目录:
- 背景
- 损失函数
- 核心思想
- 伪代码
- python 例子
一、背景
在 PPO 之前,策略梯度(Policy Gradient)家族主要面临两个两难的困境:
- 传统策略梯度(Vanilla Policy Gradient, 比如 REINFORCE):
- 痛点:步长(Step Size)极其敏感。 深度学习中的神经网络一旦更新步长过大,策略就可能"崩溃"(性能直线下降),且很难恢复;如果步长太小,学习速度又像蜗牛一样慢。
- 样本效率极低: 每次采集的数据用算完一次梯度后就必须丢弃,不能重复利用。
- TRPO (Trust Region Policy Optimization, 信任域策略优化):
- 痛点:数学和计算极其复杂。 TRPO 引入了 KL 散度约束,巧妙地从数学上保证了策略每次更新都在变好(单调递增)。但是,它在求解时需要计算 Fisher 信息矩阵以及使用共轭梯度法(二阶优化)。这不仅代码实现复杂,而且计算开销极大,很难与包含 Dropout 或参数共享的复杂神经网络架构(如
RNN/CNN配合 Actor-Critic)兼容。
- 痛点:数学和计算极其复杂。 TRPO 引入了 KL 散度约束,巧妙地从数学上保证了策略每次更新都在变好(单调递增)。但是,它在求解时需要计算 Fisher 信息矩阵以及使用共轭梯度法(二阶优化)。这不仅代码实现复杂,而且计算开销极大,很难与包含 Dropout 或参数共享的复杂神经网络架构(如
PPO 的核心动机就是: 能不能发明一种算法,既保留 TRPO 那样稳定、不崩溃的更新保证,又能像传统策略梯度那样只使用简单的一阶优化
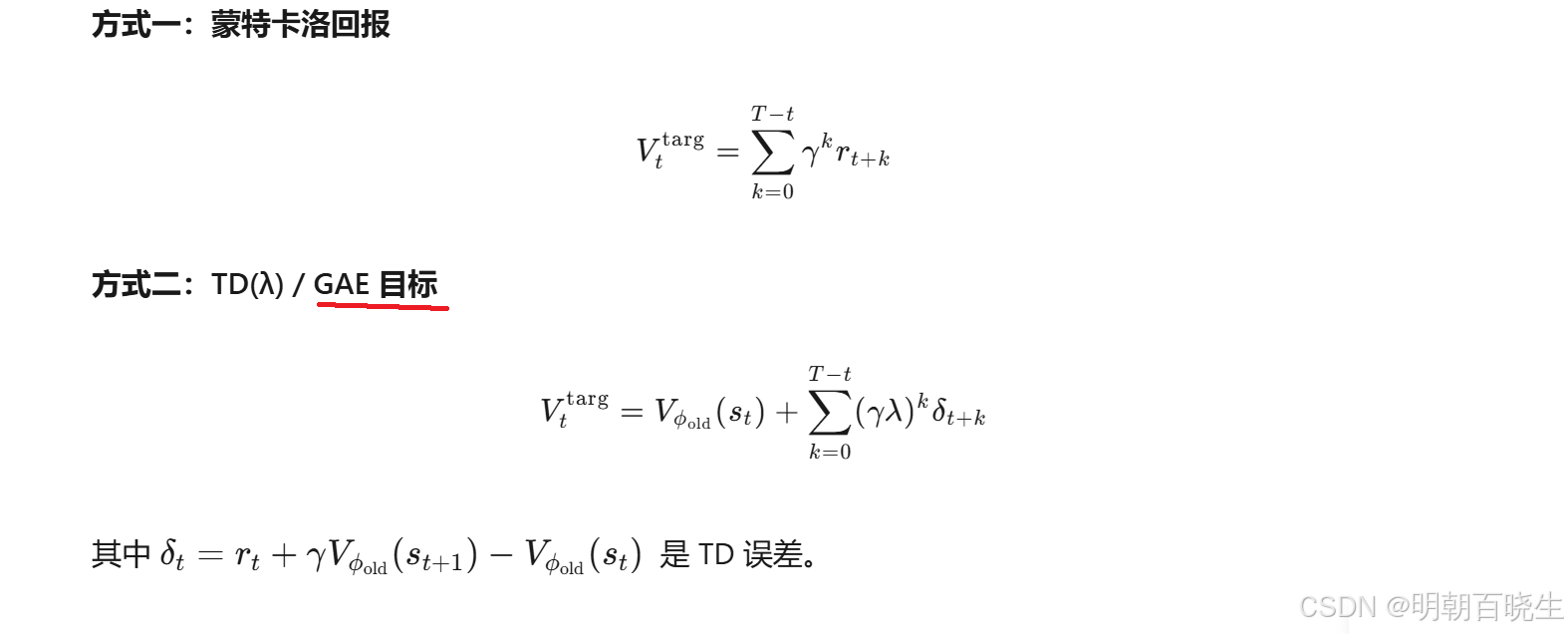
二 损失函数
1: Actor 动作网络的损失函数

2 Critic 价值网络的损失函数

一般用GAE 目标
三 核心思想
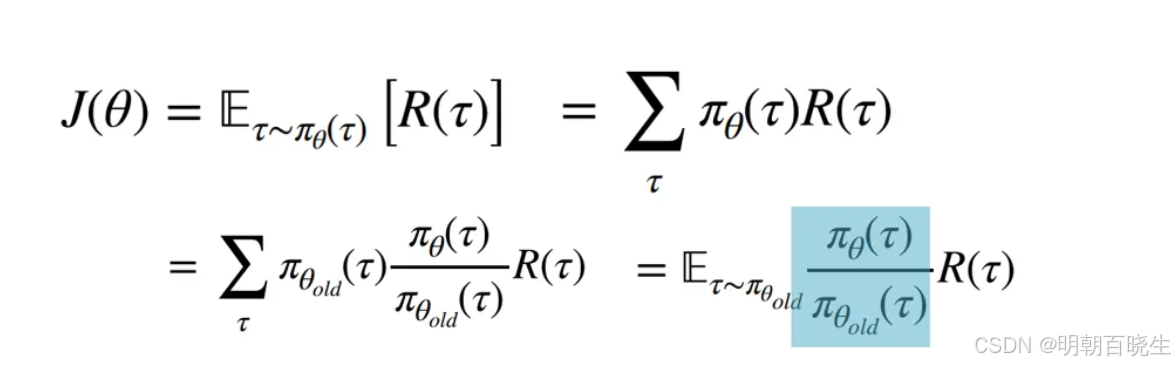
1. 概率比率 (Probability Ratio)
首先,论文定义了新旧策略在给定状态 下采取动作
的概率比率:
- 当
时,说明新策略采取该动作的概率变大了。
- 当
2. 无约束的目标函数 (CPI)
如果我们只考虑最大化优势函数(Advantage Function,用 表示,代表这个动作比平均水平好多少),目标函数是:
如果直接用神经网络优化这个函数,由于没有任何约束,网络为了追求最大化,会把
变得无限大(如果
),导致新旧策略差异过大,策略直接崩溃。
3. PPO 的杀手锏:Clipped Objective 函数
PPO 引入了一个超参数 (论文中通常取
0.2),并设计了如下的截断目标函数:
这个公式看起来复杂,但原理异常优雅。它包含了两部分,并取最小值(即悲观下界,Pessimistic Bound):
- 正常计算的项:
- 强行截断的项:将比率限制在 `0.8`, `1.2`之间,再乘上优势值。
为什么这个公式有效?我们分两种情况来理解:
-
情况 A:优势
1.2)时,clip 函数生效,截断项变成了min操作,此时目标函数的值就不再随 -
情况 B:优势
0.8)时,clip 函数生效。 同样因为外层的min操作(注意这里0.8,梯度就变成了 0。 专家直白解释: "这个动作很糟糕,我们要降低它的概率。但也不要一棍子打死,比原来降低 20% 就行了,保留一点探索的可能性,也防止策略剧烈震荡。"

根据论文的实验和随后的业界实践,PPO 胜出主要归功于以下几点:
- 样本利用率大幅提高(Sample Efficiency): 传统的 Policy Gradient,数据用一次就要扔掉。而 PPO 因为有了截断机制的保护,新旧策略不会偏差太远。因此,同一批采样来的数据,可以在神经网络中放心地循环训练好几个 Epoch(通常是 4 到 10 次)。这极大地节省了与环境交互的时间和成本。
- 实现简单,易于调试(Simplicity): 没有复杂的二阶导数,没有共轭梯度,只有几十行普通的
