目录
干货分享,感谢您的阅读!
在大模型场景里,减少过拟合最有效的思路,通常不是简单地"把模型做小",而是把真正会随任务数据波动的那部分自由度做小,把已经学到的通用表示尽量保留下来。ALBERT 的因式分解嵌入与跨层参数共享、Adapter 的瓶颈模块、LoRA/DoRA/Prompt Tuning/QLoRA 的低秩或附加参数更新,本质上都是在限制下游任务可修改的参数子空间。ALBERT 论文甚至明确指出,参数缩减技术本身也起到了正则化作用,并帮助训练稳定与泛化;Adapter 与 LoRA 则分别用很少的任务参数逼近全参微调效果。
第二个关键结论是:更大的模型并不必然更容易过拟合。Deep Double Descent 表明,随着模型大小或训练 epoch 增加,测试误差可能先变差、再变好;OpenAI 的 Scaling Laws 又显示,更大的语言模型通常更样本高效,固定算力下的最优训练往往是"大模型 + 适量数据 + 不训练到完全收敛"。但一旦进入数据受限和高重复数据阶段,额外训练就会迅速失去收益。
工程上最稳的路线,通常是预训练或迁移学习打底 + 参数高效微调 + 温和正则化 + 严格监控验证集 。相比之下,剪枝和量化首先是压缩与部署技术;它们也能控制有效容量,但通常不是解决"训练中已出现明显过拟合"的第一优先级手段。
一、背景与动机
如果只用经典偏差---方差直觉去理解大模型,会很容易得出"参数越多越危险"的结论;但现代深度网络并不总遵循这种单峰的 U 型曲线。Deep Double Descent 指出,随着模型复杂度或训练时长继续增加,测试误差可能先恶化再改善;而 Scaling Laws 则指出,语言模型损失关于模型规模、数据规模和算力近似满足幂律关系,并且更大的模型往往更样本高效。换句话说,大模型的真正问题常常不是"太大",而是"自由度的使用方式不对"。
这也是为什么,今天讨论"过拟合",最好把两类场景分开看。从零预训练时,问题更像是:数据覆盖不够、重复 token 太多、训练过久、架构没有把容量放在真正有用的位置;下游微调时,问题更像是:监督数据有限,但你却让整个模型都跟着任务一起漂移。前者更关注数据---模型---算力配比,后者更关注可训练参数量与更新子空间。
TensorFlow 的中文官方教程给出的直观表述仍然非常适用:如果训练时间过长,模型会开始学习那些无法泛化到未见数据的模式;最好的防过拟合方式是更完整的数据覆盖,若做不到,第二好的方式就是正则化------即限制模型能"记住"的信息数量与类型。这个表述非常接近大模型时代的实战经验:不是压制容量本身,而是压制"无约束地记忆"。
二、过拟合的直观解释与诊断
从整理来看,训练集上会的,不等于真实世界里会的。官方 TensorFlow 中文教程把一个典型信号描述得很清楚:验证准确率先到峰值,随后停滞或下降;而训练继续进行时,模型开始从训练数据中学习那些无法泛化的模式。Google 的损失曲线文档也把"测试损失与训练损失明显分叉"列为典型异常。
(一)诊断指标说明
实战里最常用、也最有解释力的诊断指标,可以用下面几类去看:
- 训练---验证损失分叉:当训练损失继续下降,但验证损失在某一轮之后开始上升,通常就是最经典的过拟合形态。
- 泛化间隙:定义为
gap = L_val - L_train。间隙持续拉大,说明模型越来越擅长"解释训练集",但没有相同比例地提升对未见数据的表现。这个指标尤其适合对比不同正则化与 PEFT 方案。 - 校准误差与过度自信:很多模型即使验证准确率还可以,也可能在概率上过度自信。Mixup 相关研究表明,它能显著改善 calibration,这说明"是否过拟合"不能只看准确率,还可以看置信度是否失真。
- 损失地形的尖锐度:SAM 的原论文明确指出,在严重过参数化的模型里,只优化训练损失并不能保证泛化;因此可以额外观察 sharpness 或邻域损失,对"大模型训练损失很漂亮、验证表现却一般"的情况尤其有用。
(二)典型过拟合曲线
下面这段 Matplotlib 代码可以直接生成一个典型过拟合曲线理解:训练损失持续下降,验证损失先降后升。
