一、深度学习的兴衰

1. 1958:感知机 Perceptron(第一次兴起)
- 核心:单层感知机,线性模型,人类第一个模仿人脑神经元的机器学习模型,能做简单二分类。
- 意义:神经网络的起点,当时学界非常看好,迎来第一次热潮。
2. 1969:感知机存在致命局限(第一次寒冬,红色低谷)
Minsky 出版《Perceptrons》,严格数学证明: 单层感知机无法解决异或 XOR 这类非线性可分问题,模型表达能力极弱。 直接导致政府、企业停止对神经网络的资金投入,神经网络进入十几年沉寂期。
3. 1980 年代:多层感知机 MLP(第二次复苏)
人们提出多层感知机(含隐藏层),结构和现在的深度神经网络 DNN 本质框架几乎一致:
Do not have significant difference from DNN today 翻译:和如今的深度神经网络没有本质区别。 多层结构理论上能拟合任意复杂函数,解决了单层感知机的表达缺陷,神经网络重新回到视野。
4. 1986:反向传播 Backpropagation(BP 算法,关键突破)
Hinton 等人正式完善反向传播训练算法,解决多层网络权重怎么更新、怎么训练的核心问题,多层网络终于能落地训练。 但当时有巨大瓶颈:
Usually more than 3 hidden layers is not helpful 翻译:超过 3 层隐藏层的网络基本没有效果。 原因:没有好的权重初始化方案,深层网络训练会出现梯度消失,深层参数无法更新,训不动。
5. 1989:单隐藏层就够用,为什么要做深度?(第二次寒冬,红色质疑)