PyTorch/TensorFlow代码加上一个torch.clamp(截断)操作。它可以使用标准的 Adam 优化器直接训练。 - 超强的鲁棒性和通用性(Robustness): PPO 对超参数(如学习率、网络结构)相对不敏感。无论是在离散动作空间(如玩雅达利游戏)、还是连续动作空间(如控制机器人走路、机械臂抓取),甚至是自然语言处理的生成任务(RLHF),一套标准配置的 PPO 往往都能跑到不错的 Baseline,不需要像 DDPG 或 SAC 那样疯狂调参。
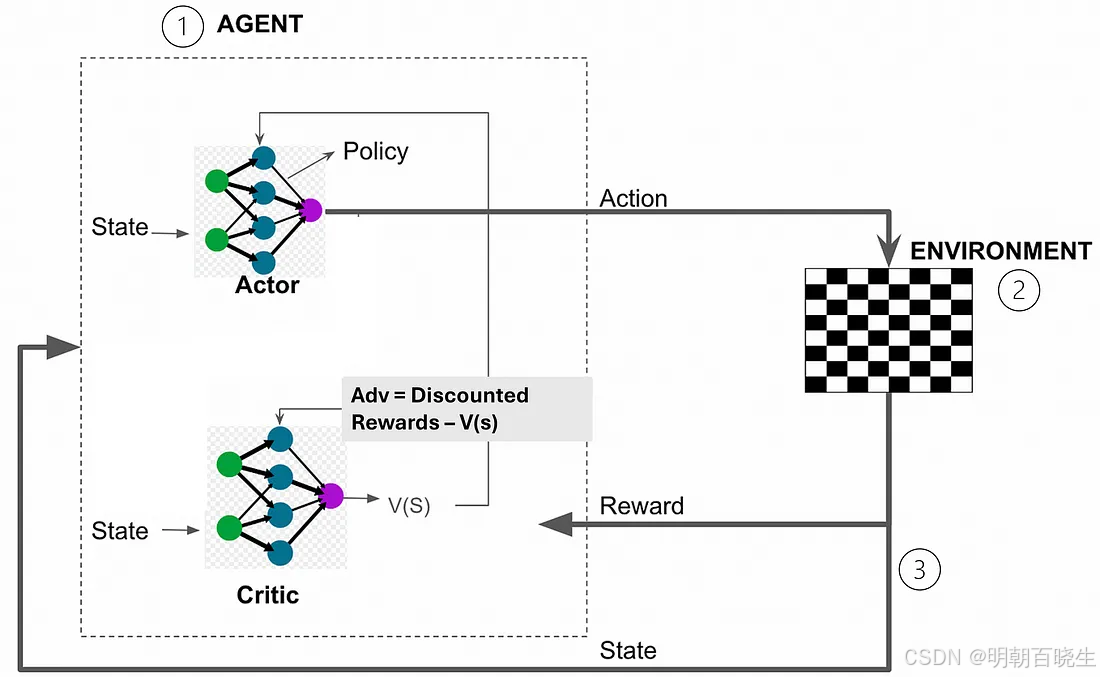
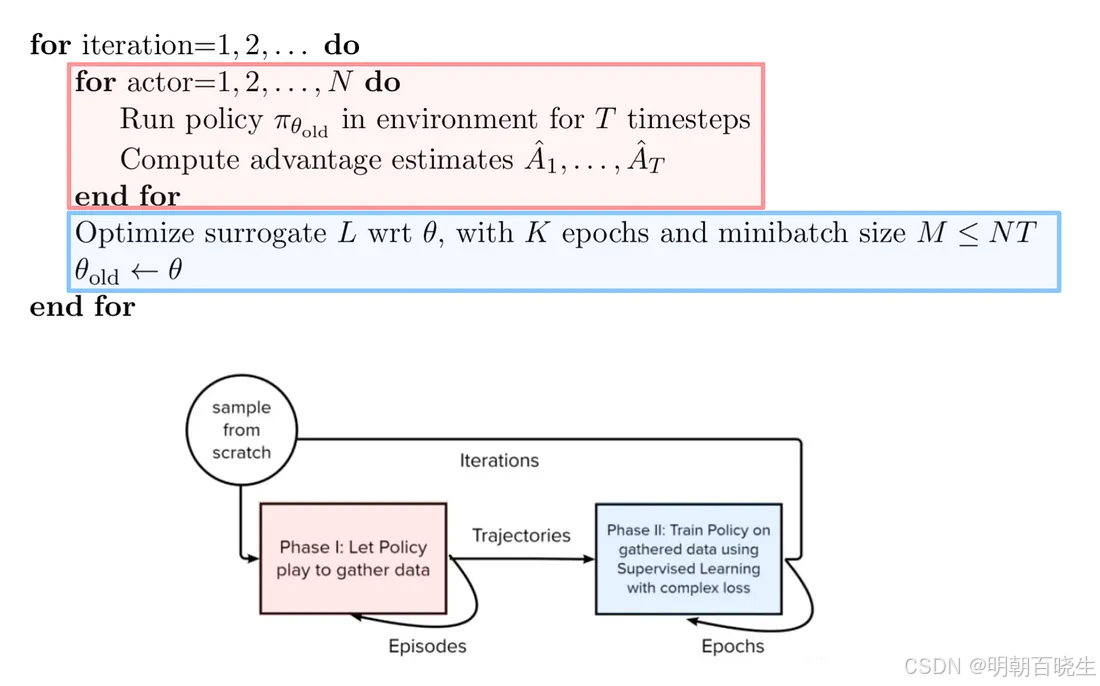
四 伪代码
五 Python 例子
BipedalWalkerHardcore-v3
# -*- coding: utf-8 -*-
"""
基于 PyTorch 的 PPO 完整实现(针对经典离散控制环境 CartPole-v1 进行深度定制)
参考 PPO 论文 (Schulman et al., 2017) 以及离散决策空间下的 PPO 最佳实践
作者: chengxf2
日期: 2026-06-17
"""
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler
# ---------------------------- 超参数配置 ----------------------------
GAMMA = 0.99 # 折扣因子
LAMBDA_GAE = 0.95 # GAE 系数
CLIP_EPSILON = 0.2 # PPO 截断范围
ACTOR_LR = 1e-3 # Actor 学习率 (经典值)
CRITIC_LR = 1e-3 # Critic 学习率 (更快速地拟合简单价值函数)
BATCH_SIZE = 500 # 每次更新前收集的步数 (CartPole 满行为 500 步,设为 500 可保证高频稳定的策略迭代)
MINI_BATCH_SIZE = 64 # 每次更新时的小批量大小
K_EPOCHS = 10 # 每批数据重复更新的轮数
ENTROPY_COEF = 0.01 # 熵正则系数 (离散空间使用 0.01 确保前期策略探索概率均匀,防止动作过早固化)
MAX_EPISODES = 200 # 最大训练回合数 (重构后在 100-150 回合内即可完美达到 500 分满分)
MAX_STEPS_PER_EP = 500 # 每回合最大步数(CartPole-v1 官方上限为 500 步)
STATE_DIM = 4 # 状态维度:4维连续观测向量(车位、车速、杆角、杆角速度)
ACTION_DIM = 2 # 动作维度:2维离散动作空间(0: 向左推小车, 1: 向右推小车)
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def orthogonal_init(layer, gain=1.0):
"""正交初始化权重,极大提高 PPO 策略梯度的更新平滑度"""
if isinstance(layer, nn.Linear):
nn.init.orthogonal_(layer.weight, gain=gain)
if layer.bias is not None:
nn.init.constant_(layer.bias, 0.0)
def kaiming_init(layer, bias=0.0):
"""正交初始化权重,极大提高 PPO 策略梯度的更新平滑度"""
if isinstance(layer, nn.Linear):
nn.init.kaiming_uniform_(layer.weight,nonlinearity='relu')
if layer.bias is not None:
nn.init.constant_(layer.bias, 0)
class ActorNet(nn.Module):
"""
策略网络(Actor):
针对 CartPole-v1 离散 2 维动作空间重新设计。
网络接收 4 维姿态输入,输出 2 维离散动作的未归一化对数概率(Logits)。
在更新和采样时结合 PyTorch 的 Categorical 离散概率分布:
- action = 0: 向左推, 施加-10N的力
- action = 1: 向右推, 施加10N的力
"""
