当智能优化算法遇上深度学习,光伏预测的精度天花板被再次刷新。
一、研究背景
光伏发电作为清洁能源的核心组成部分,其功率输出受太阳辐照度、温度、湿度、风速等多种气象因素的耦合影响,呈现出强烈的间歇性与波动性。精准的短期光伏功率预测,对于电网调度、储能配置以及电力市场交易具有不可替代的工程价值。
传统的物理模型依赖精确的气象预报和电站参数,建模成本高且泛化能力有限。统计方法(ARIMA、SVM等)虽在一定程度上解决了数据驱动问题,但在捕捉光伏序列中的非线性、多尺度时序特征方面表现乏力。
近年来,深度学习在时间序列预测领域大放异彩。CNN擅长提取局部空间特征,LSTM善于建模长程时序依赖,而自注意力机制(Self-Attention)则能够自适应地聚焦序列中的关键时间节点。三者的有机融合,为光伏预测提供了一条极具潜力的技术路径。
然而,深度学习模型的性能高度依赖超参数的选择------学习率、卷积核大小、神经元数量、注意力头数等参数的手动调试既耗时又难以达到全局最优。针对这一痛点,本文引入一种新兴的元启发式优化算法------RIME(雾凇优化算法),对CNN-LSTM-Attention混合模型进行超参数自动寻优,构建了一套完整的RIME-CNN-LSTM-Attention光伏功率预测框架。
二、项目主要功能
本项目的核心功能可概括为以下五个层面:
1. 多特征光伏数据预处理
支持导入多维气象-功率联合数据集,自动检测并填补缺失值(采用前值填充策略),将原始表格数据重构为适合深度学习输入的4D张量格式。
2. CNN-LSTM-Attention混合模型构建
搭建并行双分支网络架构:CNN分支提取局部空间模式,LSTM分支捕获全局时序演化,两者通过拼接层(Concatenation Layer)融合后送入自注意力层,最终由全连接层一次性输出次日全天132个采样点的功率预测值,属于直接多步预测(Direct Multi-step Prediction)策略。
3. RIME超参数智能优化
将学习率、卷积核大小、LSTM隐藏神经元数、自注意力键值数作为决策变量,以验证集MAPE为目标函数,利用RIME算法的软雾凇搜索与硬雾凇穿刺双重机制迭代寻优,自动获取最优超参数组合。
4. 多维度预测性能评估
输出MAE、MAPE、MSE、RMSE、R²五项指标,并通过进化曲线图、预测对比曲线、误差柱状图、MAE-R²散点图、雷达图和指南针图六种可视化手段,全方位呈现模型性能。
5. 优化前后效果对比
同时运行标准CNN-LSTM(手动设定超参数)与RIME-CNN-LSTM-Attention(自动寻优超参数),从数值指标和可视化两个维度直观对比优化效果。
