在AI for Science(AI4S)领域,如何用一个大模型解决生命科学、化学、材料等多领域的跨学科任务,一直是学术界和工业界探索的圣杯。
传统做法通常依赖专用模型(如专门处理蛋白质的ESM或处理小分子的UniMol),或者依赖复杂的3D几何神经网络来捕捉空间相互作用。然而,这种多技术栈并存的现状,不仅导致不同领域间的知识难以迁移,也使得AI4S的研究难以直接复用主流大语言模型(LLM)庞大的工程生态。

近日,阿里 ATH-Token Foundry 联合中国人民大学高瓴人工智能学院提交了最新技术报告,开源了首个 统一科学语法多领域科学生成基础模型------LOGOS(Language Of Generative Objects in Science)。
LOGOS做出了一个极其大胆且优雅的尝试:丢弃显式3D坐标和几何网络,将蛋白质、小分子、材料、反应等所有异构对象及空间交互,统一编码为离散的Token序列,并在纯序列自回归范式下实现了多学科任务的全面超越。
在开源社区上,LOGOS已同步上线 HuggingFace模型库 及 GitHub仓库。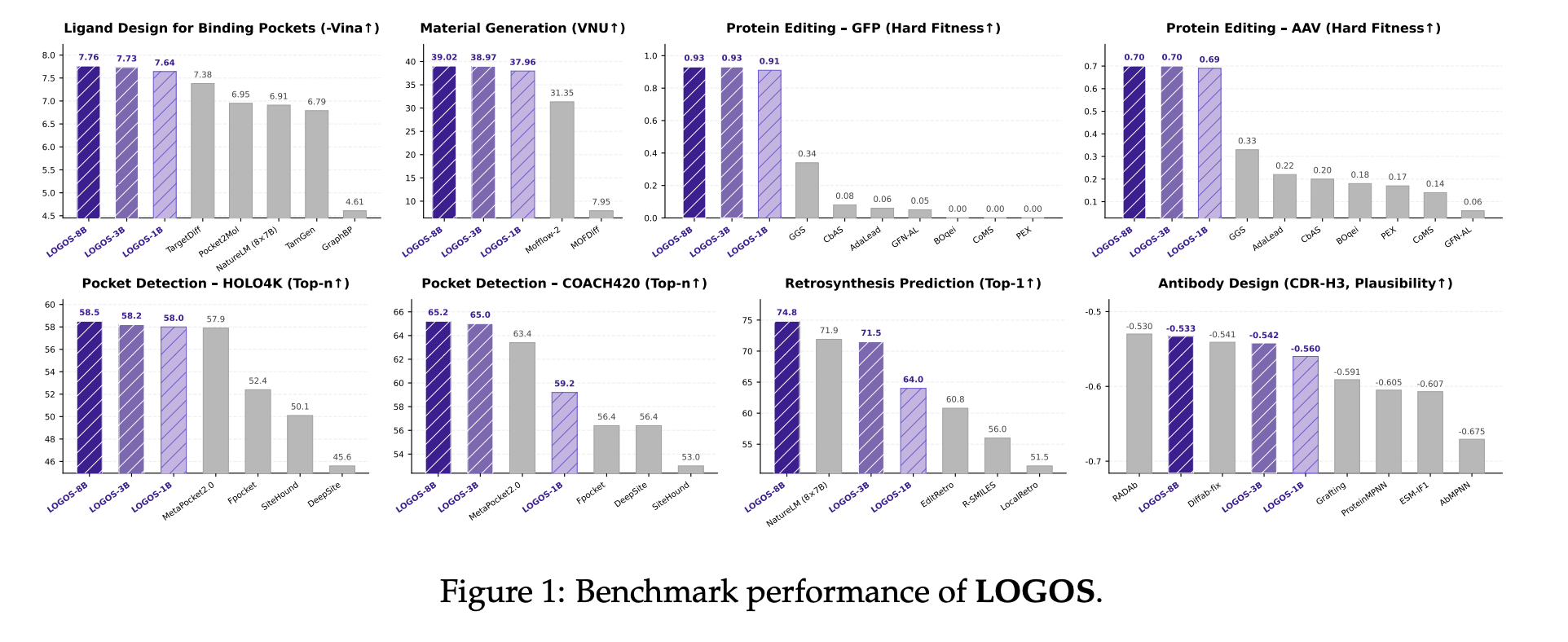
一、 核心思路:统一的"科学语法"与空间交互离散化
LOGOS的核心推论在于:尽管生物、化学、材料在符号表征上高度异构,但它们底层都遵循特定的组合规则、结构约束和交互语义。既然它们都是"自然的语言",就可以通过一套统一的形式语法(Unified Scientific Grammar)将其纳入同一个Token空间中。
