原文:levelup.gitconnected.com/designing-a...
示例代码(开源,可本地运行):github.com/matt-bentle...
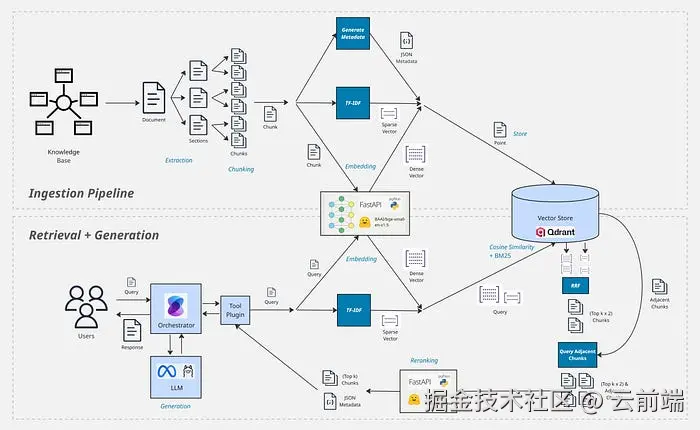
核心主题:用免费、开源的技术栈搭建一套完整的、生产级的 RAG(检索增强生成)架构,以便把大语言模型(LLM)"接地"到你自己的私有知识库上。文中以完整的 Kubernetes 官方文档(PDF 版)作为示例知识库,逐步走过你会遇到的关键设计决策。
大语言模型很强大,但在被迫"猜测"时也出了名地不可靠:它们会以极高的自信给出回答,并以惊人的流畅度编造事实(幻觉)。RAG 的存在,正是为了用从你私有知识库中检索到的、可验证的数据来"接地"LLM 的输出,从而消除这种猜测。过去几年里,RAG 已经成熟为任何严肃 AI 系统的核心构件------从智能体框架到开发者副驾。
一、高层架构
RAG 由两个独立的流程组成:
1. 摄取管线(Ingestion Pipeline)
负责从知识库中抽取文本,并把它存成可检索的格式。这是 RAG 系统中最重要也最复杂的部分------这一步做不好,整个系统就废了。难点在于:可用的技术非常多,而你必须根据数据类型在大量配置之间做出选择。
2. 检索 + 生成(Retrieval + Generation)
数据变成可检索格式后,你需要:
- 当用户输入提示时,检索出相关片段;
- 以尽可能好用的格式把它注入 LLM 作为上下文,用于生成。
两个流程就绪后,用户通过基于 LLM 的应用提问时,回答前会先被知识库中的相关信息所"增强"。
你的数据,你的系统
RAG 有大量技巧,但并不意味着你需要 或应该 全用上。也不存在对所有数据都可靠的"完美设计"。架构决策最重要的驱动因素永远是你的数据本身,以及你希望它如何被消费。要先问清楚:
- 数据是什么格式?(PDF、HTML、JSON、自由文本等)
- 是否高度结构化?(章节/子章节、层级、表格、法律引用等)
- 是否有需要索引的额外元数据?
- 是否有非文本内容?(图像、视频、音频)
- 数据的规模与体量?
- 用户将如何检索它?
二、采用哪种检索方式?
