文章目录
-
- 一、从一个真实场景说起
- 二、知识库是什么,以及它和网盘的区别
- [三、为什么是 WeKnora](#三、为什么是 WeKnora)
- [四、WeKnora 的几个核心特点](#四、WeKnora 的几个核心特点)
-
- [4.1 复合检索引擎](#4.1 复合检索引擎)
- [4.2 企业级多租户](#4.2 企业级多租户)
- [4.3 安全细节](#4.3 安全细节)
- [4.4 全链路可观测性](#4.4 全链路可观测性)
- 五、安装与部署实战
- [六、踩坑实录:17 篇文档,一篇都搜不出来](#六、踩坑实录:17 篇文档,一篇都搜不出来)
-
- [6.1 现象](#6.1 现象)
- [6.2 第一反应:是不是客户端脚本的问题?](#6.2 第一反应:是不是客户端脚本的问题?)
- [6.3 第二个怀疑:文档还在解析?](#6.3 第二个怀疑:文档还在解析?)
- [6.4 找到根因:embedding 配置为空](#6.4 找到根因:embedding 配置为空)
- [6.5 修复方向](#6.5 修复方向)
- [6.6 这个坑为什么值得写出来](#6.6 这个坑为什么值得写出来)
- 七、应用场景
- 八、适合谁,以及一些诚实的局限
本文不是一个功能罗列式的产品介绍,而是一篇真实的部署与排障记录。我实际用 WeKnora 搭了一套企业知识库,灌进去 17 篇文档,然后遇到了"所有文档都能解析、却一篇都搜不出来"的怪事。这篇文章记录了我是怎么一步步把根因挖出来的------这部分是官方文档不会写、但你想落地时最需要的内容。
一、从一个真实场景说起
做安全运营的人大概都有过这种体验:你需要的东西肯定存在,但不知道在哪儿。
制度文件散在飞书群文件、企业网盘、个人电脑桌面、邮件附件里;国家标准是 PDF,命名五花八门;上次某个应急响应的复盘记录,谁也说不清被谁存到了哪里。你问同事"漏洞修复时效要求是多少",对方回你一句"好像在某个制度里写过,你找找"。
更糟的是,你把文档丢给大模型问问题,它答得头头是道------直到你发现它在一本正经地编造,因为它的训练数据里根本没有你那几份内部制度。
这两个痛点(找不到 和幻觉)的交汇处,就是"知识库"要解决的问题。
二、知识库是什么,以及它和网盘的区别
先厘清一个常见误解:把文件集中存起来,不等于有了知识库。