def __init__(self, state_dim, action_dim=2, hidden_dim=64):
super(ActorNet, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, action_dim)
# 权重正交初始化
kaiming_init(self.fc1, bias=0.0)
kaiming_init(self.fc2, bias=0.0)
kaiming_init(self.fc3, bias=0.0) # 最后一层选用极小的增益,使初始输出的左右推动动作概率极度平衡
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
logits = self.fc3(x)
return logits
def get_action(self, state):
"""
根据状态进行离散概率采样
:param state: torch.Tensor [1, state_dim]
:return: action (torch.Tensor [1]), log_prob (torch.Tensor [1, 1])
"""
logits = self.forward(state)
#内部自动做了 softmax,把 logits 转成概率分布:
dist = Categorical(logits=logits) # 构建离散 Categorical 分布
action = dist.sample() # 采样动作 (0 或 1)
log_prob = dist.log_prob(action).unsqueeze(-1) # 离散对数概率 [1, 1] tensor([[-0.5653]]) torch.Size([1, 1])
return action, log_prob
def evaluate(self, state, action):
"""
评估动作:计算在当前控制律下,执行指定离散动作的对数概率和熵。
:param state: torch.Tensor [batch, state_dim]
:param action: torch.Tensor [batch],通常为 LongTensor
:return: log_prob (torch.Tensor [batch, 1]), entropy (torch.Tensor [])
"""
logits = self.forward(state)
#[batch_size, action_dim]
dist = Categorical(logits=logits)
log_prob = dist.log_prob(action).unsqueeze(-1)
entropy = dist.entropy().unsqueeze(-1).mean()
#熵值越大,代表动作概率分布越平坦,策略的随机性越强(探索性越好);
#熵值越小,代表策略越"自信"(倾向于某一特定动作,易陷入局部最优)。
return log_prob, entropy
class CriticNet(nn.Module):
def __init__(self, state_dim, hidden_dim=64):
super(CriticNet, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, 1)
# 使用Kaiming初始化
kaiming_init(self.fc1)
kaiming_init(self.fc2)
kaiming_init(self.fc3)
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
value = self.fc3(x)
return value
class PPO:
"""PPO 离散算法主体"""
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
# 神经网络实例化并移至设备
self.actor_net = ActorNet(state_dim, action_dim).to(device)
self.critic_net = CriticNet(state_dim).to(device)