这是第一个也是最重要的决策,其余一切都由它衍生。
关键词检索(稀疏向量 Sparse Vectors)
搜索引擎多年来一直使用关键词检索。查询中的词/词元被抽取出来,与知识库中每篇文档的词进行匹配。匹配通过稀疏向量完成------基于词表为查询或文档中的每个词建立索引。
匹配方法可以从简单词频,到更复杂的 BM25(Best Match 25)。BM25 用在整个语料上计算的**逆文档频率(IDF)**给词元赋权,降低那些在大量文档中频繁出现的词带来的噪声,从而给出更可靠的匹配。大多数全文数据库(如 Lucene、ElasticSearch)都使用 BM25 的某种变体。
嵌入相似度(稠密向量 Dense Vectors)
如果查询中的确切词不在知识库里,关键词检索就会失效。嵌入(Embedding)通过把文本表示成数值向量 来解决这个问题。嵌入由专门的机器学习模型生成,能够捕捉词的语义含义。

之所以叫稠密向量 ,是因为模型对每段文本生成的向量都具有相同的维度数。语义相近的词在向量空间中彼此更接近。检索时使用余弦相似度(Cosine Similarity)来查找语义相近的文本,因此这类检索常被称为语义检索(Semantic Search)。向量数据库专为存储数值向量并原生支持余弦相似度检索;关系型数据库(如 PostgreSQL、SQL Server)也开始原生支持向量。
混合检索(Hybrid Search)
稠密向量与稀疏向量检索可以合并成混合检索,往往能得到最好的效果。
但开箱即用支持混合检索的数据库不多,通常需要复杂的自定义工作来融合不同的检索结果。
决策:混合检索
本案例采用混合检索,因为它在 Kubernetes 文档上最可能表现最佳。权重设置为:
- 嵌入(语义)70%------预期表现最好;
- 关键词(BM25)30%------支持按特定条件/代码检索。
这是 RAG 中常用的比例。
数据库选型:Qdrant
选数据库时要考虑:
- 支持的检索功能类型
- 预算:开源还是商业
- 隐私:数据是否需要自托管
- 流行度:更好的支持和社区
- SDK 支持
- 基于需求的性能
支持混合检索的数据库有几个。BM25 比较麻烦,因为它需要维护跨所有文本的词频索引,所以建议选一个能替你做这件事的向量库。
Qdrant 能同时存储稠密向量和稀疏向量,并对两者执行混合查询,结果用 倒数排名融合(Reciprocal Rank Fusion, RRF) 合并------这是 RAG 的标准做法。Qdrant 开源、可在 Docker 中运行、托管极其简单,且对 .NET 支持出色(原作者使用 .NET)。
其他支持混合检索的优秀选项:Weaviate、Pinecone、Milvus。
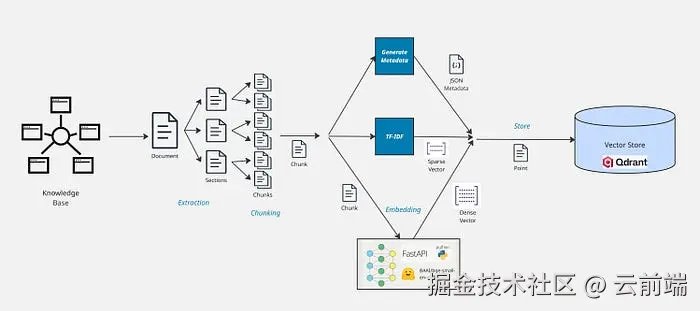
三、摄取管线(Ingestion Pipeline)
确定要做混合检索后,摄取管线就需要同时生成并存储稠密向量嵌入 和稀疏向量。
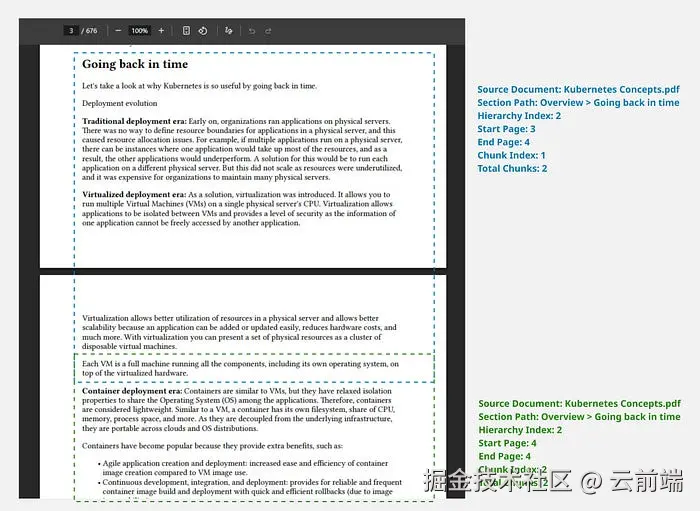
