前言
大语言模型(LLM)看起来很神秘:几百上千亿参数、几万张卡、读完 X 个互联网。但训练它的内核很简单:
在大量文本上做 next-token prediction (预测下一个词),最小化 交叉熵。
本文以 nanoGPT 为样例,介绍大语言模型训练的过程,顺带记录一些基础原理。
一、语言模型学习方式 next-token prediction
1.1 把"理解语言"变成"预测下一个 token"
给定一段文本(token 序列) x 1 , x 2 , ... , x T x_1, x_2, \dots, x_T x1,x2,...,xT,语言模型看着前面所有 token,预测下一个 token 的概率分布 ,
P ( x 1 , x 2 , ... , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , ... , x t − 1 ) = ∏ t = 1 T P ( x t ∣ x < t ) P(x_1, x_2, \dots, x_T) = \prod_{t=1}^{T} P(x_t \mid x_1, \dots, x_{t-1}) = \prod_{t=1}^{T} P(x_t \mid x_{<t}) P(x1,x2,...,xT)=t=1∏TP(xt∣x1,...,xt−1)=t=1∏TP(xt∣x<t)
训练让模型学条件分布 P θ ( x t ∣ x < t ) P_\theta(x_t \mid x_{<t}) Pθ(xt∣x<t)。生成文本是反复"预测下一个、采样、拼接、再预测"。采用的是 Transformer 的 decoder,所以这种结构也被称为 decoder-only 的自回归结构。
1.2 实例
这里使用 nanoGPT 作为工程样例。nanoGPT 是 Karpathy 写的,逐字精炼 。整个 GPT-2 实现 ~300 行,模型部分核心只 100 行,比 transformers 库的 GPT-2 简单 10 倍。它是现代 LLM 的最小完整体,pre-norm + 因果自注意力 + MLP + 残差连接 ------ Qwen / LLaMA / Mistral 的 block 结构本质就是这个,只是 LayerNorm 换成 RMSNorm,MLP 换成 SwiGLU 等。
五分钟极简版
一键跑通命令(macOS / Linux 都行)
bash
# 1. clone
git clone https://github.com/karpathy/nanoGPT
cd nanoGPT
pip install torch numpy tiktoken datasets tqdm
# 2. 准备 tinyshakespeare 字符级数据(1MB,几秒钟)
python data/shakespeare_char/prepare.py
# 3. 训练(CPU 也能跑,GPU 更爽)
# 有 GPU 用:python train.py config/train_shakespeare_char.py
# 只有 CPU 用:
python train.py config/train_shakespeare_char.py \
--device=cpu --compile=False \
--eval_iters=20 --log_interval=1 --block_size=64 \
--batch_size=12 --n_layer=4 --n_head=4 --n_embd=128 \
--max_iters=2000 --lr_decay_iters=2000 \
--dropout=0.0
# 跑 5~10 分钟,loss 应该从 ~4.2 降到 ~1.5
# 4. 生成(用刚训好的 ckpt)
python sample.py --out_dir=out-shakespeare-char --device=cpu跑通的标志:生成的文本能看到完整单词、像 Shakespeare 排版的对话格式(虽然语义还会胡言乱语)。
nanoGPT 训练就一句话:随机从训练文本里裁一段长 T 的 chunk 当输入
x,把x整体右移一位当目标y,模型 forward 输出(B, T, V)的 logits,和(B, T)的y算 cross_entropy 取平均,反传 + AdamW 更新。每隔几百步在验证集上算一次 loss,early-stop 看 val_loss 不再降为止。loss 是 next-token 交叉熵,数学上就是 L = − ∑ t log P θ ( x t ∣ x < t ) \mathcal{L} = -\sum_t \log P_\theta(x_t \mid x_{<t}) L=−∑tlogPθ(xt∣x<t),工程上就是