通用逼近定理证明:只要 1 层足够宽的隐藏层,就能拟合任意连续函数。 当时所有人产生疑问:既然单层就能搞定所有任务,费力堆叠多层网络有什么意义? 再加深层梯度消失、算力不足,神经网络再次遇冷,统计学、SVM 等算法占据主流近 20 年。
6. 2006:RBM 预训练初始化(突破性转机,第二次复兴起点)
Hinton 提出受限玻尔兹曼机 RBM 逐层无监督预训练: 先一层一层无监督初始化网络权重,再用 BP 微调,完美缓解深层网络梯度消失问题,真正让 "深度网络" 能稳定训练,是现代深度学习正式诞生的标志性突破。
7. 2009:GPU 算力普及(工程落地基础)
用图形显卡 GPU 并行加速神经网络计算,解决深度模型巨大矩阵运算的算力瓶颈,原本需要几周的训练缩短到几天,深度学习具备大规模实验条件。
8. 2011:深度学习在语音识别领域大规模流行
微软、谷歌将深度网络应用语音识别,错误率大幅下降,工业界首次大规模落地深度学习技术。
9. 2012:AlexNet 夺得 ILSVRC 图像竞赛冠军(深度学习全面爆发)
AlexNet 深度卷积神经网络,在 ImageNet 图像分类比赛上准确率碾压传统算法,错误率直接降低近一半,震惊计算机视觉领域。 自此深度学习席卷 CV、语音、NLP 所有 AI 赛道,开启至今的人工智能大时代。
二、Three Steps for Deep Learning
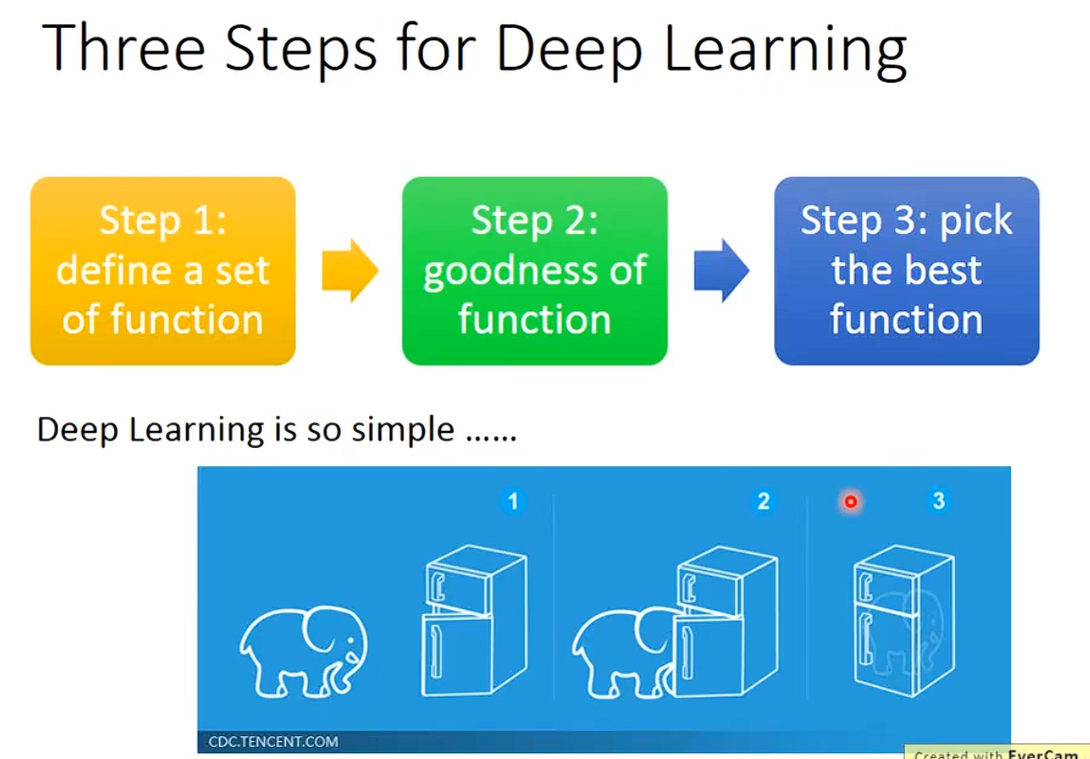
Step 1:
define a setof function
用大量的Neural network进行连接,不同的连接方式出现不同的function
