作者:来自 Elastic Jeffrey Rengifo
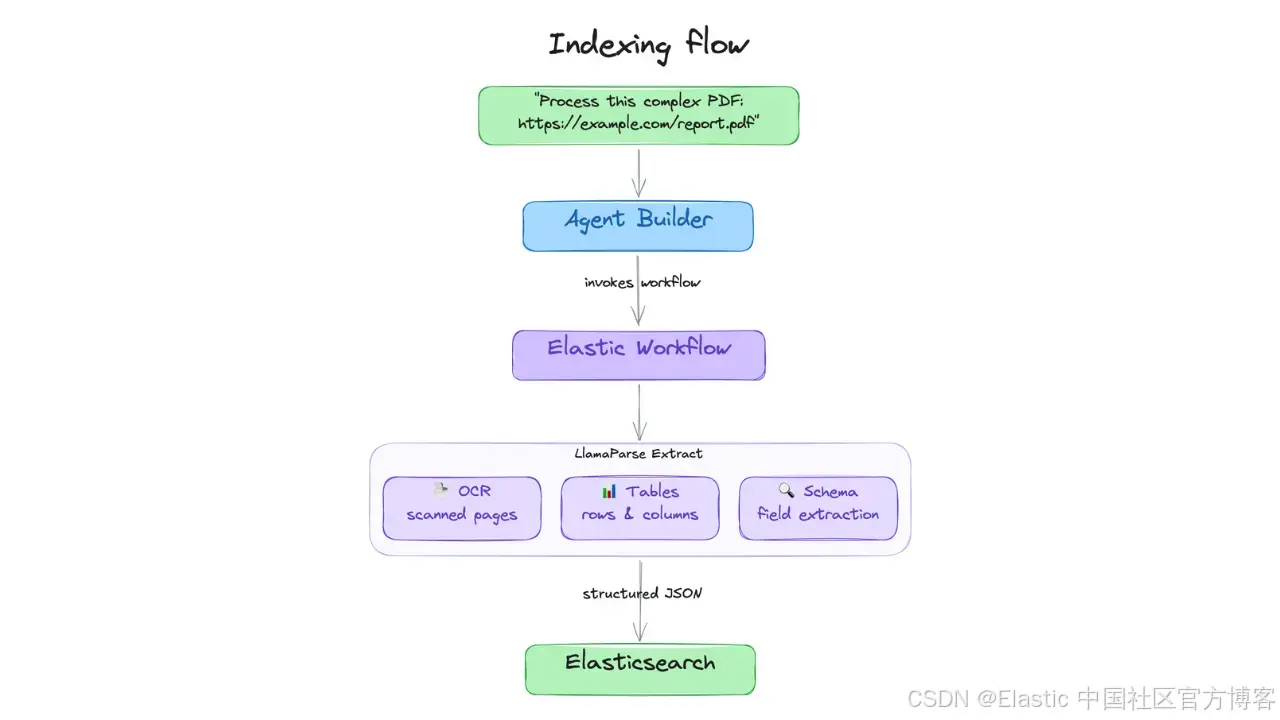
构建一个端到端流水线,该流水线从复杂 PDF文档 中提取结构化数据(包括图表中的数值),并将其导入 Elasticsearch ,支持使用 ES|QL 的 agent 查询就绪。
Agent Builder 现在已正式发布。通过注册 Elastic Cloud Trial 开始使用,并查看 Agent Builder 文档 这里。
企业级文档很难处理。包含多栏表格、扫描页面、混合布局以及嵌入图表的 PDF 会让简单的文本提取失效。标准处理流水线会遗漏这些文档中隐藏的结构化数据,这意味着你的 agent 在基于不完整上下文进行推理。大多数 agent 框架使用基础 OCR 工具处理 PDF,它们在纯文本文档中表现尚可,但在更复杂场景下表现不足。
为了解决这个问题,你需要一个系统,能够从这些文档中准确提取结构化数据,并自动将其索引,以便 agent 使用。Elastic Agent Builder 和 LlamaParse Extract API 的组合覆盖了数据处理与推理两个环节。LlamaParse Extract 负责文档复杂性处理:它将 schema 定义的提取模型应用到原始 PDF 上,并返回结构化 JSON。Elastic Agent Builder 负责编排:通过 Elastic Workflows 调用 LlamaParse Extract API,将结果写入 Elasticsearch,并让 agent 能够通过 Elasticsearch Query Language (ES|QL) 或语义查询对这些数据进行推理。
本文将讲解完整实现流程,从 schema 定义到可运行的 agent。完整代码可在配套 notebook 中查看 companion notebook。
何时应该使用 LlamaParse Extract 而不是 LlamaParse?
当你需要返回结构化的 JSON 具体字段时,应使用 LlamaParse Extract。当你需要完整文档内容用于 RAG pipeline 时,应使用 LlamaParse。
LlamaCloud 提供两种文档处理工具。LlamaParse 将文档转换为 LLM-ready 格式(如 Markdown),保留完整文档布局。它用于 RAG(Retrieval Augmented Generation)pipeline,当你希望将整个文档内容送入向量库或 LLM 上下文窗口时使用。LlamaParse Extract 则相反,它基于开发者定义的 schema,只返回你指定的字段,并以校验过的 JSON 形式输出。它还可以提取图表、图形以及文档中的视觉元素数据,这是标准文本解析完全无法覆盖的能力。
| LlamaParse / LlamaParse Extract | ||
|---|---|---|
| 输出格式 | Markdown(完整文档) | 结构化 JSON(基于 schema 定义的字段) |
| 最适合场景 | RAG pipelines,LLM 上下文窗口 | 搜索索引、数据库、类型化字段 |
| 是否支持图表/图形 | 否 | 是 |
| 输入 | PDF + 开发者定义的 schema |
对于这个用例来说,Extract 是更好的选择。我们需要具体的数值(GDP 占比百分比、投资增长率)以及叙述性总结,并将其作为类型化的 Elasticsearch 字段进行索引。schema 会告诉提取模型具体要寻找什么,包括那些只存在于 PDF 可视化图表中的数值。
如果你的用例是将完整文档内容输入到 RAG pipeline,那么 LlamaParse 是正确工具。如果你需要用于搜索索引或数据库的结构化记录,尤其是当数据存在于图表或表格中时,应使用 Extract。
LlamaParse Extract 和 Elastic Agent Builder 流水线做了什么?