企业网盘、文档中台解决的是"存储和共享"问题------文件确实在一个地方了,但检索仍然靠文件名和文件夹层级,本质上还是"人肉翻找"。
真正意义上的、面向大模型时代的知识库,核心是 RAG(Retrieval-Augmented Generation,检索增强生成)。它做三件事:
- 向量化:把文档切成小块(chunk),用 embedding 模型转成向量,让机器能"理解"语义;
- 语义检索:你提问时,不靠关键词匹配,而是按语义相似度找出最相关的片段;
- grounded 生成 :把这些片段作为上下文喂给大模型,让它基于你的文档回答,而不是凭空生成。
差异有多大?你在网盘里搜"漏洞管理",只能命中文件名包含这四个字的文件;在 RAG 知识库里问"高危漏洞多久要修完",它能从一份名为《安全运营管理办法》的 PDF 里抽出那句"高危漏洞 15 天内修复"------哪怕文件名里根本没有"漏洞管理"四个字。
这就是知识库的价值:让文档从"被存储"变成"被理解、被回答"。
三、为什么是 WeKnora
开源 RAG 框架不少,Dify、RAGFlow、FastGPT、MaxKB 都各有拥趸。我在选型时对比了一圈,最后选了腾讯开源的 WeKnora(维娜拉),原因有三:
第一,它不只是一个 RAG 问答引擎。 大多数同类产品做的是"上传文档→提问→回答"这一条线。WeKnora 把三件事做在了一个平台里:
- RAG 快速问答:常规检索增强生成;
- ReAct Agent 推理:遇到复杂问题,Agent 会自主编排多步------先检索知识库,再调用外部工具(MCP)、做网络搜索,一步步推理出答案;
- 自维护 Wiki 模式 :这是最有意思的一个,Agent 能从原始文档里自动生成结构化、相互链接的 Markdown 知识页面和可视化知识图谱。
第三个能力是真正打动我的。它意味着知识库不只是"被动问答",还能主动把散乱文档沉淀成结构化知识。
第二,国产化生态适配最全。 WeKnora 兼容 20 多家模型厂商(OpenAI、DeepSeek、通义千问、智谱、混元、豆包、Ollama 等),8 种向量库(pgvector、Milvus、OpenSearch、腾讯云 VectorDB 等),8 种对象存储,7 种 IM(企业微信、飞书、钉钉等)。对有国产化、私有化要求的企业来说,这套适配广度很难得。