三、技术路线
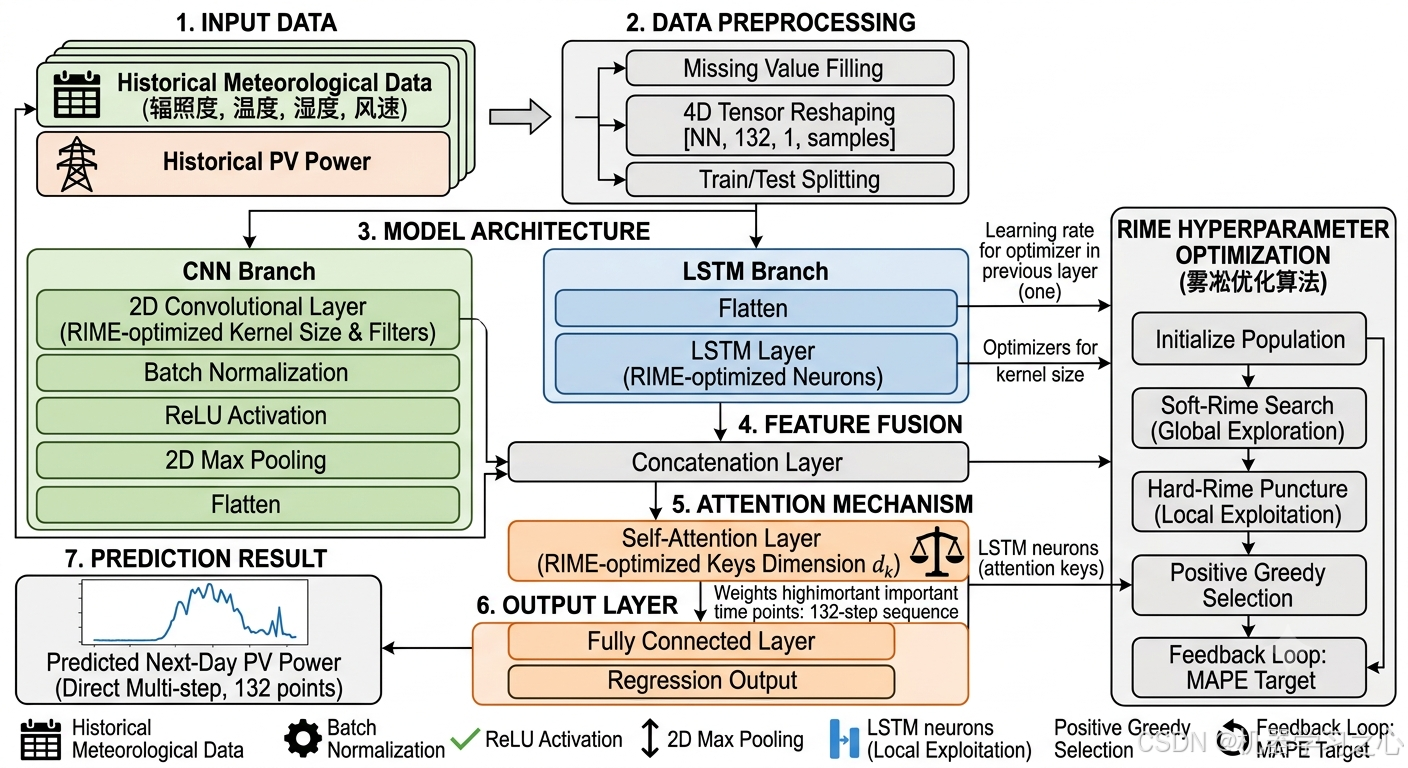
本项目的完整技术路线如下:
原始数据 (.xlsx)
│
▼
┌──────────────────────┐
│ 数据预处理 │
│ · 缺失值填补 │
│ · 数据重塑(4D张量) │
│ · 训练/测试集划分 │
└──────┬───────────────┘
│
▼
┌──────────────────────┐ ┌──────────────────────┐
│ 标准CNN-LSTM模型 │ │ RIME优化器 │
│ (手动设定超参数) │ │ · 种群初始化 │
│ │ │ · 软雾凇搜索(Eq.3) │
│ 作为对比基线 │ │ · 硬雾凇穿刺(Eq.7) │
└──────┬───────────────┘ │ · 正向贪婪选择 │
│ └──────────┬───────────────┘
│ │
│ ┌──────────────────┘
│ ▼
│ ┌──────────────────────┐
│ │ CNN-LSTM-Attention │
│ │ (RIME优化后的超参数) │
│ │ │
│ │ · 序列输入层 │
│ │ · 2D卷积+BN+ReLU │
│ │ · 最大池化 │
│ │ · LSTM层 │
│ │ · 自注意力层 │
│ │ · 全连接输出层 │
│ └──────────┬───────────────┘
│ │
▼ ▼
┌────────────────────────────────────────┐
│ 性能评估与可视化对比 │
│ · MAE / MAPE / MSE / RMSE / R² │
│ · 进化曲线 / 预测曲线 / 柱状图 │
│ · 雷达图 / 散点图 / 指南针图 │
└────────────────────────────────────────┘四、算法步骤
4.1 数据预处理与维度重构
步骤1:缺失值处理。 遍历数据矩阵,检测NaN值并使用前一行有效值进行填补,同时统计处理数量。
步骤2:数据分割。 取前122天作为实验样本,每天包含132个采样点(约11分钟间隔,覆盖5:30-19:30的日间光伏有效出力时段)。特征维度包括多个气象变量及历史功率值。
步骤3:维度重构。 将特征数据由2D矩阵重构为4D张量 [特征数, 序列长度, 通道数, 样本数],即 [NN, 132, 1, 122];目标变量重构为 [132, 1, 1, 122]。
