本文接续上一篇文章对Gemma4的vLLM部署测试,继续进行LoRA微调测试。
本文使用Gemma 4 E4B-it(instruction-tuned 版本,自带官方 chat template)在AI-ModelScope/emotion(dair-ai/emotion 镜像)情绪分类数据集上进行 LoRA 微调,提升Gemma4对语句的情绪识别能力。
一、原理
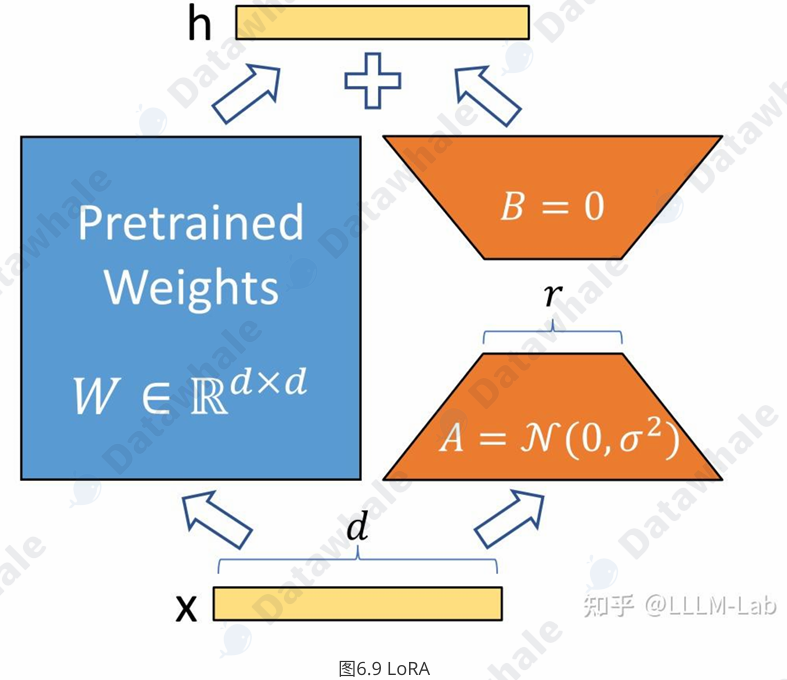
1、LoRA原理介绍
Adapt Tuning:在模型中添加 Adapter 层,在微调时冻结原参数,仅更新 Adapter 层。
如果⼀个⼤模型是将数据映射到⾼维空间进⾏处理,这⾥假定在处理⼀个细分的⼩任务时,是不需要那么复杂的⼤模型的,可能只需要在某个⼦空间范围内就可以解决,那么也就不需要对全量参数进⾏优化了,可以定义当对某个⼦空间参数进⾏优化时,能够达到全量参数优化的性能的⼀定⽔平(如90%精度)时,那么这个⼦空间参数矩阵的秩就可以称为对应当前待解决问题的本征秩(intrinsic rank)。
预训练模型本身就隐式地降低了本征秩,当针对特定任务进⾏微调后,模型中权重矩阵其实具有更低的本征秩(intrinsic rank)。同时,越简单的下游任务,对应的本征秩越低。
通过优化密集层在适应过程中变化的秩分解矩阵来间接训练神经⽹络中的⼀些密集层,从⽽实现仅优化密集层的秩分解矩阵来达到微调效果。
假设预训练参数为 θ 0 D \theta_{0}^{D} θ0D,在特定下游任务上密集层权重参数矩阵对应的本征秩为 θ d \theta^{d} θd,对应特定下游任务微调
参数为 θ D \theta^{D} θD,那么有:
θ D = θ 0 D + θ d M \theta^{D} = \theta_{0}^{D} + \theta^{d}M θD=θ0D+θdM
这个 M M M为 LoRA 优化的秩分解矩阵。
LORA的优势:
- 可以针对不同的下游任务构建⼩型 LoRA 模块,从⽽在共享预训练模型参数基础上有效地切换下游任务;
- LoRA 使⽤⾃适应优化器(Adaptive Optimizer),不需要计算梯度或维护⼤多数参数的优化器状态,训练更
有效、硬件⻔槛更低; - LoRA 使⽤简单的线性设计,在部署时将可训练矩阵与冻结权重合并,不存在推理延迟;
- LoRA 与其他⽅法正交,可以组合
因此,对于资源受限、有监督训练数据受限的情况下,LoRA 微调往往会成为 LLM 微调的⾸选⽅法。
2、数据集介绍
AI-ModelScope/emotion 是魔搭上对 dair-ai/emotion 的官方镜像,**字段、split、标签完全一致**,是一个英文情绪分类数据集:
字段:text(string)、label(int,对应下方 6 个类别)
split:train / validation / test(16000 / 2000 / 2000)
标签:
0 → sadness
1 → joy
2 → love
3 → anger
4 → fear
5 → surprise二、微调
-
从魔搭社区Modelscope社区下载模型和数据集,对国内网络友好;
-
单卡训练,更适合入手
-
保留LoRA微调,微调前后评估、CSV文件保存等完整流程
-
针对 AMD / ROCm 环境,默认不使用 bitsandbytes 4bit,因为 ROCm 下兼容性不如 CUDA 稳定。(如果你使用的是 AMD ROCm,PyTorch 里仍然通过 torch.cuda 访问 GPU,这是 PyTorch 的统一接口,并不代表你在使用 NVIDIA CUDA。)
-
AI-ModelScope/emotion(dair-ai/emotion 镜像)情绪分类数据集
开始微调
- 安装依赖
modelscope:从魔搭下载模型和数据集(snapshot_download 下载模型到本地 + dataset_snapshot_download 下载数据集)
transformers:加载 Gemma 模型和 tokenizer
datasets:用 load_dataset("parquet", ...) 从本地 parquet 加载数据,并提供 DatasetDict / ClassLabel 等数据结构
trl:使用 SFTTrainer 做指令微调instruction
peft:配置 LoRA
scikit-learn:计算 accuracy、F1、classification report、confusion matrix。
shell
!uv pip install -U vllm modelscope transformers==5.8.0 accelerate datasets trl peft scikit-learn pandas tqdm torchvision --no-cache -i https://mirrors.cloud.tencent.com/pypi/simple/ --extra-index-url https://wheels.vllm.ai/rocm/运行结果如下:

新建文件夹复制下面的内容并运行确认第三方Python包可使用,具体内容如下:
python
import os
import re
import json
import random
import warnings
import numpy as np
import pandas as pd
import torch
from tqdm.auto import tqdm
from datasets import Dataset, DatasetDict, ClassLabel, load_dataset
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, f1_score
from modelscope import snapshot_download
from modelscope.hub.snapshot_download import dataset_snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
from peft import LoraConfig, PeftModel
from trl import SFTConfig, SFTTrainer
warnings.filterwarnings("ignore")
# -----------------------------
# 基础配置
# -----------------------------
# 魔搭上的模型 ID(Gemma 4 E4B-it 在 ModelScope 上的官方仓库,instruction-tuned 版本,
# 仓库内自带官方 chat_template.jinja,无需手动处理 chat template)。
# 仓库地址: https://www.modelscope.cn/models/google/gemma-4-E4B-it
MODELSCOPE_MODEL_ID = "google/gemma-4-E4B-it"
# 魔搭上的数据集 ID(dair-ai/emotion 在 ModelScope 上的官方镜像)。
MODELSCOPE_DATASET_ID = "AI-ModelScope/emotion"
# 微调输出目录
OUTPUT_DIR = "./gemma4-it-emotion-lora-ms-single-gpu"
# 这里代码默认只截取一部分数据。跑通后你可以把 TRAIN_LIMIT 改大,甚至设为 None 使用全量数据。
TRAIN_LIMIT = 4000
VALIDATION_LIMIT = 400
TEST_LIMIT = 400
EVAL_LIMIT = 400
SEED = 42
MODEL_DTYPE = torch.bfloat16
BF16 = True # 默认使用BF16
FP16 = False
SYSTEM_PROMPT = """You are an emotion classification assistant.
