文章目录
-
- 一、前言
- 二、系统架构总览
-
- [2.1 整体架构](#2.1 整体架构)
- [2.2 设计目标](#2.2 设计目标)
- [三、SLS 索引设计------性能的基石](#三、SLS 索引设计——性能的基石)
- 四、完整代码实现
-
- [4.1 项目结构](#4.1 项目结构)
- [4.2 Maven 依赖](#4.2 Maven 依赖)
- [4.3 application.yml 配置](#4.3 application.yml 配置)
- [4.4 SLS Client 配置类](#4.4 SLS Client 配置类)
- [4.5 数据模型层](#4.5 数据模型层)
- [4.6 查询服务------智能路由核心](#4.6 查询服务——智能路由核心)
- [4.7 柱状图统计服务](#4.7 柱状图统计服务)
-
- [SQL 分析原理](#SQL 分析原理)
- [4.8 Controller 层](#4.8 Controller 层)
-
- [日志查询 + 柱状图 Controller](#日志查询 + 柱状图 Controller)
- [链路追踪 Controller](#链路追踪 Controller)
- [4.9 工具类](#4.9 工具类)
- 五、接口测试与响应数据
-
- [5.1 通用日志查询](#5.1 通用日志查询)
- [5.2 关键词全文检索](#5.2 关键词全文检索)
- [5.3 关键词 + 多条件过滤](#5.3 关键词 + 多条件过滤)
- [5.4 柱状图查询](#5.4 柱状图查询)
- [5.5 一体化搜索(日志 + 柱状图一起查)](#5.5 一体化搜索(日志 + 柱状图一起查))
- [5.6 Trace 链路查询](#5.6 Trace 链路查询)
- [5.7 Trace 链路摘要](#5.7 Trace 链路摘要)
- 六、关键设计要点
-
- [6.1 混合日志兼容策略](#6.1 混合日志兼容策略)
- [6.2 索引优化建议](#6.2 索引优化建议)
- [6.3 分页策略](#6.3 分页策略)
- [6.4 实时性保障](#6.4 实时性保障)
- [6.5 查询场景速查表](#6.5 查询场景速查表)
- 七、总结
一、前言
不知道大家有没有遇到过这种场景:业务线越来越多,日志格式五花八门,线上出了问题想查个日志,要么登录服务器 grep,要么去 SLS 控制台手写查询语句,效率低得让人头大。
我们团队维护了十几个微服务,日志大致分为两类:
- 结构化埋点日志:包含完整的调用链信息(traceId、spanId、scene、duration_ms 等),由框架层自动埋点产出,用于链路追踪和性能分析。这类日志字段固定、格式统一,查询时通常按 traceId 聚合或按耗时排序。
- 普通日志:字段不固定,可能就 message、timestamp、level 三件套,开发人员用在哪写到哪,没有统一的格式约束。
痛点很明显:两类日志写入同一个 SLS Logstore,但查询方式完全不同。结构化日志需要精确字段匹配,普通日志只能全文检索。如果分开两个 Logstore 管理,运维成本翻倍不说,联排问题时还得来回切换。
所以我们做了一个决定:写一个统一的查询服务,对外提供一套 REST API,内部智能路由到不同的查询策略,让调用方不用关心底层日志格式差异。
于是就有了这个项目------sls-log-query,一个 Spring Boot 3.5 + 阿里云 SLS SDK 的轻量查询服务,支持日志检索、Trace 链路追踪、柱状图统计三大核心能力。
本文会把从设计到落地的全过程掰开揉碎来讲,包括 SLS 索引配置、Java SDK 集成、查询路由策略、柱状图 SQL 分析、以及完整的接口测试示例。
二、系统架构总览
2.1 整体架构
先上架构图,一张图说清楚数据流和分层:
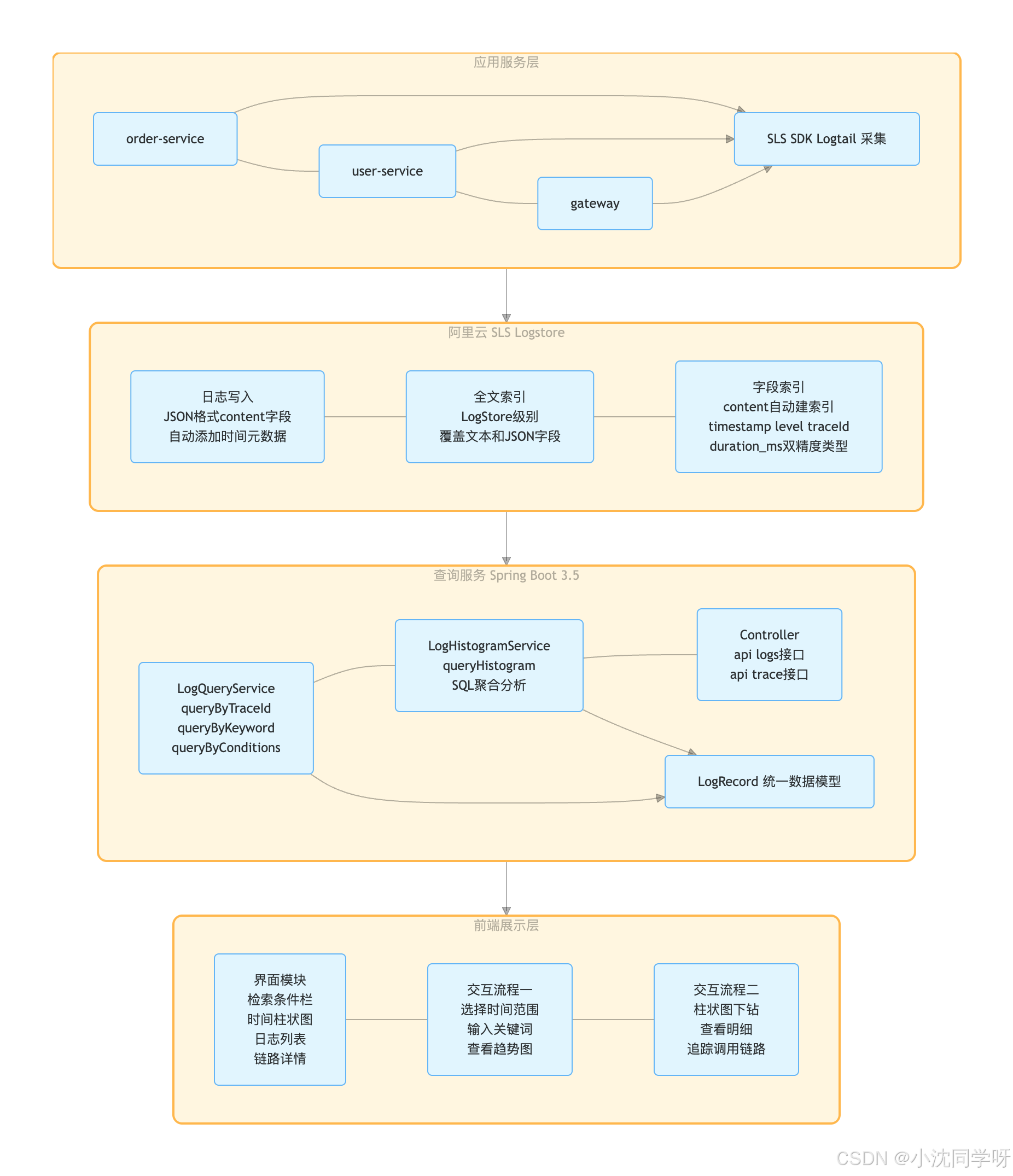
2.2 设计目标
| 目标 | 说明 | 实现方式 |
|---|---|---|
| 实时查询 | 日志写入后 1 秒内可检索 | SLS 实时写入 + SDK 轮询 |
| 混合兼容 | 同时支持结构化日志和普通日志查询 | 全文索引 + 字段索引双轨制 |
| 链路追踪 | 按 traceId 聚合全链路日志 | content.traceId:xxx 精确匹配 |
| 可视化 | 提供日志条数柱状图,支持时间粒度下钻 | SLS SQL 分析 + 时间分桶聚合 |
| 高性能 | 利用 SLS 索引,避免全量扫描 | 字段级索引 + 时间窗口限制 |
三、SLS 索引设计------性能的基石
说实话,SLS 查询快不快,90% 取决于索引配得好不好。索引配好了查询就是毫秒级响应,配不好就是全量扫描分分钟超时。
这一节我们重点讨论 SLS 的三种索引机制:全文索引 、字段索引 和 JSON 自动索引,以及我们项目最终选择了什么方案。
3.1 三种索引机制辨析
我们的日志统一以 JSON 格式写入 SLS 的 content 字段,一条典型的日志在 SLS 中存储为:
__time__: 1690000000
__source__: 10.0.1.5
__topic__:
content: {"timestamp":"2023-07-22T10:30:00Z","level":"ERROR","service":"order-service","message":"订单超时","traceId":"acb123def456","duration_ms":1520,"scene":"upstream_ingress"}先理清三个概念,很多同学容易混:
全文索引
全文索引是 LogStore 级别的配置,对整个日志的所有 text 字段生效。开启后,SLS 会将日志内容的文本(包括 JSON 字符串内的 key 名和 value)拆词索引。它的核心能力是:不限定字段的关键词搜索。
比如搜索 NullPointerException,SLS 会在所有日志的全文里匹配,不管这个关键词出现在 JSON 的哪个字段中(message、errorStack 还是别的字段),都能命中。
关于 content 字段类型 :虽然我们开启了全文索引,但
content字段本身的类型是json而不是text。设为json类型后,SLS 会解析 JSON 结构,支持对嵌套子字段建立字段索引(如content.traceId:xxx)。同时全文索引仍然对 JSON 内的文本值生效,两者并不冲突。
字段索引
对某个具体字段单独建立索引(如 content.level、content.traceId),让 SLS 能够跳过全文扫描,精确定位到特定字段值。它的核心能力是:精准的字段级查询,性能和效率最高。
比如搜索 content.level:ERROR,SLS 直接定位到 level 字段的索引,不需要扫描整个 content 文本。
JSON 自动索引
这是 SLS 控制台提供的一个便捷功能------在查询分析页面点击自动生成索引后,SLS 会根据采集时预览数据的第一条内容自动创建字段索引,操作步骤为:
- 开启索引后,在查询分析页面点击自动生成索引
- SLS 解析预览日志样本中的顶层 key,为每个 key 自动创建 text 类型的字段索引
- 对于类型为
json的字段,可以进一步手动配置嵌套子字段的索引
比如基于样本日志:
json
{"message":"订单超时","traceId":"abc123","duration_ms":1520,"errorStack":"NullPointerException at xxx"}控制台自动生成索引会创建以下字段索引:
| 自动创建的字段索引 | 类型 | 说明 |
|---|---|---|
content.message |
text | 自动生成 |
content.traceId |
text | 自动生成 |
content.errorStack |
text | 自动生成 |
content.duration_ms |
text | 自动生成,但类型不对! |
关于嵌套字段 :控制台的自动生成索引只解析日志样本的顶层的 key ,不会递归解析深层嵌套结构。如果日志中有嵌套 JSON(例如 {"request":{"headers":{"x-request-id":"xxx"}}}),自动生成索引只会识别 content.request 这个字段,而不会自动展开 content.request.headers 及更深层。要索引嵌套字段,有三种方式:
- 手动配置 :在控制台将
content字段类型设为json,然后手动添加嵌套子字段的索引 - SDK/API 方式 :使用
IndexJsonKeyConfig配置index_all: true并设置max_depth(默认 -1 表示无深度限制),SLS 会自动递归索引 JSON 内所有字符串值,直到达到最大深度 - 全文索引兜底:即使嵌套字段没有字段索引,全文索引也能保证关键词搜索可用
自动索引的局限性
自动索引虽然方便,但有三个明显的坑:
1. 数值类型默认配成 text,范围查询失效
这是最大的坑。duration_ms、cost、amount 这类数值字段,自动创建索引时默认是 text 类型,导致:
content.duration_ms > 1000 -- ❌ 不生效,text 类型不支持数值比较你必须手动把这类字段从 text 改成 double/long。
2. 不替代全文索引,不限定字段的关键词搜索仍然查不到
自动索引创建的是字段索引 ,不是全文索引。区别在于:
| 场景 | 有全文索引 | 仅靠自动索引(字段索引) |
|---|---|---|
搜索 NullPointerException |
✅ 直接搜,全字段匹配 | ❌ 必须指定 content.errorStack:NullPointerException |
| 不确定关键词在哪个字段 | ✅ 随便搜,都能命中 | ❌ 搜不到 |
字段值里有 timeout 但不知道是哪个字段 |
✅ 直接搜 timeout |
❌ 必须知道是 message 还是 error 字段 |
3. 索引膨胀风险
如果日志里有些字段是动态变化的(比如 requestHeaders 里的各种 header),自动索引会为每个新出现的字段都创建索引,长时间运行下来索引数量会膨胀,增加存储成本和索引管理复杂度。
3.2 三种方案对比