1. 空间交互的"语法化"
处理3D空间相互作用(如蛋白质口袋与小分子配体的结合)通常需要复杂的3D坐标计算。LOGOS提出了空间交互离散化:
- 放弃显式的三维坐标输入,转而将3D空间接触模式和约束规律转化为序列文字描述。
- 比如在蛋白质口袋的表征中,模型不仅在氨基酸序列中插入
<PocketS>和<PocketE>边界符,还会根据侧链化学特性,将口袋残基直接展开为其对应的化学侧链 SMILES 字符串。 - 这种设计将原本属于"生物符号"的氨基酸与属于"化学结构"的小分子片段,在同一个表征维度上进行了对齐。
2. 形式与目标的完全等价
在传统的预训练-微调(BERT范式)中,预训练通常在做掩码重构(MLM)或对比对齐,而下游则是优化结合亲和力或合成可行性,二者存在显著的语义断层(Gap)。
LOGOS基于纯自回归架构,其预训练阶段的 Next-token Prediction,在形式和目标上与下游的"条件生成任务"完全一致。例如,在药物设计任务中,输入口袋序列直接预测配体SMILES,消除了传统方法中预训练和下游应用之间的鸿沟。

二、 极致的参数效率:1B模型跨多任务超越56B
研发团队开源了 1B、3B、8B 三种参数规模的模型。实验数据表明,由于科学语法的设计避免了模型能力在无关自然语言语料上的内耗,LOGOS表现出了极其恐怖的参数效率。