python
import numpy as np
import matplotlib.pyplot as plt
epochs = np.arange(1, 51)
# 合成一组"看起来像真实训练"的损失
train_loss = 1.15 * np.exp(-epochs / 18) + 0.06
val_loss = 1.10 * np.exp(-epochs / 16) + 0.08
# 让验证损失在后半段出现过拟合反弹
turn_point = 18
val_loss[turn_point:] += 0.006 * (epochs[turn_point:] - turn_point) ** 1.25
best_epoch = int(epochs[np.argmin(val_loss)])
plt.figure(figsize=(8, 5))
plt.plot(epochs, train_loss, label="train_loss")
plt.plot(epochs, val_loss, label="val_loss")
plt.axvline(best_epoch, linestyle="--", label=f"best_epoch={best_epoch}")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.title("典型过拟合曲线:训练损失下降,验证损失先降后升")
plt.legend()
plt.tight_layout()
plt.show()还有一个经常被忽视、但在大模型里很重要的诊断点:区分预训练过拟合与微调过拟合。如果你在从零训练时看到的是低训练损失 + 大量重复数据 + 继续训练收益很小,那更像是"数据受限";如果你在下游任务上看到的是全参微调很快把训练集学满,但验证集没有同步变好,那更像是"可训练自由度过多"。两者的药方并不相同。
三、过拟合为什么发生
从工程角度看,过拟合通常不是一个单因子问题,而是模型结构、数据、训练流程、优化器和超参数同时失配的结果。TensorFlow 官方教程强调:更完整的数据覆盖是第一解法;当数据不足时,才需要借助正则化限制模型的记忆能力。另一方面,Scaling Laws 与 Data-Constrained LM 的结果又提醒我们:在大模型里,重复训练有限数据会很快进入收益递减区。
下图把常见成因整理成一张因果图,适合放进文章或 slide 里做总览。它不是某一篇论文的原图,而是根据官方教程、论文和文档做的结构化整理。

把上图翻译成更可执行的语言,大致有五类典型成因:
- 模型结构自由度过大:如果架构没有参数共享、没有瓶颈、没有稀疏路由,或者在小数据上直接做全参微调,那么模型很容易把任务数据当作一次"重写整个网络"的机会。ALBERT 和 Adapter 的成功,本质上都说明了:减少冗余自由度、增加共享与压缩表示,能显著改善参数效率与泛化。
- 数据覆盖不足或重复过多:官方教程明确指出,更完整的数据是最好的防过拟合方式;在大语言模型的 data-constrained 研究里,重复 token 超过一定程度后,继续增加训练算力的价值会迅速衰减。
- 训练时间过长、没有监控拐点:验证准确率见顶后还继续训练,往往就是在向训练噪声或偶然模式继续拟合。无论是 Lightning 的 EarlyStopping 还是 Hugging Face Trainer 的 EarlyStoppingCallback,本质都在干一件事:当监控指标不再改善时及时停下。
- 优化器与正则项配置不当:Decoupled Weight Decay Regularization 指出,在 Adam 这类自适应优化器里,L2 正则与真正的 weight decay 并不等价,因此 AdamW 才会成为更标准的选择。
- 学习率策略不匹配:Warmup 并不是"装饰品"。RAdam 的论文说明,warmup 能稳定自适应学习率的早期方差,并改善收敛与泛化;而 PyTorch 的余弦退火调度则提供了一个常见、稳定的学习率下降路径。
