核心问题:"买了A的顾客,有多大可能性也会买B?"
经典案例:"啤酒与尿布" ------ 发现看似无关的商品之间隐藏的关联。
一、基础概念:看懂"购物篮"数据
1.1 事务(Transaction)与项(Item)
-
事务:一条交易记录。比如:"顾客A在2023年1月1日购买的商品清单"。
-
项:事务中的每一个商品。比如:{牛奶, 面包, 啤酒}。
1.2 项集(Itemset)
-
包含一个或多个项的集合。
-
k-项集 :包含 k 个项的集合。例如:{牛奶, 面包} 是一个 2-项集。
1.3 支持度计数(Support Count, σ)
-
某个项集在所有事务中出现的次数。
-
记法:σ({牛奶,面包})=4,表示有4笔订单同时包含牛奶和面包。
二、关联规则与两大核心指标
一条关联规则形如:X → Y (读作"X 推导出 Y"),其中 X 和 Y 是不相交的项集(例如 {牛奶} → {面包})。
判断这条规则是否有用,主要看两个数值:
2.1 支持度(Support)
-
公式 :
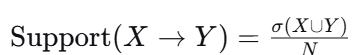 (N 为总事务数)
(N 为总事务数) -
含义 :同时包含 X 和 Y 的事务,占总事务的比例。
-
作用 :衡量规则在数据中出现的频率。太低的规则没有统计意义。
2.2 置信度(Confidence)
-
公式 :
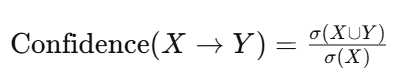
-
含义 :在包含 X 的事务中,同时包含 Y 的条件概率 P(Y∣X)。
-
作用 :衡量规则的强度,即"买了 X 的人,有多大几率也买 Y"。
💡 手算示例(总事务数 N=1000):
-
包含"茶"的事务:200个(σ(茶)=200)
-
同时包含"茶"和"咖啡"的事务:150个
-
规则 {茶} → {咖啡}:
-
支持度 = 150 / 1000 = 15%
-
置信度 = 150 / 200 = 75%
-
解读:所有订单中有15%同时买了茶和咖啡;在买茶的顾客中,75%也买了咖啡。
2.3 挖掘目标
给定两个阈值:最小支持度(minsup) 和 最小置信度(minconf) ,找出所有满足 支持度 ≥ minsup 且 置信度 ≥ minconf 的规则。
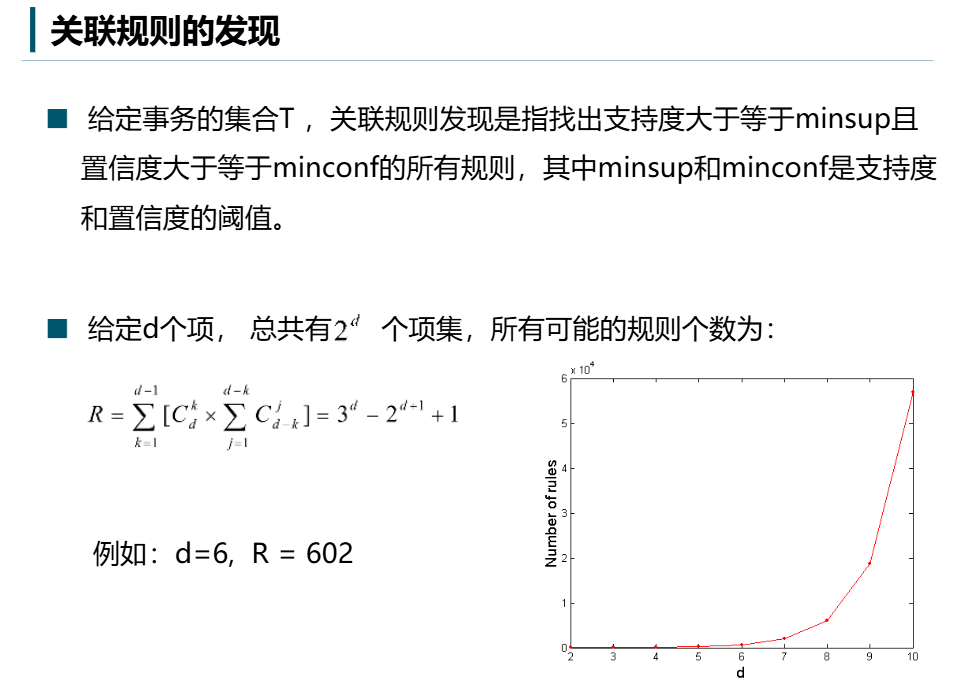
三、暴力拆解:关联规则挖掘的两步走
直接暴力搜索所有规则是不现实的。假设有 d 个不同的商品,所有可能的规则数量惊人:
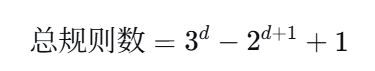
例如 d=6(6种商品),就有 602 条规则需要检验;如果 d=100,规则数量将远超宇宙原子数!