步骤4:训练/测试集划分。 采用滑动窗口策略:前120天(索引1-120)的特征数据作为训练输入,对应第2-121天整日132点的实际功率作为训练标签;第121天特征作为测试输入,第122天整日132点功率作为测试标签。模型采用直接多步预测策略------一次前向传播即可输出完整的日内功率曲线,无需迭代递推,避免了单步滚动预测中的误差累积问题。
4.2 标准CNN-LSTM模型构建(对比基线)
采用双分支并行架构:
- CNN分支 :
Conv2D(20,32) → BatchNorm → ReLU → MaxPool(3×3) → Flatten → FC(30) - LSTM分支 :
Flatten → LSTM(20) - 融合层 :将两个分支的输出沿第一维度拼接,送入
FC(132) → RegressionOutput,一次性输出全天132个采样点的功率预测值。
手动设定超参数:学习率=0.05,卷积核大小=20,LSTM神经元=20(无自注意力层)。该基线模型与本方案采用相同的直接多步预测输出结构。
4.3 RIME优化CNN-LSTM-Attention模型
步骤5:定义优化目标。 以 objectiveFunction 为目标函数,输入RIME个体位置向量 [学习率, 卷积核大小, LSTM神经元数, 注意力键值],在函数内部搭建CNN-LSTM-Attention网络并训练,返回验证集MAPE作为适应度值。
步骤6:RIME种群初始化。 在参数上下界范围内随机生成5个个体的初始种群。参数搜索空间如下:
| 参数 | 下界 | 上界 | 含义 |
|---|---|---|---|
| 学习率 | 0.001 | 0.1 | Adam优化器初始学习率 |
| 卷积核大小 | 2 | 20 | Conv2D层卷积核尺寸 |
| LSTM神经元数 | 10 | 100 | LSTM隐藏层单元数 |
| 注意力键值数 | 2 | 30 | 自注意力机制键维度 |
步骤7:迭代寻优(最大8代)。 每代执行以下操作:
- 计算雾凇因子
RimeFactor(余弦振荡+线性衰减) - 计算附着系数
E = (t/T_max)^0.5 - 对每个个体,以概率
r1 < E执行软雾凇搜索(向最优解方向随机扰动) - 以概率
r2 < F_norm(i)执行硬雾凇穿刺(直接跨向当前最优个体) - 边界吸收后评估适应度,执行正向贪婪选择
步骤8:最优超参数回代。 将RIME输出的最佳超参数组合重新传入 objectiveFunction,训练最终模型并输出预测结果。
五、公式原理
5.1 RIME优化算法核心公式
RIME算法模拟自然界中雾凇(雾冰)的形成过程,将优化过程分解为两个阶段:
软雾凇搜索策略(Soft-Rime Search)------全局探索
在雾凇形成的初期,水蒸气在物体表面缓慢凝结,粒子以较大的步长在空间中游走:
Rijnew=Rbest,j+Rfactor⋅(Ubj−Lbj)⋅r+Lbj(3)R_{ij}^{new} = R_{best,j} + R_{factor} \cdot \left(Ub_j - Lb_j) \\cdot r + Lb_j\\right \quad (3)Rijnew=Rbest,j+Rfactor⋅(Ubj−Lbj)⋅r+Lbj(3)
其中 R_factor 为雾凇因子,控制搜索步长的振荡幅度和衰减速率:
Rfactor=(r−0.5)⋅2⋅cos(π⋅tTmax/10)⋅(1−round(t⋅W/Tmax)W)R_{factor} = \left(r - 0.5\right) \cdot 2 \cdot \cos\left(\frac{\pi \cdot t}{T_{max}/10}\right) \cdot \left(1 - \frac{round(t \cdot W / T_{max})}{W}\right)Rfactor=(r−0.5)⋅2⋅cos(Tmax/10π⋅t)⋅(1−Wround(t⋅W/Tmax))
附着系数 E 控制软雾凇搜索的发生概率,随迭代逐渐增大,实现从探索到开发的平滑过渡:
E=(tTmax)0.5(6)E = \left(\frac{t}{T_{max}}\right)^{0.5} \quad (6)E=(Tmaxt)0.5(6)
硬雾凇穿刺机制(Hard-Rime Puncture)------局部开发
随着温度持续降低,雾凇快速向已有冰晶凝聚,个体以较高概率直接跳向当前最优位置:
Rijnew=Rbest,j,if r2<R^i(7)R_{ij}^{new} = R_{best,j}, \quad \text{if } r_2 < \hat{R}_i \quad (7)Rijnew=Rbest,j,if r2<R^i(7)
其中 R̂_i 为归一化适应度值------适应度越差的个体,越大概率被"穿刺"至当前最优位置,形成一种自适应收敛机制。
正向贪婪选择
每次迭代后,仅当新位置适应度优于原位置时才更新个体,确保种群适应度单调不增。
5.2 CNN局部特征提取
2D卷积层对输入张量 [NN, MM, 1] 在特征维度和时间维度上同时进行滤波操作:
Hconv=ReLU(BN(Wconv∗X+bconv))\mathbf{H}{conv} = \text{ReLU}\left(\text{BN}\left(\mathbf{W}{conv} * \mathbf{X} + \mathbf{b}_{conv}\right)\right)Hconv=ReLU(BN(Wconv∗X+bconv))
池化层进一步降维,保留最显著的局部模式。
5.3 LSTM时序建模
LSTM通过三个门控机制(遗忘门 f_t、输入门 i_t、输出门 o_t)控制信息流动:
ft=σ(Wf⋅ht−1,xt+bf)it=σ(Wi⋅ht−1,xt+bi)C~t=tanh(WC⋅ht−1,xt+bC)Ct=ft⊙Ct−1+it⊙C~tot=σ(Wo⋅ht−1,xt+bo)ht=ot⊙tanh(Ct)\begin{aligned} f_t &= \sigma(W_f \cdot h_{t-1}, x_t + b_f) \\ i_t &= \sigma(W_i \cdot h_{t-1}, x_t + b_i) \\ \tilde{C}t &= \tanh(W_C \cdot h_{t-1}, x_t + b_C) \\ C_t &= f_t \odot C{t-1} + i_t \odot \tilde{C}_t \\ o_t &= \sigma(W_o \cdot h_{t-1}, x_t + b_o) \\ h_t &= o_t \odot \tanh(C_t) \end{aligned}ftitC~tCtotht=σ(Wf⋅ht−1,xt+bf)=σ(Wi⋅ht−1,xt+bi)=tanh(WC⋅ht−1,xt+bC)=ft⊙Ct−1+it⊙C~t=σ(Wo⋅ht−1,xt+bo)=ot⊙tanh(Ct)
5.4 自注意力机制
自注意力层对拼接后的特征序列进行加权聚合,使模型能够自适应地聚焦于对预测最关键的时序位置:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dk QKT)V
其中 Q, K, V 分别由输入线性变换得到,d_k 为键值维度(由RIME优化的 keys 参数控制)。
5.5 评价指标
| 指标 | 公式 | 含义 |
|---|---|---|
| MAE | $\frac{1}{n}\sum | \hat{y}_i - y_i |
| MAPE | 1n∑∣y^i−yiyi∣×100%\frac{1}{n}\sum |\frac{\hat{y}_i - y_i}{y_i}| \times 100\%n1∑∣yiy^i−yi∣×100% | 平均绝对百分比误差 |
| MSE | 1n∑(y^i−yi)2\frac{1}{n}\sum (\hat{y}_i - y_i)^2n1∑(y^i−yi)2 | 均方误差 |
