我不是在教 AI 写标书,我是在教 AI 理解"甲方到底想要什么"。
先看下最后成品的效果


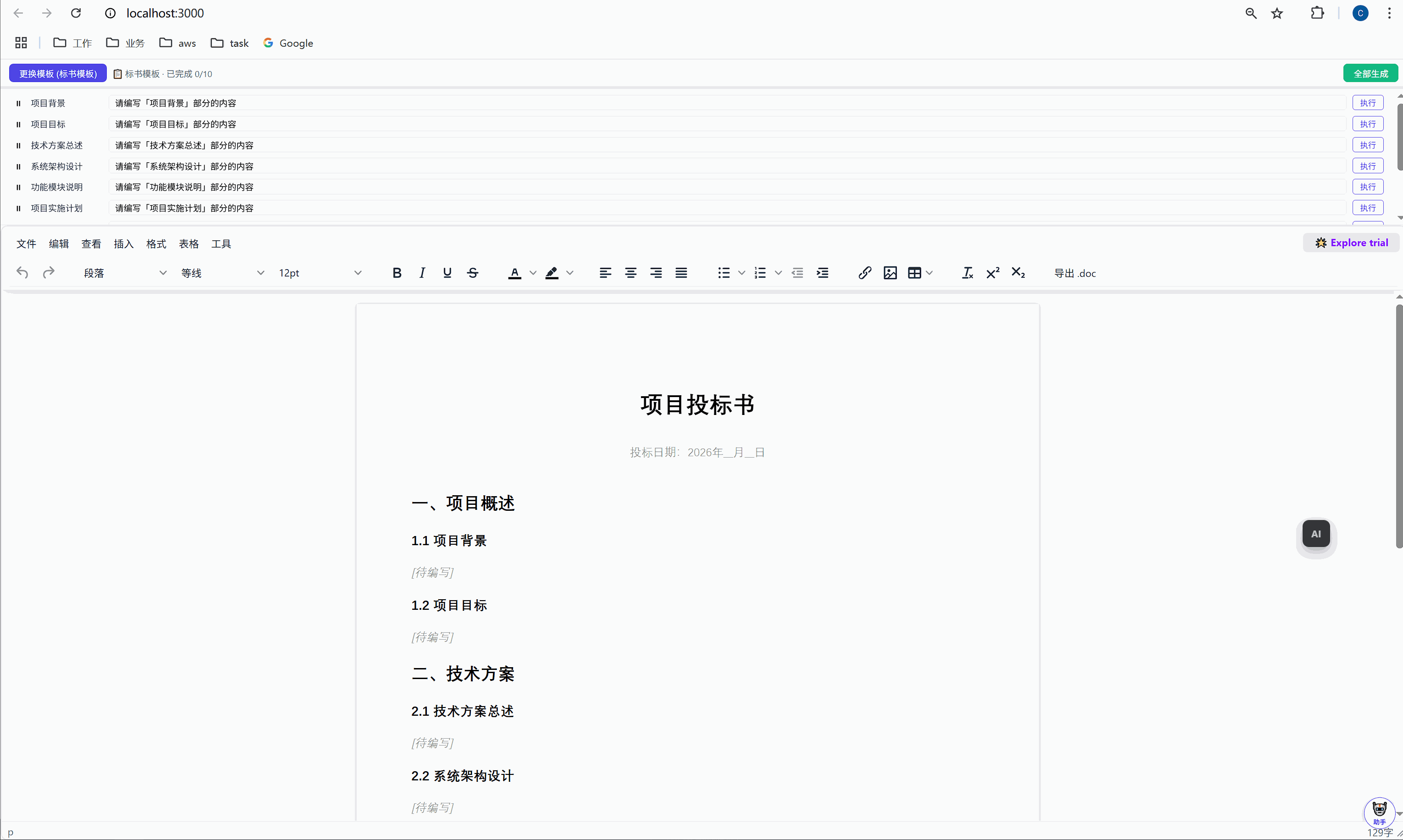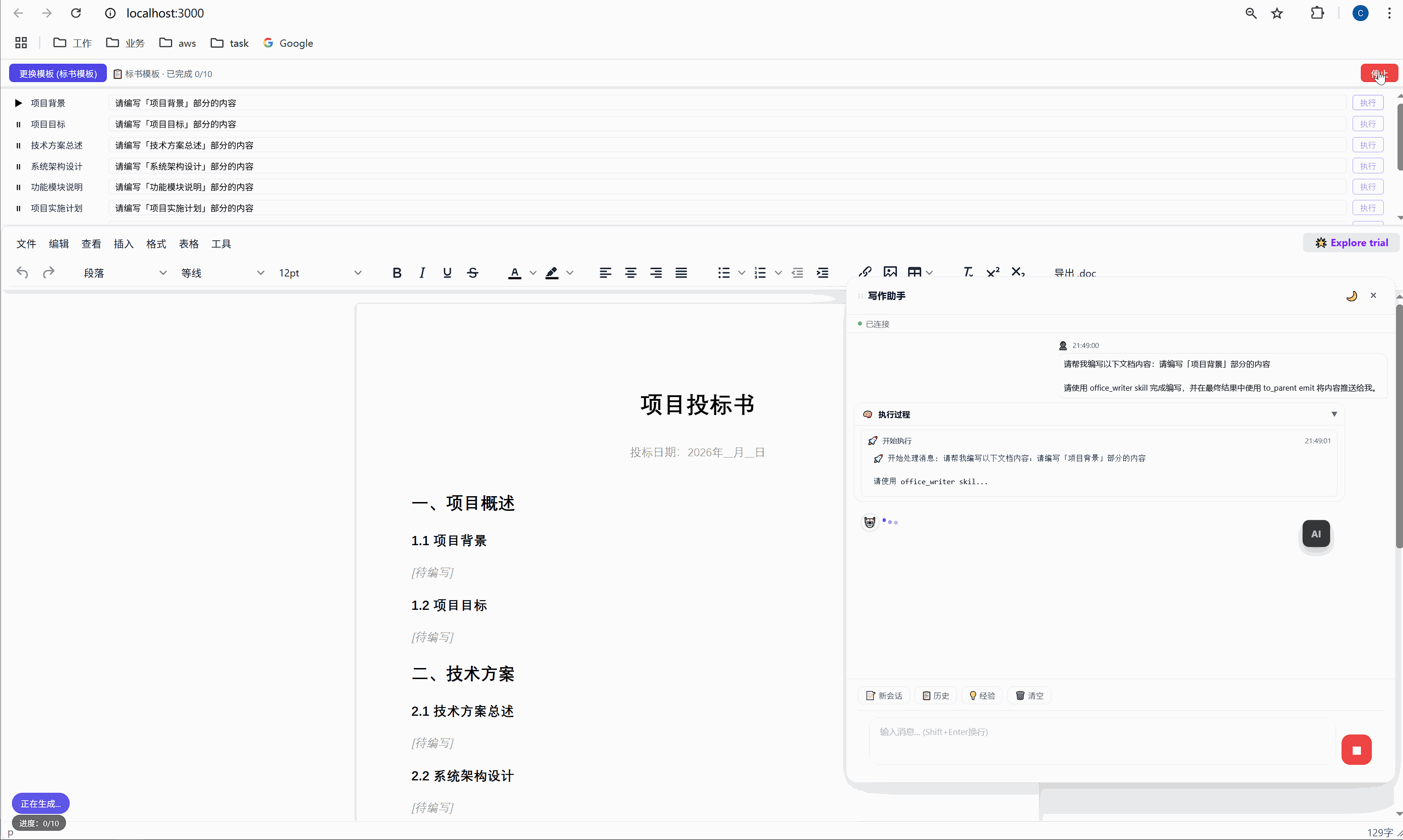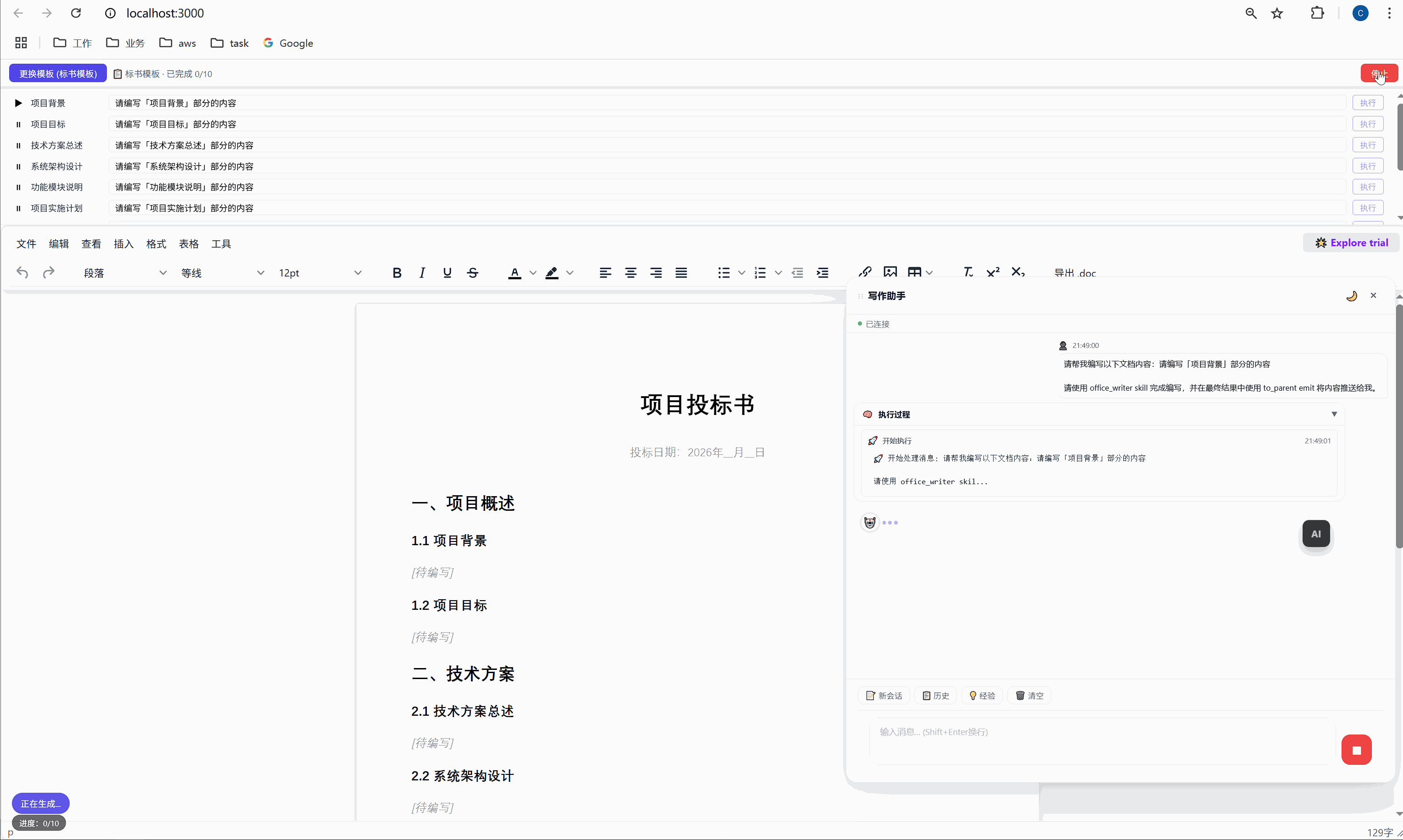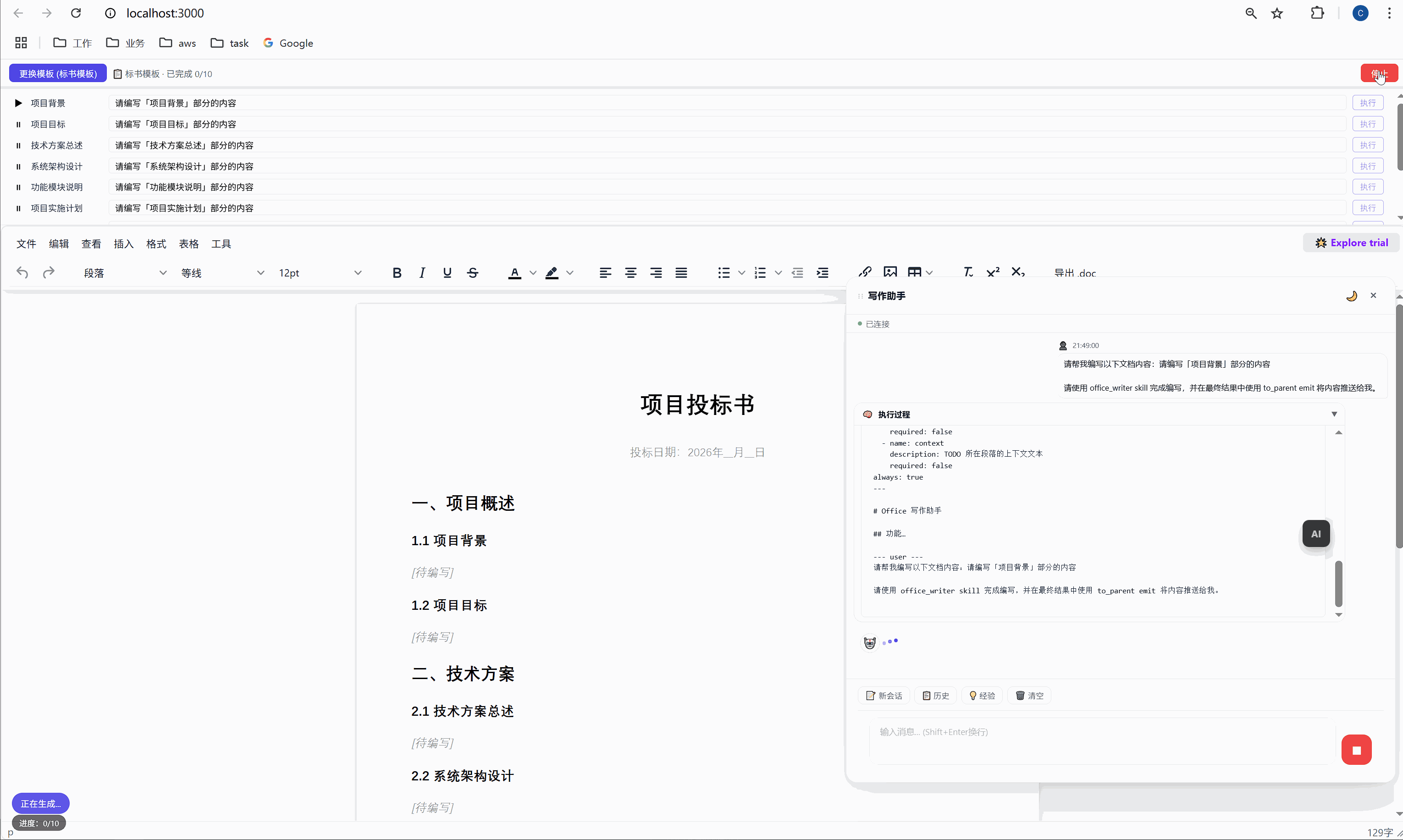
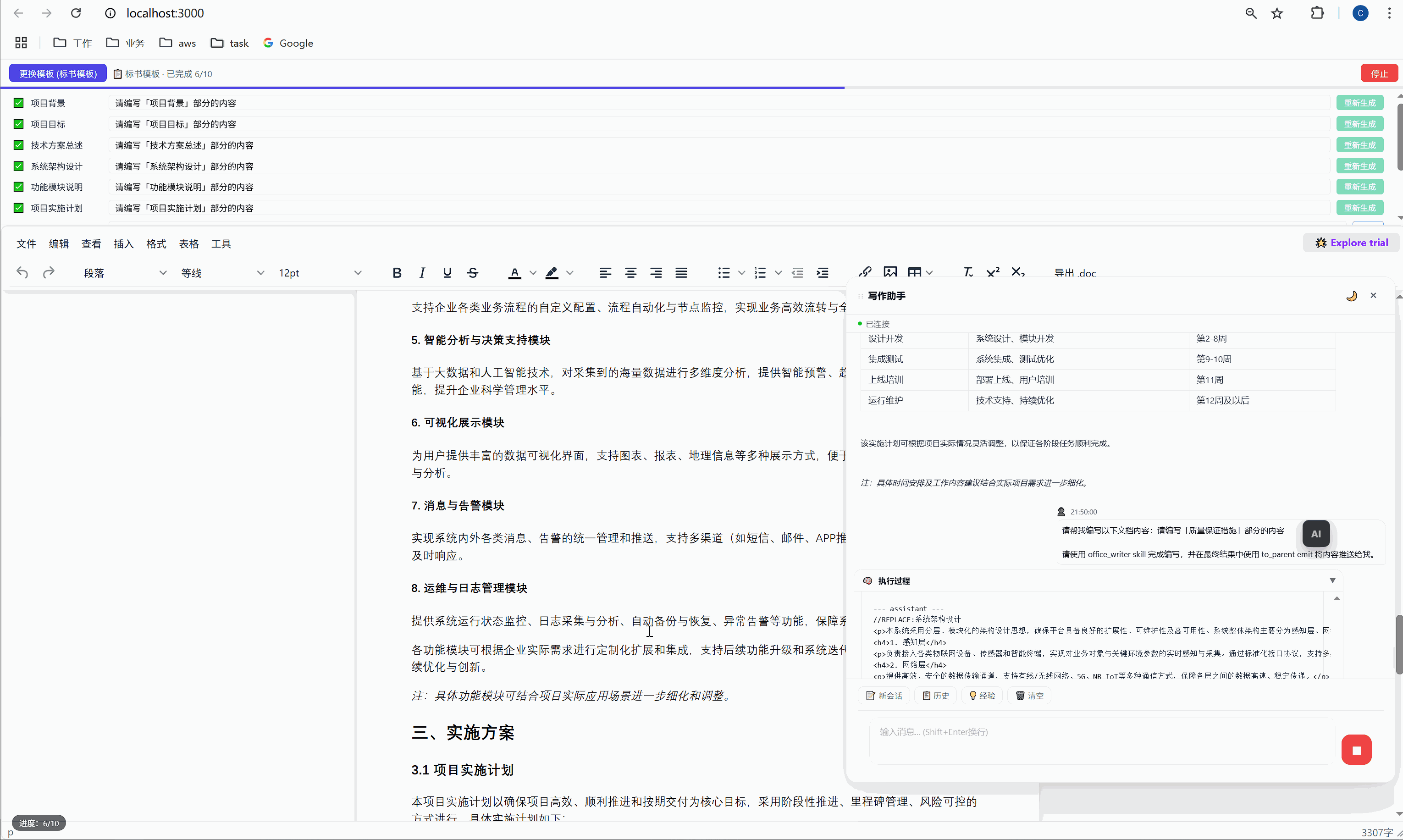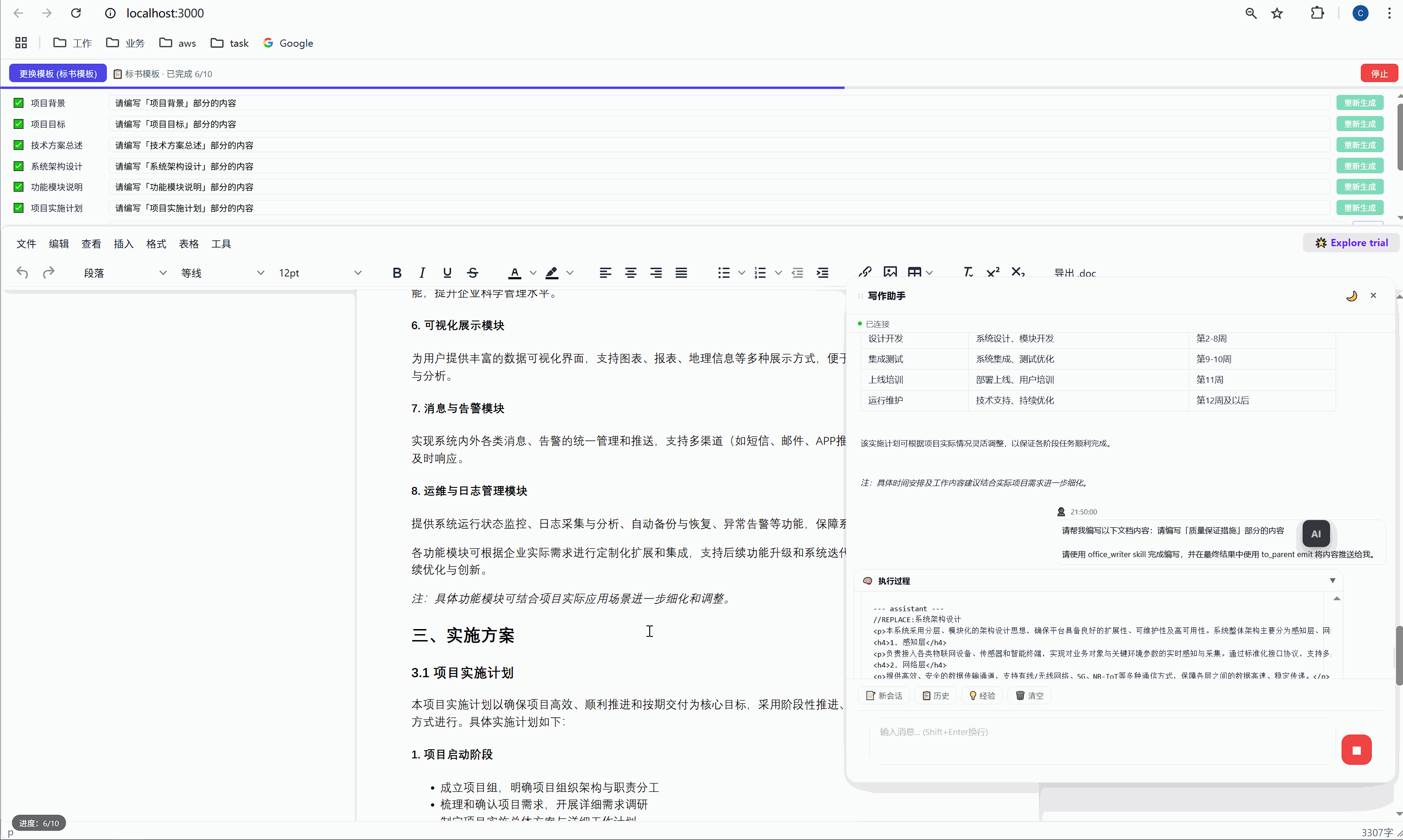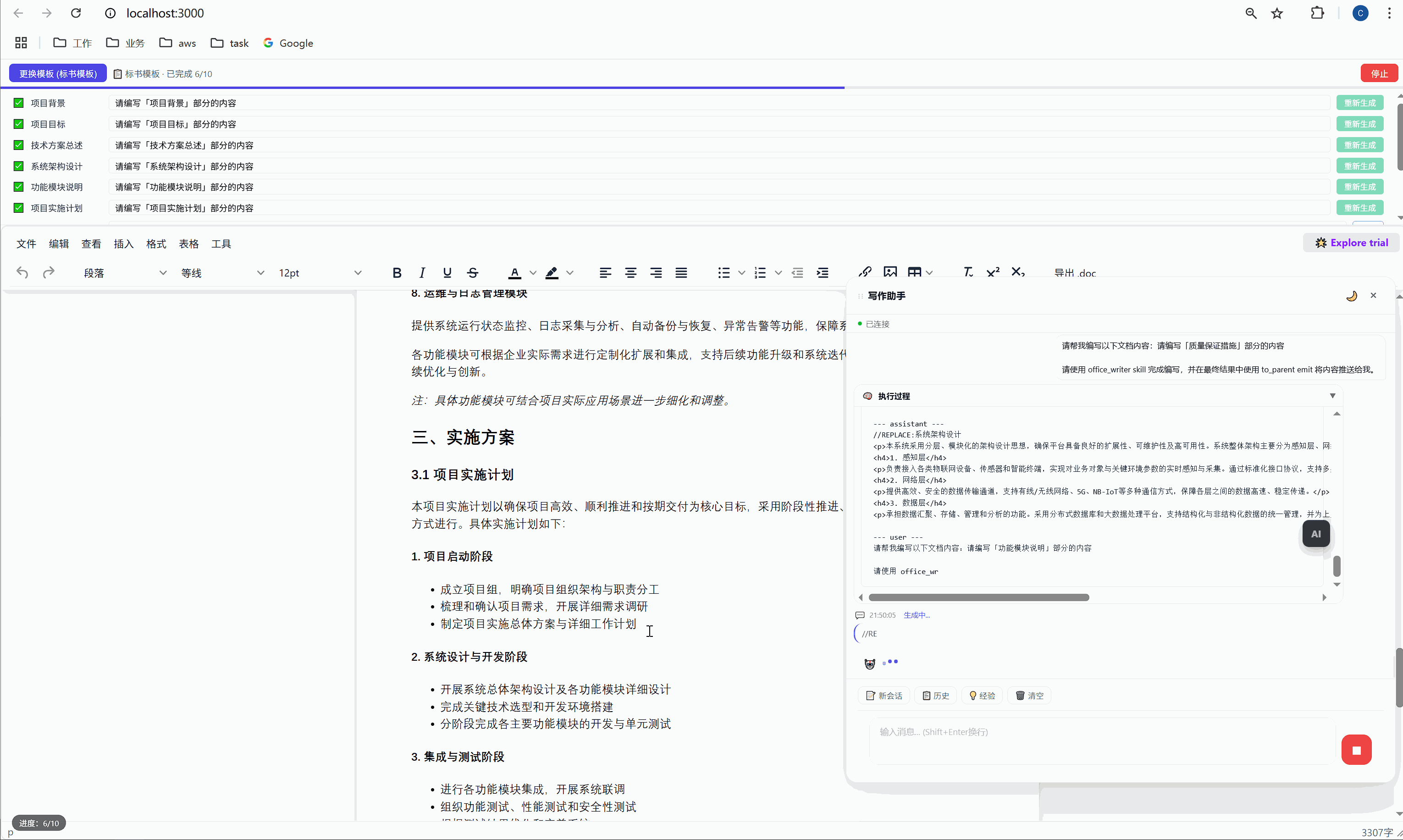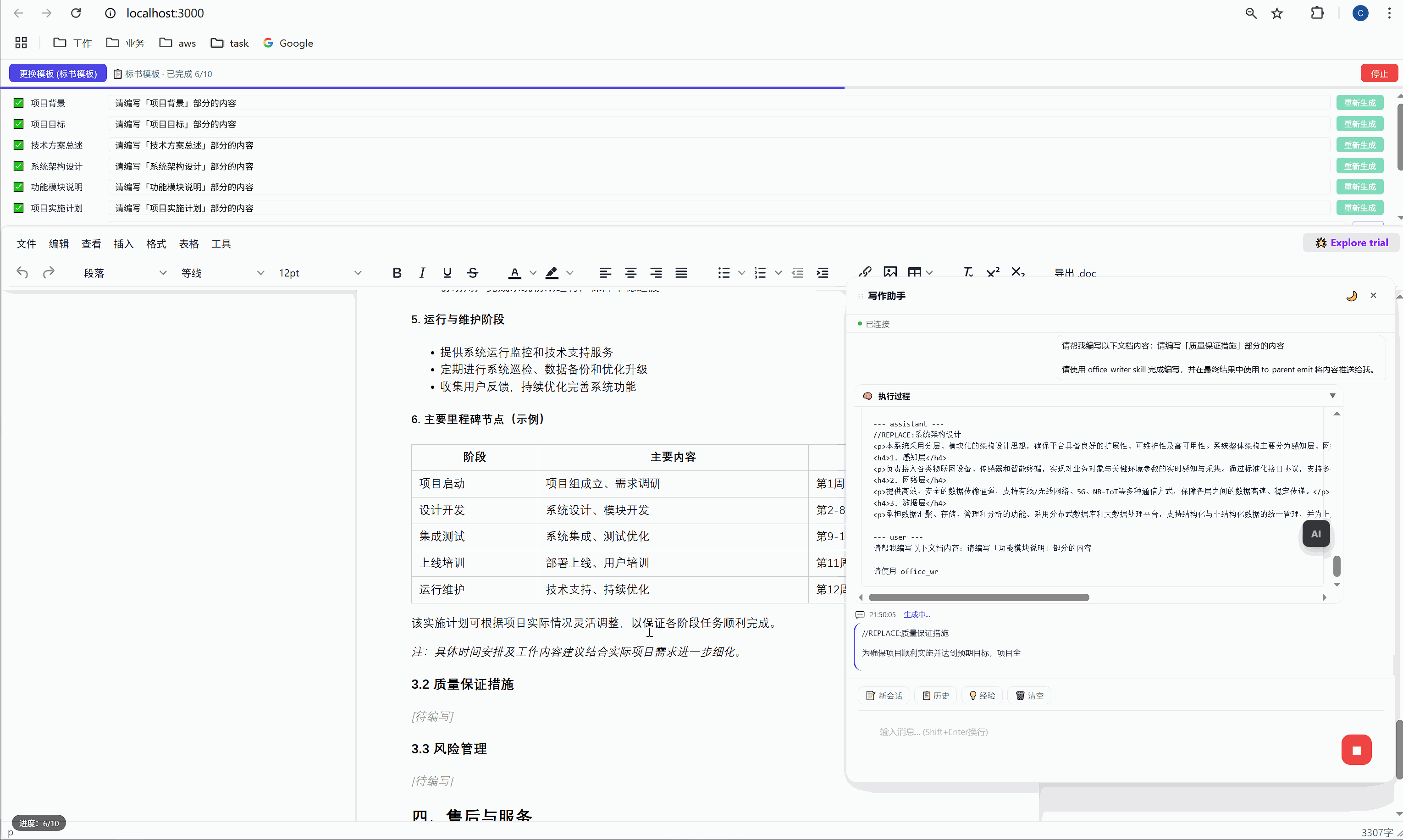
一、故事的起点:那个让我怀疑人生的夜晚
凌晨一点半,屏幕上的 Word 文档还停在"一、项目概述"下面那行刺眼的 [待补充]。
这是我这个月第三次写标书了。同样的结构,类似的套路,不同的只是客户名字和项目预算。我熟练地打开上一次的标书,Ctrl+C,Ctrl+V,然后把"某某公司"改成"某某科技公司"。
作为一名工程师,我做这件事的时候内心有一个声音在尖叫:这件事不应该由人来做。
不是因为我懒(好吧,确实有一部分原因),而是因为这种重复性的、结构化的、有模板可循的工作,恰恰是最应该被自动化掉的。如果连写标书这种八股文式的东西都要人工一个字一个字敲,那我们对"智能"二字的理解未免太谦虚了。
于是,在那个凌晨两点终于合上电脑的夜晚,我决定了:我要让 AI 帮我写标书。
听起来像是"我要让 AI 帮我上班"------没错,这就是全部动机。
二、但事情没那么简单
"让 AI 写标书"这句话,说出来只需要一秒钟。但要真正做到"写出来能用",背后涉及的问题比想象中多得多。
2.1 第一反应:直接丢给 ChatGPT 不行吗?
当然可以。你把需求发过去,ChatGPT 会给你一大段看起来还不错的文字。然后你会发现:
- 内容挺好,但格式全乱了,Markdown 符号直接裸奔到了 Word 里
- 它给你加了一个
<h2>一、项目背景</h2>,但你文档里本来就有这个标题,结果重复了 - 你想让它写"项目背景",它顺便把"项目目标"也写了,插入位置完全不对
- 你觉得写得不好想重新生成一次------不好意思,AI 不知道之前写了什么,也不知道该替换哪里
这就是大语言模型的天生缺陷:它们擅长生成,但不擅长"定位"。它们可以写出三千字的好文章,但如果你说"把文档第三段替换掉,其他不变",它们就会给你一个全新的文档,让你自己去找不同。
2.2 问题的本质:生成 vs. 编辑
写标书不是"从零生成一篇文章",而是"在已有的文档框架中,把空白的地方填满"。这是一个编辑 问题,不是生成问题。
生成是 LLM 的强项,编辑是 LLM 的弱项。
所以,我需要构建一个系统,让 LLM 专注于它擅长的事情(生成内容),而我用代码来处理它不擅长的事情(定位、替换、格式控制)。
这就是Agent 工程化 的核心思想:不是让 AI 什么都做,而是让 AI 做它该做的事,其他的交给代码。
三、架构设计:Agent 不只是"调个 API"
很多人对 AI Agent 的理解就是"包一层 API 调用"。如果这就是全部,那它和 ChatGPT 网页版有什么区别?
真正的 Agent 系统,应该是一个有结构的工程系统,每一层都有明确的职责和边界。
3.1 整体架构
我构建的这个系统叫 pricebot,名字听起来像个报价机器人,但它实际上是一个通用的 AI Agent 平台。写标书只是它的一个 skill(技能)。
整体架构是这样的:
┌──────────────────────────────────────────────────────┐
│ 前端 (React + TinyMCE) │
│ ┌──────────┐ ┌─────────────┐ ┌─────────────────┐ │
│ │ 模板选择 │ │ 任务面板 │ │ TinyMCE 编辑器 │ │
│ │ 弹窗 │ │ 顺序执行 │ │ (类 Word 界面) │ │
│ └────┬─────┘ └──────┬──────┘ └────────┬────────┘ │
│ │ │ │ │
│ └───────────────┼──────────────────┘ │
│ │ Socket.IO │
└───────────────────────┼──────────────────────────────┘
│
┌───────────────────────┼──────────────────────────────┐
│ 后端 (Python) │
│ │ │
│ ┌────────┴────────┐ │
│ │ MessageBus │ ← 消息总线解耦 │
│ └────────┬────────┘ │
│ │ │
│ ┌────────┴────────┐ │
│ │ AgentLoop │ ← 核心引擎 │
│ │ Tool Call │ │
│ │ 循环 │ │
│ └────────┬────────┘ │
│ │ │
│ ┌────────┴────────┐ │
│ │ office_writer │ ← 标书写作 Skill │
│ │ Skill │ │
│ └─────────────────┘ │
└──────────────────────────────────────────────────────┘这不是什么微服务架构------整个系统的核心代码不过几千行。但正是这种轻量而清晰的架构,让它既好维护又好扩展。
3.2 消息总线:一切皆消息
系统的第一原则是解耦。前端不直接调后端 API,后端不直接操作前端 DOM。所有通信通过一条消息总线(MessageBus)。
用户点击"全部生成"
→ 前端发送 message 到 Socket.IO
→ MessageBus 接收 InboundMessage
→ AgentLoop 消费消息,执行 Skill
→ AI 生成内容
→ MessageBus 发布 OutboundMessage
→ 前端接收 to_parent 事件
→ 内容插入编辑器每一层只做自己的事。前端不关心 AI 怎么生成内容,后端不关心内容插到编辑器的哪个位置。这种面向消息的架构看似多了一层,实则让系统具有极强的可扩展性------今天加一个 Telegram 渠道,明天加一个 WhatsApp 渠道,Agent 端完全不用改。
3.3 AgentLoop:核心引擎
AgentLoop 是整个系统的心脏。它的工作流程是一个工具调用循环:
输入消息
→ 构建上下文(系统提示 + 记忆 + Skill 说明)
→ 调用 LLM(流式输出)
→ 如果 LLM 返回 tool_calls → 执行工具 → 结果追加到消息 → 继续循环
→ 如果 LLM 返回纯文本 → 结束,输出内容最多循环 N 次(防止死循环)。每次循环 LLM 可以决定调用什么工具:读取文件、执行命令、搜索网页、发送消息......
