算法面试高频题:DeepSeek 核心算法 GRPO 到底比 PPO 强在哪?
在强化学习对齐(RLHF)的领域,OpenAI 的 PPO(近端策略优化) 曾经是绝对的统治者。但随着 DeepSeek 等开源力量的崛起,一种名为 GRPO(组内相对策略优化) 的新算法进入了大众视野,并因其极高的训练效率备受推崇。
在今年的大厂算法面试中,"GRPO 比 PPO 做了什么改进?"几乎成为了必考题。今天,我们就用最通俗的语言,结合底层逻辑把这个问题彻底讲透。
一、 痛点回顾:PPO 为什么让人头疼?
我们先来看看传统的 PPO 是怎么训练模型的。
在 PPO 框架中,除了正在训练的策略模型(Policy Model),还需要配套好几个模型打辅助:
- Reference Model (参考模型):防止模型学偏了(计算 KL 散度)。
- Reward Model (奖励模型) :给模型生成的回答打分(实际收益 rrr)。
- Value Model / Critic (价值模型) :预测当前状态下模型能拿多少分(预期收益 vvv)。
PPO 计算"优势 (Advantage, AAA)" 的公式是:优势 = 实际收益 - 预期收益。
如果优势大于 0,说明这次回答超出了预期,模型以后就会更倾向于这么回答。
PPO 的致命痛点:
你需要同时在显存里塞下足足 4 个大模型!尤其是那个用来预测分数的 Value Model,它和策略模型一样大,并且还需要实时更新梯度,极其消耗显存和算力。
二、 破局之道:GRPO 的"组内相对竞争"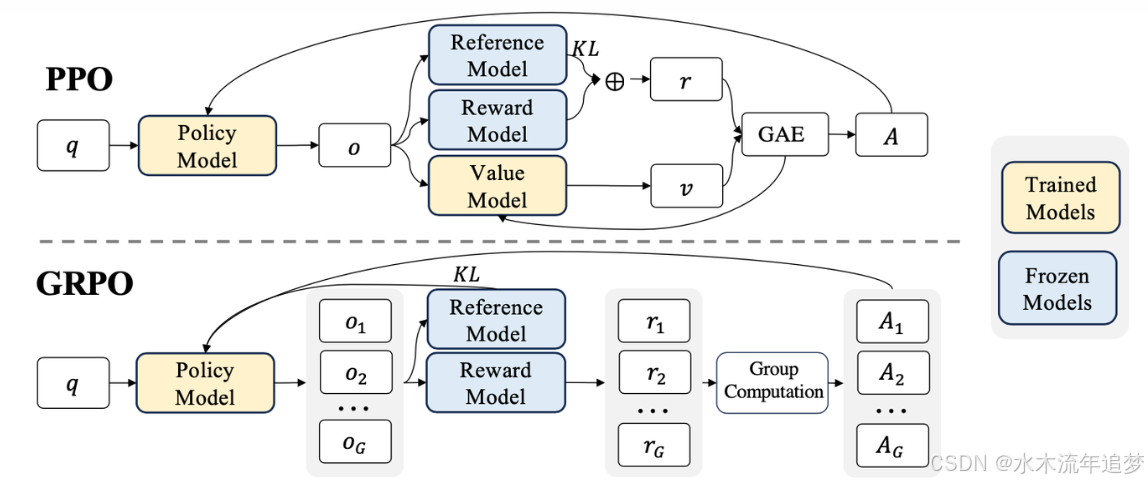
GRPO 的全称是 Group Relative Policy Optimization。它的核心创新点,就是用"组内竞争"的机制,彻底重塑了优势的计算方法。
GRPO 的运行流程 (只需 4 步):
- 一对多生成: 对于同一个输入问题 qqq,让策略模型一次性生成多个回答(比如生成 4 个:o1,o2,o3,o4o_1, o_2, o_3, o_4o1,o2,o3,o4),组成一个群体(Group)。
- 直接打分: 把这些回答送入冰冻的 Reward Model 中,直接给出每个回答的实际分数(r1,r2,r3,r4r_1, r_2, r_3, r_4r1,r2,r3,r4)。
- 计算群体统计量: 算出这组回答分数的均值 μG\mu_GμG 和标准差 σG\sigma_GσG。
- 计算相对优势: 既然有了均值,我们就不需要那个笨重的 Value Model 来预测预期收益了!直接套用标准化公式:
AiG=ri−μGσG+ϵA_i^G = \frac{r_i - \mu_G}{\sigma_G + \epsilon}AiG=σG+ϵri−μG
通俗比喻: > PPO 就像是学生考试前,必须有个老师(Value Model)先估分,然后再看实际考了多少,对比出优势。
GRPO 则是班级内部"卷":一次考好几份卷子,算出平均分。你的分数超过了平均分,优势就是正的,就会受到表扬(强化);低于平均分,就会被抑制。
三、 面试通关总结 (Cheat Sheet)
如果在面试中遇到"GRPO 相对 PPO 的区别与好处",请直接抛出以下两个核心杀手锏:
1. 工程上的绝对优势:干掉 Critic 模型,拯救显存
因为 GRPO 只需要利用 Reward 模型生成的分数进行组内均值计算,它彻底抛弃了 PPO 中那个需要实时更新的 Critic (Value) 模型。
- 结果: 节省了极大量的 GPU 内存,让普通实验室和企业也能在有限的算力下微调超大模型。
2. 算法上的范式转变:从个体对齐到群体寻优
传统的 PPO 过于关注单个样本(个体表现),而 GRPO 更加关注群体表现(Group Computation)。
- 结果: 利用群体统计量计算相对优势,能一次性提升整个模型在多种解法上的综合表现,不仅让训练更稳定,也有助于激发模型更强的逻辑推理能力(DeepSeek-R1 就是最好的证明)。
面试金句总结:
"GRPO 的本质是用空间(同一 prompt 多次采样生成的 Group)换取了模型架构上的精简,通过计算组内标准化分数替代了 PPO 中高昂的 Critic 模型估值成本,从而实现了算力与效果的双赢。"

python
print('hello world')