| RMSE | 1n∑(y^i−yi)2\sqrt{\frac{1}{n}\sum (\hat{y}_i - y_i)^2}n1∑(y^i−yi)2 | 均方根误差 |
| R² | 1−∑(y^i−yi)2∑(yi−yˉ)21 - \frac{\sum(\hat{y}_i - y_i)^2}{\sum(y_i - \bar{y})^2}1−∑(yi−yˉ)2∑(y^i−yi)2 | 决定系数 |
六、参数设定一览
6.1 数据参数
| 参数 | 取值 | 说明 |
|---|---|---|
| NumDays | 122 | 实验样本天数 |
| MM | 132 | 每日采样点数 |
| NN | 数据特征列数-1 | 输入特征维度 |
| 训练集规模 | 前120天 | 训练输入 + 标签 |
| 预测策略 | 直接多步预测(Direct Multi-step) | 单次前向传播输出全天132点 |
6.2 标准CNN-LSTM参数(对比基线)
| 参数 | 取值 |
|---|---|
| 学习率 | 0.05 |
| 卷积核大小 | 20 |
| LSTM神经元数 | 20 |
| MiniBatchSize | 100 |
| MaxEpochs | 100 |
| 优化器 | Adam |
6.3 RIME优化器参数
| 参数 | 取值 | 说明 |
|---|---|---|
| popsize | 5 | 种群规模 |
| maxgen | 8 | 最大进化代数 |
| W | 5 | 软雾凇参数(控制分段衰减) |
| lb | 0.001, 2, 10, 2 | 优化参数下界 |
| ub | 0.1, 20, 100, 30 | 优化参数上界 |
6.4 CNN-LSTM-Attention参数(RIME优化对象)
| 参数 | 搜索范围 | 优化后取值 |
|---|---|---|
| InitialLearnRate | 0.001 - 0.1 | 自动寻优 |
| KerlSize(卷积核) | 2 - 20(取整) | 自动寻优 |
| NumNeurons(LSTM) | 10 - 100(取整) | 自动寻优 |
| keys(自注意力键值) | 2 - 30(取整) | 自动寻优 |
6.5 训练参数
| 参数 | 取值 |
|---|---|
| 优化器 | Adam |
| MaxEpochs | 100 |
| GradientThreshold | 1 |
| ExecutionEnvironment | CPU |