四、通过改进模型减少过拟合的方法思考整理
如果把"过拟合"理解成"模型自由度相对可用信息过大",那么有效方法大致分成四条主线:直接减少冗余自由度、把自由度变成条件激活、把更新限制在小子空间、把表示学习前移到自监督/迁移/多任务阶段。

架构层的改进,最值得优先理解的是参数共享、瓶颈和稀疏激活。ALBERT 在论文里明确采用了因式分解 embedding 与跨层参数共享,并指出这些参数缩减技术本身也起到了正则化作用,帮助训练稳定和泛化;Adapter 则把这种思想做成了更适合"下游任务插拔"的形式:在冻结原始网络参数的前提下,插入瓶颈结构,只训练少量新增参数。Houlsby 等人的结果显示,Adapter 在 GLUE 上与全参微调非常接近,但只增加少量任务参数。对中小数据场景,这类"冻结大骨干、只开小通道"的策略通常比直接让整个模型漂移更稳。
稀疏激活与模块化的代表是 Switch Transformer。它的核心不是把总参数做小,而是让不同样本只激活一部分参数,从而把"巨大容量"变成"按需使用的容量"。这类方法更适合超大规模预训练,因为它能在近似恒定计算量下获得更高总参数容量;但它不是一个"自动消灭过拟合"的按钮,而是更像一种更合理地分配容量的方法。优点是总容量可以很大、计算可控;代价是路由、通信和训练稳定性会明显变复杂。
显式正则化方面,L1/L2、Dropout、Norm、标签平滑和数据驱动正则化仍然是绕不开的基础层。TensorFlow 中文教程对 L1/L2 的解释非常直观:L1 把权重往零拉、鼓励稀疏;L2 惩罚大权重但通常不直接导致稀疏,因此更常见。AdamW 的意义在于把 weight decay 从 Adam 的动量/方差统计中解耦出来,让这个正则项更"像它本来应该有的样子"。Dropout 的官方文档则直接把它定义为一种防过拟合的随机失活技术;R-Drop 在此基础上进一步要求两次 dropout 子模型输出保持一致,从而减少参数自由度。BatchNorm/LayerNorm 则更多是稳定优化、改善梯度流与提高可训练性;它们有时也带来间接正则化,但不是"容量控制"的主力。标签平滑会把 one-hot 目标和均匀分布混合;MixUp 与 CutMix 会构造软标签与混合样本,常常带来更平滑的决策边界和更好的校准。
下面这张图把"正则化到底在约束什么"画成了一个机制图,便于快速记忆。
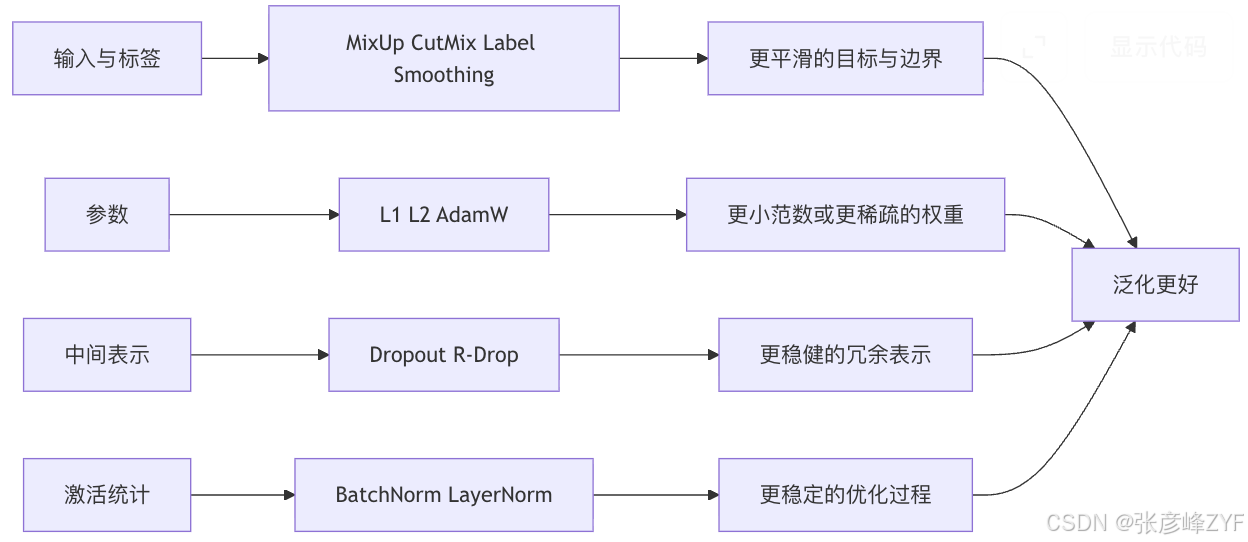
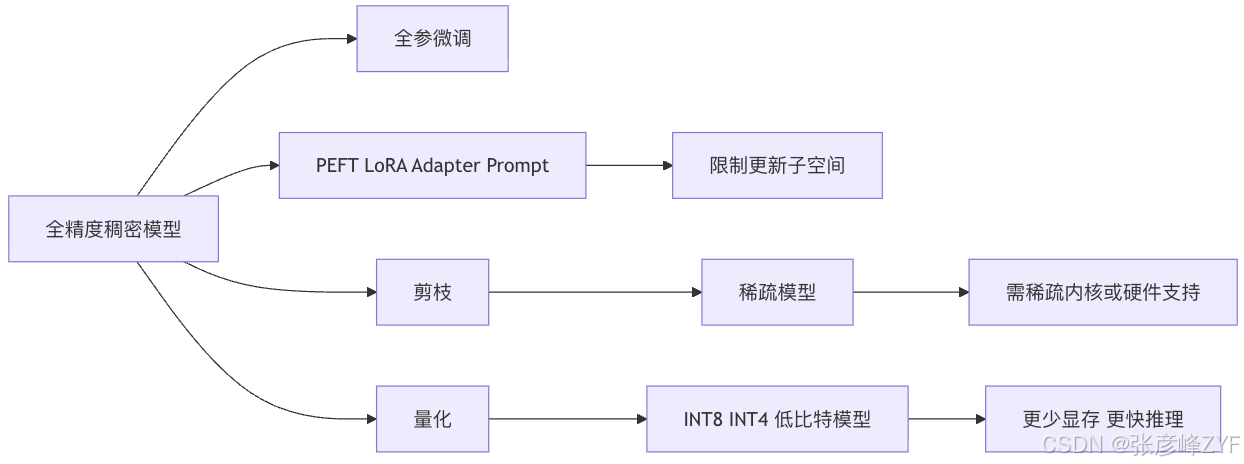
参数高效化是大模型时代最值得优先采用的一条路线。LoRA 的核心是冻结预训练权重,只在每层里加入可训练的低秩矩阵更新;原论文报告,在 GPT-3 175B 场景里,它可把可训练参数量降到全参微调的万分之一量级,并把 GPU 显存需求降到约三分之一,同时保持相当甚至更好的效果。DoRA 则进一步把权重更新分成方向与幅值两部分,提升了 LoRA 的学习能力与稳定性,而且仍然不增加额外推理开销。QLoRA 再往前一步:把冻结骨干量化到 4bit,让 65B 模型在单张 48GB GPU 上也能做高效微调。Hugging Face 的中文 Prompt Tuning 实践材料则展示了另一种极端:连 backbone 权重都不改,只训练额外提示参数。这些方法的共同点不是"压缩模型本体",而是约束更新空间------这通常正是小样本微调场景里最有效的抗过拟合手段。
相比之下,剪枝与量化更像是"压缩部署优先,顺带控制有效容量"的方法。SparseGPT 表明,大模型可以在一次性剪枝下达到 50% 以上稀疏率且精度损失很小,并兼容 2:4/4:8 半结构化模式;Wanda 用权重与激活共同决定哪些参数该剪掉;GPTQ 让 175B GPT 可以做 3bit/4bit 量化并在支持的 GPU 上获得明显的端到端推理加速;AWQ 的思路则是保护最重要的少量通道,减少低比特带来的误差。要注意的是,PyTorch 官方 torchao 文档专门提醒:仅仅把权重置零,并不会自动带来推理时延下降;真正的收益取决于是否匹配到稀疏内核或低比特后端。也正因为如此,剪枝和量化更适合放在"模型已经足够能泛化"的后半程,而不是代替前期的结构设计与训练正则。