| 配置方案 | 不限定字段关键词搜索 | 字段精确匹配 | 数值范围查询 | 新字段自动覆盖 | 索引维护成本 |
|---|---|---|---|---|---|
| 仅全文索引 | ✅ 随便搜都能命中 | ❌ 无字段索引,性能较低 | ❌ 不支持数值语义 | ✅ 自动覆盖 | 低 |
| 仅字段索引(手动配) | ❌ 必须指定字段前缀 | ✅ 性能最高 | ✅ 手动配成 double/long | ❌ 新增字段需手动配 | 高 |
| 仅 JSON 自动索引 | ❌ 必须指定字段前缀 | ✅ 自动创建 | ❌ 默认 text,需手动改类型 | ✅ 自动发现新字段 | 中 |
| 全文 + JSON 自动索引(我们的方案) | ✅ 全文兜底 | ✅ 自动索引精准定位 | ✅ 手动修正数值类型 | ✅ 双保险 | 中 |
3.3 我们最终的选择:全文索引 + JSON 自动索引 + 手动修正
我们最终的方案是:
-
content字段类型设为json:让 SLS 解析 JSON 结构,支持嵌套子字段的字段索引 -
全文索引:开启 LogStore 级全文索引,用于不限定字段的关键词搜索兜底
-
JSON 自动创建索引:开启,让 SLS 自动为 content 下的顶层子字段创建 text 索引
-
手动修正数值类型 :将
duration_ms等数值字段从 text 改为 doublecontent 字段配置:
├── 字段类型:json ✅(解析 JSON 结构,支持嵌套字段索引)
├── 开启自动创建索引 ✅
│ └── 自动为顶层子字段创建 text 索引
│ └── 手动修正:duration_ms → double,确保范围查询可用
├── 全文索引(LogStore 级)✅
│ └── 用于无指定字段的关键词搜索
├── 字段索引优先级高于全文索引
之所以这么选,是因为我们的混合日志场景决定了:普通日志字段不固定,全靠手动配字段索引不现实;但光靠全文索引,字段级精确查询的性能又不够。两者互补,每种查询走最适合的路径。
3.4 通用字段索引(两种日志共用)
下面是实际配置的字段索引,不管结构化还是普通日志都会写入:
| 字段路径 | 类型 | 说明 | 查询示例 |
|---|---|---|---|
content.timestamp |
text | ISO8601 时间 | content.timestamp:"2023-07-22T10:*" |
content.level |
text | 日志级别 | content.level:ERROR |
content.message |
text | 日志内容 | content.message:*timeout* |
content.host |
text | 宿主机名 | content.host:prod-node-01 |
content.service |
text | 应用名 | content.service:order-service |
content.env |
text | 环境标识 | content.env:production |
3.5 结构化字段索引(仅埋点日志)
这些字段只有埋点日志才有,普通日志写入时不存在这些字段,但查询时不会报错,只是匹配不到结果:
| 字段路径 | 类型 | 说明 | 查询示例 |
|---|---|---|---|
content.traceId |
text | 全链路唯一标识 | content.traceId:acb123def456 |
content.spanId |
text | 当前处理阶段 | content.spanId:span-001 |
content.parentSpanId |
text | 上级 spanId | content.parentSpanId:span-000 |
content.scene |
text | 业务场景 | content.scene:upstream_ingress |
content.path |
text | HTTP 路径/RPC 方法名 | content.path:/api/orders |
content.method |
text | HTTP Method | content.method:POST |
content.duration_ms |
double | 耗时(毫秒) | content.duration_ms > 1000 |
content.error |
text | 错误信息 | content.error:*timeout* |
content.errorStack |
text | 错误堆栈 | content.errorStack:NullPointer* |
3.6 索引类型选择说明
| 类型 | 适用场景 | 查询能力 |
|---|---|---|
| text | 字符串字段 | 精确匹配、前缀查询、模糊匹配(* 和 ?) |
| json | 结构化 JSON 字段 | 解析 JSON 结构,支持声明嵌套子字段的索引 |
| double | 数值字段 | 范围查询(>, <, >=, <=) |
| long | 整数字段 | 范围查询、聚合计算 |
踩坑提醒 :
duration_ms一定要配成double或long,不要配成text。配成 text 的话,> 1000的范围查询不生效,SLS 会把它当字符串比较,结果完全不对。如果用了 JSON 自动索引,记得手动把数值字段从 text 改成 double。
四、完整代码实现
4.1 项目结构
sls-log-query/
├── pom.xml
└── src/main/java/com/example/slslog/
├── SlsLogQueryApplication.java # 启动类
├── config/
│ └── SlsConfig.java # SLS Client 配置
├── controller/
│ ├── LogQueryController.java # 日志查询 + 柱状图 API
│ └── TraceController.java # 链路追踪 API
├── model/
│ ├── LogQueryParam.java # 统一查询参数
│ ├── LogRecord.java # 日志记录模型
│ ├── LogQueryResult.java # 查询结果封装
│ └── HistogramEntry.java # 柱状图数据点
├── service/
│ ├── LogQueryService.java # 查询服务接口
│ ├── LogHistogramService.java # 柱状图服务接口
│ └── impl/
│ ├── LogQueryServiceImpl.java # 查询服务实现
│ └── LogHistogramServiceImpl.java # 柱状图服务实现
└── util/
└── JsonUtils.java # JSON 工具类4.2 Maven 依赖
pom.xml 的核心依赖:
xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.5</version>
</parent>
<groupId>com.example</groupId>
<artifactId>sls-log-query</artifactId>
<version>1.0.0</version>
<properties>
<java.version>17</java.version>
<aliyun-log.version>0.6.120</aliyun-log.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.aliyun.openservices</groupId>
<artifactId>aliyun-log</artifactId>
<version>${aliyun-log.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
</dependencies>4.3 application.yml 配置
所有敏感信息全部走环境变量注入,杜绝硬编码:
yaml
server:
port: 8080
spring:
application:
name: sls-log-query
sls:
endpoint: ${SLS_ENDPOINT}
access-key-id: ${SLS_ACCESS_KEY_ID}
access-key-secret: ${SLS_ACCESS_KEY_SECRET}
project: ${SLS_PROJECT}
logstore: ${SLS_LOGSTORE}
connect-timeout: 10000
read-timeout: 60000
max-connections: 50启动方式:
bash
export SLS_ENDPOINT=your-log-endpoint
export SLS_ACCESS_KEY_ID=your-access-key
export SLS_ACCESS_KEY_SECRET=your-access-secret
export SLS_PROJECT=your-project
export SLS_LOGSTORE=your-logstore
mvn spring-boot:run4.4 SLS Client 配置类
通过 @Configuration 注入单例的 SLS Client,设置了连接超时、读超时和最大连接数:
java
/**
* SlsConfig
*
* @author senfel
* @date 2026/6/19 10:36
*/
@Configuration
public class SlsConfig {
@Value("${sls.endpoint}")
private String endpoint;
@Value("${sls.access-key-id}")
private String accessKeyId;
@Value("${sls.access-key-secret}")
private String accessKeySecret;
@Value("${sls.project}")
private String project;
@Value("${sls.logstore}")
private String logstore;