Read the user's text and answer with exactly one label.
Only choose from: sadness, joy, love, anger, fear, surprise.
Return only the label and nothing else."""
LABEL_PATTERN = re.compile(r"(sadness|joy|love|anger|fear|surprise)", re.IGNORECASE)
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs("./models", exist_ok=True)
os.makedirs("./datasets", exist_ok=True)
print("torch version:", torch.__version__)
print("torch.cuda.is_available():", torch.cuda.is_available())
print("torch.cuda.device_count():", torch.cuda.device_count())
if torch.cuda.is_available():
print("current device:", torch.cuda.current_device())
print("device name:", torch.cuda.get_device_name(0))运行结果如下:

注:如果使用的是显卡不支持BF16,可以把MODEL_DTYPE=torch.float16、BF16=False和FP16=True,如果显存不够,可以优先降低以下值的大小:TRAIN_LIMIT、EVAL_LIMIT、per_device_train_batch_size和max_length。
- 固定随机种子
固定随机种子可以让数据 shuffle、LoRA 初始化和训练过程尽量可复现。
python
def setup_seed(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
set_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
setup_seed(SEED)运行结果如下:

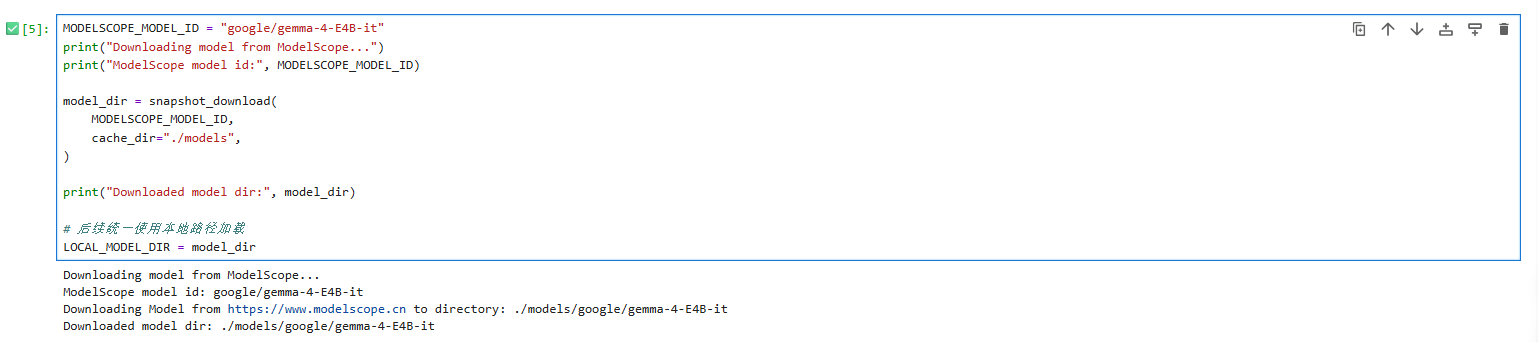
- 从MODELSCOPE下载Gemma4模型
python
MODELSCOPE_MODEL_ID = "google/gemma-4-E4B-it"
print("Downloading model from ModelScope...")
print("ModelScope model id:", MODELSCOPE_MODEL_ID)
model_dir = snapshot_download(
MODELSCOPE_MODEL_ID,
cache_dir="./models", # 将模型下载都当前models文件夹下
)
print("Downloaded model dir:", model_dir)
# 后续统一使用本地路径加载
LOCAL_MODEL_DIR = model_dir运行结果如下:
如果下载失败,常见原因是:
1、魔搭上模型仓库名google/gemma-4-E4B-it与这里配置的名称MODELSCOPE_MODEL_ID不一致
2、当前模型需要在魔搭网页登录后接受授权(需提前在网页端登录Modelscope账号)
3、网络无法访问魔搭
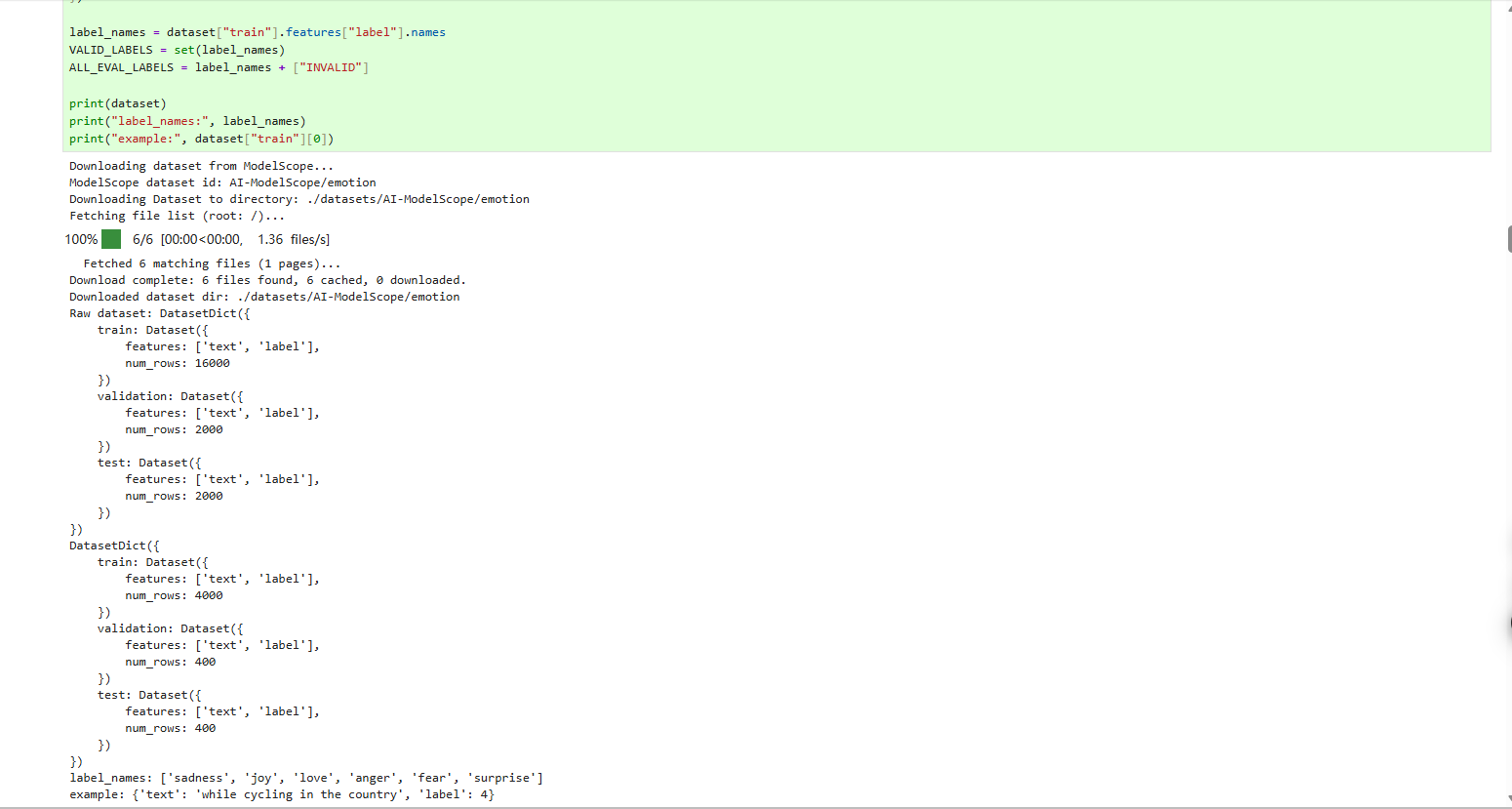
- 从Modelscope上下载数据集
本文通过modelscope.hub.snapshot_download.dataset_snapshot_download() 把数据集仓库整体拉到本地(包含data/*.parquet 文件),然后用 datasets.load_dataset("parquet", data_files=...) 从本地 parquet 加载。这样做不依赖 MsDataset 内部对 datasets 库的桥接代码,可以避开类似 as_dataset() got an unexpected keyword argument 'verification_mode' 的版本兼容报错。
实现细节:从 parquet 文件加载时,label 字段类型会退化成普通 int64。这里显式 cast_column("label", ClassLabel(names=...)),让 features"label".names 可以直接拿到标签名,与原始 HF 版本接口完全一致,后续 prompt 构造、评估、混淆矩阵等下游代码一字未改。
python
import glob
EMOTION_LABEL_NAMES = ["sadness", "joy", "love", "anger", "fear", "surprise"]