Kubernetes 源文档相当长(RAG 知识库很常见),这对检索策略尤其是基于嵌入的策略不友好。嵌入试图提炼文本的语义含义,但长文本会覆盖很多不同主题。嵌入在语义内聚良好的较小文本块 上效果最好。而且我们也很难把整篇长文档塞进 LLM 上下文------我们想根据用户查询取最相关的部分。RAG 系统通过在生成嵌入和存储前把文档**切块(Chunking)**来解决这个问题。
一个高效的摄取管线(尤其是切块策略)是 RAG 系统实现卓越检索召回率最重要的环节。
标准摄取管线的关键步骤:
- 抽取(Extract)
- 预处理(Pre-Process)
- 切块(Chunk)
- 生成元数据(Generate Metadata)
- 生成稠密与稀疏向量(Generate Dense and Sparse Vectors)
- 存储(Store)
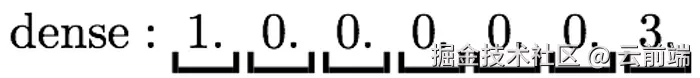
1. 抽取(Extraction)
第一步是从源文档中抽取文本。任何可用于检索或丰富回答的元数据也应一并抽取,例如文档名、页码、摘要。
如果文档有明确结构并被拆成章节,最好按章节抽取文本。这有助于后续切块------可以保证一个块不跨越多个章节。
章节按页存储,便于之后拼接还原并理解块属于哪些页。作者通常把子章节扁平化成一个"章节路径(Section Path)",并指定结构层级应嵌套多深。
由于文档布局/结构各异,通常需要多种抽取策略。示例仓库提供了:
- SimplePdfExtractor:把整个 PDF 的所有文本抽取为单个章节。
- BookmarkPdfExtractor:搜索 PDF 中的书签,用来识别章节和嵌套章节。
- FormatBasedPdfExtractor:分析文本格式来推断章节,假设标题更大或加粗,越深层的章节字号/字重越小。
Kubernetes 文档的标题格式非常一致,因此 FormatBasedExtractor 完美适用。下图展示了一个基于标题格式抽取出的章节与子章节的示例。
2. 切块(Chunking)
把文档抽取成章节/子章节后,你已经完成了高效切块的一半。下一步是把过长的章节切成更小的块,以生成高质量嵌入。
块长度(Chunk Length)
- 一般 200--300 词元 效果不错,但务必用你的数据测试不同长度来比较召回率。
- 对复杂的政策类或法律类文档,最高到 600 词元可能更好。
- 要注意嵌入模型的限制:许多开源模型有 512 词元 的硬上限。
块切分点(Chunk Breaks)
- 不要用严格的固定块大小,以免切断句子。
- 应优先在段落分隔 处切块,至少也要在句末切。
- 更高级的做法:用嵌入模型或 LLM 在语义明显不同的文本处切块。
块重叠(Chunk Overlap)
- 无论切块多复杂,总会有不理想的边界。
- 因此在块之间制造 10--20% 的重叠 通常能提升召回率,而不损害精度或延迟。
针对 Kubernetes 文档中一些较大的章节,作者发现以下配置效果好:
- 最大块长度:400 词元
- 块重叠:50 词元
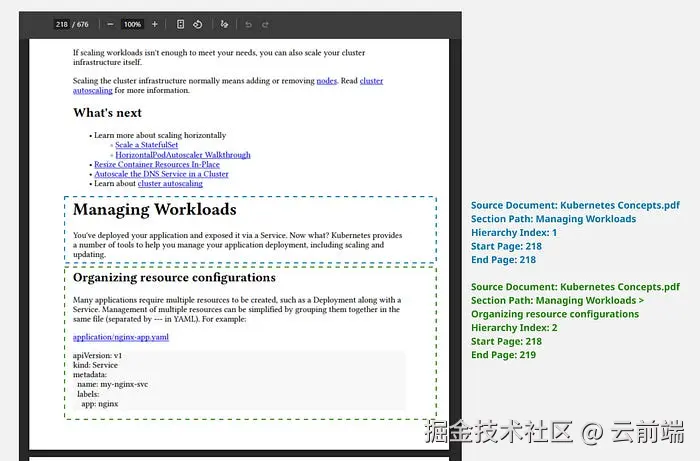
3. 生成元数据(Generating Metadata)
给块附加额外元数据有两个目的:
- 丰富 LLM 的生成,例如添加引用和页码;
- 在检索时做自定义检索或过滤。