这就是 Agent 和普通 ChatBot 的区别:Agent 有工具,ChatBot 只有嘴。
四、Skill 系统:让 AI 学会"一技之长"
pricebot 有一个 Skill(技能)系统。每个 Skill 是一个 Markdown 文件(SKILL.md),定义了:
- 这个技能是干什么的
- 需要哪些输入参数
- 执行流程是什么
- 输出格式要求
4.1 office_writer SKILL.md
yaml
---
name: office_writer
description: Office 文档写作辅助------分析 TODO 注释,根据上下文和用户需求生成专业的文档内容
emoji: "📝"
inputs:
- name: todo_content
description: 用户在文档中标注的 TODO 内容
required: true
- name: document_type
description: 文档类型(bid/合同/报告/方案/其他)
required: false
always: true
---然后是执行流程:
markdown
## 执行流程
### Step 1:分析 TODO 意图
理解用户的 TODO 注释,识别:
- 需要编写什么内容
- 属于哪个文档类型
- 在文档中的位置/章节
### Step 2:收集上下文信息
分析前后文,确保生成内容与已有内容连贯
### Step 3:生成内容
使用 HTML 格式输出(TinyMCE 富文本编辑器,非 Markdown)
**不要生成章节标题**,文档模板已包含标题结构
### Step 4:输出格式
第一行添加 //REPLACE: 指令,换行后接 HTML 正文:
//REPLACE:项目背景
<p>随着现代物流行业的快速发展...</p>这个 SKILL.md 看起来简单,但它其实是AI 的行为规范。就像给新员工写的 onboarding 文档一样,它告诉 AI:
- 你是谁(Office 写作助手)
- 你该做什么(分析 TODO,生成内容)
- 你不该做什么(不要生成标题、不要用 Markdown、不要发中间状态通知)
- 你的输出应该长什么样(
//REPLACE:xxx指令 + HTML 正文)
4.2 为什么 SKILL.md 很重要
很多人做 AI 应用时,把所有提示词(prompt)都写死在代码里。这样做的问题是:
- 不好维护:改提示词需要改代码、重新部署
- 不好调试:出了问题是 prompt 的问题还是代码的问题?说不清
- 不好复用:同一个 skill 想在不同场景下用,得复制粘贴
把 prompt 抽成 SKILL.md 的好处是:
- 改 prompt 只需要改文件,不需要重新部署代码
- 出了问题时可以直接看 SKILL.md,快速定位是 prompt 写得不好
- Skill 可以在不同的 Agent 会话中复用
这本质上就是配置与代码分离的经典工程实践,只不过配置的内容变成了自然语言。
五、前端工程化:一个富文本编辑器的自我修养
前端用的是 React + TinyMCE。TinyMCE 是一个成熟的富文本编辑器,默认长这样就是一个类似 Word 的编辑界面。但我做了一些关键的定制。
5.1 Office 化外观
没人愿意在一个看起来像 2005 年网页的编辑器里写标书。所以我把 TinyMCE 调整成了 Office Word 的风格:
- A4 纸张外观:白色页面居中,灰色背景,带轻微阴影,看起来就像一张真实的纸
- 菜单栏:启用了"文件/编辑/视图/插入/格式/表格"等完整菜单