最常见的是全连接前馈传播网络
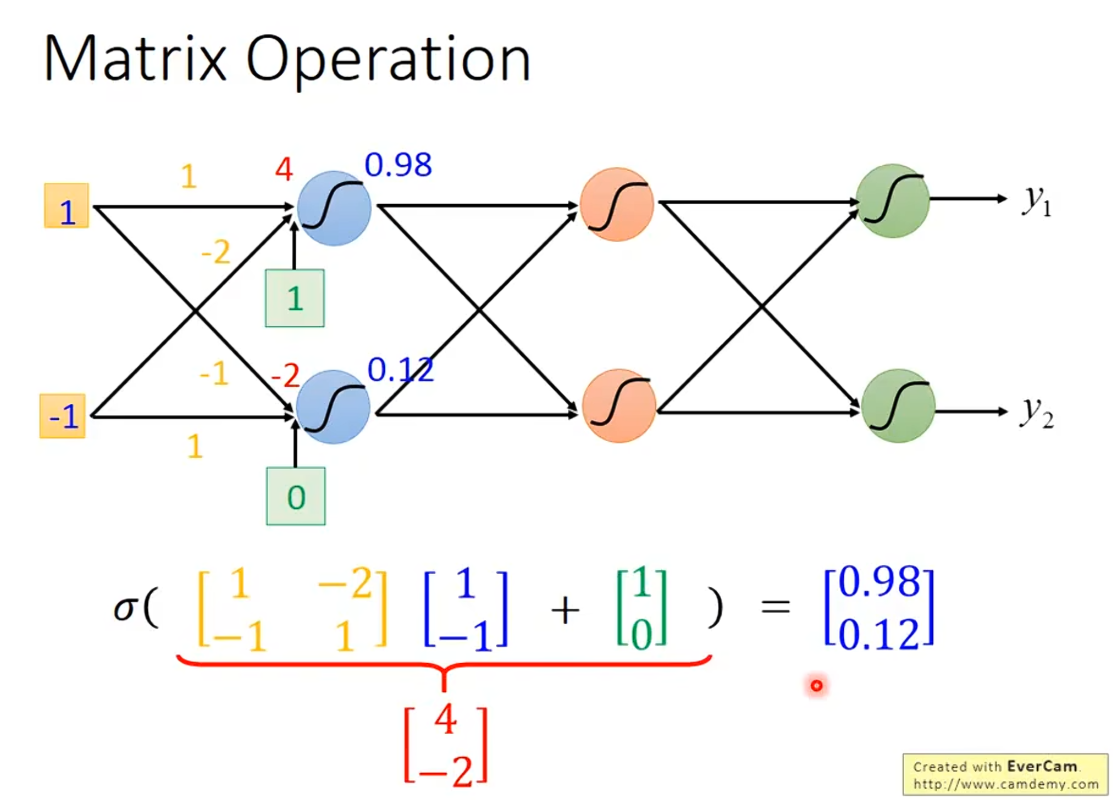
neuron:神经元,每一个带颜色的圆就是一个neuron
Bias:偏置值,绿色框
圈内 S 曲线Sigmoid Activation FunctionSigmoid 激活函数
左右连线数字Weight value (Connection Weight)连接权重值
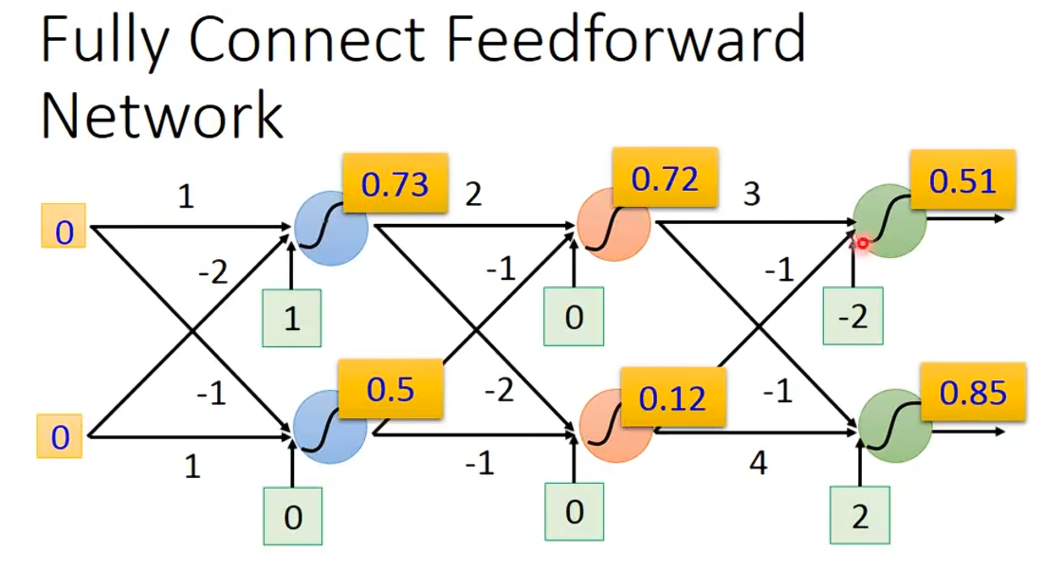
0x1 +0x(-2) + 1 = 1 得出来的数字就是e的负次方数 σ(1)=1/(1+e^(-1))≈0.73
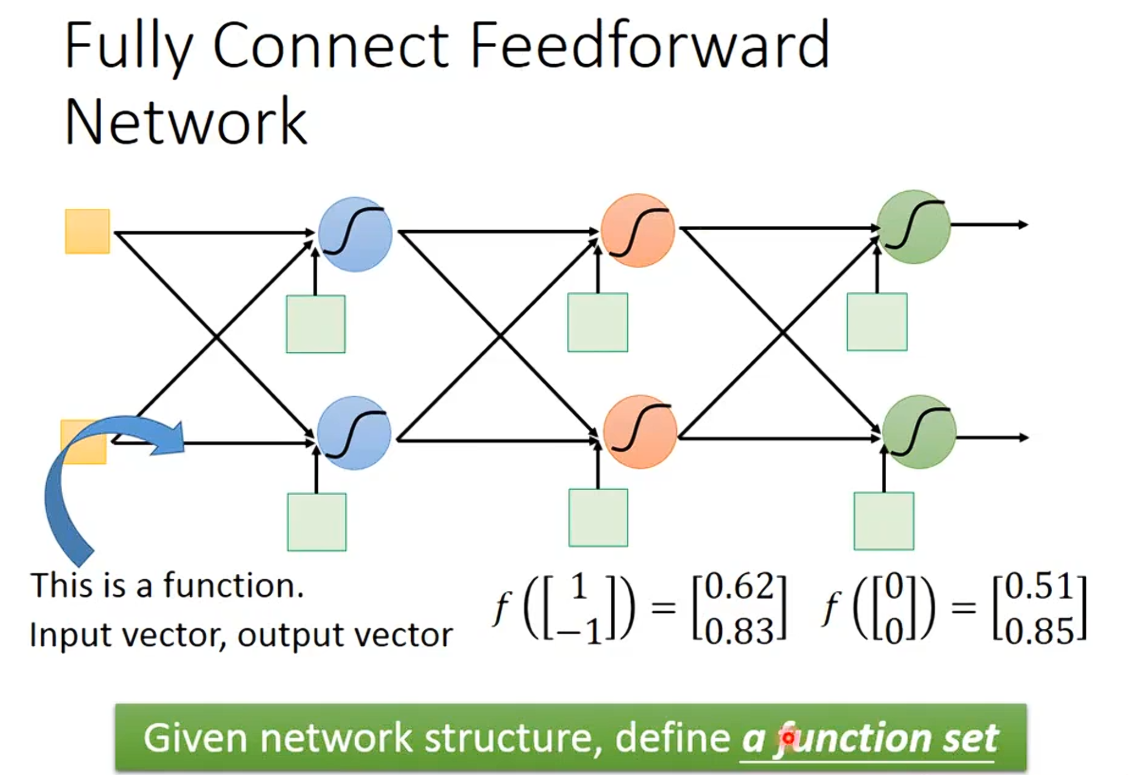