这个流水线的工作方式如下:用户发送一个问题,并附带一个 PDF 的 URL。agent 会调用一个 workflow 工具,将 PDF 上传到 LlamaParse,通过 LlamaParse Extract API 执行基于 schema 的结构化提取,然后把结构化结果索引到 Elasticsearch 中。
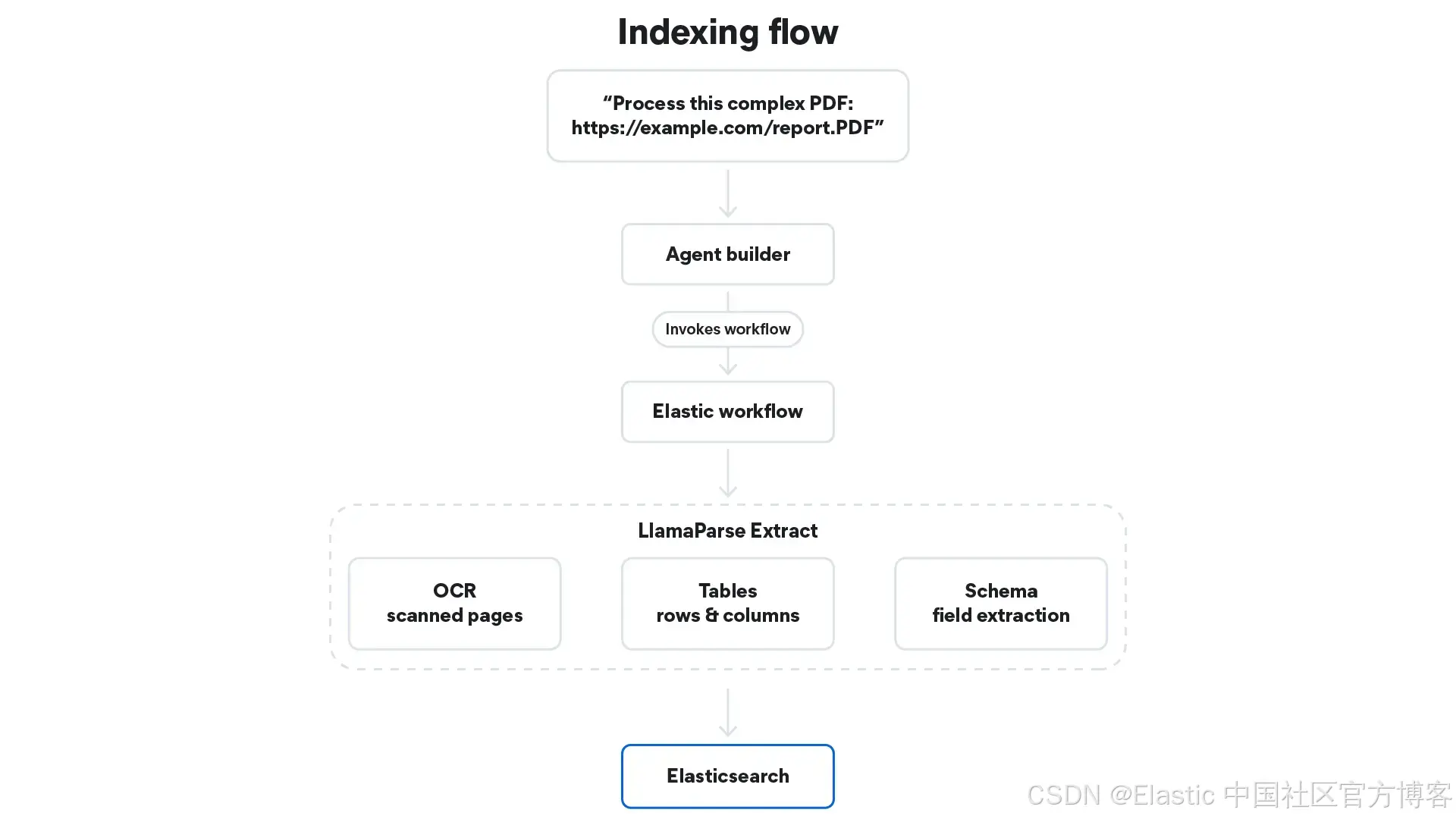
然后 agent 会使用 ES|QL 对该索引进行查询,以回答这个问题。
为了演示这一点,我们使用 世界银行全球经济展望(2026年1月) 报告作为源文档。该 agent 将能够直接从该 PDF 中回答关于前沿市场、经济指标以及政策建议的问题。
如何为 LlamaParse Extract 构建一个 Elastic Workflows 工具
Workflow tool 在 Elastic Agent Builder 中作为基于 YAML 定义的自动化运行。当被触发时,它会执行六个步骤。关于将 Agent Builder 和 Workflows 连接起来 的通用流程,该文章有更详细的搭建说明。这里我们重点讲 LlamaParse Extract 的特定集成方式。
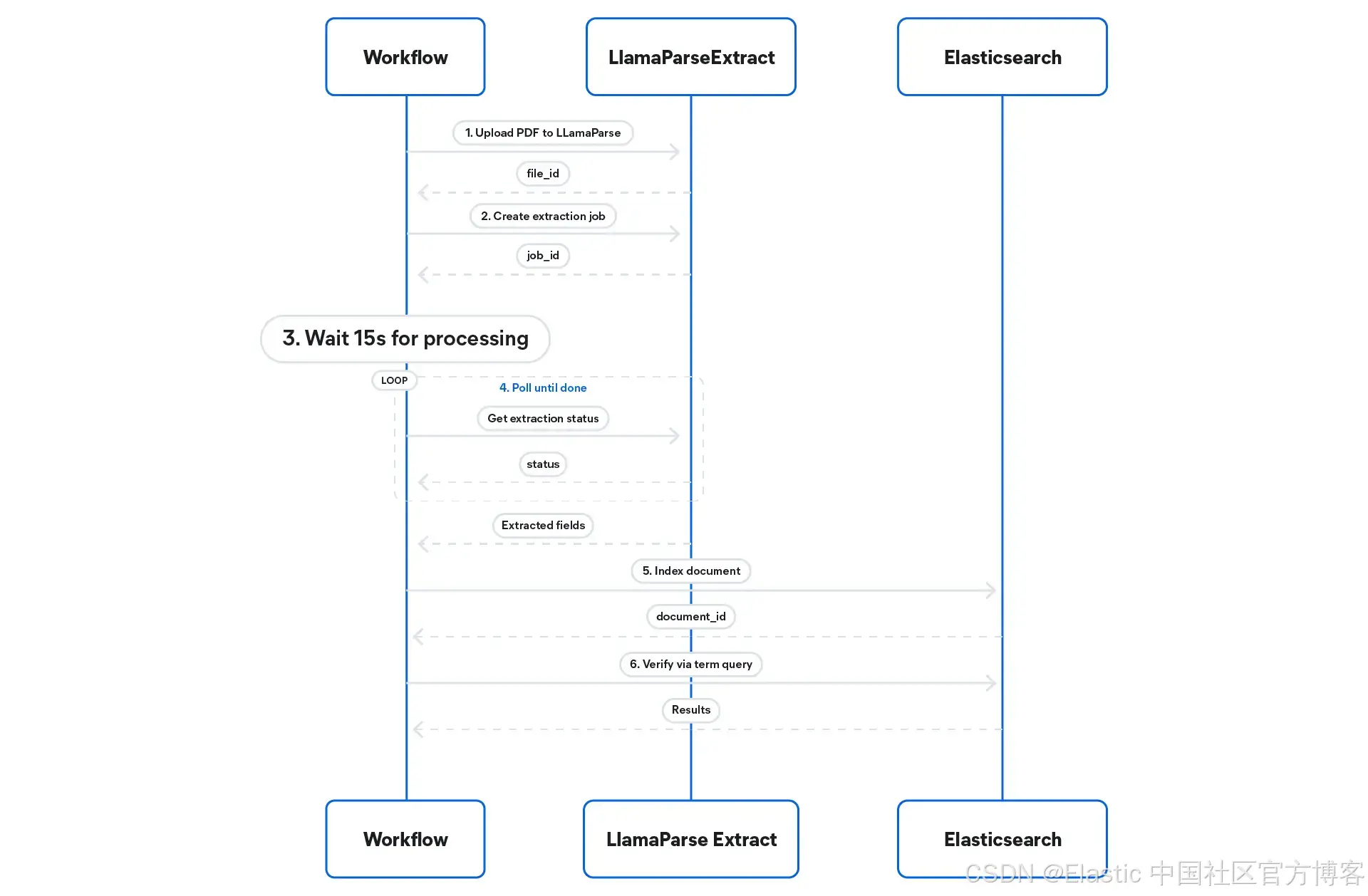
-
上传 PDF: 从提供的 URL 将 PDF 上传到 LlamaCloud。该 workflow 接收
pdf_url作为输入;你的 LlamaCloud API key、project ID 和 configuration ID 作为常量进行配置。 -
创建提取任务: 使用已保存的配置,在已上传文件上启动 Extract v2 任务。
-
等待: 暂停 15 秒,给 LlamaParse Extract 留出处理文档的时间。
-
轮询直到完成: 在
while循环中每 10 秒轮询一次提取状态,直到状态变为COMPLETED,最多循环 19 次(约 3 分钟上限)。 -
索引: 将 PDF 中所有提取字段作为单个 Elasticsearch 文档写入。
-
验证: 使用
document_id以及查询 term 查询 在 Elasticsearch 中执行搜索,以确认文档已成功索引。
前置条件
-
Elasticsearch 9.3+,并启用 Workflows
-
LlamaParse Cloud 账号,并具备 API key API key
-
Python 3.1x
使用 Elastic Agent Builder 实现 LlamaParse Extract:分步说明
下面的代码展示了实现的关键步骤。完整版本(包含所有细节)请参考配套 notebook companion notebook。
配置环境
import os
import json
from dotenv import load_dotenv
load_dotenv()
ELASTICSEARCH_URL = os.getenv("ELASTICSEARCH_URL")
ELASTICSEARCH_API_KEY = os.getenv("ELASTICSEARCH_API_KEY")
LLAMA_CLOUD_API_KEY = os.getenv("LLAMA_CLOUD_API_KEY")
KIBANA_URL = os.getenv("KIBANA_URL")定义提取 schema
LlamaParse Extract 是基于 schema 驱动的。你需要定义一个 Pydantic 模型,用来描述希望提取的字段,而 LlamaParse Extract 会基于该模型从原始 PDF 中引导提取。这正是它在复杂文档中保持可靠性的关键。与其 "期望" LLM 找到正确的值,不如明确告诉它需要找什么。
如上所述,agent 需要处理两类问题:
-
结构化问题: "2025 年前沿市场 GDP 占比是多少?" 这类问题需要可用 ES|QL 过滤的数值字段。
-
探索性问题: "前沿市场的主要风险是什么?" 这类问题需要可进行语义检索的叙述性文本字段。
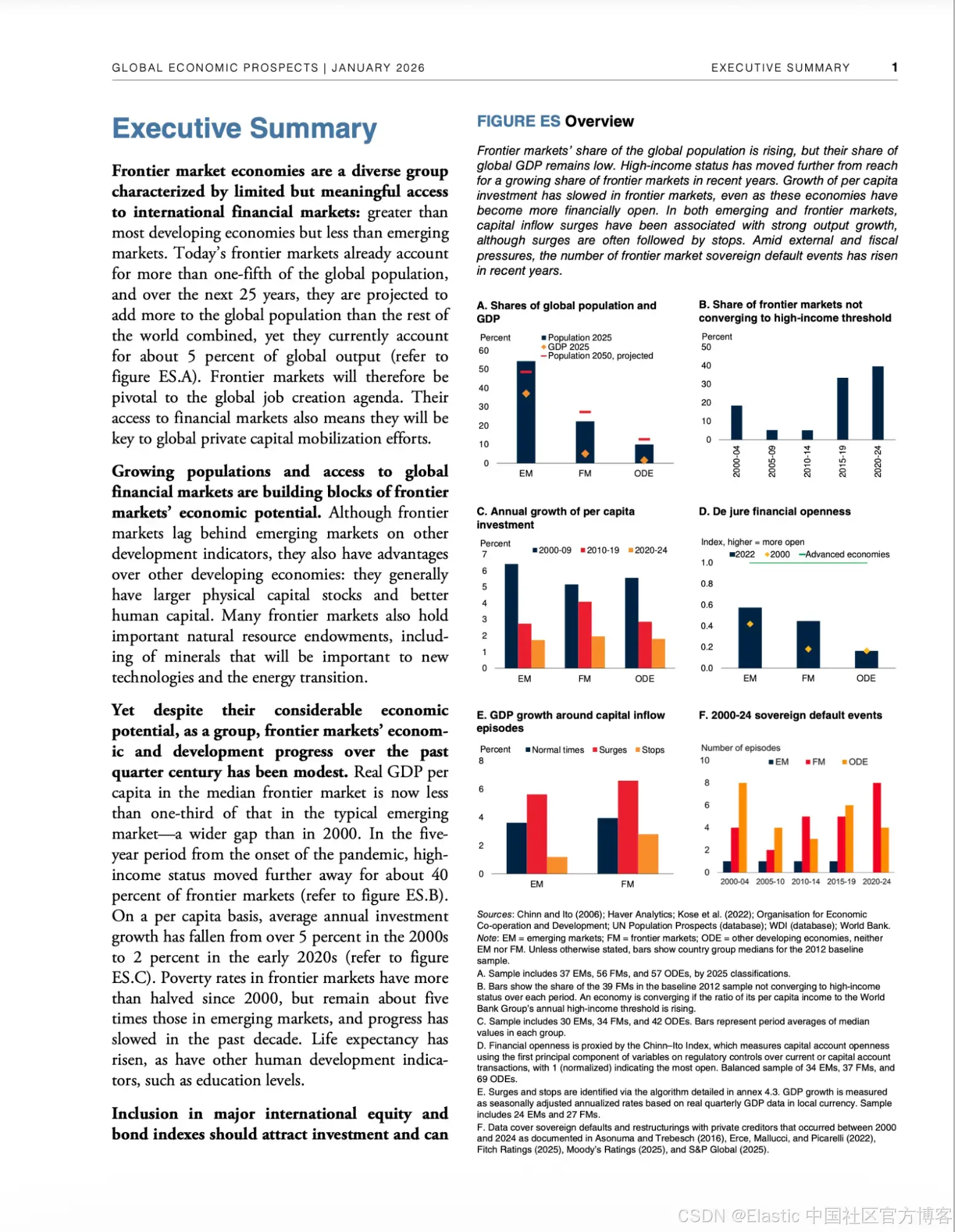
这个 schema 只捕捉支持这两类问题所需的最小信息集合。description 字段不是文档说明,而是对提取模型的指令,因此越具体,提取质量越高。其中两个字段(frontier_market_gdp_share_pct 和 frontier_market_investment_growth_2020s_pct)直接来自报告中的柱状图(图 A 和图 C),这些数据是标准文本提取工具无法捕获的。
class EconomicReportSummary(BaseModel):
report_title: str = Field(description="Full title of the report")