@Value("${sls.connect-timeout:10000}")
private int connectTimeout;
@Value("${sls.read-timeout:60000}")
private int readTimeout;
@Value("${sls.max-connections:50}")
private int maxConnections;
public String getProject() {
return project;
}
public String getLogstore() {
return logstore;
}
@Bean
public Client slsClient() {
ClientConfiguration config = new ClientConfiguration();
config.setConnectionTimeout(connectTimeout);
config.setSocketTimeout(readTimeout);
config.setMaxConnections(maxConnections);
return new Client(endpoint, accessKeyId, accessKeySecret, "", config);
}
}配置参数说明:
| 参数 | 默认值 | 说明 |
|---|---|---|
connect-timeout |
10000ms | 建立连接超时 |
read-timeout |
60000ms | 读取数据超时,大查询要设置大一点 |
max-connections |
50 | 连接池大小,按 QPS 估算 |
4.5 数据模型层
统一查询参数
LogQueryParam 兼顾两类日志的所有查询场景:
java
/**
* LogQueryParam
*
* @author senfel
* @date 2026/6/19 10:37
*/
@Data
public class LogQueryParam {
private String keyword;
private String level;
private String service;
private String host;
private String env;
private String traceId;
private String scene;
private String path;
private String method;
private Double minDuration;
private Double maxDuration;
private Long from;
private Long to;
private Integer offset;
private Integer line;
private Integer intervalMinutes;
}参数分组速查:
| 分组 | 参数 | 适用日志类型 |
|---|---|---|
| 通用过滤 | keyword, level, service, host, env | 两种日志 |
| 结构化查询 | traceId, scene, path, method, minDuration, maxDuration | 仅埋点日志 |
| 时间范围 | from, to | 必填 |
| 分页控制 | offset, line | 两种日志 |
| 柱状图 | intervalMinutes | 柱状图专用 |
日志记录模型
LogRecord 是核心数据模型,关键设计点是 structured 标记字段和 contentMap 原始数据兜底:
java
/**
* LogRecord
*
* @author senfel
* @date 2026/6/19 10:37
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class LogRecord {
private String timestamp;
private String level;
private String message;
private String host;
private String service;
private String env;
private String traceId;
private String spanId;
private String parentSpanId;
private String scene;
private String path;
private String method;
private Double durationMs;
private String error;
private String rawJson;
private Map<String, Object> contentMap;
private boolean structured;
}structured 字段的判定逻辑很简单:如果这条日志包含 traceId,就认为是结构化埋点日志;否则就是普通日志。前端拿到这个标识就知道要不要展示 spanId、duration_ms 等结构化字段。
查询结果封装
java
/**
* LogQueryResult
*
* @author senfel
* @date 2026/6/19 10:37
*/
@Data
@Builder
public class LogQueryResult {
private List<LogRecord> records;
private long total;
private int offset;
private int line;
private boolean isCompleted;
}isCompleted 字段用来标识查询是否精确完成。SLS 在大数据量场景下可能返回部分结果(isCompleted = false),前端需要给用户提示"结果不精确,建议缩小时间范围"。
柱状图数据点
java
/**
* HistogramEntry
*
* @author senfel
* @date 2026/6/19 10:36
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class HistogramEntry {
private long timestamp;
private long count;
}每个 HistogramEntry 代表一个时间分桶,timestamp 是分桶起始时间戳(秒),count 是该桶内的日志条数。前端 ECharts 直接映射为柱状图的 X 轴和 Y 轴。
4.6 查询服务------智能路由核心
LogQueryServiceImpl 是整个系统的灵魂,实现了三种查询策略的智能路由:
java
/**
* LogQueryServiceImpl
*
* @author senfel
* @date 2026/6/19 10:38
*/
@Service
public class LogQueryServiceImpl implements LogQueryService {
private static final Logger log = LoggerFactory.getLogger(LogQueryServiceImpl.class);
private final Client slsClient;
private final SlsConfig slsConfig;
public LogQueryServiceImpl(Client slsClient, SlsConfig slsConfig) {
this.slsClient = slsClient;
this.slsConfig = slsConfig;
}
@Override
public LogQueryResult query(LogQueryParam param) throws Exception {
if (StringUtils.isNotBlank(param.getTraceId())) {
return queryByTraceId(param.getTraceId(), param);
} else if (StringUtils.isNotBlank(param.getKeyword())) {
return queryByKeyword(param);
} else {
return queryByConditions(param);
}
}
@Override
public LogQueryResult queryByTraceId(String traceId, LogQueryParam param) throws Exception {
LogQueryParam traceParam = new LogQueryParam();
traceParam.setFrom(param.getFrom() != null ? param.getFrom() : (System.currentTimeMillis() / 1000 - 1800));
traceParam.setTo(param.getTo() != null ? param.getTo() : (System.currentTimeMillis() / 1000));
traceParam.setOffset(0);
traceParam.setLine(100);
String query = "content.traceId:" + traceId;
LogQueryResult result = executeQuery(query, traceParam, false);
result.getRecords().sort(Comparator.comparing(LogRecord::getTimestamp,
Comparator.nullsFirst(Comparator.naturalOrder())));
return LogQueryResult.builder()
.records(result.getRecords())
.total(result.getTotal())
.isCompleted(result.isCompleted())
.build();
}
@Override
public LogQueryResult queryByKeyword(LogQueryParam param) throws Exception {