下面这张图可以直接作为"压缩路线图"示意。
自监督、迁移学习与多任务学习,在很多时候反而是"最强的抗过拟合手段",因为它们减少了下游监督标签对模型参数的直接塑形需求。T5 用统一的 text-to-text 框架系统比较了预训练目标、架构和迁移方式,证明了大规模迁移学习的普适性;FLAN 则进一步证明,把很多任务一起做 instruction tuning,能够显著提高对未见任务的泛化。对于现实任务来说,这意味着:**与其在 5k 条标注数据上让 70 亿参数全部更新,不如先通过通用预训练和多任务共享把"会什么"学好,再只让任务相关的一小部分参数改变。**
最后,训练策略必须和结构方法联动。Warmup 能稳定 Adam/RMSprop 这类自适应优化器的早期方差;余弦退火提供了平滑衰减的学习率路径;EarlyStopping 用验证集指标来阻断"继续拟合训练噪声"的过程;SAM 则在"大模型训练损失很好看但泛化一般"时尤其有价值,因为它直接把邻域 sharpness 加入优化考量。单独看,这些方法像训练技巧;和架构/PEFT 结合起来看,它们其实都是在控制可利用自由度的时间轨迹。
五、方法对比与取舍
我们把近年的代表性论文与官方实现整理成一张工程决策表。其中"实现复杂度"和"对推理性能的影响"属于结合论文结构、Hugging Face/PyTorch/torchao 官方实现做出的工程判断,目的是便于快速选型。
| 方法 | 核心思想 | 优点 | 局限 | 适用场景 | 实现复杂度 | 对推理性能的影响 |
|---|---|---|---|---|---|---|
| 参数共享 | 共享层参数、因式分解嵌入 | 直接减少冗余自由度;有机会把"更大深度"做成"更少参数" | 设计阶段就要改骨干;共享过强可能欠拟合 | 从零预训练、想提高参数效率 | 中 | 通常中性,更多是省参数与显存 |
| 瓶颈 Adapter | 冻结骨干,只训练插入层 | 很适合小数据与多任务;任务隔离好 | 需要插入额外模块;不如 LoRA 那样容易 merge | 下游微调、多租户服务 | 中 | 轻微额外开销,取决于是否融合 |
| LoRA / DoRA / Prompt Tuning | 限制更新到低秩或附加提示子空间 | 极大降低可训练参数;通常更稳;显存友好 | rank、target_modules 需要调;过强限制会欠拟合 | 大模型下游微调 | 中 | LoRA/DoRA 通常可做到近似无额外开销;Prompt 影响很小 |
| L1 / L2 / AdamW | 在损失或更新中约束大权重 | 简单、适用面最广,是默认基线 | 强度过大易欠拟合;强度过小效果弱 | 几乎所有训练场景 | 低 | 无影响 |
| Dropout / R-Drop | 训练时随机失活,并约束不同 dropout 子模型输出一致 | 对中等数据量很有效;实现直接 | p、KL 权重等需要调;并非所有 LLM 任务都最优 | 分类、翻译、理解任务 | 低到中 | 推理阶段通常无影响 |
| BatchNorm / LayerNorm | 稳定激活分布与梯度流 | 训练更稳、可支持更大学习率 | 不是直接减少参数自由度;BN 对 batch 统计更敏感 | CNN、Transformer、各类深网 | 低 | 通常无或极小影响 |
| Label Smoothing / MixUp / CutMix | 用软标签或混合样本平滑目标函数 | 改善泛化和校准;对分类尤其稳妥 | 前提是增强不破坏语义标签 | 分类和判别任务 | 低到中 | 无影响 |
| 稀疏激活与 MoE | 只激活部分专家/模块 | 同等计算下可用更大总容量 | 路由、通信、稳定性复杂 | 超大规模预训练 | 高 | 单 token 计算可控,但系统复杂度更高 |