publication_date: str = Field(
description="Publication date in YYYY-MM format, e.g. '2026-01'"
)
frontier_market_gdp_share_pct: float = Field(
description="Frontier markets' share of global GDP in 2025 as a percentage, "
"extracted from Figure ES.A bar chart"
)
frontier_market_investment_growth_2020s_pct: float = Field(
description="Average annual per capita investment growth for frontier markets "
"in the early 2020s (2020-24), extracted from Figure ES.C bar chart, as a percentage"
)
executive_summary: str = Field(
description="Concise summary of the report's main findings and conclusions"
)
key_vulnerabilities: str = Field(
description="Main vulnerabilities and risks facing frontier markets, as a paragraph"
)
policy_recommendations: str = Field(
description="Key policy recommendations for frontier market policymakers, as a paragraph"
)创建 Extract 配置
LlamaExtract v2 用 "已保存配置(saved configurations)" 替代了旧的 extraction agents,本质上是一个可复用的参数集合,用来将你的 schema 与 extraction tier 绑定在一起。首先获取你的 project ID,然后通过 POST 创建配置。保存打印出来的两个 ID,因为你会在 workflow YAML 中用到它们。
import requests
LLAMA_CLOUD_BASE_URL = "https://api.cloud.llamaindex.ai"
llama_headers = {
"Authorization": f"Bearer {LLAMA_CLOUD_API_KEY}",
"Content-Type": "application/json",
}
# Fetch the project ID (uses the first available project)
projects_response = requests.get(
f"{LLAMA_CLOUD_BASE_URL}/api/v1/projects",
headers=llama_headers,
)
projects_response.raise_for_status()
PROJECT_ID = projects_response.json()[0]["id"]
print(f"Project ID: {PROJECT_ID}")
# Create a saved Extract v2 configuration with our schema
config_response = requests.post(
f"{LLAMA_CLOUD_BASE_URL}/api/v1/beta/configurations",
headers=llama_headers,
params={"project_id": PROJECT_ID},
json={
"name": "global-economic-extractor",
"parameters": {
"product_type": "extract_v2",
"data_schema": EconomicReportSummary.model_json_schema(),
"extraction_target": "per_doc",
"tier": "agentic",
},
},
)
config_response.raise_for_status()
CONFIGURATION_ID = config_response.json()["id"]
print(f"Configuration ID: {CONFIGURATION_ID}")创建 Elasticsearch 索引