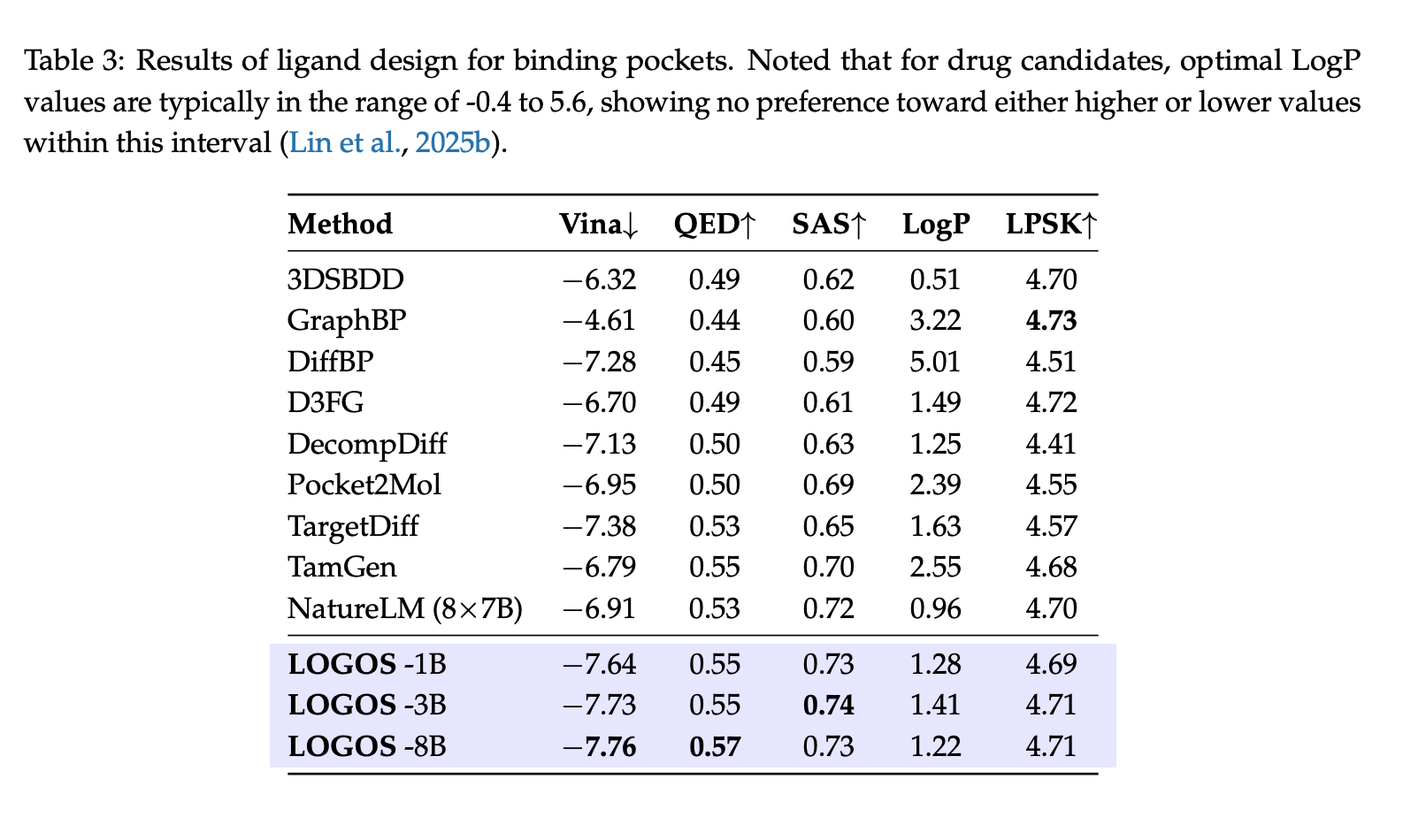
1. 口袋条件配体生成(药物设计)
在测试集评估中,仅有 1B 参数的 LOGOS-1B 模型,在关键指标 Vina Docking Score(结合亲和力)上达到了 -7.64,直接击败了参数量高达56B(8×7B)的 NatureLM 模型。同时,LOGOS在生成小分子的药物相似性(QED)和合成可行性(SAS)上均大幅领先依赖3D坐标的扩散模型(如TargetDiff)。
2. 逆合成预测
给定目标分子,预测其合成前体。在 USPTO-50K 标准基准上,LOGOS-8B 的 Top-1 准确率达到了 74.8%,超越了包括 LocalRetro 在内的所有专用和通用大模型baseline,展现了极强的化学键断裂与重组逻辑推理能力。
3. 突破性的材料创新(MOF材料生成)
在金属有机框架(MOF)材料生成任务中,衡量模型"能否探索未见过的化学空间"的核心指标是新构建单元比例(NBB)。LOGOS-8B 在该指标上达到了 17.78% ,相较于领域顶尖的基线模型(MOFFlow-2,10.10%)提升了 76%。
此外,LOGOS在蛋白质定向编辑(Hard Fitness任务得分0.93,提升174%) 、抗体CDR设计(AAR达79.82%)以及零3D结构依赖的口袋位点识别 等跨学科任务中,均拿到了匹配或超越领域专用方法的亮眼数据。
三、 探索实验的启示:为什么不用自然语言做交互界面?