| 剪枝 | 删除部分权重或通道,降低有效容量 | 可做后处理压缩;也可与稀疏训练结合 | 不一定自动提速;无内核支持时收益有限 | 部署前压缩、研究有效容量 | 中到高 | 强依赖硬件与稀疏模式 |
| 量化 / QLoRA / GPTQ / AWQ | 降低权重位宽,或量化骨干再做 PEFT | 显存和带宽收益显著;常能加速推理 | 首要目标是压缩,不是首选抗过拟合手段 | 显存受限微调、部署优化 | 中 | 在支持后端上通常正向 |
| 自监督 / 迁移 / 多任务 | 先学通用表示,再在任务上少量适配 | 最强的数据效率手段之一 | 预训练成本高;任务不匹配时收益受限 | 小标注数据、有预训练骨干时 | 高 | 推理通常无额外影响 |
如果只看"减少过拟合"的优先级,而不把部署压缩算进去,一个很实用的排序是:先做迁移/多任务与 PEFT,再做温和正则化与学习率策略,最后才考虑剪枝/量化。原因很简单:前两者是在"减少错误的更新",后两者更多是在"压缩已经训练好的东西"。对大多数下游微调任务,这是收益/风险比最高的顺序。
六、关键参考与中文要点
下面这几组参考可能帮助我们把概念连成一张图的入口。
- 中文直觉入门:TensorFlow 中文《过拟合与欠拟合》最适合建立直觉,尤其是"训练更久不一定更好""更完整数据优先于正则化"的部分;Google Developers 的中文《过拟合:解读损失曲线》适合建立曲线诊断能力。
- 参数共享与瓶颈架构:ALBERT 适合看"参数缩减为什么本身就能像正则化一样工作";Houlsby Adapter 适合看"如何在冻结骨干的前提下,用瓶颈模块做高效迁移"。
- 参数高效微调主线:LoRA 是低秩更新的起点;QLoRA 说明了低比特骨干 + LoRA 的内存效率;DoRA 说明了如何进一步弥合 LoRA 与全参微调的能力差距。
- 官方实现材料:Hugging Face PEFT 的 LoRA 文档适合看工程入口;中文 Prompt Tuning cookbook 适合看"冻结骨干、只训练附加参数"到底意味着什么。
- 迁移与多任务:T5 适合看"统一任务形式 + 大规模迁移学习"的系统视角;FLAN 适合看"多任务/指令微调如何提升未见任务泛化"。
- 训练正则与损失地形:SAM 适合理解"大模型里为什么只看训练损失不够";R-Drop 适合把 dropout 从"随机技巧"提升到"输出一致性正则"。
- 数据驱动正则化:PyTorch/Torchvision 关于 label smoothing、MixUp、CutMix 的官方文档和示例,最适合对照着代码落地;Mixup 的校准研究则补上了"为什么它不只提高精度,也经常改善概率可信度"。
- 压缩与部署:SparseGPT、GPTQ、AWQ 和 torchao 文档最适合放进"训练后半程或部署阶段"阅读,帮助区分"哪些方法是为了泛化,哪些方法主要是为了压缩"。
七、实践建议清单与可复制代码片段
如果你只想要一套最快上手、又尽量少踩坑的路线,可以按下面的顺序执行。它覆盖中小模型到超大预训练骨干的通用情形,默认你使用 PyTorch 或 Hugging Face 生态。
- 先分场景:如果是从零训练,先检查数据覆盖、重复率和架构归纳偏置;如果是下游微调,先默认"不要全参微调",优先从 LoRA/Adapter/Prompt Tuning 开始。
- 先降可训练参数,再谈强正则:对小数据场景,PEFT 往往比"全参微调 + 更大 dropout"更稳,因为它直接减少了更新子空间。
- 把 AdamW、warmup、cosine、early stopping 当成默认骨架:这套组合不是万金油,但在大多数现代训练里是比"固定学习率一路跑到底"更稳的起点。
- 分类任务优先尝试软目标正则:label smoothing、MixUp、CutMix 往往是收益很高、代价很低的先手;如果使用 dropout,可进一步考虑 R-Drop。