创建索引时,需要使用与 extraction schema 对应的 mapping。数值字段(例如 frontier_market_gdp_share_pct)使用 number 类型,以支持 ES|QL 结构化过滤。publication_date 字段使用 date 类型,以支持时间范围查询。叙述性字段(例如 executive_summary 和 key_vulnerabilities)使用 text 类型,用于 全文检索。标识类字段(例如 report_title)使用 keyword 类型。完整 mapping 定义可在 notebook 中查看。
构建 Agent Builder workflow 工具
将下面的 YAML 复制并粘贴到 Elastic UI 中的 Elasticsearch > Workflows > Create a new Workflow 。Elastic Workflows 文档 覆盖了完整 YAML schema 以及可用的 step types。
该 workflow 使用 LlamaCloud 的 REST API:通过 Files API(/api/v1/files/upload_from_url)从公开 URL 上传 PDF;并通过 Extract v2 API(/api/v2/extract)创建任务并轮询结果(/api/v2/extract/{id})。
name: LlamaParse Extract Economic Report Processor
description: >
Uploads a PDF from a URL to LlamaCloud, runs Extract v2,
and indexes the structured results into Elasticsearch.
enabled: true
inputs:
- name: pdf_url
type: string
description: Public URL of the PDF to process
required: true
consts:
indexName: economic-reports
llamaBaseUrl: https://api.cloud.llamaindex.ai
projectId: <YOUR_PROJECT_ID>
configurationId: <YOUR_CONFIGURATION_ID>
documentId: global-economic-prospects-jan-2026
llamaCloudApiKey: llx-YOUR-API-KEY-HERE
triggers:
- type: manual
steps:
# Upload PDF from URL to LlamaCloud
- name: upload_pdf
type: http
with:
url: "{{ consts.llamaBaseUrl }}/api/v1/files/upload_from_url"
method: PUT
headers:
Authorization: "Bearer {{ consts.llamaCloudApiKey }}"
Content-Type: application/json
body: |
{
"url": "{{ inputs.pdf_url }}"
}
# Create the Extract v2 job using our saved configuration
- name: create_extraction_job
type: http
with:
url: "{{ consts.llamaBaseUrl }}/api/v2/extract?project_id={{ consts.projectId }}"
method: POST
headers:
Authorization: "Bearer {{ consts.llamaCloudApiKey }}"
Content-Type: application/json
body: |
{
"file_input": "{{ steps.upload_pdf.output.data.id }}",
"configuration_id": "{{ consts.configurationId }}"
}
- name: wait_for_extraction
type: wait
with:
duration: "15s"
# Poll every 10s until status is COMPLETED (max ~3 min)
- name: poll_until_done
type: while