# 优化器
self.actor_optimizer = optim.Adam(self.actor_net.parameters(), lr=ACTOR_LR, eps=1e-5)
self.critic_optimizer = optim.Adam(self.critic_net.parameters(), lr=CRITIC_LR, eps=1e-5)
# 经验缓冲区
self.states = []
self.actions = []
self.rewards = []
self.terminateds = []
self.truncateds = []
self.log_probs = []
self.values = []
def choose_action(self, state):
"""
纯净非阻塞动作采样(解耦存储逻辑,易于评估)
"""
#(feature_dim)
state_t = torch.FloatTensor(state)
#(feature_dim)--->(batch, feature_dim)
state_t = state_t.unsqueeze(0).to(device) # [1, state_dim]
with torch.no_grad():
action_t, log_prob_t = self.actor_net.get_action(state_t)
value_t = self.critic_net(state_t)
action = action_t.squeeze(0).cpu().numpy().item() # 转换为 Python 整数 (0 或 1)
log_prob = log_prob_t.squeeze().cpu().numpy().item() # 对数概率标量
value = value_t.squeeze().cpu().numpy().item() # 状态价值标量
return action, log_prob, value
def get_value(self, state):
"""姿态评估 V(s)"""
state_t = torch.FloatTensor(state).unsqueeze(0).to(device)
with torch.no_grad():
value = self.critic_net(state_t)
return value.squeeze().cpu().numpy().item()
def store_transition(self, state, action, reward, terminated, truncated, log_prob, value):
"""向缓冲区存入一步物理交互经验"""
self.states.append(state)
self.actions.append(action)
self.rewards.append(reward)
self.terminateds.append(terminated)
self.truncateds.append(truncated)
self.log_probs.append(log_prob)
self.values.append(value)
def compute_gae(self, next_value):
"""
计算广义优势估计(GAE),为 PPO 提供平滑、低方差、低偏差的优势值。
GAE 的核心作用:
-----------------
- **平衡偏差与方差**:直接使用蒙特卡洛回报(高方差)或 TD(0)(高偏差)都不理想。
GAE 通过指数加权平均所有时刻的 TD 误差,将方差压到极低(因为不依赖未来随机回报的累加),
同时允许价值网络的微小误差被后续的时序差分项逐步修正,从而显著降低偏差。
- **稳定策略更新**:GAE 提供的优势值极其平滑且可信,使得 PPO 能够以较大的步长进行多次梯度更新
而不导致性能崩溃------这是 PPO 成为工业界首选 on-policy 算法的关键原因之一。
- **超参数控制权衡**:参数 λ(LAMBDA_GAE)允许平滑地在偏差(λ→0,接近 TD(0))和