不同的参数的就是不同的function,如果没有参数,就是一个function set
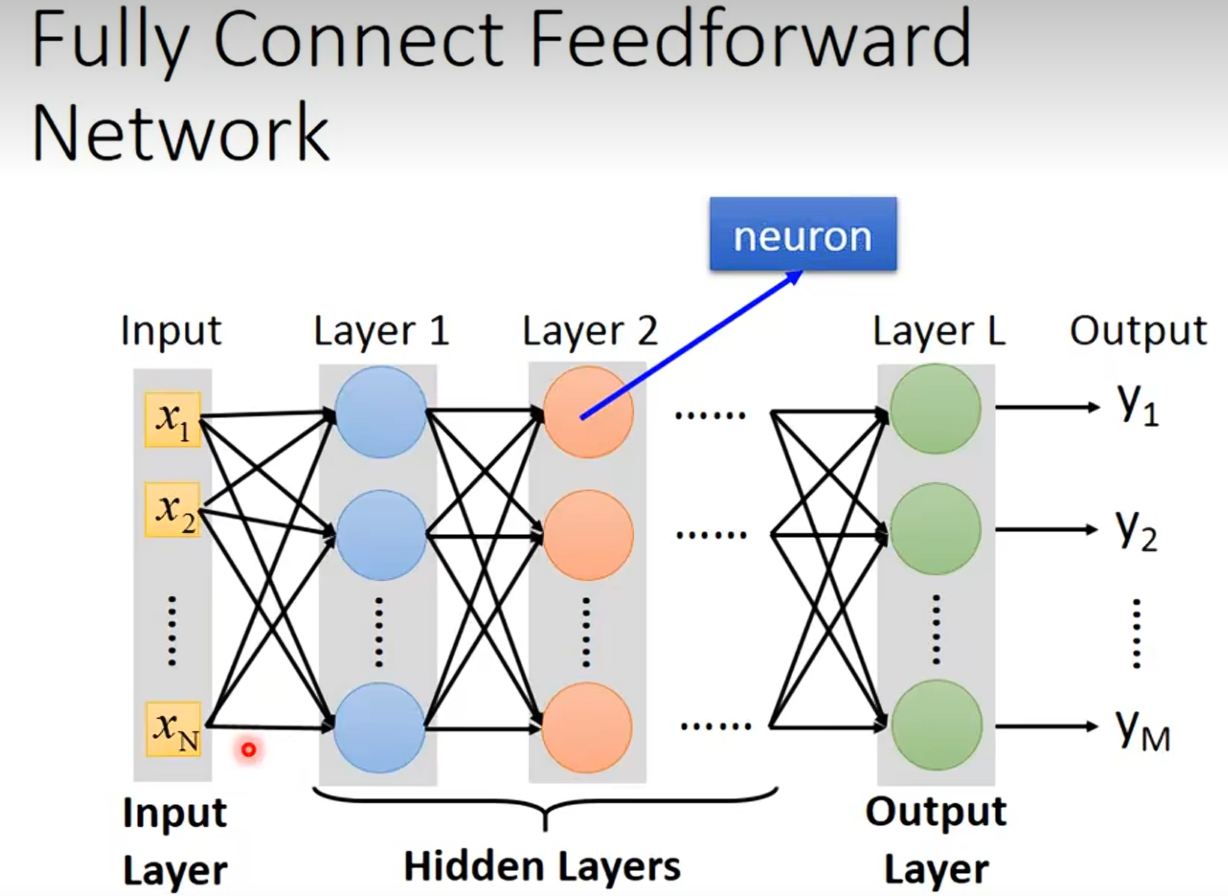
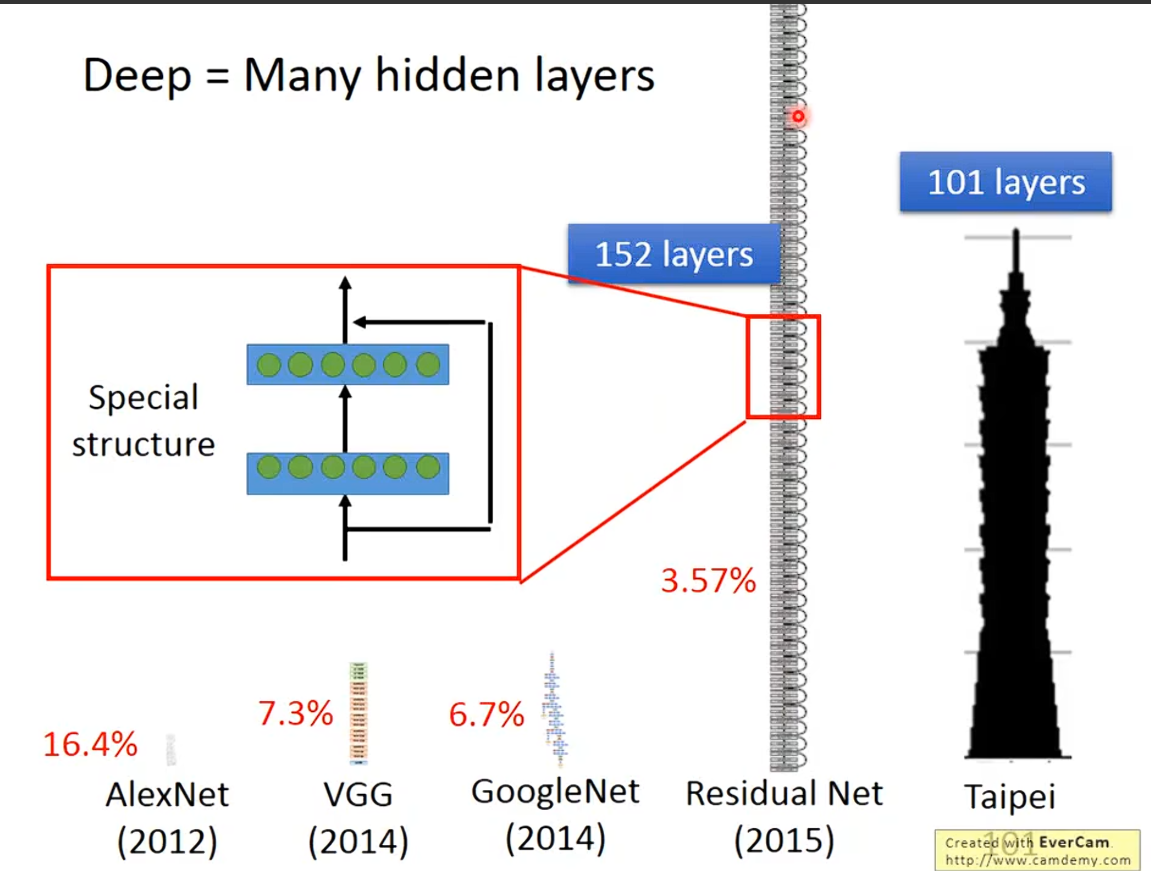
deep:就是很多层的layer
error rate:错误率 数值越低,图像识别精度越高。
写成矩阵运算的形式
把weight和bias,input,output,layers也写成矩阵的形式
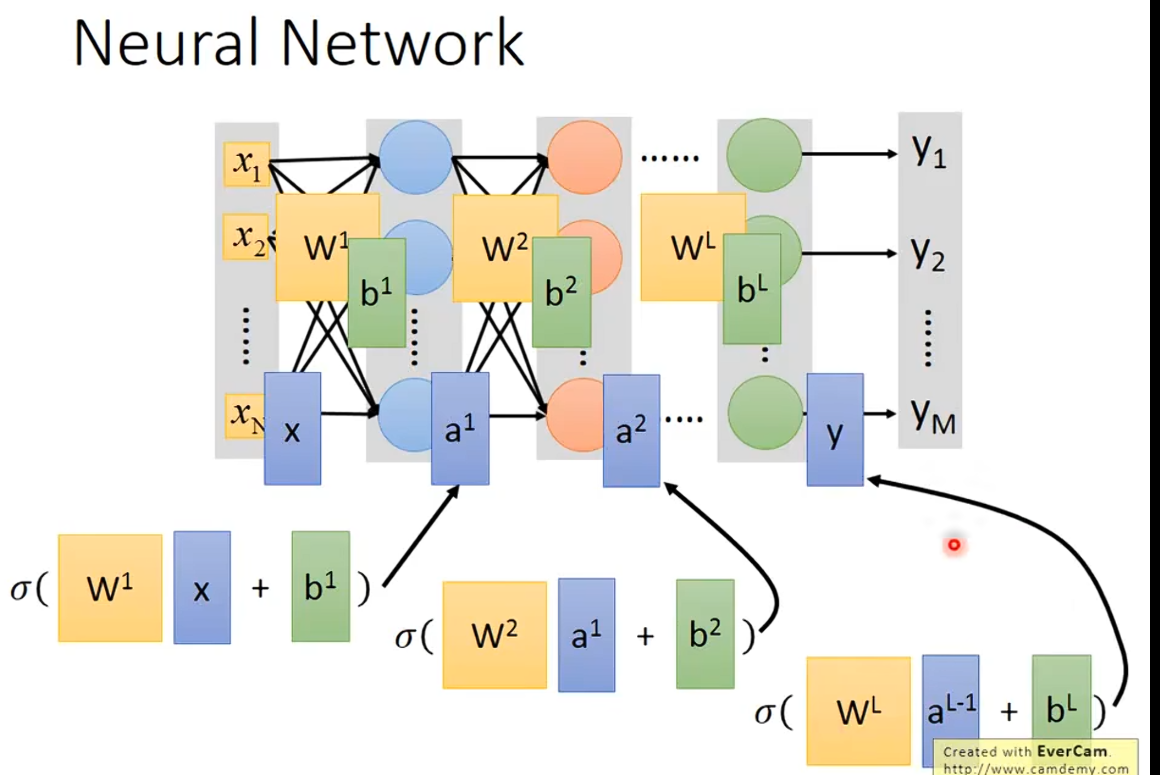
一层套一层,把前面的数据算出来后,用到后面
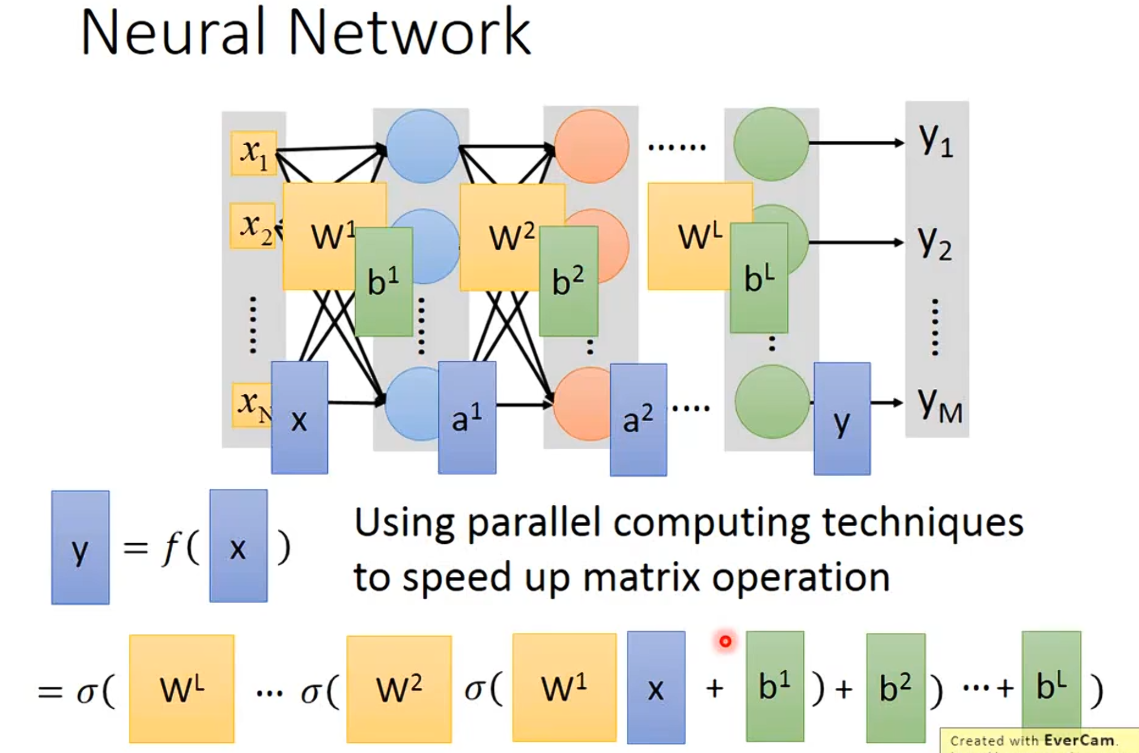
为什么写成矩阵的形式?GPU计算矩阵更快