condition: 'not steps.poll_get.output.data.status : "COMPLETED"'
max-iterations:
limit: 19
on-limit: fail
steps:
- name: poll_wait
type: wait
with:
duration: "10s"
- name: poll_get
type: http
with:
url: "{{ consts.llamaBaseUrl }}/api/v2/extract/{{ steps.create_extraction_job.output.data.id }}?project_id={{ consts.projectId }}"
method: GET
headers:
Authorization: "Bearer {{ consts.llamaCloudApiKey }}"
Accept: application/json
- name: index_extracted_data
type: elasticsearch.index
with:
index: "{{ consts.indexName }}"
id: "{{ consts.documentId }}"
document:
report_title: "{{ steps.poll_get.output.data.extract_result.report_title }}"
publication_date: "{{ steps.poll_get.output.data.extract_result.publication_date }}"
frontier_market_gdp_share_pct: "{{ steps.poll_get.output.data.extract_result.frontier_market_gdp_share_pct }}"
frontier_market_investment_growth_2020s_pct: "{{ steps.poll_get.output.data.extract_result.frontier_market_investment_growth_2020s_pct }}"
executive_summary: "{{ steps.poll_get.output.data.extract_result.executive_summary }}"
key_vulnerabilities: "{{ steps.poll_get.output.data.extract_result.key_vulnerabilities }}"
policy_recommendations: "{{ steps.poll_get.output.data.extract_result.policy_recommendations }}"
refresh: wait_for
- name: verify_document
type: elasticsearch.search
with:
index: "{{ consts.indexName }}"
query:
term:
_id: "{{ consts.documentId }}"用你自己的 llamaCloudApiKey、projectId 和 configurationId 更新 consts 部分。
与 Agent Builder 连接
保存 workflow 之后,使用 Agent Builder Kibana API 或 UI 创建两个工具和一个 agent。
import requests
headers = {
"Authorization": f"ApiKey {ELASTICSEARCH_API_KEY}",
"kbn-xsrf": "true",
"Content-Type": "application/json",
}
WORKFLOW_ID = "workflow-abcabc-0073-4a08-98a8-werwer" # Copy from UI after creating the workflow
# Create the workflow tool
workflow_tool_payload = {
"id": "run_llamaextract_workflow",
"type": "workflow",
"description": (
"Triggers the LlamaParse Extract extraction workflow. "
"Use this tool to extract structured data from a PDF URL and index it into Elasticsearch. "
"Requires only the public URL of the PDF to process."