因此,我们分两步走:
-
频繁项集生成 :找出所有支持度 ≥ minsup 的项集(称为频繁项集)。
-
规则生成:从每个频繁项集中,枚举所有可能的划分(X → Y),筛选出置信度 ≥ minconf 的规则。
核心策略:先找"常客"(频繁项集),再看"搭配"(高置信度)。
四、Apriori 算法:最经典的频繁项集挖掘算法
4.1 核心原则(Apriori Principle)
"如果一个项集是频繁的,那么它的所有子集也一定是频繁的。"
(反过来说:"如果一个项集是非频繁的,那么它的所有超集一定是非频繁的。")
🚀 剪枝应用(避开计算爆炸) :
假设我们发现 {A, B} 是不频繁的(低于 minsup)。
那么,任何包含 {A, B} 的超集(如 {A, B, C}, {A, B, D, E})一定也是不频繁的,可以直接丢弃,无需再计算它们的支持度!
4.2 算法流程(逐层搜索)
-
生成候选1-项集 :扫描数据,剔除不频繁的,得到 频繁1-项集(L₁)。
-
生成候选2-项集(C₂):将 L₁ 中的项两两组合。
-
剪枝 :扫描数据计算 C₂ 的支持度,剔除不频繁的,得到 频繁2-项集(L₂)。
-
循环:用 L₂ 生成候选3-项集(C₃)... 直到无法生成新的频繁项集为止。
4.3 候选项集生成详解(连接步与剪枝步)
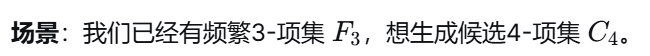
-
Step 1:连接(Join)
将两个只有最后一个项不同的频繁3-项集合并。
- 例如:{A, B, C} 和 {A, B, D} 合并 → {A, B, C, D}
-
Step 2:剪枝(Prune)
根据Apriori原则,检查新生成的4-项集的所有3-项子集是否都在
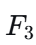 中。
中。如果有一个3-项子集不在
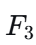 中,该4-项集就不可能是频繁的,直接删除!
中,该4-项集就不可能是频繁的,直接删除!
🔥 PPT手算验证(重点) :
假设
连接生成:ABCD(ABC+ABD)、ABCE(ABC+ABE)、ABDE(ABD+ABE)。
剪枝检验 ABCE :它的子集 ACE 和 BCE 不在 F3 中 → 删除。
剪枝检验 ABDE :它的子集 ADE 不在 F3 中 → 删除。
保留 ABCD :其子集 ABC, ABD, ACD, BCD 全部在 F3 中 → 保留 。
最终 C4={ABCD}C4={ABCD},完美符合 PPT。
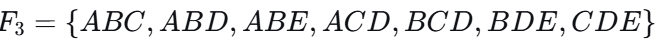
4.4 支持度计数加速:Hash 树
当候选集非常多时,Apriori 使用 Hash 树(哈希树) 来存储候选项集。遍历每个事务时,只需将事务中的项集哈希到树的特定叶子节点进行匹配,大大减少了比较次数。
五、规则生成:从频繁项集中提炼"高价值"规则
拿到频繁项集 Y 后,我们要把它分成两部分:前提(LHS) 和 结论(RHS)。
5.1 置信度剪枝原理(重要定理)
定理 :如果规则 X→Y−X不满足置信度阈值,那么将 X缩小为 X′(即 X′⊂X)后,新规则 X′→Y−X′也一定不满足置信度阈值。
通俗理解 :如果"A+B → C"不可靠,那么"A → B+C"会更不可靠(因为前提条件更少,样本更多,误差波动更大)。基于此原理,我们可以在规则生成时大胆剪枝,只从频繁项集的最大子集开始递推。
六、频繁项集的紧致表示(压缩存储)
随着数据增大,频繁项集数量可能爆炸。我们有两种方法压缩它们:
6.1 极大频繁项集(Maximal Frequent Itemset)
-
定义 :如果一个频繁项集的所有直接超集都是非频繁的,它就是极大频繁项集。
-
作用 :它确定了频繁项集的边界。其所有子集必定是频繁的,但它本身丢失了子集的具体支持度信息。
6.2 闭频繁项集(Closed Frequent Itemset)
-
定义 :如果项集 X 的所有直接超集 的支持度计数都小于 X 的支持度计数,则 X是闭项集。如果 X 同时是频繁的,称为闭频繁项集。
-
优势:比极大频繁项集保留了更多的支持度信息,同时大大压缩了项集数量。
| 类型 | 保留支持度信息? | 典型用途 |
|---|---|---|
| 极大频繁项集 | 不保留(只知边界) | 快速判断一个项集是否频繁 |
| 闭频繁项集 | 保留(精确支持度) | 更精准地恢复所有频繁项集的支持度 |
七、评估标准:置信度的陷阱与更优度量
高置信度不一定代表"强关联",甚至可能是误导!