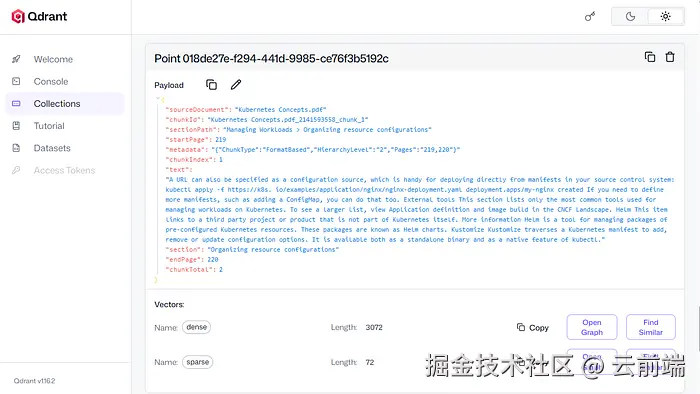
存哪些元数据取决于你的数据,示例:
- 源文档名
- 页码
- 章节 与 章节路径(Section Path)
- 章节内块索引 与 块总数(Chunk Index / Total Chunks)
- 引用 ID、条款号、规则/错误/产品代码
- 块内容摘要(由 LLM 生成)
4. 生成稠密向量(语义嵌入)
嵌入由所选嵌入模型基于块文本生成。如果有助于语义相关性,也可以把源文档名和/或章节路径加入嵌入文本。
模型选择很多,不同模型对不同数据类型表现各异。更强的模型通常产出维度更高的向量,但需要更多算力和 GPU。
作者选用 BAAI/bge-small-en-v1.5 ,因为它足够小、能在 CPU 上较快运行,产出 384 维 向量。通过一个 Python FastAPI 应用托管 Hugging Face 模型。
5. 生成稀疏向量(BM25)
稀疏向量只包含块中出现词项的词频。不存词项文本,而是给每个词项分配整数 ID。两种分配方式:
- 用一份词表做"词项 → ID"映射;
- 对词项做哈希得到整数。
作者一般偏好简单哈希 ,避免维护词表。像 xxHash 这样的算法极快,且几乎不会发生哈希冲突。
摄取调度(Ingestion Schedule)
如何运行、多久运行摄取管线取决于数据和场景:
- 手动:数据极少变化时可以手动跑。
- 定时任务:文档变化较频繁时用定时/cron 任务,常见做法是每日运行。
- 实时:如果有文档管理层且文档频繁变化,可用异步事件驱动流程,在源文档变化时触发管线。
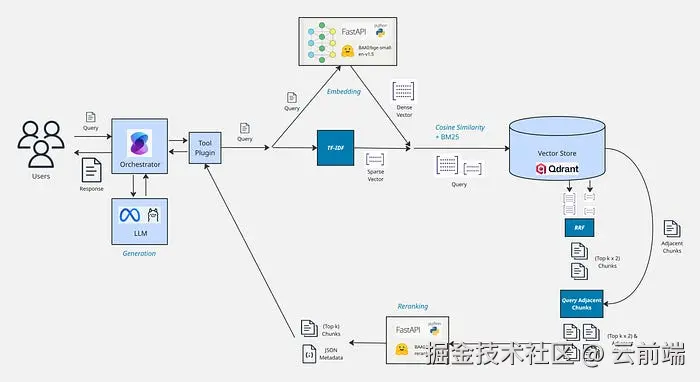
四、检索 + 生成(Retrieval + Generation)
大部分决策和复杂度都在摄取阶段解决了。接下来只需一个根据用户提示检索块的流程。

检索(Retrieval)
选 Qdrant 是因为它开箱即用地同时执行 BM25 关键词检索和嵌入余弦相似度检索。建议给混合检索的不同策略加权,RAG 常用:
- 稠密向量(嵌入)70%
- 稀疏向量(关键词/BM25)30%
嵌入捕捉语义、通常表现最好,所以一般最依赖它。但理想权重取决于你的数据以及关键词查询是否非常重要。
检索前,先把用户查询走一遍摄取管线中的部分步骤:
- 预处理(Pre-Process)
- 生成稠密与稀疏向量
- 检索(Search)
检索时应返回多个块,因为可能有多个块匹配查询------这通常叫 "Top k" 结果。Top k 取 5--10 通常够用,取决于数据和切块策略。块越小,通常需要越大的 Top k。
这套做法不错但并非万无一失。混合检索不完美,尤其当用户查询很短时。可以在检索之后叠加一些技术来提升召回率和精度。
相邻块(Adjacent Chunks)
我们是按章节抽取并在章节内切块的,这意味着检索结果的相邻块极可能也相关(如果它们没被检索直接返回的话)。
推荐的第一个后续步骤是用相邻块 丰富检索结果。一般取检索块前后 1--2 个索引 内的块效果好。这正是为什么要把文档名、块索引、块总数、章节路径存为元数据------以便高效查询相邻块。
如果向量库支持索引(Qdrant 支持),应在这些字段上建索引,以高效查询相邻块。