- 字体选择器:等线、Calibri、宋体、黑体、微软雅黑------都是中国 Office 用户的老朋友
- 字号选择器:8pt 到 72pt,从脚注到封面标题全覆盖
- 工具栏分组:撤销重做 → 字体字号 → 粗体斜体下划线 → 颜色 → 对齐 → 列表 → 链接表格 → 其他
还有导出 .doc 按钮------点击即可将编辑器内容导出为 Word 兼容的 .doc 文件。实现方式很巧妙:把 HTML 包装成 Word 能识别的格式(带 urn:schemas-microsoft-com:office:word 命名空间 + BOM 头),然后用 Blob 下载。零依赖,15 行代码搞定。
5.2 模板系统
标书是有固定结构的。一份标准的投标书通常包含:
一、项目概述
├── 项目背景
└── 项目目标
二、技术方案
├── 技术方案总述
├── 系统架构设计
└── 功能模块说明
三、实施方案
├── 项目实施计划
├── 质量保证措施
└── 风险管理
四、售后与服务
├── 售后服务方案
└── 团队与人员配置我把这个结构做成了模板,用 HTML 文件存储在 public/templates/bid_template.html 中。每个待填项用一个 <p> 标签标记:
html
<h3>1.1 项目背景</h3>
<p class="todo" data-todo="项目背景" style="color:#999;">[待编写]</p>标题是可见的(<h3>),占位符也是可见的(灰色斜体的 [待编写])。这样用户在编辑器里一眼就能看到哪些地方还没写。
5.3 模板选择弹窗
点击"选择模板"按钮,弹出一个居中的模态框,展示所有可用模板:
┌─────────────────────────────────────┐
│ 选择文档模板 │
├─────────────────────────────────────┤
│ 📋 标书模板 │
│ 标准项目投标书,含技术方案、 │
│ 实施方案、售后服务等章节 │
│ 包含 10 个待填项:项目背景、... │
├─────────────────────────────────────┤
│ 📄 合同模板(待添加) │
└─────────────────────────────────────┘新增模板只需要两件事:在 TEMPLATES 数组里加一个对象,在 public/templates/ 下放一个 HTML 文件。零配置,零代码改动。
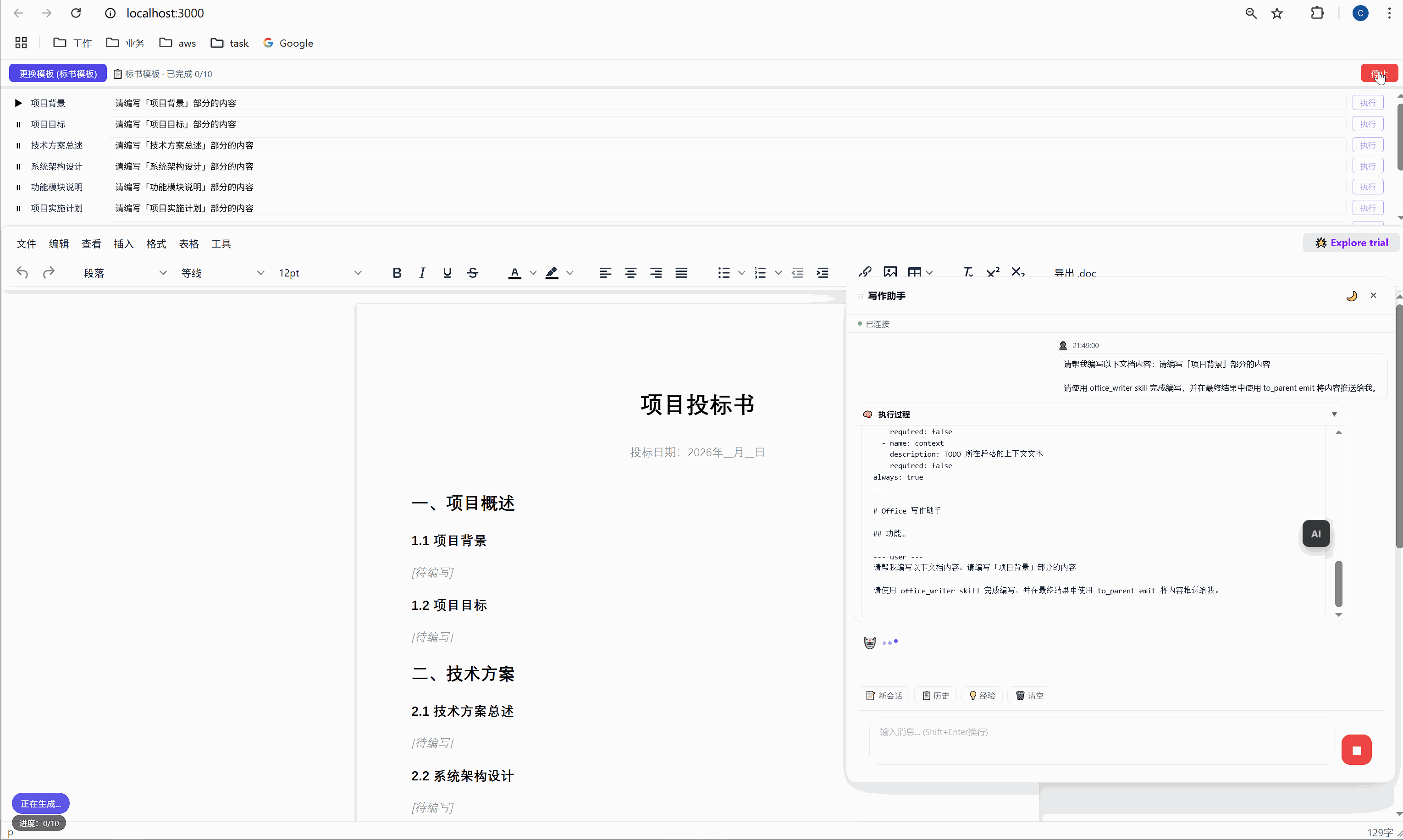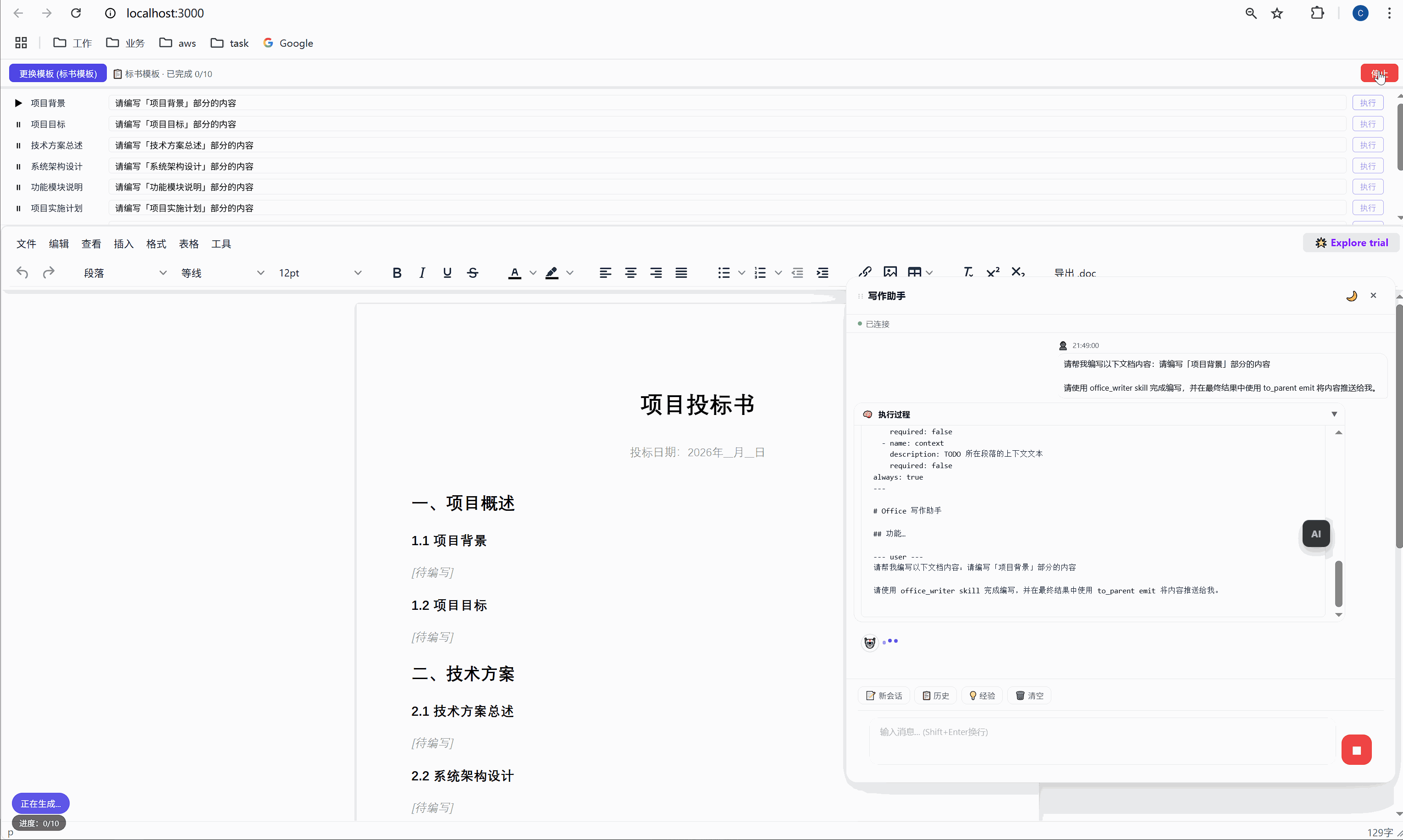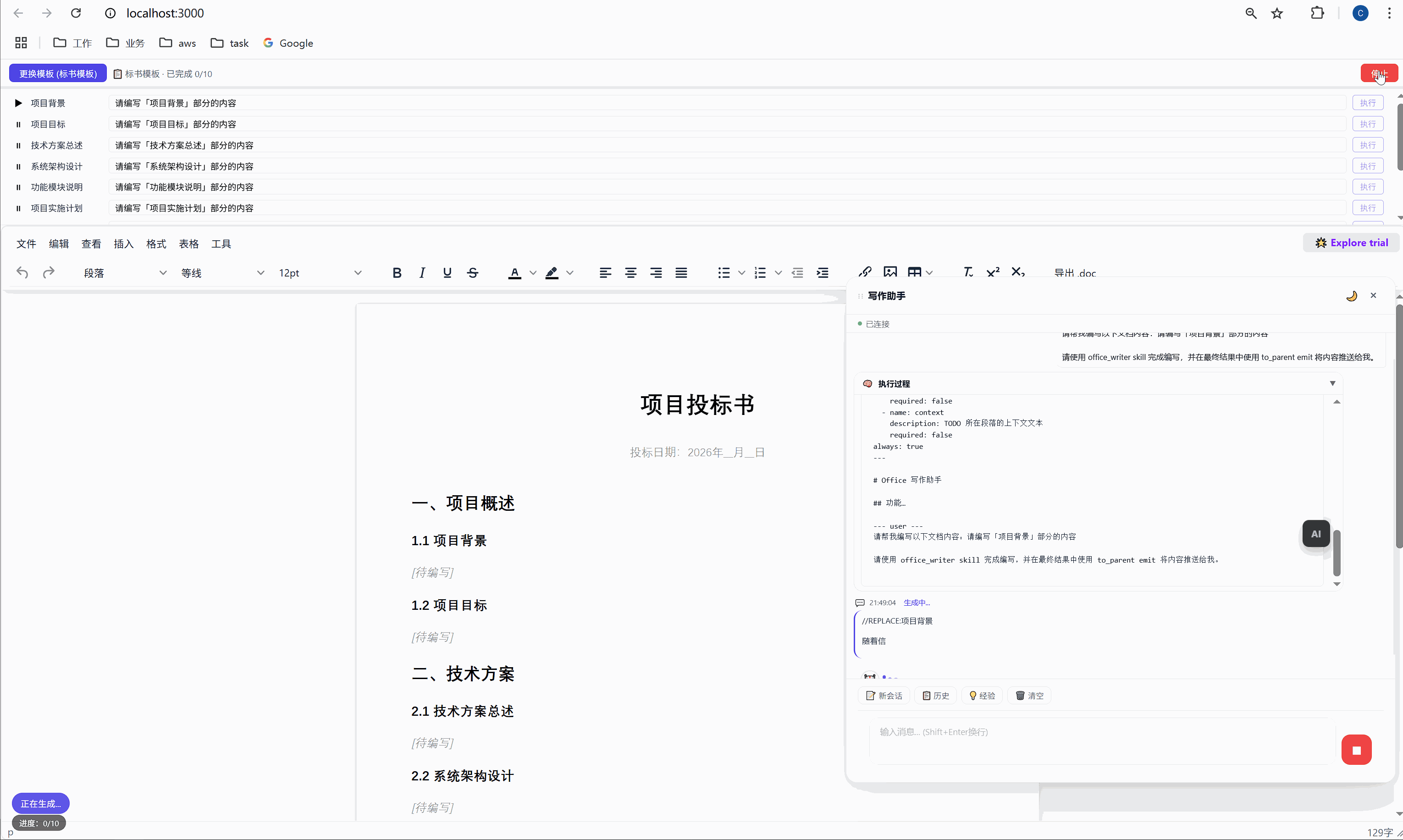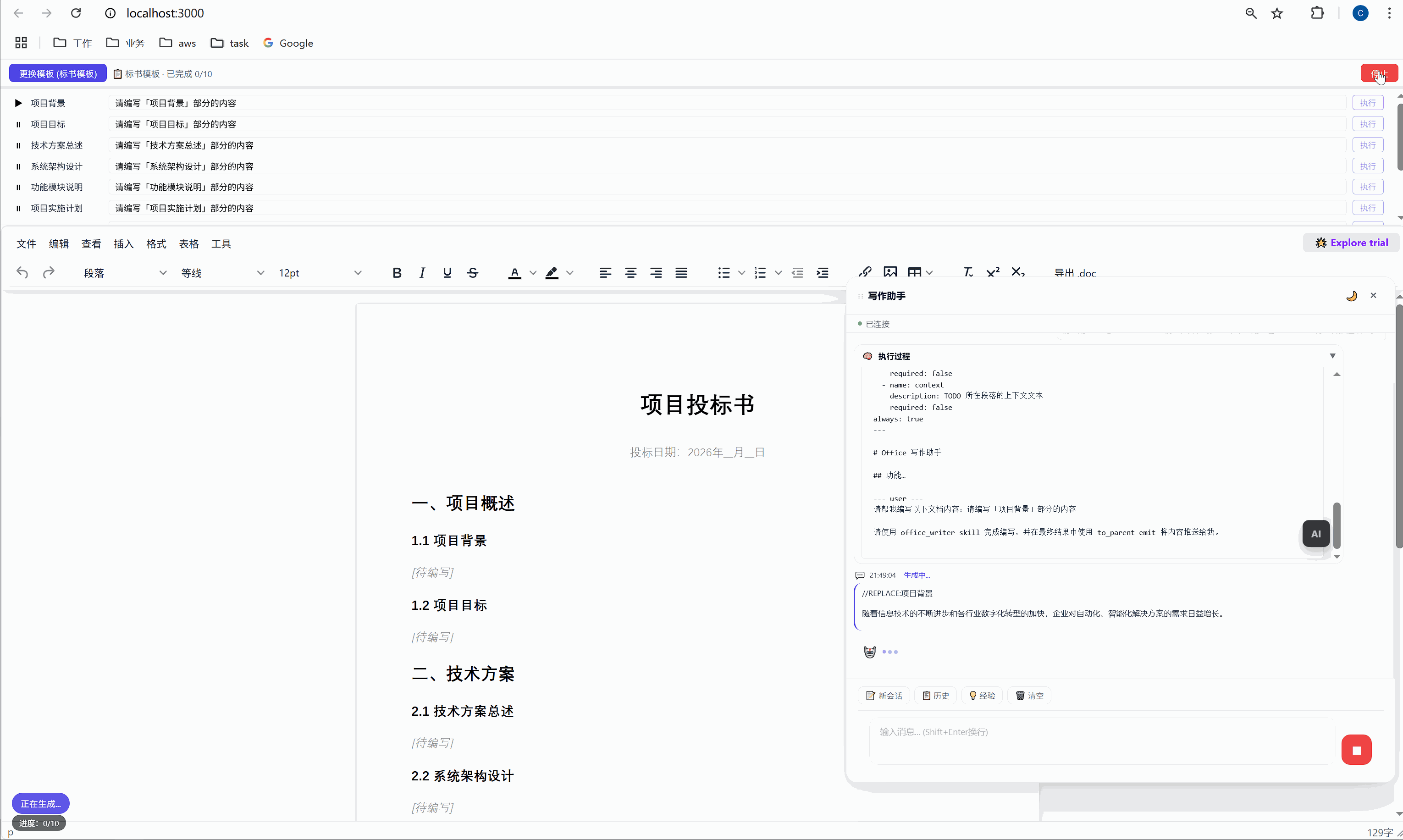
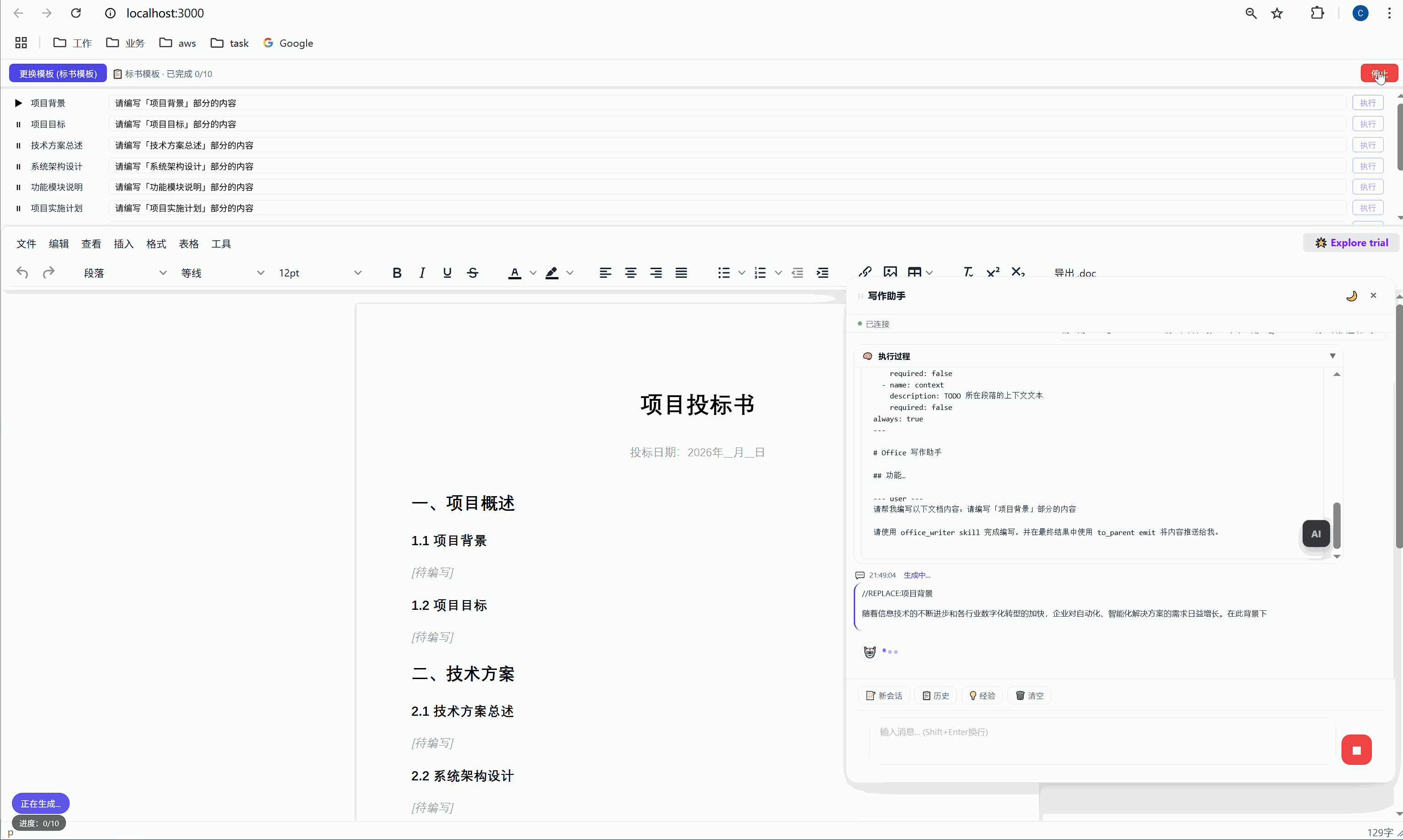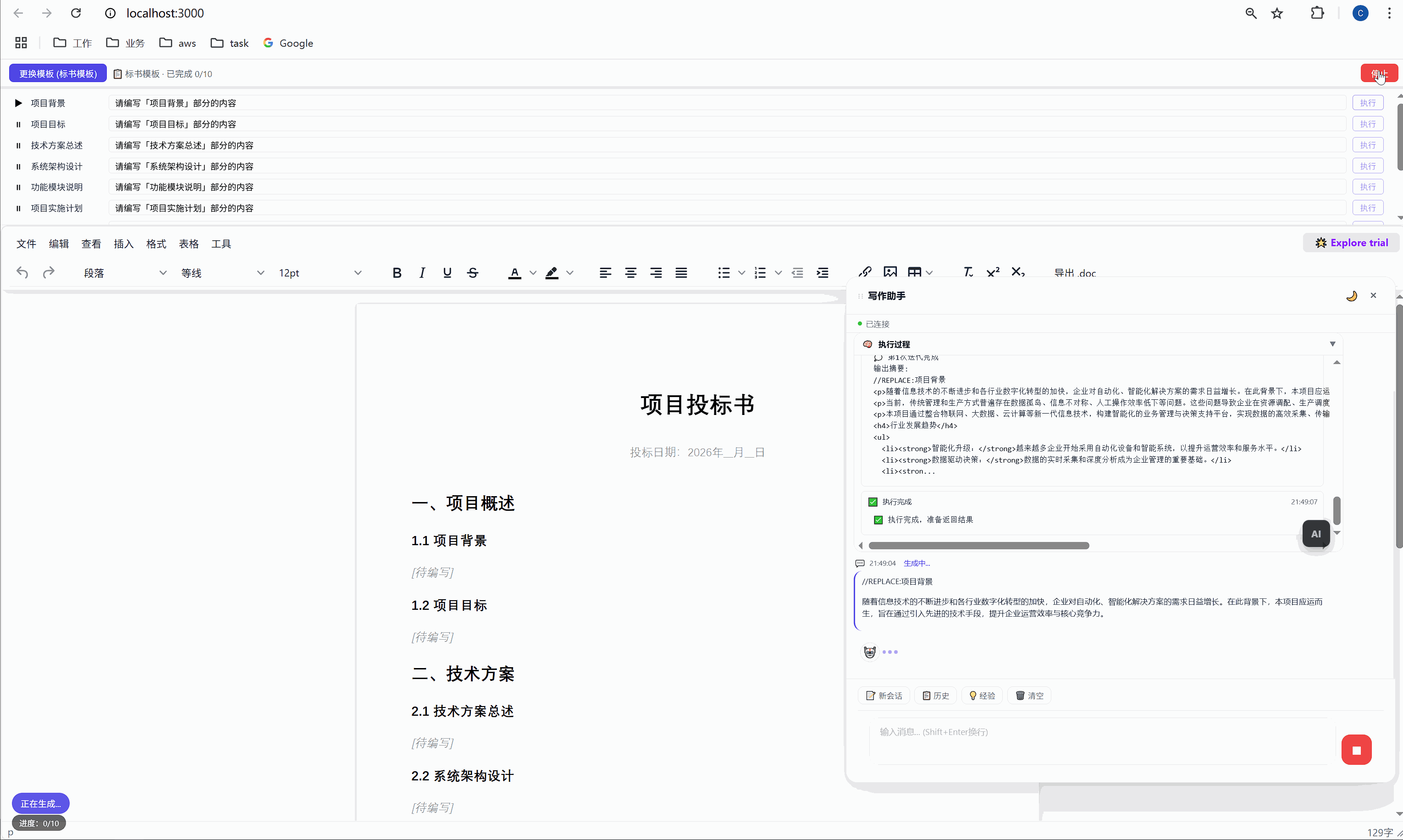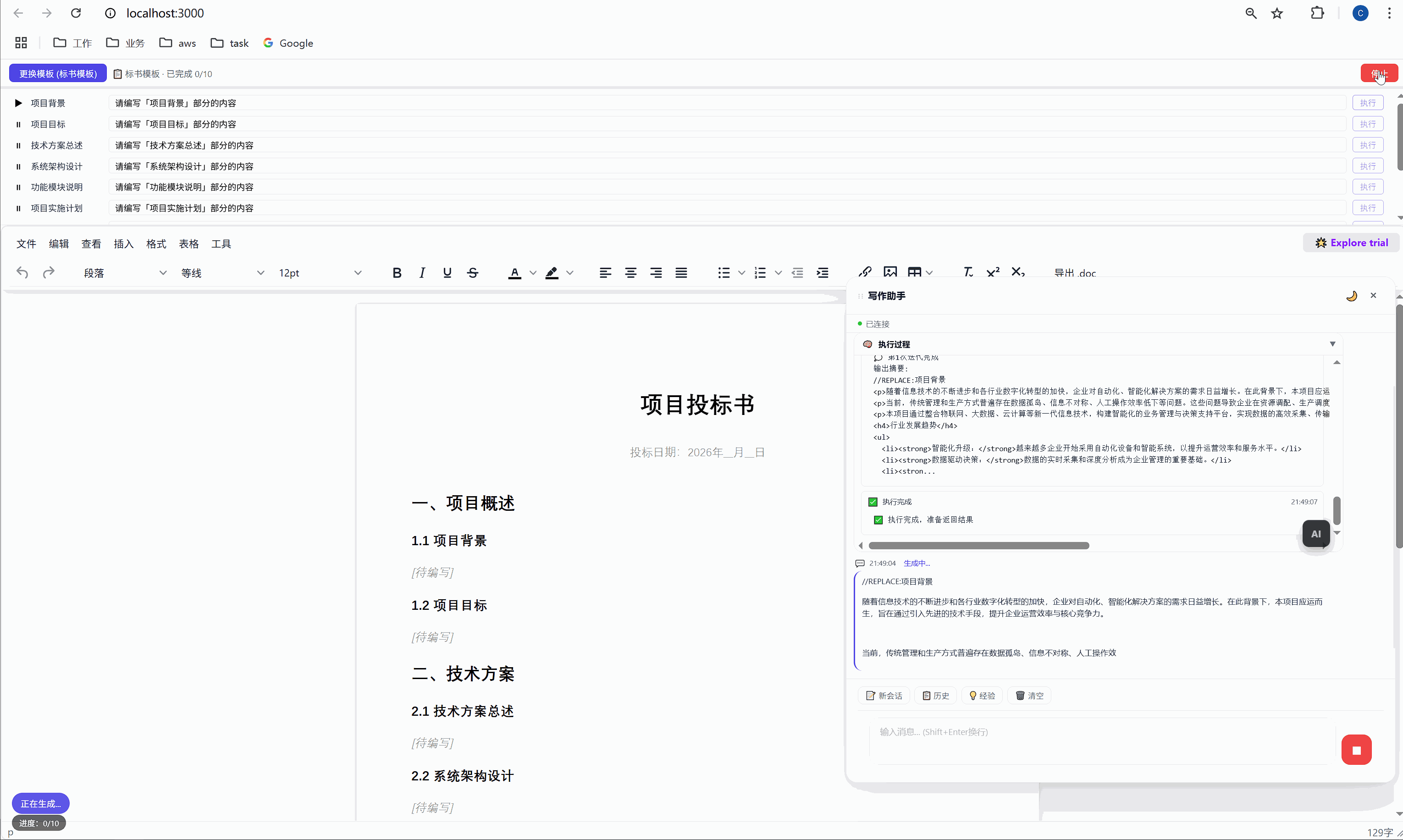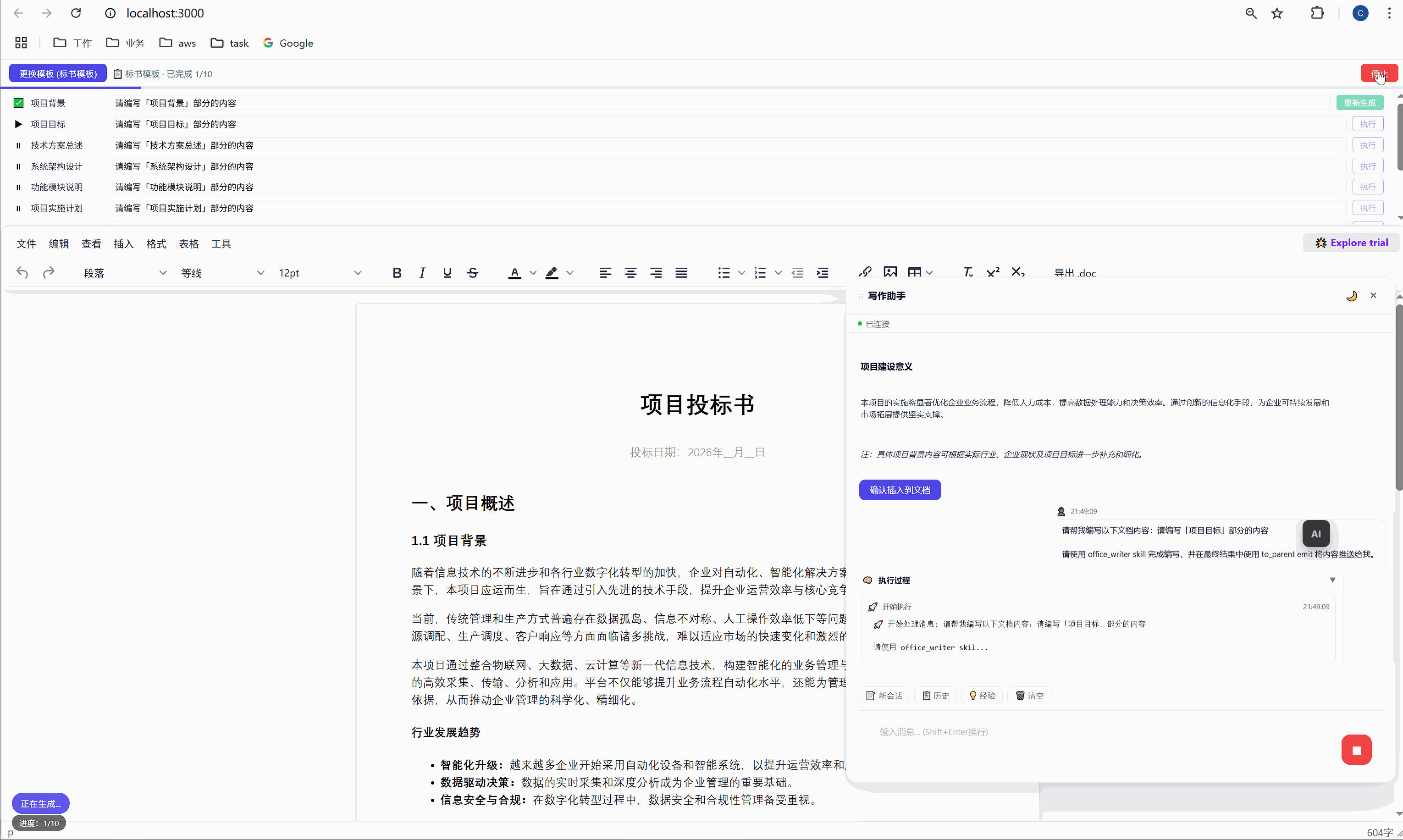
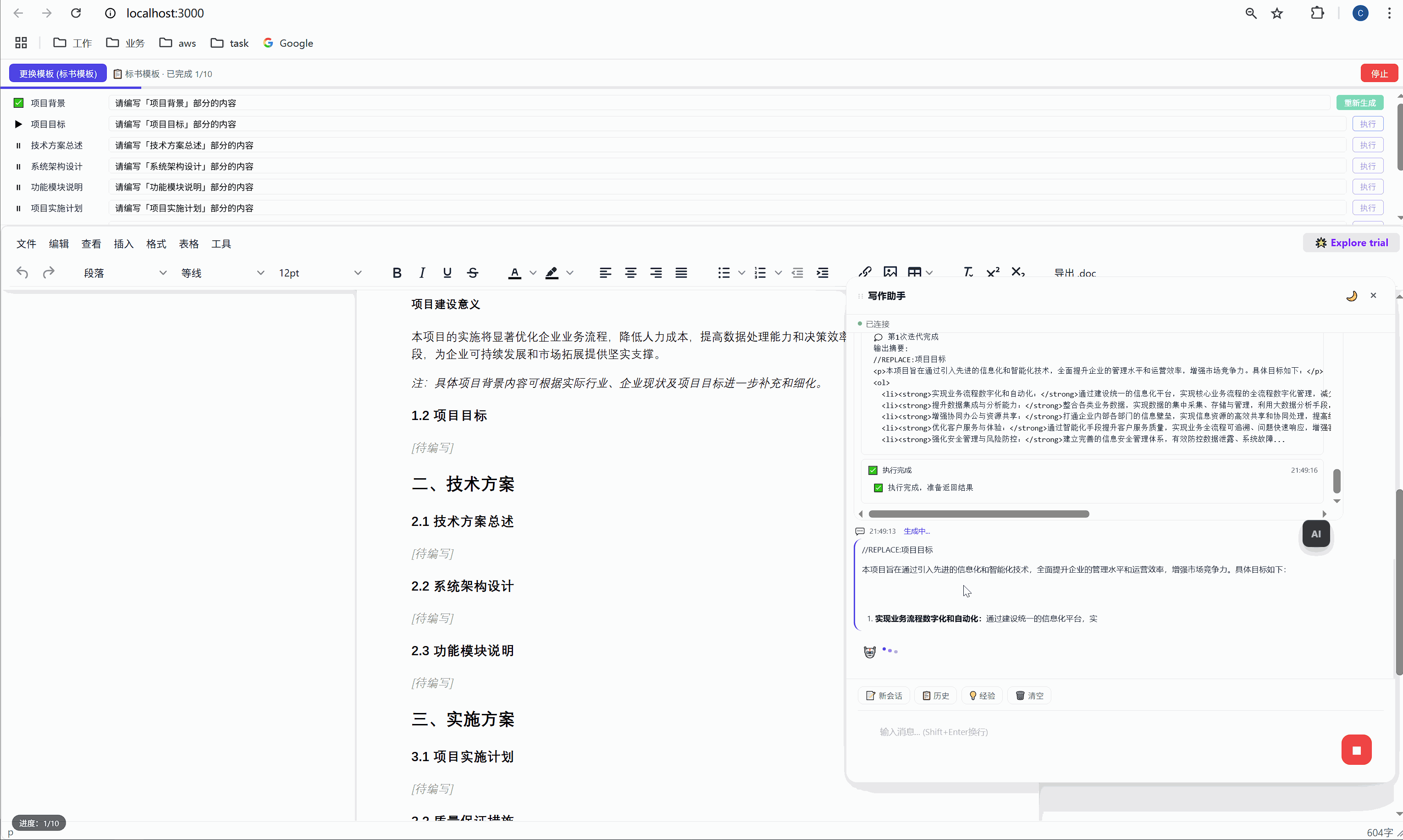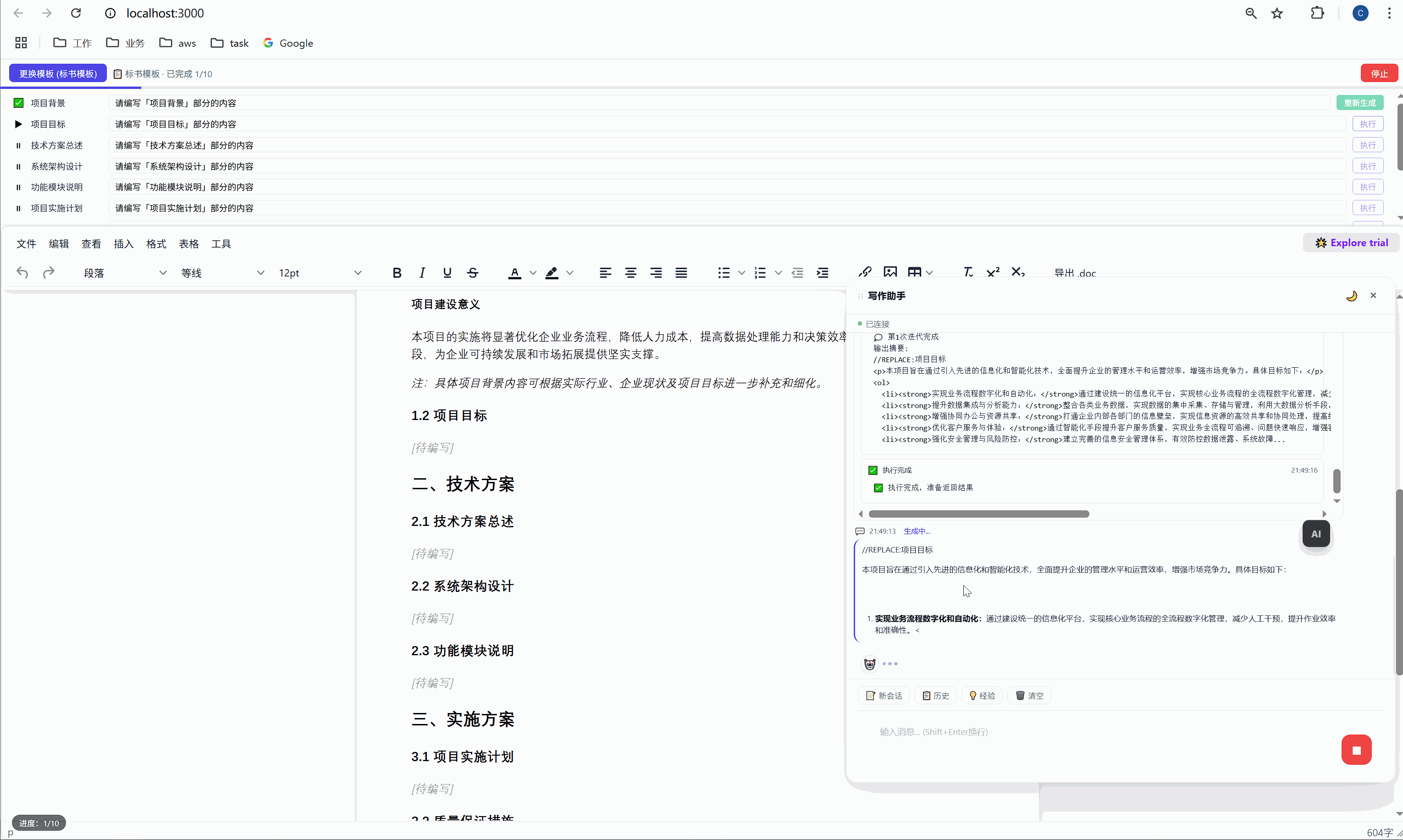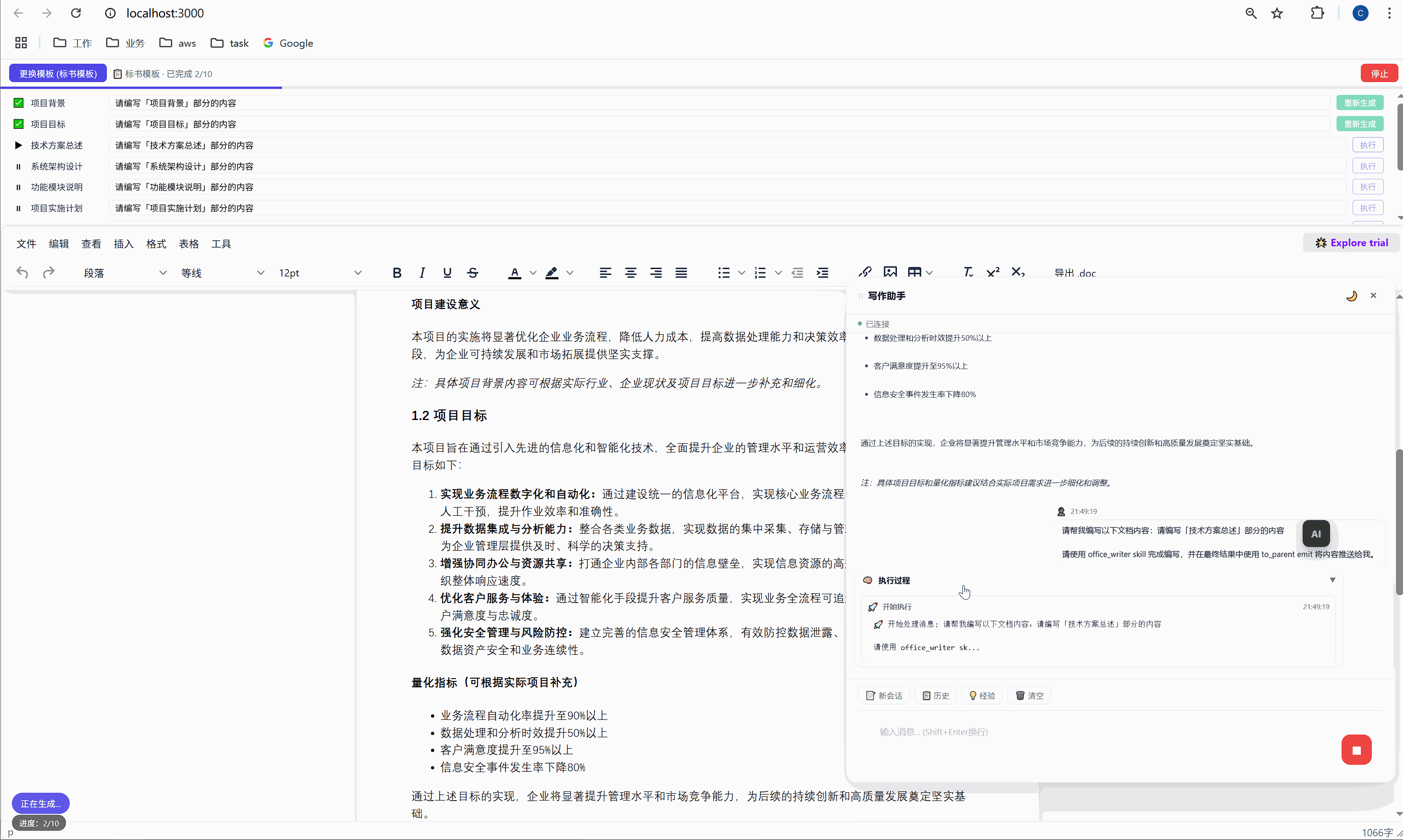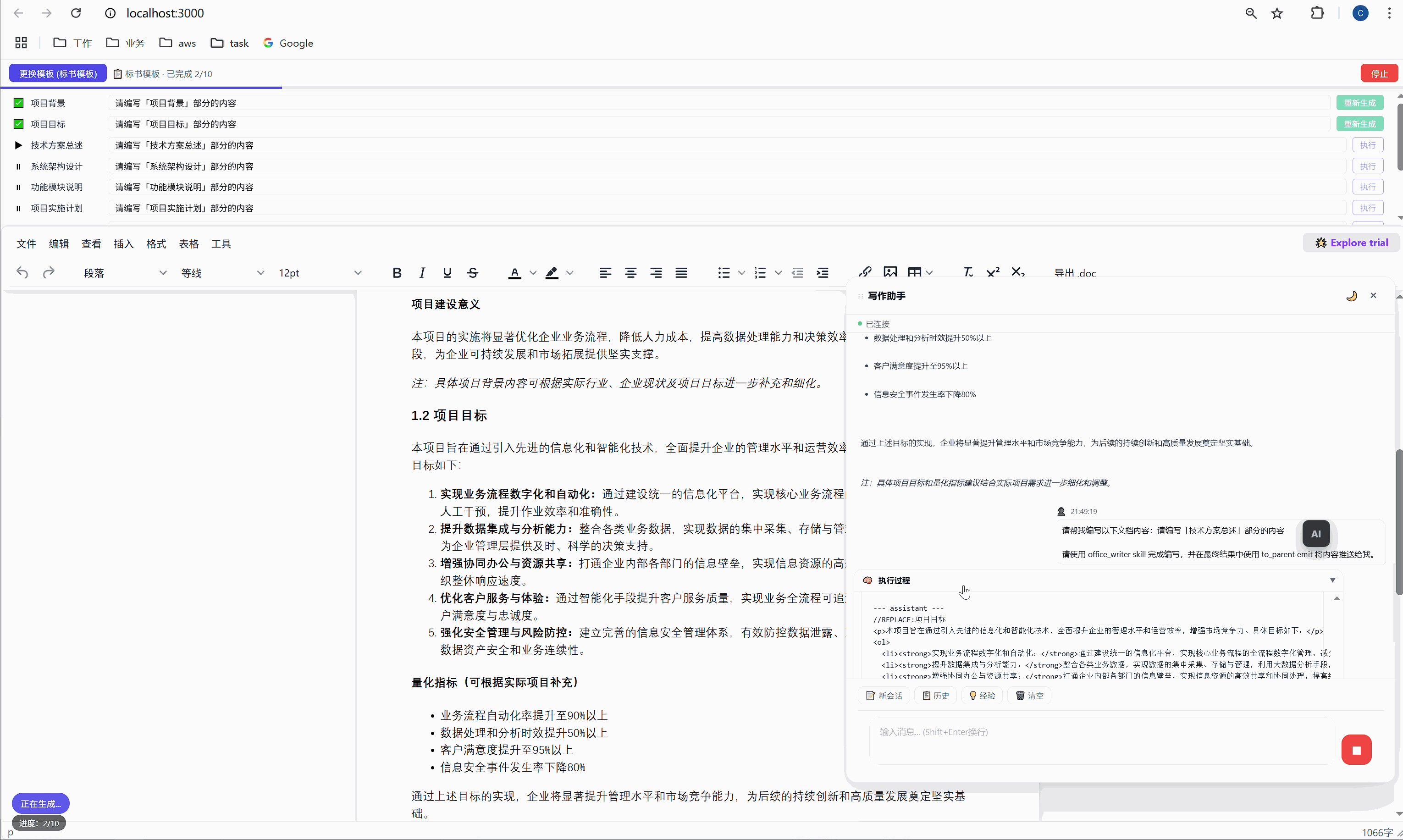