F.cross_entropy(logits.view(-1, V), targets.view(-1)),每个 token 位置都贡献一条 loss(信号密度 100%,不是 BERT 的 15%)。
我们用字符级 tokenize 做例子(最简单,每个字符一个 ID)。nanoGPT 的 prepare.py 准备数据。
python
# 读入约 1MB 的莎士比亚文本
data = open('input.txt').read()
# 收集所有出现过的字符,构造词表(约 65 个:字母+数字+标点+空格+换行)
chars = sorted(list(set(data)))
vocab_size = len(chars)
stoi = {ch: i for i, ch in enumerate(chars)} # 字符 → ID
itos = {i: ch for i, ch in enumerate(chars)} # ID → 字符
encode = lambda s: [stoi[c] for c in s]
decode = lambda l: ''.join(itos[i] for i in l)
# 90/10 切分,编码成 uint16 存盘
n = len(data)
np.array(encode(data[:int(n*0.9)]), dtype=np.uint16).tofile('train.bin')
np.array(encode(data[int(n*0.9):]), dtype=np.uint16).tofile('val.bin')得到的 train.bin 是一条长达约 100 万的连续 ID 序列(没切句、没分段)。训练时再从这条长流里随机采样:
python
def get_batch(split):
data = train_data if split == 'train' else val_data
# 随机选 batch_size 个起点,每个起点取 block_size 个连续 token
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([torch.from_numpy(data[i : i+block_size ].astype(np.int64)) for i in ix])
y = torch.stack([torch.from_numpy(data[i+1 : i+block_size+1].astype(np.int64)) for i in ix])
return x.to(device), y.to(device)核心(x, y)是
x = data[i : i+T]------ 从位置 i i i 取 T 个 token;y = data[i+1 : i+T+1]------ 整体右移一位。
举个例子,原始流是 ... A B C D E F G ...,采到某起点、block_size=4:
text
x = [B, C, D, E]
y = [C, D, E, F]y[t] 就是 x[t] 的下一个 token 。模型在每个位置 t t t 看着 x[≤t],要预测的就是 y[t]。y 只是 x 错开一位的副本------自监督:数据本身就是标签,可以无限切、造。
1.3 数据流
text
原始训练流(长度 N ≈ 90 万):
[t0, t1, t2, t3, t4, t5, t6, ..., t_{N-1}]
随机选 batch_size=4 个起点,block_size=8:
起点 i:
x = [t_i, t_{i+1}, ..., t_{i+7}]
y = [t_{i+1}, t_{i+2}, ..., t_{i+8}] ← x 右移 1
stack 成批:
x ∈ Z^(4×8) y ∈ Z^(4×8)
模型 forward(x):
logits ∈ R^(4×8×vocab_size) ← 每个位置都预测下一个 token 的分布每个位置都在做一次"下一个字符是什么"的多分类预测。
二、训练目标:next-token 交叉熵
2.1 loss 的代码与公式
模型最后一层 lm_head 把每个位置的隐状态投影成词表上的 logits,然后和 y 算交叉熵:
python
logits = self.lm_head(x) # (B, T, vocab_size)
