A telomere-to-telomere reference genome assembly of tomato cultivar 'Heinz 1706'
番茄栽培品种'Heinz 1706'端粒到端粒完整参考基因组组装

番茄(Solanum lycopersicum )是全球最重要的蔬菜作物之一,同时也是开展遗传与基因组学研究的模式植物,目前针对其果实发育机理、生物胁迫与非生物胁迫抗性机制等方向已开展大量研究。十余年前,番茄基因组联盟已于 2012 年发布首个栽培品种海因茨 1706 的基因组组装版本;后续基于太平洋生物科学公司高保真测序数据组装得到的最新 SL5.0 版本仍存在诸多缺陷,该版本共计存在 31 个组装缺口、21 条端粒序列缺失,且缺失 45S 核糖体 RNA 基因相关序列信息。
近年来,超长片段牛津纳米孔测序技术飞速发展,诸多植物端粒到端粒(T2T)完整基因组相继完成组装。构建番茄端粒到端粒水平的完整参考基因组,对开展番茄基因组解析与进化研究具有重要意义。
本研究以海因茨 1706 番茄为材料,共测得 95.7 Gb 超长牛津纳米孔测序 reads,其中高质量测序片段(长度>50 kb、碱基准确度>99%,平均质量值约 Q25)测序深度约 98 倍,同时获得 11.8 Gb 二代短读长测序数据(详见附表 1、附图 1A)。
将高质量纳米孔长序列导入 Hifiasm 组装软件进行基因组组装,初步组装结果包含 10 条两端均含端粒的完整染色体、1 条仅含单端端粒的近完整 3 号染色体、1 条仅含单端端粒的不完整 2 号染色体,另有 4 条长度超 1 Mb 的额外重叠群,这类序列主要由 45S 核糖体 RNA 基因序列构成,其中一条重叠群携带端粒序列(详见附表 2)。
研究利用纳米孔测序重叠序列延伸染色体末端,补齐缺失端粒,最终完成 3 号染色体完整组装(附图 2A);再将 5 条含核糖体 RNA 基因的重叠群进行支架拼接,完成 2 号染色体组装,该染色体目前仍保留 4 个组装缺口,均以 100 个碱基 N 进行填充。
利用二代短读长数据对基因组纯合单核苷酸变异及小片段插入缺失进行碱基校正(附表 3),最终得到命名为SL-T2T 的番茄端粒到端粒基因组序列。该基因组总大小为 831.45 Mb,重叠群 N50 长度达 68.49 Mb,共组装得到 12 条染色体,集齐全部 24 个端粒序列;除 2 号染色体上 45S 核糖体 RNA 基因区域尚未完全拼接完成外,其余区域均实现无缺口完整组装(图 1A、附表 4、附表 5)。
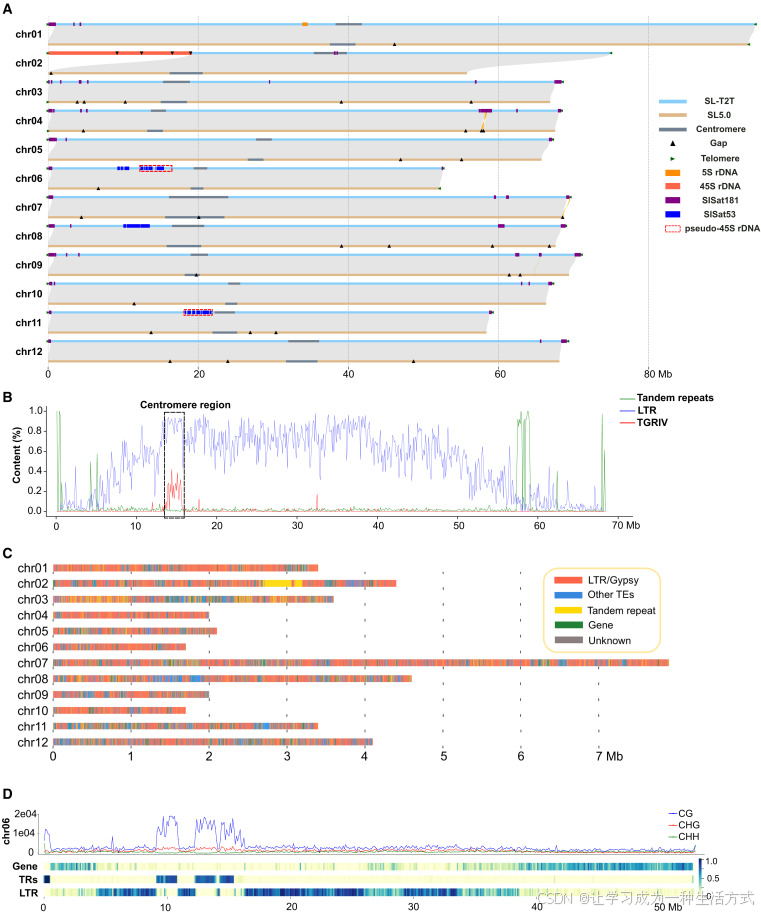
图 1 SL-T2T 基因组整体特征
(A) SL-T2T 基因组与 SL5.0 基因组对比; (B) 利用着丝粒富集重复序列 TGRIV 鉴定 4 号染色体候选着丝粒区域,同时展示长末端重复反转座子与串联重复序列的分布特征; (C) 候选着丝粒区域内串联重复序列、转座子与基因的分布模式; (D) 6 号染色体上 CG、CHG、CHH 三类甲基化位点,以及基因、串联重复序列、长末端重复反转座子的分布情况。
为评估组装质量,本研究整合已发表的高保真测序数据(测序深度约 43 倍)与高质量牛津纳米孔长读长数据,借助 Verkko 软件组装得到 12 条染色体水平重叠群。对比 SL-T2T、SL5.0 基因组及该组装版本的核心序列发现,二者仅存在少量差异区段(最长 46 千碱基对),差异成因主要为材料杂合性(本研究所用种子存在种质混杂)与两种测序平台样本差异;SL-T2T 还含有诸多新增特有序列。
将纳米孔长读长、高保真长读长、二代短读长数据分别比对至 SL-T2T 基因组,比对率依次为 100%、100%、98.15%;除 45S 核糖体 RNA 基因区域外,全基因组测序深度分布均匀。通过整合基因组可视化工具对所有卫星 DNA 区域进行可视化验证,证实纳米孔测序读长可实现序列连续比对。 经评估,SL-T2T 基因组 Merqury 质量值达 53.39,基于 25-mer、拷贝数大于 22 的序列完整度为 99.66%,通用单拷贝直系同源基因完整度达 98.6%,充分证明该基因组碱基准确度高、序列完整性优异。