第三,它是微信对话开放平台的核心技术框架------意味着背后有真实的大规模产品在驱动,不是周末玩具项目。MIT 协议,后端 Go、前端 Vue,可全栈私有化部署。
📷:WeKnora 官方架构图,展示从文档解析、向量化、检索到 LLM 推理的模块化流水线。来源:项目 README。
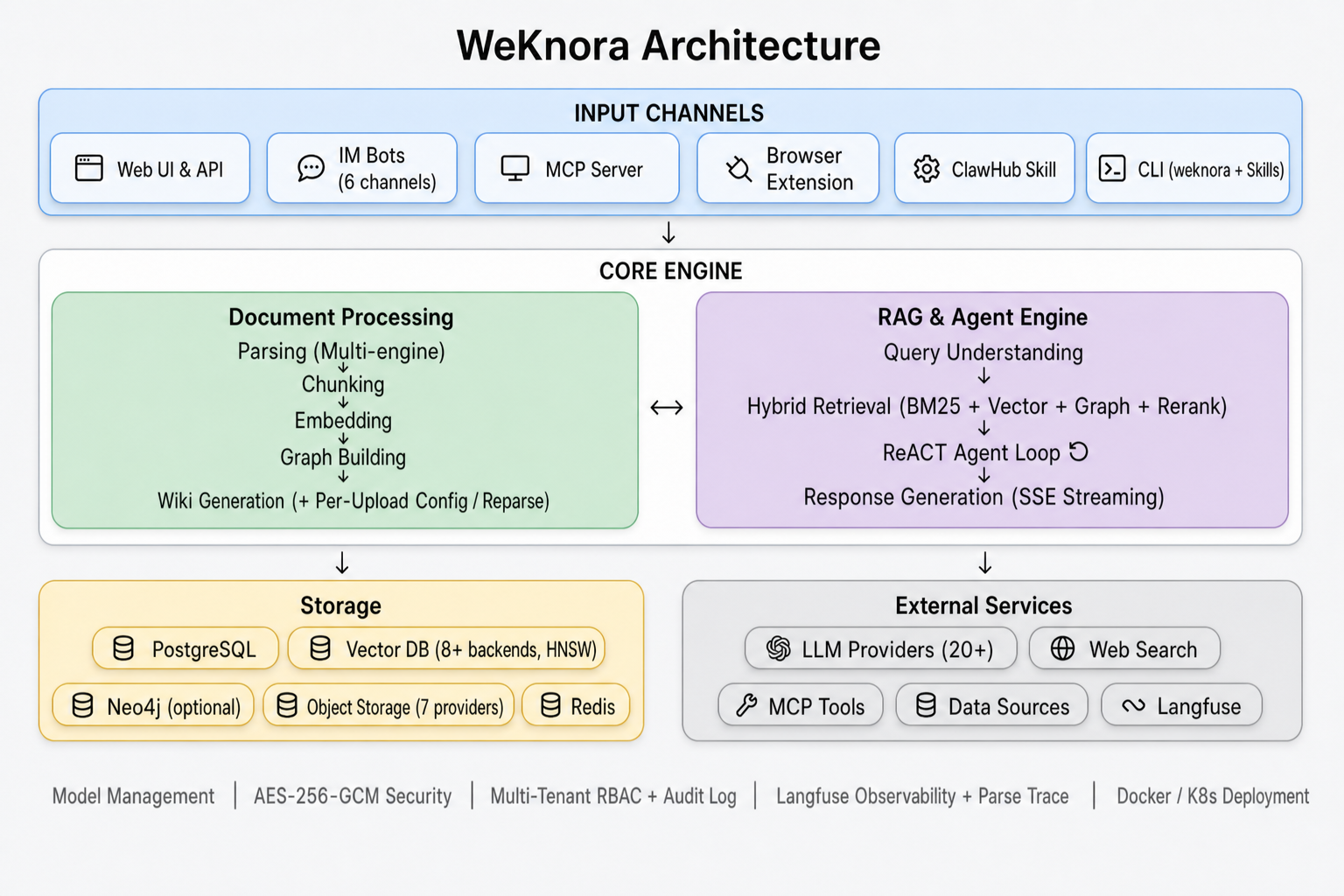
四、WeKnora 的几个核心特点
部署之前,先快速过一下它身上值得记住的几个设计。
4.1 复合检索引擎
这是 RAG 质量的命门。WeKnora 不是只做向量检索,而是三路并行召回:
- BM25 稀疏召回:传统全文检索,擅长精确关键词;
- Dense 稠密召回:向量语义检索,擅长理解意图;
- GraphRAG 图谱召回:基于知识图谱的实体关系查询,擅长多跳推理。
三路结果再经过 Rerank 重排,最后把最相关的片段喂给大模型。这种混合检索的召回率,明显优于单一向量检索。
4.2 企业级多租户
WeKnora 的多租户做得相当认真:四级 RBAC 角色矩阵(Owner / Admin / Contributor / Viewer)、按知识库的资源归属、每租户审计日志、invite-only 准入、跨租户超级管理员。对于一个要在企业内部给多个团队用的平台,这套权限模型是刚需,而不是锦上添花。
4.3 安全细节
API Key 和数据源凭据用 AES-256-GCM 静态加密,支持平滑密钥轮换;内部服务间走 gRPC TLS;HTTP 客户端做了防 SSRF 处理;Agent 技能跑在沙箱里隔离。这套安全基线对要过等保、要做关基运营的企业是有意义的。
4.4 全链路可观测性
集成 Langfuse,能追踪每一次 ReAct 推理循环、Token 消耗、工具调用链路。文档解析过程也有 Span 树追踪,能看到"卡在哪一步"。这对排查问题极其有用------后面我的踩坑过程就会用到这种思路。
五、安装与部署实战
WeKnora 的部署门槛很低,三条命令起步:
bash
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora
cp .env.example .env # 按需编辑
docker compose up -d # 启动核心服务启动后访问 http://<your-server-ip> 即可看到 Web UI,后端 API 在 http://<your-server-ip>:8080。