# 直接把魔搭上的数据集仓库(parquet 文件)整体下载到本地,然后用 datasets 库从本地 parquet 加载。
# 不走 MsDataset.load -> datasets.load_dataset 的桥接路径,可以规避 modelscope 与 datasets 之间
# `as_dataset() got an unexpected keyword argument 'verification_mode'` 这类版本错配错误。
print("Downloading dataset from ModelScope...")
print("ModelScope dataset id:", MODELSCOPE_DATASET_ID)
dataset_dir = dataset_snapshot_download(
MODELSCOPE_DATASET_ID,
cache_dir="./datasets",
)
print("Downloaded dataset dir:", dataset_dir)
def _parquet_files_for(split_name: str):
pattern = os.path.join(dataset_dir, "data", f"{split_name}-*.parquet")
files = sorted(glob.glob(pattern))
if not files:
raise FileNotFoundError(
f"No parquet files matched pattern: {pattern}. "
f"Please check the dataset repo layout under {dataset_dir}."
)
return files
raw_dataset = load_dataset(
"parquet",
data_files={
"train": _parquet_files_for("train"),
"validation": _parquet_files_for("validation"),
"test": _parquet_files_for("test"),
},
)
# 从 parquet 加载时,label 字段类型会退化成普通整数,这里显式 cast 成 ClassLabel,
# 这样后续 `dataset["train"].features["label"].names` 和原始 HF 版接口完全一致。
for split_name in list(raw_dataset.keys()):
if not isinstance(raw_dataset[split_name].features.get("label"), ClassLabel):
raw_dataset[split_name] = raw_dataset[split_name].cast_column(
"label", ClassLabel(names=EMOTION_LABEL_NAMES)
)
print("Raw dataset:", raw_dataset)
def maybe_limit(split, limit):
split = split.shuffle(seed=SEED)
if limit is None:
return split
return split.select(range(min(limit, len(split))))
dataset = DatasetDict({
"train": maybe_limit(raw_dataset["train"], TRAIN_LIMIT),
"validation": maybe_limit(raw_dataset["validation"], VALIDATION_LIMIT),
"test": maybe_limit(raw_dataset["test"], TEST_LIMIT),
})
label_names = dataset["train"].features["label"].names
VALID_LABELS = set(label_names)
ALL_EVAL_LABELS = label_names + ["INVALID"]
print(dataset)
print("label_names:", label_names)
print("example:", dataset["train"][0])运行结果如下:
-
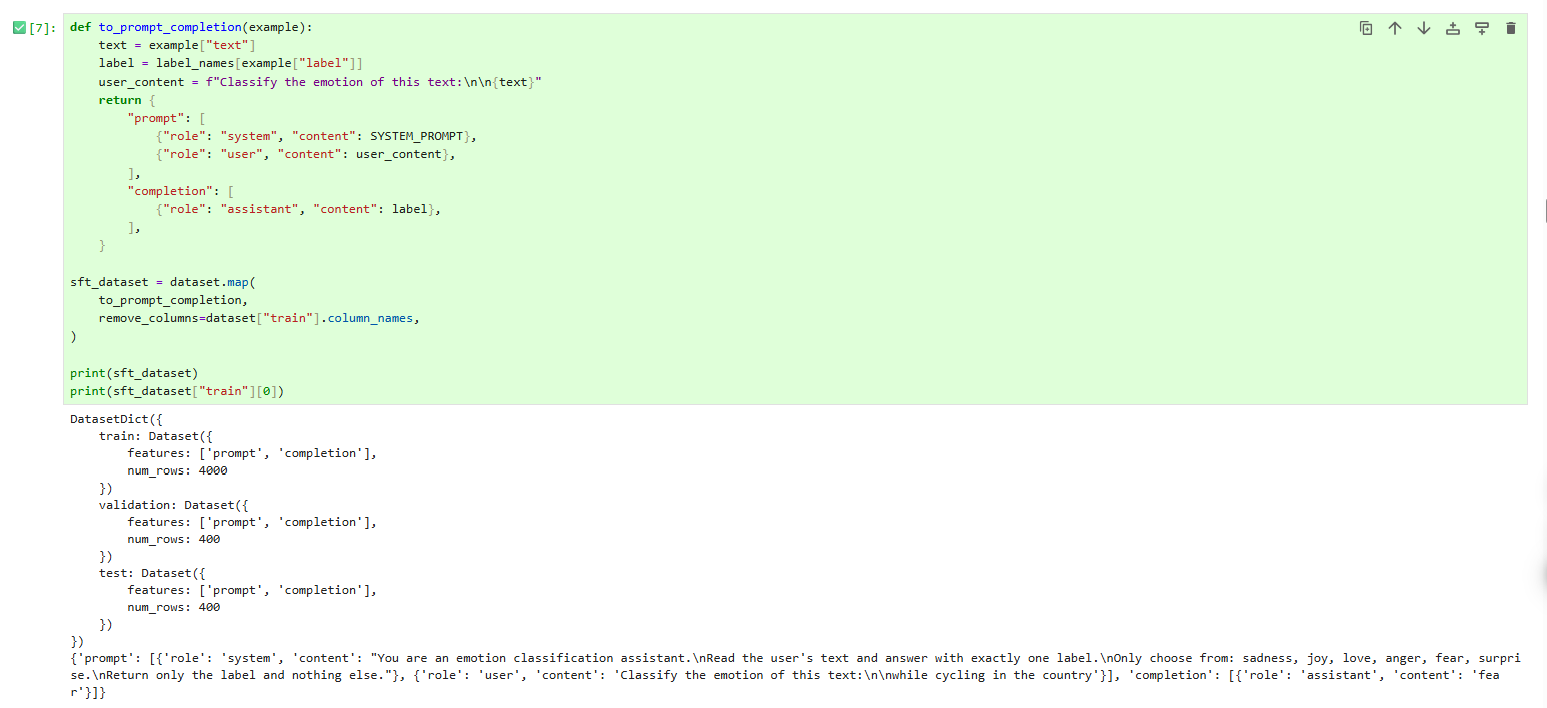
构造prompt-completion格式数据
这里把普通分类数据转换成聊天模型适合的指令微调格式:
prompt:system + user
completion:assistant 只输出一个情绪标签
这样训练后的模型会更倾向于严格输出:
sadness / joy / love / anger / fear / surprise
python
def to_prompt_completion(example):
text = example["text"]
label = label_names[example["label"]]
user_content = f"Classify the emotion of this text:\n\n{text}"
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"completion": [