- 压缩放在后面做:先保证验证集泛化,再做量化/剪枝;若你追求真实推理收益,优先选择有后端支持的 int8/int4 或 2:4 半结构化稀疏,而不是只做"逻辑上删掉一些权重"。
- 别指望正则化替代正确的模型尺寸与结构:TensorFlow 官方示例里,L2 和 Dropout 虽然改善了"大模型"的行为,但仍未超过更合适的小基线模型,这说明正则化不能无限弥补模型---数据错配。
下面给出三段可以直接复制的代码,相对是一个足够稳、足够清晰、适合扩展的起点。相关 API 与思路分别对应 PyTorch 的 AdamW / scheduler / loss、Hugging Face PEFT,以及 torchao / PyTorch pruning 教程。
python
# 代码片段一:PyTorch 稳定训练骨架
# 目标:AdamW + warmup + cosine + label smoothing + gradient clipping + early stopping
import copy
import torch
from torch import nn
from torch.optim import AdamW
from torch.optim.lr_scheduler import LinearLR, CosineAnnealingLR, SequentialLR
class EarlyStopper:
def __init__(self, patience=3, min_delta=1e-4):
self.patience = patience
self.min_delta = min_delta
self.best = float("inf")
self.bad_count = 0
self.best_state = None
def step(self, model, val_loss):
if val_loss < self.best - self.min_delta:
self.best = val_loss
self.bad_count = 0
self.best_state = copy.deepcopy(model.state_dict())
return False
self.bad_count += 1
return self.bad_count >= self.patience
device = "cuda" if torch.cuda.is_available() else "cpu"
model = MyModel().to(device) # 你自己的模型
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
optimizer = AdamW(model.parameters(), lr=3e-4, weight_decay=0.01)
num_epochs = 20
warmup_epochs = 2
warmup = LinearLR(optimizer, start_factor=0.1, total_iters=warmup_epochs)
cosine = CosineAnnealingLR(
optimizer,
T_max=max(1, num_epochs - warmup_epochs),
eta_min=1e-6
)
scheduler = SequentialLR(
optimizer,
schedulers=[warmup, cosine],
milestones=[warmup_epochs]
)
stopper = EarlyStopper(patience=3, min_delta=1e-4)
for epoch in range(num_epochs):
model.train()
train_loss_sum = 0.0
train_count = 0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
logits = model(x)
