摘要
实时流式视频编辑(Video-to-Video, V2V)是直播、游戏等交互式场景的关键需求,但时序一致性与推理吞吐的双重约束使其极具挑战。NVIDIA 联合 MIT/THU/NUS/HKU 提出 SANA-Streaming,通过算法-系统协同设计,在单张 RTX 5090 上实现 1280x704 分辨率、24 FPS 端到端实时视频编辑。核心贡献包括:混合扩散 Transformer 架构(GDN 线性注意力 + softmax 窗口注意力)、Cycle-Reverse 正则化训练策略、以及面向 Blackwell 架构的混合精度量化系统优化。
论文 :SANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer
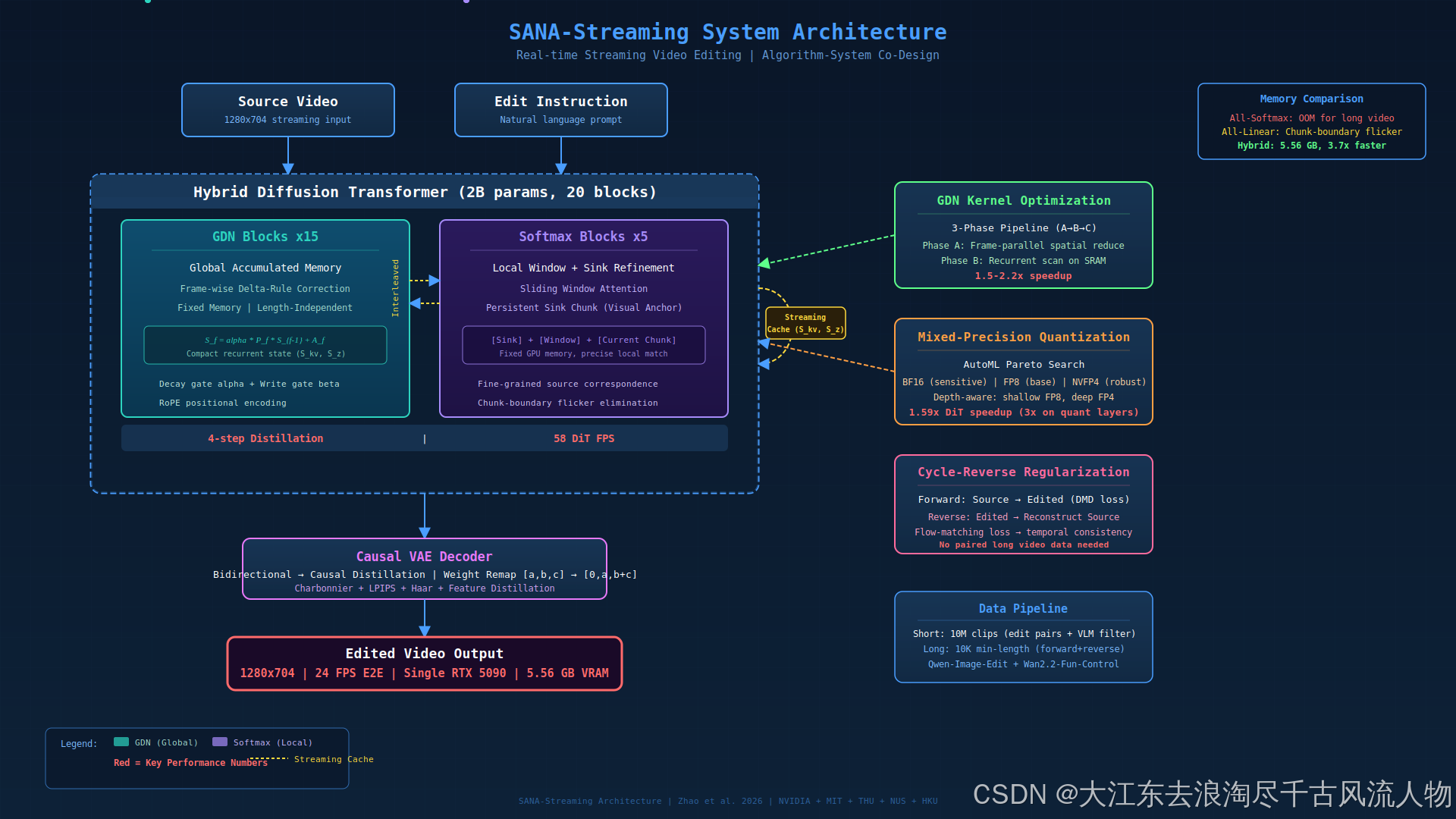
图 1:SANA-Streaming 系统整体架构。混合 DiT 由 15 个 GDN 块(全局记忆)和 5 个 Softmax 块(局部精炼)交替组成,配合 GDN Kernel 优化和混合精度量化实现 RTX 5090 上 24 FPS 实时推理。重绘自 design skill
一、问题背景
现有视频编辑方法(VACE、OpenVE、Lucy-Edit 等)主要面向离线短片段编辑,无法满足实时流式场景需求。核心矛盾在于:
| 注意力机制 | 优势 | 劣势 |
|---|---|---|
| Softmax 全注意力 | 局部建模精确,源帧对应保真 | KV Cache 随视频长度线性增长,内存不可控 |
| 线性注意力(SANA-Video) | 固定内存,适合流式 | 局部信息不足,chunk 边界闪烁 |

图 2:SANA-Streaming 系统概览,支持分钟级 1280x704 视频编辑,内存有界,单卡实时。来源:SANA-Streaming Fig 1
SANA-Video 的全线性注意力方案虽然内存友好,但注意力图过于均匀(Figure 3(b)),导致相邻 chunk 之间出现明显的外观跳变。直接替换为 softmax 注意力则内存爆炸。这一矛盾驱动了混合架构的设计。
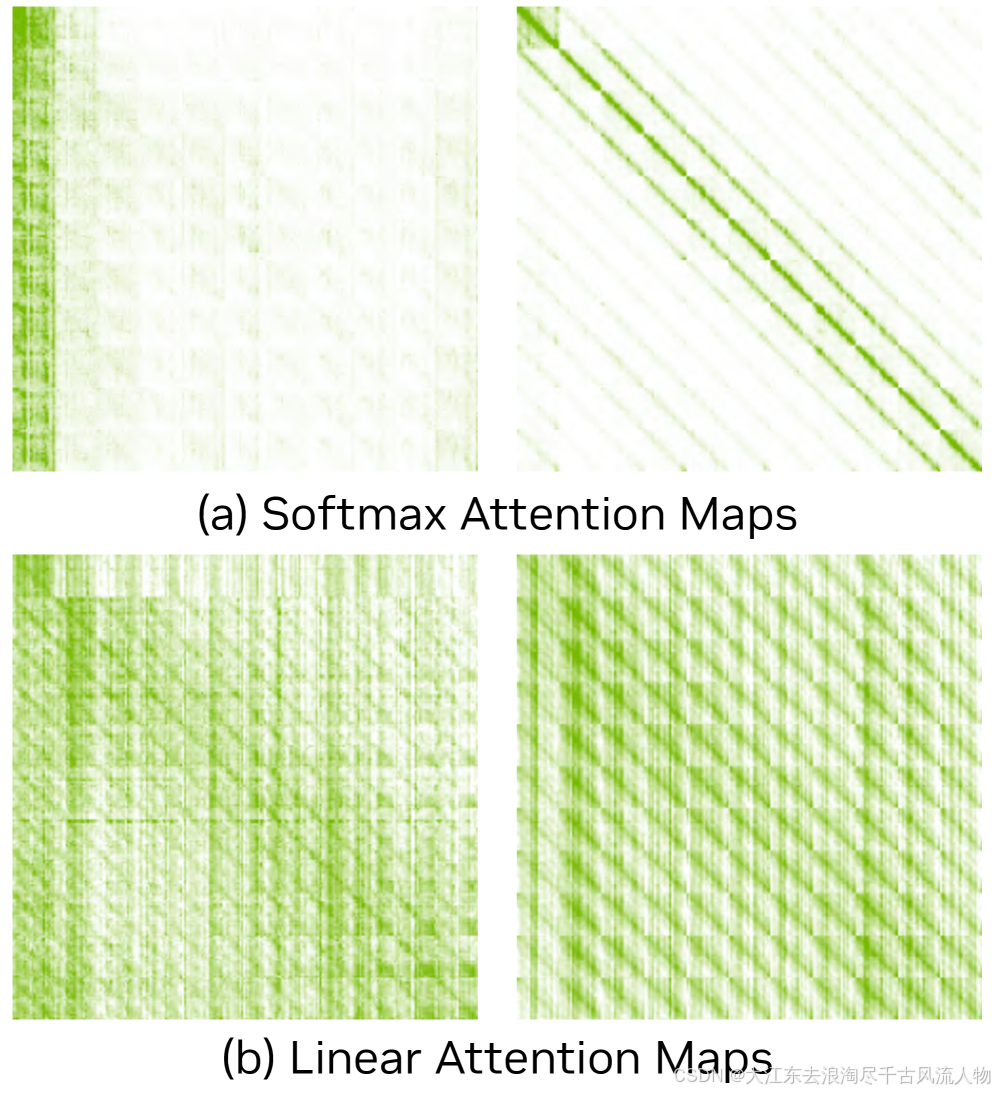
图 3:Softmax 注意力(左)聚焦局部,线性注意力(右)分布均匀但缺乏局部性。来源:SANA-Streaming Fig 3
二、核心方法
2.1 混合扩散 Transformer 架构
SANA-Streaming 的 DiT 包含 20 个 Transformer block,其中 15 个使用 Gated DeltaNet(GDN)线性注意力 ,5 个均匀插入 softmax 窗口注意力。两类 block 分工明确:
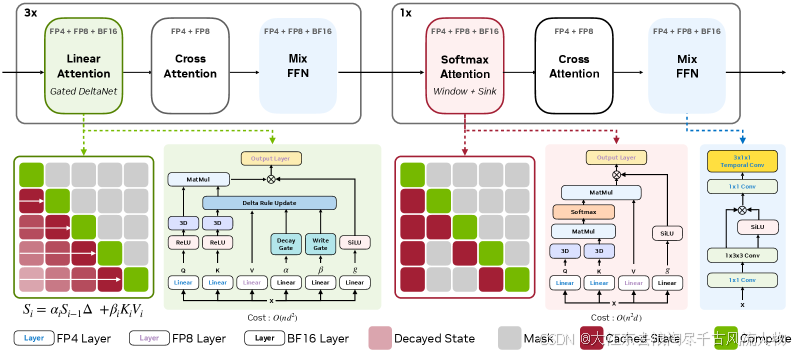