List<String> conditions = new ArrayList<>();
conditions.add(param.getKeyword());
if (StringUtils.isNotBlank(param.getService())) {
conditions.add("content.service:" + param.getService());
}
if (StringUtils.isNotBlank(param.getLevel())) {
conditions.add("content.level:" + param.getLevel());
}
if (StringUtils.isNotBlank(param.getHost())) {
conditions.add("content.host:" + param.getHost());
}
if (StringUtils.isNotBlank(param.getEnv())) {
conditions.add("content.env:" + param.getEnv());
}
if (StringUtils.isNotBlank(param.getScene())) {
conditions.add("content.scene:" + param.getScene());
}
if (StringUtils.isNotBlank(param.getPath())) {
conditions.add("content.path:" + param.getPath());
}
String query = String.join(" AND ", conditions);
return executeQuery(query, param, true);
}
@Override
public LogQueryResult queryByConditions(LogQueryParam param) throws Exception {
List<String> conditions = new ArrayList<>();
if (StringUtils.isNotBlank(param.getLevel())) {
conditions.add("content.level:" + param.getLevel());
}
if (StringUtils.isNotBlank(param.getService())) {
conditions.add("content.service:" + param.getService());
}
if (StringUtils.isNotBlank(param.getHost())) {
conditions.add("content.host:" + param.getHost());
}
if (StringUtils.isNotBlank(param.getEnv())) {
conditions.add("content.env:" + param.getEnv());
}
if (StringUtils.isNotBlank(param.getScene())) {
conditions.add("content.scene:" + param.getScene());
}
if (StringUtils.isNotBlank(param.getPath())) {
conditions.add("content.path:" + param.getPath());
}
if (param.getMinDuration() != null) {
conditions.add("content.duration_ms > " + param.getMinDuration());
}
if (param.getMaxDuration() != null) {
conditions.add("content.duration_ms < " + param.getMaxDuration());
}
String query = conditions.isEmpty() ? "*" : String.join(" AND ", conditions);
return executeQuery(query, param, true);
}
private LogQueryResult executeQuery(String query, LogQueryParam param, boolean reverse) throws Exception {
int from = getFrom(param);
int to = getTo(param);
int offset = param.getOffset() != null ? param.getOffset() : 0;
int line = Math.min(param.getLine() != null ? param.getLine() : 100, 100);
GetLogsResponse response = null;
Exception lastException = null;
for (int retry = 0; retry < 3; retry++) {
if (retry > 0) {
Thread.sleep((long) Math.pow(2, retry) * 1000);
}
try {
GetLogsRequest request = new GetLogsRequest(
slsConfig.getProject(),
slsConfig.getLogstore(),
from, to, "", query, offset, line, reverse
);
response = slsClient.GetLogs(request);
if (response != null && response.IsCompleted()) {
break;
}
} catch (Exception e) {
lastException = e;
log.warn("SLS query attempt {} failed, will retry: {}", retry + 1, e.getMessage());
}
}
if (response == null) {
throw new RuntimeException("SLS query failed after 3 retries, query=" + query, lastException);
}
return LogQueryResult.builder()
.records(parseRecords(response))
.total(response.GetCount())
.offset(offset)
.line(line)
.isCompleted(response.IsCompleted())
.build();
}
private List<LogRecord> parseRecords(GetLogsResponse response) {
List<LogRecord> records = new ArrayList<>();
for (QueriedLog queriedLog : response.getLogs()) {
LogItem item = queriedLog.GetLogItem();
LogRecord.LogRecordBuilder builder = LogRecord.builder();
for (LogContent content : item.mContents) {
String key = content.mKey;
String value = content.mValue;
switch (key) {
case "content.timestamp":
builder.timestamp(value);
break;
case "content.level":
builder.level(value);
break;
case "content.traceId":
builder.traceId(value);
break;
case "content.spanId":
builder.spanId(value);
break;
case "content.parentSpanId":
builder.parentSpanId(value);
break;
case "content.scene":
builder.scene(value);
break;
case "content.path":
builder.path(value);
break;
case "content.method":
builder.method(value);
break;
case "content.duration_ms":
try {
builder.durationMs(Double.parseDouble(value));
} catch (Exception e) {
builder.durationMs(null);
}
break;
case "content.message":
builder.message(value);
break;
case "content.host":
builder.host(value);
break;
case "content.service":
builder.service(value);
break;
case "content.env":
builder.env(value);
break;
case "content.error":
builder.error(value);
break;
case "content":
builder.rawJson(value);
Map<String, Object> contentMap = JsonUtils.parseMap(value);
builder.contentMap(contentMap);
if (contentMap != null) {
Object ts = contentMap.get("timestamp");
if (ts != null) builder.timestamp(String.valueOf(ts));
Object lv = contentMap.get("level");