7.1 置信度的局限性(PPT 经典案例)
数据:
-
P(咖啡)=0.8(80%的人买咖啡)
-
P(咖啡∣茶)=0.75(喝茶的人中75%买咖啡)
矛盾 :虽然置信度 0.75 很高,但 喝茶反而降低了买咖啡的概率 (因为总体是 0.8)。这规则是误导性的!它只是咖啡整体热销的假象。
7.2 提升度(Lift)------ 解决误导的关键

计算上面的例子:
-
规则 {茶} → {咖啡}:Lift = 0.75 / 0.8 = 0.9375(<1)。
-
结论:虽然置信度高,但茶和咖啡实际上是负相关的(抑制关系)。而如果另一个规则 {茶} → {蜂蜜},置信度 0.5,P(蜂蜜)=0.12,Lift=0.5/0.12≈4.17(>1),这才是真正有意义的强关联!

7.3 辛普森悖论(Simpson's Paradox)
警告:聚合数据看起来的关联,在细分群体中可能完全相反!
PPT例子 :整体上看,买 HDTV 的人更倾向于买健身器(置信度 0.55 vs 不买的 0.45)。
但将人群分为大学生 和在职人员后:
大学生组:买 HDTV 的反而更少买健身器(0.1 vs 0.118)。
在职组:差距也变得极小。
结论 :数据分组后,之前的"强关联"消失了。这说明忽略了潜在混杂因素(如收入、年龄),挖掘时需警惕!
八、本章核心公式与要点速记卡
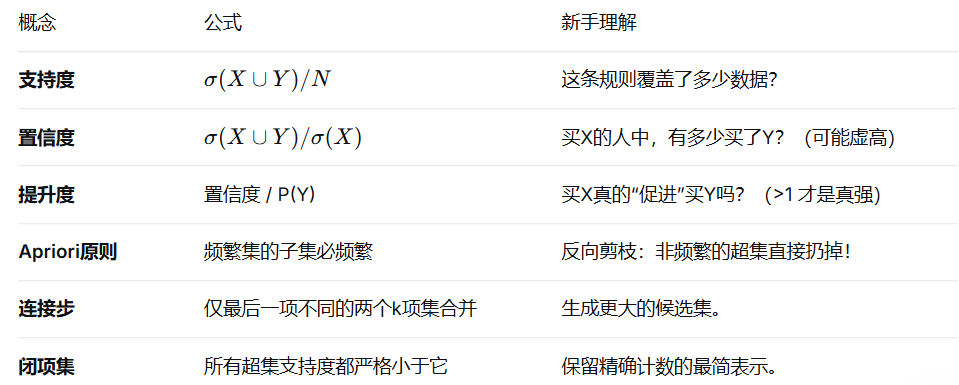 |
|---|
九、总结:实战建议
-
先设最小支持度:过滤掉噪音(太冷门的商品搭配没意义)。
-
提升度比置信度重要:高置信度 + 提升度 > 1,才是真正靠谱的"捆绑销售"依据。
-
注意辛普森悖论:在对整体数据做关联分析后,一定要按关键维度(如地区、用户等级)分层验证,防止被虚假关联欺骗。
-
算法选择:
-
传统小数据:Apriori 足够。
-
大数据(亿级事务) :使用 FP-Growth (不产生候选集,直接压缩数据)或 PCY 等改进算法。
-