图 4:混合流式扩散 Transformer。GDN 块和 Softmax 块交替排列,每层使用最优精度。来源:SANA-Streaming Fig 2
GDN Block -- 全局累积记忆
GDN 以帧为单位更新循环状态,每个 block 维护一个固定大小的递推矩阵 ( S f k v , S f z ) (S_f^{kv}, S_f^z) (Sfkv,Sfz):
S f k v = α f S f − 1 k v ( I − β f k ^ f k ^ f ⊤ ) + β f v f k ^ f ⊤ S_f^{kv} = \alpha_f S_{f-1}^{kv}(I - \beta_f \hat{k}_f \hat{k}_f^\top) + \beta_f v_f \hat{k}_f^\top Sfkv=αfSf−1kv(I−βfk^fk^f⊤)+βfvfk^f⊤
其中 α f \alpha_f αf 为衰减门控, β f \beta_f βf 为写入门控。关键在于 delta-rule 校正 :不是直接写入 v f k f ⊤ v_f k_f^\top vfkf⊤,而是只写入残差,使循环状态更鲁棒。输出通过归一化读出:
o f = W o ( g f ⊙ S f k v q ^ f ( S f z ) ⊤ q f + ϵ ) o_f = W_o \left( g_f \odot \frac{S_f^{kv} \hat{q}_f}{(S_f^z)^\top q_f + \epsilon} \right) of=Wo(gf⊙(Sfz)⊤qf+ϵSfkvq^f)
流式推理时,每个 GDN block 只缓存上一个 chunk 的末尾状态 ( S k v , S z ) (S^{kv}, S^z) (Skv,Sz) 作为下一个 chunk 的初始状态,内存与视频长度无关。
Softmax Block -- 局部窗口 + Sink 精炼
每个 chunk 的注意力范围限制为:
- 自身(当前 chunk 的所有 token)
- Sink chunk(第一个 chunk,作为全局视觉锚点)
- 局部窗口(相邻若干 chunk)
相比全序列注意力,内存消耗固定;相比纯线性注意力,局部匹配精度大幅提升。
架构效果:混合设计仅需 5.56 GB VRAM 即可处理长视频,速度是全 softmax 方案的 3.7 倍。
2.2 Cycle-Reverse 正则化
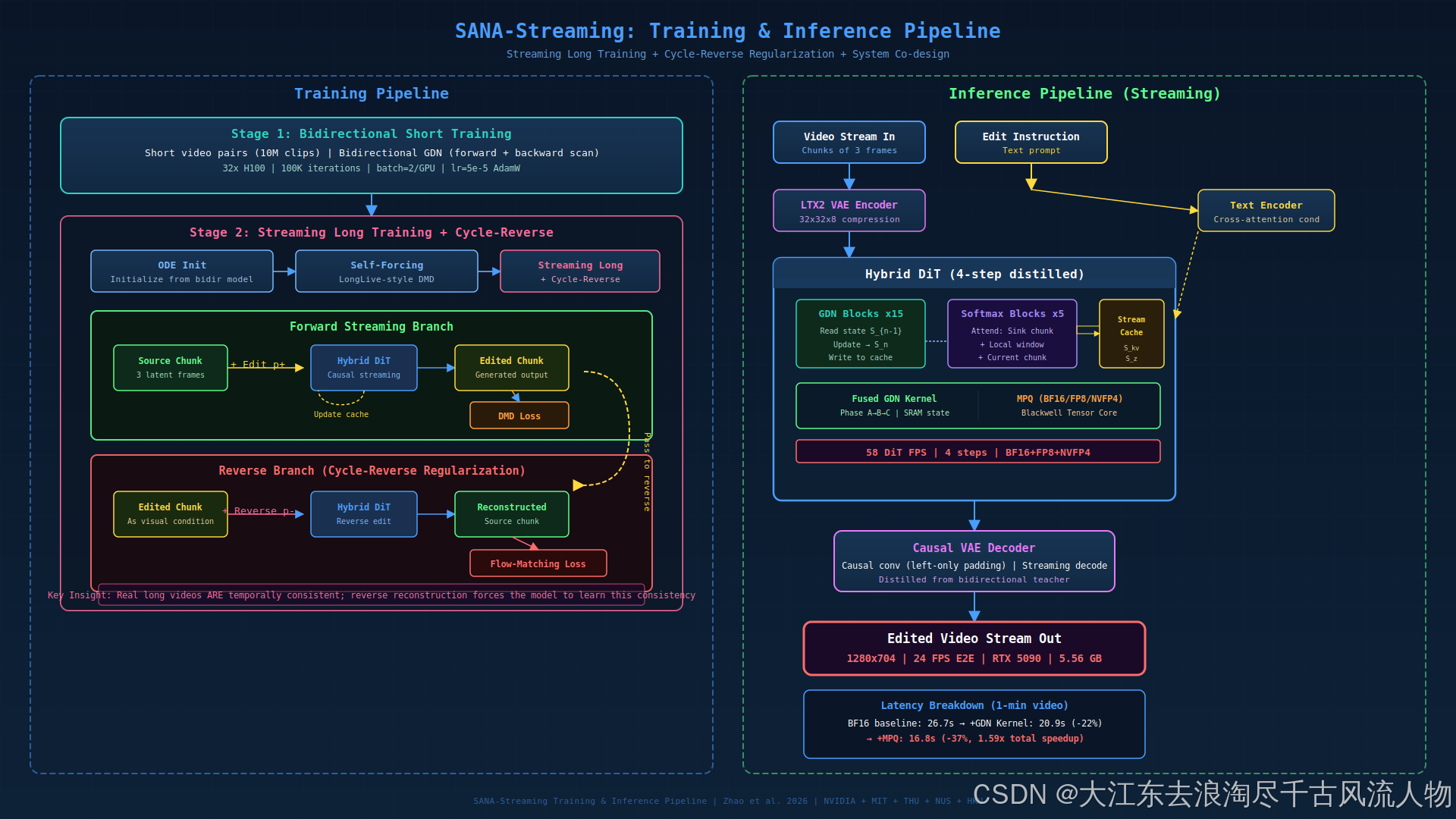
图 5:SANA-Streaming 训练与推理全流程。左侧为两阶段训练(含 Cycle-Reverse 正则化),右侧为流式推理流水线。重绘自 design skill
长视频编辑缺乏成对训练数据(没有分钟级的源-编辑视频对)。SANA-Streaming 采用两阶段训练策略:
流式长训练:沿用 LongLive 框架,模型自回归生成编辑 chunk,每个 chunk 用 DMD(Distribution Matching Distillation)损失与短视频教师对齐。
Cycle-Reverse 正则化:
- 正向 :源视频 + 编辑指令 → \to → 生成编辑 chunk
- 反向 :将生成的编辑 chunk 作为条件,配合反向指令 → \to → 重建源视频 chunk
- 反向分支使用 flow-matching 损失对齐原始源帧
#mermaid-svg-E5fIUtvsg85oHMJ8{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-E5fIUtvsg85oHMJ8 .error-icon{fill:#552222;}#mermaid-svg-E5fIUtvsg85oHMJ8 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-E5fIUtvsg85oHMJ8 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .marker.cross{stroke:#333333;}#mermaid-svg-E5fIUtvsg85oHMJ8 svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-E5fIUtvsg85oHMJ8 p{margin:0;}#mermaid-svg-E5fIUtvsg85oHMJ8 .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .cluster-label text{fill:#333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .cluster-label span{color:#333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .cluster-label span p{background-color:transparent;}#mermaid-svg-E5fIUtvsg85oHMJ8 .label text,#mermaid-svg-E5fIUtvsg85oHMJ8 span{fill:#333;color:#333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .node rect,#mermaid-svg-E5fIUtvsg85oHMJ8 .node circle,#mermaid-svg-E5fIUtvsg85oHMJ8 .node ellipse,#mermaid-svg-E5fIUtvsg85oHMJ8 .node polygon,#mermaid-svg-E5fIUtvsg85oHMJ8 