if (lv != null) builder.level(String.valueOf(lv));
Object msg = contentMap.get("message");
if (msg != null) builder.message(String.valueOf(msg));
Object host = contentMap.get("host");
if (host != null) builder.host(String.valueOf(host));
Object svc = contentMap.get("service");
if (svc != null) builder.service(String.valueOf(svc));
Object env = contentMap.get("env");
if (env != null) builder.env(String.valueOf(env));
Object traceId = contentMap.get("traceId");
if (traceId != null) builder.traceId(String.valueOf(traceId));
Object spanId = contentMap.get("spanId");
if (spanId != null) builder.spanId(String.valueOf(spanId));
Object parentSpanId = contentMap.get("parentSpanId");
if (parentSpanId != null) builder.parentSpanId(String.valueOf(parentSpanId));
Object scene = contentMap.get("scene");
if (scene != null) builder.scene(String.valueOf(scene));
Object path = contentMap.get("path");
if (path != null) builder.path(String.valueOf(path));
Object method = contentMap.get("method");
if (method != null) builder.method(String.valueOf(method));
Object dur = contentMap.get("duration_ms");
if (dur != null) {
try {
builder.durationMs(Double.parseDouble(String.valueOf(dur)));
} catch (Exception e) {
builder.durationMs(null);
}
}
Object err = contentMap.get("error");
if (err != null) builder.error(String.valueOf(err));
}
break;
}
}
LogRecord record = builder.build();
record.setStructured(record.getTraceId() != null);
records.add(record);
}
return records;
}
private int getFrom(LogQueryParam param) {
return (int) (param.getFrom() != null ? param.getFrom() : System.currentTimeMillis() / 1000 - 3600);
}
private int getTo(LogQueryParam param) {
return (int) (param.getTo() != null ? param.getTo() : System.currentTimeMillis() / 1000);
}
}智能路由逻辑详解
核心在于 query() 方法的优先级路由:
用户请求参数
│
├── 有 traceId? ──→ queryByTraceId() 链路追踪
│ 生成 "content.traceId:xxx" 查询语句
│ 结果按时间戳升序排列
│
├── 有关键词? ──→ queryByKeyword() 全文检索
│ 关键词 + 可选过滤条件 AND 拼接
│ 兼容普通日志全文搜索
│
└── 其他条件 ──→ queryByConditions() 条件组合
通用条件 + 结构化条件自由组合
支持 duration_ms 范围查询响应解析中的两层兜底策略
parseRecords() 方法做了两层解析:
- 字段直接映射 :SLS 返回的
content.xxx字段直接赋值到 LogRecord 对应属性 - JSON 原始解析 :同时解析
content字段的完整 JSON 字符串,提取所有字段到contentMap
这样做的好处是:即使某个字段没有配置字段索引(比如 extra.someField),也能通过 contentMap 拿到原始数据,前端可以自由展示。
重试机制
executeQuery() 中的重试逻辑采用指数退避策略:
| 重试次数 | 等待时间 | 说明 |
|---|---|---|
| 第 1 次 | 0 | 直接请求 |
| 第 2 次 | 4 秒 | 2^2 = 4s |
| 第 3 次 | 8 秒 | 2^3 = 8s |
每次重试前检查 IsCompleted(),如果返回完整结果就直接返回,不需要等到 3 次都跑完。
4.7 柱状图统计服务
LogHistogramServiceImpl 利用 SLS 的 SQL 分析能力实现时间维度聚合:
java
/**
* LogHistogramServiceImpl
*
* @author senfel
* @date 2026/6/19 10:37
*/
@Service
public class LogHistogramServiceImpl implements LogHistogramService {
private static final Logger log = LoggerFactory.getLogger(LogHistogramServiceImpl.class);
private final Client slsClient;
private final SlsConfig slsConfig;
public LogHistogramServiceImpl(Client slsClient, SlsConfig slsConfig) {
this.slsClient = slsClient;
this.slsConfig = slsConfig;
}
@Override
public List<HistogramEntry> queryHistogram(LogQueryParam param) throws Exception {
int from = getFrom(param);
int to = getTo(param);
int interval = param.getIntervalMinutes() != null ? param.getIntervalMinutes() : 1;
String searchQuery = buildSearchQuery(param);
String sql = String.format(
"%s | SELECT __time__ - __time__ %% %d AS t, COUNT(*) AS cnt " +
"FROM log " +
"GROUP BY t " +
"ORDER BY t " +
"LIMIT 1000",
searchQuery,
interval * 60
);
GetLogsRequest request = new GetLogsRequest(
slsConfig.getProject(),
slsConfig.getLogstore(),
from, to, "", sql
);
GetLogsResponse response = slsClient.GetLogs(request);
List<HistogramEntry> entries = new ArrayList<>();
if (response != null) {
for (QueriedLog queriedLog : response.getLogs()) {
LogItem item = queriedLog.GetLogItem();
String colT = null;
String colCnt = null;
for (LogContent lc : item.mContents) {
if ("t".equals(lc.mKey)) {
colT = lc.mValue;
} else if ("cnt".equals(lc.mKey)) {
colCnt = lc.mValue;
}
}
if (colT != null && colCnt != null) {
long timestamp = Long.parseLong(colT);
long count = Long.parseLong(colCnt);
entries.add(new HistogramEntry(timestamp, count));
}
}
}
return entries;
}
private String buildSearchQuery(LogQueryParam param) {
List<String> conditions = new ArrayList<>();
if (param.getKeyword() != null) {
conditions.add(param.getKeyword());
}
if (param.getLevel() != null) {
conditions.add("content.level:" + param.getLevel());
}
if (param.getService() != null) {
conditions.add("content.service:" + param.getService());
}
if (param.getHost() != null) {