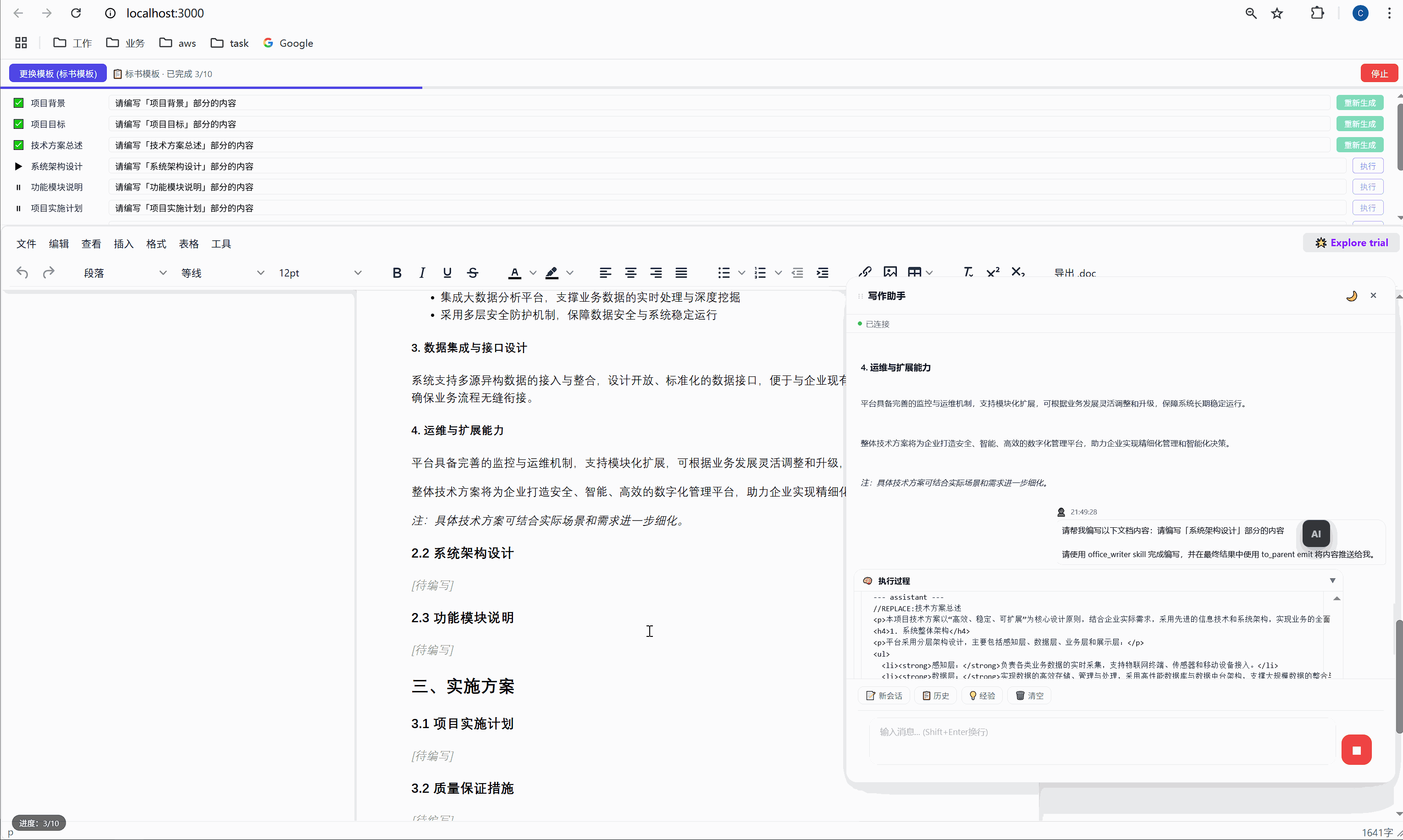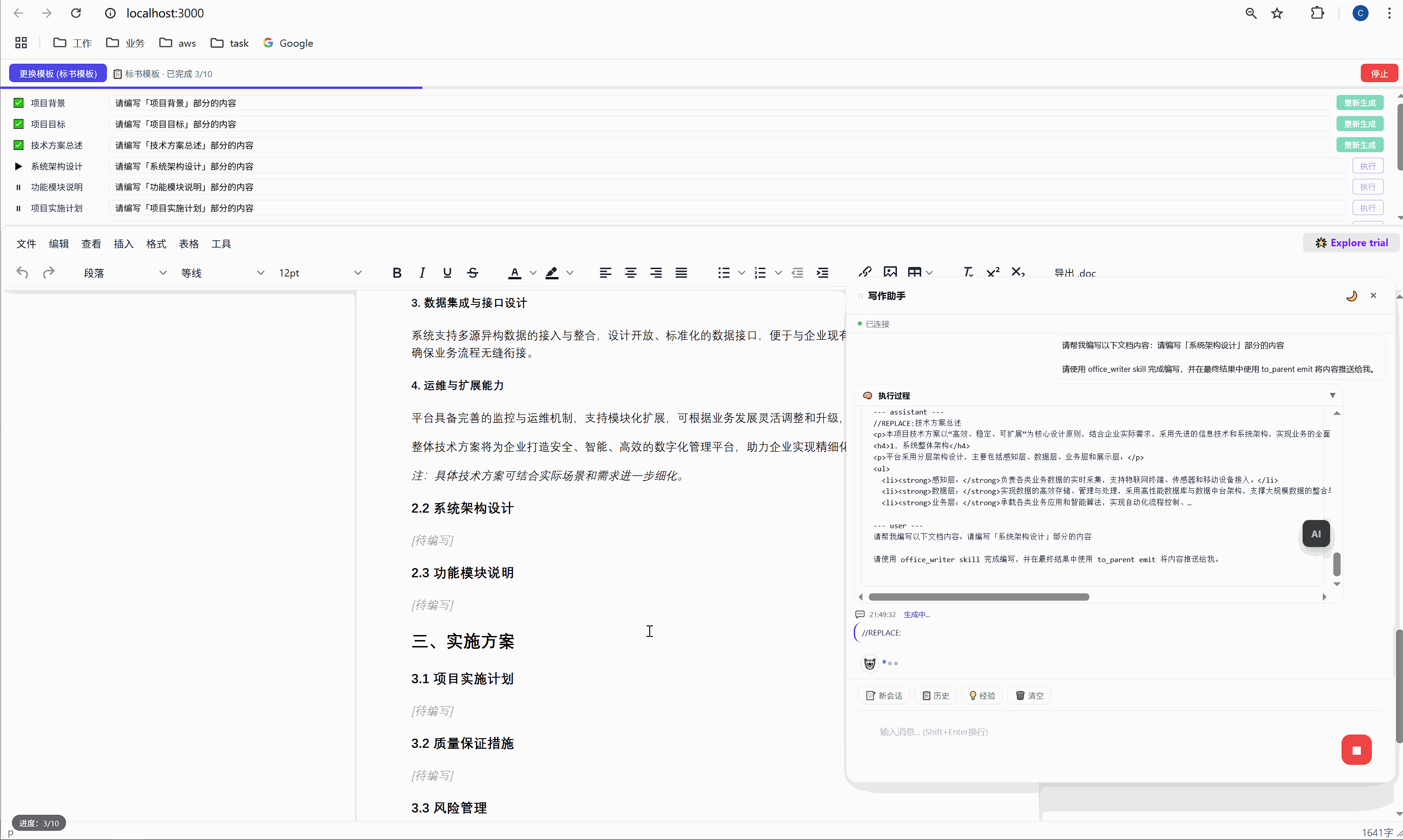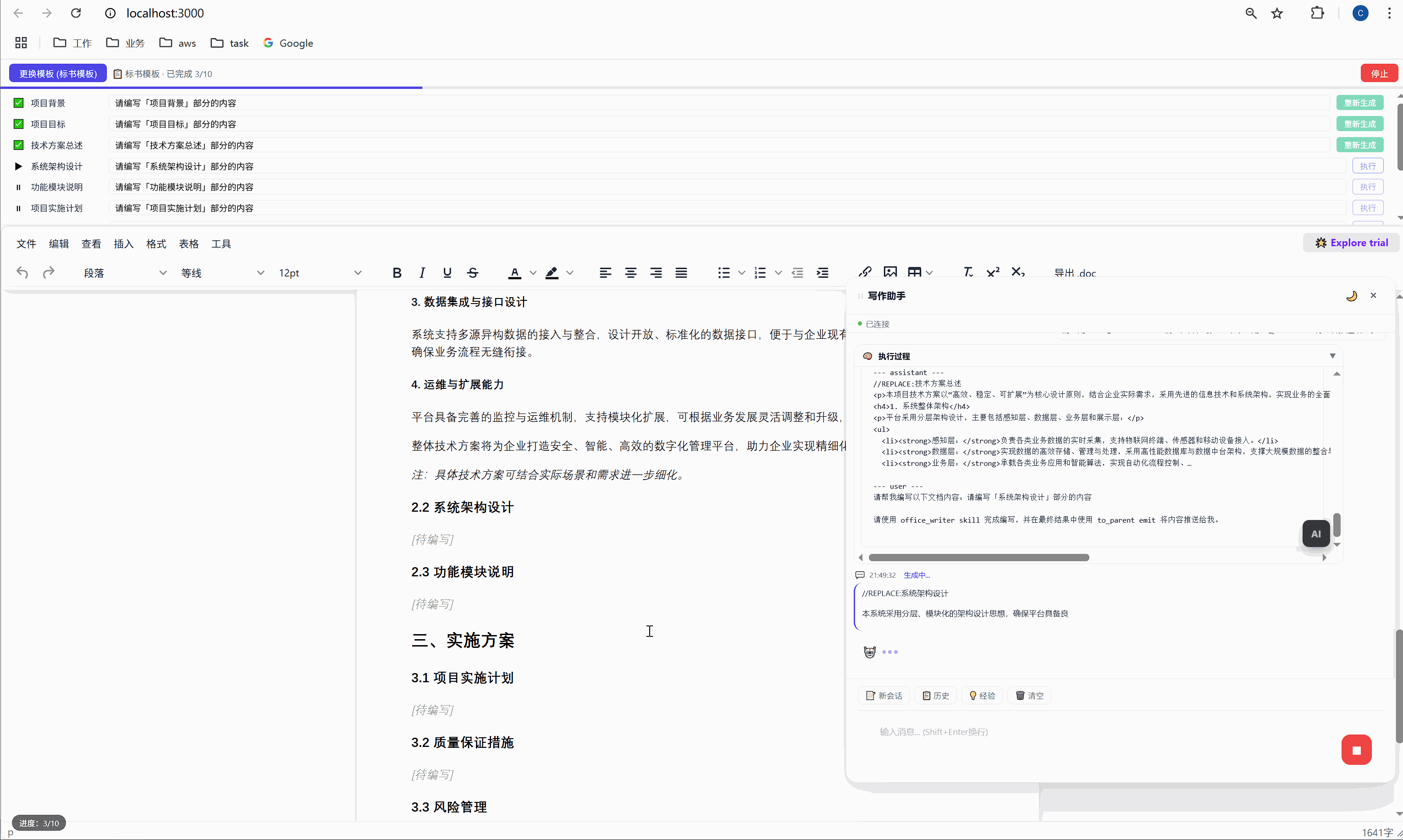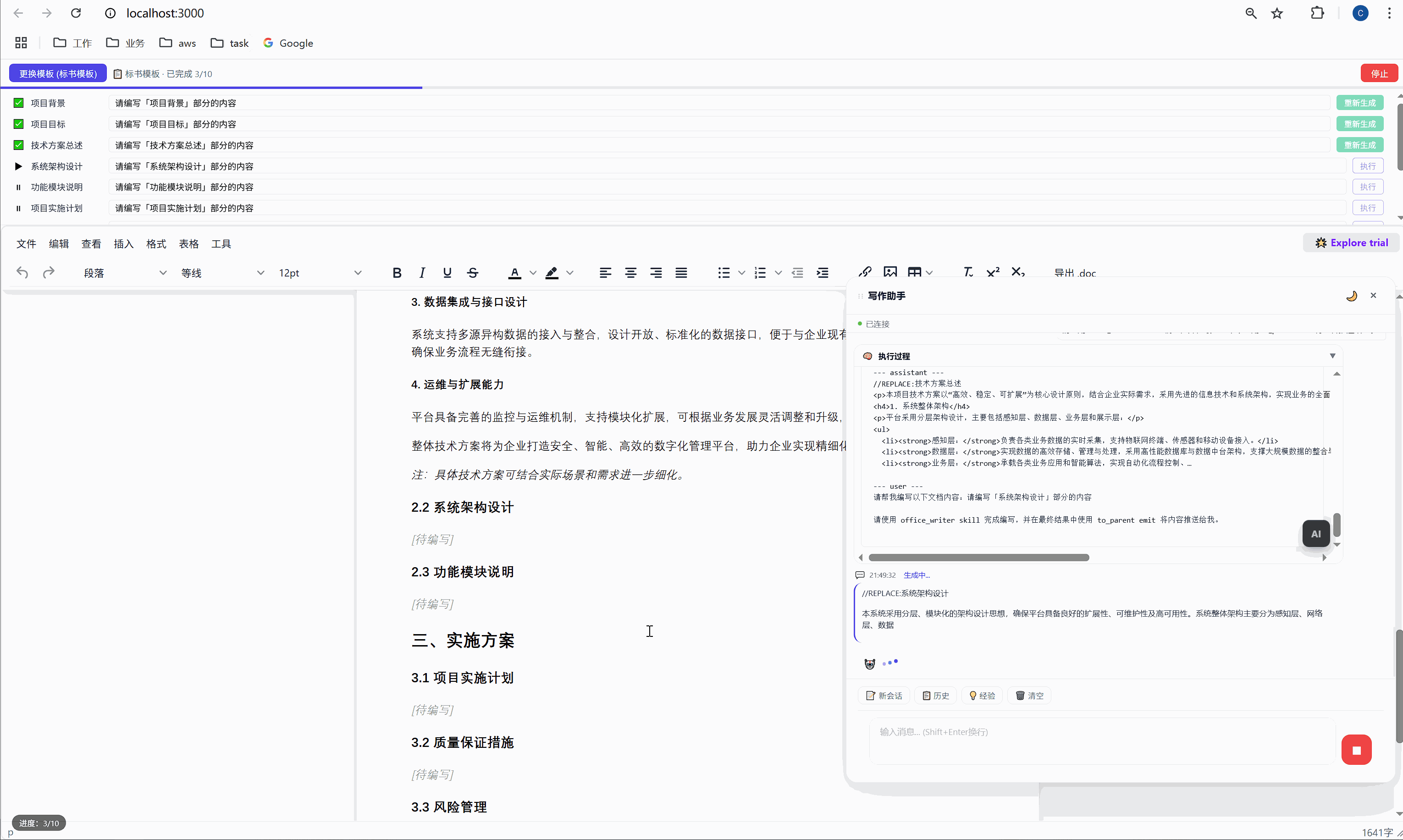
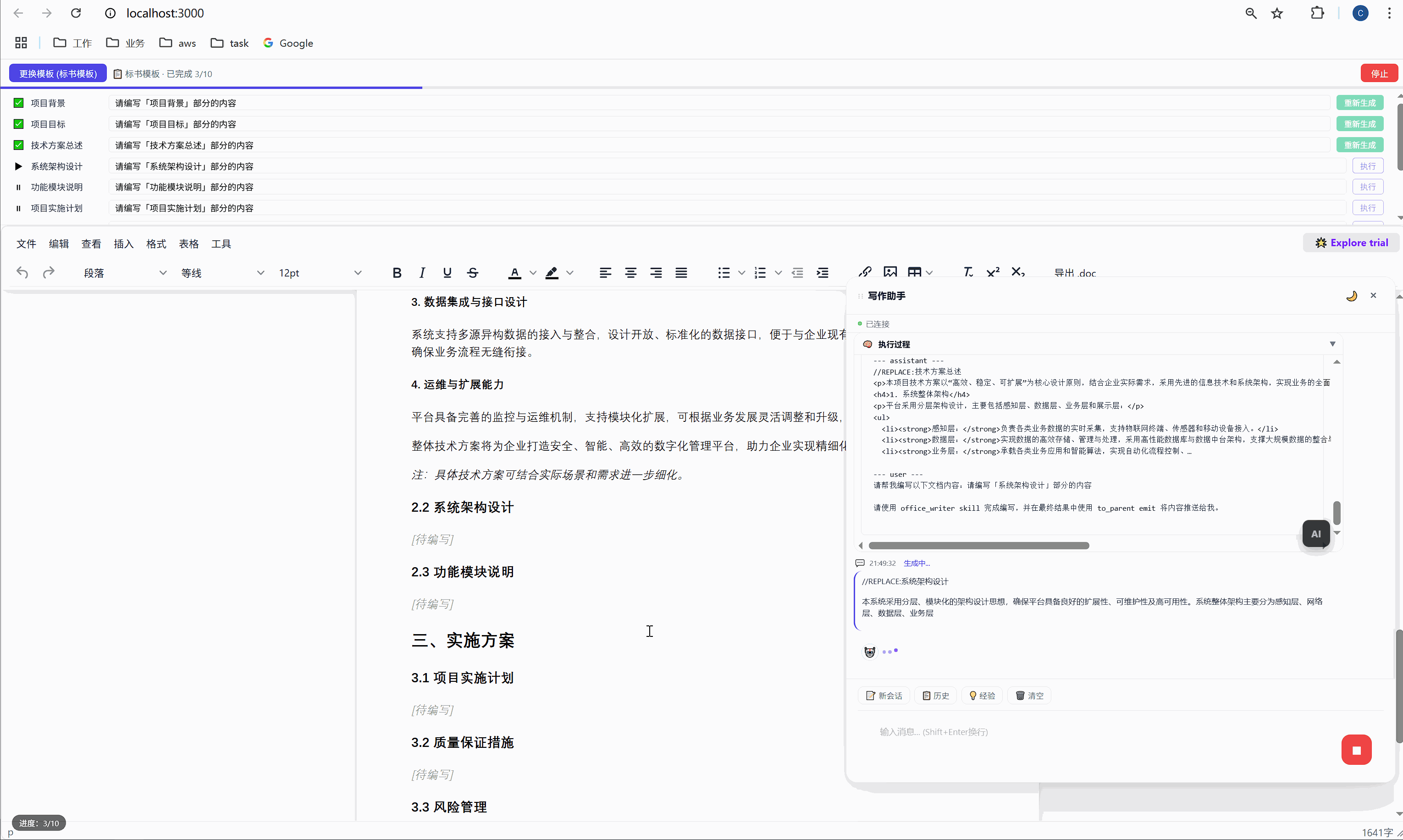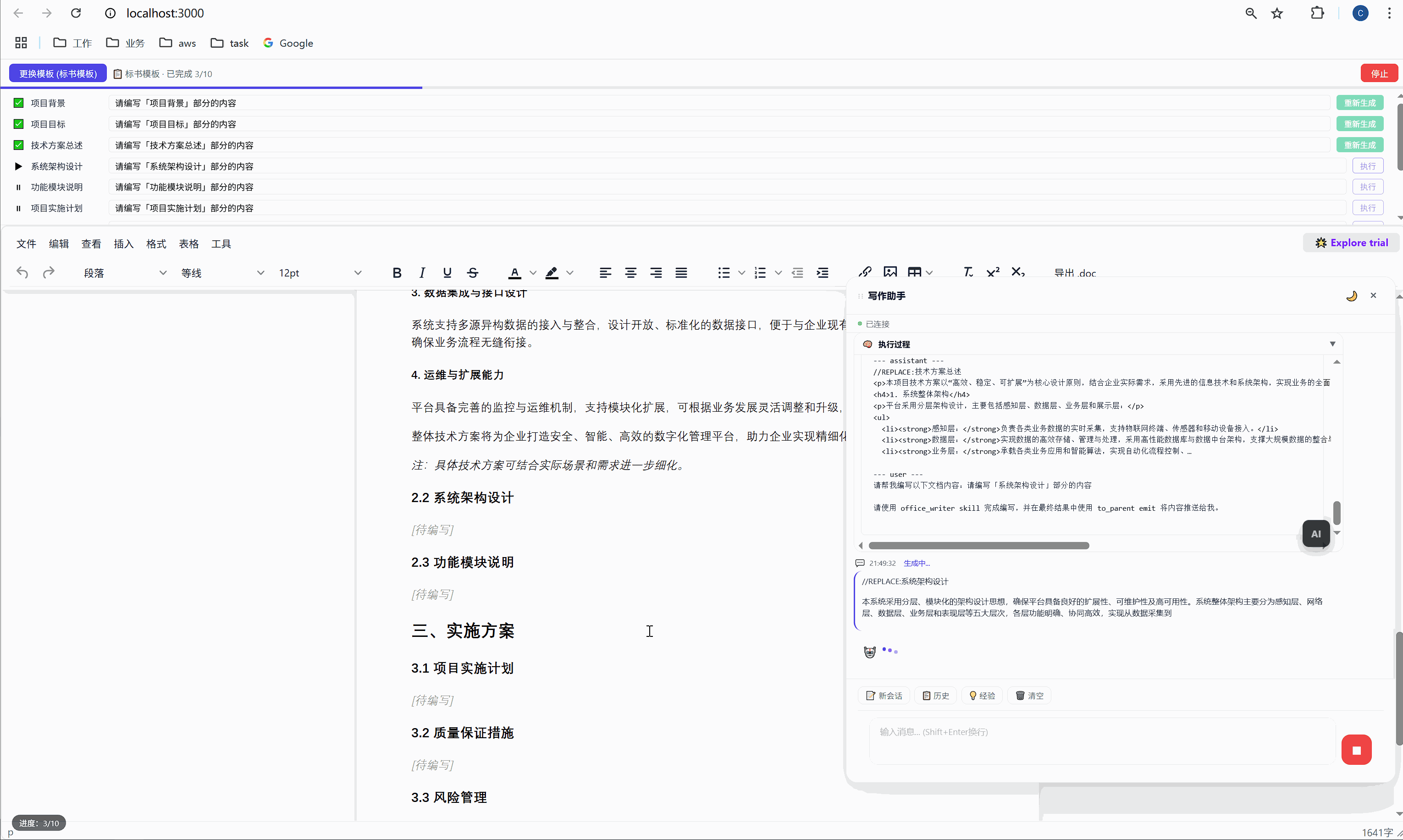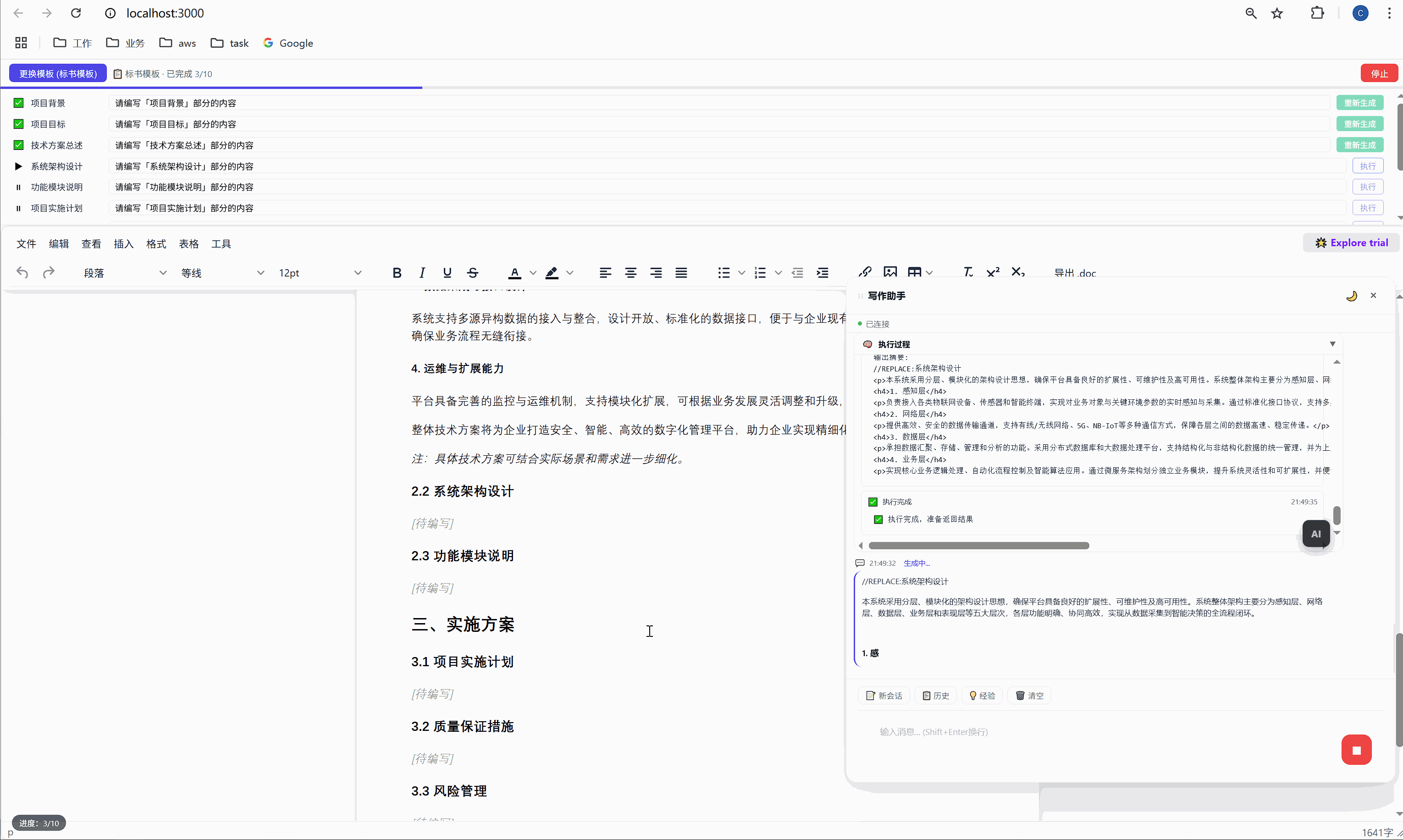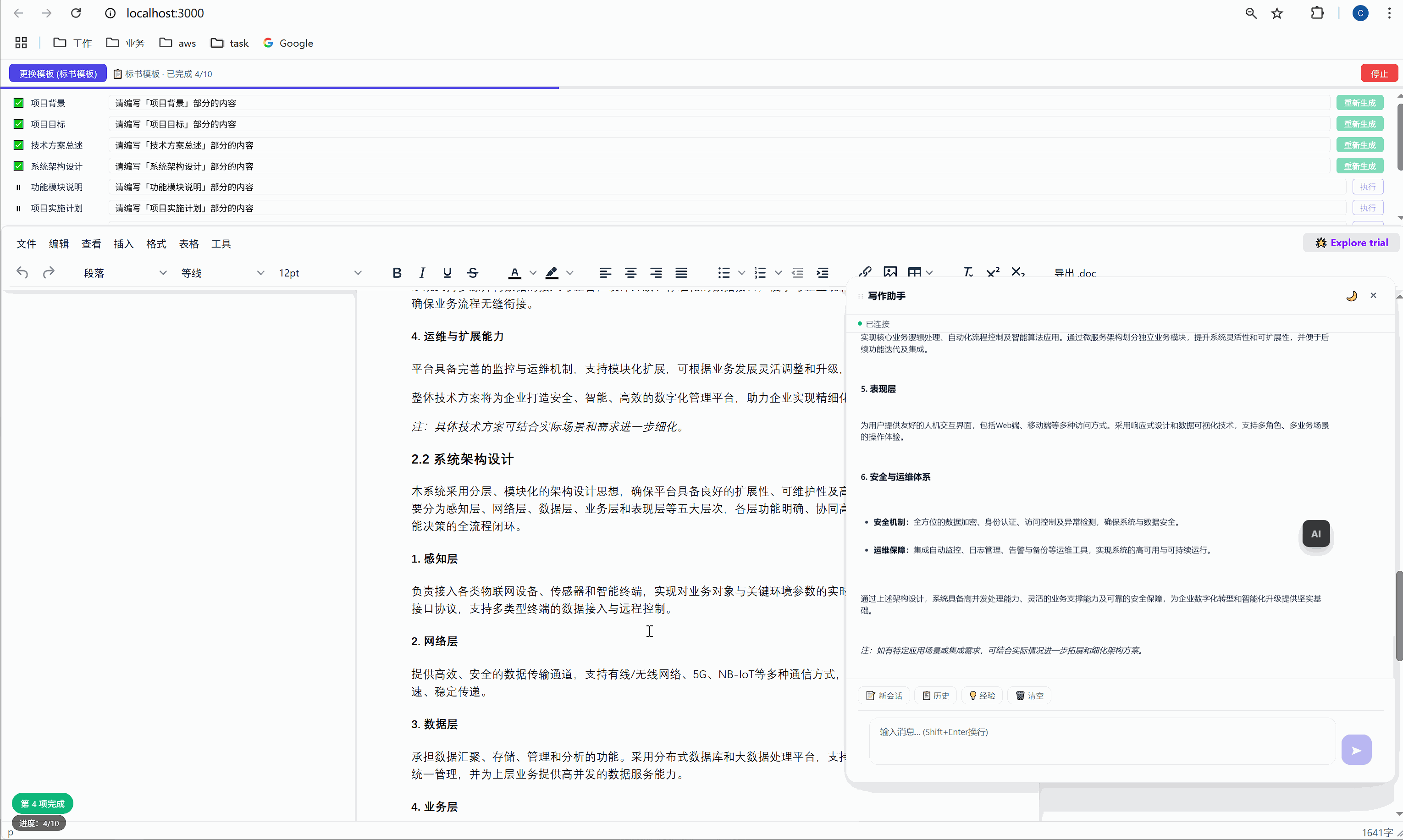
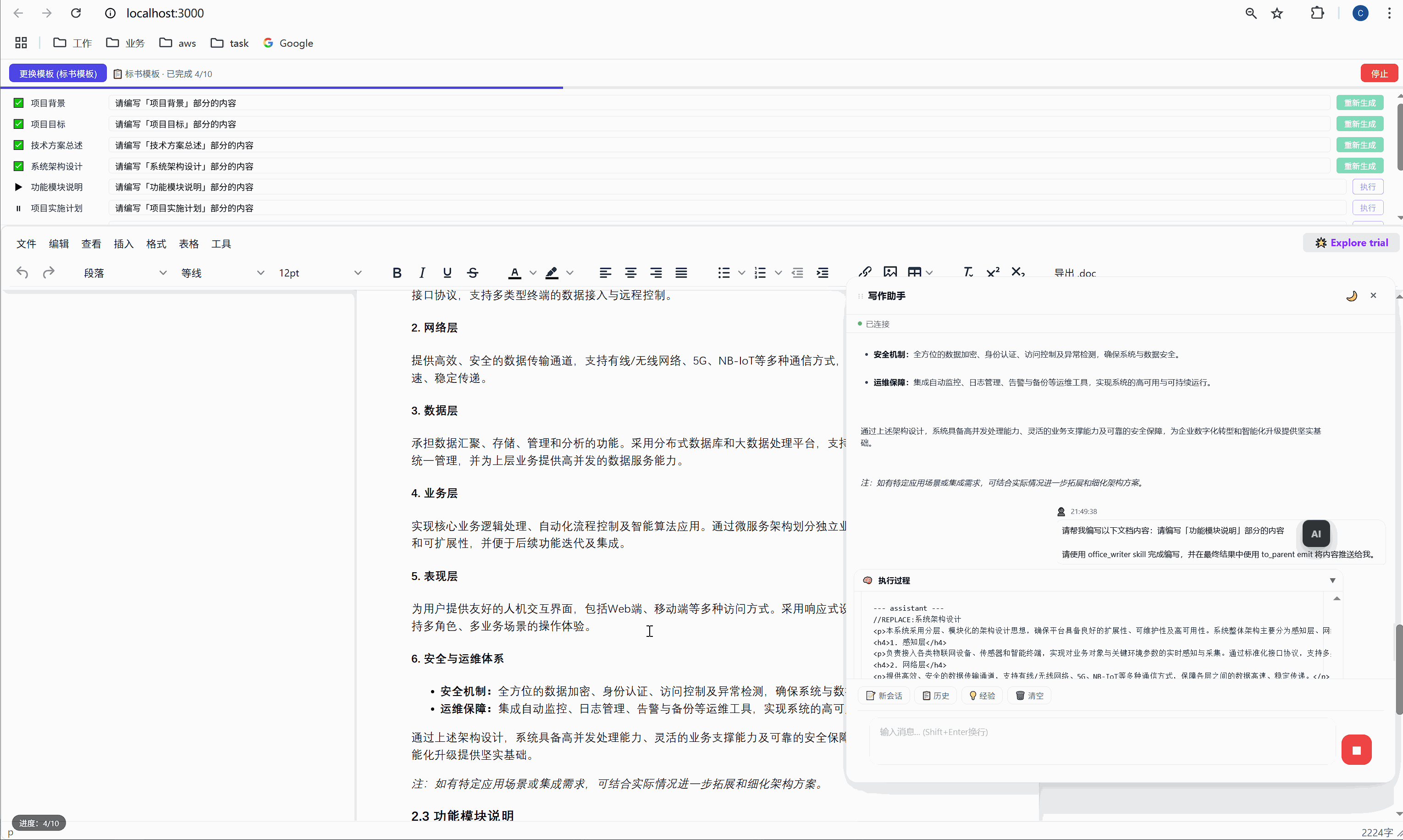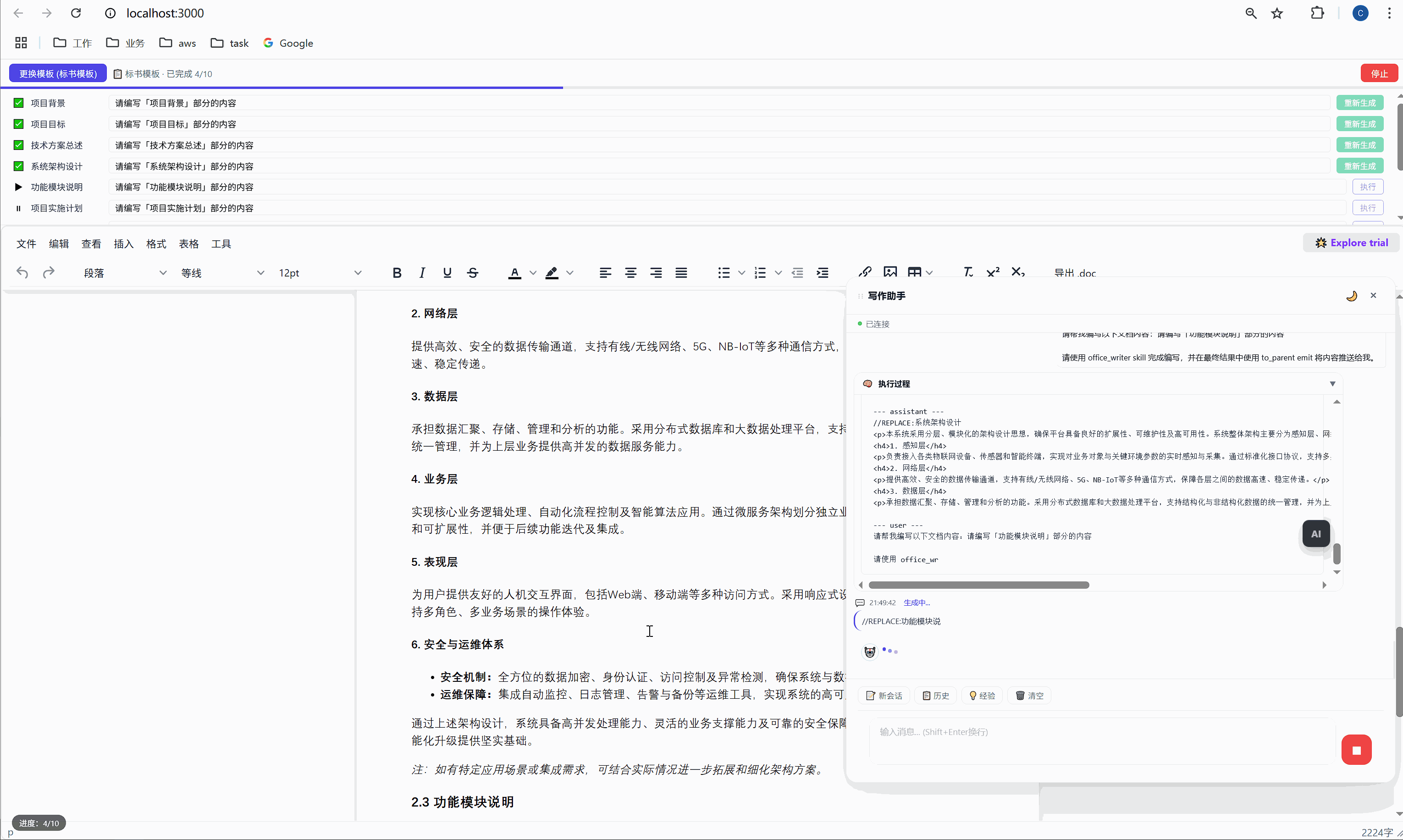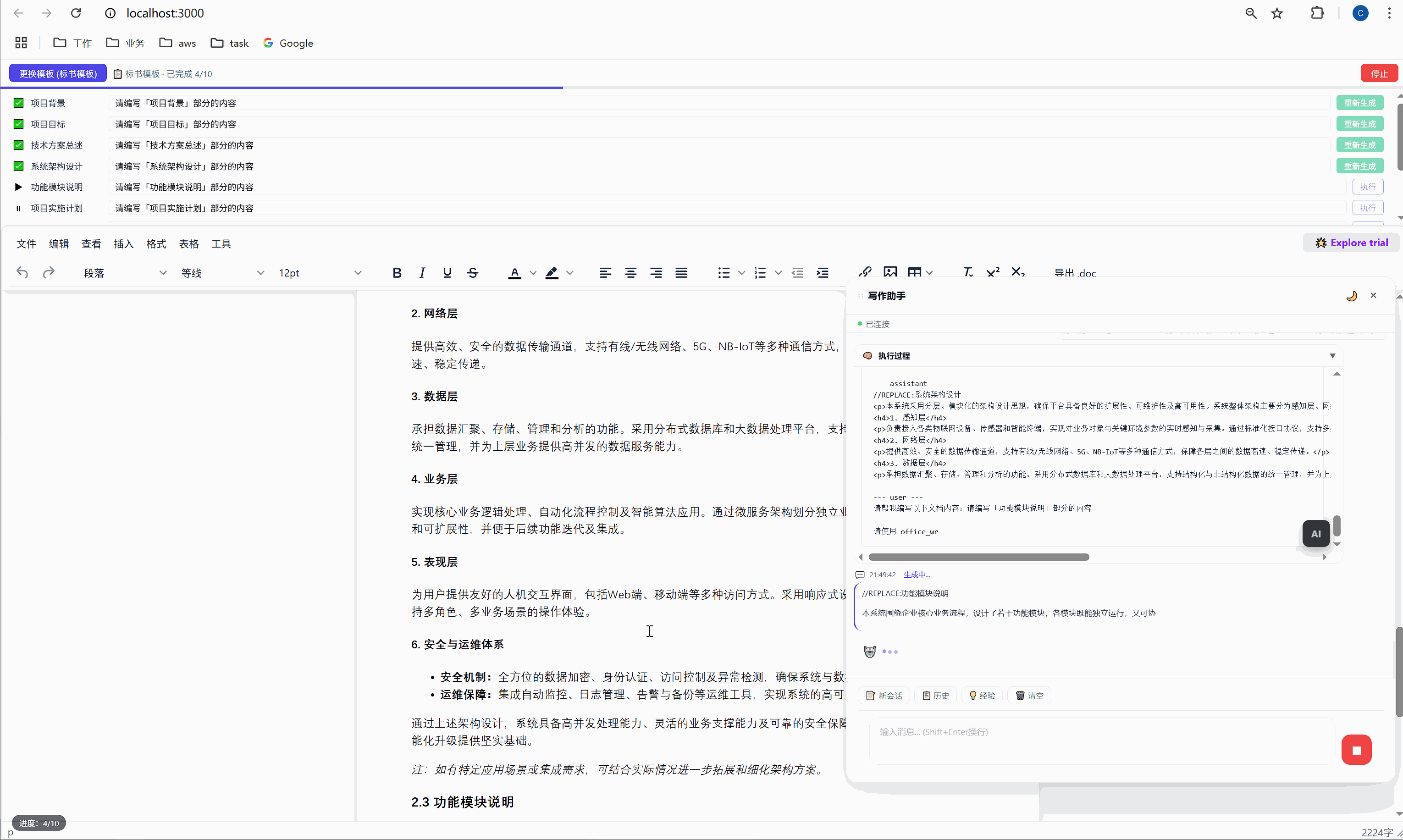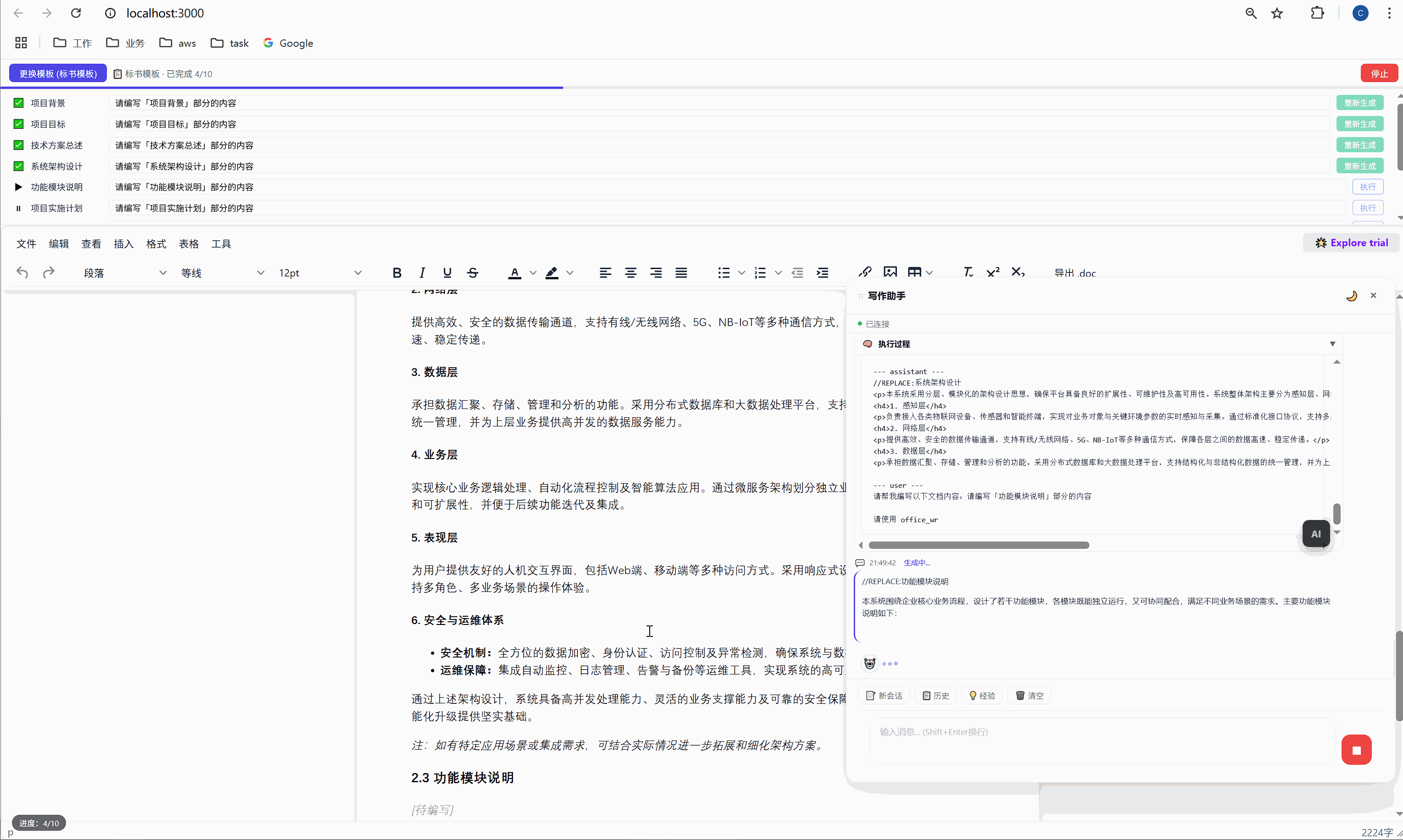
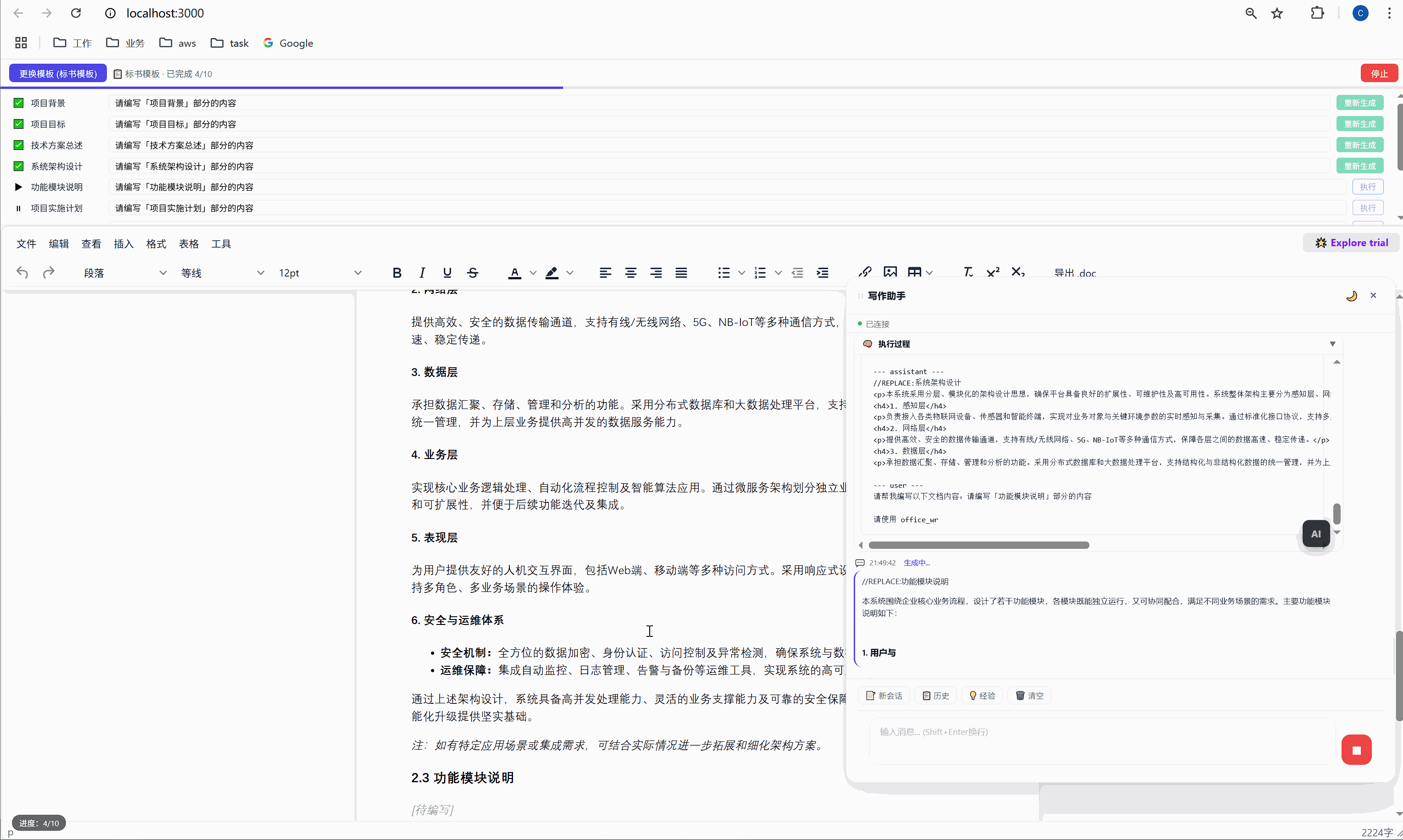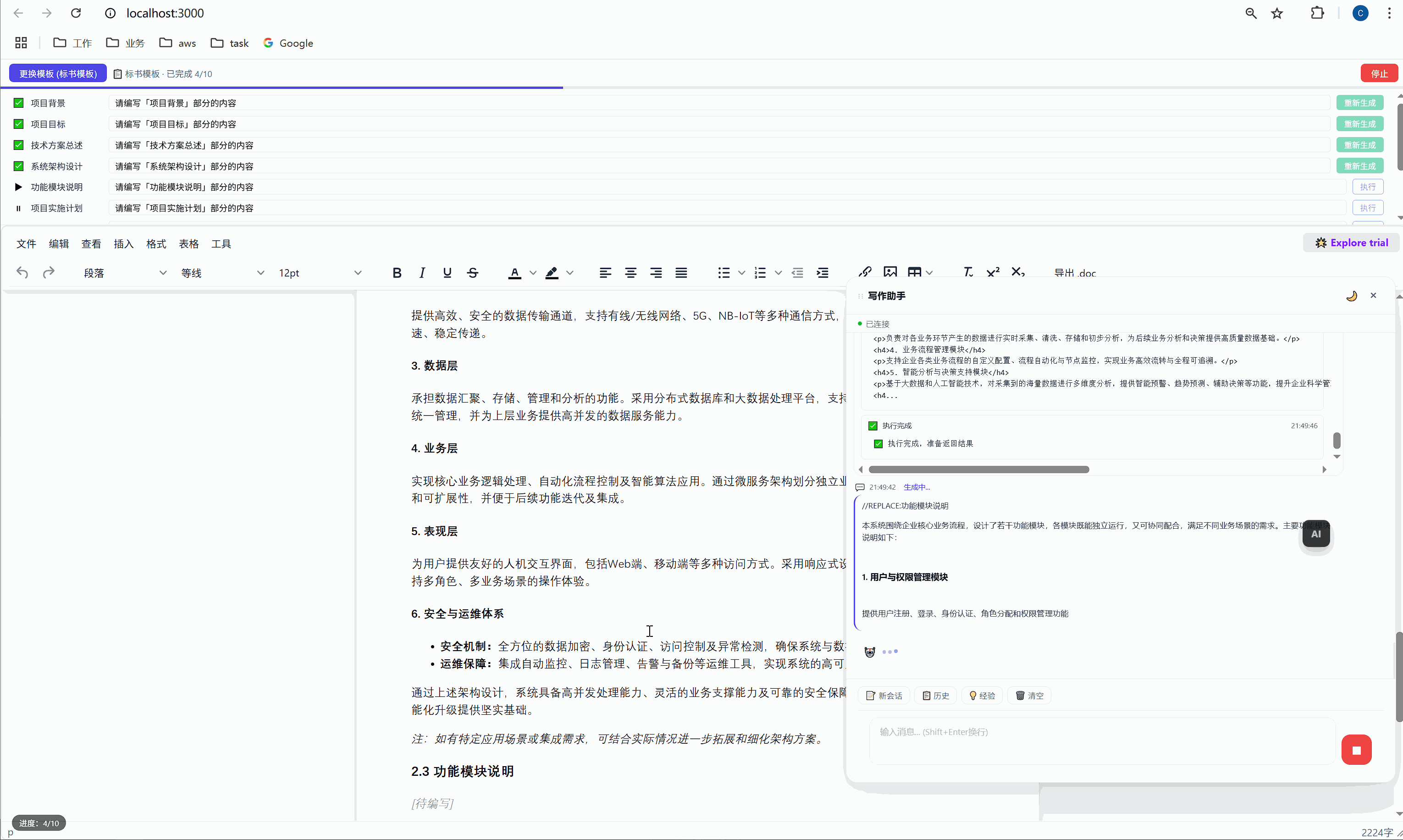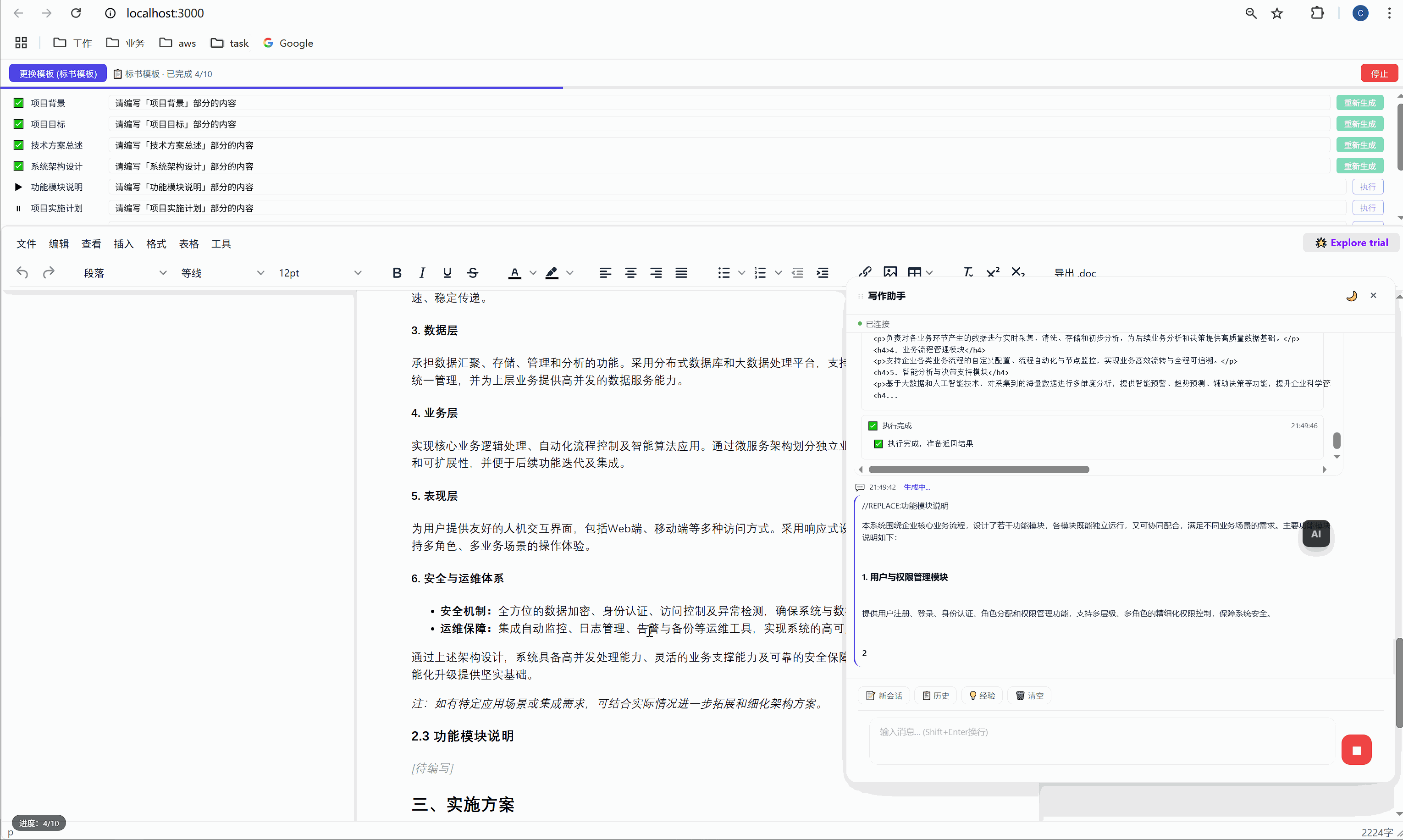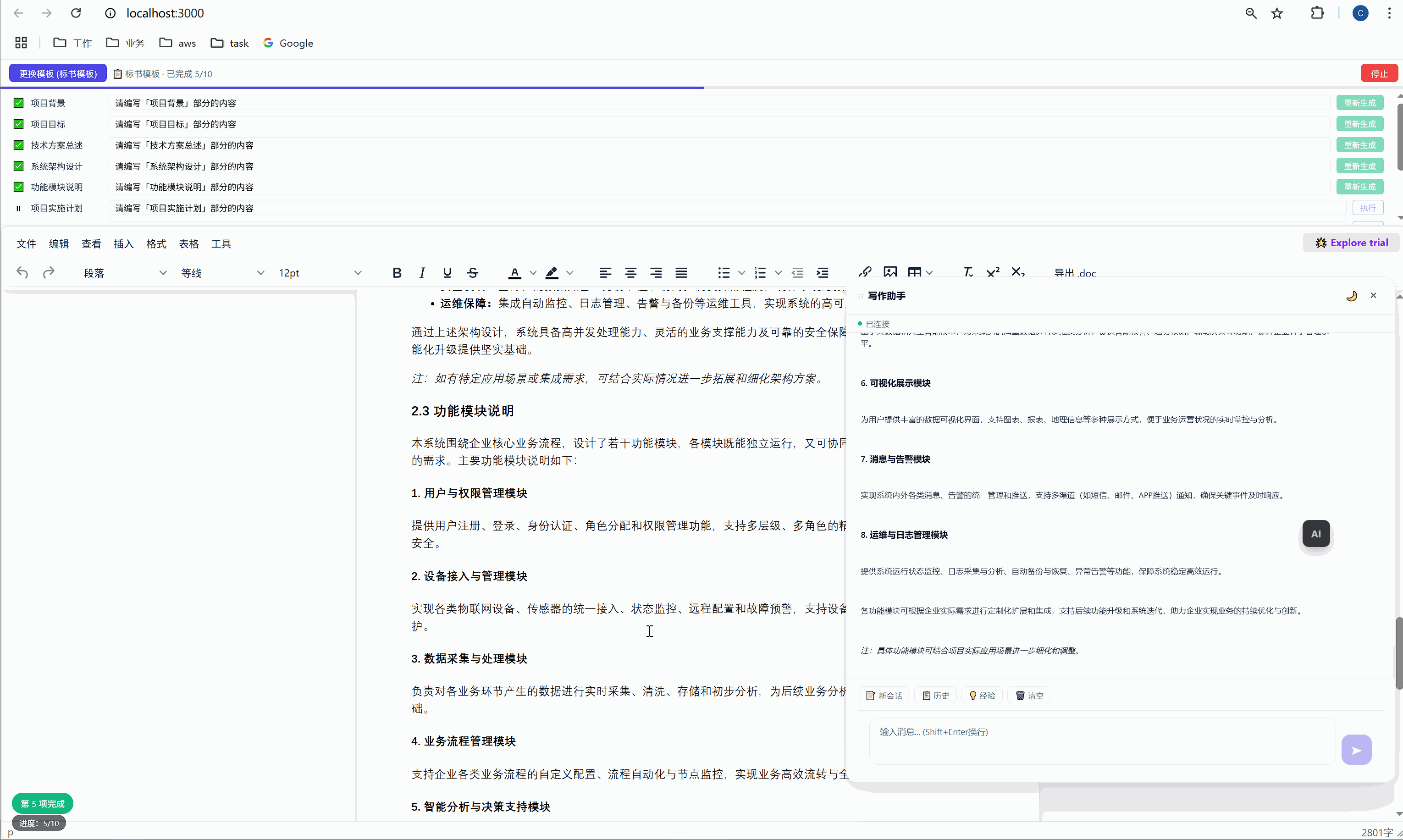
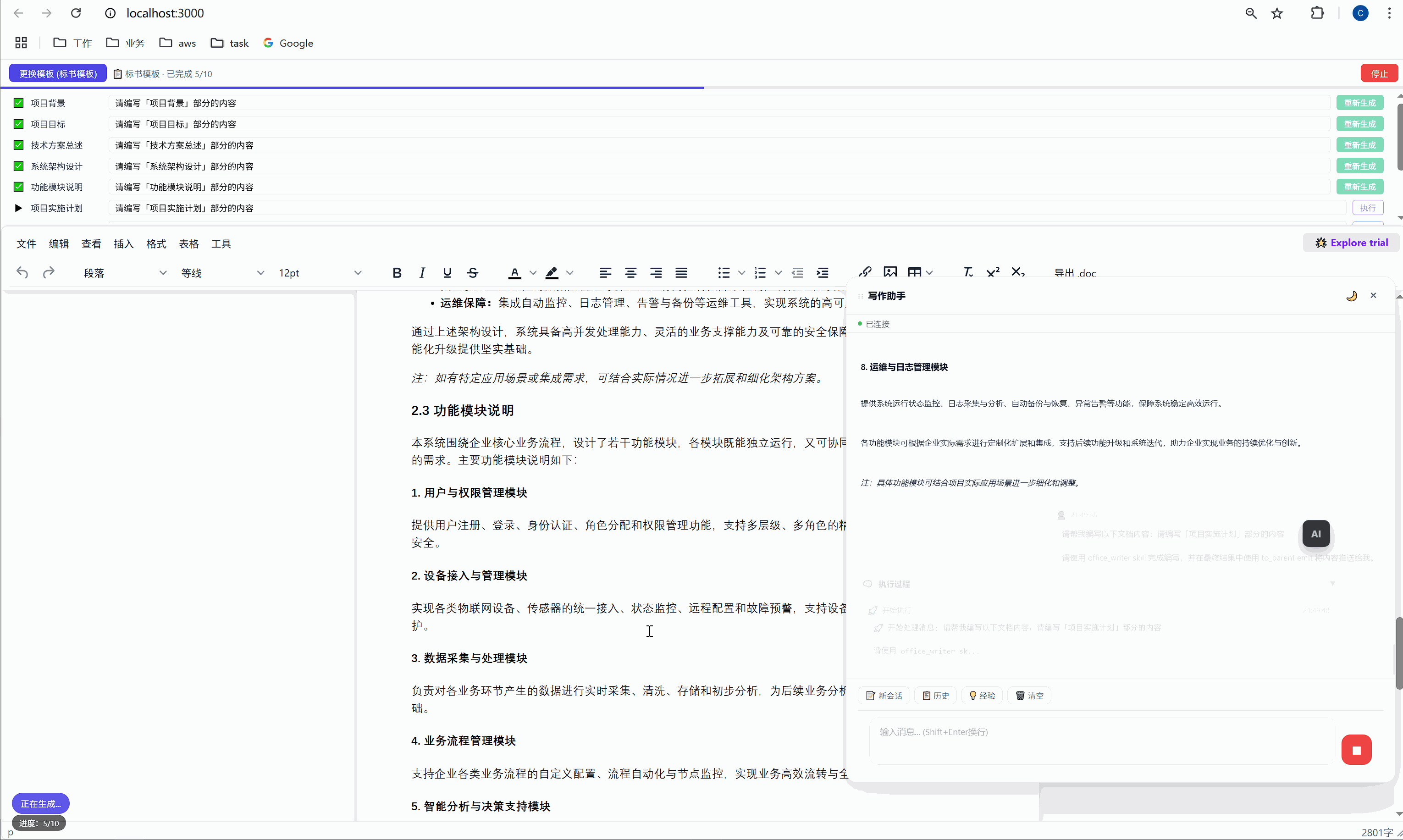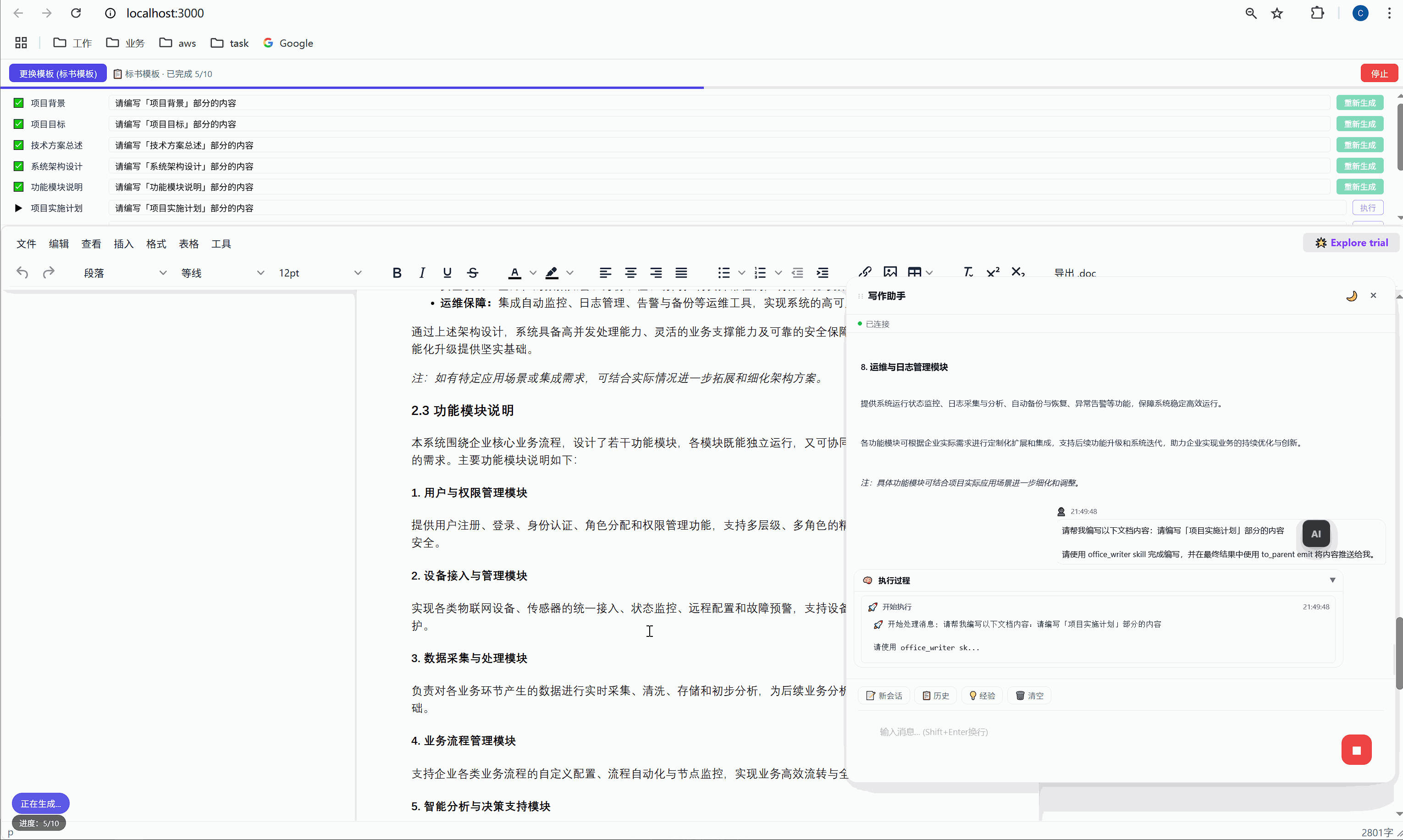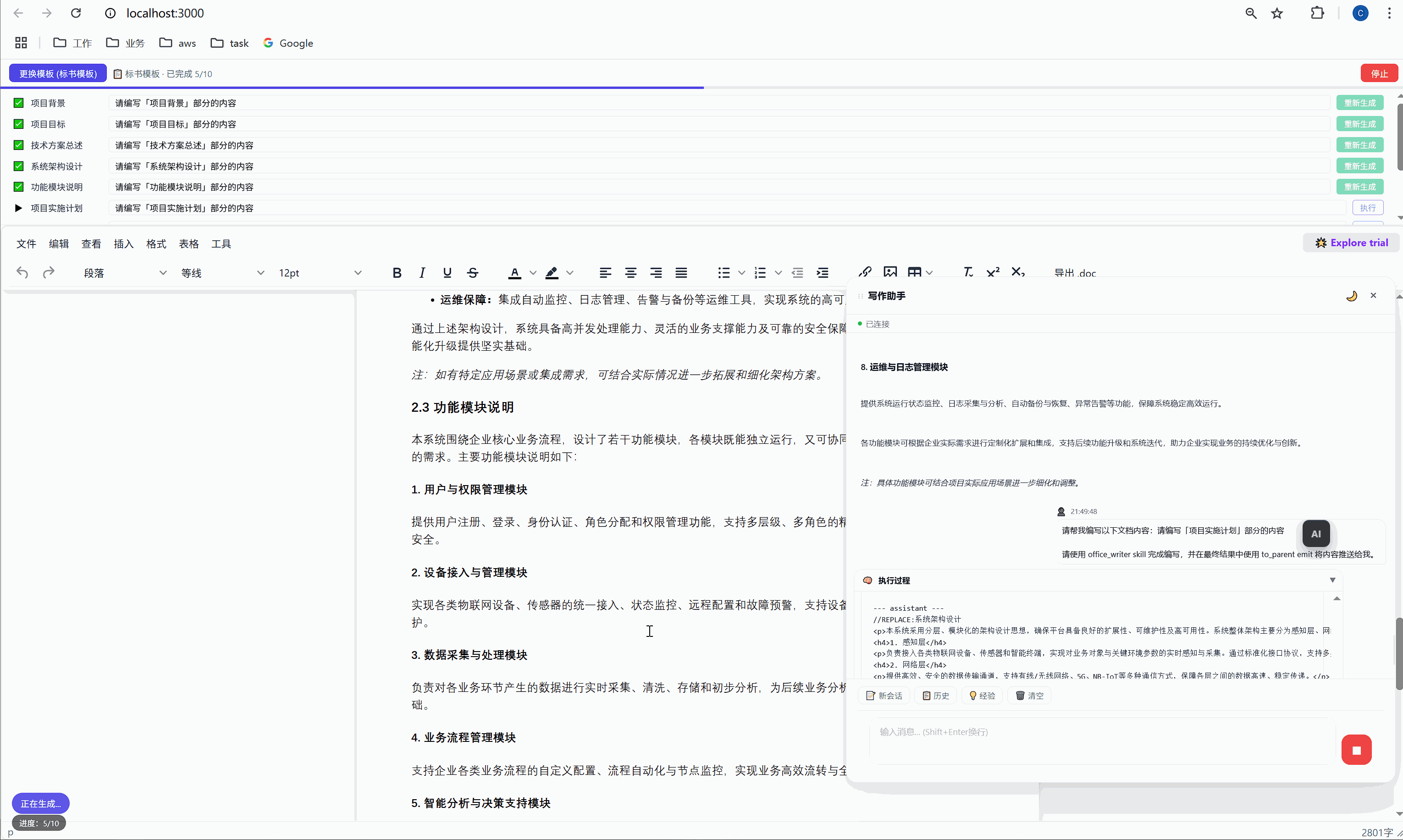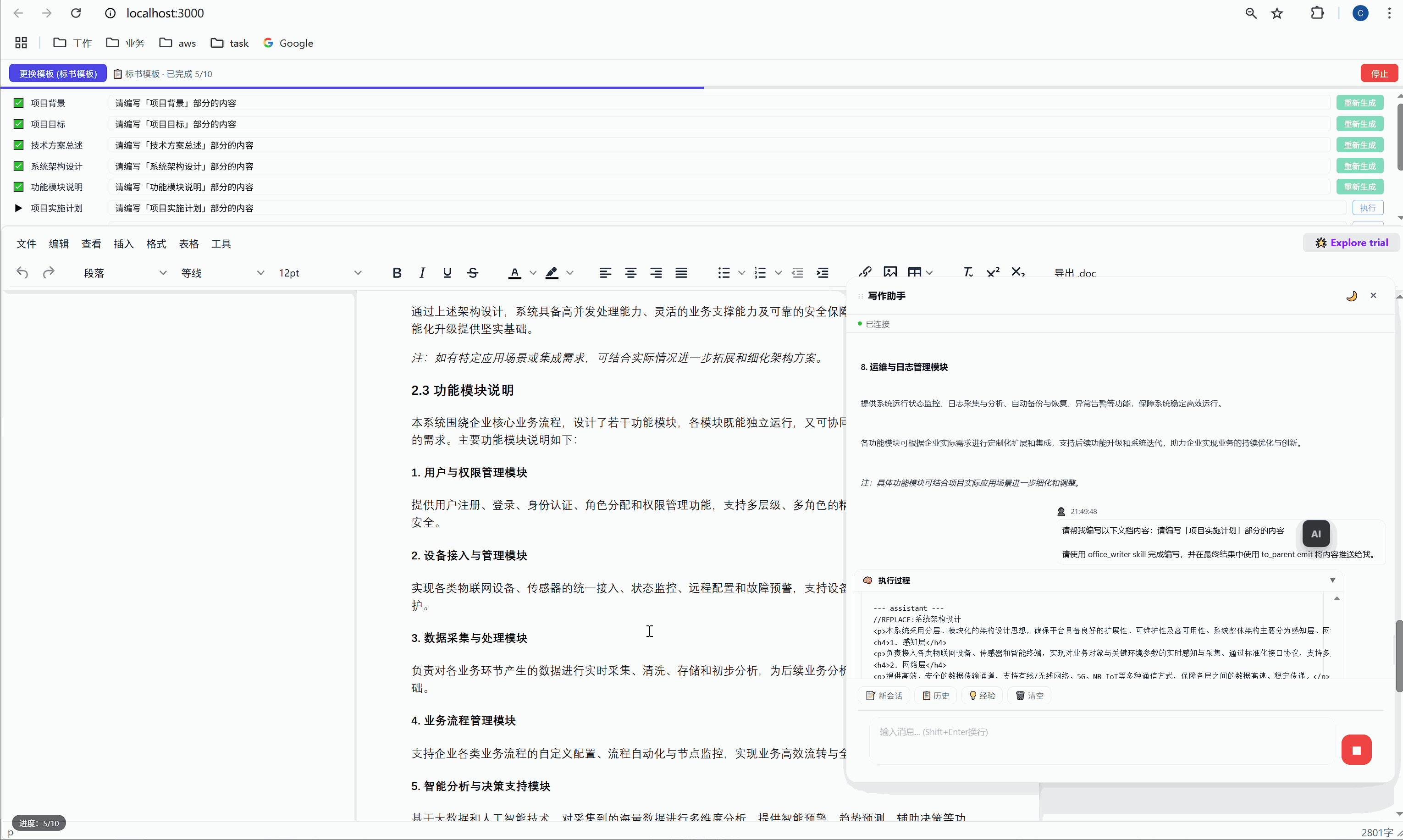
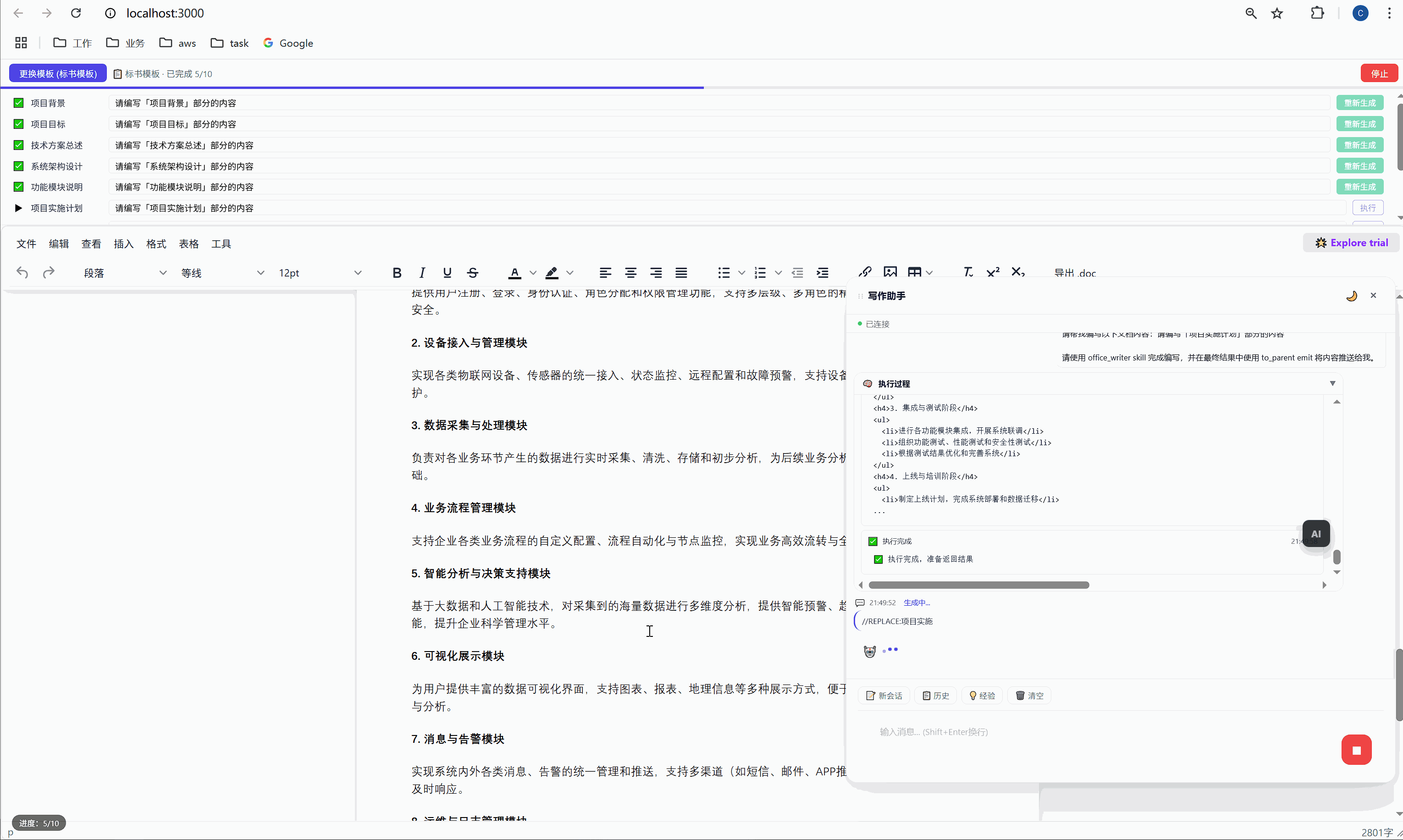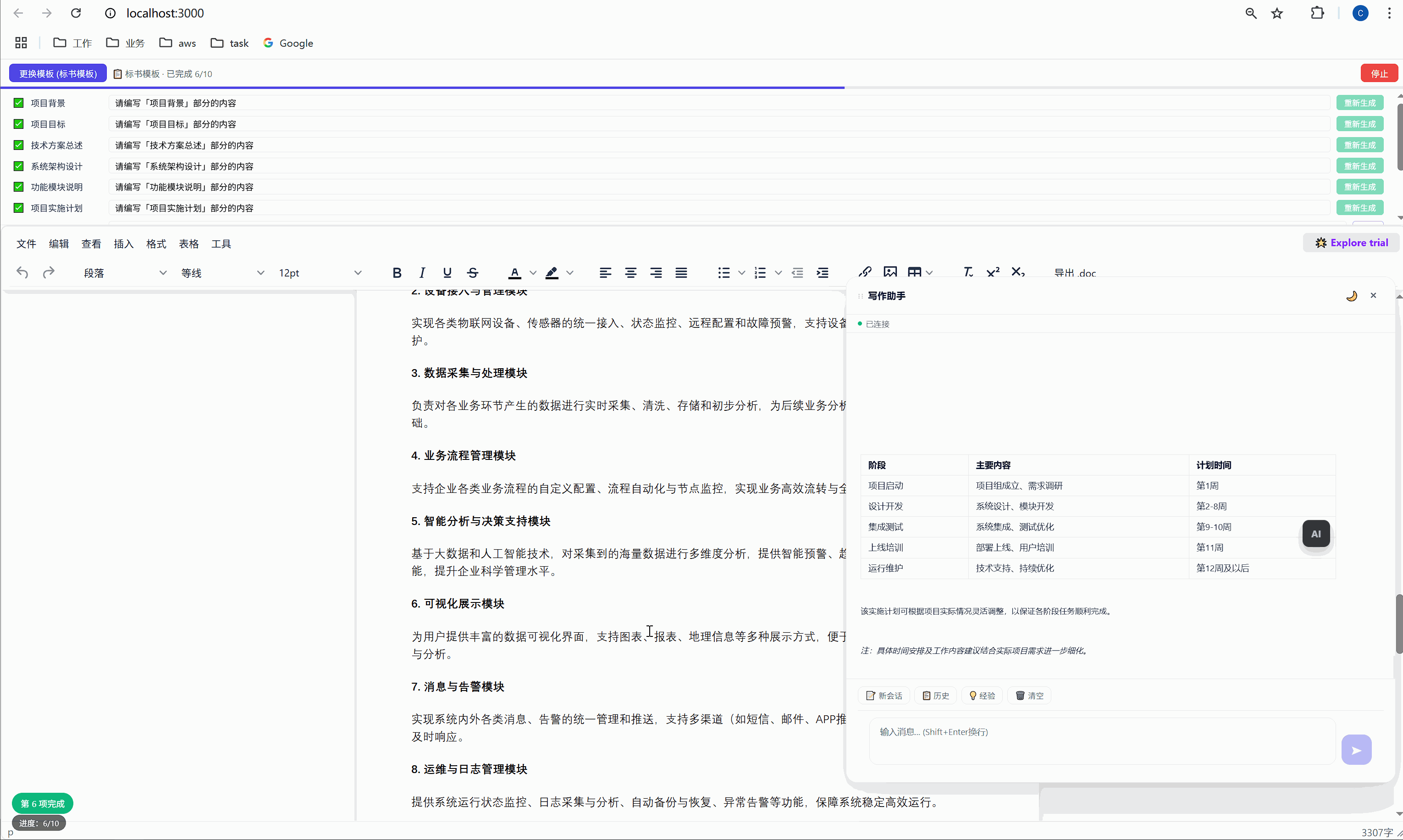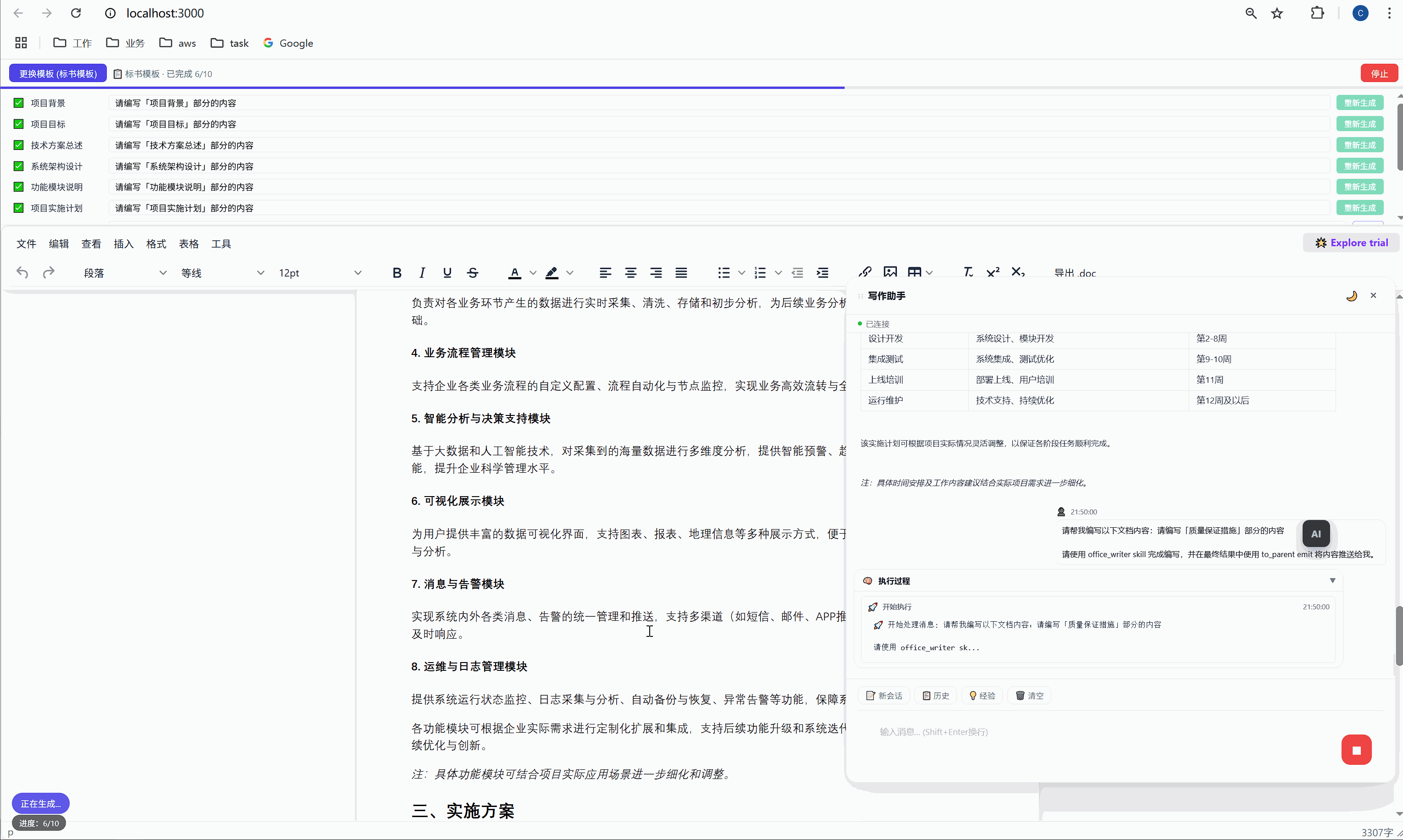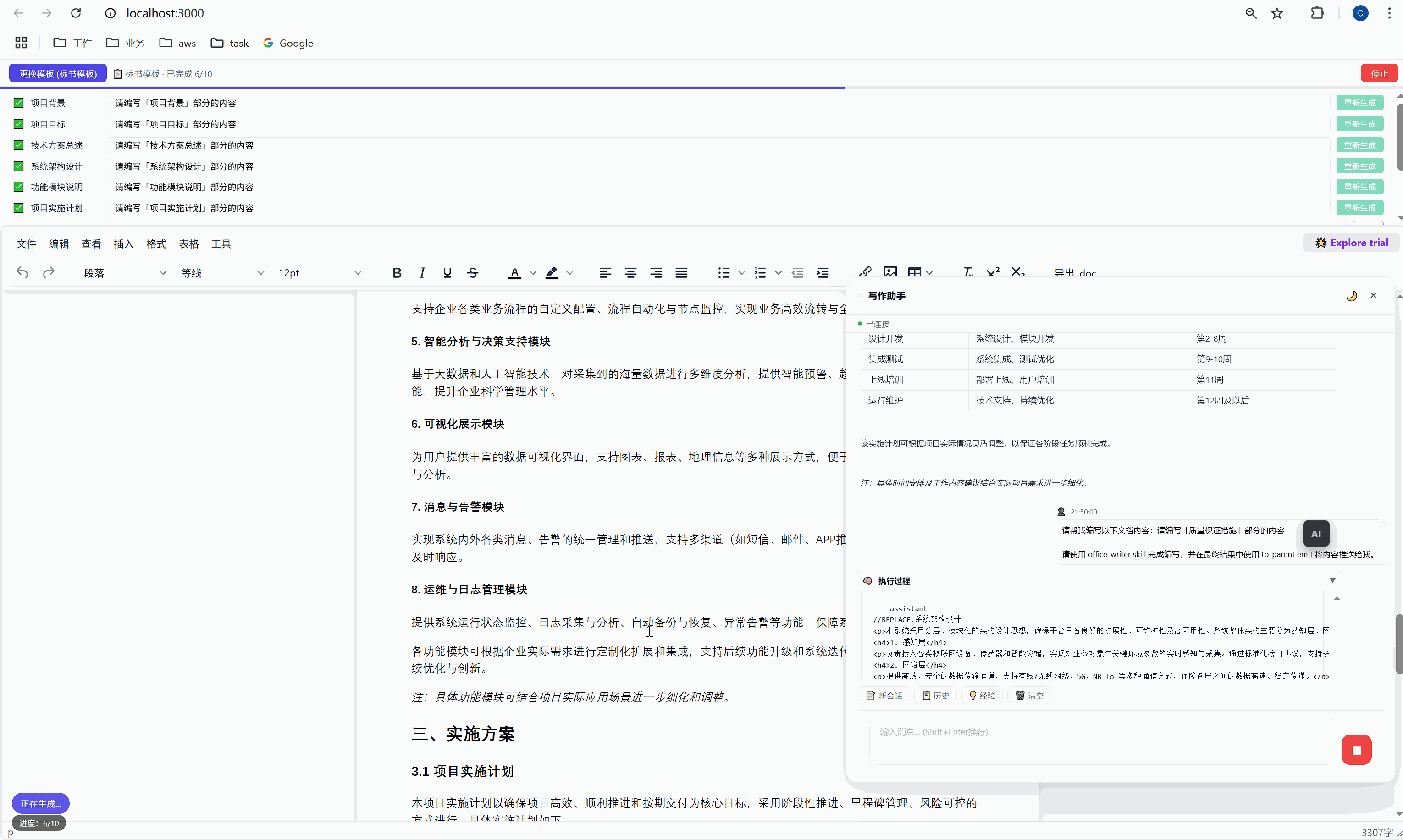
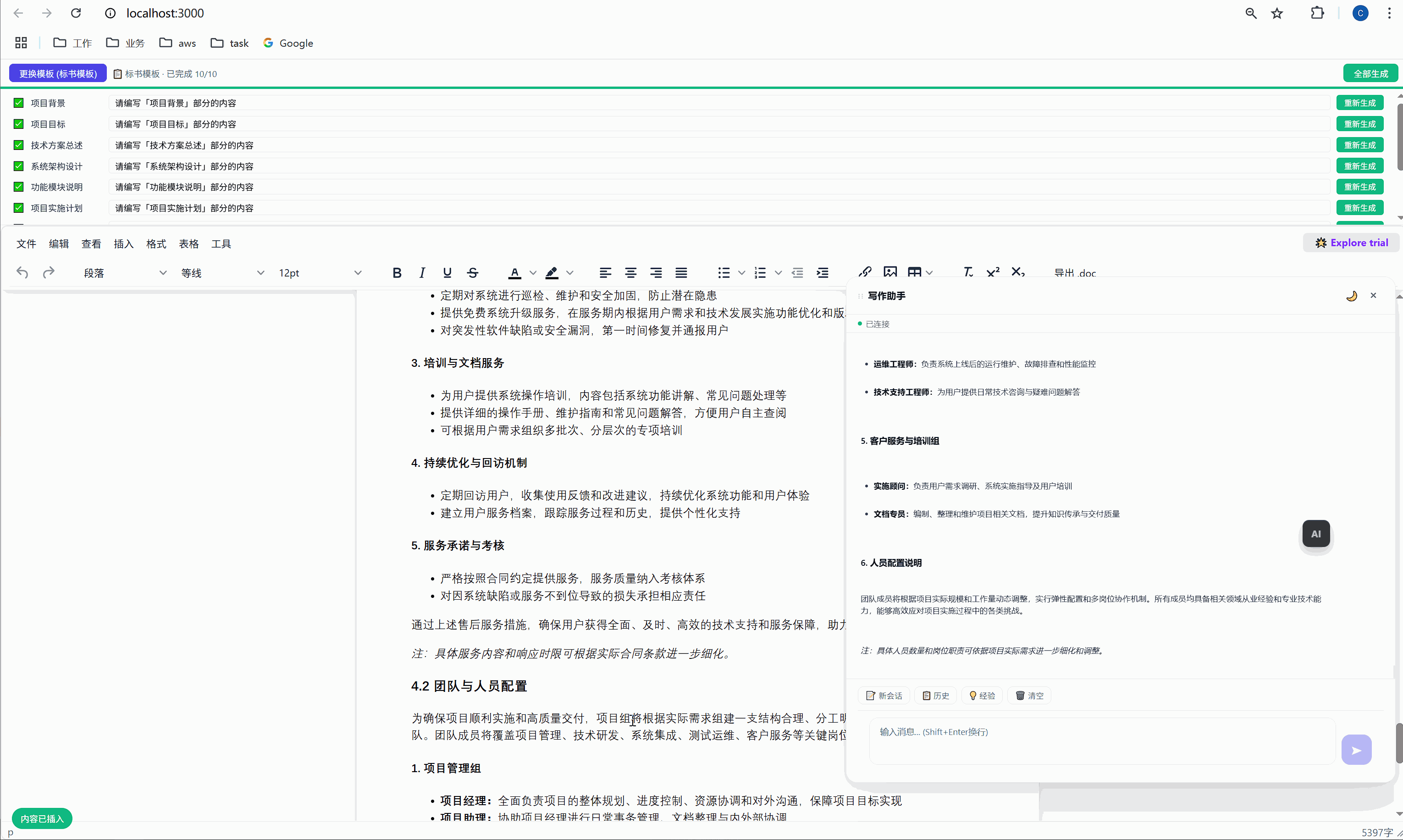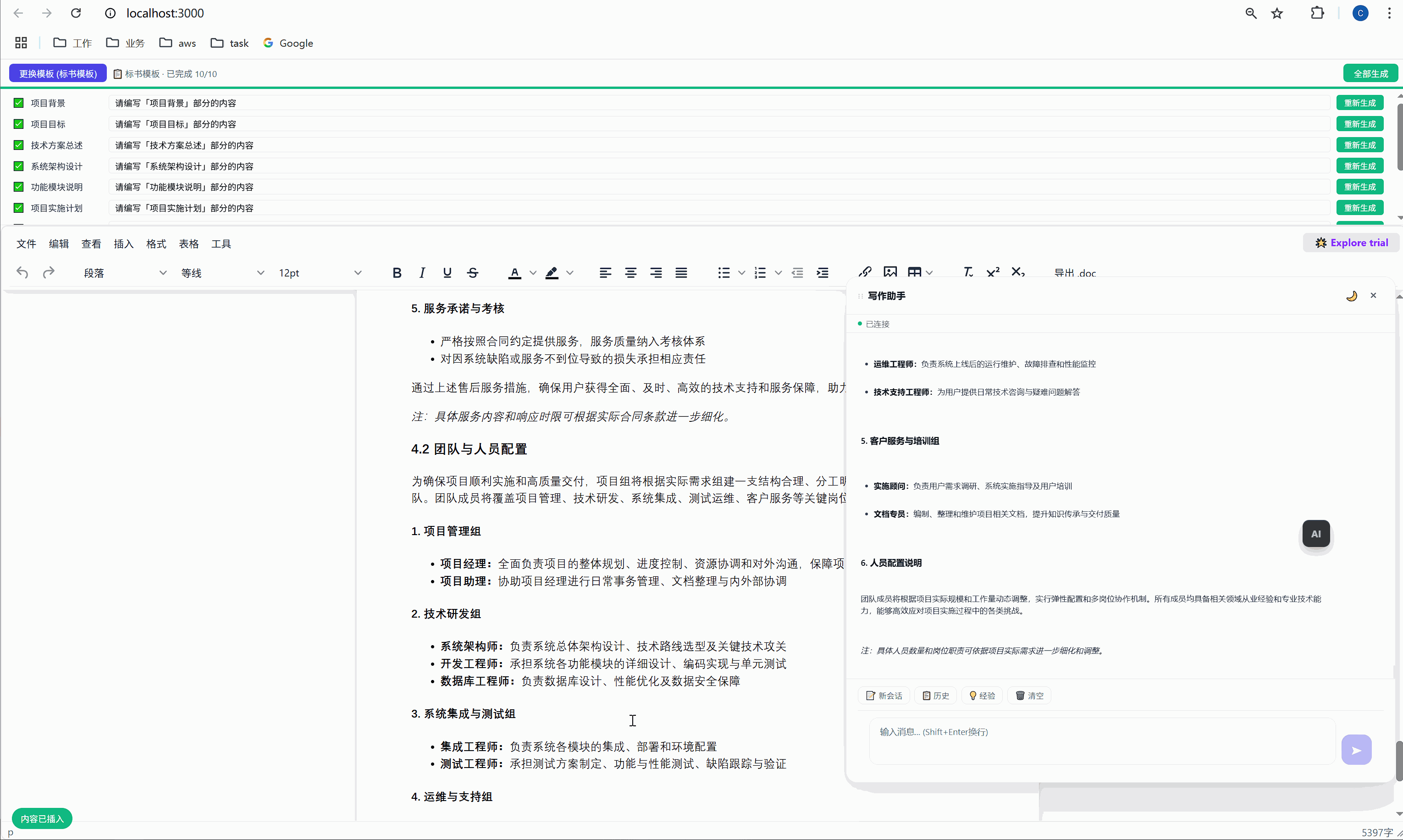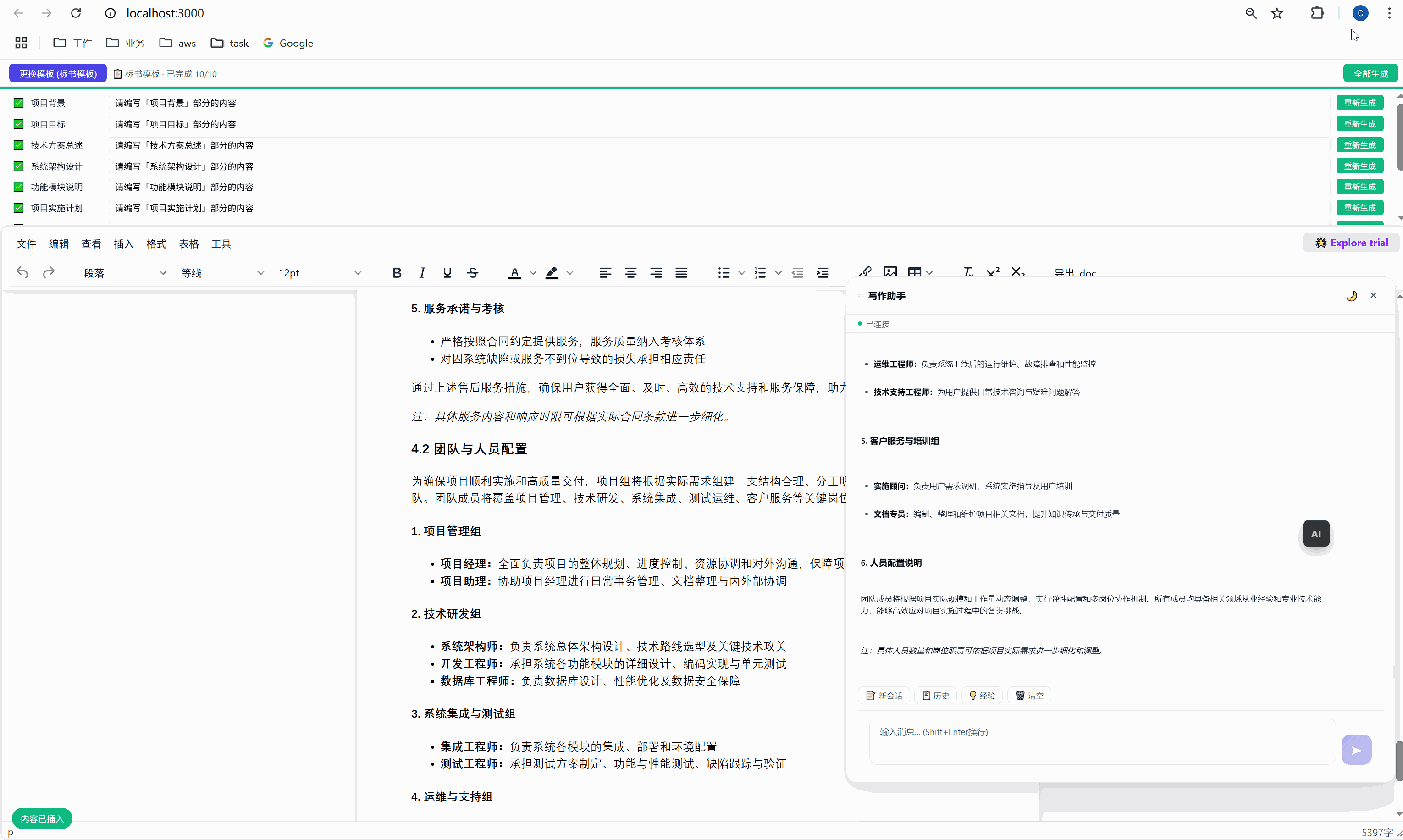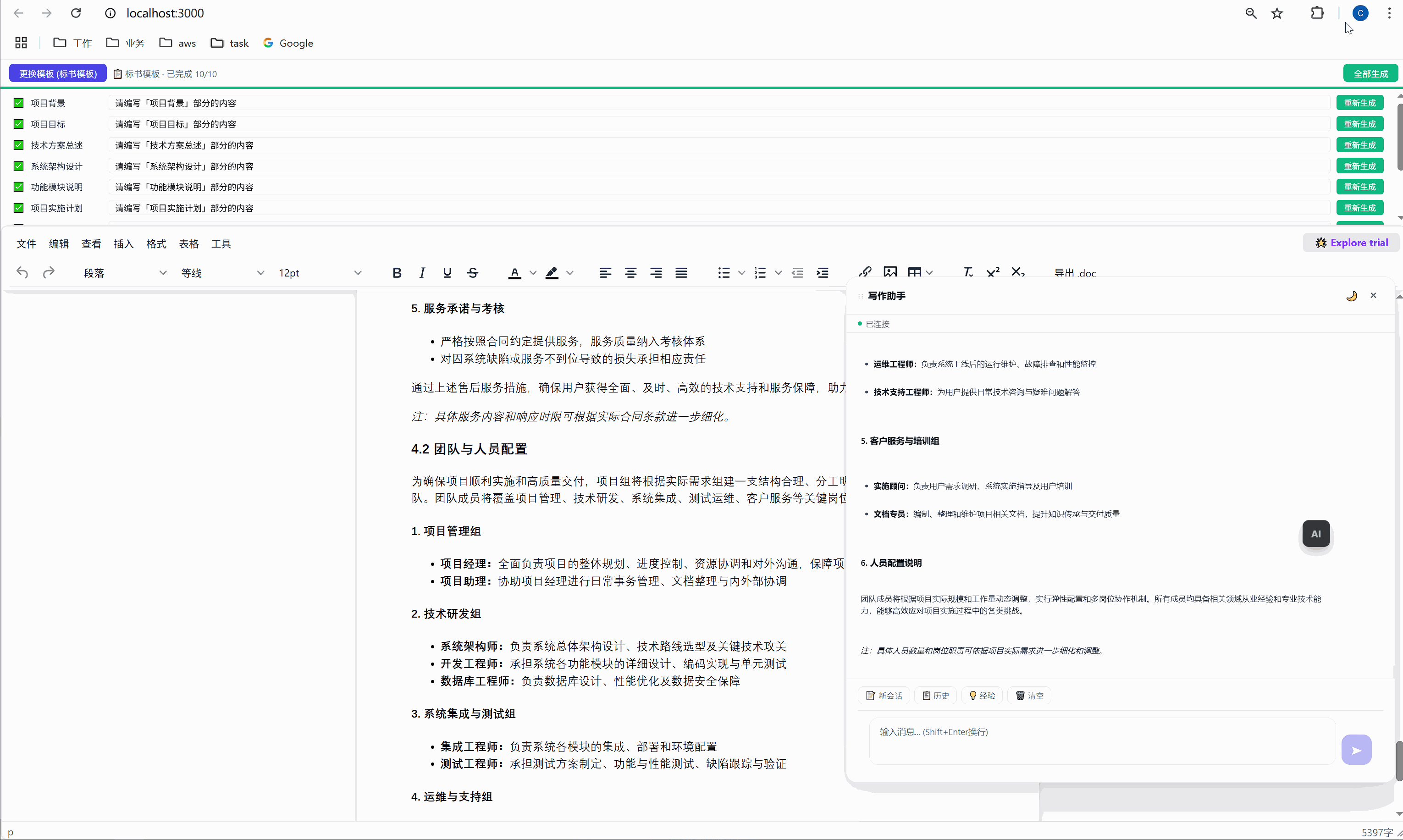
六、任务面板:AI 批量执行的驾驶舱
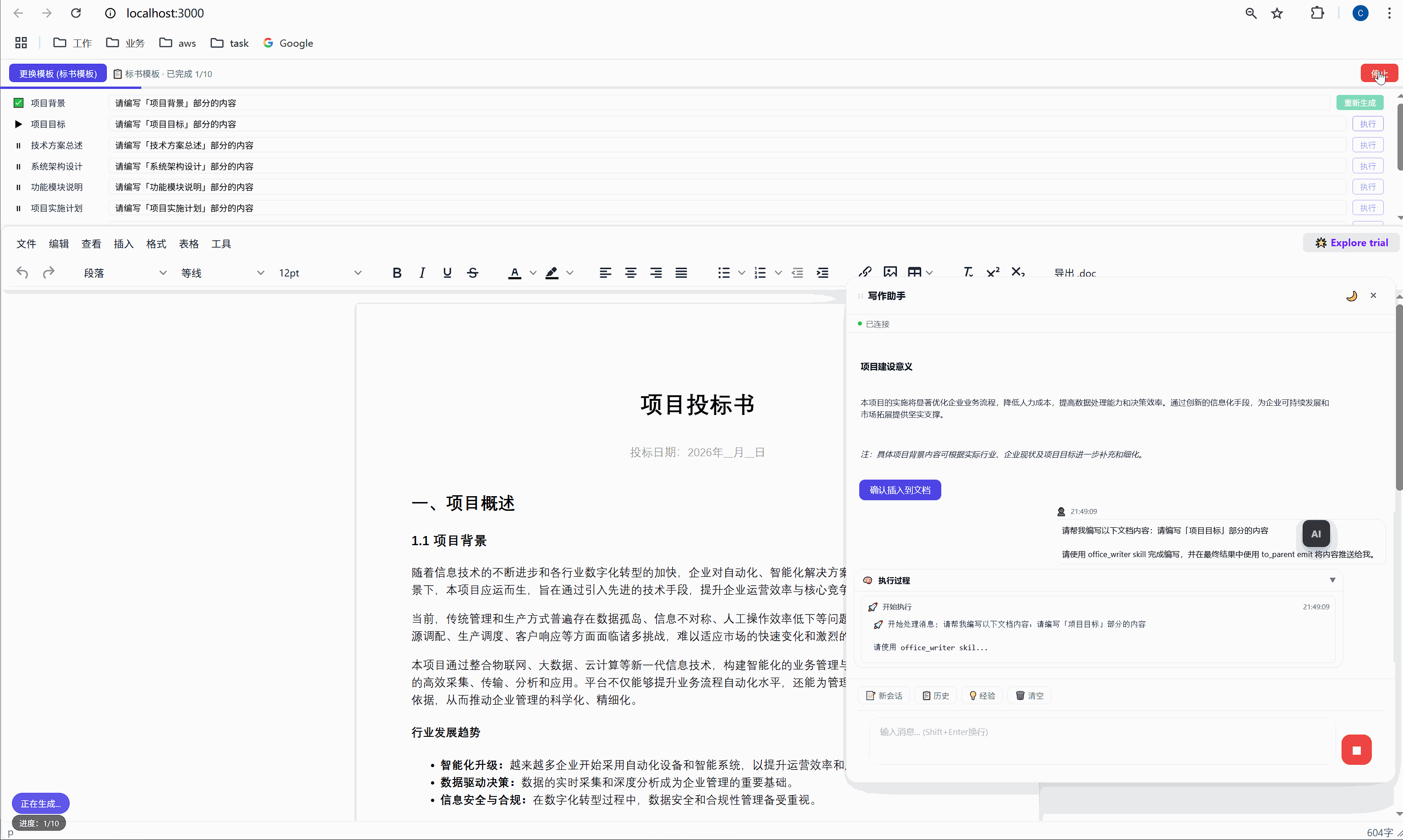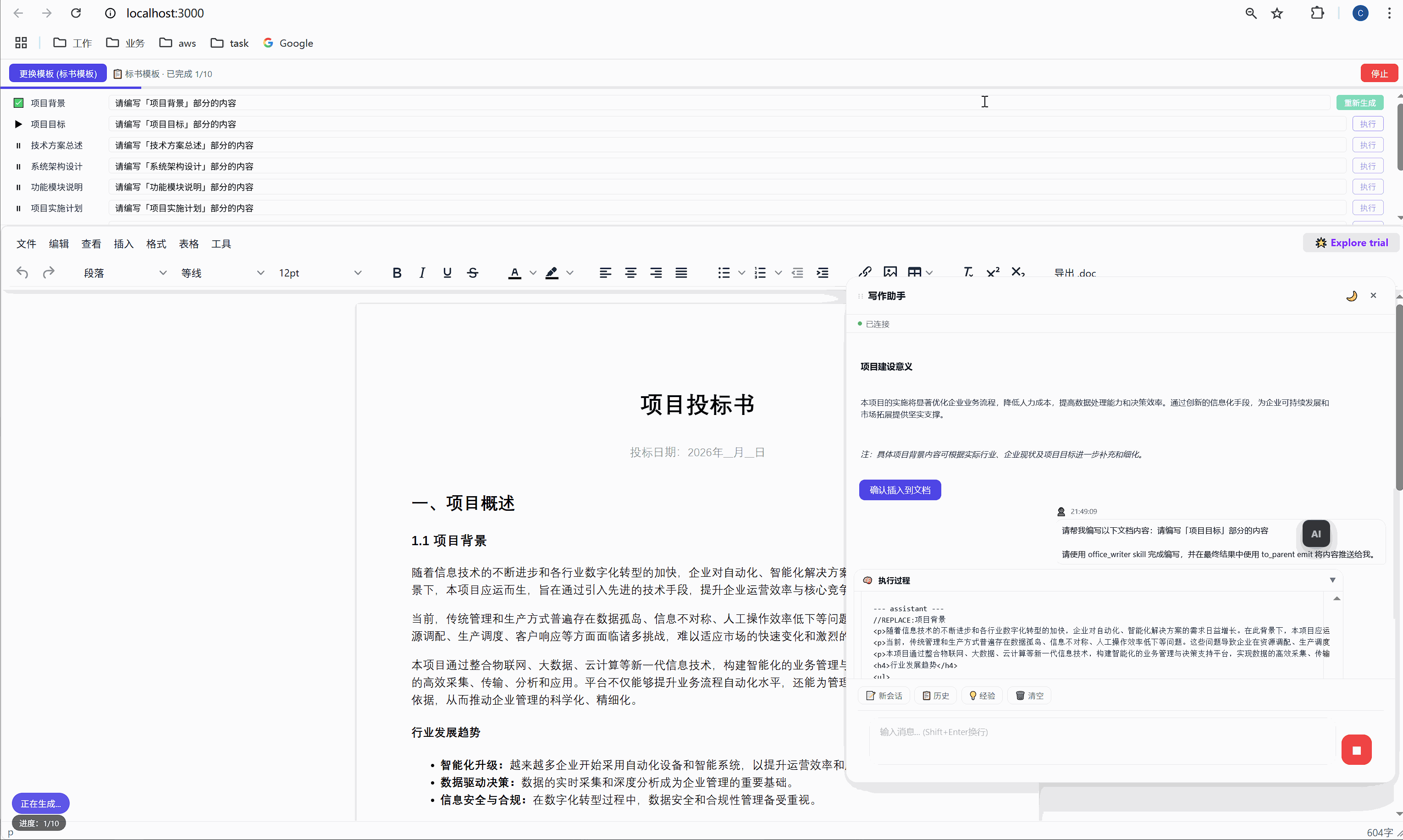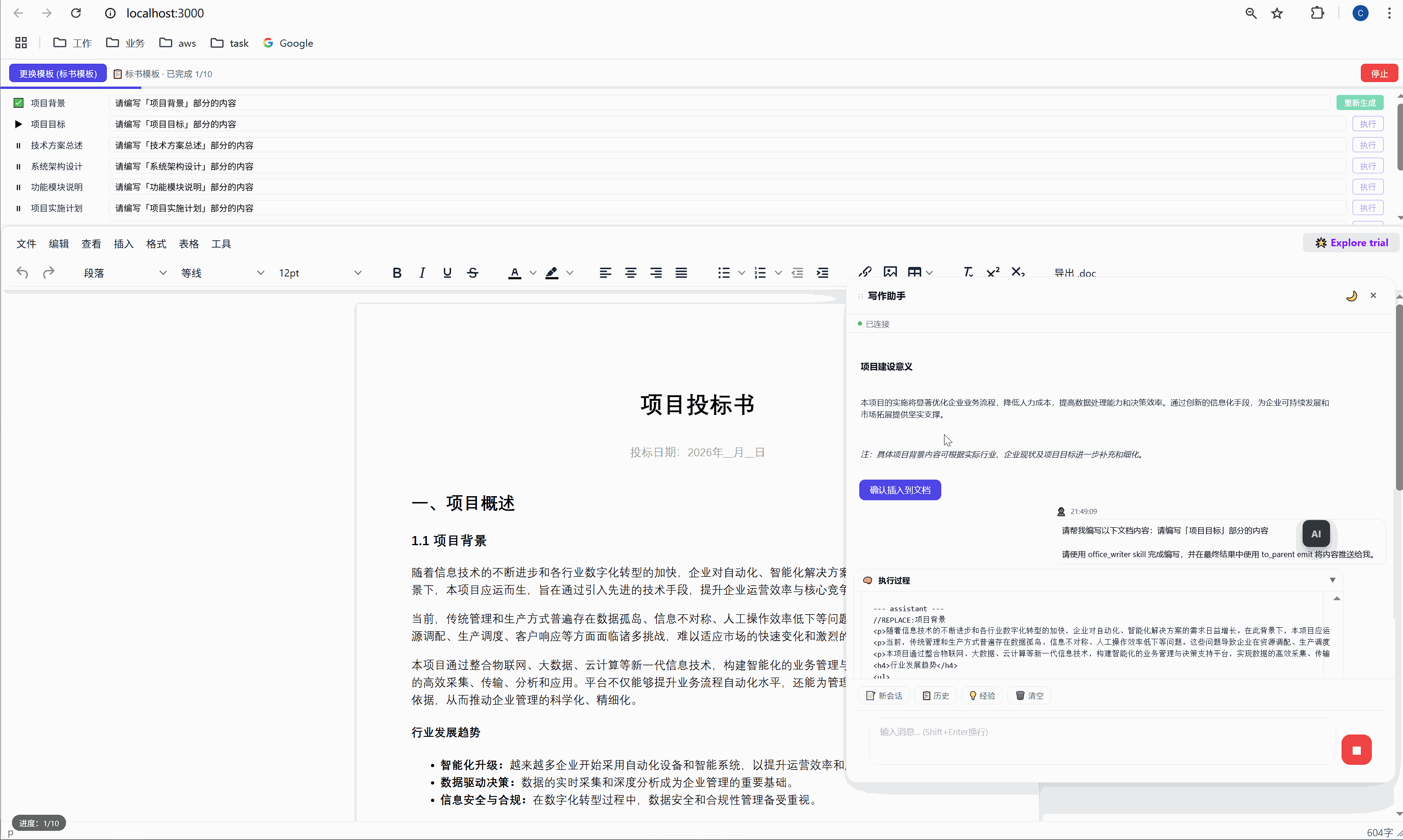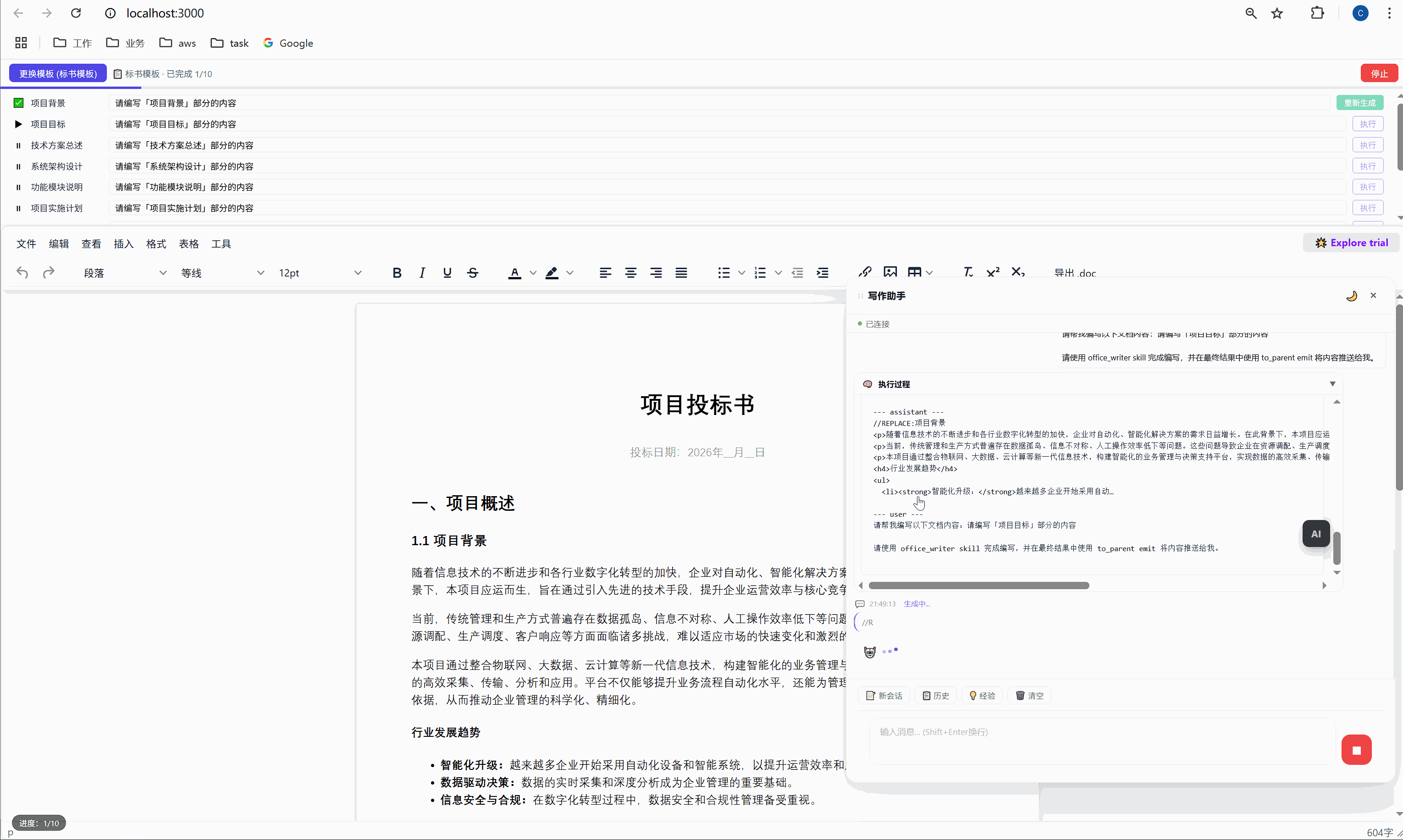
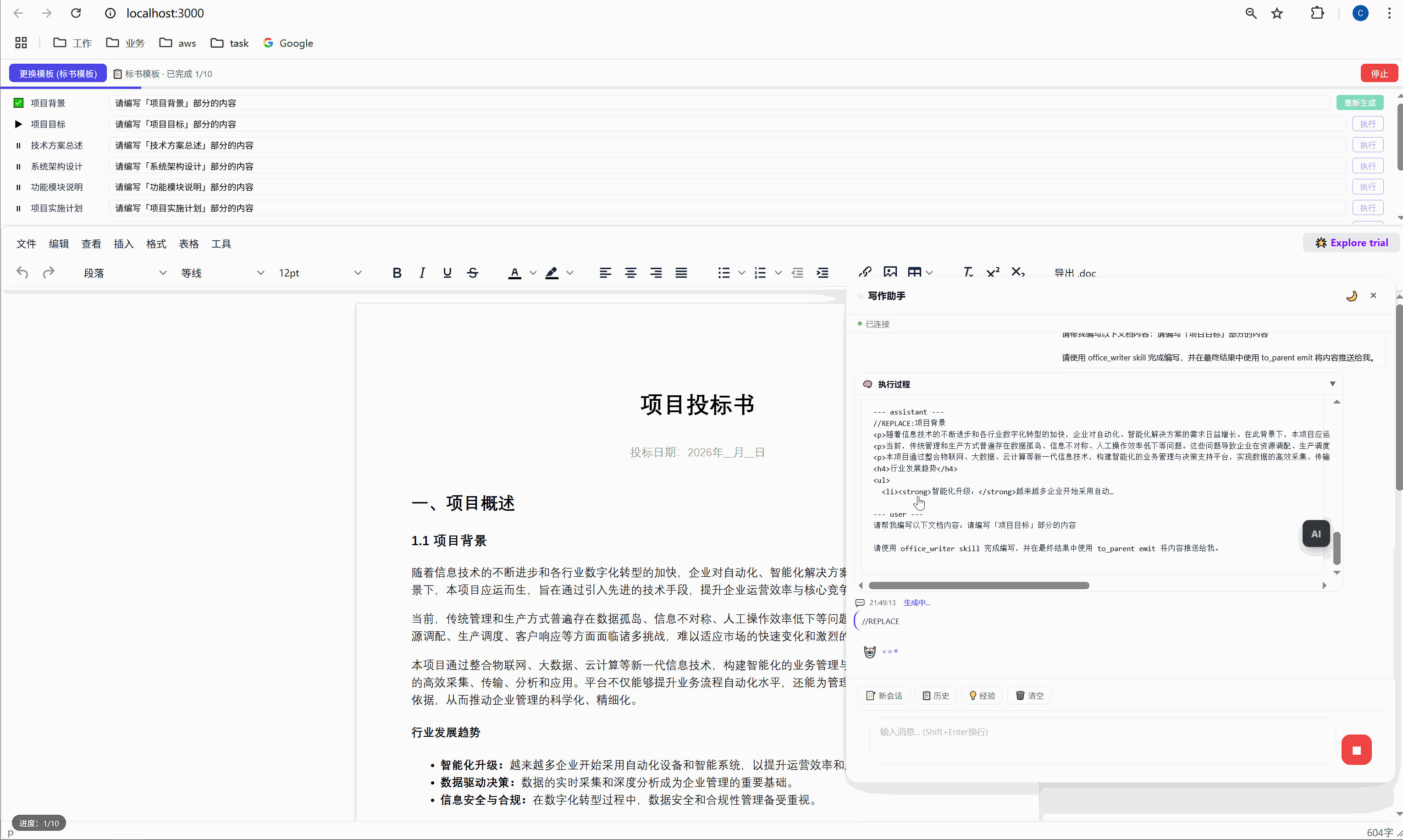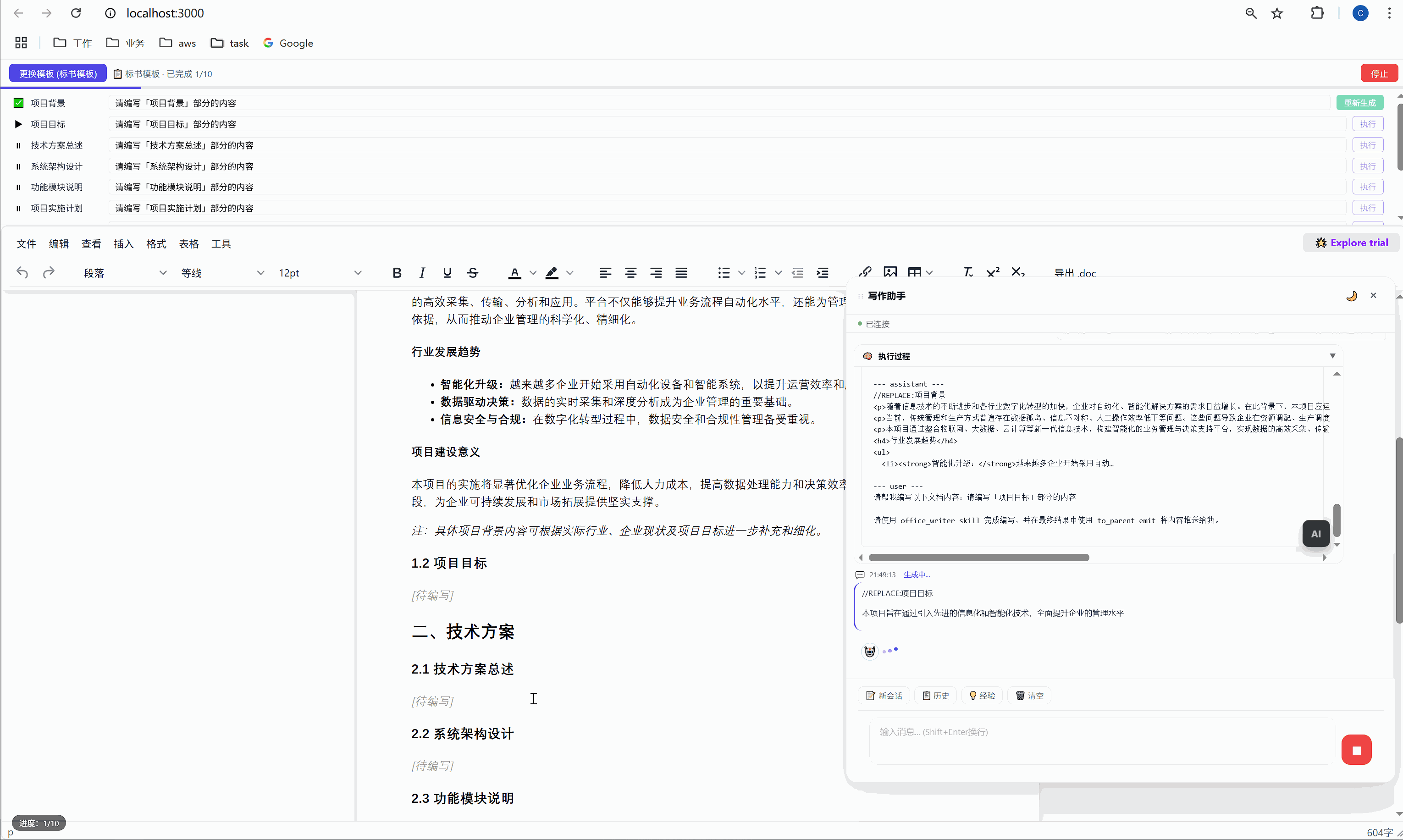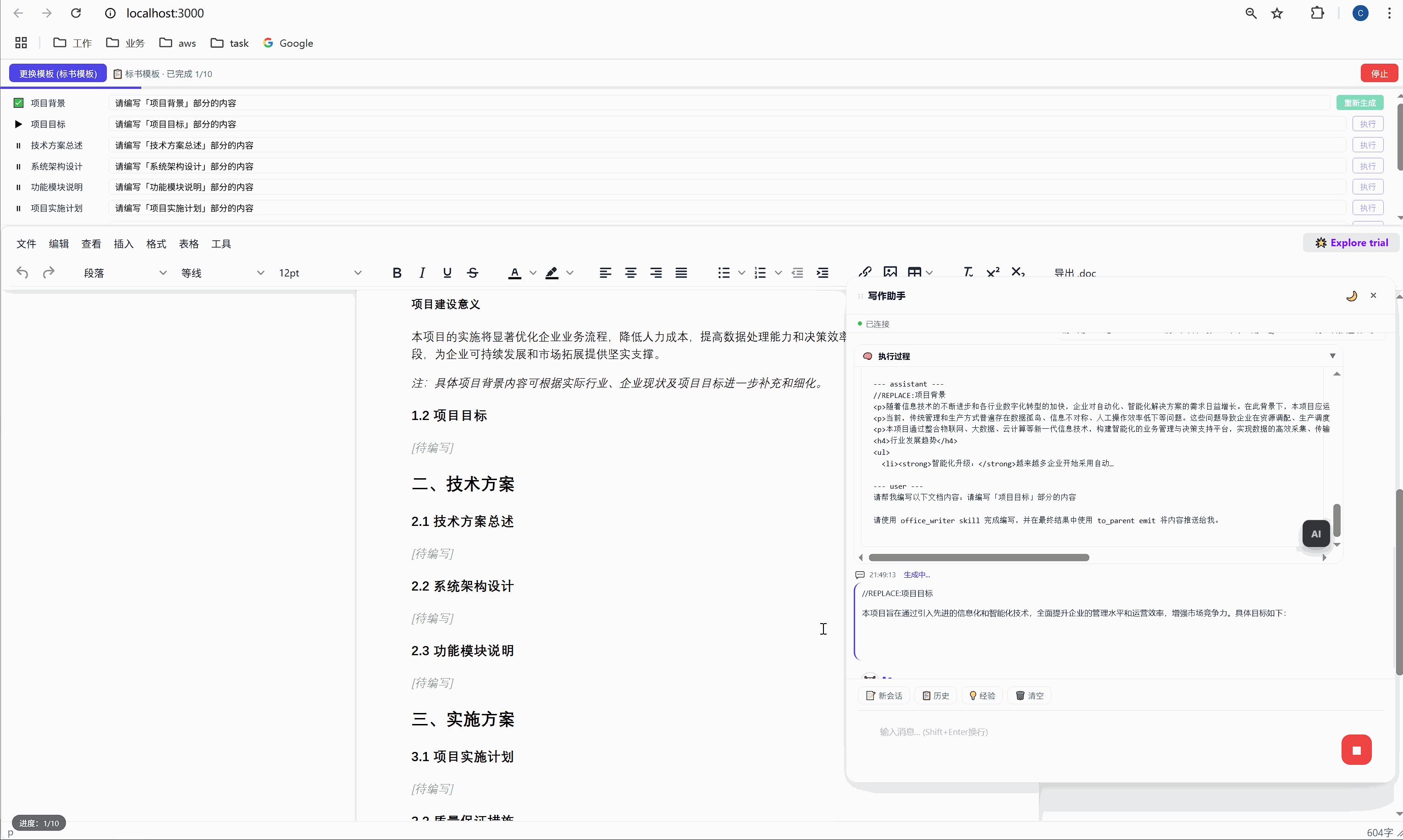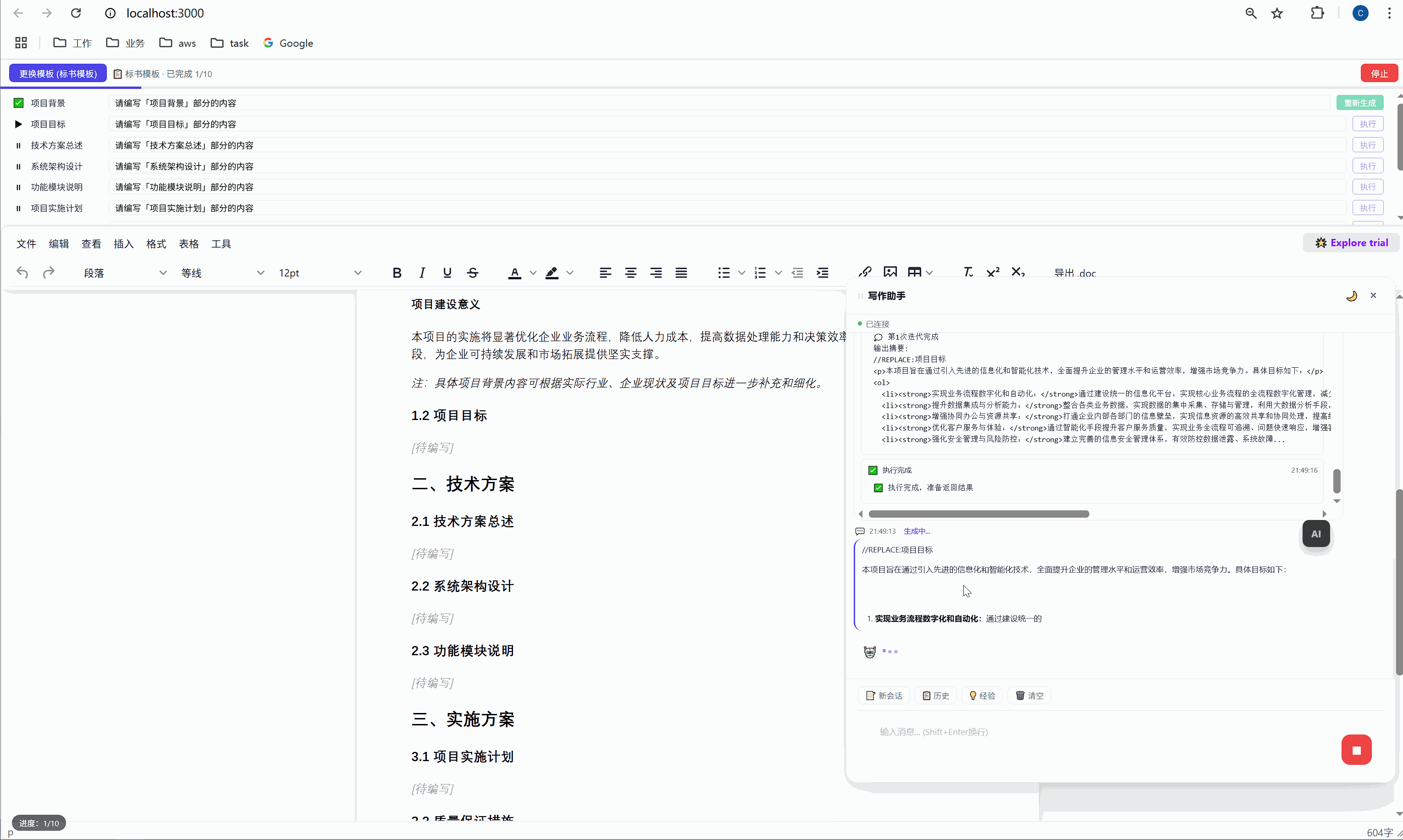