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-E5fIUtvsg85oHMJ8 .rough-node .label text,#mermaid-svg-E5fIUtvsg85oHMJ8 .node .label text,#mermaid-svg-E5fIUtvsg85oHMJ8 .image-shape .label,#mermaid-svg-E5fIUtvsg85oHMJ8 .icon-shape .label{text-anchor:middle;}#mermaid-svg-E5fIUtvsg85oHMJ8 .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-E5fIUtvsg85oHMJ8 .rough-node .label,#mermaid-svg-E5fIUtvsg85oHMJ8 .node .label,#mermaid-svg-E5fIUtvsg85oHMJ8 .image-shape .label,#mermaid-svg-E5fIUtvsg85oHMJ8 .icon-shape .label{text-align:center;}#mermaid-svg-E5fIUtvsg85oHMJ8 .node.clickable{cursor:pointer;}#mermaid-svg-E5fIUtvsg85oHMJ8 .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .arrowheadPath{fill:#333333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-E5fIUtvsg85oHMJ8 .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-E5fIUtvsg85oHMJ8 .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-E5fIUtvsg85oHMJ8 .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-E5fIUtvsg85oHMJ8 .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-E5fIUtvsg85oHMJ8 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-E5fIUtvsg85oHMJ8 .cluster text{fill:#333;}#mermaid-svg-E5fIUtvsg85oHMJ8 .cluster span{color:#333;}#mermaid-svg-E5fIUtvsg85oHMJ8 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-E5fIUtvsg85oHMJ8 .