它用 Docker Compose Profile 机制管理可选组件,按需叠加:
| Profile | 作用 | 命令 |
|---|---|---|
| (默认) | 核心服务(RAG 问答 + 文档管理) | docker compose up -d |
neo4j |
知识图谱(GraphRAG 依赖) | docker compose --profile neo4j up -d |
minio |
对象存储 | docker compose --profile minio up -d |
langfuse |
链路追踪 | docker compose --profile langfuse up -d |
full |
全部功能 | docker compose --profile full up -d |
我自己的部署实例规划了 6 个知识库,按文档生命周期分类:
| 知识库 | 定位 |
|---|---|
| 01_标准规范库 | 等保、分级保护、安全基线等国家标准 |
| 02_管理制度库 | 安全策略、管理规定、操作规程、应急预案 |
| 03_产品设计库 | 需求规格、设计方案、架构文档 |
| 04_局点建设库 | 各局点建设方案、实施方案、验收报告 |
| 05_交付文档库 | 部署手册、用户手册、运维指南、培训材料 |
| 安全运营管理知识库 | 综合,存放核心参考材料 |
往里面灌了 17 篇文档,包括几份国家标准(GB/T 45940、GB/T 32914)、安全运营管理办法、还有客户的几份制度文件。Web UI 里能看到文档逐个进入"解析中→已完成"的状态。
WeKnora Web UI 的知识库列表页面,展示 6 个知识库及其文档数量
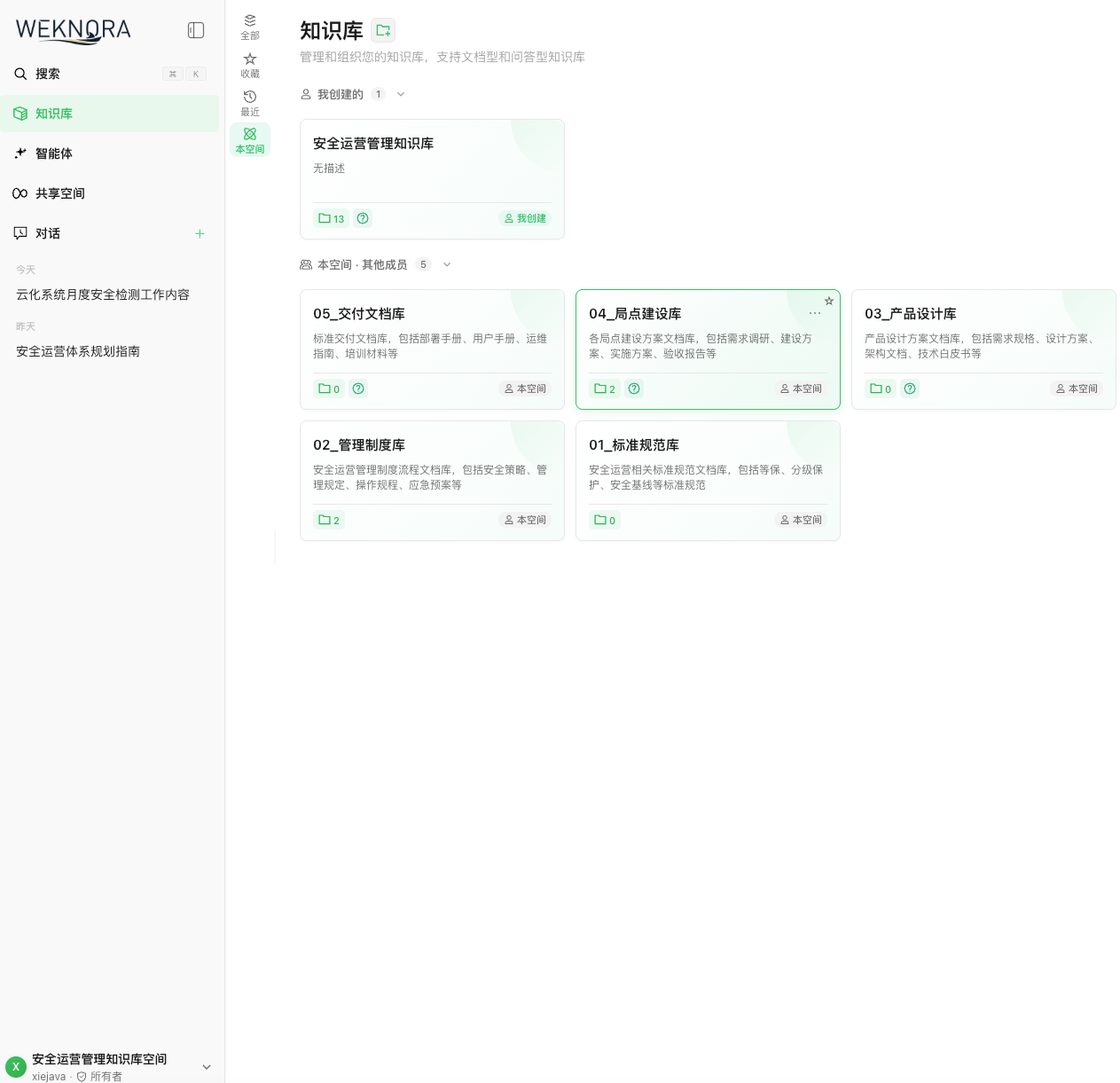
到这里,一切看起来都很顺利。文档全部显示 parse_status: completed,我以为大功告成了------直到我开始试着检索。
六、踩坑实录:17 篇文档,一篇都搜不出来
这是全文最值得读的部分。WeKnora 提供了一系列 RESTful API,用于创建和管理知识库、检索知识,以及进行基于知识的问答。所以你可以将它嵌入到你的应用中来,可以编写自己的客户端脚本对知识库进行操作。
https://github.com/Tencent/WeKnora/blob/main/docs/api/README.md