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)), # (B*T, V)
targets.view(-1) # (B*T,)
)F.cross_entropy 的标准接口是 input: (N, C)、target: (N,)------N 个样本、每个 C 类。而 logits 是三维的 (B, T, V),所以把前两维拍平:(B, T, V) → (B*T, V),等价于"把 B*T 个 token 位置当成 B*T 个独立的多分类样本"。
即
L = − 1 B ⋅ T ∑ b = 1 B ∑ t = 1 T log P θ ( y t ( b ) | x ≤ t ( b ) ) \mathcal{L} = -\frac{1}{B\cdot T}\sum_{b=1}^{B}\sum_{t=1}^{T} \log P_\theta\!\left(y^{(b)}t \;\middle|\; x^{(b)}{\le t}\right) L=−B⋅T1b=1∑Bt=1∑TlogPθ(yt(b) x≤t(b))
cross_entropy 内部对 N = B ⋅ T N = B\cdot T N=B⋅T 个样本取了平均,所以前面多了 1 B T \frac{1}{BT} BT1。
2.2 交叉熵
cross_entropy 对单个 token 位置做两步:
- 对该位置的 logits 做 softmax,得到模型在整个词表上的预测分布 q q q;
- 取真实下一个 token y t y_t yt 对应的概率 q y t q_{y_t} qyt,损失是 − log q y t -\log q_{y_t} −logqyt。
模型给"正确答案"的概率越高, − log q y t -\log q_{y_t} −logqyt 越小;给得越低,罚得越狠( q → 0 q\to 0 q→0 时损失 → + ∞ \to +\infty →+∞)。把所有位置平均,就是上面的 L \mathcal{L} L。
为了判断 loss 的走势,把握模型训练的情况,下一节补充说明一下交叉熵的信息论含义。
三、理论标尺:熵、交叉熵
这一节说明交叉熵在信息论中的含义以及它和熵的关系。
3.1 "猜下一个字母"
想象一个游戏:我捂住一段英文文本,逐个字母让你猜下一个是什么,你每次要给出一个概率分布(比如"我觉得 60% 是 e、20% 是 a......")。
- 文本是
th_,你几乎确定下一个是e,毫不惊讶 → 这个字符携带的信息很少; - 文本是
xqz_,下一个是啥你完全没底,很惊讶 → 这个字符携带的信息很多。
熵,量的就是"平均下来,你猜下一个字符有多难、有多惊讶"。 语言越规律、越可预测,熵越低;越随机,熵越高。
熵是"语言本身"的性质,不是模型的性质。 英文有它自己内在的不确定性,跟用什么模型无关。
3.2 自信息 → 熵
自信息 :一个概率为 p p p 的事件真的发生了,它带来的信息量(惊讶度)定义为
I = − log p I = -\log p I=−logp
3 个性质:
- p = 1 p = 1 p=1(必然发生)→ I = 0 I = 0 I=0,毫不惊讶,零信息;
- p p p 越小 → − log p -\log p −logp 越大,越罕见越惊讶;
- 两个独立事件同时发生,概率相乘 p 1 p 2 p_1 p_2 p1p2,而信息量应当相加 − log p 1 − log p 2 -\log p_1 - \log p_2 −logp1−logp2------"乘法概率对应加法信息"这个性质,只有对数函数能满足。
熵:把每个可能取值的自信息,按它真实出现的概率加权平均:
H ( p ) = ∑ i p i ⋅ ( − log p i ) = − ∑ i p i log p i H(p) = \sum_i p_i \cdot (-\log p_i) = -\sum_i p_i \log p_i H(p)=i∑pi⋅(−logpi)=−i∑pilogpi
读法:"按真实分布 p p p 采样,平均每个符号携带多少信息。"这就是"猜字母游戏"的平均难度分。
3.3 交叉熵:训练 loss
现实里我们不知道真实分布 p p p ,模型只能输出一个估计分布 q q q 。当真实符号 i i i 出现,模型给它的概率是 q i q_i qi,损失是 − log q i -\log q_i −logqi。把这个损失按真实分布 p p p 平均,就是交叉熵:
H ( p , q ) = − ∑ i p i log q i H(p, q) = -\sum_i p_i \log q_i H(p,q)=−i∑pilogqi