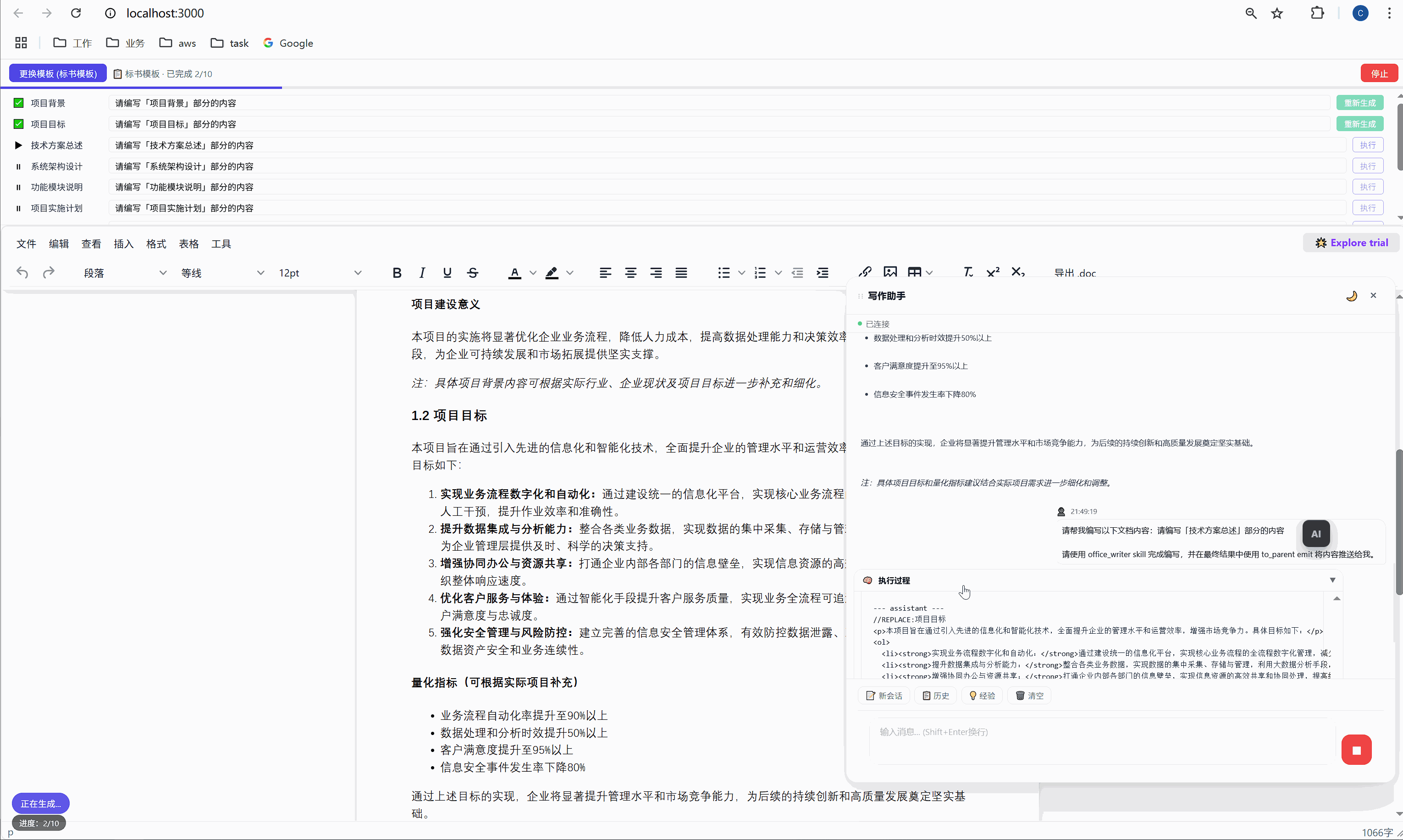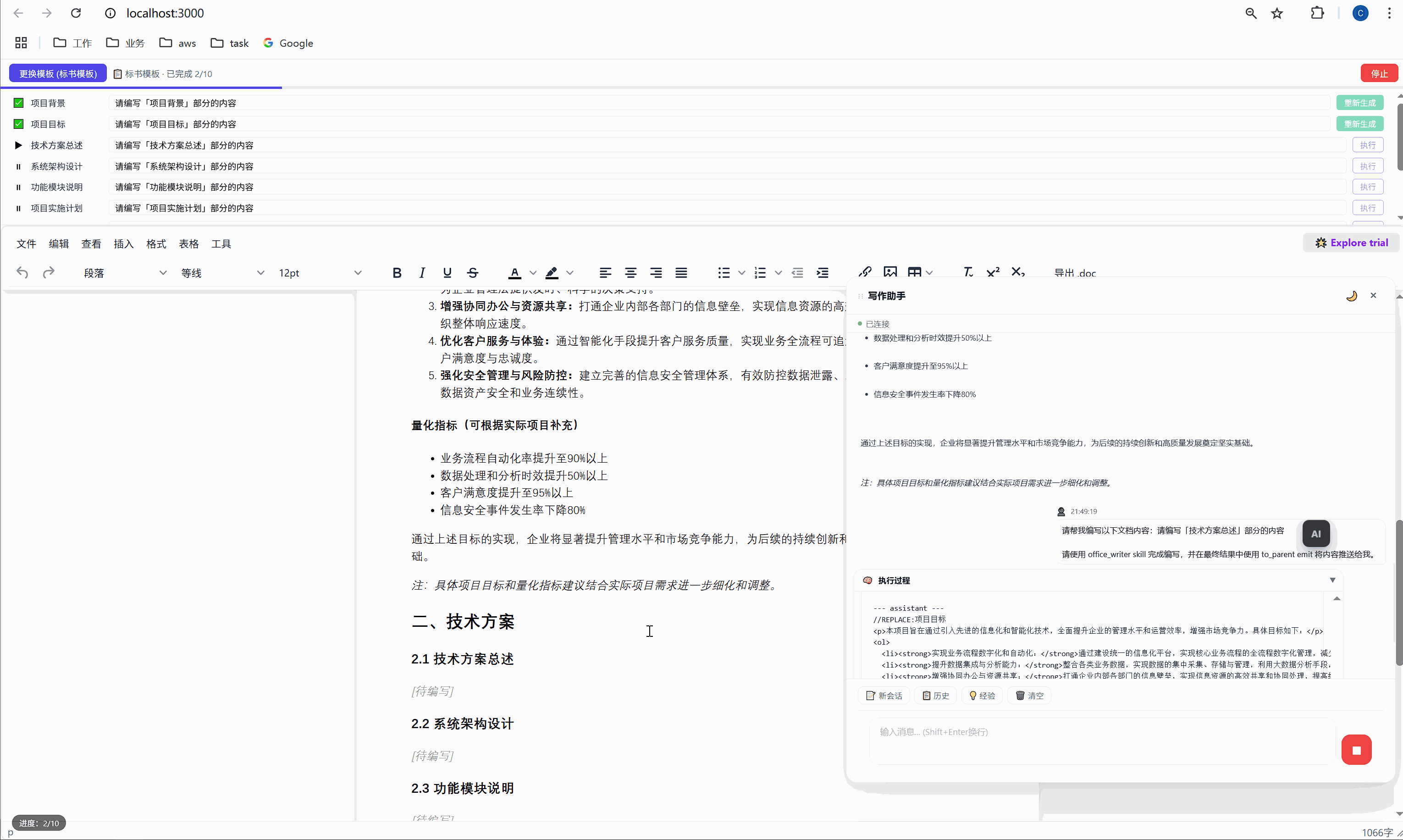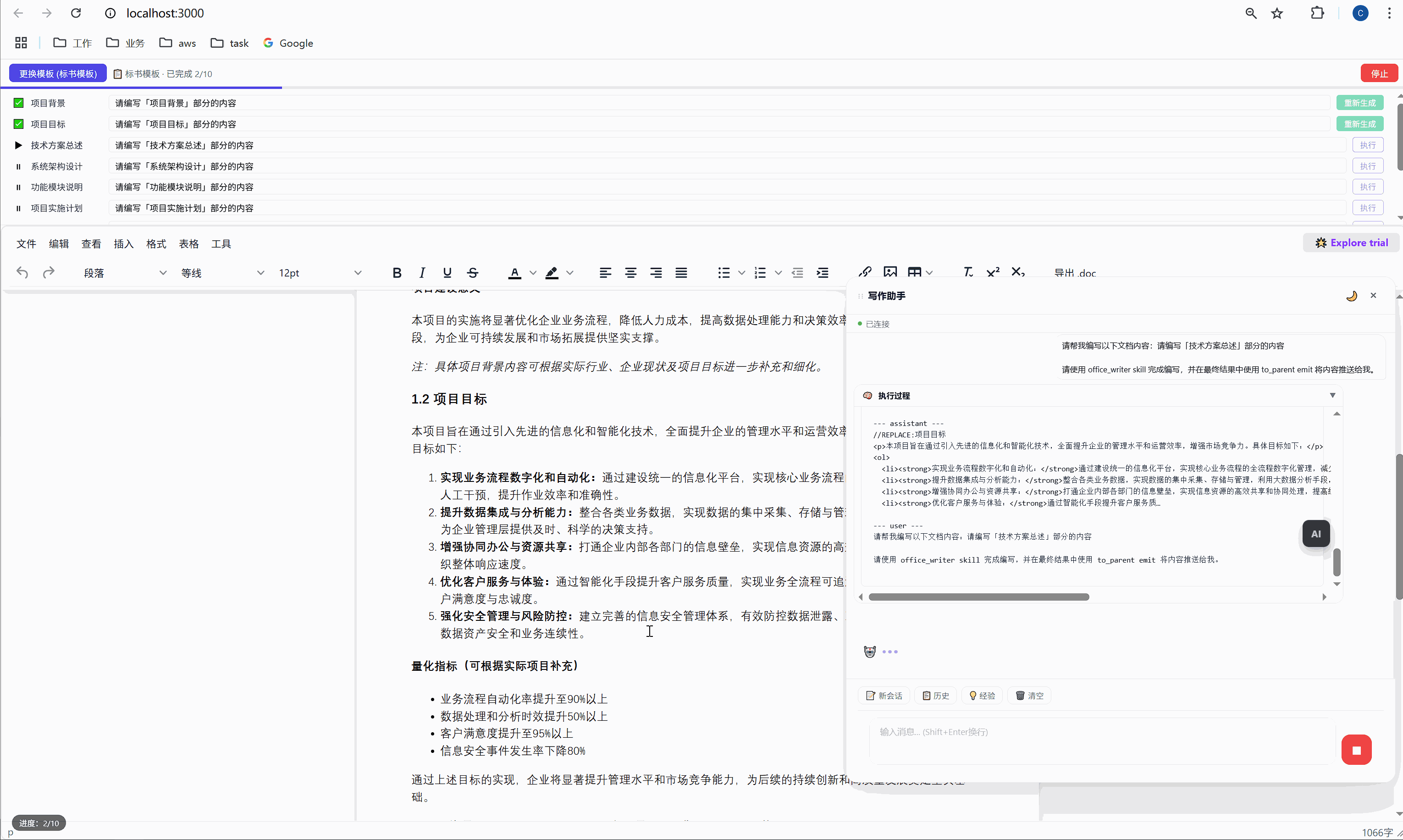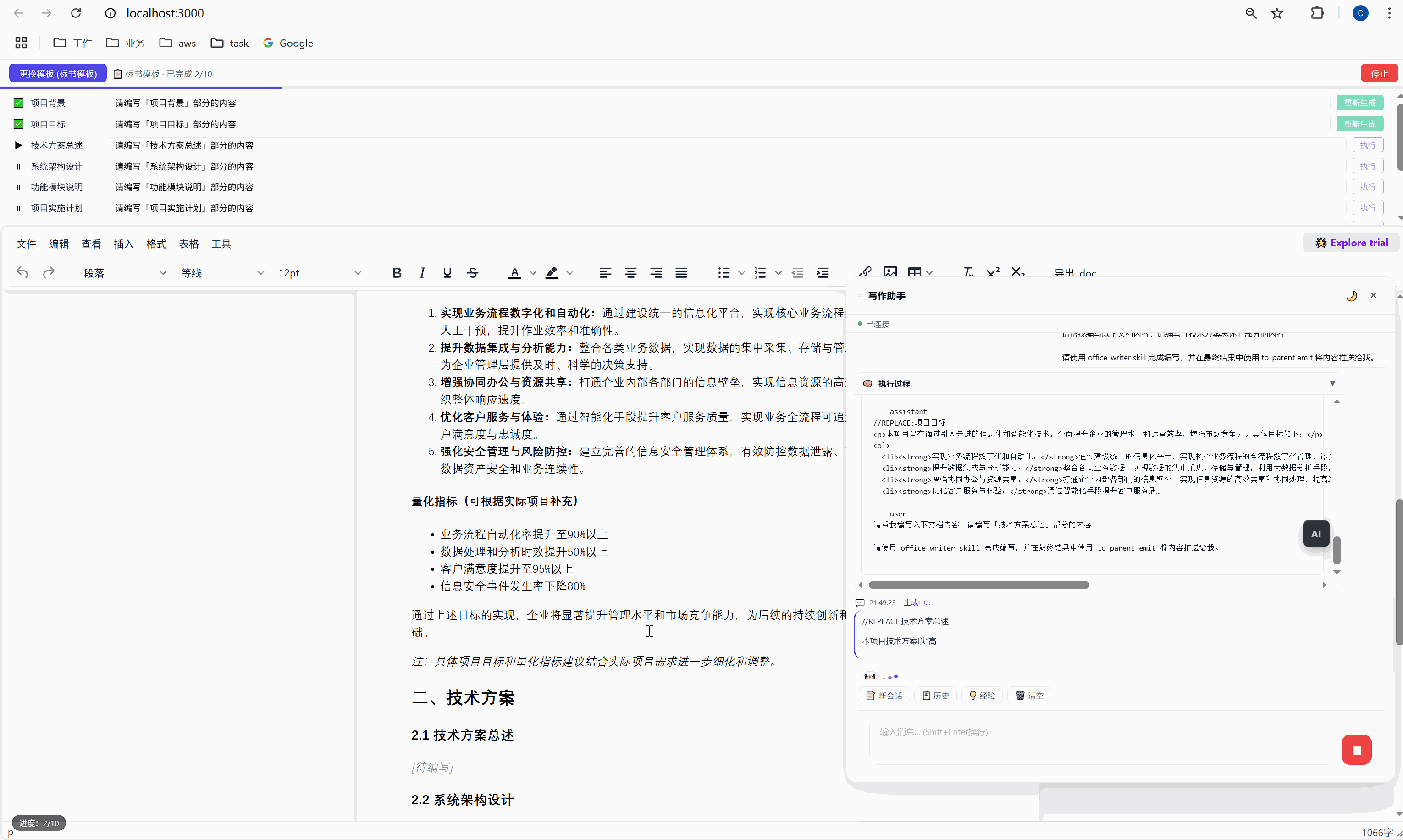
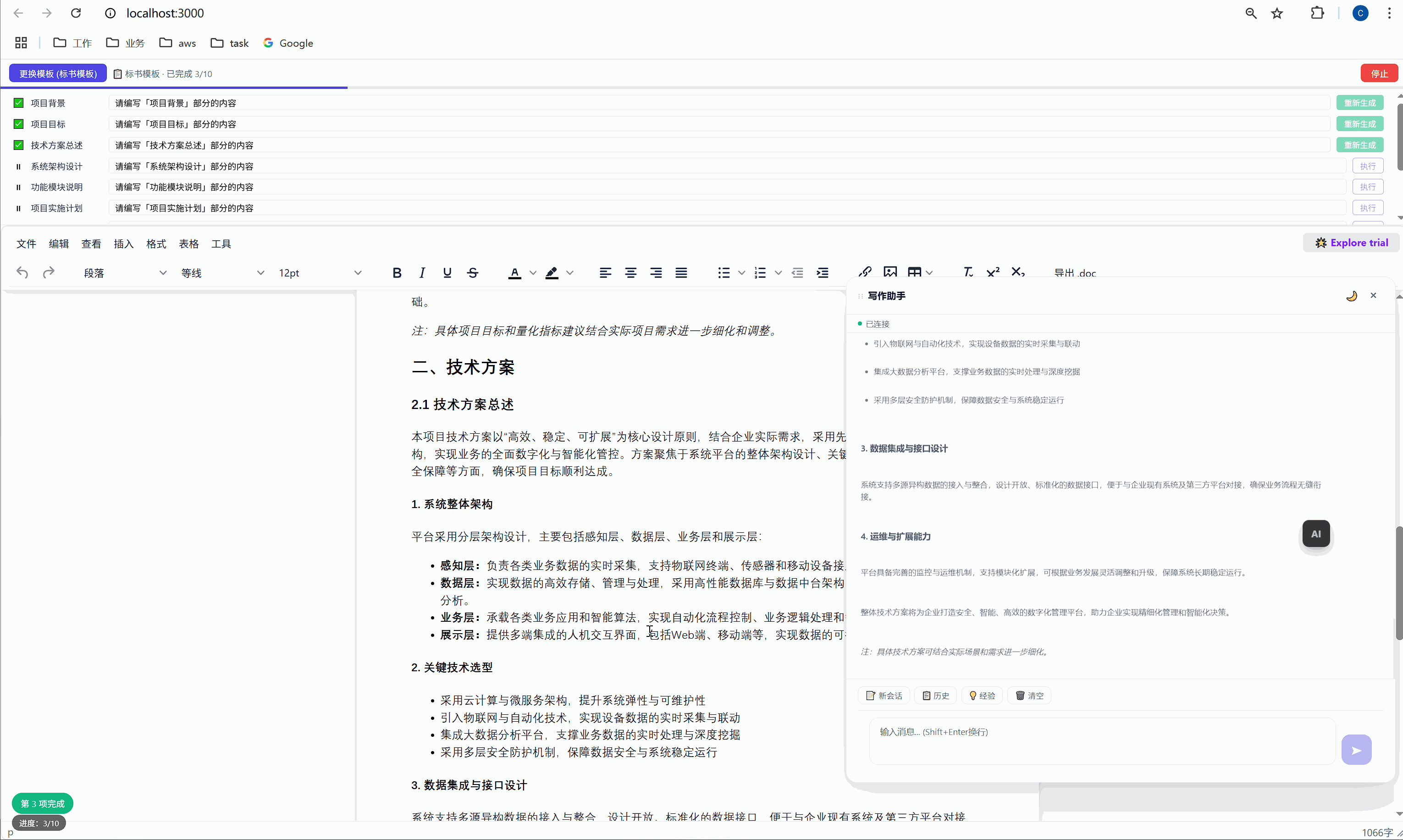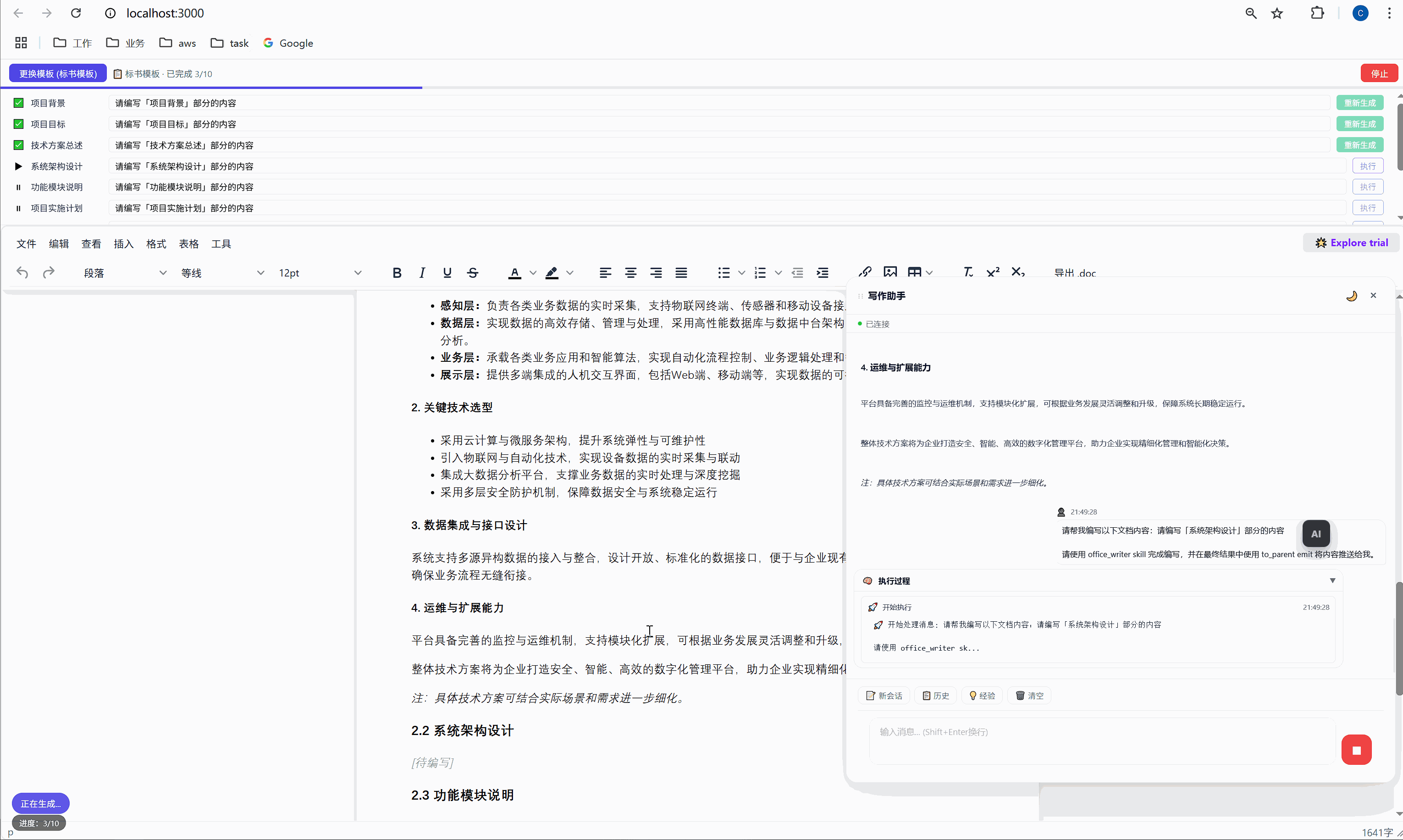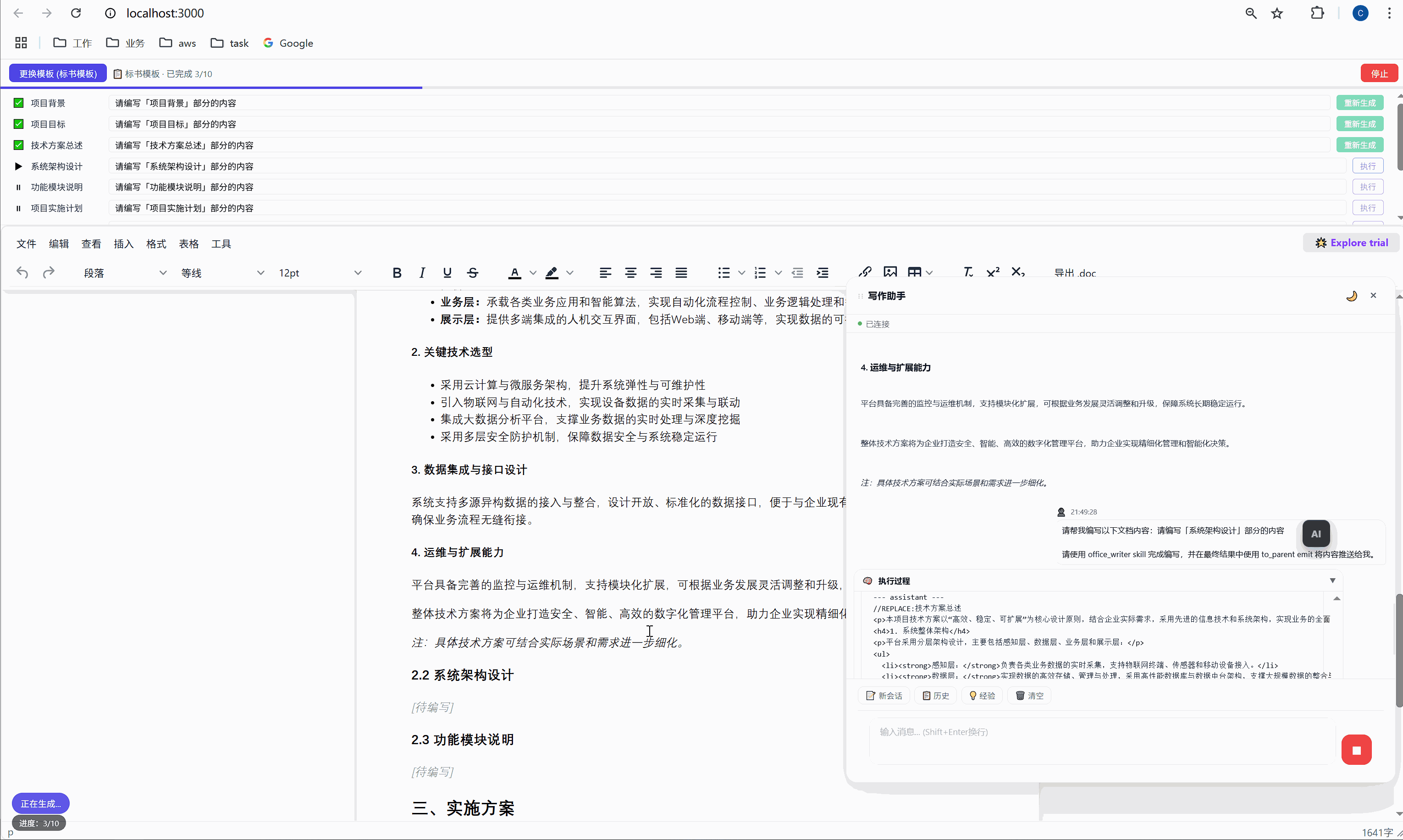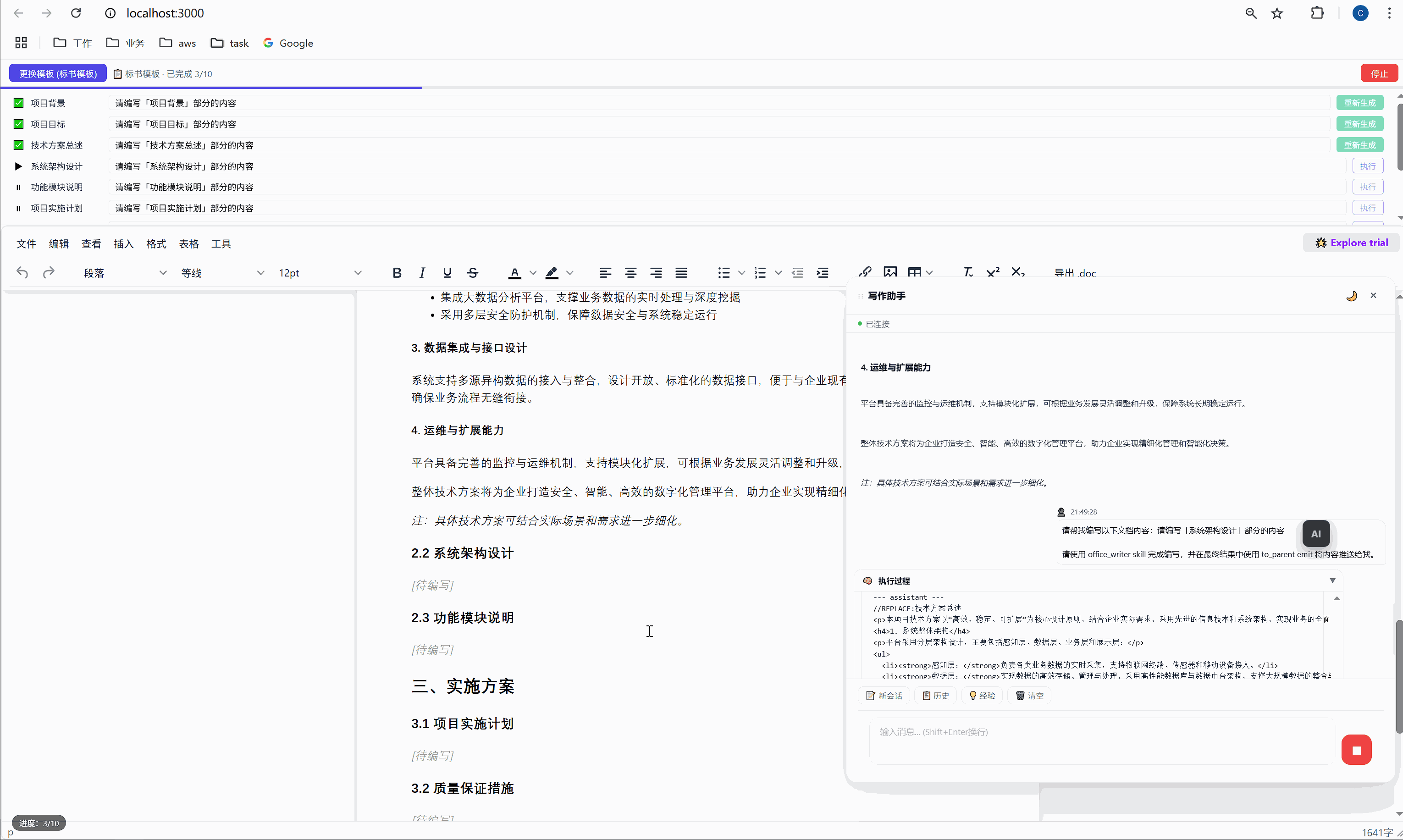
这是整个系统最核心的交互界面。
6.1 任务面板长什么样
选择模板后,顶部会出现任务面板:
┌─────────────────────────────────────────────────────┐
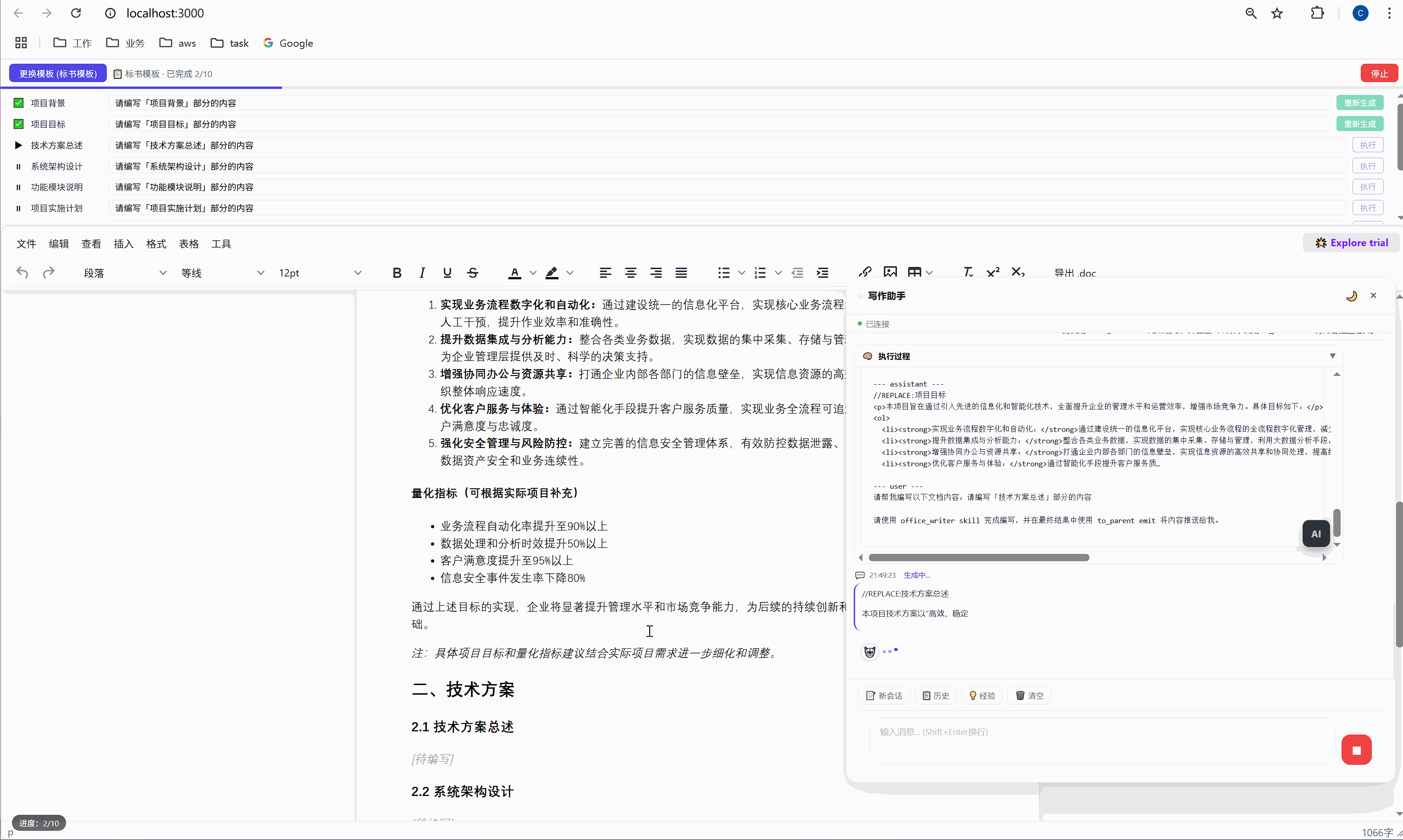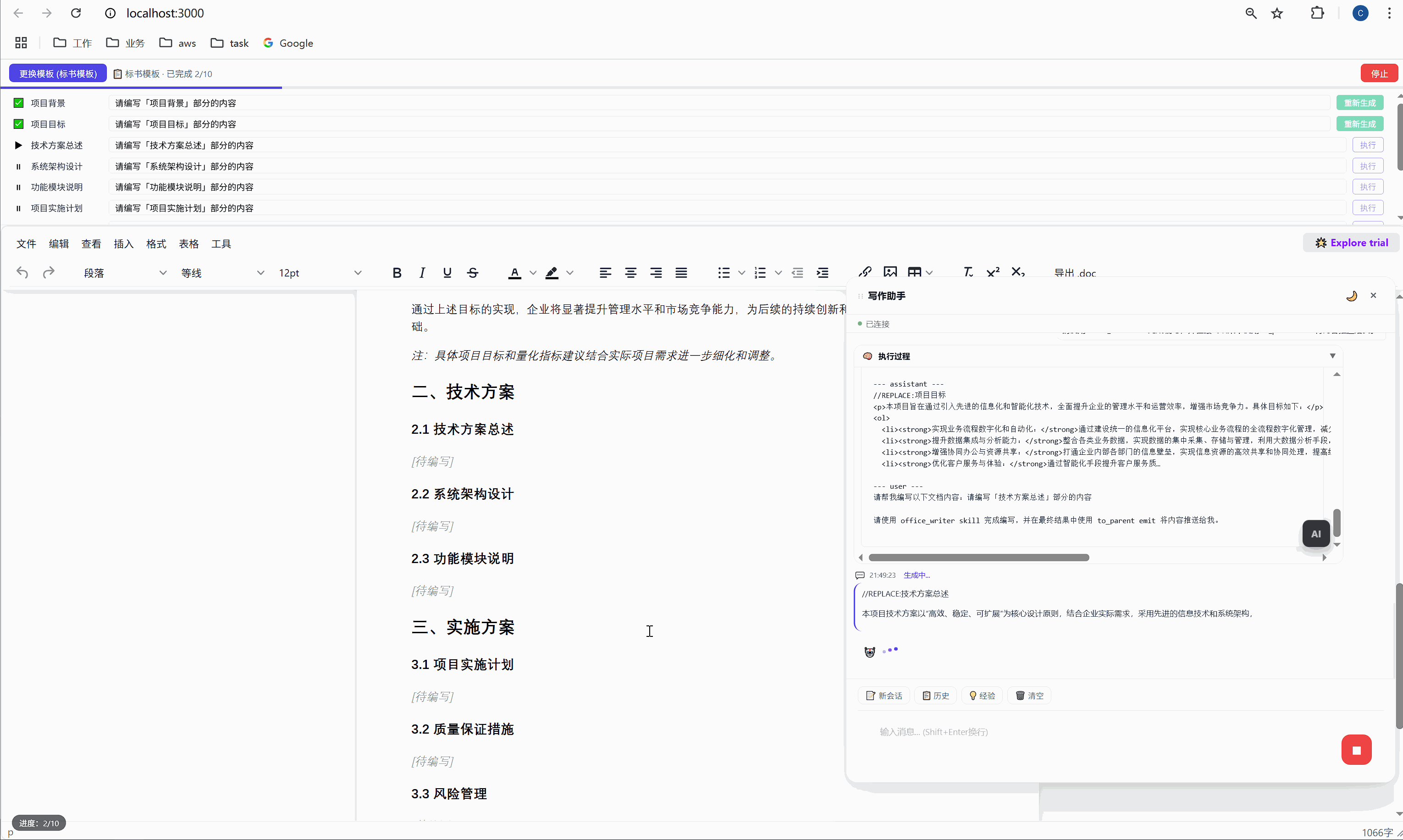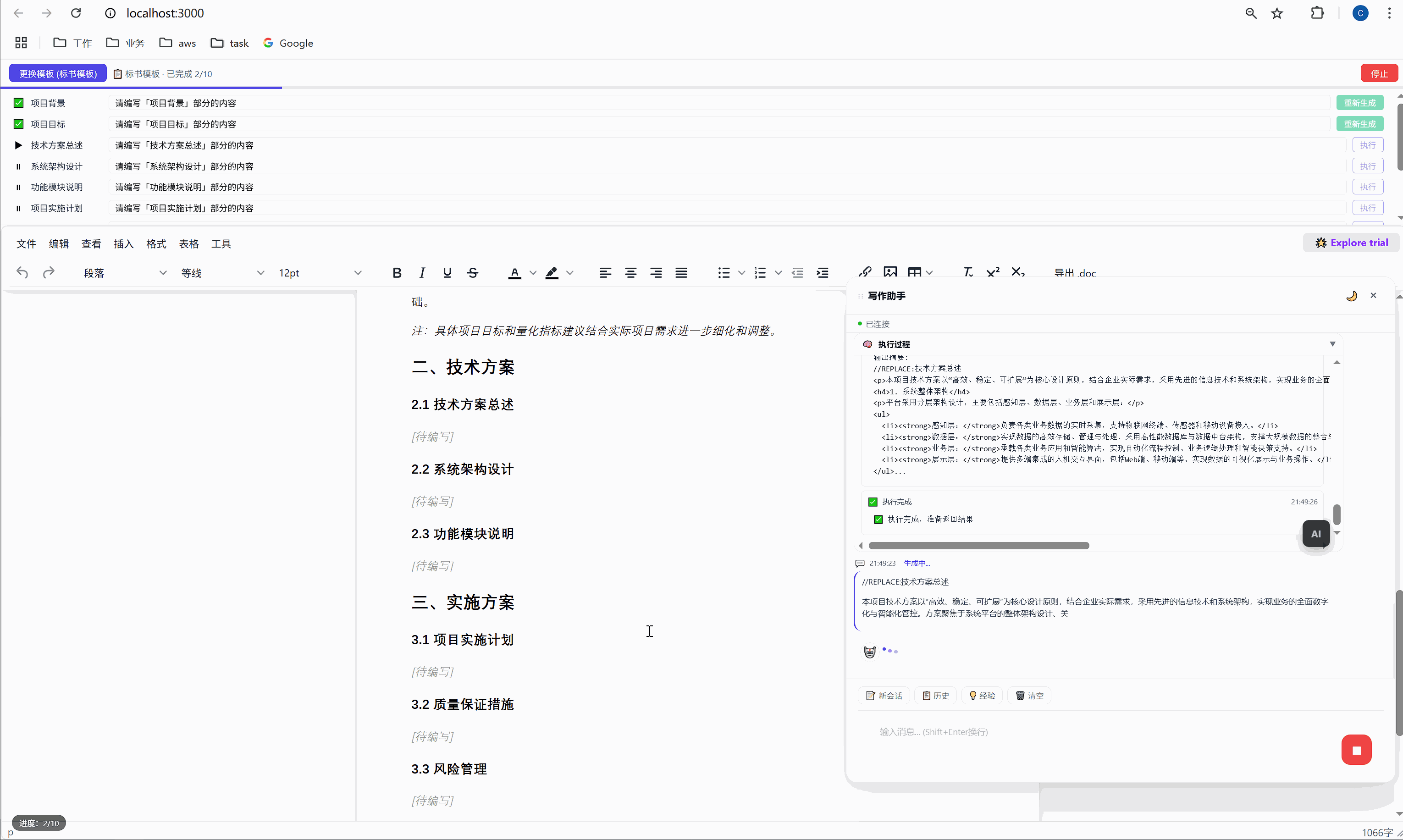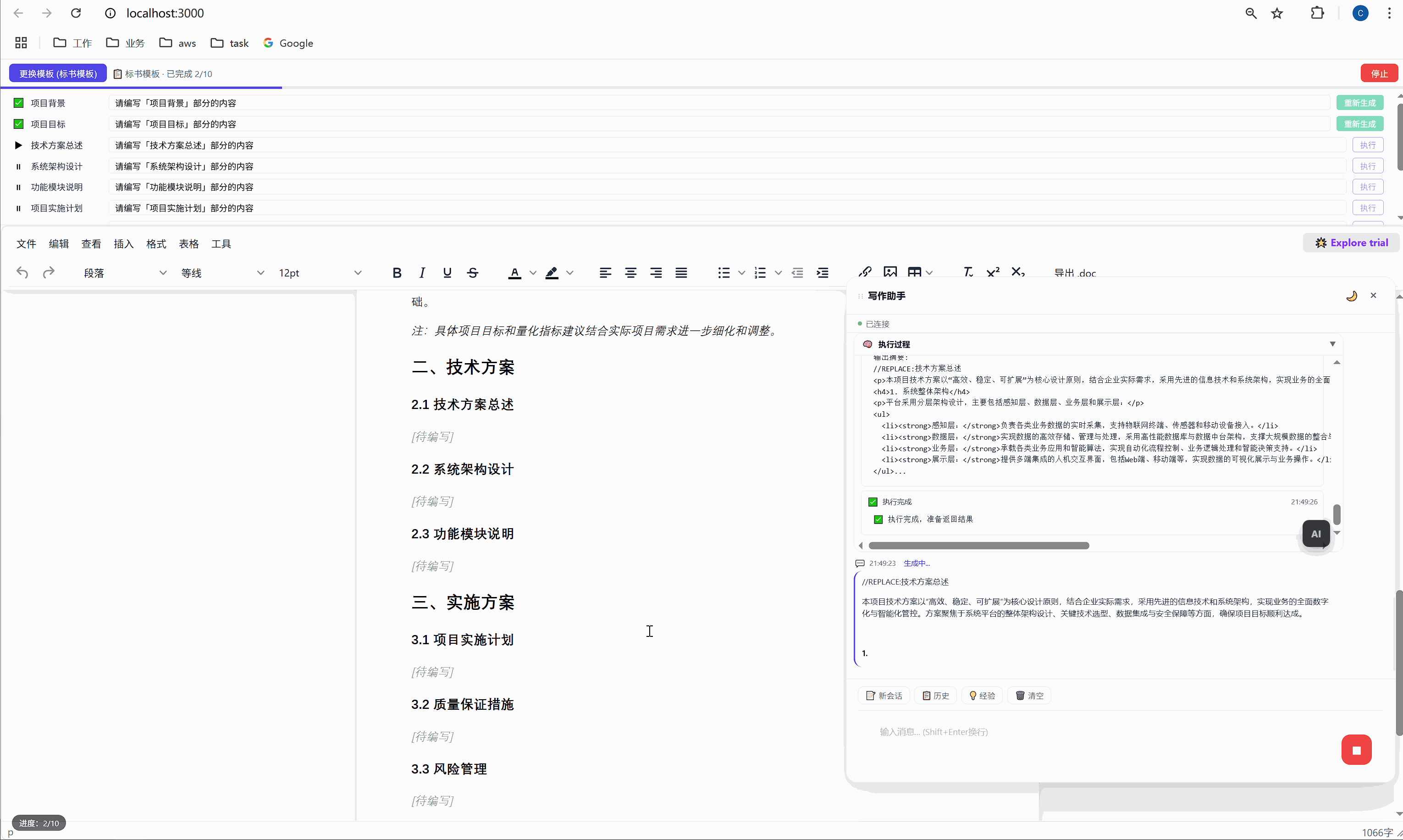
│ ████░░░░░░░░░░░░░░░░░░░░░░░░░░░ 2/10 已完成 │
├─────────────────────────────────────────────────────┤
│ ✅ 项目背景 [需求文本_____________] [重新生成] │
│ ▶ 项目目标 [正在生成... ] │
│ ⏸ 技术方案总述 [请编写「技术方案总述」部分内容] [执行] │
│ ⏸ 系统架构设计 [请编写「系统架构设计」部分内容] [执行] │
│ ⏸ 功能模块说明 [请编写「功能模块说明」部分内容] [执行] │
│ ... │
├─────────────────────────────────────────────────────┤
│ [ 停止 ] │
└─────────────────────────────────────────────────────┘每一行是一个任务,包含:
- 状态图标:✅ 已完成 / ▶ 正在执行 / ⏸ 等待中
- 任务标签:对应文档中的章节名
- 需求输入框:可编辑,用户可以自定义每段内容的生成要求
- 操作按钮:未完成的显示"执行",已完成的显示"重新生成"
6.2 "全部生成":一键批量执行
点击绿色的"全部生成"按钮,系统开始逐项执行:
第 1 项:项目背景 → 发送 → AI 生成 → 插入文档 → ✅
↓ (500ms 间隔)
第 2 项:项目目标 → 发送 → AI 生成 → 插入文档 → ✅
↓ (500ms 间隔)
第 3 项:技术方案总述 → 发送 → AI 生成 → 插入文档 → ✅
...整个过程全自动,用户只需要泡杯咖啡等着。进度条实时更新,左下角显示"进度:3/10"。
6.3 "重新生成":精准覆盖
某一段写得不好?点击那行的"重新生成"按钮,AI 会重新生成这段内容并精准替换,不影响其他任何部分。
这是怎么实现的?背后有一个巧妙的锚点机制:
首次生成时 ,AI 的内容被插入到 <p data-todo="xxx">[待编写]</p> 的位置,同时系统会在内容前后埋入 HTML 注释锚点:
html
<h3>1.1 项目背景</h3>
<!-- section-anchor: 项目背景 -->
<p>随着现代物流行业的快速发展...</p>