conditions.add("content.host:" + param.getHost());
}
if (param.getEnv() != null) {
conditions.add("content.env:" + param.getEnv());
}
if (param.getScene() != null) {
conditions.add("content.scene:" + param.getScene());
}
if (param.getPath() != null) {
conditions.add("content.path:" + param.getPath());
}
if (param.getTraceId() != null) {
conditions.add("content.traceId:" + param.getTraceId());
}
if (param.getMinDuration() != null) {
conditions.add("content.duration_ms > " + param.getMinDuration());
}
if (param.getMaxDuration() != null) {
conditions.add("content.duration_ms < " + param.getMaxDuration());
}
if (conditions.isEmpty()) {
return "*";
}
return String.join(" AND ", conditions);
}
private int getFrom(LogQueryParam param) {
return (int) (param.getFrom() != null ? param.getFrom() : System.currentTimeMillis() / 1000 - 21600);
}
private int getTo(LogQueryParam param) {
return (int) (param.getTo() != null ? param.getTo() : System.currentTimeMillis() / 1000);
}
}SQL 分析原理
生成的 SQL 类似这样:
sql
* | SELECT __time__ - __time__ % 60 AS t, COUNT(*) AS cnt
FROM log
GROUP BY t
ORDER BY t
LIMIT 1000核心技巧是 __time__ - __time__ % {intervalSeconds}:
__time__是 SLS 自带的 Unix 时间戳(秒)% intervalSeconds取模得到该桶内的偏移量- 两者相减得到桶的起始时间戳
举例说明:假设 intervalSeconds = 60(1分钟),时间戳 1690000050:
1690000050 - 1690000050 % 60=1690000050 - 30=1690000020- 所有落在 [1690000020, 1690000080) 范围内的日志都被归到同一个桶
柱状图粒度建议:
| 时间范围 | 推荐粒度 | 桶数量 |
|---|---|---|
| 1 小时内 | 1 分钟 | ≤ 60 |
| 6 小时内 | 5 分钟 | ≤ 72 |
| 24 小时内 | 30 分钟 | ≤ 48 |
| 7 天内 | 6 小时 | ≤ 28 |
4.8 Controller 层
日志查询 + 柱状图 Controller
LogQueryController 提供了三个接口:纯日志查询、纯柱状图、以及一体化搜索:
java
/**
* LogQueryController
*
* @author senfel
* @date 2026/6/19 10:29
*/
@RestController
@RequestMapping("/api/logs")
public class LogQueryController {
private final LogQueryService logQueryService;
private final LogHistogramService logHistogramService;
public LogQueryController(LogQueryService logQueryService, LogHistogramService logHistogramService) {
this.logQueryService = logQueryService;
this.logHistogramService = logHistogramService;
}
/**
* 通用日志查询
*/
@GetMapping("/query")
public ResponseEntity<LogQueryResult> query(LogQueryParam param) throws Exception {
LogQueryResult result = logQueryService.query(param);
return ResponseEntity.ok(result);
}
/**
* 柱状图统计
*/
@GetMapping("/histogram")
public ResponseEntity<List<HistogramEntry>> histogram(LogQueryParam param) throws Exception {
List<HistogramEntry> entries = logHistogramService.queryHistogram(param);
return ResponseEntity.ok(entries);
}
/**
* 一体化搜索:同时返回日志列表和柱状图
*/
@GetMapping("/search")
public ResponseEntity<Map<String, Object>> searchWithHistogram(LogQueryParam param) throws Exception {
long start = System.currentTimeMillis();
LogQueryResult logs = logQueryService.query(param);
List<HistogramEntry> histogram = logHistogramService.queryHistogram(param);
long elapsed = System.currentTimeMillis() - start;
Map<String, Object> response = new HashMap<>();
response.put("logs", logs);
response.put("histogram", histogram);
response.put("elapsedMs", elapsed);
return ResponseEntity.ok(response);
}
}链路追踪 Controller
TraceController 提供链路日志查询和链路摘要两个接口:
java
/**
* TraceController
*
* @author senfel
* @date 2026/6/19 10:32
*/
@RestController
@RequestMapping("/api/trace")
public class TraceController {
private final LogQueryService logQueryService;
public TraceController(LogQueryService logQueryService) {
this.logQueryService = logQueryService;
}
/**
* 按 traceId 查询全链路日志
*/
@GetMapping("/{traceId}")
public ResponseEntity<LogQueryResult> getTrace(
@PathVariable String traceId,
@RequestParam(required = false) Long from,
@RequestParam(required = false) Long to) throws Exception {
LogQueryParam param = new LogQueryParam();
param.setFrom(from);
param.setTo(to);
LogQueryResult result = logQueryService.queryByTraceId(traceId, param);
return ResponseEntity.ok(result);
}
/**
* 查询 Trace 链路摘要(含统计信息)
*/
@GetMapping("/{traceId}/summary")
public ResponseEntity<Map<String, Object>> getTraceSummary(
@PathVariable String traceId,
@RequestParam(required = false) Long from,
@RequestParam(required = false) Long to) throws Exception {
LogQueryParam param = new LogQueryParam();
param.setFrom(from);
param.setTo(to);
LogQueryResult result = logQueryService.queryByTraceId(traceId, param);
List<String> services = result.getRecords().stream()
.map(r -> r.getService())
.filter(s -> s != null)
.distinct()
.toList();
double totalDuration = result.getRecords().stream()
.filter(r -> r.getDurationMs() != null)
.mapToDouble(r -> r.getDurationMs())
.sum();