方差(λ→1,接近蒙特卡洛)之间调节,适应不同环境的时间关联性。
回合结束状态的处理(防止非平稳自举):
------------------------------------------
本实现区分两种"done"状态,分别处理 GA 的自举与重置:
1. **terminated**(真正的任务终止,如失败/成功):
- 未来奖励为零,因此 `next_val = 0.0`(不自举)。
- GAE 累计因子 `(1 - done_i)` 置零,使得 `gae = δ_i`,即历史优势被丢弃,
当前步的 TD 误差成为新的起点(这等价于"GAE 重置")。
2. **truncated**(因达到最大时间步而截断,如 500 步限制):
- 环境可能尚未真正结束,因此使用价值网络自举 `next_val = V(s_{i+1})`,以保留截断后的潜在回报。
- 但同样将 `(1 - done_i)` 置零,使 GAE 重置,避免将"人为截断"误判为长期优势,从而防止价值估计偏差传播。
计算步骤(逆序):
-----------------
对每个时间步 i(从后向前):
δ_i = r_i + γ * next_val - V(s_i)
gae_i = δ_i + γ * λ * (1 - done_i) * gae_{i+1}
adv_i = gae_i
return_i = gae_i + V(s_i)
参数:
next_value (float):最后一个时间步之后的状态价值 V(s_T),用于在截断时自举。
返回:
advantages (list[float]):每个时间步的优势估计 adv_i,用于策略网络更新。
returns (list[float]):每个时间步的回报估计 return_i,用于价值网络拟合。
全局超参数(在外部定义):
GAMMA (float) : 折扣因子,控制未来奖励的权重。
LAMBDA_GAE (float) : GAE 衰减系数,0~1 之间,越大越偏向蒙特卡洛(高方差),越小越偏向 TD(高偏差)。
"""
advantages = []
returns = []
gae = 0.0
values = self.values + [next_value]
for i in reversed(range(len(self.rewards))):
done_i = self.terminateds[i] or self.truncateds[i]
if self.terminateds[i]:
next_val = 0.0
else:
next_val = values[i + 1]
delta = self.rewards[i] + GAMMA * next_val - values[i]
gae = delta + GAMMA * LAMBDA_GAE * (1.0 - done_i) * gae
advantages.insert(0, gae)
returns.insert(0, gae + values[i])
return advantages, returns
def update(self, next_state):
"""
离散动作 PPO 策略参数优化
"""
data_len = len(self.states)
if data_len == 0:
return
if self.terminateds[-1]:
next_value = 0.0
else:
next_value = self.get_value(next_state)
advantages, returns = self.compute_gae(next_value)
states = torch.FloatTensor(np.array(self.states)).to(device)
# 离散动作更新在 PyTorch 索引中必须使用 LongTensor 格式类型
actions = torch.LongTensor(np.array(self.actions)).to(device)
old_log_probs = torch.FloatTensor(np.array(self.log_probs)).to(device)