<!-- /section-anchor: 项目背景 -->重新生成时 ,系统找到 <!-- section-anchor: 项目背景 --> 到 <!-- /section-anchor: 项目背景 --> 之间的内容,整体替换为新的 AI 输出。
HTML 注释在编辑器中是不可见的,所以用户看到的是一份干净的文档。但系统内部,这些注释充当了精确的定位标记。
这个设计的关键在于:定位不依赖 AI 的输出,不依赖光标位置,不依赖文本内容匹配。它依赖的是我们在首次生成时主动埋入的结构化锚点。
这就是工程化思维和"随便调个 API"的区别。
七、定位问题:AI 工程化中最容易被忽视的坑
如果说前面讲的都是"怎么做",这一节讲的就是"为什么要这么做"。
7.1 最开始的版本是什么样的
最开始,我的 replaceTodo 函数是这样的:
javascript
function replaceTodo(todoText, newContent) {
const html = editor.getContent()
const marker = `<!-- TODO: ${todoText} -->`
if (!html.includes(marker)) return false
editor.setContent(html.replace(marker, newContent))
return true
}看起来没问题对吧?HTML 注释作为标记,查找、替换,一气呵成。
但实际用起来有三个致命问题:
问题一:AI 输出的内容自带标题。
AI 很热情,生成"项目背景"时开头自带一个 <h3>一、项目背景</h3>。替换之后,文档里原有的 <h3> 标题被 AI 的新标题替代了------看起来没问题,但如果有多个同名章节就乱了。
问题二:重新生成找不到位置。
第一次生成后,<!-- TODO: 项目背景 --> 注释已经被替换掉了。第二次点"重新生成",注释不存在了,找不到位置。
问题三:单条执行时任务状态不更新。
AI 内容插入成功了,但任务面板上的状态一直停留在"执行中",按钮也不会变成"重新生成"。
7.2 怎么解决的
解决一:去掉 AI 输出中的第一个标题。
javascript
const bodyContent = newContent
.replace(/^[ \t]*<h[1-6][^>]*>.*?<\/h[1-6]>\n?/i, '')
.trim()只去掉第一个标题(重复的章节标题),保留后续的子标题(如"1.1 行业现状"、"1.2 建设目标")。这样文档结构保持完整,AI 的子标题也能正常显示。
同时在 SKILL.md 中明确告诉 AI:"不要生成章节标题,文档模板已包含"。双保险------代码层面会处理,prompt 层面也会指导。
解决二:首次生成时埋锚点,重新生成时按锚点定位。
javascript
// 首次生成:替换占位符 → 埋入锚点
const wrapped = `<!-- section-anchor: ${todoText} -->\n${bodyContent}\n<!-- /section-anchor: ${todoText} -->`
editor.setContent(html.replace(match[0], wrapped))
// 重新生成:找到锚点区间 → 整体替换
const anchorRegex = new RegExp(`<!-- section-anchor: ${todoText} -->[\\s\\S]*?<!-- /section-anchor: ${todoText} -->`, 'i')
