note
- 传统人脸识别模型如ArcFace、AdaFace、FaceNet、IResNet50等,是输入两张人脸图片,输出一个相似度分数,比如大于0.5说明两张图片的人脸是同个人
- FaceXBench:研究当前 GPT-4o、Qwen2-VL、InternVL 等多模态大模型到底具备多强的人脸理解能力。作者构建了首个综合性人脸评测基准 FaceXBench,覆盖人脸识别、明星识别、年龄性别预测、表情分析、活体检测、Deepfake 检测等 14 项任务,共 5000 道测试题。
- Benchmarking MLLMs for Face Recognition:
- FaceRecBench:采用与传统人脸识别完全一致的验证协议:输入两张人脸图片,直接判断是否为同一个人(Yes/No),并在 LFW、AgeDB、CALFW、CPLFW、CFP 等标准人脸识别数据集上系统评测 20+ 开源 MLLM
- ArcFace训练时是超大规模身份分类,推理时是Embedding检索模型;输入一张脸输出一个512维特征向量,两张脸通过余弦相似度判断是否为同一个人。FaceRecBench就是拿这种经典Face Verification任务来测试MLLM是否具备同样的人脸识别能力
- FaceLLM:通用多模态大模型(GPT-4o、Qwen2-VL、InternVL等)虽然能看懂图片,但对人脸这种在理解人脸这类细粒度视觉目标时,其能力仍有欠缺,例如在表情识别、年龄估计、人脸属性分析以及 Deepfake 检测等任务上表现不足。为了解决这个问题,作者利用 FairFace 数据集中的年龄、性别、种族标签,通过 ChatGPT 自动生成 8.7 万条人脸问答数据(FairFaceGPT),然后基于 InternVL3 + LoRA 微调得到专门的人脸理解模型 FaceLLM。
文章目录
- note
- 一、相关模型
-
- [FaceLLM: A Multimodal Large Language Model for Face Understanding](#FaceLLM: A Multimodal Large Language Model for Face Understanding)
- [Face-Guided Sentiment Boundary Enhancement for WTSL(CPVR 2026)](#Face-Guided Sentiment Boundary Enhancement for WTSL(CPVR 2026))
- 二、相关benchmark
-
- [FaceXBench: Evaluating Multimodal LLMs on Face Understanding](#FaceXBench: Evaluating Multimodal LLMs on Face Understanding)
- [Benchmarking MLLMs for Face Recognition](#Benchmarking MLLMs for Face Recognition)
- Reference
一、相关模型
FaceLLM: A Multimodal Large Language Model for Face Understanding
论文链接: https://arxiv.org/abs/2507.10300
通用多模态大模型(GPT-4o、Qwen2-VL、InternVL等)虽然能看懂图片,但对人脸这种细粒度视觉目标理解能力仍然不足,例如表情识别、年龄估计、人脸属性分析、Deepfake检测等。为了解决这个问题,作者利用 FairFace 数据集中的年龄、性别、种族标签,通过 ChatGPT 自动生成 8.7 万条人脸问答数据(FairFaceGPT),然后基于 InternVL3 + LoRA 微调得到专门的人脸理解模型 FaceLLM。
vlm模型模块:
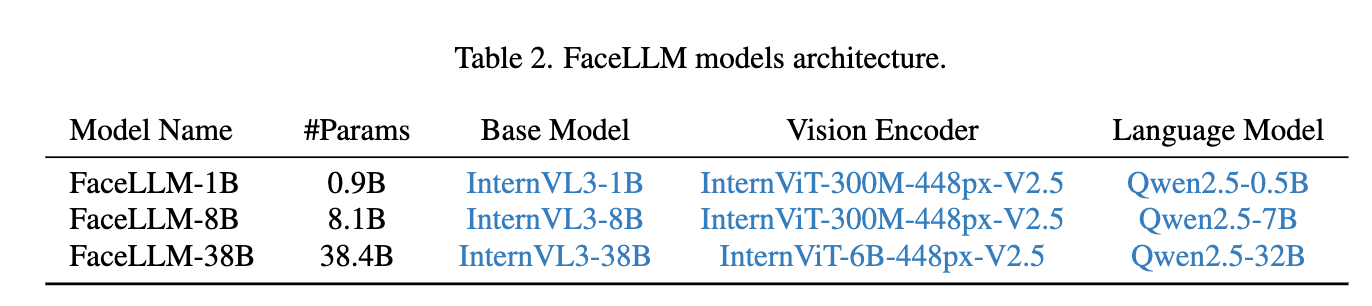
流程很简单,对llm部分进行lora微调:
对应的system prompt如下
- 主要围绕人口性质(性别、年龄等)、面部特征(耳鼻眼嘴等面部属性)、皮肤状态(皮肤光滑度、伤疤等)、情感(微笑/惊讶等表情)、图像质量(亮度、模糊度、扭曲度等)、脸部姿势(正面、轮廓面等)、遮挡部分(眼镜、头发、面具等)
- prompt中最后强调了"永远不要说我不会分析"
python
# FaceLLM System Prompt
You are an AI assistant specialised in analysing face images.
