文件导入功能实现
在很多后台系统里,Excel 导入 几乎是必不可少的功能。
但真正好用、稳定、可维护的导入功能并不多见:
- 有的只能粗暴导入,不校验数据
- 有的校验不完善,报错不明确
- 有的中途失败会造成部分数据入库
- 有的解析慢,一个几 MB 的 Excel 能卡几十秒
- 有的用户看到报错完全不知道错在哪里
最近我在做一个数据导入功能时,顺手整理了我设定的一套 后端 Excel 导入流程体系 ,
包含:
- 文件解析 ✓
- Excel 表头校验 ✓
- 行级字段校验 ✓
- 组合唯一性校验 ✓
- 数据对象转换 ✓
- 业务规则计算 ✓
- 批量落库 ✓
- 异步处理额外逻辑 ✓
这篇文章就把核心的技术设计 + 踩坑点分享出来,希望对你有帮助。
一、 📥 文件解析:为什么选择 EasyExcel?
Java 解析 Excel 的方案很多,POI、JXL 都可以。但在大文件场景下:
- POI 容易 OOM
- JXL 老旧不维护
- EasyExcel 解析速度快 & 流式处理不占内存
所以我封装了一个通用方法如下,能实现表头自动与实体类注解比对、数据逐行读取,不占内存、自动封装成 Java 实体类、表格为空时自动报错。这是整个导入流程最核心的逻辑。
java
public static <T> List<T> readMultipartFile(InputStream inputStream, Class<T> clazz) {
final List<T> dataList = new ArrayList<>();
EasyExcel.read(inputStream, clazz, new AnalysisEventListener<T>() {
// 表头校验
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
List<String> expectedHeaders = readExcelPropertyAnnotations(clazz);
List<String> actualHeaders = headMap.values().stream()
.filter(h -> h != null && !h.trim().isEmpty())
.toList();
if (!actualHeaders.equals(expectedHeaders)) {
throw new BusinessException("Excel 表头不匹配");
}
}
// 每行数据回调
@Override
public void invoke(T data, AnalysisContext context) {
dataList.add(data);
}
// 读取完成后可以进行一些操作
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
}
}).sheet().doRead();
if (dataList.isEmpty()) {
throw new BusinessException("Excel 无数据");
}
return dataList;
}二、🔍 Excel 行级校验:拒绝脏数据入库
我们这个业务场景主要处理的是自用户上传的Excel文件数据,并将其入库。但导入 Excel 最大的问题就是:**用户给的数据永远不干净,**入库的时候不可避免地需要对用户数据进行校验。
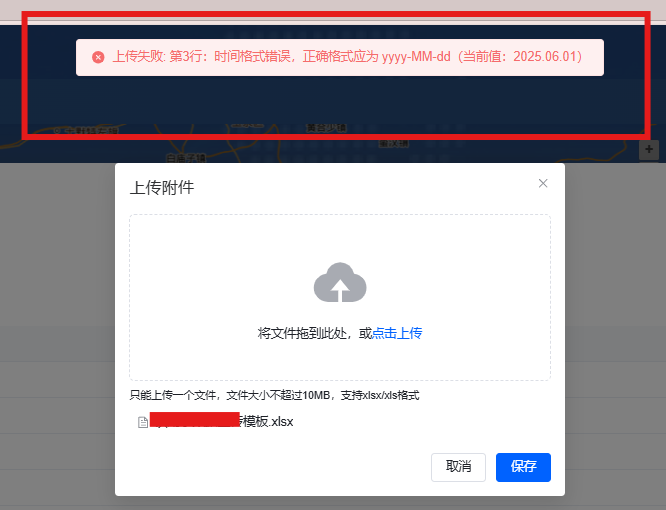
这里主要针对用户上传的日期格式进行校验,假设我们需要的是 **"yyyy-MM-dd"**的时间格式,不需要精确到时分秒,在数据入库之前,我们需要将校验逻辑统一放到循环中进行处理:
java
for (int i = 0; i < excels.size(); i++) {
WaterExcelRow row = excels.get(i);
int realRowNum = i + 2; // 因为 Excel 从第2行开始是数据
// ① 日期不能为空
if (StringUtils.isBlank(row.getDate())) {
return fail("第 " + realRowNum + " 行:日期不能为空");
}
// ② 日期格式校验 yyyy-MM-dd
try {
LocalDate.parse(row.getDate(), DateTimeFormatter.ofPattern("yyyy-MM-dd"));
} catch (Exception e) {
return fail("第 " + realRowNum + " 行:日期格式错误(当前值:" + row.getDate() + ")");
}
// ③ 针对其他字段进行的校验...