6.1 现象
我用客户端脚本对"安全运营管理知识库"做了一次检索,查询词是"安全运营管理制度体系"。结果:
json
{"chunks": [], "total": 0}一个 chunk 都没有。换了"漏洞管理""安全运营""等保""网络安全"四个高频词,全部返回 0。17 篇文档明明都解析成功了,却一篇都搜不出来。
6.2 第一反应:是不是客户端脚本的问题?
我用的检索脚本会对返回结果做字段归一化和 score 过滤。万一是它把字段名认错了,或者阈值卡得太严,导致本来有的结果被丢弃了呢?
为了排除这层干扰,我绕过客户端脚本,直接用 curl 打 WeKnora 的原始 API:
bash
curl -sk -X POST -H "X-API-Key: $API_KEY" -H "Content-Type: application/json" \
"http://<your-server-ip>/api/v1/knowledge-search" \
-d '{"query":"漏洞管理","knowledge_base_id":"<kb_id>","top_k":5,"min_score":0.0}'注意我把 min_score 设成了 0.0------最宽松的条件,只要有一丝相似度都应该返回。结果:
json
{"data": [], "success": true}服务端确实返回空。 这下排除了客户端的问题:检索为空是服务端真实状态,不是脚本过滤掉的。
6.3 第二个怀疑:文档还在解析?
WeKnora 的文档上传是异步的------上传后要经历解析、切块、向量化几步,期间 parse_status 会从 pending 变到 processing 再到 completed。如果文档还在处理中,搜不到是正常的。
但我查了一下文档清单,所有 17 篇文档的 parse_status 都是 completed ,is_processing 都是 false。解析这关也排除了。
6.4 找到根因:embedding 配置为空
既然文档解析成功了,为什么检索还是空?我把目光转向知识库本身的配置,调原始 API 看每个库的完整字段。关键发现来了:
安全运营管理知识库:
knowledge_count = 13 # 元数据里文档数
chunk_count = 0 # 实际索引的 chunk 数!