advantages = torch.FloatTensor(np.array(advantages)).to(device)
returns = torch.FloatTensor(np.array(returns)).to(device)
# 10 轮小批量策略迭代
for _ in range(K_EPOCHS):
sampler = BatchSampler(SubsetRandomSampler(range(data_len)), MINI_BATCH_SIZE, drop_last=False)
for indices in sampler:
batch_states = states[indices]
batch_actions = actions[indices]
batch_old_log_probs = old_log_probs[indices]
batch_adv = advantages[indices]
batch_returns = returns[indices]
# ------------------ Actor 离散优化 ------------------
new_log_probs, entropy = self.actor_net.evaluate(batch_states, batch_actions)
ratio = torch.exp(new_log_probs.squeeze(-1) - batch_old_log_probs)
surr1 = ratio * batch_adv
surr2 = torch.clamp(ratio, 1 - CLIP_EPSILON, 1 + CLIP_EPSILON) * batch_adv
clip_loss = torch.min(surr1, surr2).mean()
#熵越大,探索性越好,损失函数中增加探索性
actor_loss = -clip_loss - ENTROPY_COEF * entropy
self.actor_optimizer.zero_grad()
actor_loss.backward()
#nn.utils.clip_grad_norm_(self.actor_net.parameters(), max_norm=0.5)
self.actor_optimizer.step()
# ------------------ Critic 价值优化 ------------------
current_values = self.critic_net(batch_states).squeeze(-1)
critic_loss = nn.MSELoss()(current_values, batch_returns)
self.critic_optimizer.zero_grad()
critic_loss.backward()
#nn.utils.clip_grad_norm_(self.critic_net.parameters(), max_norm=0.5)
self.critic_optimizer.step()
# 清除本批次缓冲区
self.states.clear()
self.actions.clear()
self.rewards.clear()
self.terminateds.clear()
self.truncateds.clear()
self.log_probs.clear()
self.values.clear()
def train(self, env, max_episodes=MAX_EPISODES, max_steps=MAX_STEPS_PER_EP):
"""
PPO 离散训练主循环
"""
total_steps = 0
all_rewards = []
for ep in range(max_episodes):
state, _ = env.reset()
episode_reward = 0
for t in range(max_steps):
action, log_prob, value = self.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