editor.setContent(html.replace(anchorRegex, wrapped))解决三:用 ref 追踪最新状态。
React 的 useEffect 闭包有一个经典的"过期状态"问题------在 useEffect(..., []) 中定义的回调函数,拿到的永远是初始化时的状态值。
解决方法是用 useRef 实时追踪:
javascript
const currentTaskIdxRef = useRef(0)
const tasksRef = useRef([])
currentTaskIdxRef.current = currentTaskIdx // 每次渲染都更新
tasksRef.current = tasks
// onToParent 回调中通过 ref 获取最新值
const idx = currentTaskIdxRef.current
const currentTask = tasksRef.current[idx]这样即使 onToParent 是在 useEffect 中定义的闭包,它也能通过 ref 拿到最新的任务索引和任务列表。
7.3 兜底策略:三层定位
即使做了以上所有优化,还有一个隐患:AI 可能不按照 //REPLACE:xxx 的格式输出。
LLM 不是确定性的。你告诉它"输出第一行写 //REPLACE:项目背景",它可能会忘记,可能会写成 // REPLACE: 项目背景(多了空格),可能完全忽略这个指令。
所以 tryReplaceTodo 函数设计了一个三层兜底策略:
优先级1: 解析 //REPLACE:xxx 指令
→ 精确匹配 data-todo 属性
→ 失败则模糊匹配(子串包含)
优先级2: 没有 //REPLACE: 指令
→ 直接用当前任务的 label 调用 replaceTodo()
优先级3: 都失败
→ mdToHtml 转换后在光标处插入(兜底)这就像写代码时的 try-catch-finally------正常路径走第一步,异常路径有第二步兜着,最坏情况还有第三步保底。
永远不要让 AI 的输出格式成为系统正确运行的必要条件。 这是我从这个项目中学到的最重要的一条经验。
八、Agent 工程化的几个核心原则
回顾整个项目,我想总结几条在构建 AI Agent 应用时反复验证过的原则。
8.1 原则一:让 AI 做 AI 的事,让代码做代码的事
LLM 擅长的是:理解意图、生成自然语言、组织结构化内容。
LLM 不擅长的是:精确定位、格式控制、状态管理、错误处理。
所以系统的职责划分应该是:
| 职责 | 由谁负责 |
|---|---|
| 理解用户需求 | AI |
| 生成专业文档内容 | AI |
| 确定插入位置 | 代码 |
| 维护文档结构 | 代码 |
| 任务状态管理 | 代码 |
| 格式转换(MD→HTML) | 代码 |
如果你的系统里 AI 既要生成内容又要控制格式还要管理状态------那大概率会出问题。
8.2 原则二:确定性代码 + 不确定性 AI = 确定性系统
LLM 的输出是不确定的。同样的 prompt,两次运行可能得到不同的结果。但用户对系统的期望是确定的------点击"生成",内容出现在正确的位置,任务状态变为"完成"。
实现确定性的关键是:在 AI 的不确定性输出和系统的确定性行为之间,建立一道防火墙。
tryReplaceTodo 的三层策略就是这道防火墙。无论 AI 输出什么格式,系统都有对应的处理路径,最终结果是确定的------内容被正确插入。