相较于 SL5.0 版本,SL-T2T 新增序列总长 29.67 兆碱基对,其中 84.51% 为 45S 核糖体 RNA 基因及其他串联重复序列。SL5.0 基因组中共存在 31 个组装缺口,最大缺口长度 362 千碱基对,其余缺口均小于 100 千碱基对,其中 9 个缺口两侧被重复序列包围。此外,SL5.0 还存在两处序列倒置错误、三处序列易位错误,错误序列长度分别为 371 千碱基对与 23 千碱基对。依托超长高精准纳米孔测序读长的连续比对支撑,SL-T2T 成功填补上述所有缺口并修正结构错误,凸显超长高精度纳米孔测序在基因组复杂区域组装中的显著优势。
本研究在 SL-T2T 基因组中共注释得到 36006 个基因,其中 22784 个完成功能注释(含 254 个从 SL5.0 注释迁移获得的基因);31350 个基因与 SL5.0 注释结果一致,23294 个基因的基因结构与 SL5.0 相符。相较于 SL5.0 注释基因,SL-T2T 中存在差异的基因均具备更完善的转录组表达证据。 重复序列占 SL-T2T 基因组总长的 66.51%,其中转座子占比 61.09%,串联重复序列占比 4.94%;鉴定得到两类卫星 DNA(SlSat181、SlSat141)与两类小卫星 DNA(SlSat53、SlSat35)。
利用已报道的番茄着丝粒特征重复序列 TGRIV,本研究在 SL-T2T 基因组中精准鉴定出 12 条染色体的着丝粒区域,总长度 40.90 兆碱基对。着丝粒区域共注释 582 个基因,其中 195 个完成功能注释,基因密度远低于基因组平均水平。着丝粒区内串联重复序列仅 1.24 兆碱基对,印证茄科植物着丝粒区域主要由长末端重复反转座子构成的已有研究结论。
单元长度为 181 碱基对的卫星序列 SlSat181 分布于 21 个亚端粒区域,串联阵列长度介于 100 千碱基对至 1.1 兆碱基对之间,同时少量分布于 2 号、5 号染色体着丝粒区。35 碱基对的小卫星 DNA SlSat35 在全基因组广泛分布,覆盖全部 12 个着丝粒区域,基因组内总重复次数达 57254 次。此外,在 1 号染色体 33.87~34.58 兆碱基对区间鉴定出一处 5S 核糖体 RNA 基因串联阵列,包含 1918 个基因单元与 1 个长末端重复反转座子。
已有研究证实番茄 2 号染色体端部富集大量 45S 核糖体 RNA 基因,预估拷贝数约 2300 个。结合纳米孔测序数据统计估算,海因茨 1706 番茄基因组内完整 45S 核糖体 RNA 基因拷贝数约 3400 个。SL-T2T 基因组中端粒邻近的 45S 核糖体 RNA 基因阵列包含 2105 个完整基因单元,总长 19.11 兆碱基对;纳米孔测序读长中未发现反向排列单元,推测 2 号染色体上所有 45S 核糖体 RNA 基因排列方向一致。除 2 号染色体外,仅在 11 号染色体 24.38 兆碱基对位置发现单个 45S 核糖体 RNA 基因单元。 SL-T2T 中 45S 核糖体 RNA 基因未能完全组装,原因是该家族基因序列相似度极高,组装得到的基因单元连同间隔区平均序列相似度达 99.92%,测序读长内基因单元平均相似度也达 98.24%,已接近纳米孔 Q25 测序精度极限。 在等位基因频率不低于 0.05 的筛选标准下,共鉴定出 11 个单核苷酸变异与 62 个长度不超过 5 碱基对的小片段插入缺失变异,变异特征无明显分组规律。比对多款近期发表的茄科植物端粒水平基因组发现,番茄 45S 核糖体 RNA 基因阵列规模最大、序列相似度最高,表明番茄与马铃薯分化之后,其 45S 核糖体 RNA 基因发生过近期大规模扩张。