在技术报告中,团队分享了几个非常关键的微调与消融实验结论,对未来 AI4S 基础模型的设计具有重要的参考价值:
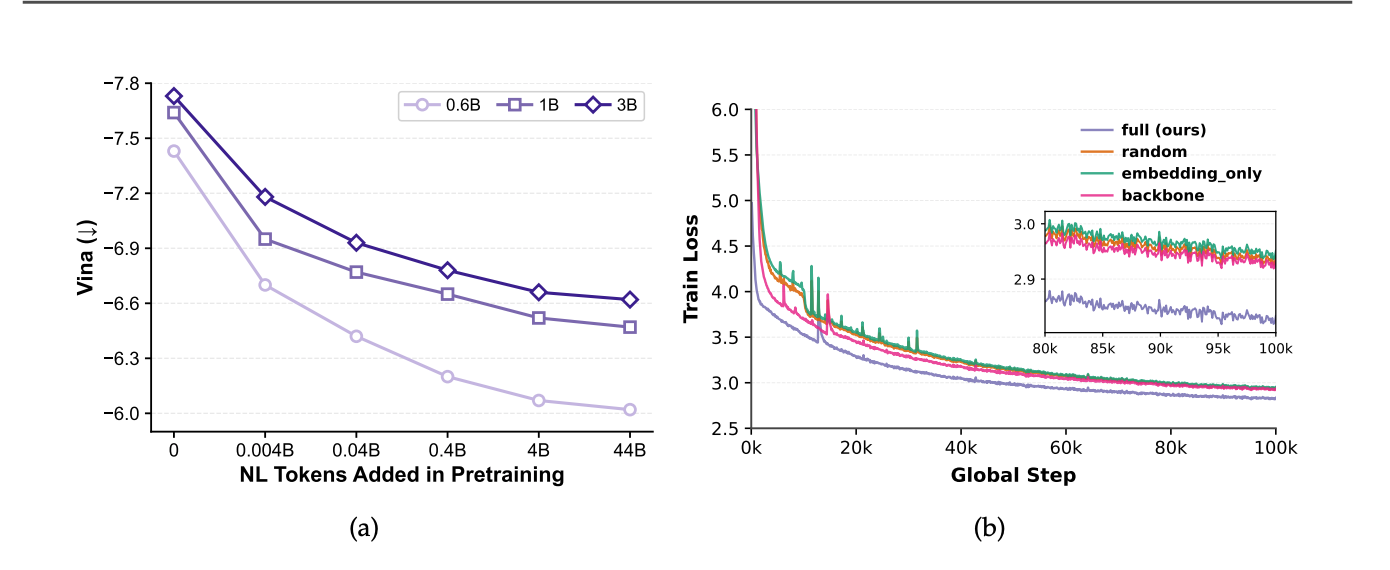
- 自然语言会稀释专业能力 :实验发现,在增量预训练阶段,若引入大量通用自然语言文本,模型在科学任务(如小分子生成)上的性能会随语言文本比例的增加而持续退化。在固定参数预算下,把容量留给本科学 modalities 效率更高。
- LLM的深度序列逻辑可复用:尽管不适合直接输入自然语言,但如果全盘继承 LLM(如 Qwen3 或 Llama3.2)的 Transformer 骨干网络(Backbone)权重作为初始化,模型的收敛速度和最终泛化性能远超全随机初始化。这说明 LLM 训练出的"长程依赖捕捉"和"上下文推理"等底层逻辑,在科学序列上是完全通用的。