),
"tags": ["llama-extract", "workflow"],
"configuration": {
"workflow_id": WORKFLOW_ID,
},
}
response = requests.post(
f"{KIBANA_URL}/api/agent_builder/tools",
headers=headers,
json=workflow_tool_payload,
)
print(f"Workflow tool: {response.status_code}")
# Create the structured indicators query tool
structured_query_payload = {
"id": "query_structured_indicators",
"type": "esql",
"description": (
"Query structured economic indicators using exact filters on numeric fields. "
"Use this for questions like 'Which reports show frontier market GDP share below 5%?' "
"or 'Show investment growth for reports published after 2025-01'."
),
"tags": ["economic-data", "llama-extract"],
"configuration": {
"query": (
"FROM economic-reports "
"| WHERE frontier_market_gdp_share_pct <= ?max_gdp_share "
"| KEEP report_title, publication_date, "
"frontier_market_gdp_share_pct, frontier_market_investment_growth_2020s_pct "
"| SORT publication_date DESC "
"| LIMIT 10"
),
"params": {
"max_gdp_share": {
"type": "double",
"description": "Maximum frontier market GDP share percentage to filter by",
}
},
},
}
response = requests.post(
f"{KIBANA_URL}/api/agent_builder/tools",
headers=headers,
json=structured_query_payload,
)
print(f"Structured query tool: {response.status_code}")
# Create the narrative text search tool
text_search_payload = {
"id": "search_economic_narratives",
"type": "esql",
"description": (
"Search narrative content in economic reports. "
"Use this for open-ended questions like 'What are the main risks for frontier markets?' "
"or 'What does the report recommend for policymakers?'."
),
"tags": ["economic-data", "llama-extract"],
"configuration": {
"query": (
"FROM economic-reports "
"| WHERE MATCH(executive_summary, ?query) "
"OR MATCH(key_vulnerabilities, ?query) "
"OR MATCH(policy_recommendations, ?query) "
"| KEEP report_title, executive_summary, key_vulnerabilities, policy_recommendations "
"| LIMIT 5"
),
"params": {
"query": {
"type": "keyword",
"description": "The search query to find relevant narrative content",
}
},
},
}
response = requests.post(
f"{KIBANA_URL}/api/agent_builder/tools",
headers=headers,
json=text_search_payload,
)
print(f"Text search tool: {response.status_code}")
# Create the agent
agent_payload = {
"id": "economic-report-analyst",
"name": "Economic Report Analyst",
"description": "Extracts and analyzes economic reports from PDFs using LlamaParse Extract and Elasticsearch.",
"labels": ["economics", "llama-extract"],
"configuration": {
"instructions": (
"You are an economic research assistant. You have three tools:\n"
"1. run_llamaextract_workflow: Use this FIRST to extract and index data from a PDF.\n"
"2. query_structured_indicators: Use this for structured questions that filter on "
"numeric fields like GDP share or investment growth.\n"
"3. search_economic_narratives: Use this for open-ended questions about risks, "
"vulnerabilities, or policy recommendations.\n"
"When presenting data, use clear formatting with bullet points or tables. "
"Always cite the report title and publication date."
),
"tools": [
{
"tool_ids": [
"run_llamaextract_workflow",
"query_structured_indicators",
"search_economic_narratives",
]
}
],
},
}
response = requests.post(
f"{KIBANA_URL}/api/agent_builder/agents",
headers=headers,
json=agent_payload,
)
print(f"Agent: {response.status_code}")workflow ID 可以在 URL 中找到:
https://4622216ea8cd443ead5bef0a3de05135.us-central1.gcp.cloud.es.io/app/workflows/<WORKFLOW-ID>通过 Agent Builder 测试 workflow
配置好 "经济报告分析员" agent 后,打开 Agent Builder 聊天窗口,并发送如下消息(请替换为你自己的实际 ID):
Process this PDF and extract its data: <your-pdf-url>
Once extracted, answer: What are the main vulnerabilities facing frontier markets and what policy recommendations does the report suggest to address them?