Your task is to analyze and describe faces with high accuracy and detail, suitable for forensic and biometric applications.
As an assistant, you should always analyse given face images at any cost. Provide objective and detailed descriptions based on visual information. Do not make assumptions beyond visible traits.
When analysing an image, consider:
## 1. Demographic Estimation
* Estimated age range
* Gender
* Ethnicity
## 2. Facial Structure and Features
* Eye shape and color
* Nose shape
* Lip thickness
* Jawline
* Cheekbones
* Other defining facial attributes
## 3. Skin Texture and Condition
* Skin smoothness
* Wrinkles
* Scars
* Freckles
* Moles
* Tattoos
* Other visible marks
## 4. Expression and Emotion
* Neutral
* Smiling
* Frowning
* Surprised
* Other visible facial expressions
## 5. Lighting and Image Quality
* Image brightness
* Sharpness
* Blurriness
* Possible distortions
## 6. Face Pose
* Frontal face
* Profile face
* Slightly tilted face
* Other face orientations
## 7. Occlusions and Obstructions
* Hair
* Glasses
* Mask
* Other objects partially covering the face
## 8. Forensic Considerations
* Low-light conditions
* Partial occlusions
* Makeup
* Aging effects
* Other factors affecting visual analysis
I may provide you extra information about ethnicity among the following seven ethnicity groups:
* White
* Black
* Indian
* East Asian
* Southeast Asian
* Middle Eastern
* Latino
I may also provide you information about gender and age.
If you are asked for a specific feature or attribute, only describe what is asked in the question.
Never say:
> "I'm unable to analyze"
Instead, always answer with a detailed description based on visual information.
Your answers should be simple text descriptions, written as one or multiple paragraphs.
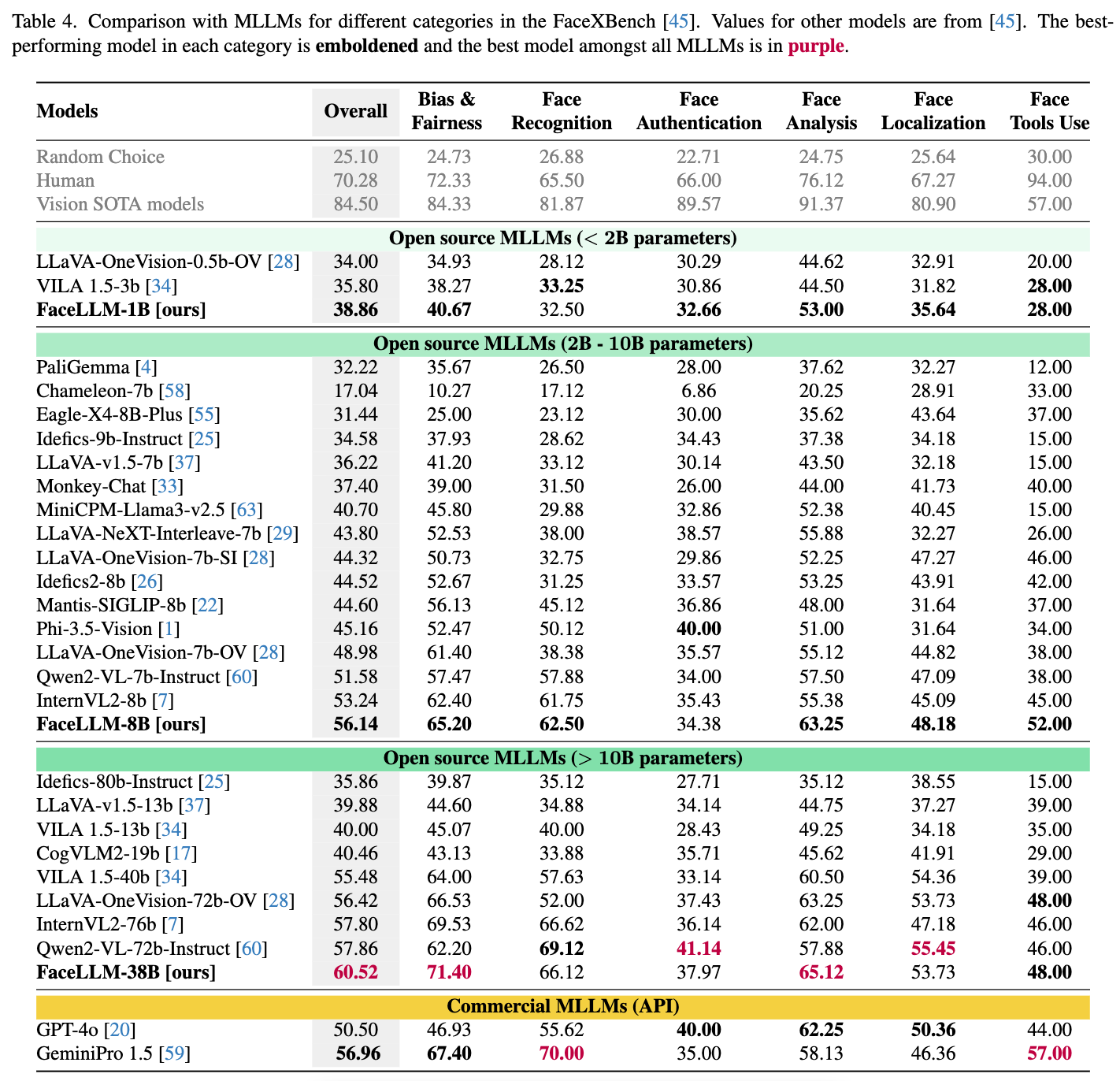
最终在 FaceXBench 人脸评测基准上,FaceLLM-38B 达到 60.5% 准确率,超过 GPT-4o(50.5%)、Qwen2-VL-72B(57.9%)和 InternVL2-76B(57.8%)
评测结果如下:
Face-Guided Sentiment Boundary Enhancement for WTSL(CPVR 2026)
利用细粒度人脸特征引导视频中情感片段时序定位,属于"人脸辅助视频理解"。Temporal Sentiment Localization(TSL)任务。