}
}这个时候你可能有其他的问题:如何在导入数据时校验某个字段的唯一性或组合字段的唯一性?
**需求分析:**为什么需要某些字段的内部唯一性校验呢?因为用户总是喜欢复制粘贴的。或许多粘了一行或输入的两行数据一样自己却没有察觉,就将这样带着脏数据的 Excel 丢给了我们的接口。
场景示例: 你正在导入一份"学生某次考试的成绩单",系统要求 每个学生在同一次考试中只能出现一条成绩记录 。那么我们就需要在导入过程中,对**"学生 ID + 考试批次"**进行唯一性校验。
**做法:**在遍历 Excel 数据行时,将"学生ID+考试批次的组合 Key " 依次放入一个集合 Set 中。当某一行的数据尝试加入 Set 时,如果发现该元素已经存在,就说明出现了重复数据,当前 Excel 的这一组数据将被判定为不合规,此次导入也应该直接中止。
java// 用于校验唯一性的 Set(存 studentId + examBatch 的组合) Set<String> uniqueKeySet = new HashSet<>(); for (int i = 0; i < excelList.size(); i++) { StudentScoreExcel row = excelList.get(i); // 1. 基本字段校验 if (StringUtils.isBlank(row.getStudentId())) { return CommonResult.fail("第" + (i + 2) + "行:学生ID不能为空"); } if (StringUtils.isBlank(row.getExamBatch())) { return CommonResult.fail("第" + (i + 2) + "行:考试批次不能为空"); } // 2. 组合唯一性校验:studentId + examBatch String key = row.getStudentId() + "|" + row.getExamBatch(); if (!uniqueKeySet.add(key)) { // add() 返回 false 表示已经存在该元素,即数据重复 return CommonResult.fail( "第" + (i + 2) + "行:学生ID [" + row.getStudentId() + "] 在考试批次 [" + row.getExamBatch() + "] 中已有成绩记录,数据重复" ); } // 3. 其他字段校验... // 比如成绩范围、日期格式、科目合法性等 }
三、🧩 数据校验通过后,再统一转换成实体对象
校验通过的行,会被转换成实际要入库的实体对象,这个就贴合你的需求实际,看你的入库实体包含什么字段、你会往里面添加什么字段入库了。一定要避免直接使用 Excel 行对象入库,因为:
- Excel DTO 与数据库 Entity 结构不一致
- Excel 格式不等于业务格式
- Excel 注解多,会污染数据库实体类
四、💾 全量校验通过后再入库(避免部分入库)
这是非常关键的点。很多系统的导入做得很糟糕------
- 遭遇第一条错误后,前几条数据已经入库
- 一半成功、一半失败
- 回滚不彻底
可采取的一个建议措施是:只要有错误,一行都不能入库。
在设计导入流程时,千万不要只给用户一句"导入失败"这种模糊提示。更好的做法是:在校验阶段就将所有问题收集起来,并清晰告知用户例如"第 X 行某字段格式错误""第 Y 行数据重复"等详细信息,让用户能够有针对性地修改文件后重新上传。这样既避免了用户反复尝试,又能防止出现"前半部分已经入库,后面某行失败导致整体回滚"的情况,使整个导入体验更加友好和可控。
五、🔄 异步处理:避免阻塞导入流程
某些逻辑(比如针对入库数据进行安全校验、对超标、不合规数据发送告警/调用其他系统)不能阻塞导入,可以考虑用线程池异步执行:
java
Executors.newSingleThreadExecutor()
.execute(() -> alarmClient.saveAlarm(alarmList));这样:
- 用户体验更好
- 导入速度不受外部接口影响
- 不会因为某系统卡顿而导致导入失败
六、📑 完整日志记录:无日志等于无真相
最后,把上传的文件存到对象存储或文件服务器,
并记录数据库日志:
java
fileUpload(file);
insertLog(filename, fileId);这样当用户说:"我导入成功了但你们系统没数据啊?"
你能用日志稳稳锤他。
七、🏁总结:一套成熟的 Excel 导入处理体系应该具备的能力
✔ 表头严格匹配
✔ Excel DTO → Entity 结构分离
✔ 行级校验
✔ 格式校验
✔ 唯一性校验
✔ 批量转换
✔ 业务规则计算
✔ 批量入库
✔ 失败即终止
✔ 异步扩展逻辑
✔ 文件日志记录
不是简单的"把 Excel 转成 List 吐给数据库"。
这是成熟系统必须做的事,也是一个优秀后端开发应该具备的思维。