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-E5fIUtvsg85oHMJ8 rect.text{fill:none;stroke-width:0;}#mermaid-svg-E5fIUtvsg85oHMJ8 .icon-shape,#mermaid-svg-E5fIUtvsg85oHMJ8 .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-E5fIUtvsg85oHMJ8 .icon-shape p,#mermaid-svg-E5fIUtvsg85oHMJ8 .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-E5fIUtvsg85oHMJ8 .icon-shape .label rect,#mermaid-svg-E5fIUtvsg85oHMJ8 .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-E5fIUtvsg85oHMJ8 .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-E5fIUtvsg85oHMJ8 .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-E5fIUtvsg85oHMJ8 :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 编辑指令 p+
反向指令 p-
flow-matching loss
DMD loss
源视频 chunk
编辑 chunk
重建 chunk
短视频教师
核心洞察:原始长视频本身是时序一致的,反向重建损失迫使模型学习保持长程时序一致性,无需成对长编辑视频。

图 6:Cycle-Reverse 正则化效果对比。加入正则化后非编辑区域保持一致,编辑目标全程稳定。来源:SANA-Streaming Fig 9
2.3 因果 VAE 蒸馏
原始 LTX2 VAE 解码器使用双向时序卷积,无法用于流式场景。SANA-Streaming 将其转换为因果解码器:
- 权重重映射 :双向卷积核 a , b , c a, b, c a,b,c → \to → 因果卷积核 0 , a , b + c 0, a, b+c 0,a,b+c
- 蒸馏目标:Charbonnier 重建损失 + LPIPS 感知损失 + Haar 小波高频损失 + 中间特征蒸馏
蒸馏后的因果 VAE 在纹理清晰度和边缘还原上接近双向教师模型。
2.4 高效系统协同设计
高效 GDN Kernel
遵循 FlashAttention 的 IO-aware 原则,将 GDN 更新分解为三阶段流水线:
| 阶段 | 操作 | 并行度 |
|---|---|---|
| Phase A | 帧级空间归约 ( P f , A f ) (P_f, A_f) (Pf,Af) | 帧间并行 |
| Phase B | 紧凑递推扫描 ( S f , z f ) (S_f, z_f) (Sf,zf) | 序列执行,状态驻留 SRAM |
| Phase C | 查询-状态乘法输出 | 帧间并行 |
双向 GDN 利用 Phase C 的线性性,合并正反向历史后只做一次输出 kernel,避免重复读取 Q f Q_f Qf。效果:单层级 1.4x-13.8x 加速,端到端 1.5x-2.2x 采样加速。
混合精度量化(MPQ)
面向 RTX 5090 Blackwell 的 NVFP4/FP8 Tensor Core,设计 AutoML 风格的精度搜索:
- BF16 保留:patch embedding、output layer、timestep embedding、attention gate、MixFFN DW-Conv
- FP4 降级:SA-Q/K、CA-O、Temporal FFN(全 block)+ FFN I/O(中层+深层 block)
- FP8 保留:SA-V/O、CA-Q 等敏感层
搜索指标为相对 RMSE / Speedup 的帕累托前沿(Eq. 6)。最终策略在量化层获得 3x 加速,DiT 整体获得 1.59x 加速,质量损失可忽略(Cost/Speedup = 0.21,优于纯 FP8 的 0.23)。
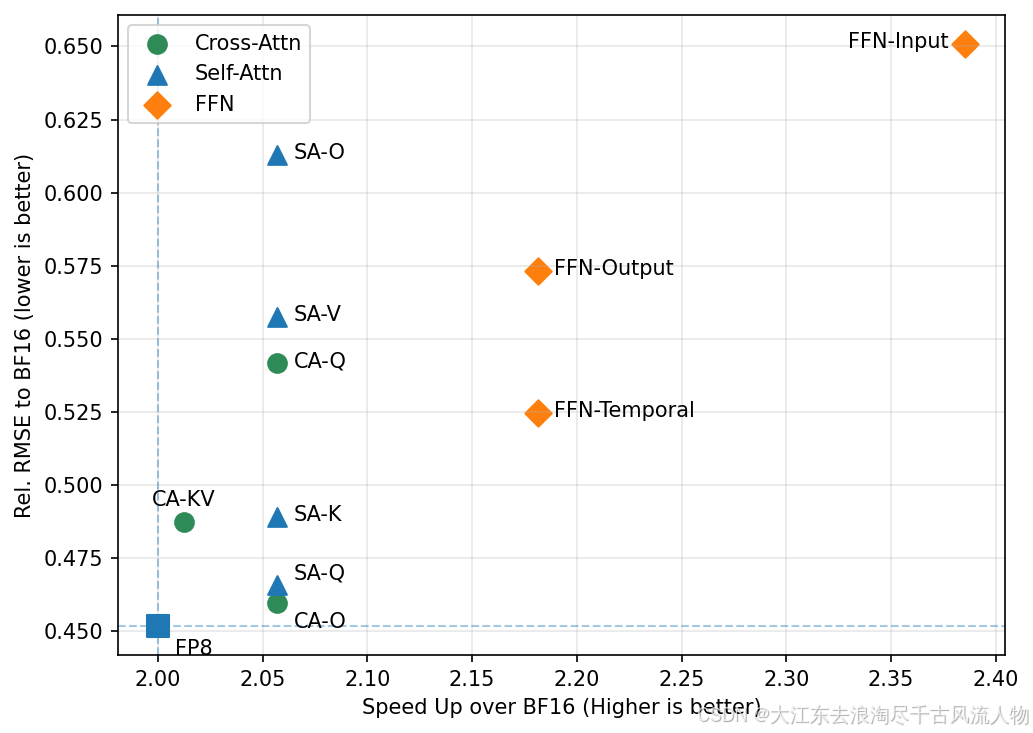
图 7:混合精度量化帕累托搜索(逐层粒度)。红星为最终策略,在效率与质量之间取得最优平衡。来源:SANA-Streaming Fig 6a
三、数据流水线
SANA-Streaming 构建了完整的编辑数据流水线:
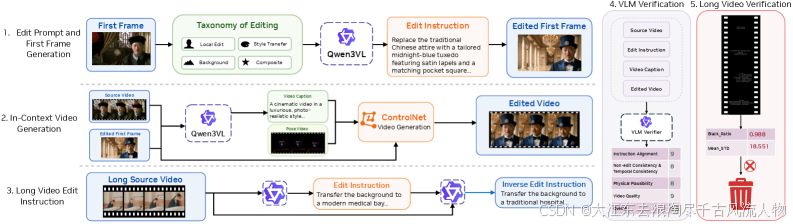
图 8:完整数据流水线。短视频通过首帧编辑+条件生成构建编辑对,长视频通过 VLM 生成正反向指令。来源:SANA-Streaming Fig 7
短视频对构建:
- 分类编辑指令生成(局部人物编辑 / 背景替换 / 风格迁移 / 组合编辑)
- Qwen-Image-Edit 编辑首帧作为视觉锚点
- Wan2.2-Fun-Control 条件生成编辑视频(文本 + 姿态 + 首帧引导)
- VLM 四维度验证过滤(指令对齐 / 非编辑一致性 / 物理合理性 / 视频质量)
长视频指令构建:
- Gemini-3-Flash 生成正向编辑指令 p + p^+ p+
- VLM 推断反向指令 p − p^- p−(从编辑结果恢复源域)
- 总计约 10M 短视频 + 10K 分钟级长视频
四、实验分析
OpenVE-Bench 对比