{"role": "assistant", "content": label},
],
}
sft_dataset = dataset.map(
to_prompt_completion,
remove_columns=dataset["train"].column_names,
)
print(sft_dataset)
print(sft_dataset["train"][0])运行结果如下:
- 加载tokenizer和基础模型
python
print("Loading tokenizer from:", LOCAL_MODEL_DIR)
tokenizer = AutoTokenizer.from_pretrained(
LOCAL_MODEL_DIR,
use_fast=True,
trust_remote_code=True,
extra_special_tokens={}, # 传入空字典而非列表
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print("pad_token:", tokenizer.pad_token)
print("eos_token:", tokenizer.eos_token)
# `google/gemma-4-E4B-it` 的 tokenizer 通常会自带 chat_template。
# 若缺失(缓存不完整等),从同一魔搭仓库拉取官方 chat_template.jinja 注入(权重已在上面整仓下载时可跳过额外拉取)。
TEMPLATE_SOURCE_MODEL_ID = "google/gemma-4-E4B-it"
def _load_official_gemma_chat_template() -> str:
"""从 gemma-4-E4B-it 仓库下载官方 chat_template.jinja 并返回字符串。
主路径:modelscope.snapshot_download(allow_file_pattern=["chat_template.jinja"])
兜底:ModelScope raw file API 直接 HTTP GET
"""
try:
template_dir = snapshot_download(
TEMPLATE_SOURCE_MODEL_ID,
cache_dir="./models",
allow_file_pattern=["chat_template.jinja"],
)
path = os.path.join(template_dir, "chat_template.jinja")
if os.path.exists(path):
with open(path, "r", encoding="utf-8") as f:
return f.read()
except Exception as e:
print("snapshot_download(allow_file_pattern) failed, fallback to HTTP. err =", e)
import urllib.request
url = (
"https://www.modelscope.cn/api/v1/models/"
f"{TEMPLATE_SOURCE_MODEL_ID}/repo?Revision=master&FilePath=chat_template.jinja"
)
with urllib.request.urlopen(url, timeout=60) as resp:
return resp.read().decode("utf-8")
if not getattr(tokenizer, "chat_template", None):
print(f"Loading official chat_template.jinja from {TEMPLATE_SOURCE_MODEL_ID} ...")
tokenizer.chat_template = _load_official_gemma_chat_template()
print("Loaded official chat_template, length =", len(tokenizer.chat_template))
else:
print("tokenizer.chat_template already set, leaving as-is.")
# 自检:跑一次 apply_chat_template,确保模板可用。
_probe = tokenizer.apply_chat_template(
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
],
tokenize=False,
add_generation_prompt=True,
)
print("chat_template probe output:\n" + _probe)
print("Loading base model from:", LOCAL_MODEL_DIR)
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using device:", device)