self.store_transition(state, action, reward, terminated, truncated, log_prob, value)
state = next_state
episode_reward += reward
total_steps += 1
# 缓冲区集满 BATCH_SIZE 步,触发策略更新
if len(self.states) >= BATCH_SIZE:
self.update(next_state)
if terminated or truncated:
break
all_rewards.append(episode_reward)
if (ep + 1) % 10 == 0:
avg_reward = np.mean(all_rewards[-10:])
print(f"Episode {ep+1:4d} | Avg Reward (last 10): {avg_reward:8.2f} | Total Steps: {total_steps}")
# 如果最近十个回合已经达到 500 分满分(说明完全训练解决),可以提前终止训练
if avg_reward >= 495.0:
print(f"--> 环境在第 {ep+1} 回合已被完全解决 (Solved)! 退出训练。")
break
if len(self.states) > 0:
self.update(state)
return all_rewards
def test_agent(env_name, agent, num_episodes=100, render=False, device='cpu'):
"""
使用给定智能体在 CartPole-v1 离散环境中进行评估
:param env_name: 环境名称,如 'CartPole-v1'
:param agent: PPO 离散智能体对象
:param num_episodes: 测试回合数(建议 ≥30,默认100)
:param render: 是否渲染显示画面
:param device: 推理设备
:return: 平均步数(每步 reward=1,所以也是平均 reward)
"""
if render:
test_env = gym.make(env_name, render_mode='human')
print(f"-> 创建渲染环境: {env_name} (图形窗口即将显示)")
else:
test_env = gym.make(env_name)
all_rewards = []
for ep in range(num_episodes):
state, _ = test_env.reset()
episode_reward = 0
done = False
t = 0
while not done:
state_t = torch.FloatTensor(state).unsqueeze(0).to(device)
with torch.no_grad():
logits = agent.actor_net(state_t)
action = torch.argmax(logits, dim=-1).cpu().numpy().item()
next_state, reward, terminated, truncated, _ = test_env.step(action)
state = next_state
episode_reward += reward
done = terminated or truncated
t += 1
all_rewards.append(episode_reward)
# 按评分标准判断
if t >= 450:
print(f" [✅ 好策略] 回合 {ep+1:3d} | 步数: {t:4d}")
elif t >= 200:
print(f" [⚠️ 一般] 回合 {ep+1:3d} | 步数: {t:4d}")
else:
print(f" [❌ 差] 回合 {ep+1:3d} | 步数: {t:4d}")
test_env.close()
avg_steps = np.mean(all_rewards)
std_steps = np.std(all_rewards)