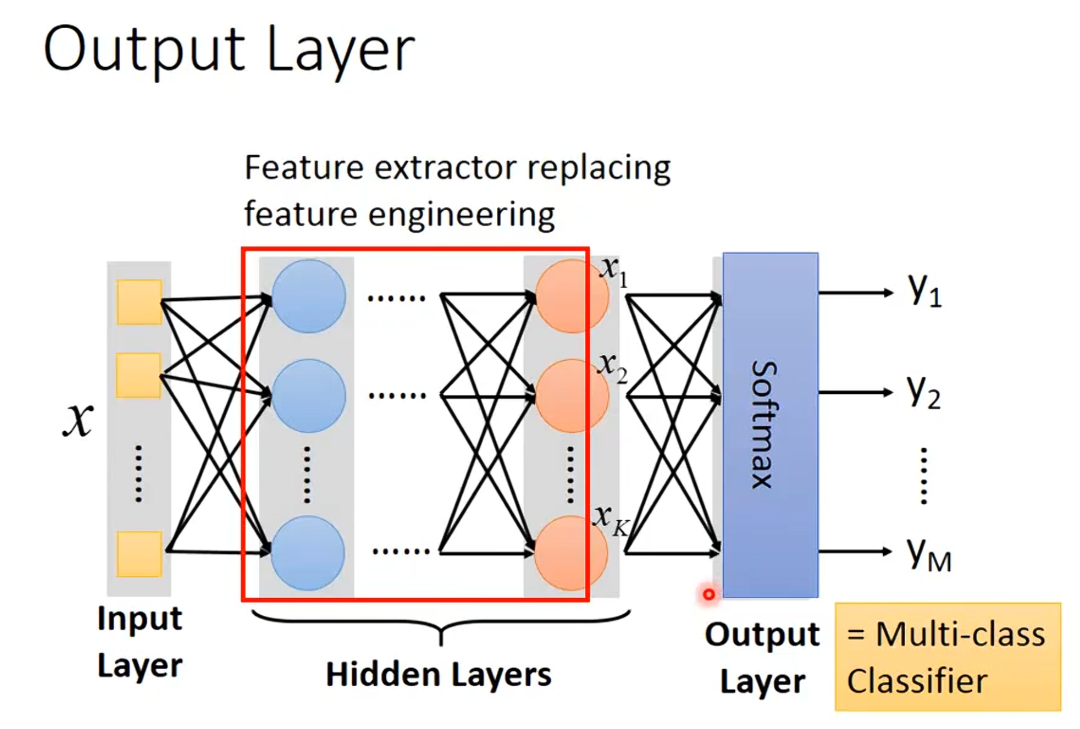
Feature extractor replacing feature engineering
翻译:特征提取器,替代人工特征工程
- Feature engineering 人工特征工程 传统机器学习(SVM、逻辑回归等)必须靠人手动设计、挑选、加工有用特征,人要先想哪些信息有用,再写代码提取,很费时、依赖专家经验。
- Feature extractor 自动特征提取器 神经网络的多层隐藏层可以自动从原始数据里逐层提炼有效特征 ,不用人工设计特征,这是深度学习最核心优势。
- 浅层隐藏层:提取简单基础特征(边缘、线条、基础纹理)
- 深层隐藏层:组合成复杂高级特征(轮廓、局部部件、整体语义