print("HIP version:", getattr(torch.version, "hip", None))
# base_model = AutoModelForCausalLM.from_pretrained(
# LOCAL_MODEL_DIR,
# torch_dtype=MODEL_DTYPE,
# low_cpu_mem_usage=True,
# trust_remote_code=True,
# )
base_model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=MODEL_DTYPE,
device_map="auto",
trust_remote_code=True,
)
base_model.to(device)
base_model.config.use_cache = False
base_model.config.pad_token_id = tokenizer.pad_token_id
base_model.config.bos_token_id = tokenizer.bos_token_id
base_model.config.eos_token_id = tokenizer.eos_token_id
base_model.generation_config.pad_token_id = tokenizer.pad_token_id
base_model.generation_config.bos_token_id = tokenizer.bos_token_id
base_model.generation_config.eos_token_id = tokenizer.eos_token_id
print("Base model loaded.")
print("Base model device:", next(base_model.parameters()).device)运行结果如下:
- 推理函数
微调前后都用同一套推理函数做评估,方便对比模型效果。
extract_label()用于从模型生成文本里提取合法标签。如果模型输出了奇怪内容,会被记为 INVALID。
python
def extract_label(raw_text: str) -> str:
raw_text = raw_text.strip().lower()
match = LABEL_PATTERN.search(raw_text)
if match:
return match.group(1)
tokens = raw_text.split()
if not tokens:
return "INVALID"
return tokens[0].strip(".,!?:;\"'()[]{}")
def generate_label(model, tokenizer, user_text: str, system_prompt: str = SYSTEM_PROMPT, max_new_tokens: int = 4) -> str:
user_content = f"Classify the emotion of this text:\n\n{user_text}"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
device = next(model.parameters()).device
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(device) for k, v in inputs.items()}
input_len = inputs["input_ids"].shape[-1]
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
raw_pred = tokenizer.decode(outputs[0][input_len:], skip_special_tokens=True).strip()
return extract_label(raw_pred)
def predict_emotion(text: str, model=None):
model = model or base_model
return generate_label(model, tokenizer, text)
predict_emotion("I feel so happy and excited today!")运行结果如下:
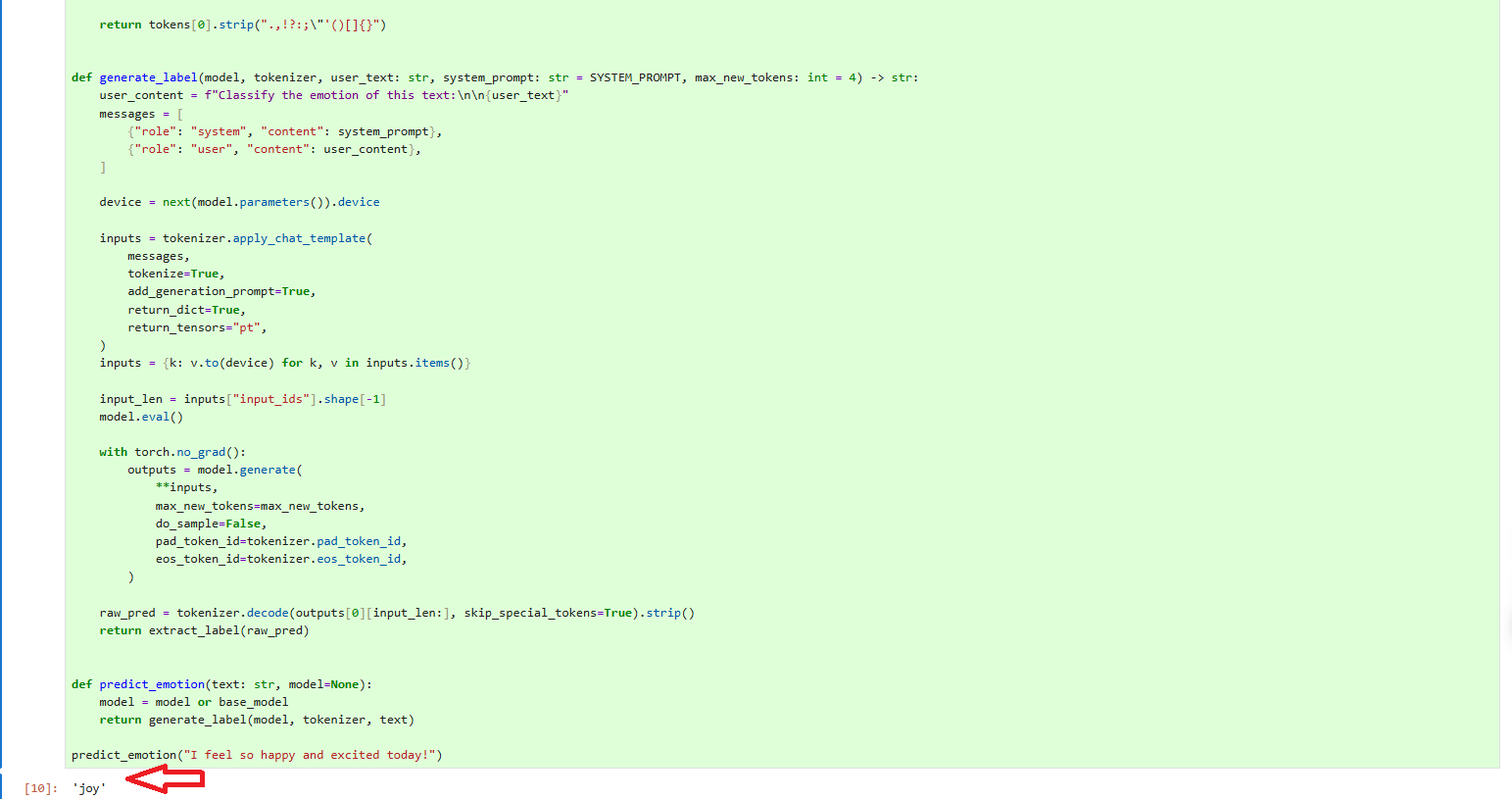
可以看出这里输入我今天感觉非常开心和兴奋,模型回答的情绪是开心,答案是准确的。
- 评估函数
评估指标包括:
accuracy
macro_f1
invalid_predictions
classification_report
confusion_matrix
由于生成式评估比较慢,默认只评估 EVAL_LIMIT=400 条测试样本。
python
def evaluate_model(model, tokenizer, split="test", limit=EVAL_LIMIT):