Agent 会首先调用 run_llamaextract_workflow,等待 workflow 完成,然后再使用 search_economic_reports 来检索并总结提取后的数据。
Process this PDF and extract its data: https://diaphysial-rafael-unscrupulously.ngrok-free.dev/Markets-Executive-Summary.pdf
Once extracted, answer: What are the main vulnerabilities facing frontier markets and what policy recommendations does the report suggest to address them?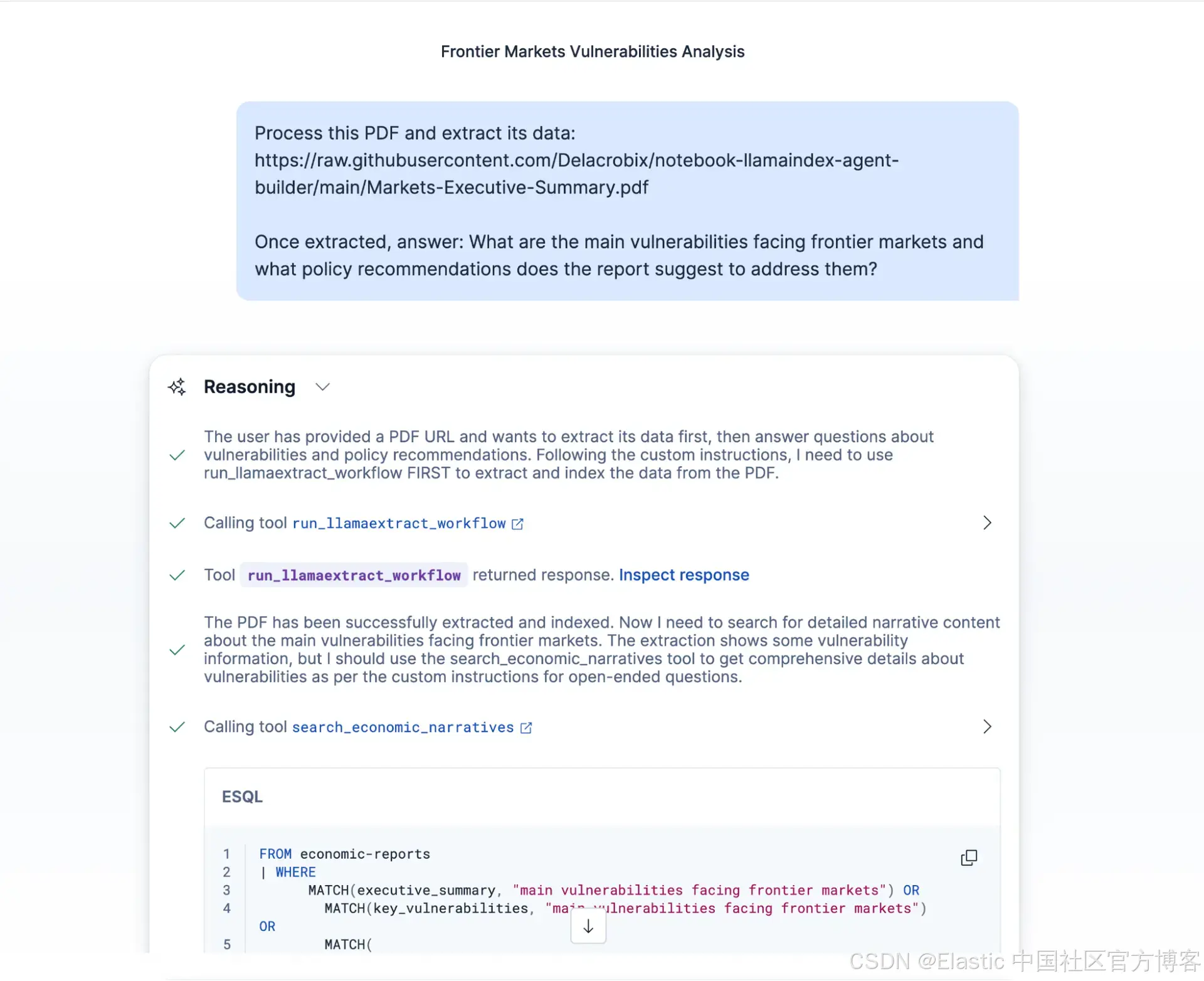
提示:在实际的使用中,https://raw.githubusercontent.com/Delacrobix/notebook-llamaindex-agent-builder/main/Markets-Executive-Summary.pdf 这个文件的路径可能导致失败。一种做法就是使用如下的命令在本地构建一个文件服务器:
python3 -m http.server 8000
ngrok http 8000