8.3 原则三:可观察性比聪明更重要
一开始我写了一个很"聪明"的替换逻辑,用复杂的正则匹配各种边缘情况。出了问题之后,我完全不知道是哪一步失败了------是正则没匹配到?是替换成功了但 TinyMCE 没渲染?还是 AI 输出格式不对?
后来我做了两件事:
- 简化逻辑:把复杂的单函数拆成三层,每层职责清晰
- 增加可观察性:任务面板实时显示每项的状态(pending/running/done),左下角显示当前进度
现在出了问题,看一眼任务面板就知道:如果某项一直卡在"running",说明 bot 的响应没回来;如果状态变成"done"但文档没变化,说明定位失败了。
一个好的 UI 就是最好的调试工具。
8.4 原则四:轻量 > 重量
整个系统的核心代码量:
- 后端 Agent 核心循环:约 800 行
- 前端 App.jsx:约 300 行
- TinyMCE 编辑器封装:约 130 行
- SKILL.md prompt:约 120 行
- 标书模板 HTML:约 40 行
总共不过一千多行。但它实现了一个完整的 AI 辅助文档编写系统:模板选择、任务管理、批量执行、精准定位、重新生成、Word 导出。
不需要 React Flow,不需要 LangChain,不需要向量数据库。一个简单的 SKILL.md + 一个消息总线 + 一个编辑器的 replaceTodo 函数,就够了。
不要为了"像一个 Agent 系统"而去添加组件。 如果问题可以用 50 行代码解决,就不要写 500 行。YAGNI(You Ain't Gonna Need It)在 AI 应用领域同样适用------甚至更重要,因为 AI 应用天然容易过度设计。
九、未来展望:还能做什么
目前这个系统已经能用,而且好用。但还有几个方向可以继续探索:
9.1 更多模板
目前只有标书模板。但同样的架构可以用于:合同、报告、方案、论文等任何有固定结构的文档类型。只需要:
- 在
TEMPLATES数组中添加一个条目 - 创建对应的 HTML 模板文件
5 分钟搞定一个新模板。
9.2 知识库增强
在生成内容时,可以接入企业知识库(已有的项目文档、历史标书、产品资料),让 AI 生成的内容更贴合企业实际情况。pricebot 本身已经支持知识库 skill(kb_recall),可以无缝接入。
9.3 多人协作
当前的 session 是单人单会话的。如果加入用户认证和 session 共享,就可以实现多人同时编辑同一份标书的不同章节------每个人负责自己的任务,AI 分别生成,最终自动合并。
9.4 质量评估
在 AI 生成内容后,加入一个自动评估环节(可以是另一个 LLM 调用),从完整性、针对性、专业性、可读性等维度打分。低于阈值时自动修订。这其实就是 pricebot 中已有的 bid_writing 引擎的 Plan→Write→Evaluate→Revise 流程。
十、写在最后
回到开头那个凌晨一点半的夜晚。
如果当时我有这个工具,我大概只需要:点击"选择模板" → 选标书模板 → 点击"全部生成" → 泡杯咖啡 → 回来检查一下每段内容 → 导出 .doc 发给客户。
整个过程可能不超过 20 分钟,而且质量比我手动 Ctrl+C/Ctrl+V 的要高得多。
我不是在教 AI 替我工作。我是在用工程化的方法,把重复性的工作从人类身上转移出去,让人去做真正需要创造力的事情。
比如:想想这个系统的下一个版本该做什么。
或者,至少能早点睡觉。