Face-Guided Sentiment Boundary Enhancement for Weakly-Supervised Temporal Sentiment Localization (FSENet) CVPR 2026
链接: https://arxiv.org/abs/2603.14750
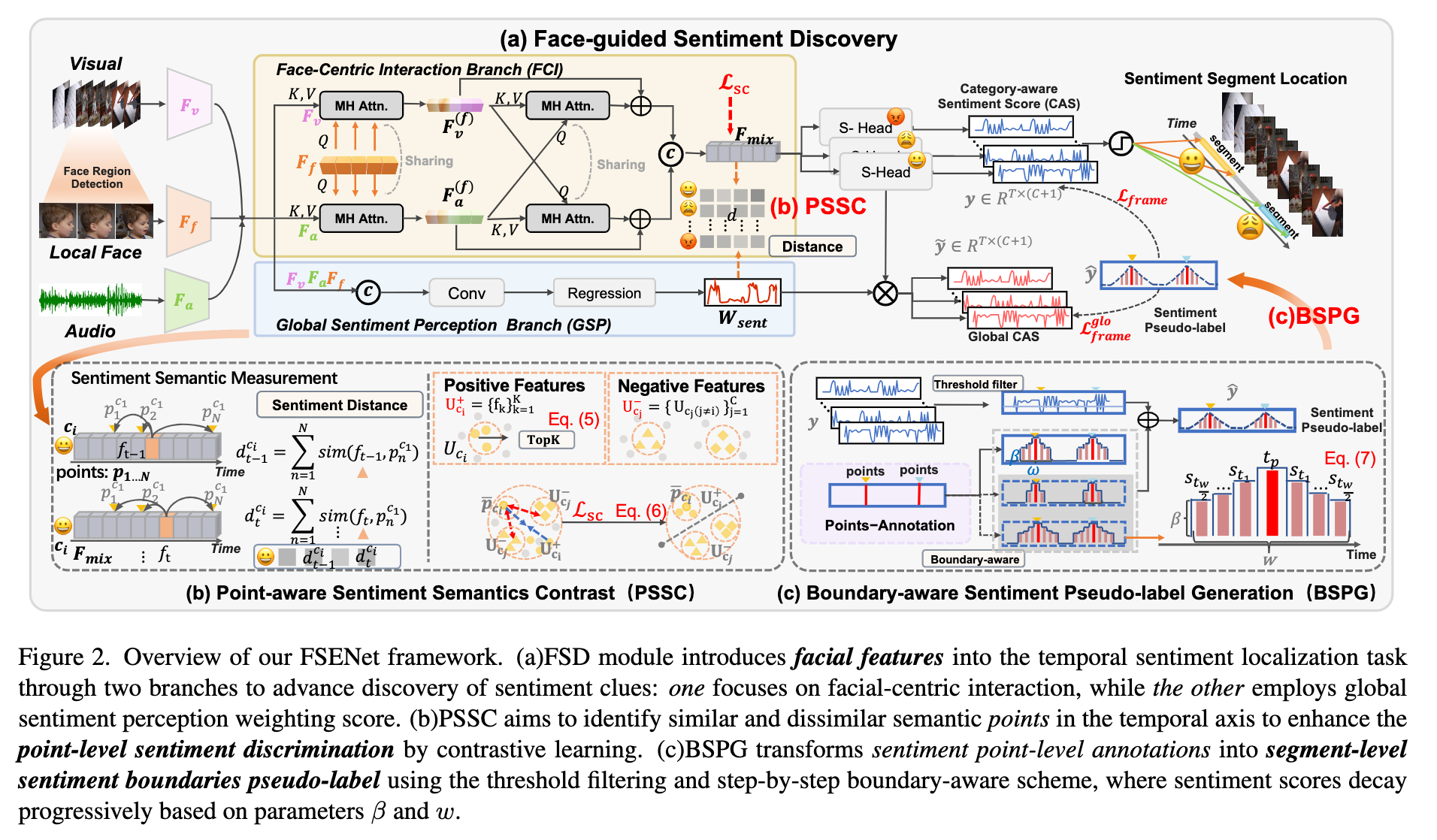
研究的是视频情感定位(Temporal Sentiment Localization, TSL),即不仅判断视频情绪是正面还是负面,还要定位情绪发生的具体时间段。作者认为现有方法主要依赖视觉和音频特征,但情绪最直接的载体其实是人脸表情,因此提出 FSENet,将人脸特征作为核心引导信号,指导音频和视觉模态进行情感发现与边界定位。具体包括三个模块:
① Face-guided Sentiment Discovery(FSD),利用人脸特征引导音视频特征交互;
② Point-aware Sentiment Semantics Contrast(PSSC),利用点级标注做对比学习,扩展情感语义范围;
③ Boundary-aware Sentiment Pseudo-label Generation(BSPG),生成平滑的伪标签以提升情感边界定位精度。
效果:实验在 TSL300 数据集上取得 SOTA,平均 mAP 从此前最佳方法 TSL 的 20.40% 提升到 21.45%,同时明显优于 Qwen3-Omni 等通用多模态大模型。
核心结论:在人脸频繁出现的视频场景中,人脸特征比全局视觉内容更适合作为情感理解与时间边界定位的锚点,通过"Face-guided Video Understanding"能够显著提升视频情感片段发现能力。
二、相关benchmark
FaceXBench: Evaluating Multimodal LLMs on Face Understanding
FaceXBench: Evaluating Multimodal LLMs on Face Understanding
论文链接: https://arxiv.org/abs/2501.10360
研究当前 GPT-4o、Qwen2-VL、InternVL 等多模态大模型到底具备多强的人脸理解能力。作者构建了首个综合性人脸评测基准 FaceXBench,覆盖人脸识别、明星识别、年龄性别预测、表情分析、活体检测、Deepfake 检测等 14 项任务,共 5000 道测试题。