- 多任务联合微调的协同效应 :将逆合成、药物生成、材料设计等数据混合进行联合 SFT 训练,其各项指标均优于独立任务单独微调。这意味着统一的语法打破了学科界限,化学反应中习得的断键规律,正向迁移到了药物分子的骨架搭建中,实现了"1+1>2"的协同效应。
四、 拥抱 LLM 成熟生态
对于工程落地而言,LOGOS 带来的最大隐形红利在于技术栈的并轨 。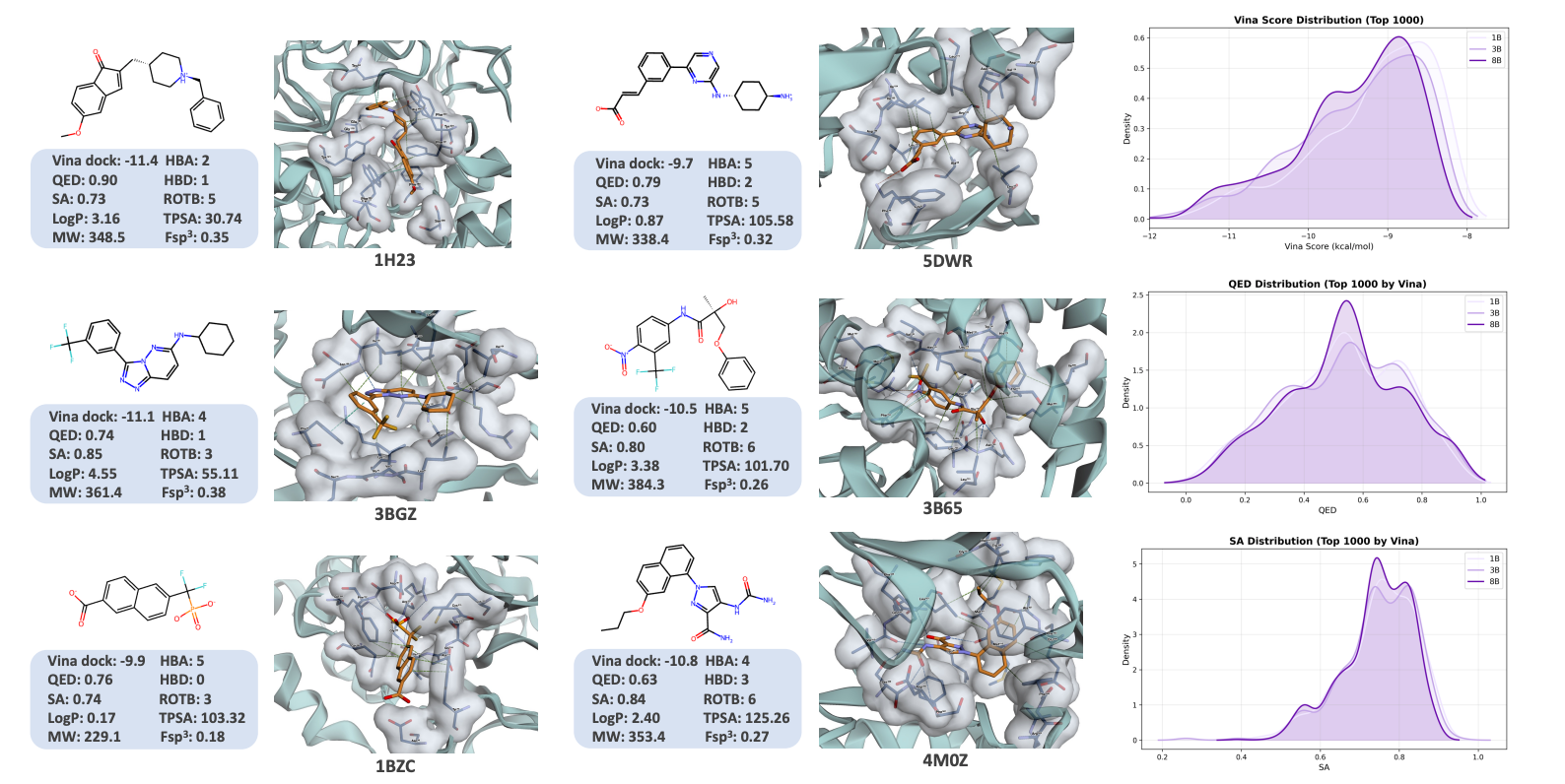
以往的3D几何模型需要构建完全独立的推理和量化工程基建。而 LOGOS 由于采用了与通用 LLM 共享的自回归架构,开发者和科研团队可以直接将模型部署在 vLLM 等业界成熟的加速推理框架中,甚至直接复用现成的模型量化、分布式微调工具链。