y_true, y_pred, rows = [], [], []
raw_source = dataset[split]
if limit is not None:
raw_source = raw_source.select(range(min(limit, len(raw_source))))
model.eval()
for ex in tqdm(raw_source, desc=f"Evaluating {split}", leave=False):
true_label = label_names[ex["label"]]
raw_pred_label = generate_label(model, tokenizer, ex["text"], SYSTEM_PROMPT)
pred_label = raw_pred_label if raw_pred_label in VALID_LABELS else "INVALID"
y_true.append(true_label)
y_pred.append(pred_label)
rows.append({
"text": ex["text"],
"true_label": true_label,
"pred_label": pred_label,
"raw_pred_label": raw_pred_label,
"correct": true_label == pred_label,
})
metrics = {
"accuracy": accuracy_score(y_true, y_pred),
"macro_f1": f1_score(y_true, y_pred, labels=label_names, average="macro", zero_division=0),
"invalid_predictions": sum(1 for p in y_pred if p == "INVALID"),
"evaluated_examples": len(y_true),
}
report = classification_report(
y_true,
y_pred,
labels=label_names,
output_dict=True,
zero_division=0,
)
return metrics, report, pd.DataFrame(rows)
def confusion_matrix_df(pred_df):
return pd.DataFrame(
confusion_matrix(pred_df["true_label"], pred_df["pred_label"], labels=ALL_EVAL_LABELS),
index=ALL_EVAL_LABELS,
columns=ALL_EVAL_LABELS,
)- 微调前评估原Gemma4对情绪分类能力
python
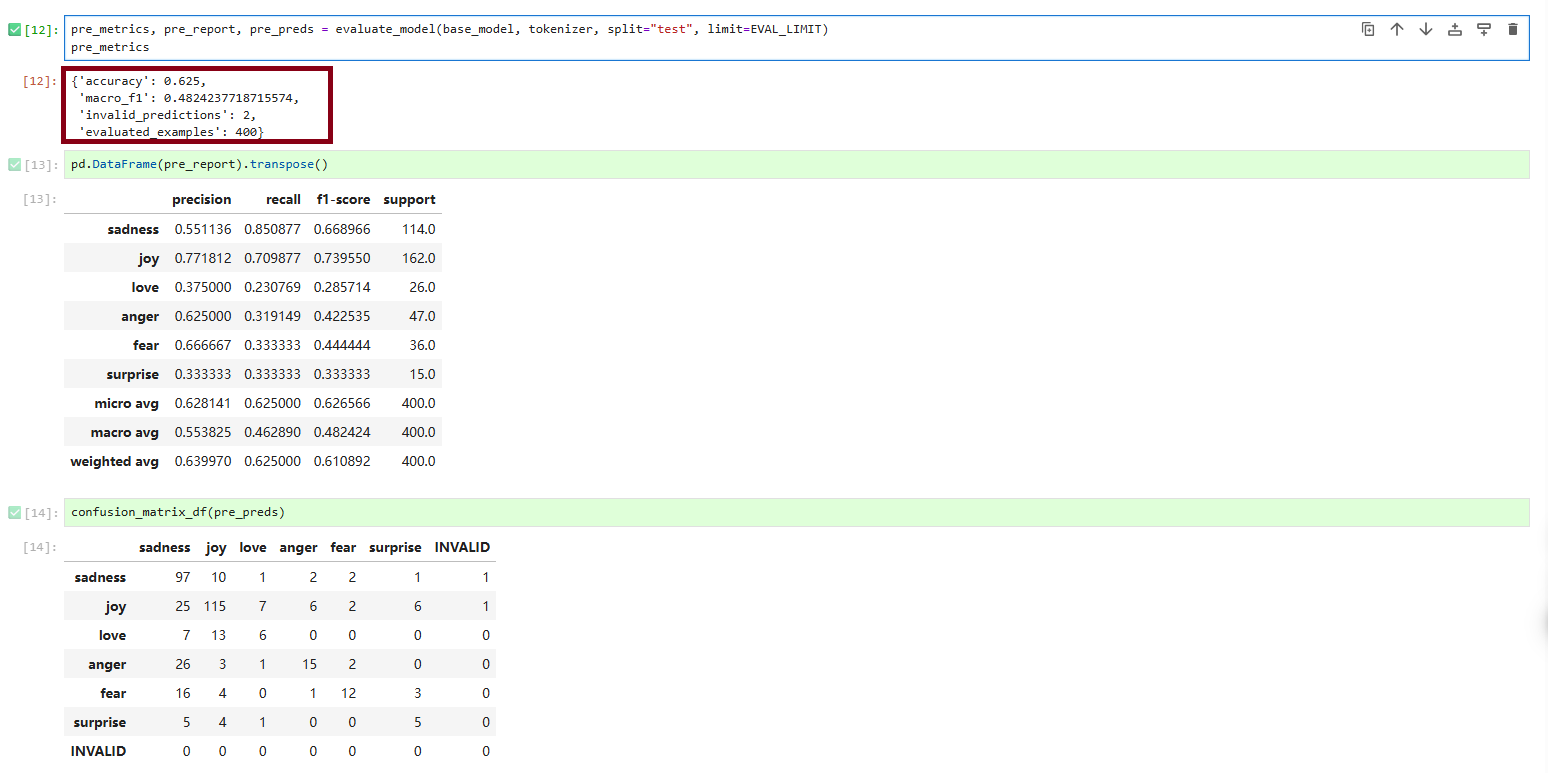
pre_metrics, pre_report, pre_preds = evaluate_model(base_model, tokenizer, split="test", limit=EVAL_LIMIT)
print(pre_metrics)
print(pd.DataFrame(pre_report).transpose())
print(confusion_matrix_df(pre_preds))运行结果如下:
- 配置LoRA
LoRA 只训练一小部分低秩适配器参数,不直接全量更新大模型权重。这里使用:target_modules="all-linear"表示尽量给模型中的线性层加 LoRA,适合先快速跑通。如果你后面想进一步控制显存和训练速度,可以改成指定模块名。
python
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)
training_args = SFTConfig(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=4, # 显存不够的话,可以把 per_device_train_batch_size 改成 1 或 2
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=1e-4,
weight_decay=0.01,
lr_scheduler_type="linear",
warmup_steps=50,
num_train_epochs=1,
logging_steps=5,
eval_strategy="steps",
eval_steps=25,
save_strategy="steps",
save_steps=25,
save_total_limit=2,
metric_for_best_model="eval_loss",
greater_is_better=False,
gradient_checkpointing=True,
bf16=BF16,
fp16=FP16,
tf32=False,
max_length=256,
packing=False,
completion_only_loss=True,
remove_unused_columns=False,