| 方法 | 参数量 | 分辨率 | 延迟(s) | 吞吐(FPS) | 平均分 |
|---|---|---|---|---|---|
| VACE | 14B | 1280x720 | 1991 | 0.3 | 1.57 |
| DITTO | 14B | 832x480 | 1971 | 0.3 | 2.13 |
| OpenVE-Edit | 5B | 1280x704 | 97 | 6.7 | 2.50 |
| Lucy-Edit | 5B | 1280x704 | 97 | 6.7 | 2.22 |
| SANA-Streaming | 2B | 1280x704 | 20 | 32.4 | 2.62 |
| SANA-Streaming (蒸馏) | 2B | 1280x704 | 1 | 762.8 | 2.42 |
关键数据:
- 模型仅 2B 参数,比 OpenVE (5B) 小 2.5 倍,质量反超(2.62 vs 2.50)
- 吞吐 32.4 FPS,比 OpenVE 快 5 倍
- 蒸馏版本吞吐 762.8 FPS,比之前最快方法快 100 倍以上

图 9:与现有方法的定性对比。SANA-Streaming 在保持源视频运动和非编辑内容的同时准确执行编辑指令。来源:SANA-Streaming Fig 8
系统优化消融
| 配置 | DiT 延迟 |
|---|---|
| BF16 基线 | 26.7s |
| + GDN Kernel | 20.9s (-22%) |
| + MPQ | 16.8s (-37%, 1.59x) |
端到端 FPS:24 FPS(DiT 核心 58 FPS)。
Cycle-Reverse 消融
去掉 Cycle-Reverse 正则化后,非编辑区域在后续帧出现漂移,编辑目标(如"水晶树")在长视频中逐渐变形。加入正则化后全程一致。
小结
创新点:
- GDN + softmax 混合架构巧妙解决了线性注意力局部性不足与 softmax 注意力内存爆炸的矛盾
- Cycle-Reverse 正则化利用反向重建避开了长视频成对数据缺失的难题
- 三阶段 GDN kernel + 混合精度搜索实现了从算法到硬件的端到端优化
局限性:
- 高质量长视频编辑数据仍然稀缺,复杂场景下时序一致性有待提升
- 对模糊/欠规范的编辑指令缺乏消歧机制
个人判断:这篇工作的核心价值在于 system-algorithm co-design 的方法论。混合注意力架构并非新概念(LLM 领域 Kimi Linear、Qwen3.5 已有类似设计),但将其系统性地应用于流式视频编辑、配合硬件感知的量化搜索达到实时推理,工程完成度非常高。GDN kernel 的三阶段分解和 MPQ 的帕累托搜索都值得做系统优化的团队参考。Cycle-Reverse 正则化的思路(用反向重建替代成对数据)具有通用性,可以迁移到其他缺乏成对数据的生成任务中。