这极大地降低了 AI4S 在工业级落地时的工程成本。
阿里的这一开源工作提供了一个清晰的信号:AI for Science 的未来可能并不需要一套独立于大模型之外的封闭技术栈;相反,通过设计科学语法,将物质世界深度对齐到自回归语言空间中,用大模型的基础设施作为全学科科学创新的统一入口,是一条完全可行的道路。 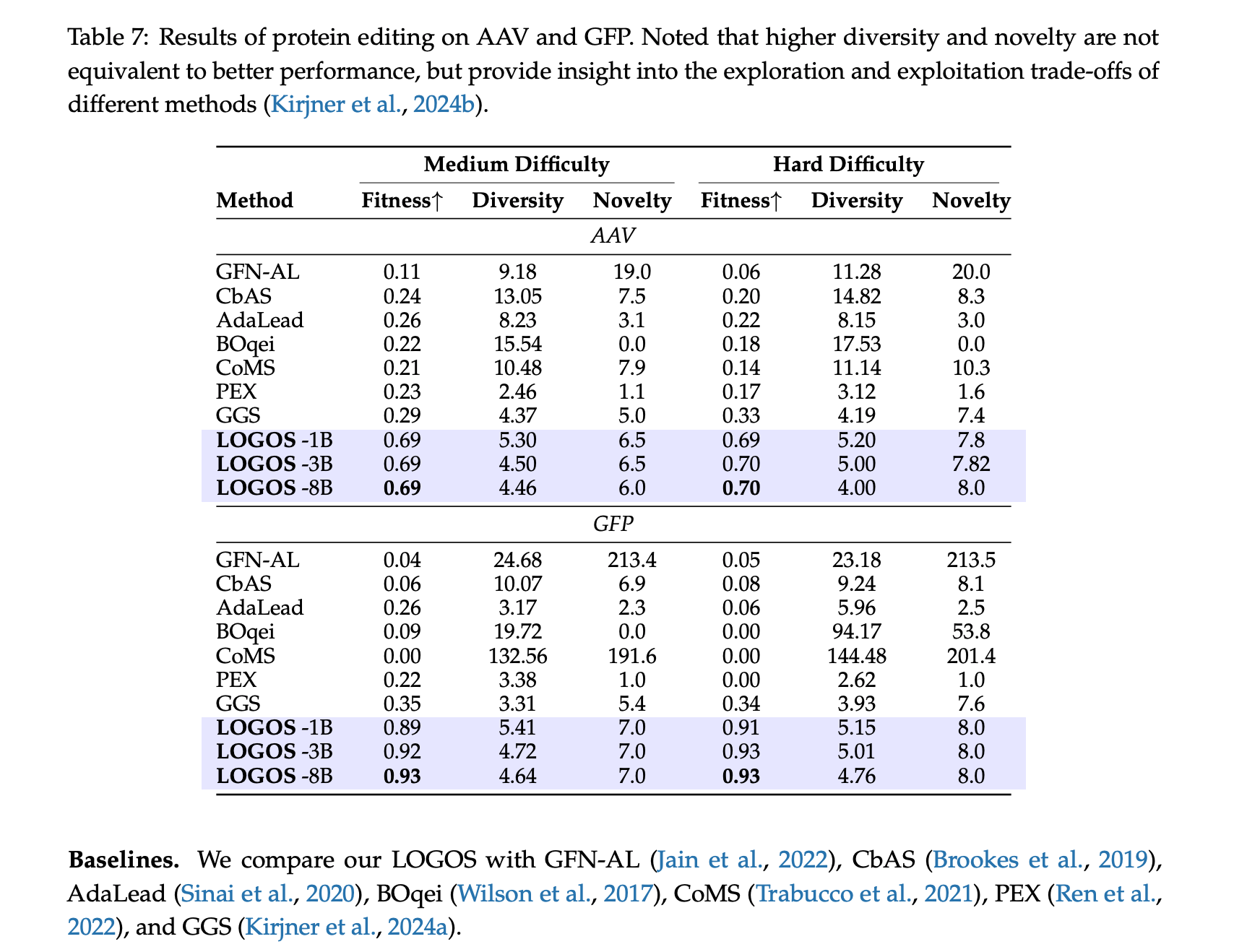
项目相关资源:
- GitHub 仓库 :LOGOS-Hub/LOGOS
- HuggingFace 模型库 :LOGOS-Hub
- 技术论文 PDF :arXiv:2606.16905