dataloader_num_workers=2,
optim="adamw_torch",
report_to="none",
seed=SEED,
data_seed=SEED,
)- LoRA微调
这里会创建 SFTTrainer 并开始训练。训练前会检查 LoRA 参数是否真的被挂上。如果 Trainable LoRA parameters 为 0,说明 target_modules 没匹配成功,需要调整 LoRA 配置。
python
if isinstance(base_model, PeftModel):
base_model = base_model.unload()
base_model.config.use_cache = False
trainer = SFTTrainer(
model=base_model,
train_dataset=sft_dataset["train"],
eval_dataset=sft_dataset["validation"],
peft_config=lora_config,
args=training_args,
processing_class=tokenizer,
)
trainable_params = 0
total_params = 0
trainable_param_names = []
for name, param in trainer.model.named_parameters():
total_params += param.numel()
if param.requires_grad:
trainable_params += param.numel()
trainable_param_names.append(name)
if trainable_params == 0:
raise RuntimeError("No trainable LoRA parameters were attached. Check target_modules before training.")
print(f"Trainable LoRA parameters: {trainable_params:,}")
print(f"Total parameters: {total_params:,}")
print(f"Trainable ratio: {100 * trainable_params / total_params:.4f}%")
print("Example trainable parameters:")
print(trainable_param_names[:20])
train_result = trainer.train()
trainer.model.eval()
trainer.model.config.use_cache = True
print(train_result)运行结果如下:
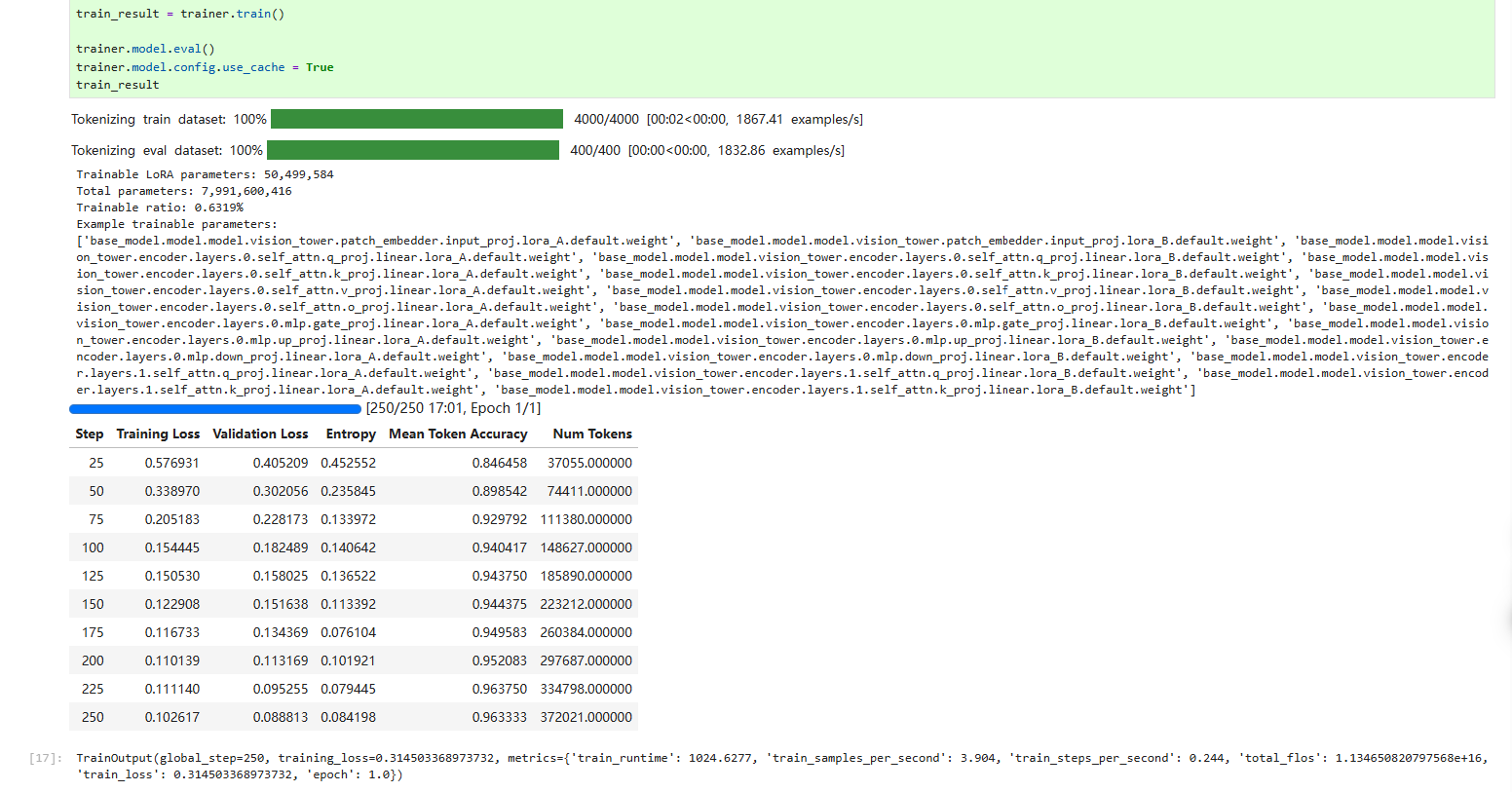
随着微调次数的增加,模型对情绪分类的准确率越来越高。
- 保存LoRA adapter和tokenizer
保存的是 LoRA adapter,不是完整大模型权重。目录中通常包括:adapter_model.safetensors、adapter_config.json、tokenizer 相关文件和training checkpoints。
python
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
with open(os.path.join(OUTPUT_DIR, "train_metrics.json"), "w", encoding="utf-8") as f:
json.dump(train_result.metrics, f, ensure_ascii=False, indent=2)
print("Saved adapter and tokenizer to:", OUTPUT_DIR)- 微调后评估
python
ft_model = trainer.model
ft_model.eval()
ft_model.config.use_cache = True
post_metrics, post_report, post_preds = evaluate_model(ft_model, tokenizer, split="test", limit=EVAL_LIMIT)
print(post_metrics)
print(pd.DataFrame(post_report).transpose())
print(confusion_matrix_df(post_preds))运行结果如下:
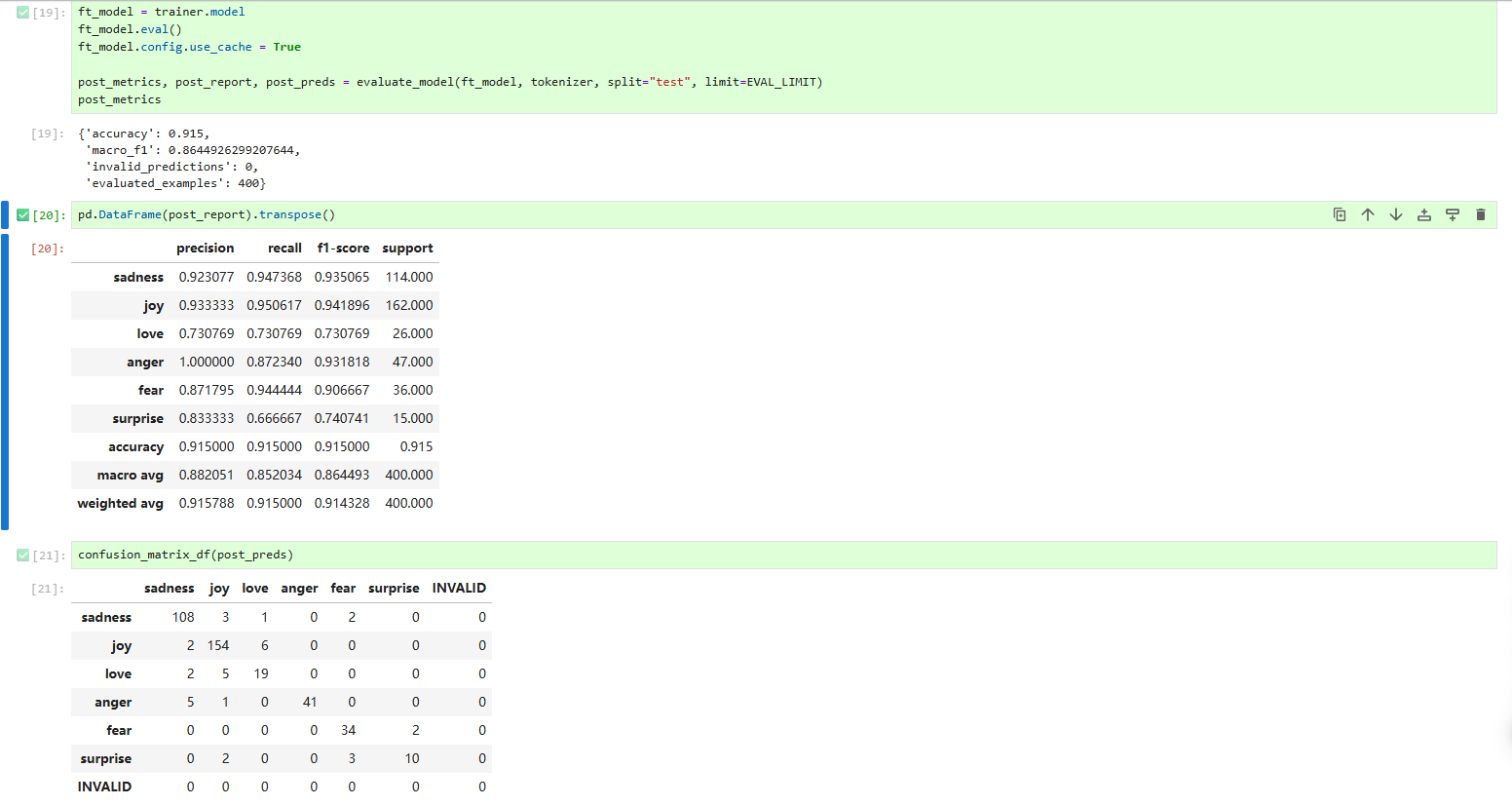
- 微调前后对比
python
comparison_df = pd.DataFrame([
{"stage": "pre_finetuning", **pre_metrics},
{"stage": "post_finetuning", **post_metrics},
])
print(comparison_df)
# 部分分类效果展示
merged_examples = pre_preds.copy()