Map<String, Object> summary = new HashMap<>();
summary.put("traceId", traceId);
summary.put("spanCount", result.getRecords().size());
summary.put("services", services);
summary.put("totalDurationMs", totalDuration);
summary.put("records", result.getRecords());
return ResponseEntity.ok(summary);
}
}4.9 工具类
java
/**
* JsonUtils
*
* @author senfel
* @date 2026/6/19 10:36
*/
public class JsonUtils {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
private JsonUtils() {
}
public static Map<String, Object> parseMap(String json) {
try {
return OBJECT_MAPPER.readValue(json, new TypeReference<Map<String, Object>>() {
});
} catch (JsonProcessingException e) {
return Collections.emptyMap();
}
}
public static String toJson(Object value) {
try {
return OBJECT_MAPPER.writeValueAsString(value);
} catch (JsonProcessingException e) {
return "";
}
}
}五、接口测试与响应数据
下面用 curl 演示实际接口调用,并附上完整的 JSON 响应。
5.1 通用日志查询
请求:查询 order-service 的 ERROR 级别日志
bash
curl -s "http://localhost:8080/api/logs/query?service=order-service&level=ERROR&from=1690000000&to=1690086400&offset=0&line=10" | jq响应:
json
{
"records": [
{
"timestamp": "2023-07-22T10:30:00Z",
"level": "ERROR",
"message": "订单超时,订单ID: 202307221030001",
"host": "prod-node-01",
"service": "order-service",
"env": "production",
"traceId": "acb123def456",
"spanId": "span-003",
"parentSpanId": "span-001",
"scene": "upstream_ingress",
"path": "/api/orders/create",
"method": "POST",
"durationMs": 1520.0,
"error": "上游服务响应超时",
"structured": true,
"contentMap": {
"timestamp": "2023-07-22T10:30:00Z",
"level": "ERROR",
"message": "订单超时,订单ID: 202307221030001",
"service": "order-service",
"traceId": "acb123def456",
"duration_ms": 1520
}
},
{
"timestamp": "2023-07-22T10:25:00Z",
"level": "ERROR",
"message": "数据库连接超时",
"host": "prod-node-01",
"service": "order-service",
"env": "production",
"structured": false,
"contentMap": {
"timestamp": "2023-07-22T10:25:00Z",
"level": "ERROR",
"message": "数据库连接超时",
"service": "order-service"
}
}
],
"total": 2,
"offset": 0,
"line": 10,
"isCompleted": true
}注意看 structured 字段:第一条是 true(有 traceId),第二条是 false(没有 traceId,普通日志),前端可以根据这个标识来决定展示哪些字段列。
5.2 关键词全文检索
请求:搜索所有包含 "NullPointerException" 的日志
bash
curl -s "http://localhost:8080/api/logs/query?keyword=NullPointerException&from=1690000000&to=1690086400&line=20" | jq响应:
json
{
"records": [
{
"timestamp": "2023-07-22T09:15:30Z",
"level": "ERROR",
"message": "java.lang.NullPointerException: Cannot invoke method on null object",
"host": "prod-node-03",
"service": "user-service",
"env": "production",
"traceId": "xyz789abc012",
"spanId": "span-005",
"scene": "user_login",
"path": "/api/user/info",
"method": "GET",
"durationMs": 45.0,
"error": "NullPointerException",
"errorStack": "java.lang.NullPointerException\n\tat com.example.user.UserServiceImpl.getUserInfo(UserServiceImpl.java:85)\n\tat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)",
"structured": true,
"contentMap": {
"timestamp": "2023-07-22T09:15:30Z",
"level": "ERROR",
"message": "java.lang.NullPointerException: Cannot invoke method on null object",
"service": "user-service",
"traceId": "xyz789abc012",
"errorStack": "java.lang.NullPointerException\n\tat com.example.user..."
}
}
],
"total": 1,
"offset": 0,
"line": 20,
"isCompleted": true
}关键词全文检索对普通日志尤其有用------普通日志没有 traceId 之类的结构化字段,但通过全文索引,只要消息体里匹配到关键词就能搜出来。
5.3 关键词 + 多条件过滤
请求:搜索 ERROR 级别且耗时超过 1000ms 的日志
bash
curl -s "http://localhost:8080/api/logs/query?level=ERROR&minDuration=1000&from=1690000000&to=1690086400" | jq内部构建的 SLS 查询语句:
content.level:ERROR AND content.duration_ms > 10005.4 柱状图查询
请求:查询 6 小时内的日志分布,按 30 分钟粒度聚合
bash
curl -s "http://localhost:8080/api/logs/histogram?from=1690000000&to=1690086400&intervalMinutes=30&level=ERROR" | jq响应:
json
[
{
"timestamp": 1690000200,
"count": 5
},
{
"timestamp": 1690002000,
"count": 12
},
{
"timestamp": 1690003800,
"count": 8
},
{
"timestamp": 1690005600,
"count": 23
},
{
"timestamp": 1690007400,
"count": 3
}
]前端拿到这个数据结构后,ECharts 的配置非常简洁:
javascript
option = {
xAxis: {
type: 'category',
data: data.map(d => new Date(d.timestamp * 1000).toLocaleTimeString())
},
yAxis: { type: 'value' },
series: [{
type: 'bar',
data: data.map(d => d.count)
}]
};从响应数据可以直观看到,1690005600(2023-07-22 10:00)这个时段出现了一个异常峰值(23 条),运维同学可以点击这个柱状图下钻到该时间段的日志明细。
5.5 一体化搜索(日志 + 柱状图一起查)
请求:一次请求同时获取日志列表和柱状图
bash
curl -s "http://localhost:8080/api/logs/search?service=order-service&level=ERROR&from=1690000000&to=1690086400&intervalMinutes=30" | jq响应:
json
{
"logs": {
"records": [
{
"timestamp": "2023-07-22T10:30:00Z",
"level": "ERROR",