重排序(Reranking)
检索常会取到完全不相关的块,关键词检索尤其严重。重排序 可按相关性对结果排序并过滤掉不相关的块。一个强力技巧:检索时返回 Top k 的 2--3 倍 结果,再用重排序器筛到最相关的 Top k。
示例(Top k = 5):
- 混合检索返回 Top k × 2 = 10 块
- 加入相邻块 → 18 块
- 重排序器按相关性排序并返回 Top k → 5 块
这种方式能显著提升检索精度。
重排序器是接受一对文本 作为输入、输出相关性分数 的专用模型。把每个检索结果连同用户查询喂给重排序器即可。还可以用相关性分数设定一个最低相关度阈值,而不是只取 Top k。
交叉编码器(Cross Encoders) :专为相关性打分训练的机器学习模型,处理文本比 LLM 快得多。更高质量的重排序器在生产系统中通常仍需 GPU。本例用免费开源的 BAAI/bge-reranker-base,表现不错且在 CPU 上够快,同样通过 Python FastAPI 托管 Hugging Face 模型。
LLM 重排序(LLM Reranking) :目前云托管的重排序模型不多,另一种方式是用 LLM 配合定制的系统消息(System message)来重排序。建议用轻量 LLM(如 GPT-4.1 Mini),以免显著拖慢 RAG 系统的延迟。原文为此提供了一个可用于 LLM 重排序的系统消息模板(见原作者 GitHub 仓库)。
生成(Generation)
检索搞定后,剩下的就是把块送进 LLM 做总结。
上下文格式(Context Format) :如果 LLM 支持,注入块的最佳方式是作为工具消息(Tool message)。在系统消息中加入 LLM 应如何解释检索结果、以及找不到匹配时如何反应的规则与护栏。
清晰的角色划分:
- 系统消息(System message)→ 规则、行为、护栏
- 工具消息(Tool message)→ 检索到的上下文(块)
- 用户消息(User message)→ 问题
工具消息中要包含你希望 LLM 引用的任何元数据,连同块内容一起。用户消息示例:"Pod 是如何被调度的?" (原文给出了 LLM 重排序系统消息、RAG 系统消息、RAG 工具上下文 JSON 三个模板片段,完整内容见原作者 GitHub 仓库。)
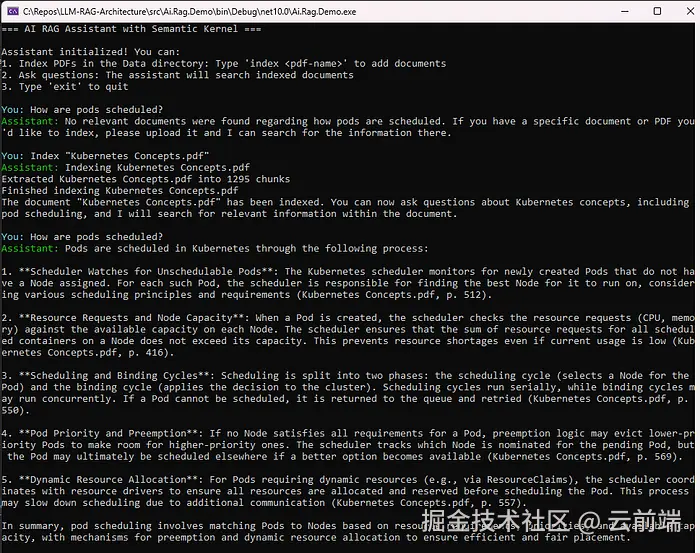
编排(Orchestration)
更易管理的方式是用编排器(Orchestrator)来生成工具调用和输出,例如 Semantic Kernel 或 LangChain。用编排器还有两个额外好处:
- 发往 RAG 系统的查询先由 LLM 解释,可在需要时被改进/纠正;
- 知识库可作为更大的 AI 智能体/副驾的一部分被使用。
用编排器时,你只需关心系统消息和用户消息。编排器负责在需要时调用 RAG 检索,并把数据作为工具消息(通常是 JSON)加入上下文。
示例应用中,作者用 Semantic Kernel 插件集成了 OpenAI 风格的工具调用,以支持基于提示的索引和 RAG 查询。
LLM 模型选择
- 如果系统只有 RAG 这一个功能,便宜的 LLM 就够用------只需对检索到的文档做基本总结。