研究还鉴定出两处 45S 核糖体 RNA 假基因区域,仅保留部分 18S、28S 核糖体 RNA 基因片段,分别位于 6 号染色体与 11 号染色体。两处假基因区域内长末端重复反转座子占比差异显著,而 2 号染色体完整 45S 核糖体 RNA 基因区域仅含微型反向重复转座元件。45S 核糖体 RNA 基因间隔区含有 SlSat141、SlSat53 两类串联重复序列;两处假基因区域以 SlSat53 小卫星序列为主,该序列在此处发生明显扩张,8 号染色体特定区段也富集 SlSat53 序列但无 45S 核糖体 RNA 基因分布。上述结果表明,45S 核糖体 RNA 假基因区域由完整基因序列退化、SlSat53 小卫星序列扩张演化形成。
植物基因组胞嘧啶甲基化主要分为 CG、CHG、CHH 三种类型。依托纳米孔测序数据,本研究在 SL-T2T 基因组中鉴定出 4849 万余处甲基化位点。串联重复序列区域内 CG 型甲基化位点密度与占比远高于全基因组平均水平,与人类基因组甲基化特征相似,暗示 CG 甲基化在维持番茄基因组稳定性中发挥重要作用。长末端重复反转座子区域的 CG、CHG 甲基化水平同样显著偏高,符合 DNA 甲基化沉默转座子、稳定基因组的经典作用机制。 45S 核糖体 RNA 基因区域三类甲基化位点密度位居所有基因组元件之首,推测与核仁组织区基因选择性表达相关;基因上游 500 碱基对区间内 CHH 甲基化水平显著上升,印证该类甲基化修饰参与基因表达调控的功能。综上,三类甲基化位点在番茄基因组中功能分化明确,甲基化修饰分布特征与其生物学功能高度契合。
综上,本研究成功组装获得总长 831.45 兆碱基对、高精度的海因茨 1706 番茄端粒水平完整基因组,为番茄基因组学基础研究与分子遗传育种改良提供全新优质参考基因组。
数据与代码公开
本研究全部原始测序数据及 SL-T2T 基因组序列已上传至国家基因组科学数据中心,生物项目编号:PRJCA034231,基因组库登录号:GWHFILF00000000;高保真测序数据存放于美国国立生物技术信息中心,生物项目编号:PRJNA733299;甲基化位点鉴定相关数据可在线查询;基因组序列与基因注释文件可通过番茄基因组数据库浏览比对;所有数据分析脚本已上传至 GitHub 开源仓库。
All raw sequencing reads and SL-T2T genome sequences have been deposited in the Chinese National Genomics Data Center (首页 - 国家基因组科学数据中心) under BioProject PRJCA034231 and Genome Warehouse accession GWHFILF00000000. HiFi sequencing data are available in GenBank (National Center for Biotechnology Information) under BioProject PRJNA733299. Data related to methylation site identification can be accessed at https://tomato.mbkbase.org/slt2t. Genome sequences and gene annotations are also available at the tomato genome database (https://tomato.mbkbase.org) through JBrowse and/or BLAST. Scripts used for data analysis are available at https://github.com/chenys1998/SL-T2T-assembly.