loss = criterion(logits, y)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
train_loss_sum += loss.item() * x.size(0)
train_count += x.size(0)
model.eval()
val_loss_sum = 0.0
val_count = 0
with torch.no_grad():
for x, y in val_loader:
x, y = x.to(device), y.to(device)
logits = model(x)
loss = criterion(logits, y)
val_loss_sum += loss.item() * x.size(0)
val_count += x.size(0)
train_loss = train_loss_sum / train_count
val_loss = val_loss_sum / val_count
scheduler.step()
print(
f"epoch={epoch+1:02d} "
f"train_loss={train_loss:.4f} "
f"val_loss={val_loss:.4f} "
f"lr={optimizer.param_groups[0]['lr']:.2e}"
)
if stopper.step(model, val_loss):
print(f"early stop at epoch {epoch+1}")
break
if stopper.best_state is not None:
model.load_state_dict(stopper.best_state)
# 代码片段二:Hugging Face PEFT 的 LoRA 起步模板
# 说明:target_modules 需要按具体模型家族调整
from transformers import AutoModelForSequenceClassification
from peft import LoraConfig, TaskType, get_peft_model
base_model = AutoModelForSequenceClassification.from_pretrained(
"roberta-base",
num_labels=2
)
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["query", "value"], # 不同模型名字可能不同
bias="none"
)
model = get_peft_model(base_model, lora_config)
model.print_trainable_parameters()
# 代码片段三:一个"压缩后处理"示例
# 说明:量化优先考虑有后端支持的场景;剪枝做完后不一定自动提速
# A. torchao 的 int4 weight-only 量化
from torchao.quantization import Int4WeightOnlyConfig, quantize_
quantize_(model, Int4WeightOnlyConfig(group_size=32))
# B. PyTorch 的简单非结构化剪枝
import torch.nn.utils.prune as prune
# 假设 model.classifier 是一个线性分类头
prune.l1_unstructured(model.classifier, name="weight", amount=0.3)
prune.remove(model.classifier, "weight") # 将 mask 融入权重,便于导出与部署先用预训练和参数高效微调减少"需要被学坏的参数,再用 AdamW、学习率调度、温和正则和早停把训练过程跑稳,最后才把剪枝/量化用于部署优化。这是当前从中小模型到超大模型都最通用、最不容易走偏的一条线。