print(f"\n-> 测试完成 | 平均步数: {avg_steps:6.2f} ± {std_steps:5.2f}")
# 根据评分标准给出明确结论
if avg_steps >= 450:
print(" 结论: ✅ 好策略(≥450 步)")
elif avg_steps >= 200:
print(" 结论: ⚠️ 学了但没学好(200~450 步)")
else:
print(" 结论: ❌ 差策略(<200 步,接近随机水平)")
return avg_steps
# ---------------------------- 主程序入口 ----------------------------
if __name__ == "__main__":
env_name = 'CartPole-v1'
'''
环境说明: 用一个可移动的小车,通过左右推,让杆子始终保持直立不倒
类型:Box(4,) --- 4维连续向量
State(观测 / 状态)
索引 变量名 物理含义 取值范围
0 cart_pos 小车位置(轨道中心为0) [-4.8, 4.8] 米
1 cart_vel 小车速度 (-∞, +∞),实际约 [-3.5, 3.5]
2 pole_angle 杆子与垂直方向的夹角 [-0.418, 0.418] rad ≈ [-24°, 24°]
3 pole_vel 杆子的角速度 (-∞, +∞),实际约 [-8, 8】
Action(动作)
类型:Discrete(2) --- 离散2个动作
动作值 物理含义 施加的力
0 向左推小车 -10 N
1 向右推小车 +10 N
力是瞬间施加的,不是持续的。每一步只能选一个方向推
Reward(奖励)
情况 奖励
每存活一步 +1
终止(杆子倒了/小车出界) 0(无额外惩罚)
所以最大化奖励 = 尽可能存活更多步数。
Done(终止条件)
满足任一条件即终止:
条件 阈值 含义
杆子角度过大 ` pole_angle
小车出界 ` cart_pos
达到最大步数 steps >= 500 成功保持了500步(v1的标准)
'''
# 创建训练环境
env = gym.make(env_name)
# 实例化针对离散动作空间的 PPO 智能体
agent = PPO(STATE_DIM, ACTION_DIM)
# 1. 评估未训练的离散控制律,展现初始的平衡动作分配
print("====================================================")
print("【功能 1】使用 [未训练] 的网络在环境中执行离散动作并评估...")
print(" (下方将打印前几个物理步中智能体的原始直觉动作指令)")
print("====================================================")
test_agent(env_name, agent, num_episodes=3, render=True)
# 2. 训练智能体
print("\n====================================================")
print(f"在设备: {device} 上启动离散 PPO 神经网络训练...")
print("====================================================")
reward_history = agent.train(env, max_episodes=MAX_EPISODES)
# 3. 评估已训练的离散控制律,展示平衡控制律如何完美平控直杆
print("\n====================================================")
print("【功能 2】使用 [已训练] 的网络在环境中执行离散动作并评估...")
print(" (下方将展示策略神经网络学习平衡后,如何精准对冲车杆抖动)")
print("====================================================")
test_agent(env_name, agent, num_episodes=3, render=True)
env.close()