对照第二节:训练时单个 token 位置的损失 − log q y t -\log q_{y_t} −logqyt,在大量样本上平均,逼近的正是 H ( p , q ) H(p, q) H(p,q)------其中 p p p 是真实数据的"下一个 token"条件分布, q q q 是模型的预测分布。
我们的训练是在海量数据上加权平均,故经验上最小化的逐样本 − log q y t -\log q_{y_t} −logqyt,其期望就是 H ( p , q ) H(p, q) H(p,q) (大数定律)。
H ( p ) H(p) H(p) 和 H ( p , q ) H(p,q) H(p,q) 的区别:前者用真实概率 p i p_i pi 加权真实分布,是理想;后者用模型概率 q i q_i qi 算损失、仍按真实 p i p_i pi 加权,是现实。
交叉熵减去熵
H ( p , q ) − H ( p ) = − ∑ i p i log q i + ∑ i p i log p i = ∑ i p i log p i q i H(p,q) - H(p) = -\sum_i p_i \log q_i + \sum_i p_i \log p_i = \sum_i p_i \log \frac{p_i}{q_i} H(p,q)−H(p)=−i∑pilogqi+i∑pilogpi=i∑pilogqipi
右边量是 KL 散度 (相对熵),记作 D K L ( p ∥ q ) D_{\mathrm{KL}}(p \,\|\, q) DKL(p∥q),衡量"模型分布 q q q 离真实分布 p p p 有多远"。于是我们得到
H ( p , q ) = H ( p ) + D K L ( p ∥ q ) \boxed{\;H(p,q) \;=\; H(p) \;+\; D_{\mathrm{KL}}(p\,\|\,q)\;} H(p,q)=H(p)+DKL(p∥q)
由于 D K L ( p ∥ q ) ≥ 0 D_{\mathrm{KL}}(p\|q) \ge 0 DKL(p∥q)≥0,故
H ( p , q ) ≥ H ( p ) H(p,q) \ge H(p) H(p,q)≥H(p)
即
训练 loss(交叉熵)= 语言本身的熵(下界) + 模型与真实分布的差距(KL,非负)。
模型再强,只能把 KL 项压到 0,loss 最低也只能降到 H ( p ) H(p) H(p),熵是交叉熵的下界。
整个训练过程就是把 D K L ( p ∥ q ) D_{\mathrm{KL}}(p\|q) DKL(p∥q) 往 0 推。
3.4 证明 KL 散度非负
设定 :设 p = ( p 1 , ... , p n ) p = (p_1, \dots, p_n) p=(p1,...,pn)、 q = ( q 1 , ... , q n ) q = (q_1, \dots, q_n) q=(q1,...,qn) 是同一有限符号集上的两个概率分布, ∑ i p i = ∑ i q i = 1 \sum_i p_i = \sum_i q_i = 1 ∑ipi=∑iqi=1,各分量非负。定义
D K L ( p ∥ q ) = ∑ i p i ln p i q i D_{\mathrm{KL}}(p\|q) = \sum_i p_i \ln\frac{p_i}{q_i} DKL(p∥q)=i∑pilnqipi
约定: p i = 0 p_i = 0 pi=0 的项取 0(因为 lim p → 0 + p ln p = 0 \lim_{p\to 0^+} p\ln p = 0 limp→0+plnp=0);若某个 q i = 0 q_i = 0 qi=0 而 p i > 0 p_i > 0 pi>0,则该项为 + ∞ +\infty +∞, D K L = + ∞ ≥ 0 D_{\mathrm{KL}} = +\infty \ge 0 DKL=+∞≥0 平凡成立。下面只需处理所有 q i > 0 q_i > 0 qi>0 的情形。
证明(Jensen 不等式) : − ln -\ln −ln 是下凸函数。把 D K L D_{\mathrm{KL}} DKL 看作随机变量 q i p i \frac{q_i}{p_i} piqi 在分布 p p p 下取期望:
D K L ( p ∥ q ) = ∑ i p i ln p i q i = E p − ln q i p i ≥ − ln E p q i p i = − ln ∑ i p i ⋅ q i p i = − ln ∑ i q i = − ln 1 = 0 D_{\mathrm{KL}}(p\|q) = \sum_i p_i \ln\frac{p_i}{q_i} = \mathbb{E}{p}\!\left-\\ln\\frac{q_i}{p_i}\\right \;\ge\; -\ln \mathbb{E}{p}\!\left\\frac{q_i}{p_i}\\right = -\ln\sum_i p_i\cdot\frac{q_i}{p_i} = -\ln\sum_i q_i = -\ln 1 = 0 DKL(p∥q)=i∑pilnqipi=Ep−lnpiqi≥−lnEppiqi=−lni∑pi⋅piqi=−lni∑qi=−ln1=0
中间一步用的是 Jensen 不等式 E φ ( X ) ≥ φ ( E X ) \mathbb{E}\\varphi(X) \ge \varphi(\mathbb{E}X) Eφ(X)≥φ(EX)(对下凸函数 φ = − ln \varphi = -\ln φ=−ln)。等号当且仅当 q i p i \frac{q_i}{p_i} piqi 几乎处处为常数,结合归一化条件得该常数为 1,即 p = q p = q p=q。 ■ \;\blacksquare ■
故 交叉熵 ≥ \ge ≥ 熵,当且仅当模型分布精确等于真实分布时取等。
3.5 与我们实验的关系
英文文本的熵,Shannon 在 1951 年用人类实验估计约 1.0 ~ 1.3 bits/char (取 1.1 bits/char 当代表值),换算约 0.76 nats/char。这就是字符级英文语言模型 loss 的理论下界。
一个在莎士比亚文本上训练的字符级 GPT,收敛后 val loss 约 1.45 nats/char。对照下界:
| nats/char | bits/char | 距下界(1.1 bits) | |
|---|---|---|---|
| 随机瞎猜(65 字符均匀) | ln 65 ≈ 4.17 \ln 65 \approx 4.17 ln65≈4.17 | 6.02 | 约 4.9 bits |
| 训练收敛 | 1.45 | 2.09 | 约 1.0 bits |
| 语言熵(下界) | 0.76 | 1.10 | 0 |
收敛后模型已经把 KL 压掉了一大半,但离下界还差约 1 bit/char。有没办法让 val loss 更低一些,这个模型基本已经做到头了。因为
- 数据墙(KL 项) :训练数据(约 1MB)太小,模型容量一旦超过数据的信息量,继续加大只会过拟合。在小数据上,模型加深加宽的边际收益会很快归零。
- 建模粒度墙(熵项) :Shannon 熵 H ( p ) = 1.1 H(p) = 1.1 H(p)=1.1 bits/char 是语言本身的不确定性,任何模型、任何算力都突破不了。而且字符级建模还要分出容量去学"哪些字母能拼成合法单词",上限更低。
要优化可以用大量更多样的数据 (突破数据墙),以及换成子词级(BPE)tokenization(让模型不必浪费容量学拼写,直接拿合法语言单元当 token)。作为参照,GPT-2 这类子词级模型在大规模语料上的 loss 更接近语言的熵下界。
所以能看到 nanoGPT 训练收敛后,生成的文本看着像样,却没有语义。
四、训练代码
nanoGPT 的 train.py 约 350 行,骨架可以压缩到下面这段。
python
# 1. 模型 + 优化器
model = GPT(GPTConfig(n_layer=6, n_head=6, n_embd=384,
block_size=256, vocab_size=vocab_size))
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3,
betas=(0.9, 0.95), weight_decay=0.1)
# 2. 学习率调度:warmup + cosine decay
def get_lr(it):
if it < warmup_iters: # 线性 warmup
return max_lr * it / warmup_iters
decay_ratio = (it - warmup_iters) / (max_iters - warmup_iters)
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) # cosine 衰减
return min_lr + coeff * (max_lr - min_lr)
# 3. 主循环------每轮做 7 件事
for it in range(max_iters):