"message": "订单超时,订单ID: 202307221030001",
"service": "order-service",
"structured": true,
"durationMs": 1520.0
}
],
"total": 1,
"offset": 0,
"line": 100,
"isCompleted": true
},
"histogram": [
{ "timestamp": 1690000200, "count": 2 },
{ "timestamp": 1690002000, "count": 5 },
{ "timestamp": 1690003800, "count": 1 }
],
"elapsedMs": 234
}elapsedMs 字段返回了总耗时(234ms),前端可以展示给用户或者做性能监控。这个接口适合页面首次加载时一次性获取所有数据。
5.6 Trace 链路查询
请求:查询指定 traceId 的全链路日志
bash
curl -s "http://localhost:8080/api/trace/acb123def456?from=1690000000&to=1690086400" | jq响应:
json
{
"records": [
{
"timestamp": "2023-07-22T10:29:50Z",
"service": "gateway",
"traceId": "acb123def456",
"spanId": "span-000",
"parentSpanId": null,
"scene": "http_ingress",
"path": "/api/orders/create",
"method": "POST",
"durationMs": 1520.0
},
{
"timestamp": "2023-07-22T10:29:51Z",
"service": "order-service",
"traceId": "acb123def456",
"spanId": "span-001",
"parentSpanId": "span-000",
"scene": "upstream_ingress",
"path": "/api/orders/create",
"method": "POST",
"durationMs": 1500.0
},
{
"timestamp": "2023-07-22T10:29:52Z",
"service": "payment-service",
"traceId": "acb123def456",
"spanId": "span-002",
"parentSpanId": "span-001",
"scene": "payment_process",
"durationMs": 1420.0
}
],
"total": 3,
"offset": 0,
"line": 100,
"isCompleted": true
}从结果可以还原整个调用链路:
gateway (span-000, 1520ms)
└── order-service (span-001, 1500ms)
└── payment-service (span-002, 1420ms)一眼就能看出慢在哪里------payment-service 占了 1420ms,是整个请求的瓶颈。
5.7 Trace 链路摘要
请求:查询链路摘要(含统计信息)
bash
curl -s "http://localhost:8080/api/trace/acb123def456/summary?from=1690000000&to=1690086400" | jq响应:
json
{
"traceId": "acb123def456",
"spanCount": 3,
"services": ["gateway", "order-service", "payment-service"],
"totalDurationMs": 4440.0,
"records": [
{
"timestamp": "2023-07-22T10:29:50Z",
"service": "gateway",
"spanId": "span-000",
"durationMs": 1520.0
},
{
"timestamp": "2023-07-22T10:29:51Z",
"service": "order-service",
"spanId": "span-001",
"durationMs": 1500.0
},
{
"timestamp": "2023-07-22T10:29:52Z",
"service": "payment-service",
"spanId": "span-002",
"durationMs": 1420.0
}
]
}摘要接口特别适合做 Trace 详情页的顶部概览------一眼看到涉及多少个服务、总耗时多少,再往下展开看明细。
六、关键设计要点
6.1 混合日志兼容策略
这是项目最核心的挑战,也是花时间最多的部分。最终方案总结如下:
| 策略 | 实现方式 | 原理 |
|---|---|---|
| 全文检索兜底 | keyword 直接放入 SLS 查询语句 |
利用 LogStore 级全文索引,不依赖字段索引 |
| 字段查询容错 | content.traceId:xxx,不存在的字段自然无结果 |
SLS 不会因为字段不存在而报错 |
| 聚合兼容 | SQL 中使用 COALESCE(content.service, 'unknown') |
空值自动填充默认值 |
| 类型自动识别 | Java 代码判断 traceId 是否存在 |
record.setStructured(traceId != null) |
| 原始数据兜底 | contentMap 保留完整 JSON |
前端可以拿到所有原始字段 |
6.2 索引优化建议
| 查询场景 | 索引建议 | 原因 |
|---|---|---|
| level 过滤 | 建 text 索引 | 精确匹配,无索引则全量扫描 |
| traceId 查询 | 建 text 索引 | 链路追踪的核心字段 |
| duration_ms 范围查询 | 建 double 索引 | > < 范围查询必须数值索引 |
| message 模糊查询 | 建 text 索引 | 支持 *timeout* 通配符 |
| 耗时排序 | duration_ms 建 double 索引 | 排序操作需要字段索引 |
6.3 分页策略
| 场景 | 分页方式 | 说明 |
|---|---|---|
| 纯查询语句 | offset + line |
line 最大 100,超了会被截断 |
| SQL 分析语句 | LIMIT offset, line |
建议每次 500~1000 |
| 翻页结束判断 | IsCompleted() && count == 0 |
必须检查 IsCompleted() |
6.4 实时性保障
| 措施 | 说明 |
|---|---|
| SLS 实时写入 | 日志写入后 1 秒内可查询(SLS 保证) |
| 索引配置 | 所有查询字段建立索引,避免全量扫描 |
| 时间窗口 | 默认查询最近 6 小时,限制扫描范围 |
| 重试机制 | 指数退避重试,最多 3 次,应对网络抖动 |
| 超时控制 | 读超时 60 秒,大查询不会无限等待 |
| 连接池 | 50 个连接,复用 TCP 连接减少开销 |
6.5 查询场景速查表
| 场景 | 接口 | 参数示例 | 对应日志类型 |
|---|---|---|---|
| Trace 链路 | GET /api/trace/{traceId} |
traceId=acb123def456 |
结构化 |
| 服务 ERROR | GET /api/logs/query |
service=order-service&level=ERROR |
通用 |
| 全文关键词 | GET /api/logs/query |
keyword=NullPointerException |
通用 |
| 慢查询 | GET /api/logs/query |
minDuration=1000&level=ERROR |
结构化 |
| 特定路径 | GET /api/logs/query |
path=/api/orders |
结构化 |
| 普通日志全文 | GET /api/logs/query |
keyword=数据库连接超时 |
普通日志 |
| 柱状图趋势 | GET /api/logs/histogram |
intervalMinutes=30 |
通用 |
| 登录页面 | GET /api/logs/search |
一体化搜索 | 通用 |
七、总结
项目整体做下来,核心收获有三点:
1. SLS 索引是性能的命门。 字段级索引配得好,查询就是毫秒级;配不好就是全表扫描,等得你想砸键盘。尤其要注意 double 类型和 text 类型的区别,数值范围查询必须用数值索引。
2. 混合日志兼容并不复杂。 核心思路是"宽容设计"------不强制字段存在,查询时自然过滤,代码里兜底处理。全文索引 + 字段索引双管齐下,两种日志都能高效检索。JSON 原始数据的 contentMap 兜底策略,保证了即使未来新增字段也能无缝展示。
3. 柱状图 + 日志列表的交互模式 真的很好用。运维同学先看趋势图定位异常时间段,再点击柱状图下钻到具体日志明细,排查效率比纯列表翻页高了一个档次。从测试数据来看,一次一体化搜索请求在 200~300ms 内就能同时返回日志列表和柱状图数据,体验相当流畅。
适用场景
- 微服务架构下的统一日志查询平台
- 需要链路追踪能力的业务系统
- 运维监控、故障排查场景
- 多环境(生产、预发、测试)日志统一管理
后续优化方向
- TraceId 结果缓存:同一链路短时间内反复查看,缓存 30 秒避免重复查 SLS
- 异步写入:接入消息队列做异步日志写入,避免日志量突增时打满 SLS 写入 QPS
- 多维聚合:柱状图支持按 level、service 分组堆叠展示,一个图表里看到各服务的错误分布
- 告警集成:柱状图数据对接告警规则,日志量突增时自动触发告警
感谢各位看官的一路陪伴,这篇文章从设计文档、完整代码到接口测试数据都梳理了一遍,希望能对正在建设日志平台的你有所帮助。有任何问题或者更好的思路,欢迎留言交流!