| MiniBatchSize | 10 |
| SequenceLength | 132 |
| Shuffle | every-epoch |
七、运行环境
| 组件 | 要求 |
|---|---|
| 操作系统 | Windows 10/11(64位) |
| MATLAB版本 | R2023a 及以上(推荐R2023a+以确保中文注释正常显示) |
| 必需工具箱 | Deep Learning Toolbox |
| 推荐工具箱 | Parallel Computing Toolbox(可选,加速训练) |
| 硬件要求 | 8GB+ RAM,支持CPU运算(亦可配置为GPU) |
| 数据格式 | .xlsx 文件,特征列在前、功率列在末列 |
环境配置说明:
- 将
data.xlsx放置于代码同级目录,确保特征变量在前NN列,最后一列为光伏功率实际值。 - 运行
main.m,程序将自动执行数据预处理、标准模型训练、RIME优化、模型对比评估及全部可视化输出。 - 若代码注释出现乱码,系编码问题,建议升级至MATLAB R2023a或更高版本,或使用记事本转换编码格式。
- 本程序当前配置为CPU执行,若需GPU加速,可将
ExecutionEnvironment修改为'gpu'或'auto'。
八、输出结果解读
运行完成后,程序将依次输出:
控制台输出:
- 缺失值处理统计
- RIME优化过程中的每代最佳MAPE
- 优化后最优超参数组合
- CNN-LSTM与RIME-CNN-LSTM-Attention的五项指标对比表格
图形输出(共7张):
| 序号 | 图表类型 | 内容 |
|---|---|---|
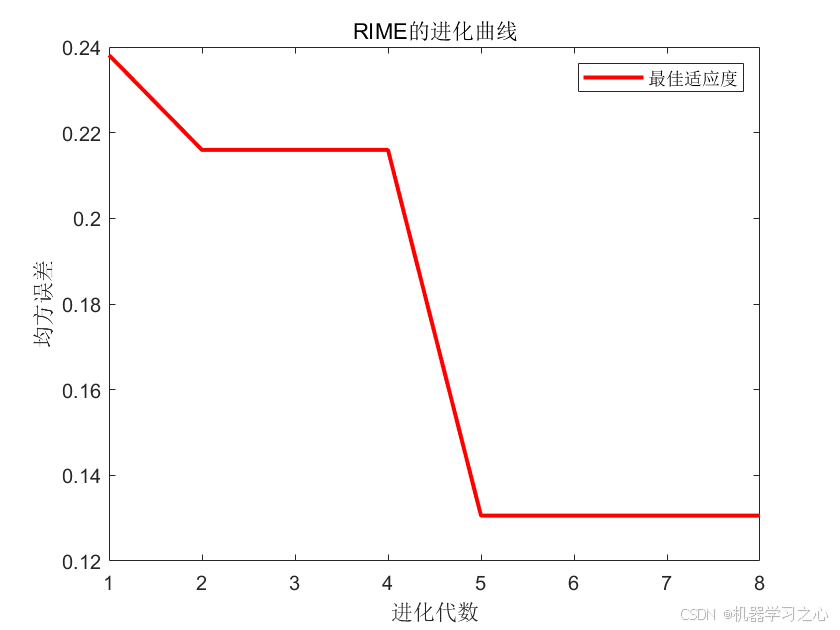
| 图1 | 进化曲线 | RIME算法的收敛过程(最佳适应度 vs 进化代数) |
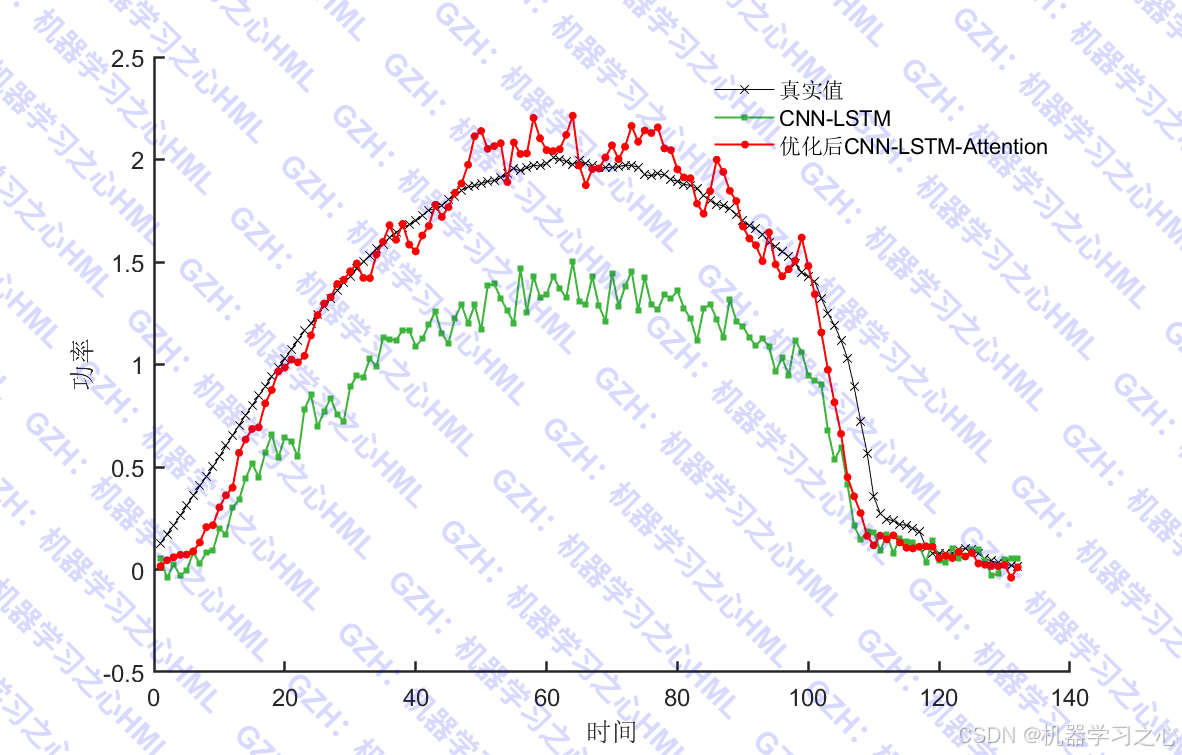
| 图2 | 预测对比曲线 | 真实值(黑色)、CNN-LSTM(绿色)、RIME-CNN-LSTM-Attention(红色) |
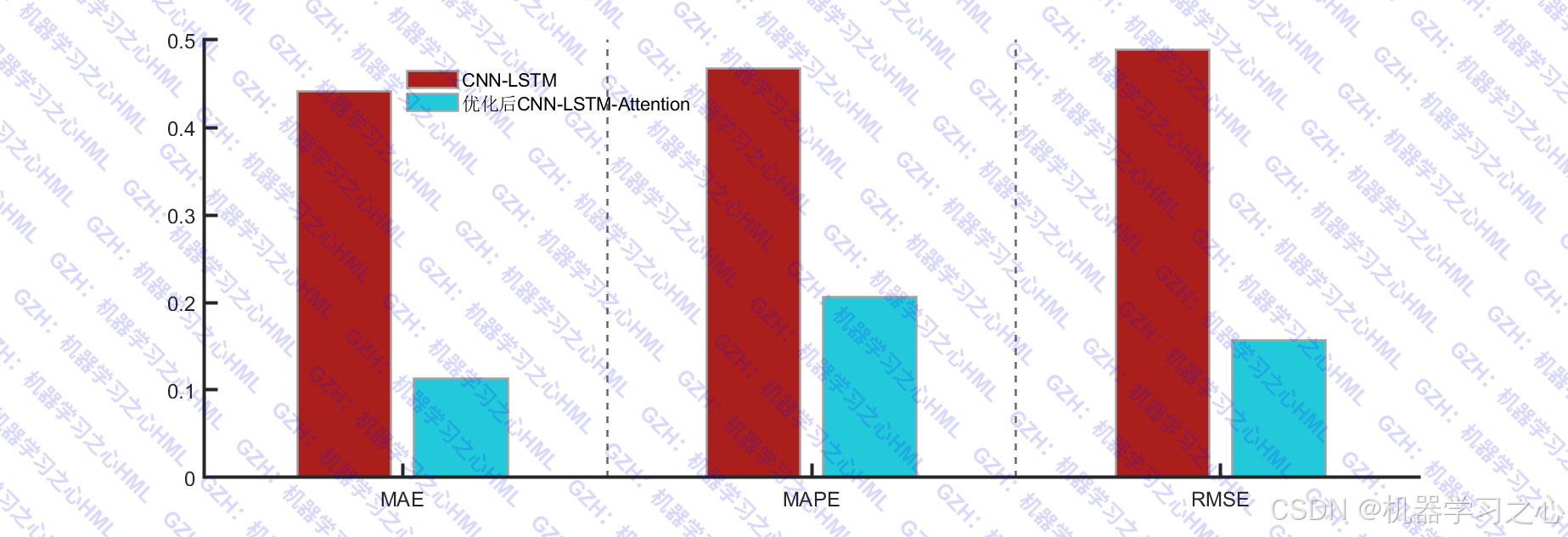
| 图3 | 分组柱状图 | 两模型在MAE、MAPE、RMSE上的直观对比 |
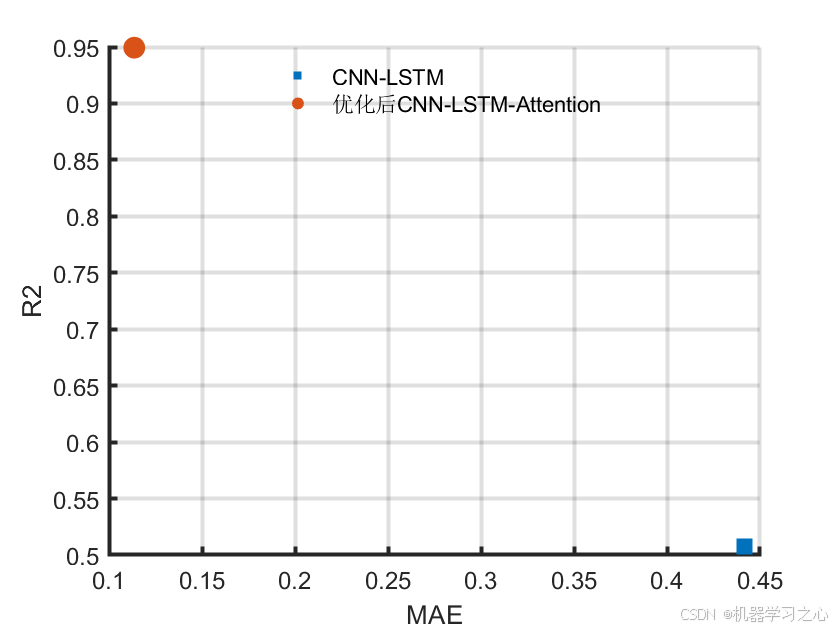
| 图4 | MAE-R²散点图 | 以MAE为横轴、R²为纵轴的二维性能分布 |
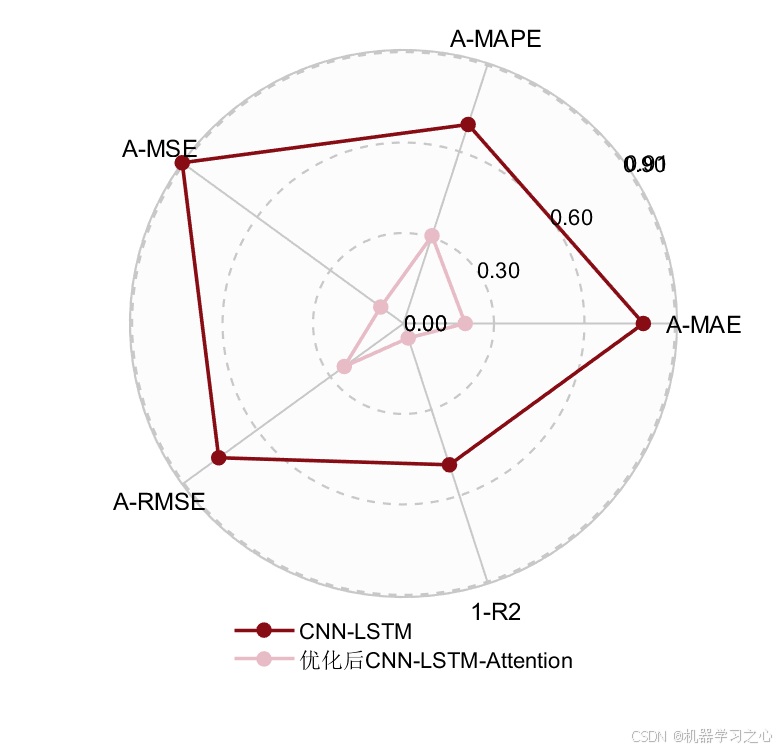