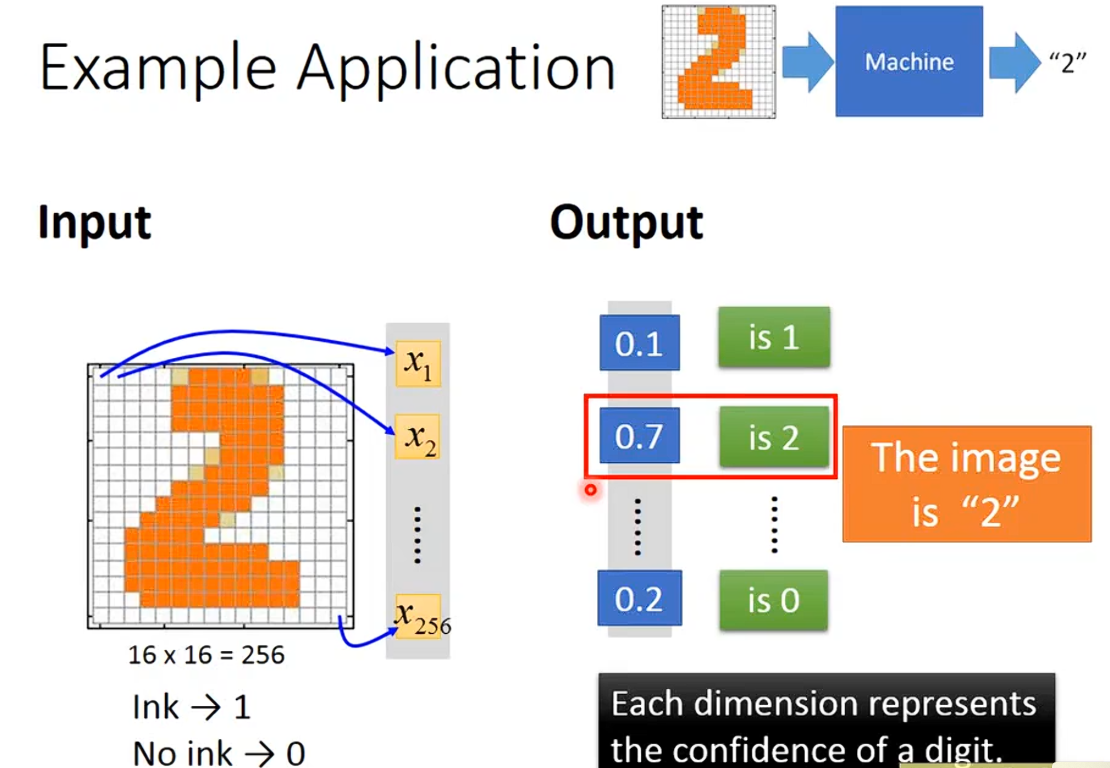
案例举例
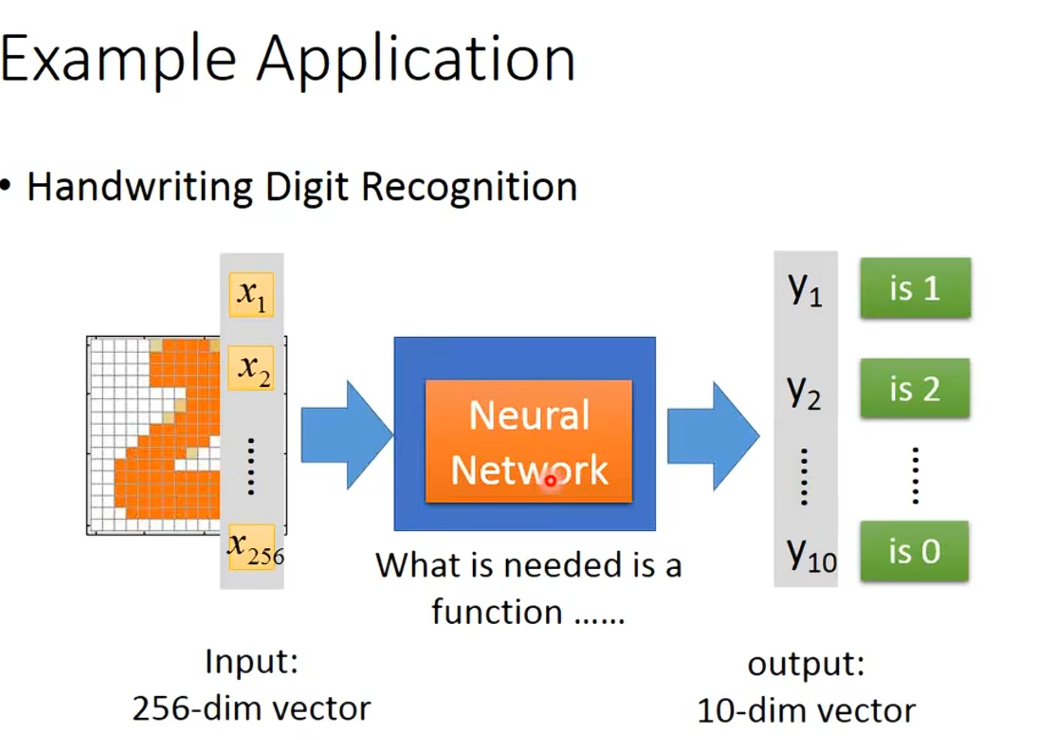
怎么确定多少层layer和多少neurons? 直觉+经验+训练
Step 2:goodness of function
定义function的好坏
看看得到的结果和目标的差距 Loss损失函数
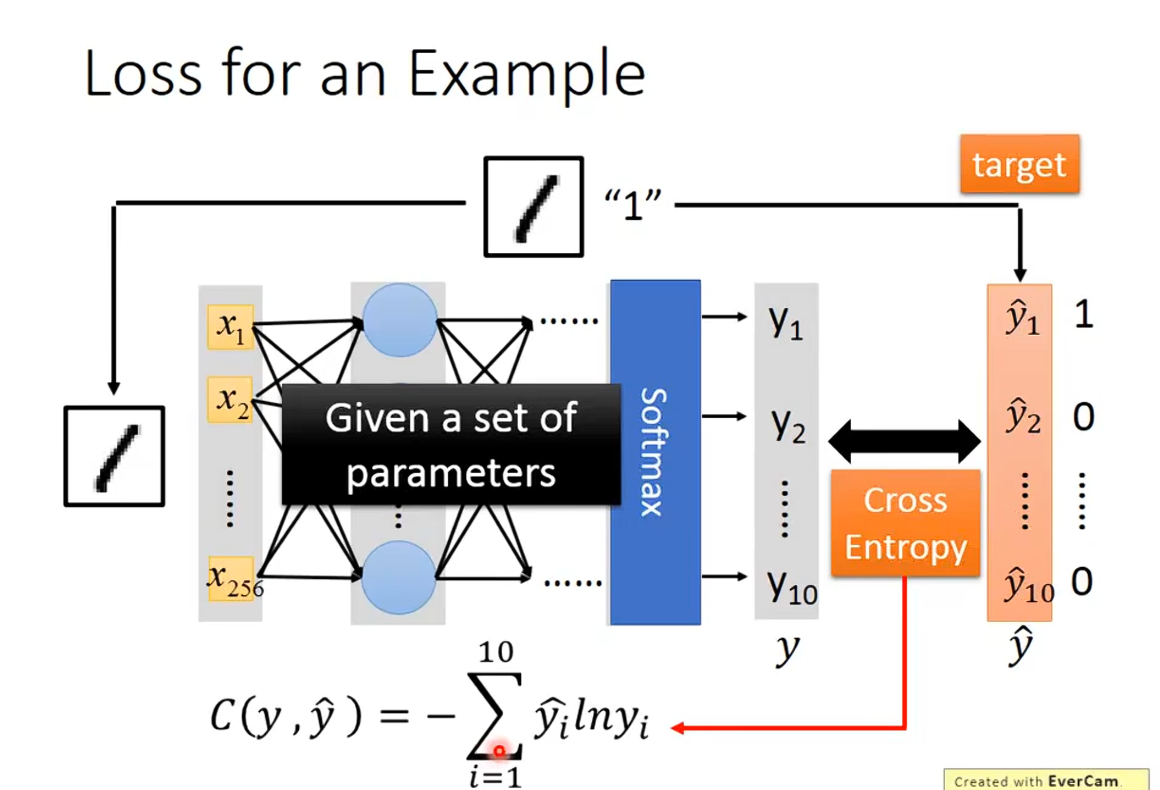
计算总的差距
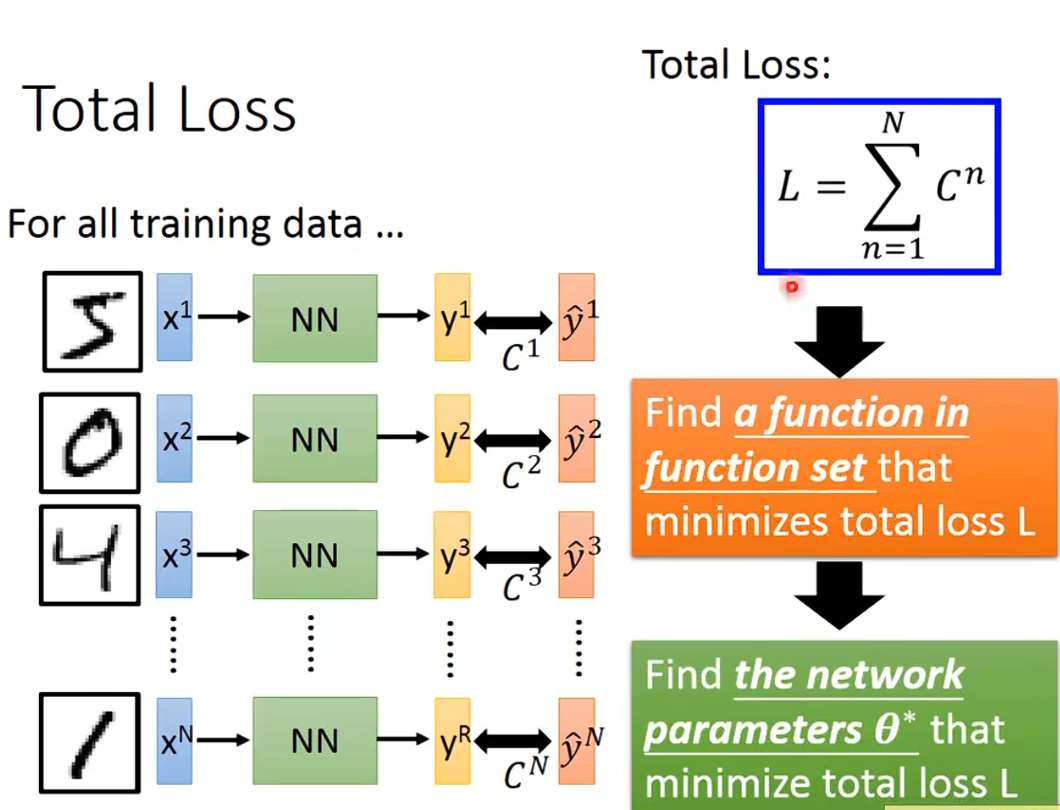
如何找到差距最小对应的参数?梯度下降


学习率怎么确定?Adam 默认 0.001;SGD 默认 0.01; 看损失调参:震荡就缩小,太慢就放大;
反向传播(Backpropagation)