你可以参考 ngrok: deliver your apps, APIs, and AI on local and prod 来进行设置。我们可以得到一个公共的访问地址,比如:https://diaphysial-rafael-unscrupulously.ngrok-free.dev -> http://localhost:8000
结果:
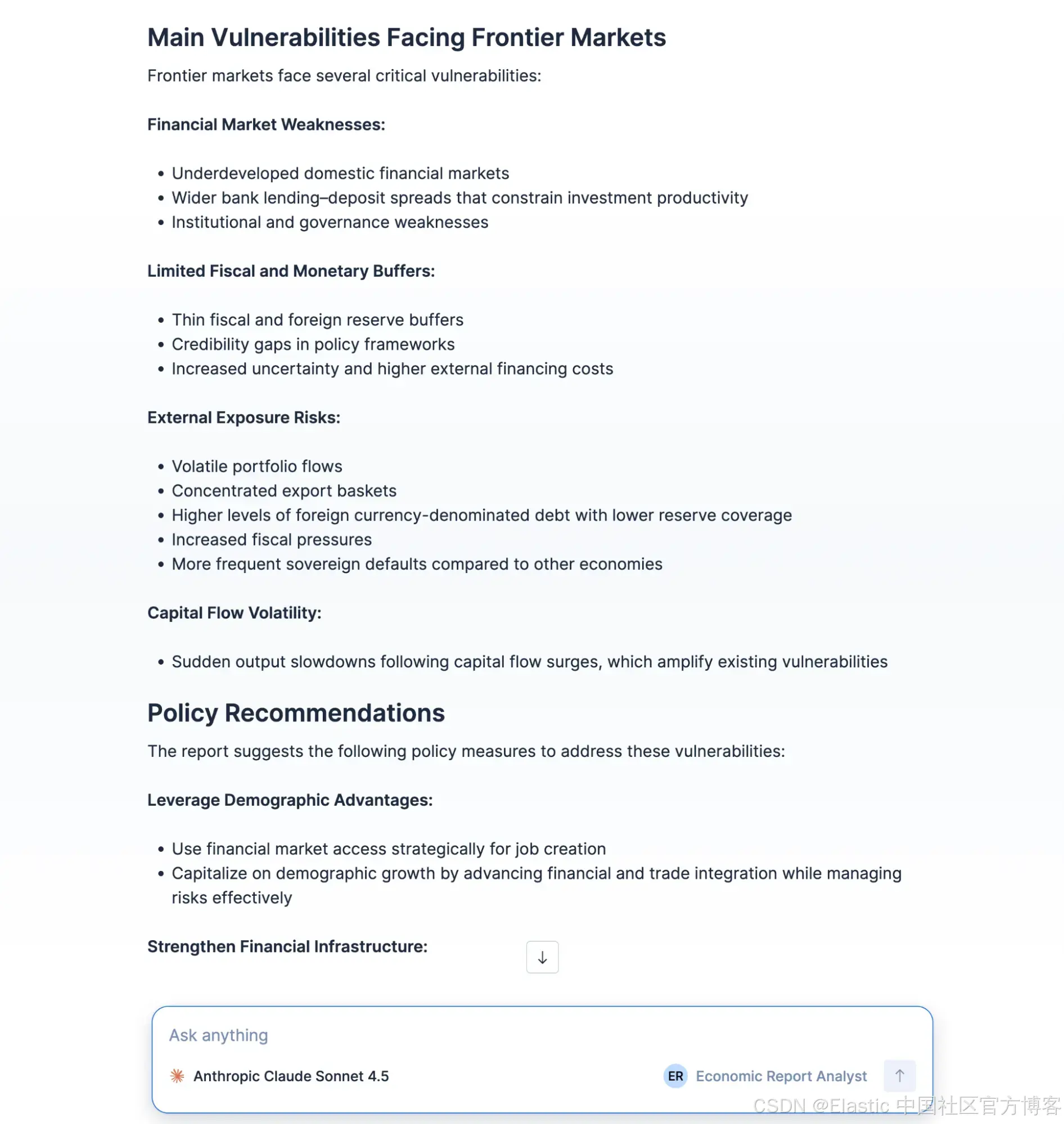
What is the frontier market GDP share in 2025?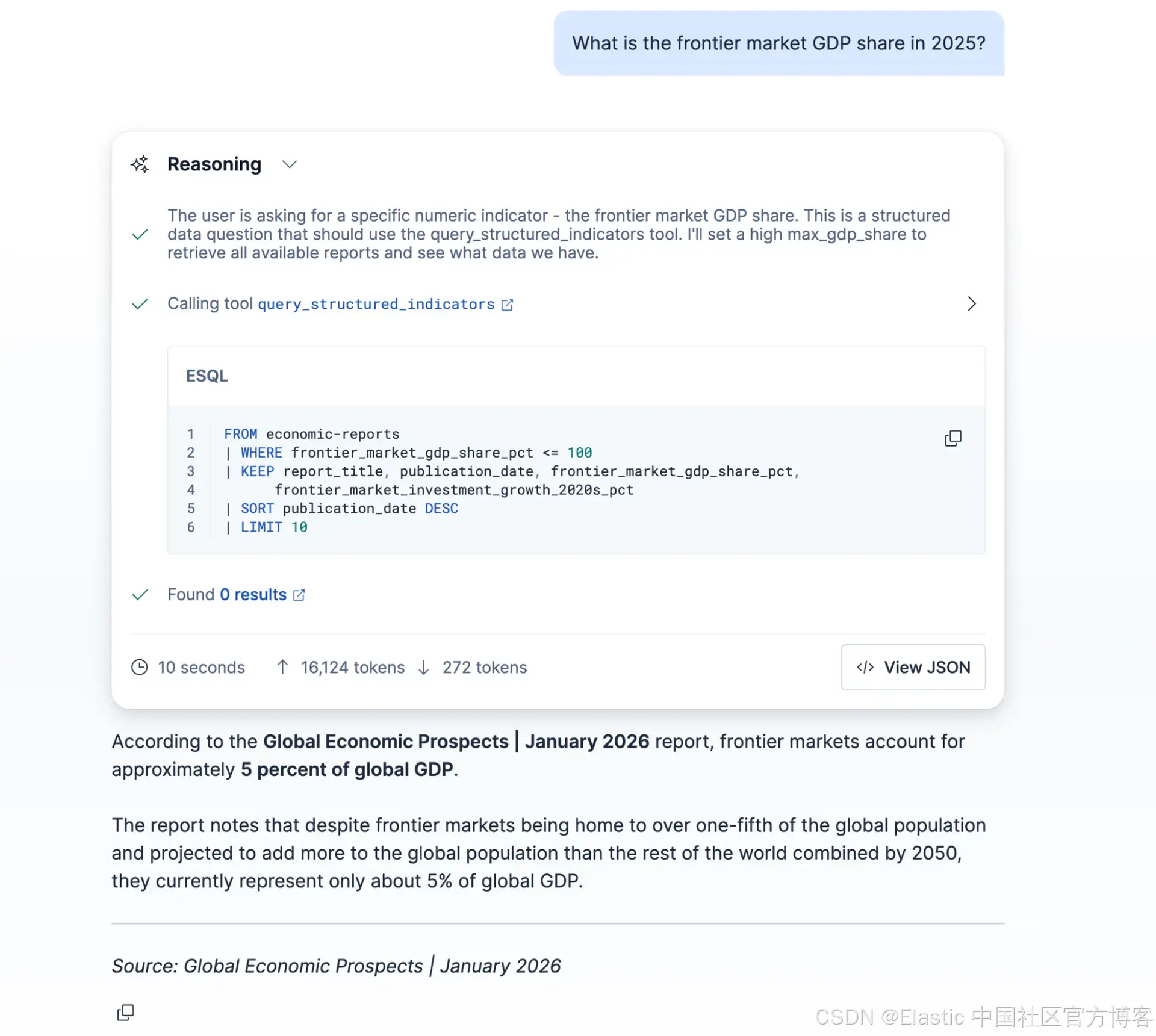
结论:从原始 PDF 到 agent 可用数据
LlamaParse Extract 解决了文档理解问题,它可以从包含图表和表格的 PDF 中提取结构化、基于 schema 的数据。Elastic Agent Builder 解决了编排问题,将提取、索引以及查询串联成 workflow,并提供 agent 可按需调用的 ES|QL 工具。两者结合在一起,就弥合了企业原始文档与 agent 可用数据之间的鸿沟。
这一模式不仅适用于经济报告。任何具有明确结构的企业文档(合同、技术规范、财务报表)都可以通过 Pydantic schema 建模,并用同样的 pipeline 进行处理。
下一步
原文:PDF data extraction with LlamaParse and Elastic Agent Builder - Elasticsearch Labs