merged_examples = merged_examples.rename(columns={
"pred_label": "pre_pred",
"correct": "pre_correct",
"raw_pred_label": "pre_raw_pred_label",
})
merged_examples["post_pred"] = post_preds["pred_label"]
merged_examples["post_raw_pred_label"] = post_preds["raw_pred_label"]
merged_examples["post_correct"] = post_preds["correct"]
changed_predictions = merged_examples[merged_examples["pre_pred"] != merged_examples["post_pred"]]
print(changed_predictions.head(20))运行结果如下:
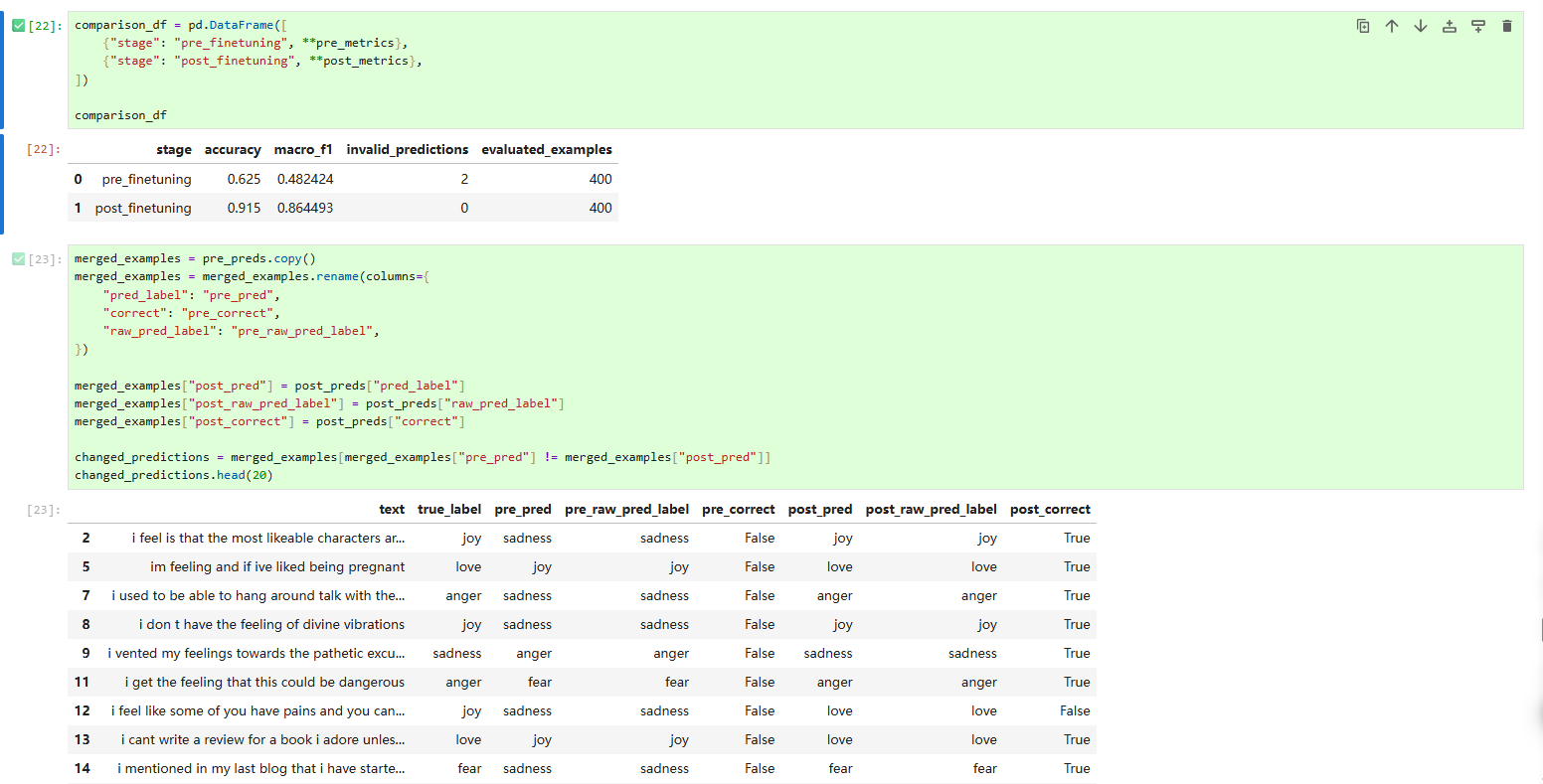
- 保存评估结果
python
comparison_df.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_before_after_metrics.csv"), index=False)
merged_examples.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_prediction_examples.csv"), index=False)
changed_predictions.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_changed_predictions.csv"), index=False)
pre_preds.to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_predictions.csv"), index=False)
post_preds.to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_predictions.csv"), index=False)
pd.DataFrame(pre_report).transpose().to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_classification_report.csv"))
pd.DataFrame(post_report).transpose().to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_classification_report.csv"))
confusion_matrix_df(pre_preds).to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_confusion_matrix.csv"))
confusion_matrix_df(post_preds).to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_confusion_matrix.csv"))
print("Saved all outputs to:", OUTPUT_DIR)三、本地部署测试
结合第二部分的函数,可在本地模型上进行情绪分类的简单部署测试,具体代码如下:
python
user_input = "I feel completely heartbroken and alone." # 待识别的语句
reload_tokenizer = AutoTokenizer.from_pretrained(
OUTPUT_DIR,
use_fast=True,
trust_remote_code=True,
)
if reload_tokenizer.pad_token is None:
reload_tokenizer.pad_token = reload_tokenizer.eos_token
reload_base_model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=MODEL_DTYPE,
low_cpu_mem_usage=True,
trust_remote_code=True,
)
reload_model = PeftModel.from_pretrained(
reload_base_model,
OUTPUT_DIR,
)
reload_model.eval()
print(generate_label(reload_model, reload_tokenizer, user_input))运行结果如下:
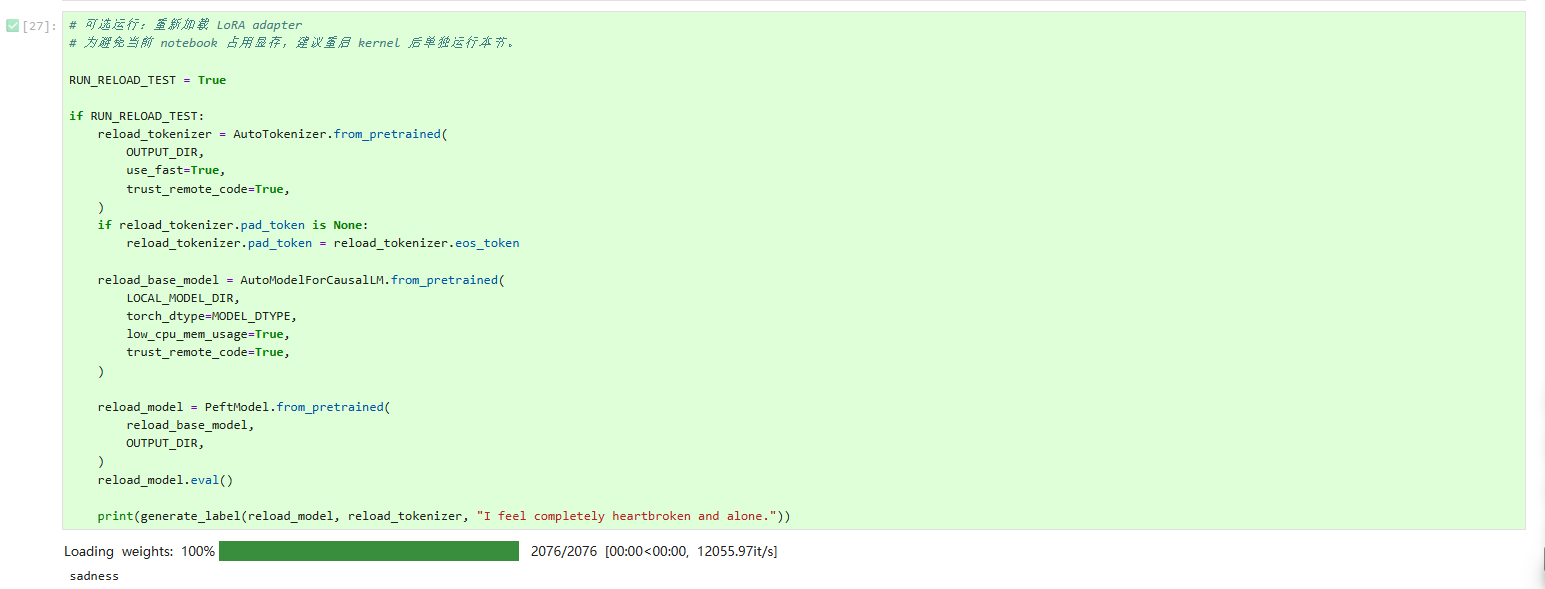
综上,这套代码相信也可以用在Nvidia显卡上进行测试,欢迎大家尝试。