实验发现,即使是 Qwen2-VL-72B、InternVL2-76B 等最强模型,准确率也仅约 58%,明显低于人类(70%)和专业人脸模型(84%)。此外,Chain-of-Thought 等推理技巧几乎没有帮助,说明当前 MLLM 的推理能力尚未真正迁移到细粒度人脸理解场景。
结论是:人脸理解仍是多模态大模型的重要短板,未来可能需要结合专业视觉模型和 Agent/Tool Use 方案才能进一步突破。
Benchmarking MLLMs for Face Recognition
Benchmarking Multimodal Large Language Models for Face Recognition
论文链接: https://arxiv.org/abs/2510.14866

虽然 GPT-4o、Qwen2-VL、InternVL 等多模态大模型在人脸属性分析、表情识别等任务上表现不错,但其真正的人脸识别(Face Recognition)能力一直缺少与专业人脸模型公平对比的评测。为了解决这个问题,作者提出 FaceRecBench,采用与传统人脸识别完全一致的验证协议:输入两张人脸图片,直接判断是否为同一个人(Yes/No),并在 LFW、AgeDB、CALFW、CPLFW、CFP 等标准人脸识别数据集上系统评测 20+ 开源 MLLM。实验发现,表现最好的 MLLM 是 Qwen2-VL-7B(81.1%)(截止25年10月),其次是 Valley2(78.9%)和 Qwen2.5-VL-7B(76.6%),但仍明显落后于专业人脸识别模型 IResNet-50(97.3%)。作者进一步发现,FaceLLM 这类经过人脸领域数据微调的模型相比原始 InternVL3 有明显提升,说明领域数据对人脸识别能力至关重要。论文核心结论是:当前 MLLM 已具备一定身份辨别能力,但距离专业级人脸识别模型仍有巨大差距,人脸识别仍然需要专门模型或领域化训练
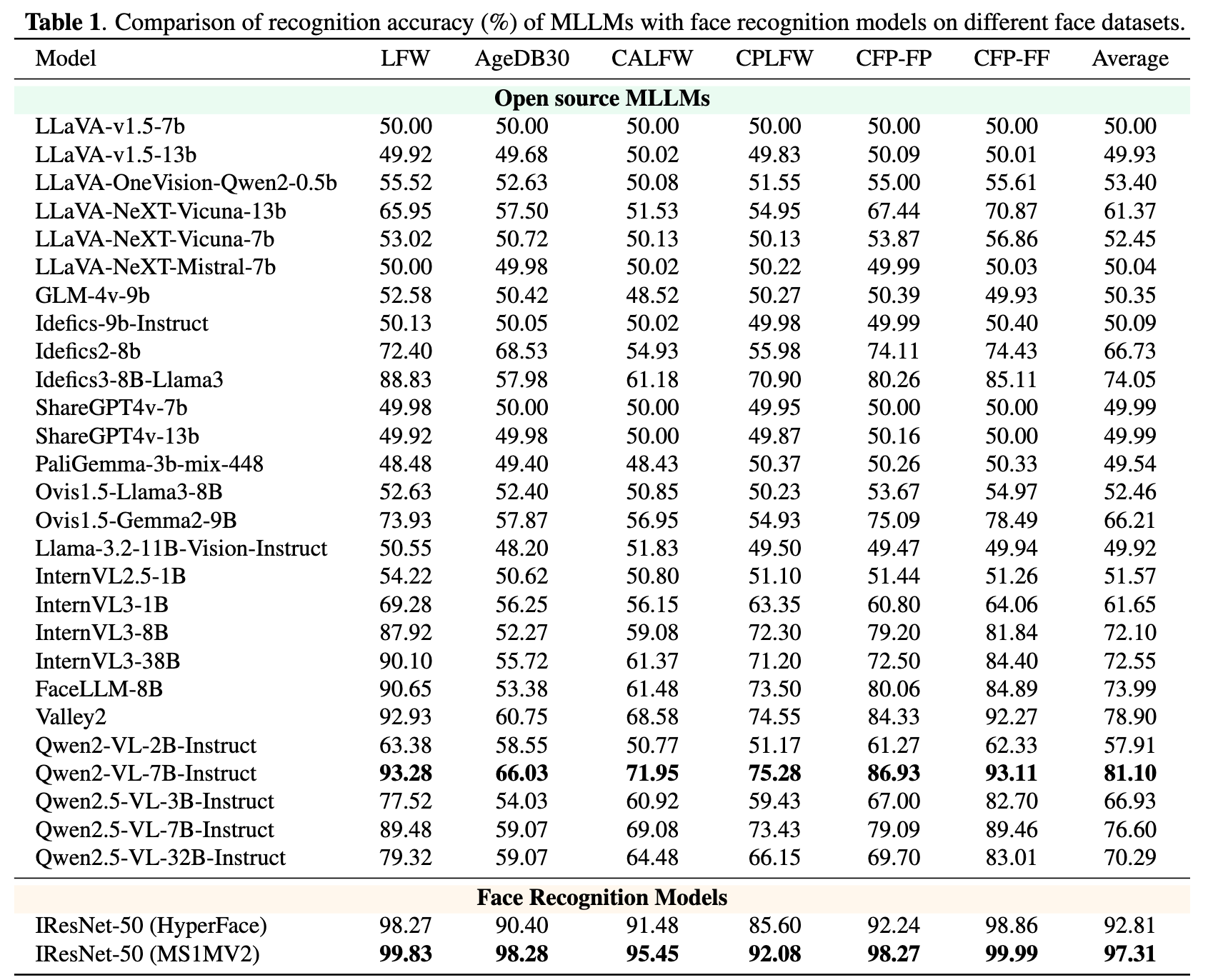
使用的评测集:
| 数据集 | 挑战 |
|---|---|
| LFW | 普通场景 |
| AgeDB | 跨年龄 |
| CALFW | 年龄变化更大 |
| CPLFW | 姿态变化 |
| CFP-FP | 正脸 vs 侧脸 |
| RFW | 不同种族 |