一层事件驱动能力:
当使用 KEDA 的 ScaledObject 时,KEDA 会自动创建和管理对应的 HPA 资源。
用户无需手动创建 HPA,只需定义 ScaledObject。
KEDA 将事件源指标转换为 HPA 可消费的格式。
查看 KEDA 自动创建的 HPA:
bash
kubectl get hpa七、KEDA 最佳实践
合理设置阈值:阈值过低会导致频繁伸缩,过高则响应滞后。建议根据业务峰值和启动时间调优。
配置冷启动优化:如果应用启动较慢,考虑设置 cooldownPeriod 延长缩容等待时间。
监控 ScaledObject 状态:kubectl describe scaledobject 查看事件和状态。
选择合适的 Scaler:根据事件源类型选择官方支持的 Scaler,避免自行开发。
在测试环境验证:先在小规模集群验证伸缩行为,再部署到生产环境。
八、HPA、VPA、KEDA 三者对比
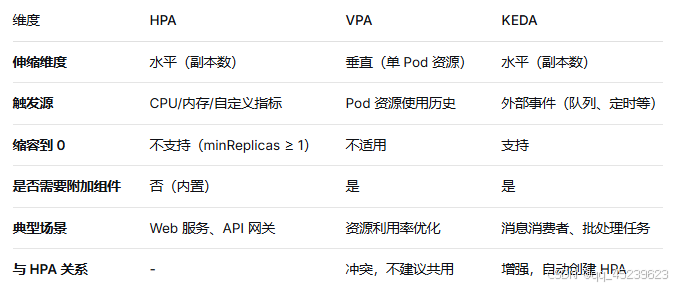
九、综合选型建议
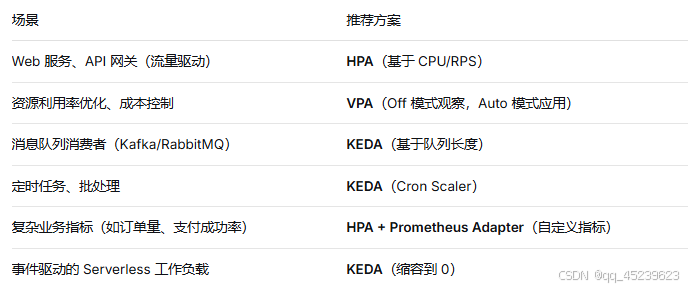
十、小结
KEDA 将 Kubernetes 的自动伸缩能力从"资源驱动"扩展到"事件驱动",让 Pod 能够根据消息队列积压、定时任务、外部系统事件等真实业务信号进行伸缩。它尤其适合消息消费者、批处理任务、事件驱动架构等场景,并支持缩容到 0,大幅降低闲置资源成本。HPA、VPA、KEDA 三者各有侧重,合理组合可以构建完整的自动伸缩体系。