vector_store_status = available
embedding_config = {} # ← 空对象!所有 6 个知识库的 embedding_config 都是空对象 {},chunk_count 全是 0。
诊断逻辑链一下子清晰了:
capabilities.vector = true (向量检索开关是开的)
↓ 但
embedding_config = {} (没配置 embedding 模型)
↓ 导致
文档解析成功 → 无法向量化 → chunk_count = 0
↓ 进而
knowledge-search 全部返回空根因:知识库开启了向量检索能力,但没有绑定 embedding 模型。文档虽然解析成了文本,却没法转成向量索引,检索自然全是空。
6.5 修复方向
定位到根因,修复路径就明确了:
- 在 WeKnora 管理端为知识库绑定 embedding 模型(如 BGE-M3、GTE,或 OpenAI 兼容的 embedding 接口);
- 对已有文档触发重新向量化(重新解析或重建索引);
- 重新向量化后,
chunk_count应该从 0 变为大于 0,检索即可恢复正常。
修复后用一条命令就能验证:
bash
python kb_search.py --kb <kb_id> --query "漏洞管理" --min-score 0.36.6 这个坑为什么值得写出来
因为它极具迷惑性 。整个过程中,Web UI 上一切显示正常------文档状态都是绿色的"已完成",没有任何错误提示,知识库列表也看不出异常。如果不是我较真去对 chunk_count 这个字段,很可能就停在"为什么搜不到东西"的困惑里,转而怀疑文档质量或 query 写得不好。
这条排查链的关键经验是:当检索为空时,不要只看 parse_status,一定要看 chunk_count 和 embedding_config。 解析成功和向量化成功是两回事,中间隔着一个 embedding 模型配置。这个区分,官方文档里并没有醒目地写出来。
七、应用场景
修好检索之后,WeKnora 这类知识库能用在哪些地方?结合我的实践,说三个真实场景。
场景一:企业内部制度问答。 这是最低门槛的应用。把安全管理制度、操作规程、应急预案灌进去,员工不用再翻文件找条款,直接问"离职人员账号多久要关停""高危漏洞几天要修完",知识库基于原文给出带出处的回答。对一个安全团队来说,这能省下大量重复答疑的时间。