lr = get_lr(it) # ① 调 lr
for pg in optimizer.param_groups: pg['lr'] = lr
if it % eval_interval == 0: # ② 周期性看 val loss
val_loss = estimate_loss()
print(f"iter {it}: val loss {val_loss:.4f}")
x, y = get_batch('train') # ③ 取 batch(x; y=x右移1)
logits, loss = model(x, y) # ④ forward + next-token CE
optimizer.zero_grad(set_to_none=True) # ⑤ 清梯度
loss.backward() # ⑥ 反传
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # ⑦ 梯度裁剪
optimizer.step() # 更新参数4.1 AdamW、weight decay、grad clip
| 名字 | 作用 | 常见值 | 一句话直觉 |
|---|---|---|---|
| AdamW | 优化器 | β=(0.9, 0.95) | 给每个参数自适应学习率,比 SGD 收敛快很多 |
| weight_decay | L2 正则 | 0.1 | 抑制参数无限增大,缓解过拟合 |
| grad_clip | 梯度裁剪 | 1.0 | 某次梯度爆炸就裁回 1.0 |
4.2 学习率:warmup + cosine decay
LLM 训练的标准 lr 曲线分两段:
text
lr ▲
max│ ╭──────╮
│ ╱ ╲
│ ╱ ╲___
│ ╱ ╲────___
min│____╱ ────
└────────────────────────────────▶ iter
warmup cosine decay
(前~100步) (剩余所有步)- Warmup(0 → max_lr):开头几百步把 lr 从 0 线性拉起来,防止一上来 lr 太大、把随机初始化的参数打乱;
- Cosine decay(max_lr → min_lr) :之后用余弦曲线缓慢降到
min_lr(常取0.1 × max_lr),让模型后期在 loss 曲面的细节上精修。
4.3 流程图
text
┌───────────────────────────────────────────────┐
│ for it in range(max_iters): │
│ lr = get_lr(it) ← warmup+cos │
│ if it % eval_interval == 0: │
│ val_loss = estimate_loss() ← 看泛化 │
│ x, y = get_batch('train') ← y 是 x 右移1 │
│ logits, loss = model(x, y) ← next-token CE│
│ optimizer.zero_grad() │
│ loss.backward() │
│ clip_grad_norm_(.., 1.0) ← 防梯度爆 │
│ optimizer.step() │
└───────────────────────────────────────────────┘
▲ 这 7 件事,几乎所有 LLM 训练都一样五、 loss 曲线
字符级模型的典型 loss 阶段
| iter | val loss(nats) | 生成文本的样子 |
|---|---|---|
| 0 | ~4.20 | 完全随机,像键盘乱按 qwxz!! 03e!@ |
| 100 | ~3.0 | 出现空格和常用字母,像 hej e o tho |
| 500 | ~2.0 | 蹦出完整短词(the, and, of),语法乱 |
| 2000 | ~1.6 | 有了对话排版、人名结构 |
| 收敛(~5000) | ~1.4--1.5 | 像模像样的剧本格式,语义仍胡言乱语 |
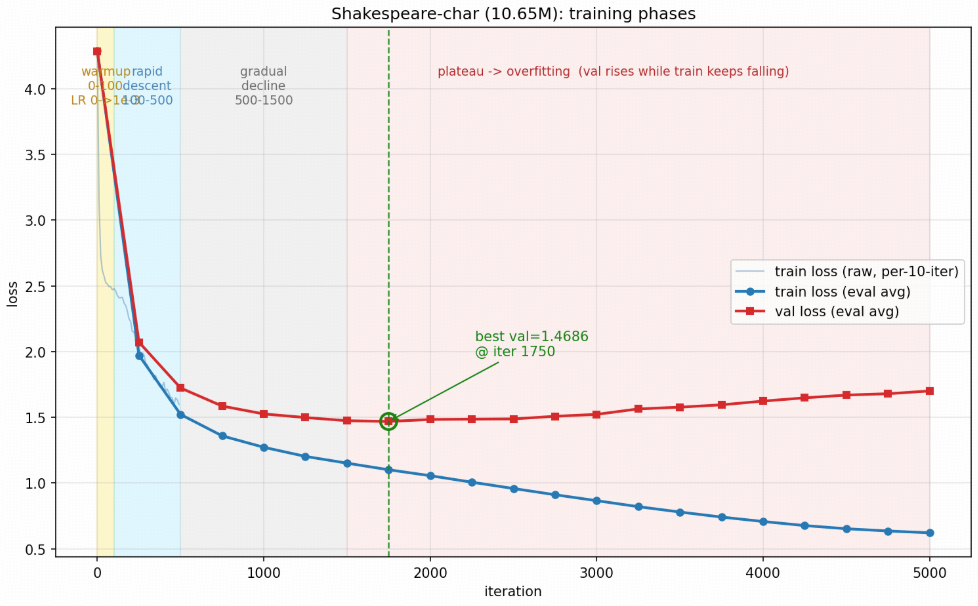
图 1 loss 曲线
图 1 是比较正常的 loss 曲线,容易遇到的 3 种病态曲线:
- 过拟合:数据太少 / 模型太大 / 训太久 → 减小模型或早停、加正则;
- 梯度爆:lr 太大 / 没开 grad_clip → 降 lr 或开裁剪;
- 不降 :lr 太小 / 数据加载错位(检查
y是不是x右移)/ 词表设错。
六、生成:从概率分布到文本