- 如果用编排器,则需要支持工具调用 的模型。作者通过 Ollama 使用了 Llama 3.2 3B(小语言模型 SLM),以便在 CPU 上运行;但更大的模型会可靠得多。
五、托管(Hosting)
作者把 Semantic Kernel RAG 助手打包成了 CLI 控制台应用,简单场景够用。若要面向更广泛的用户,最好在上面写个小的 Web UI(如 React 或 Angular)。
每个服务(重排序器、嵌入器等)作为独立进程运行。独立托管每个服务可以独立扩缩,并为各服务使用不同的基础设施或资源配置。例如重排序器可能很吃资源,需要扩容到大量副本;而 LLM 很可能需要在 GPU 基础设施上运行。
容器非常适合这类进程------把各服务隔离打包成容器镜像,在不同托管环境中获得可靠运行。推荐用容器编排器以便快速扩缩,Kubernetes 就很理想。
自托管 vs 云服务
示例方案全用开源技术拼成,因此你可以全部自托管,或在 CPU 上本地运行。但作者一般不推荐走纯自托管路线,除非你公司有重大数据风险且不接受云服务。要注意,大多数云服务(如 Azure OpenAI)面向企业用途且完全无状态------即不存储你提示或回答中的任何数据。
混合方式也可行:把较轻量的模型自托管。嵌入和重排序模型通常不像 LLM 那么吃算力。理想情况下,生成用的 LLM 需要 GPU 才能可靠运行,而在这方面云服务通常比自建基础设施便宜得多。
市面上有很多通用的开箱即用 RAG 方案,但自建架构能让一切都贴合你特定的数据需求,往往带来更优的召回率和精度。即便你决定用外部 RAG 服务,这里讨论的很多技术(不同切块策略、重排序等)也能与之协同使用。
完整代码见原作者 GitHub:matt-bentley/LLM-RAG-Architecture。
关键参数速查
| 决策点 | 推荐值 / 选择 |
|---|---|
| 检索方式 | 混合检索(Hybrid Search) |
| 混合权重 | 稠密 70% / 稀疏 30% |
| 结果融合 | 倒数排名融合(RRF) |
| 向量数据库 | Qdrant(备选:Weaviate / Pinecone / Milvus) |
| 块长度 | 一般 200--300 词元;复杂文档可到 600;K8s 案例用 400 |
| 块重叠 | 10--20%;K8s 案例用 50 词元 |
| 嵌入模型 | BAAI/bge-small-en-v1.5(384 维,CPU 友好) |
| 稀疏向量词项 ID | 偏好哈希(如 xxHash),免维护词表 |
| Top k | 5--10(块越小,k 越大) |
| 重排序召回 | 检索 Top k 的 2--3 倍,再筛到 Top k |
| 重排序模型 | BAAI/bge-reranker-base(交叉编码器)或轻量 LLM(如 GPT-4.1 Mini) |
| 相邻块扩展 | 前后 1--2 个索引 |
| 编排器 | Semantic Kernel / LangChain |
| 生成 LLM | 纯 RAG 用便宜模型;需工具调用用 Llama 3.2 3B 等 |
| 部署 | 各服务独立容器化,用 Kubernetes 编排 |