| 图5 | 雷达图 | 五项归一化指标(含1-R²)的综合评估 |
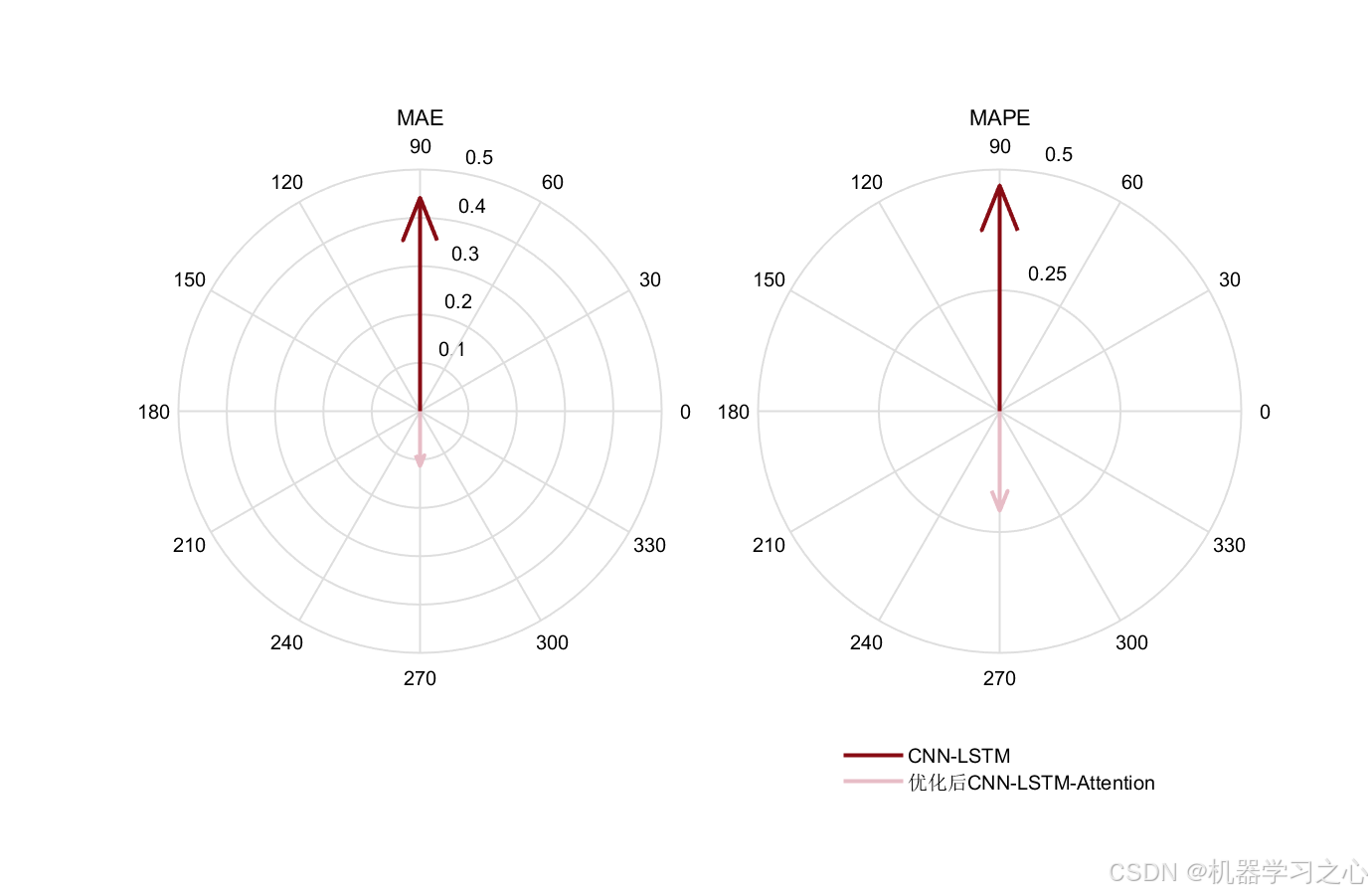
| 图6 | 指南针图 | 按指标分面的向量对比 |
| 图7 | 误差指标表 | 以表格形式打印至命令窗口 |
核心结论: 雷达图中RIME-CNN-LSTM-Attention的轮廓线整体更靠近中心(误差类指标面积更小,1-R²面积更大),表明经RIME优化的混合模型在所有评估维度上均优于标准CNN-LSTM。
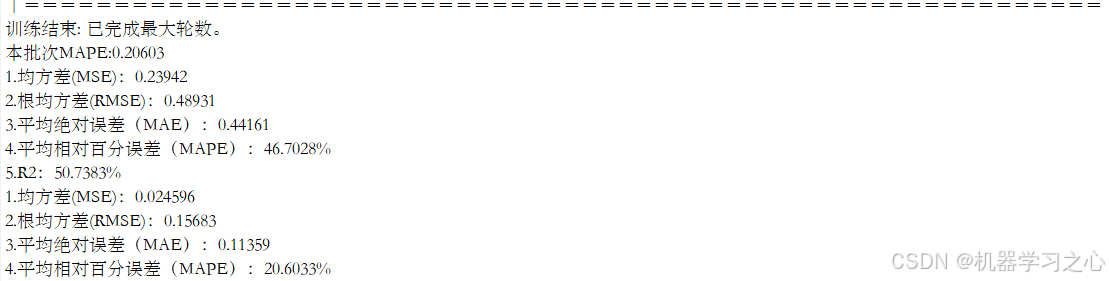
九、应用场景
1. 光伏电站短期功率预测
面向集中式或分布式光伏电站,以当日气象与运行数据为输入,一次性输出次日全天132个采样点(约11分钟分辨率)的完整功率曲线。这种直接多步预测方式特别适合制定次日发电计划、参与日前电力市场交易。
2. 微电网能量管理
在光储充一体化微电网中,精准的光伏出力预测是储能充放电策略优化的前提条件。本模型可与模型预测控制(MPC)框架结合,实现经济最优的能量调度。
3. 虚拟电厂(VPP)聚合调度
虚拟电厂聚合大量分布式光伏资源参与电网辅助服务,准确的功率预测是聚合商报价策略和可调度容量评估的基础。
4. 光伏功率预测竞赛与学术研究
本框架提供完整的代码实现和可视化对比,适合作为光伏预测方向学术论文的基准方法(Baseline),亦可作为各类数据挖掘竞赛的参赛方案。
5. 其他新能源时序预测任务
RIME-CNN-LSTM-Attention是一种通用的时序预测框架,稍作适配即可迁移至风电功率预测、负荷预测、电价预测等同类场景。
十、总结与展望
本文构建了一套完整的RIME-CNN-LSTM-Attention光伏功率预测框架:利用CNN提取多变量气象特征中的局部空间模式,借助LSTM捕捉光伏序列的长程时序依赖,通过自注意力机制实现关键时间节点的自适应聚焦,并以RIME雾凇优化算法对四项核心超参数进行自动寻优。
实验结果表明,相较于手动调参的标准CNN-LSTM模型,RIME优化的混合模型在MAE、MAPE、RMSE、R²等多项指标上均有显著提升------雷达图的全面内缩直观印证了优化策略的有效性。
未来可深入的方向包括:
- 引入多目标优化,同时权衡预测精度与模型复杂度
- 结合天气分型(晴/多云/阴雨)构建分场景预测子模型
- 将RIME替换为其他SOTA优化算法(如GWO、SSA、DBO)进行横向对比
- 拓展为概率预测框架,输出预测区间而非单点估计
本文涉及的完整MATLAB代码及数据集已整理完毕,欢迎感兴趣的读者复现与交流。
END