训好之后,生成就是把训练时学到的条件分布反复采样。核心循环约 20 行:
python
@torch.no_grad()
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None):
for _ in range(max_new_tokens):
# 上下文超过 block_size 就只留最后 block_size 个 token
idx_cond = idx[:, -block_size:] if idx.size(1) > block_size else idx
logits, _ = self(idx_cond)
logits = logits[:, -1, :] / temperature # 只取最后位置,temperature 缩放
if top_k is not None: # top-k:只保留概率最高的 k 个
v, _ = torch.topk(logits, top_k)
logits[logits < v[:, [-1]]] = -float('Inf')
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1) # 采样一个 token
idx = torch.cat((idx, idx_next), dim=1) # 接到末尾,继续
return idx三个采样旋钮:
| 参数 | 作用 | 调小 | 调大 |
|---|---|---|---|
| temperature | logits 缩放 | 更确定(趋近 argmax) | 更随机、更"发散" |
| top_k | 只从前 K 个候选里采 | 更保守 | 更开放 |
| top_p(核采样) | 累积概率到 p 的最小集合 | 同 top_k 思路 | 动态候选数 |
一个字符级模型收敛后的生成,大致是
text
ROMEO:
She is not.
JULIET:
What is't, my lord?
ROMEO:
She doth lay it.有完整单词、对话格式、人名,容易胡言乱语,这是字符级 + 小数据的性能上限。
七、全景
text
一段长文本
│ 字符级/子词级 tokenize
▼
一条 token ID 长流 ──随机采样──▶ x:(B,T)
│ y:(B,T) = x 右移 1 位
▼
模型 forward(x) ─▶ logits:(B,T,V) 每个位置预测下一个 token 分布 q
│
▼
loss = cross_entropy(logits, y)
= -1/(BT) ΣΣ log q(y_t | x_≤t)
≈ H(p, q) = H(p) + D_KL(p‖q) ← 下界是数据的熵 H(p)
│
▼
backward → grad_clip → AdamW.step (lr: warmup+cosine)
│ 反复迭代,把 D_KL 往 0 挤;盯 val loss 防过拟合
▼
收敛后:从学到的 q 反复采样 → 生成文本总结
- 语言模型学的是条件分布 P ( x t ∣ x < t ) P(x_t \mid x_{<t}) P(xt∣x<t) ;训练数据就是把一条 token 长流切成
x和它右移一位的y,自监督、可无限造。 - 训练目标是 next-token 交叉熵 ,代码上就是
F.cross_entropy(logits.view(-1,V), targets.view(-1)),数学上是 − 1 B T ∑ ∑ log P θ ( y t ∣ x ≤ t ) -\frac{1}{BT}\sum\sum \log P_\theta(y_t \mid x_{\le t}) −BT1∑∑logPθ(yt∣x≤t)。 - 交叉熵 = 熵 + KL 散度,且 KL 散度严格非负。交叉熵的下界是数据本身的熵,训练就是把 KL 压到 0。
- 判断训得好不好,靠读 val loss 曲线:健康曲线平滑下降,过拟合会让 val 掉头,梯度爆会让 loss 飙升。
- 生成 = 从学到的分布反复采样,temperature / top-k / top-p 控制随机性。
本文用最朴素的 Transformer + 学习式位置编码 当载体,说明 LLM 的训练过程。现代 LLM 有一些优化:把位置编码换成 RoPE 、把 LayerNorm 换成 RMSNorm 、把 FFN 换成 SwiGLU 、把多头注意力换成 GQA 、推理时加上 KV cache 、tokenization 用 BPE...
无论组件怎么换,训练的内核 "最小化 next-token 交叉熵" 始终不变。