场景二:安全运营的"知识大脑"。 在构建 AI 驱动的安全运营中心(AI-miniSOC)时,我做过一轮 Agent 框架选型,结论是 WeKnora 适合做知识大脑层------它擅长基于私有知识库的检索和推理,但不是通用 Agent 编排工具。把它和专门的执行引擎、编排层组合起来,能形成一个"知识→执行→编排"的完整栈:WeKnora 负责回答"该怎么办",执行层负责"去干"。
场景三:自动沉淀知识资产。 这是 WeKnora 的 Wiki 模式发挥威力的地方。持续的运营会产生大量原始材料------告警记录、事件复盘、巡检报告。Wiki 模式能让 Agent 从这些散乱文档里自动提炼出结构化的知识页面和知识图谱,把"运营过程"沉淀成"可复用的知识"。这比人工整理高效得多,也更可持续。
根据知识库的知识进行问答
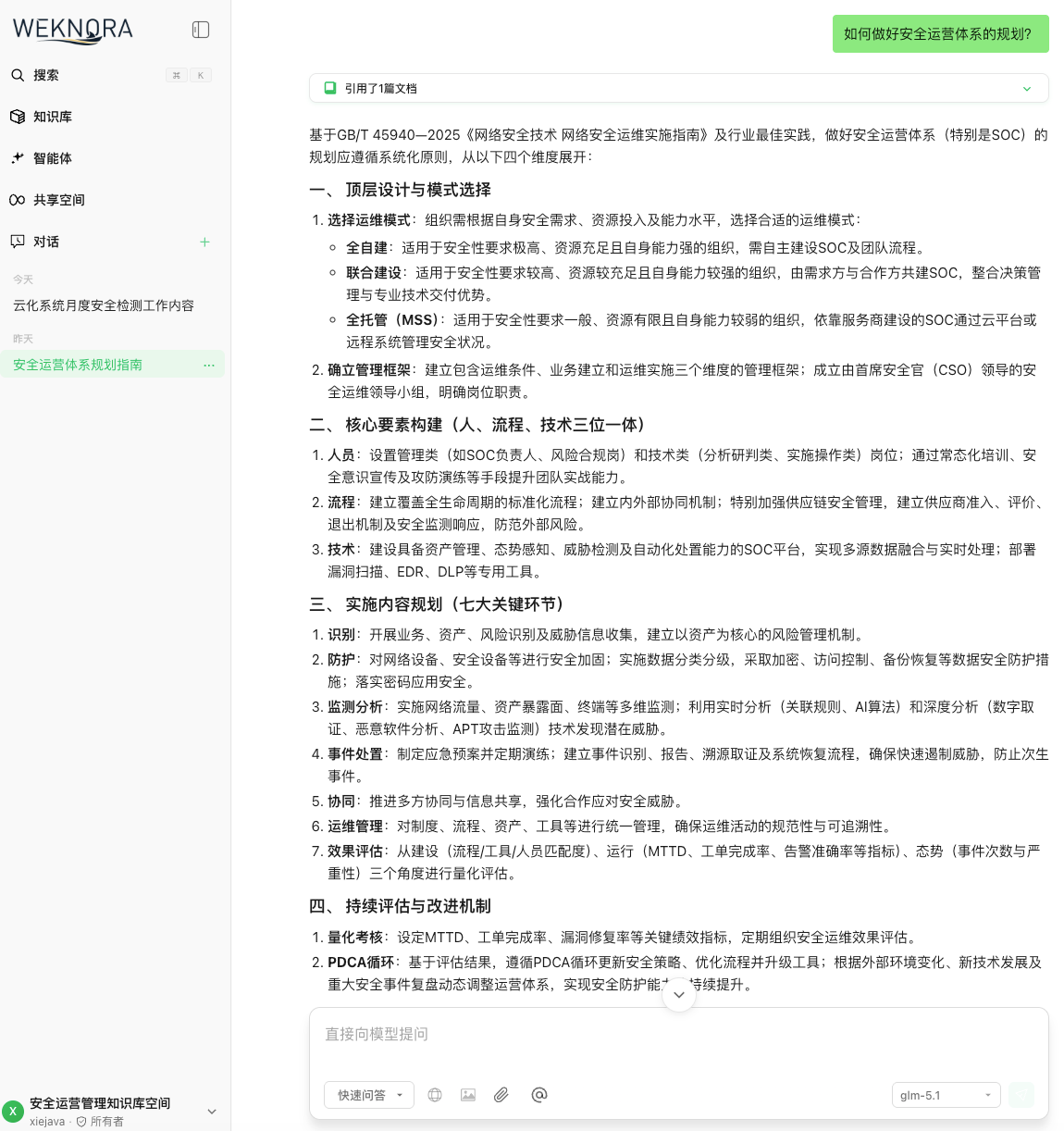
八、适合谁,以及一些诚实的局限
最后给一个明确的选型建议。
适合用 WeKnora 的情况:
- 有国产化、私有化部署要求的企业;
- 需要多团队、多租户共享知识库;
- 不满足于"问答",还想让知识自动结构化沉淀;
- 技术栈偏 Go / Vue,愿意自己维护部署。
一些诚实的局限(截至我使用的版本):
- Wiki 模式仍在快速迭代,万级以上文档规模的稳定性还需要验证;
- Agent 能力偏向"知识增强推理",不是通用 Agent 编排框架;
- 自研的 embedding / rerank 模型、语义分块等优化项还在路线图上,尚未完全落地;
- 配置陷阱多(比如我踩的 embedding 配置坑),文档对这类边角问题的覆盖不足,需要自己摸索。
一句话总结 :WeKnora 是目前国产开源里把"RAG + Agent + Wiki"三件事整合得最完整、工程化程度最高的知识框架。如果你的场景匹配,它值得认真评估------但做好踩坑的心理准备,尤其是部署后的检索验证环节,一定要像我这样逐层确认到 chunk_count 真的大于 0,才算真正落地。
相关链接
- 项目仓库:https://github.com/Tencent/WeKnora
- 官方网站:https://weknora.weixin.qq.com
- 微信对话开放平台:https://chatbot.weixin.qq.com
如果你也在部署 WeKnora 或类似的知识库,欢迎在评论区交流你踩过的坑。